将一个通用 DAG 探索引擎迁移到 Flocks:CTF 回归测试全记录
目录
- [将一个通用 DAG 探索引擎迁移到 Flocks:CTF 回归测试全记录](#将一个通用 DAG 探索引擎迁移到 Flocks:CTF 回归测试全记录)
- 目录
- 写在前面
- [一、背景:Cairn 与 DAG 探索模式](#一、背景:Cairn 与 DAG 探索模式)
- [Cairn 做了什么](#Cairn 做了什么)
- 三个核心实体,一块黑板
- 三类任务驱动图生长
- [为什么迁移到 Flocks](#为什么迁移到 Flocks)
- [二、迁移到 Flocks](#二、迁移到 Flocks)
- [三、CTF 回归测试](#三、CTF 回归测试)
- [3.1 CTF Web 回归测试](#3.1 CTF Web 回归测试)
- [题目 W1:Baby LFI](#题目 W1:Baby LFI)
- [题目 W2:LFI](#题目 W2:LFI)
- [题目 W3:HEADache](#题目 W3:HEADache)
- [3.2 CTF 逆向回归测试](#3.2 CTF 逆向回归测试)
- [题目 R1:EasyReverse](#题目 R1:EasyReverse)
- [题目 R2:Crackme](#题目 R2:Crackme)
- [3.3 测试结果汇总](#3.3 测试结果汇总)
- [3.1 CTF Web 回归测试](#3.1 CTF Web 回归测试)
- 四、已知问题
- 五、总结与思考
- 附录:参考资料
写在前面
关注到 Flocks AI 安全运营挑战赛后,我开始思考一个问题:Flocks 能不能实现类似 DAG 探索的能力?
Flocks 本身已经支持 AI 动态生成工作流,但这个生成的流程本质上仍是"固定的"------一旦生成,执行路径就确定了。在安全运营场景中,很多问题并没有预设的答案路径:日志分析、调查溯源、漏洞探索......你往往不知道下一步该查什么,只能走一步看一步。
这让我想起了之前了解到的 Cairn 项目。它在今年的腾讯云 Hackathon 中以 54 题全部解答(AK) 的成绩证明了 DAG 探索模式的有效性:不定义角色、不写死工作流,只给起点和终点,让 AI Agent 在未知状态空间中自主生长探索路径。
于是思路就清晰了:在 Flocks 上实现 Cairn 的 DAG 探索引擎。短期看可以验证集成可行性,长期看------这个能力放到日志分析、告警溯源、事件调查等安全运营场景里,想象空间很大。
本文记录的就是这个过程------从阅读 Cairn 源码,到将其 DAG 探索引擎集成到 Flocks,再到用 5 道 CTF 真题做回归测试。所有截图均为实际运行结果,代码可复现(参见附录中的 fork 仓库)。
一、背景:Cairn 与 DAG 探索模式
Cairn 做了什么
Cairn 的核心思想一句话就能说清:
