文章目录:
- 一、前言
- 二、讨论
- 三、HTTP协议
- 三、Requests库的详细介绍
-
- 1、安装Requests库
- 2、requests发送请求的三种方式
-
- [2.1 方式1:`request+请求方法`](#2.1 方式1:
request+请求方法) - [2.2 方式2:`requests.request(构造请求)`](#2.2 方式2:
requests.request(构造请求)) - [2.3 方式3:`requests.session().request(构造请求)`](#2.3 方式3:
requests.session().request(构造请求))
- [2.1 方式1:`request+请求方法`](#2.1 方式1:
- 3、详细介绍requests发送请求的参数
-
- [3.1 查询字符串](#3.1 查询字符串)
- [3.2 表单参数](#3.2 表单参数)
- [3.3 json参数](#3.3 json参数)
- [3.4 文件参数](#3.4 文件参数)
- 4、requests响应对象的介绍
- 四、接口自动化-接口关联
-
- 1、是什么是接口关联
- 2、提取响应中的值的方式
-
- [2.1 正则提取](#2.1 正则提取)
- [2.2 JSONPATH提取](#2.2 JSONPATH提取)
- 3、案例演示
-
- [3.1 正则提取](#3.1 正则提取)
- [3.2 JSONPath提取](#3.2 JSONPath提取)
-
- 第一步:安装依赖库
- 第二步:导入模块
- 第三步:使用前提(必看)
-
- [准备测试数据(全程共用示例 JSON)](#准备测试数据(全程共用示例 JSON))
- [方式1:旧版 jsonpath(简单易懂,入门首选)](#方式1:旧版 jsonpath(简单易懂,入门首选))
-
- [1. 基础语法格式](#1. 基础语法格式)
- [方式2:主流 jsonpath-ng(企业/自动化测试常用)](#方式2:主流 jsonpath-ng(企业/自动化测试常用))
-
- [1. 分步语法(固定两步)](#1. 分步语法(固定两步))
- [2. 实战示例(同上面需求,提取 access_token)](#2. 实战示例(同上面需求,提取 access_token))
- [拓展:多层级 / 数组数据提取示例](#拓展:多层级 / 数组数据提取示例)
-
- 示例1:提取普通多层字段
- [示例2:提取数组内数据(JSON 数组常用)](#示例2:提取数组内数据(JSON 数组常用))
- [总结 正则 vs JSONPath](#总结 正则 vs JSONPath)
-
- 正则提取(re)
- [JSONPath 提取](#JSONPath 提取)
一、前言
我们前面已经介绍过了pytest,有了这个基础之后,本期开始我们就进入接口自动化轻量封装的学习,我们本期会介绍requests模块的封装,以及一些接口关联的知识。
二、讨论
我们目前常用的接口自动化方案有哪些呢?
