今天我们要深度拆解的工具 CodexPotter,正是一个为了解决"烂尾"而生的自主循环执行器。它不和你聊天,它只负责干活------直到把你的代码库"对齐"到你指定的目标状态。
解决什么问题:从"对话"到"自主执行"
在使用常规 AI 编程工具处理中大型任务时,通常有三个绕不开的痛点:
1.任务执行不彻底:单轮生成往往只能覆盖核心逻辑,剩下的琐碎边界、错误处理和单元测试常常被忽略,留下一个需要人工大量收尾的"半成品"。
2.上下文质量退化:随着对话轮次增加,历史讨论中的干扰信息会稀释模型对核心工程规范的理解。模型"越聊越蠢"往往不是能力问题,而是上下文太脏。
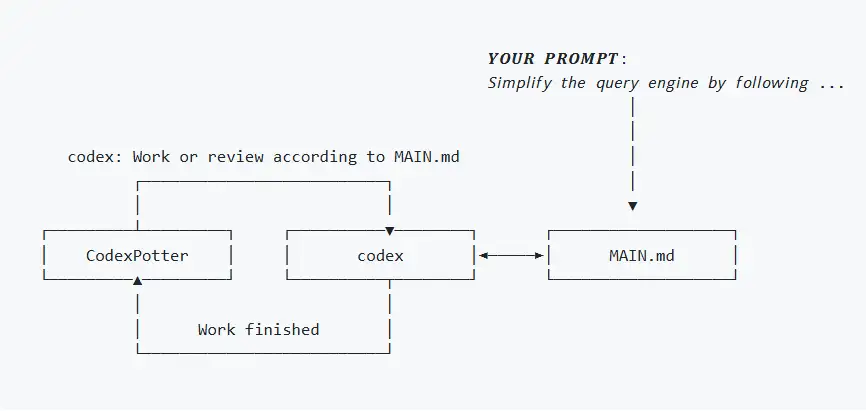
3.注意力频繁切换 :开发者需要不断 Review、追问、纠错,无法真正从繁琐的编码执行中抽身去思考架构。 CodexPotter 的核心理念是引入了 Ralph Loop(Ralph Wiggum 模式)。它将任务目标写入进度文件,通过"自主拆解-执行-自动 Review-继续对齐"的闭环,确保任务在没有人工干预的情况下也能走向 100% 完成。
环境准备与安装
CodexPotter 支持 Linux、macOS 以及 Windows 全平台。在开始之前,请确保你的开发环境已经具备以下条件:
-
前置依赖 CodexPotter 依赖于底层模型驱动(如 OpenAI Codex CLI)。你需要确保本地已配置好相应的 CLI 环境并拥有活跃的服务权限。
-
安装步骤 你可以通过 npm 或 bun 全局安装:
bash # 使用 npm 安装 npm install -g codex-potter # 或者使用 bun 安装 bun install -g codex-potter如果安装过程中提示Missing optional dependency,通常是因为 npm 没能正确匹配你当前平台的原生二进制包。解决办法是先卸载再重新安装,确保网络环境能正常拉取二进制组件。
配置模型服务环境
为了让 CodexPotter 能够调用强大的模型能力,我们需要配置 API Key 和 Base URL。 对于希望在本地开发环境进行稳定性测试的开发者,建议使用支持 OpenAI Compatible API 的模型服务。这里我们以 iThinkAPI 作为配置环境的演示示例。
配置实操
在项目根目录或环境变量中,你需要关注以下三个核心配置项:
•Base URL:https://token.ithinkai.cn/v1
•API Key:YOUR_API_KEY(请替换为实际获取的 Key)
•Model:建议使用当前服务文档推荐的高性能编码模型。
iThinkAPI 配置环境示例
注意:为了方便复现,本文使用支持 OpenAI Compatible API 的 iThinkAPI 作为演示环境。实际配置时,你只需要关注 API Key、Base URL 和模型名称。这里只作为配置示例,实际可用模型、接口格式和配置方式请以服务商提供的最新文档为准。
核心机制:Ralph Loop 是如何工作的?