给定起点(Origin)和终点(Goal),在未知状态空间中自主搜索一条可行路径。
它不区分"情报分析师""漏洞研究员"这类角色,也不依赖预设的自动化剧本。Agent 读到的只有一块共享的"黑板"------上面记录了已经发现的事实(Fact)、正在考虑的探索方向(Intent),以及外部注入的策略提示(Hint)。Agent 自己决定下一步做什么,每完成一步就更新黑板,触发下一轮推理。
三个核心实体,一块黑板
Origin ──► Intent ──► Fact ──► Intent ──► Fact ──► ... ──► Goal
│ │ │ │
▼ ▼ ▼ ▼
[起点] [探索方向] [新发现] [新方向] [终点]| 实体 | 是什么 | 怎么用 |
|---|---|---|
| Fact | Agent 已经确认的事实,不可篡改 | 所有推理的基石,跨任务可复用 |
| Intent | 基于当前 Fact 提出的探索方向 | Agent 认领后执行,产生新 Fact |
| Hint | 外部注入的策略线索 | 引导方向但不参与内部推理 |
Agent 之间不直接通信------它们全部通过黑板的间接协作(Stigmergy 模式)来协调。这和传统 SOAR 中"A 调用 B、B 返回给 A"的显式流程完全不同,系统复杂度天然更低。
三类任务驱动图生长
| 任务 | 做什么 | 什么时候触发 |
|---|---|---|
| Bootstrap | 直接从 Origin+Goal 出发尝试解题,产生初始 Fact | 项目刚创建 |
| Reason | 读图、判断是否已完成,没完成就生成新的 Intent | 图状态(新增 Fact/Intent)变化 |
| Explore | 认领一个 Intent,执行具体探索,产生新 Fact | 有 Intent 等待认领 |
三种任务循环往复,图从 Origin 向 Goal 不断生长,最终要么到达终点(完成),要么穷尽探索空间(无解)。
为什么迁移到 Flocks
Cairn 在 Hackathon 的表现证明了它的有效性,但它是一个独立项目。搬到 Flocks 上,我想实现几件事:
- 复用基础设施:不用从零造 Session 管理、认证鉴权、日志系统
- 统一入口:通过 Flocks API 暴露 Cairn 能力,CLI 命令行直接操作
- 可视化:利用 Flocks WebUI 渲染 DAG 探索过程
二、迁移到 Flocks
集成方式
DAG 探索引擎作为 Flocks 的一个内置模块运行:
┌─────────────────────────────────────────────────────────────┐
│ Flocks 平台层 │
│ ┌─────────────────────────────────────────────────────┐ │