基于工具的自动化:他一般适用于中小型的一个项目。
比如:postman+nweman+git/svn+jenkins(使用JavaScript实现的)
基于代码的自动化:适用于大中型的项目。
比如:python+requests+pytest+yaml+热加载+allure+logging+Jenkins
基于平台的自动化:适用于特大型项目
前端:vue
后端:Django(python)、springboot(Java)
三、HTTP协议
HTTP协议:咱们使用的是请求---->响应 模式
主动是请求,被动是响应,所以咱们的重点就是请求。
1、请求的四要素
请求方法 :GET、POST、PUT、DELETE等等
请求路径 :URL
请求头:
- content-type:内容格式
- multipart/form-data:文件上传
- application/x-www-form-urlencoded:普通表单
- application/json:JSON参数
- User-Agent:请求客户端
- Accept:预期内容
- X-Request-With:AJAX声明使用异步请求
- Cookie:存sessionid
请求体:
- 支持不同的格式、不同的内容
- 对于表单数据有一个特点,他的数据形式是键值对
- 对于JSON数据他有一个特点,数据形式是JSON字符串
2、响应的四要素
状态码:
- 2xx:成功
- 3xx:重定向
- 4xx:客户端错误
- 401:缺少身份凭据
- 403:权限不足
- 404:资源不存在
- 405:请求方法不允许
- 5xx:服务端错误
响应头:
- content-type:可以知道响应格式是什么,用于修饰响应体
- set-cookies:对cookies设置
响应体 :可以支持不同的格式、不同的内容