CodexPotter 的工作流程并不是线性的,而是一个状态机。
1. 进度持久化(MAIN.md)
当你输入一个 Prompt 后,CodexPotter 会在 .codexpotter/ 目录下创建一个 MAIN.md 文件。这个文件是整个任务的"大脑",记录了任务的初始状态、已识别的子任务(Todo)、正在进行的任务(In Progress)以及已完成的任务(Done)。 这种做法的好处是:细节永不丢失 。即使网络中断或 CLI 崩溃,你只需要重新启动并执行 Resume,它能立刻从 MAIN.md 的状态继续往下走。
2. 干净上下文(Clean Context)
这是 CodexPotter 区别于普通 Chat 工具的最大特点。在每一轮循环(即处理每一个 Todo)时,它都会开启一个新的会话。
•它不读取之前的聊天历史 ,只读取 MAIN.md、当前的知识库以及相关的代码片段。•这从物理层面隔绝了"上下文污染",确保模型在处理第 10 个子任务时,依然能保持和第 1 个子任务一样的高水准。
3. 本地知识库(Knowledge Base)
CodexPotter 会在 .codexpotter/kb/ 中维护一个本地知识库。当它深入探索某个模块后,会把关键的代码位置、逻辑关系写入 Markdown 文件。后续的任务可以直接引用这些"经验",避免重复扫描代码库。
实战场景示例
场景一:单任务自主对齐
如果你需要将另一个项目的某个功能迁移到当前项目,并保持代码风格一致,可以直接输入: > port upstream codex's /resume into this project, keep code aligned CodexPotter 会自动扫描上游代码、分析当前项目结构、拆解迁移步骤、执行代码编写,并进行多轮 Review 确认迁移是否完整。
场景二:先规划、后实现的两阶段工作流 对于复杂系统,直接编码容易乱。
我们可以通过文件作为媒介,将任务拆分为"设计"和"执行"。
第一步(规划): > Analyze the codebase, research and design a solution for introducing subscription system. Output plan to docs/subscription_design.md. Do not implement the plan, just design a good and simple solution.
第二步(实现): > Implement according to docs/subscription_design.md. Make sure all user journeys are properly covered by e2e tests and pass. 这种工作流将"思考"和"动手"完全解耦,模型在第二阶段会严格对照第一阶段生成的 subscription_design.md 进行对齐。
场景三:双模型交叉 Review(高级技巧) 利用 --xmodel 参数,你可以启动"专家会诊"模式。例如,让一个模型负责执行(Coding),另一个模型负责审核(Reviewing)。 bash codex-potter --yolo --xmodel 这种模式在处理逻辑严密的底层重构时效果极佳,因为审核模型往往能发现执行模型在盲点区域留下的 Bug。
避坑指南与排错方式
在实际使用过程中,有几个关键点需要注意,避免踩坑。
1. 关于 --yolo 模式
默认情况下,CodexPotter 可能会在某些敏感操作上请求你的许可。如果你对任务目标非常明确,且项目已通过 Git 进行版本控制,建议开启 --yolo 模式实现完全自动化。 风险提示 :YOLO 模式下 AI 会自主执行删除、修改、运行脚本等操作,务必在干净的 Git 分支上操作。
2. 模型调用成本核算
CodexPotter 的设计初衷是"用 Token 换质量"。因为它会进行多轮 Review 和循环对齐,其 Token 消耗量会远高于简单的 Chat。
•建议 :对于简单的语法咨询,直接用网页端或常规 IDE 插件。•适用场景:只在需要处理复杂逻辑、大规模迁移、全量测试覆盖等"重活"时,才祭出 CodexPotter。
3. 常见报错排查
•CLI 直接退出 :这是目前社区反馈较多的一个 Bug(Issue #1),通常是因为某个工具调用返回了非预期错误。
•对策 :使用 /list 查看历史任务,然后选择对应的项目编号进行 Resume。CodexPotter 会从断点继续,无需重头开始。
•输出质量下降 :如果发现模型开始胡言乱语,请检查 .codexpotter/kb/。如果知识库里包含了过时的设计方案,模型会被误导。•对策:手动清理或更新知识库文件。
进阶配置:让它更懂你的工程规范
如果你希望 CodexPotter 遵循特定的代码风格(如:必须使用 Functional Programming,或者变量命名必须符合某项规范),你可以在项目根目录放置一个 AGENTS.md 文件。 CodexPotter 与 Codex 的 AGENTS.md、Skills 以及 MCP(Model Context Protocol)无缝兼容。它在启动每一轮任务前,都会优先读取这些规范,从而保证生成的代码像是由你亲手写出的一样。
总结:从"AI 助手"进化为"AI 雇员"
CodexPotter 的出现标志着 AI 编程工具从"交互式"向"任务导向型"的转变。它不再是一个需要你不断投喂指令的对话框,而是一个只要给出目标、就能自主交付结果的"虚拟雇员"。
核心建议回顾:
•不要把它当 Chat 用:每个 Prompt 都是独立任务,尽量一次性描述清楚目标。
•善用文件传递状态:大任务拆分为规划和实现两个阶段。
•做好 Git 管理:利用它自动提交 commit 的特性,在独立分支进行 Review。 如果你也厌倦了每天对着 AI 纠错、重写、补全那剩下 20% 的代码,不妨试试将 iThinkAPI 的兼容接口接入 CodexPotter,开启你的自主编程对齐之旅。
延伸阅读:如需获取文中提到的配置模板或核心 Prompt 示例,可以在留言或关注相关技术专栏。