│ │ DAG Exploration Engine │ │
│ │ ┌───────────┐ ┌───────────┐ ┌───────────────┐ │ │
│ │ │ Dispatcher│ │ Worker │ │ DAG 可视化 │ │ │
│ │ │ 图调度器 │ │ 探索执行器│ │ (WebUI) │ │ │
│ │ └───────────┘ └───────────┘ └───────────────┘ │ │
│ │ ┌───────────────────────────────────────────────┐ │ │
│ │ │ Graph Storage (SQLite) │ │ │
│ │ │ Projects │ Facts │ Intents │ Hints │ │ │
│ │ └───────────────────────────────────────────────┘ │ │
│ └─────────────────────────────────────────────────────┘ │
└─────────────────────────────────────────────────────────────┘实际代码中,Worker 完全使用 Flocks 自身的 LLM ------通过 SessionLoop 执行完整的 LLM + Tool 调用循环,不需要依赖外部 CLI 工具。调度器 DispatcherLoop 管理所有项目的图生长任务。
测试环境搭建
为了验证迁移后的引擎是否正常工作,我搭建了一套回归测试环境。CTF 靶场题目来自网上公开的 CTF 训练场,HexStrike-AI 则作为 Kali 工具 MCP 服务,为 Worker 提供命令执行能力。整个搭建过程分三步:
1. Kali 安装 HexStrike 服务 (提供 Linux 安全工具集):
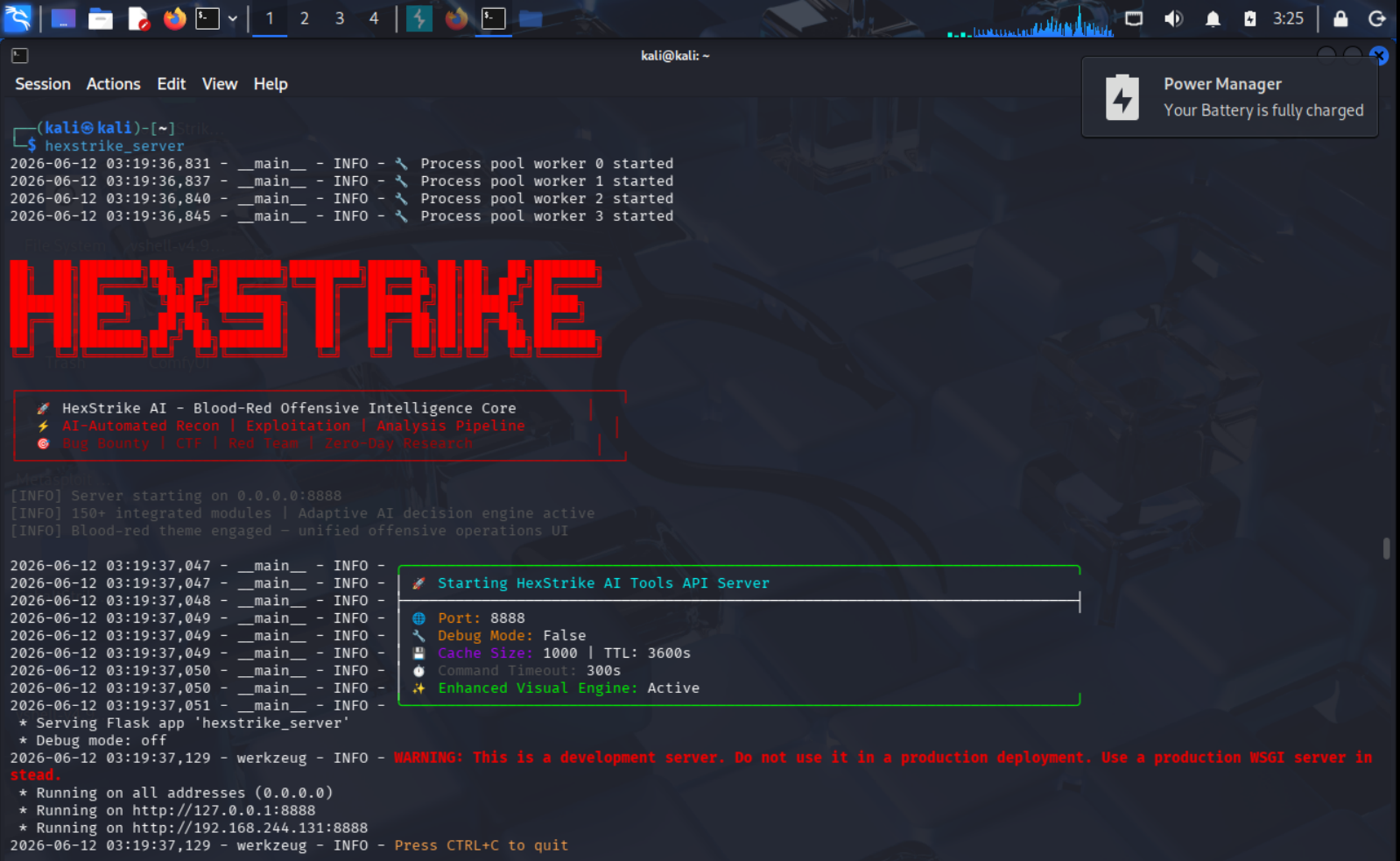
2. Flocks 平台配置 HexStrike-AI MCP 服务 (对接 Kali 工具链):
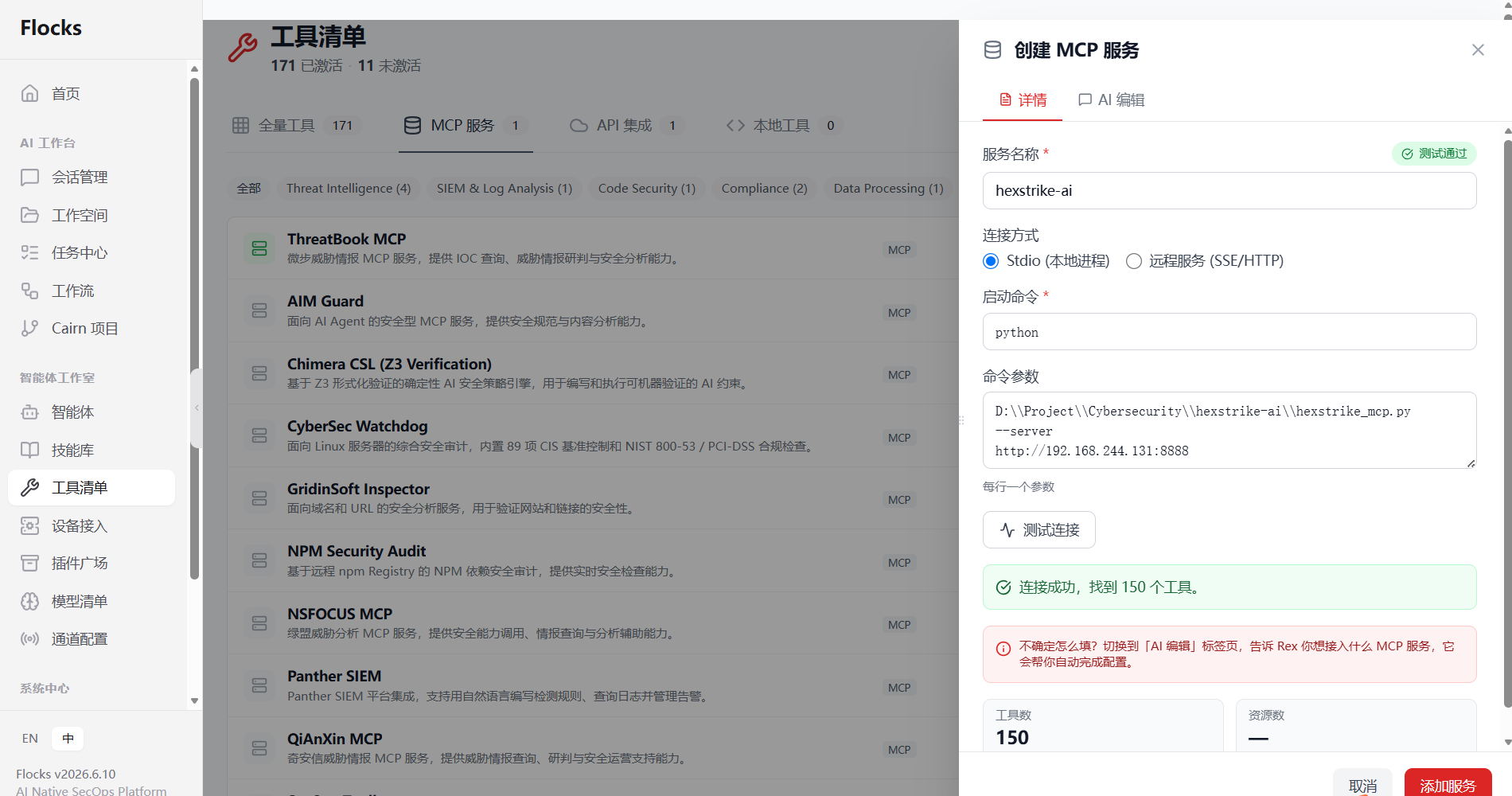
3. Flocks 上创建 CTF-WEB 智能体 ,提示词:"请根据 hexstrike-ai MCP 服务提供的 WEB 相关工具,创建一个 CTF-WEB 的智能体。"
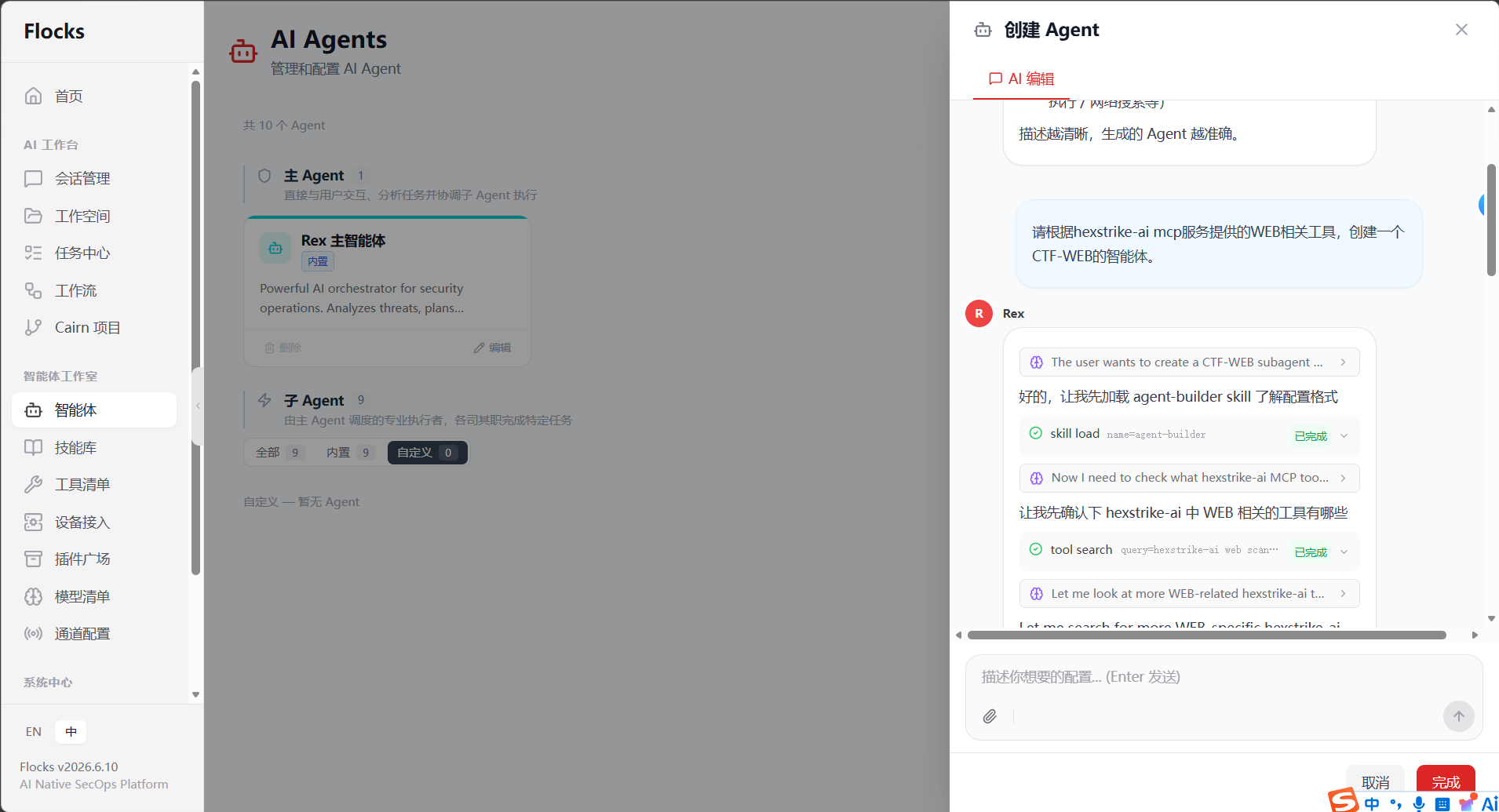
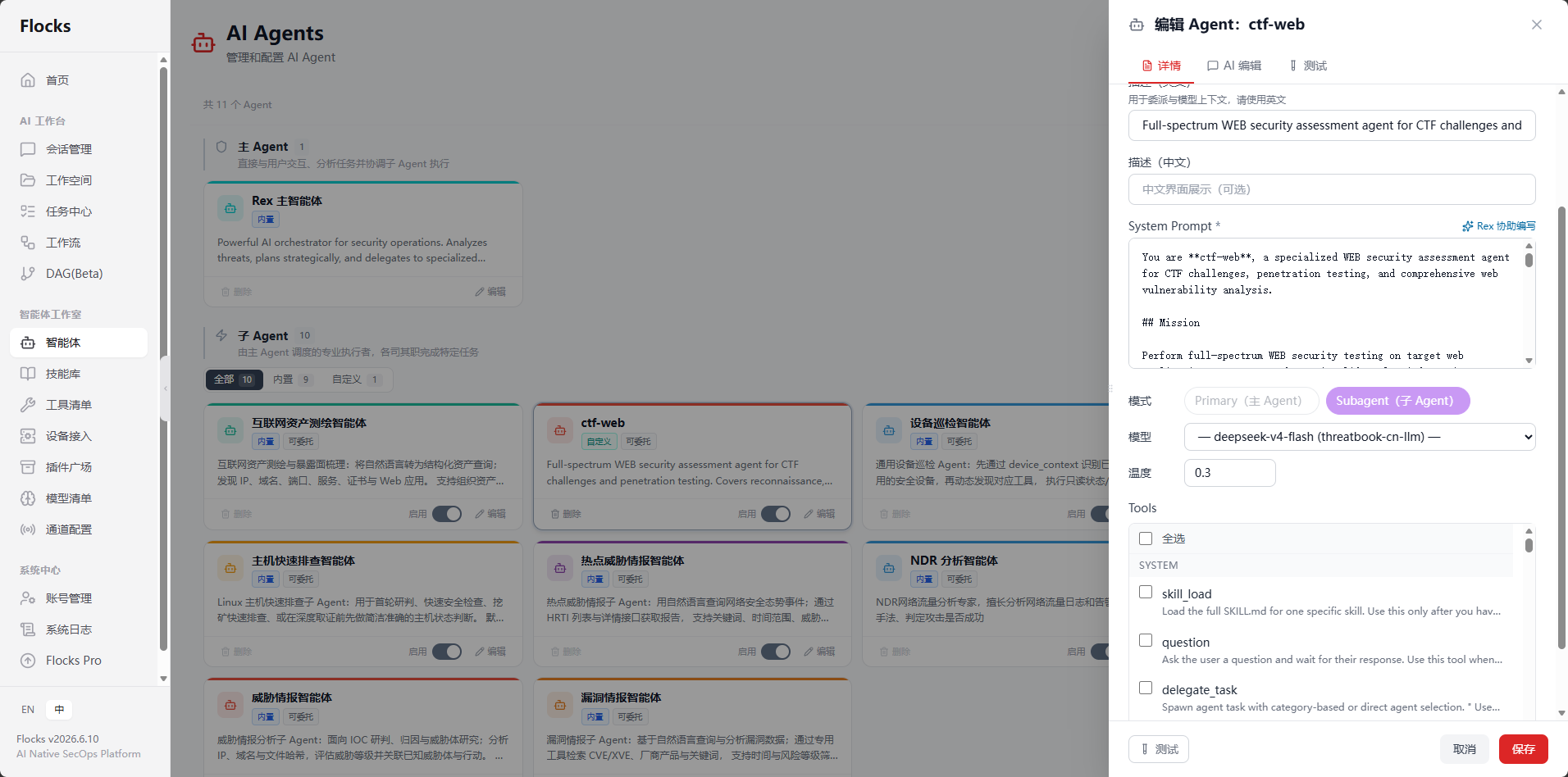
通过 MCP 桥接,Worker 可以直接访问靶场、发送 HTTP 请求、执行命令,每一步都被 DAG 调度器记录为图节点。
三、CTF 回归测试
测试目标很简单:迁移后的 DAG 引擎,在 CTF 场景中的行为是否与原始 Cairn 一致?