响应时间:一个接口一般响应时间是在200~400ms之间的
三、Requests库的详细介绍
1、安装Requests库
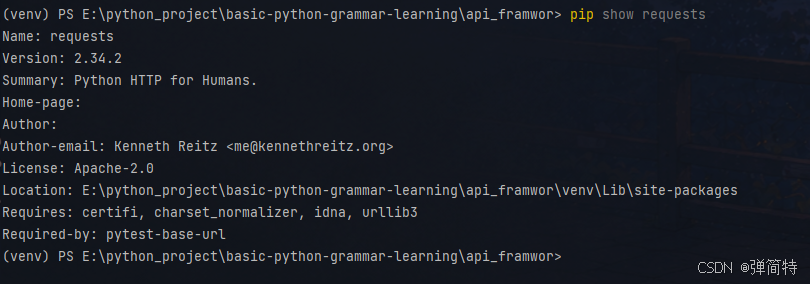
咱们的Requests是一个第三方库,我们只有安装之后才可以使用的。
bash
# 安装
pip install requests
# 看安装信息
pip show requests
我们Requests他在我们Python领域是我们HTTP请求非常之通用的工具,被广泛用于开发、测试、运维、数据分析、爬虫等等领域。
2、requests发送请求的三种方式
2.1 方式1:request+请求方法
使用request+请求方法的例子:
py
import requests
#他有四个方法
requests.get("https://www.baidu.com")
requests.post("https://www.baidu.com")
requests.put("https://www.baidu.com")
requests.delete("https://www.baidu.com")使用这种方式有一个缺点就是:不支持不常用的方法,他就只有上述四个方法
py
# 使用这种方法他不支持不常用的方法
# 比如:
requests.move("https://www.baidu.com")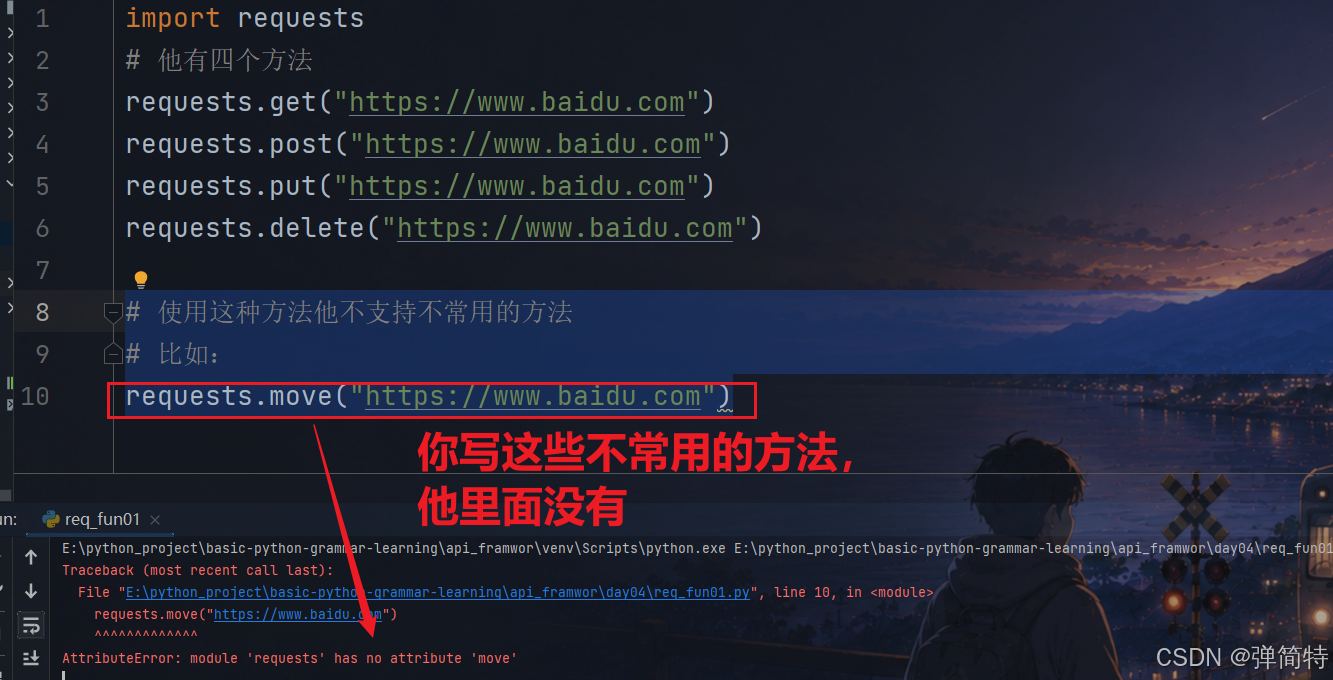
我们怎么解决呢?我们此时就会使用第二种方法
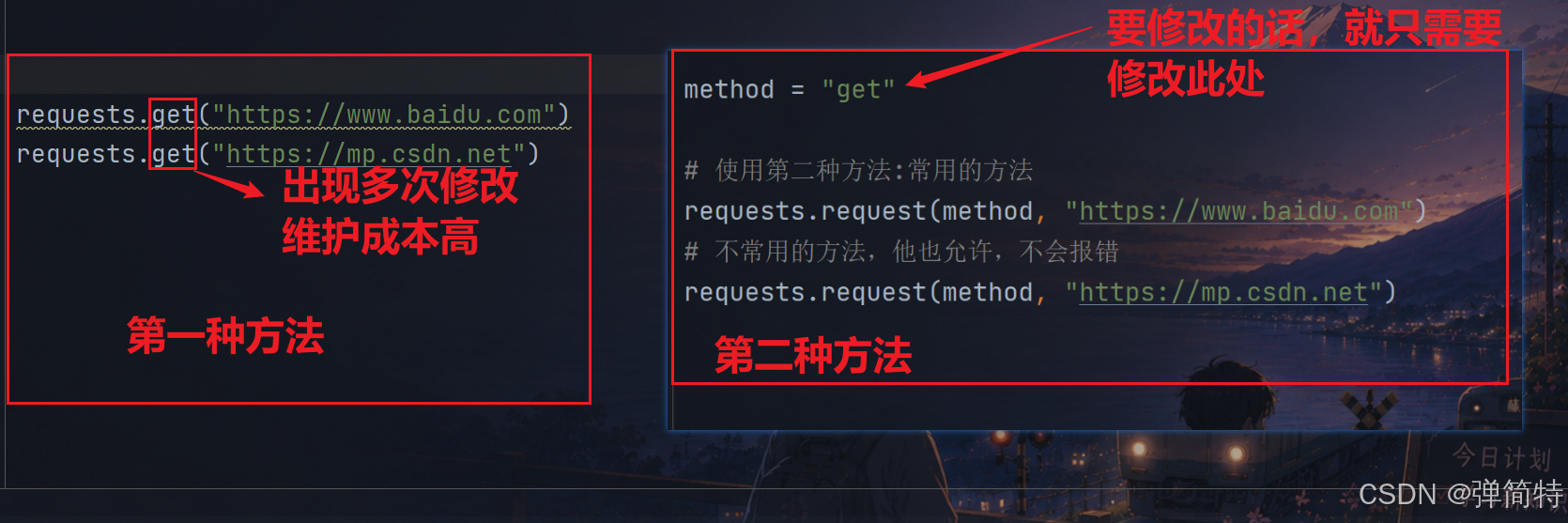
2.2 方式2:requests.request(构造请求)
注意:所谓的构造请求,就是封装请求的四要素。