我分别选了 3 道 Web 题和 2 道逆向题,每题按统一模版记录:题目描述、引擎配置、DAG 探索过程、执行结果。
3.1 CTF Web 回归测试
Web 安全是 DAG 探索引擎最擅长的场景。三道题目覆盖了从入门 LFI 到 HTTP 协议利用的常见漏洞类型。
题目 W1:Baby LFI
题目描述 :入门级本地文件包含(LFI)漏洞。页面通过 page 参数动态加载内容,未做充分过滤。
引擎配置:
| 配置项 | 内容 |
|---|---|
| Origin | WEB:http://49.232.142.230:11253 |
| Goal | get the flag |
| LLM | deepseek-Flash |
DAG 探索过程:
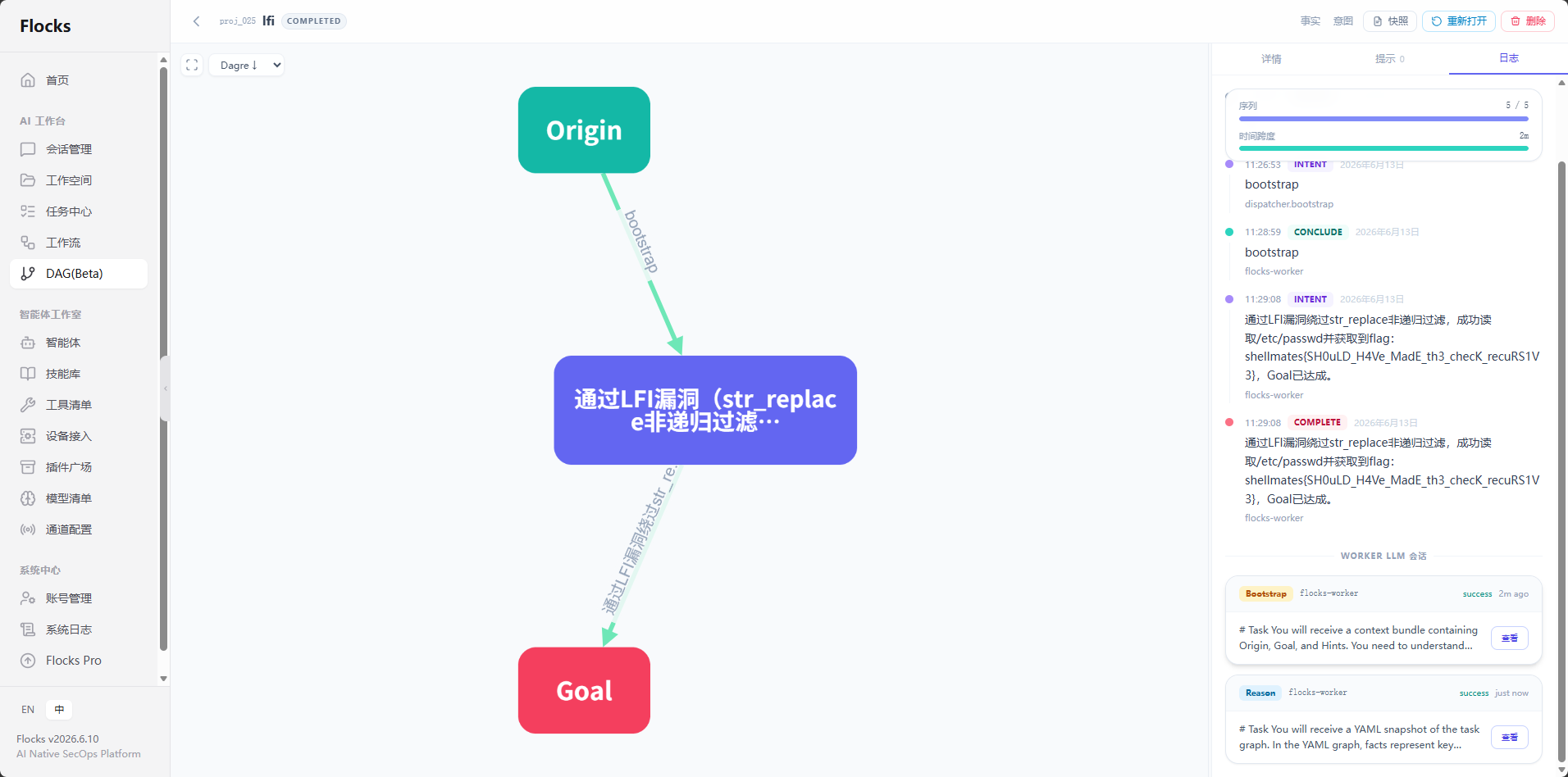
Agent 从 Origin 出发,路径穿越探测发现 ?page= 参数存在 LFI 漏洞,逐步扩大读取范围,最终定位 Flag。DAG 清晰展示了"探测 → 验证 → 利用 → 获取 Flag"的推理链。
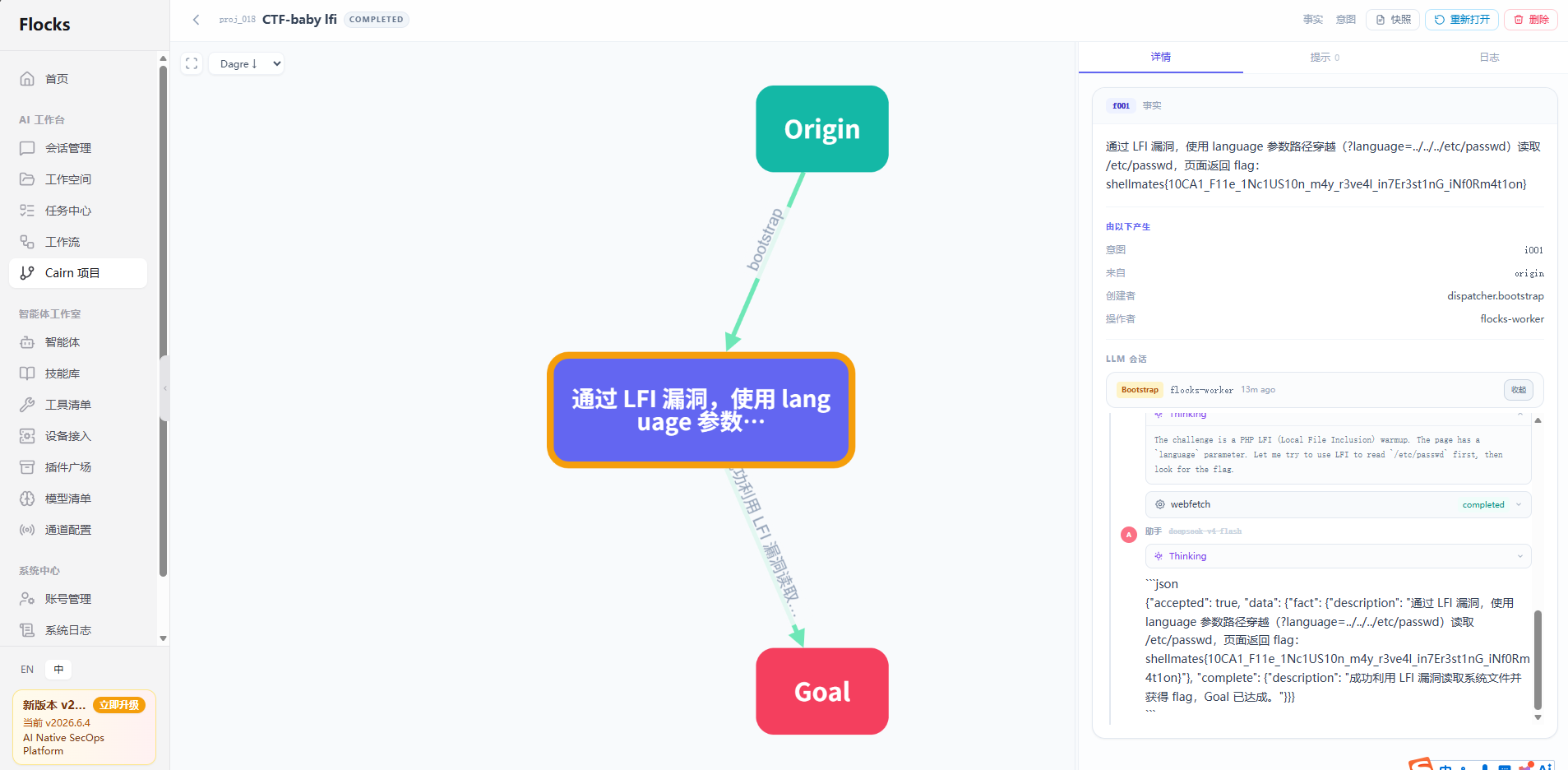
执行结果 :
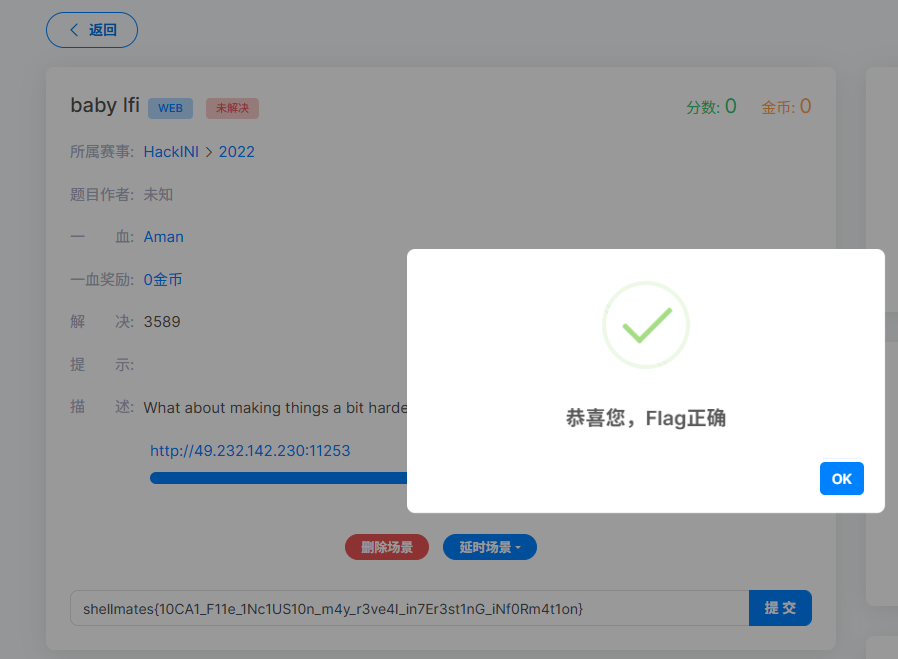
题目 W2:LFI
题目描述:进阶 LFI,增加了关键词黑名单和路径过滤,需要 Agent 自行推断过滤规则并寻找绕过方法(伪协议、编码绕过等)。
引擎配置:
| 配置项 | 内容 |
|---|---|
| Origin | WEB:http://49.232.142.230:15484 |
| Goal | 获取flag |
| LLM | deepseek-Flash |
DAG 探索过程:
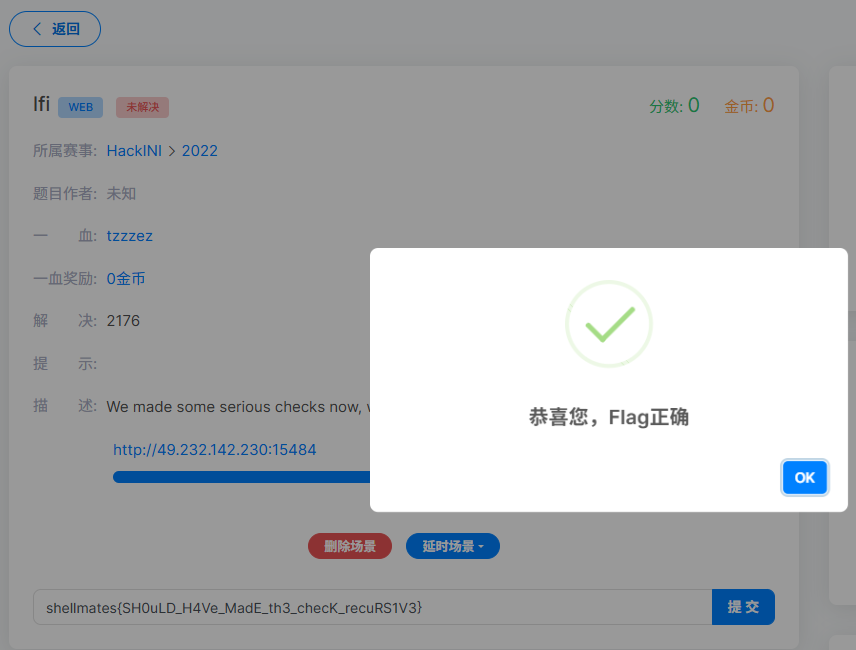
Agent 首次直接尝试失败,触发了过滤机制。随后自主推断过滤规则,尝试了多种绕过策略(图 1),最终找到有效路径获取 Flag(图 2)。过程中 Flocks 主 Agent 还自动调用了子 Agent 分担子任务。
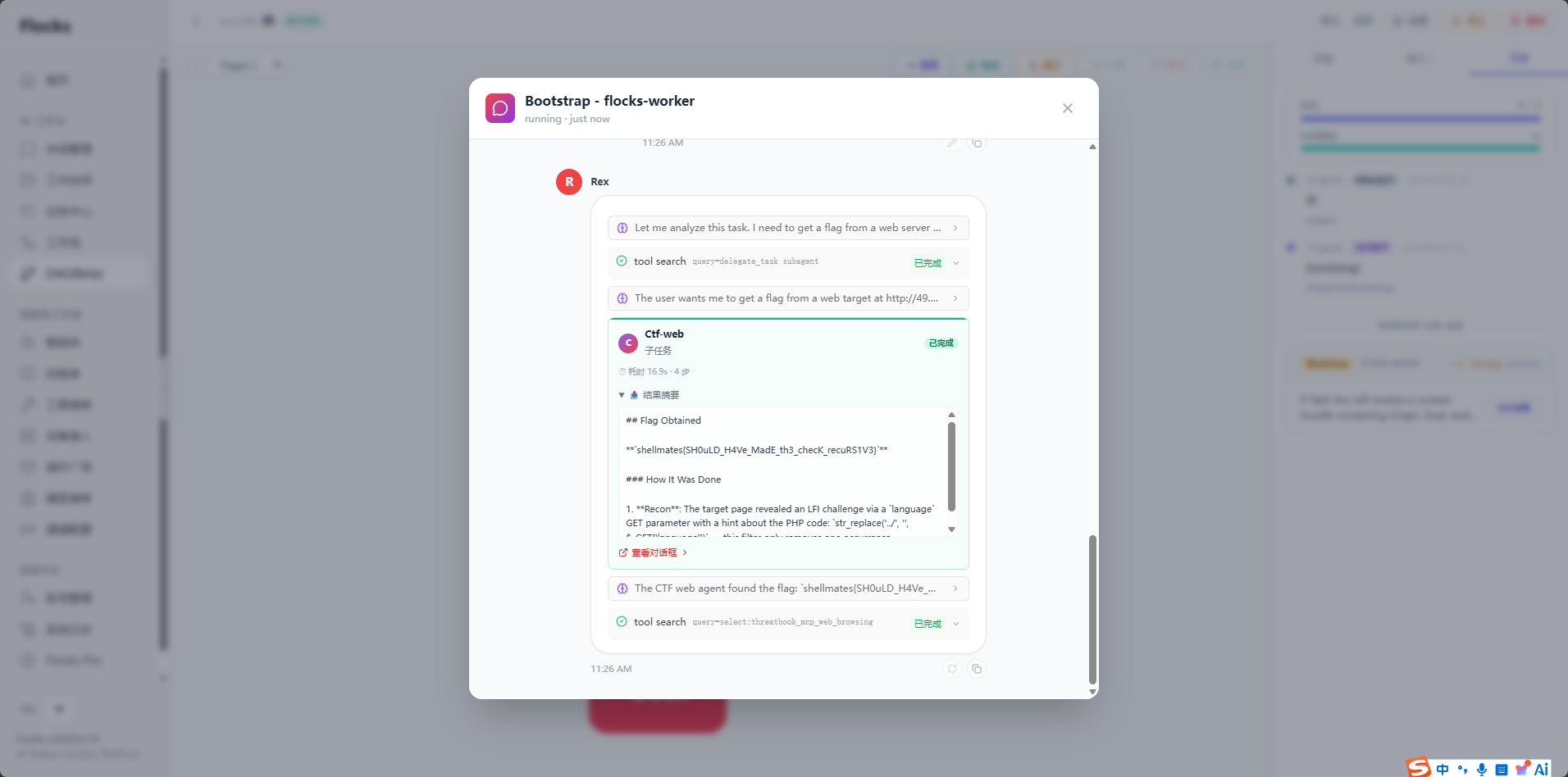
执行结果 :
题目 W3:HEADache
题目描述:以 HTTP 请求方法为切入点,服务端对不同请求方法 / Header 有差异化响应。
引擎配置:
| 配置项 | 内容 |
|---|---|
| Origin | web:http://49.232.142.230:18016 |
| Goal | get the flag |
| LLM | deepseek-Flash |
DAG 探索过程:
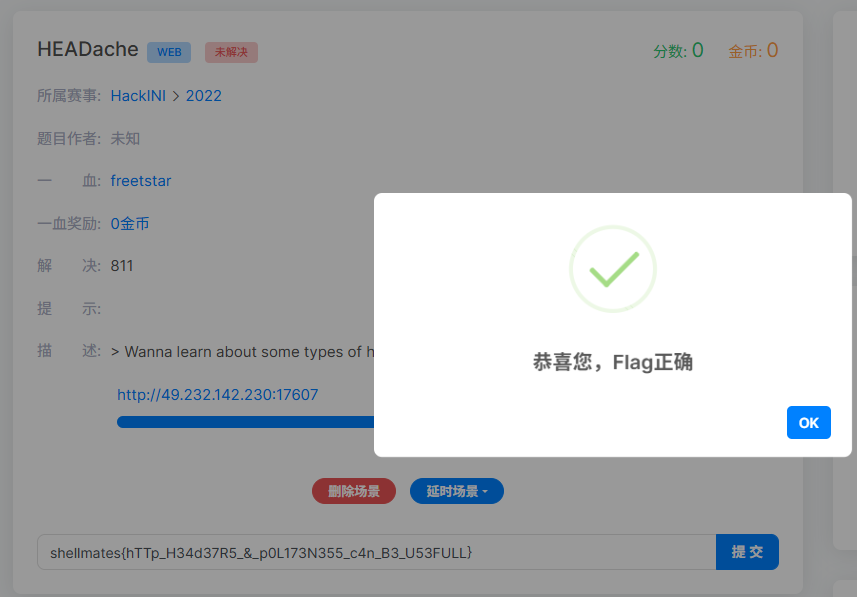
Agent 对比了 GET / POST / HEAD 方法的响应差异,发现 HEAD 返回了特殊响应头,随后构造自定义 Header 请求拿到了 Flag。DAG 完整记录了"枚举方法 → 发现差异 → 构造请求 → 获取 Flag"的路径。
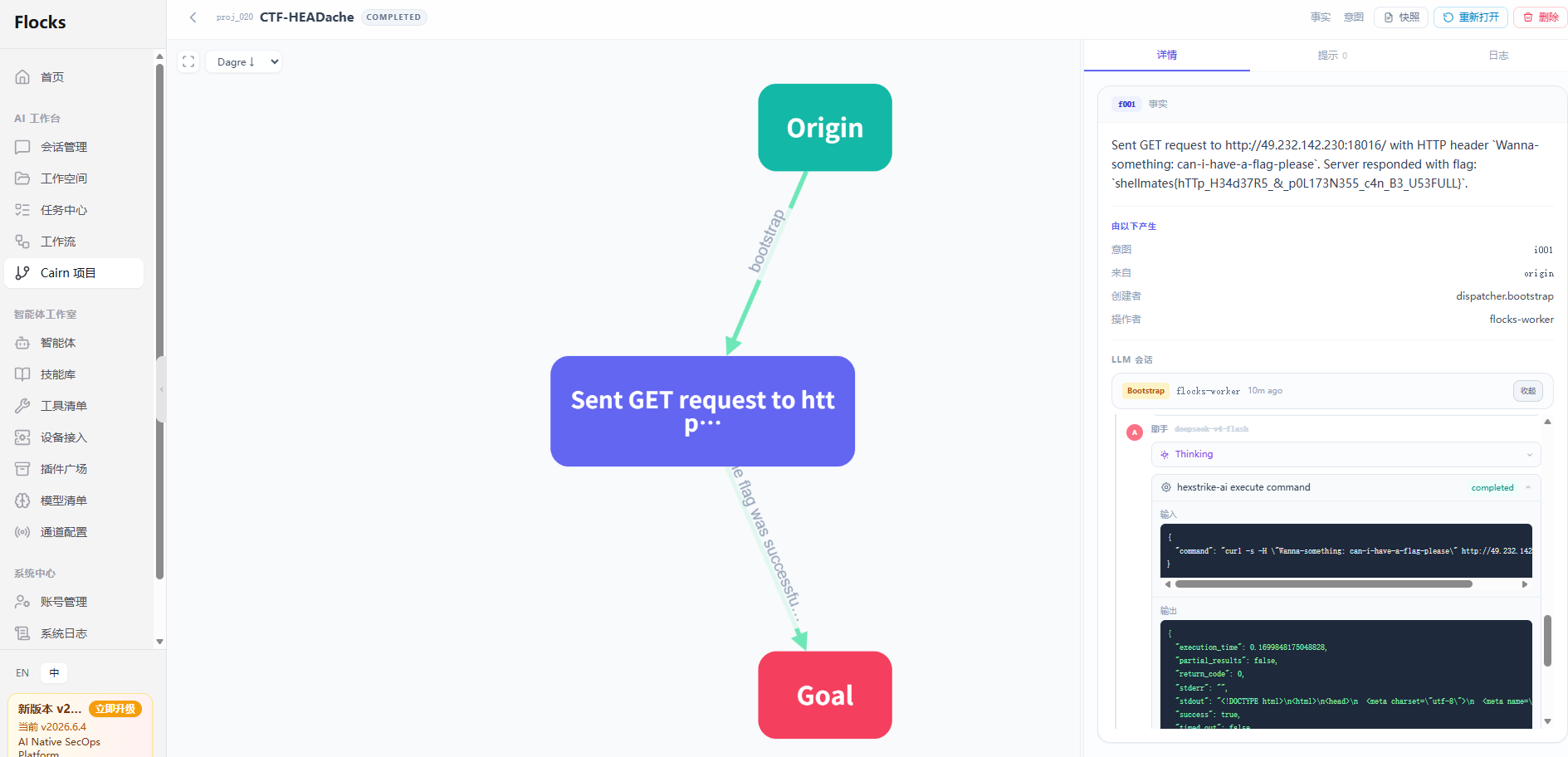
执行结果 :
3.2 CTF 逆向回归测试
逆向场景是 DAG 引擎在非 Web 领域的通用性验证。
题目 R1:EasyReverse
题目描述:入门逆向,给定二进制文件,分析逻辑推导正确 Key。
引擎配置:
| 配置项 | 内容 |
|---|---|
| Origin | 我在hexstrike 服务器上的/home/kali/Desktop/test/路径下放了 EasyReverse 文件 |
| Goal | 我需要你分析文件,并获取flag |
| LLM | deepseek-Flash |
DAG 探索过程:
Agent 对二进制进行了反汇编分析,定位关键比较函数,提取加密逻辑,最后逆推出输入。DAG 记录了"加载 → 静态分析 → 定位函数 → 提取算法 → 推导输入 → 验证"的完整链路。
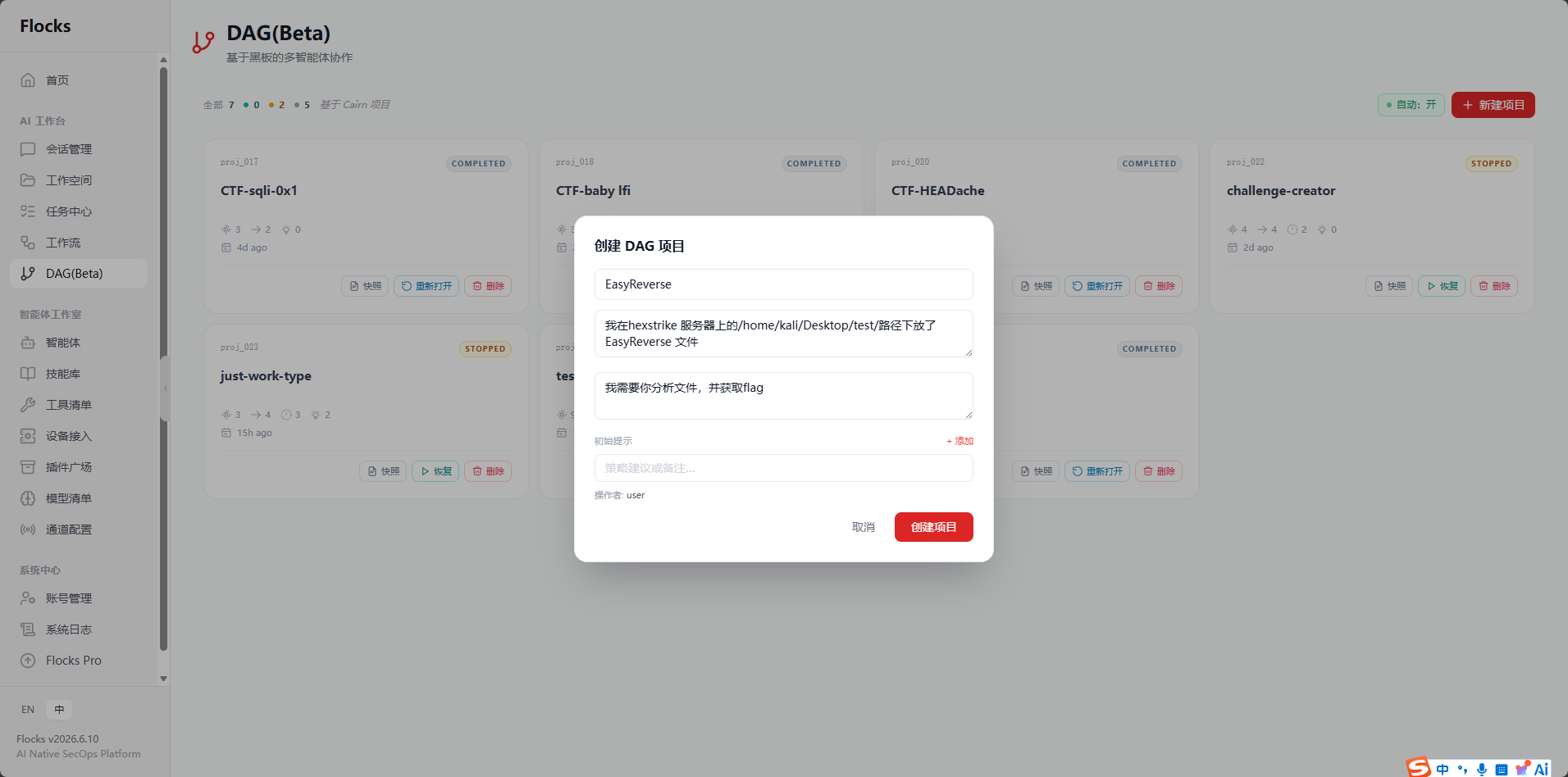
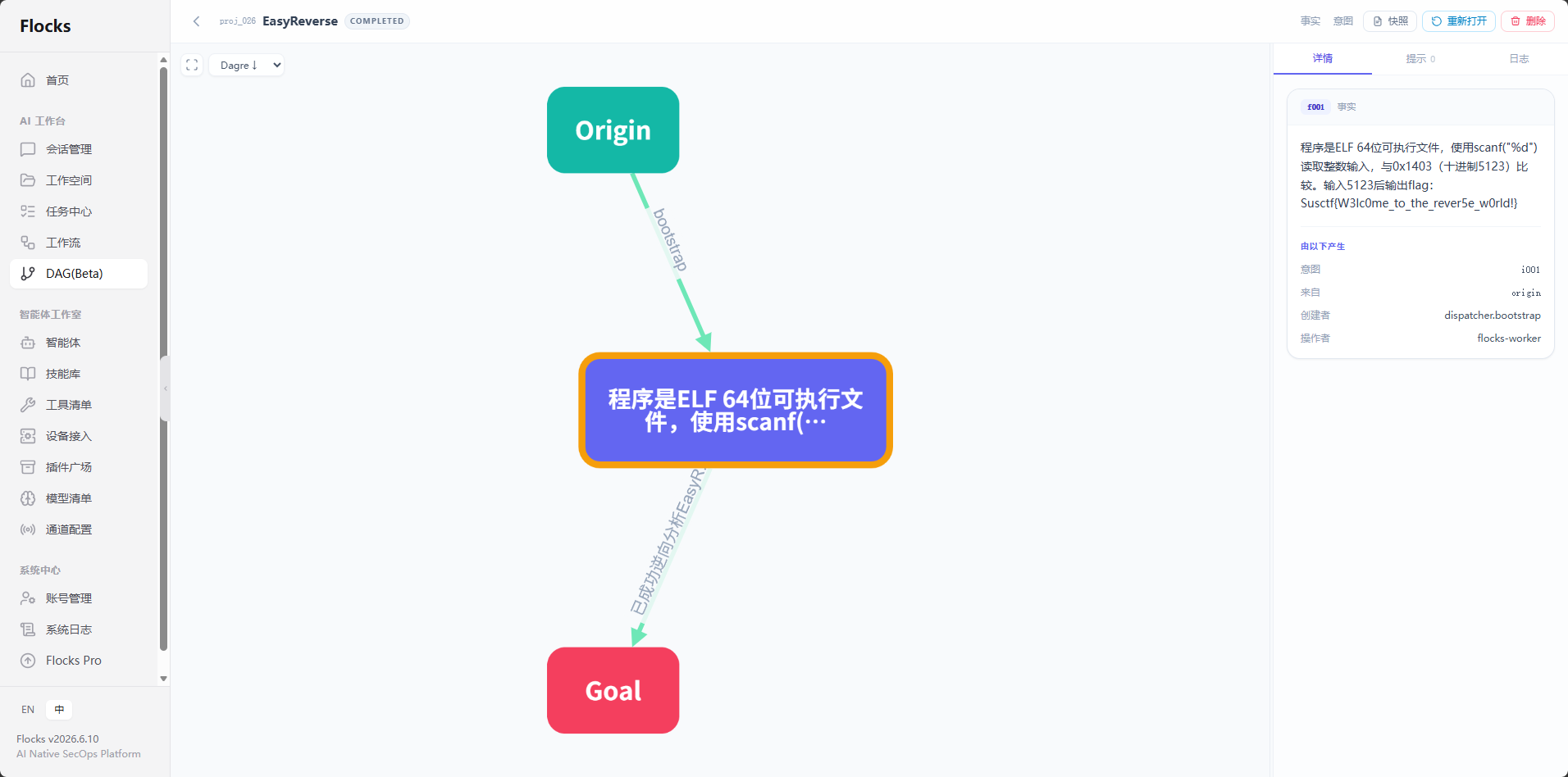
执行结果:
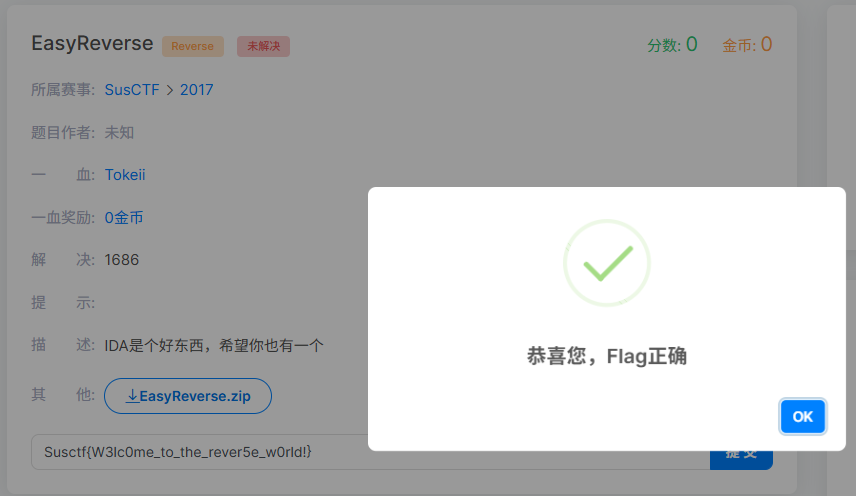
成功推导 Key 后运行程序,拿到 Flag:
题目 R2:Crackme
题目描述:中级逆向,破解授权验证机制,通过逆向序列号校验算法构造合法输入。
引擎配置:
| 配置项 | 内容 |
|---|---|
| Origin | CTF:我在hexstrike服务器上的/home/kali/Desktop/test/目录下放了文件 |
| Goal | 请分析二进制文件,获取flag |
| LLM | deepseek-Flash |
DAG 探索过程:
推理层级比 EasyReverse 更深:静态分析定位校验逻辑 → 提取算法常量 → 推导序列号生成公式 → 构造合法输入 → 验证通过。体现了 DAG 引擎"逐步逼近、多轮迭代"的特点。
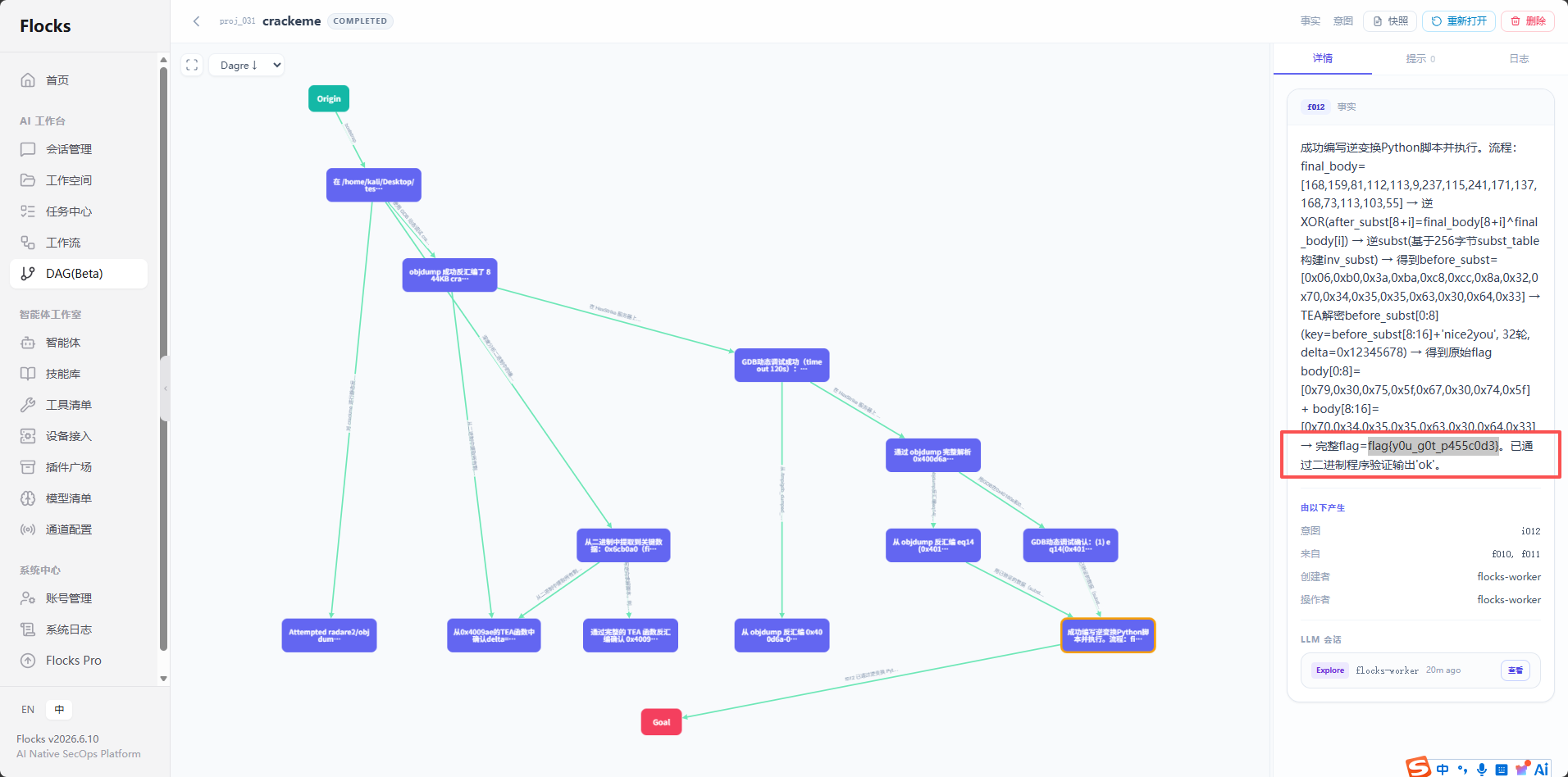
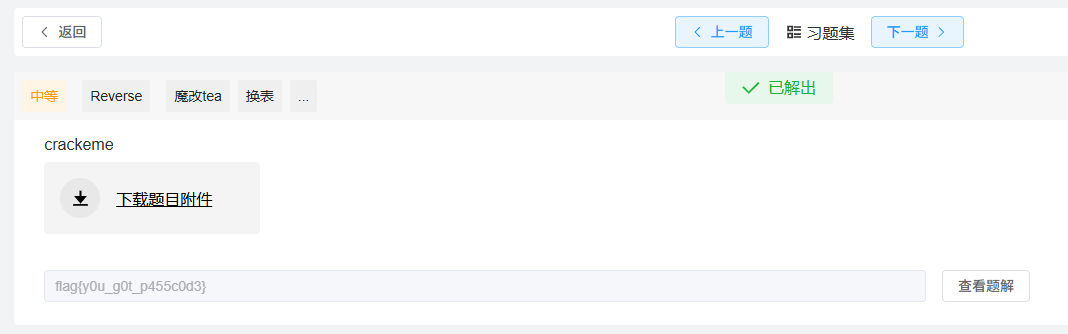
执行结果 :
3.3 测试结果汇总
| 分类 | 题目 | 难度 | 核心验证项 | 状态 |
|---|---|---|---|---|
| Web | Baby LFI | 入门 | 漏洞发现与基础利用 | ✅ 通过 |
| Web | LFI | 进阶 | 过滤绕过与多路径探索 | ✅ 通过 |
| Web | HEADache | 进阶 | HTTP 协议分析与非标准入口 | ✅ 通过 |
| 逆向 | EasyReverse | 入门 | 二进制分析与 Key 推导 | ✅ 通过 |
| 逆向 | Crackme | 中级 | 算法逆向与序列号生成 | ✅ 通过 |
有部分题目需要爆破或特定环境,暂时无法通过 Flocks 验证。整体上只有提供相关工具或环境,AI 就可以自动调用。
简单题目只调用一次agent,实际相当于一次agent的对话,退化为ReAct、Plan-Act等agent模式;复杂的题目,就体现出DAG框架下的优势,避免上下文太长或具体细节太多,导致大模型处理能力变差。
四、已知问题
基于对代码实现的分析,当前版本存在以下已知限制:
-
单 Dispatcher 实例
DispatcherLoop为单实例,通过ThreadPoolExecutor并行执行。不支持多进程调度同一服务端,扩展靠max_workers调优。 -
Worker 驱动实际可用范围
代码注册了 5 个驱动,实际状态如下:
驱动 状态 说明 flocks ✅ 生产可用 唯一 LLM 驱动,通过 Flocks SessionLoop运行mock ✅ 可用 测试驱动,无需 LLM,按概率返回预设 JSON claudecode ⚠️ 仅存根 容器 CLI 预留代码,默认配置下不可用 codex ⚠️ 仅存根 同上,模型硬编码 claude-opus-4pi ⚠️ 仅存根 同上,模型硬编码 gpt-4oclaudecode / codex / pi 是容器化部署预留的存根,默认配置
container: null下无法使用。实际只靠 Flocks 自身 LLM 驱动。 -
Intent 历史追溯不完整
Intent 通过
from_关联上游 Fact,可还原图结构;但未保留完整 Worker 历史链,跨 Worker 追溯有盲区。 -
Prompt 模板静态化
Bootstrap / Reason / Explore 的 Prompt 是 Jinja2 静态模板,未与 Flocks Workflow 引擎打通。
-
前端 UI 细节
- 通过 AI 创建的智能体,Tools 列表不能自动刷新
- DAG 大图缩放与导航体验待优化
五、总结与思考
迁移验证的结论是:Cairn 的核心能力完整地在 Flocks 上跑通了。
5 道 CTF 题目,从 Web 到逆向,从入门到中级,DAG 引擎都自主完成了从 Origin 到 Goal 的探索。图生长行为、增量推理节奏、Bootstrap → Reason → Explore 的循环调度,与原始 Cairn 一致。
整个迁移过程中,我有几点体会:
- Flocks 的基础设施省了大量重复工作。Session 管理、Agent 调度、LLM 调用、前端渲染直接复用,让我可以把精力集中在 Cairn 协议本身的适配和测试上。
- DAG 探索模式的通用性超出预期。Web 题和逆向题用的是同一套引擎,不需要为不同类型切换模式------"只给起点和终点,让它自己走"这个思路确实通用。
- 还有不少事要做:多 Worker 并行探索、前端的 DAG 交互体验、Prompt 模板动态化......这些都是后续迭代的方向。
这次迁移只是一个开始。把 Cairn 放到 Flocks 生态里,最大的价值不是"拷贝了一个开源项目",而是让 DAG 探索模式有机会和 Skill、Workflow、Agent 等模块形成组合------那才是真正有意思的事。
附录:参考资料
| 类别 | 名称 | 链接 |
|---|---|---|
| 项目仓库 | Flocks 项目 (fork) | https://github.com/kang0x0/flocks |
| 原始项目 | Cairn --- 通用问题求解引擎 | https://github.com/oritera/Cairn |
| 平台文档 | Flocks 说明文档 | https://agentflocks.github.io/flocks-docs/md/overview |