使用第二种方法,我们可以直接自己构造请求,所以就避免了第一种的局限性:
py
import requests
# 使用第二种方法:常用的方法
requests.request("get", "https://www.baidu.com")
# 不常用的方法,他也允许,不会报错
requests.request("move", "https://www.baidu.com")第二种相较于第一种:维护成本低,代码比较灵活
虽然,第二种方式好,但是我们更希望掌握第三种,因为他会更加的灵活👇
2.3 方式3:requests.session().request(构造请求)
使用session的话,同一个session他们之间不隔离,不同的session之间隔离:
py
import requests
session_1 = requests.session()
session_2 = requests.session()
method = "get"
session_1.request(method, "https://www.baidu.com")
session_1.request(method, "https://www.baidu.com")
session_2.request(method, "https://www.baidu.com")
session_2.request(method, "https://www.baidu.com")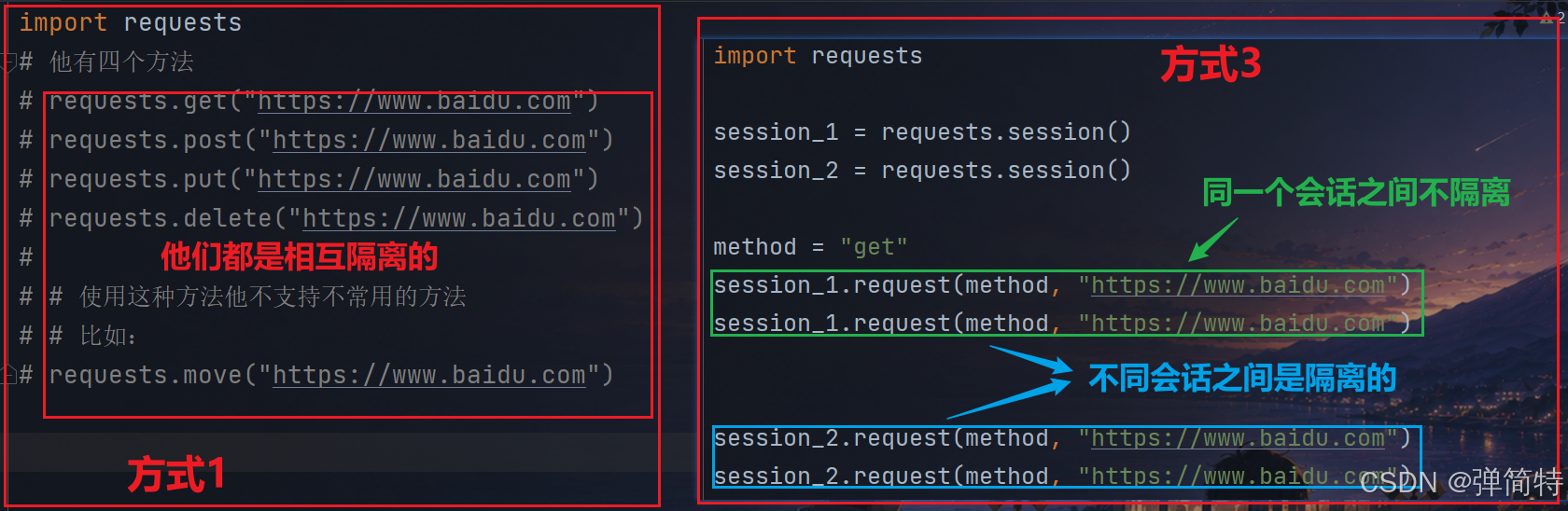
想要不隔离就得使用方法3,那么为什么这个方法可以进行隔离呢?此时我们就得配合源码来看:
首先,第一种方法:request+请求方法 他底层实际是调用我们的request方法,只不过他给我们传递了第一个参数,所以第一种方法底层在调用第二种方法
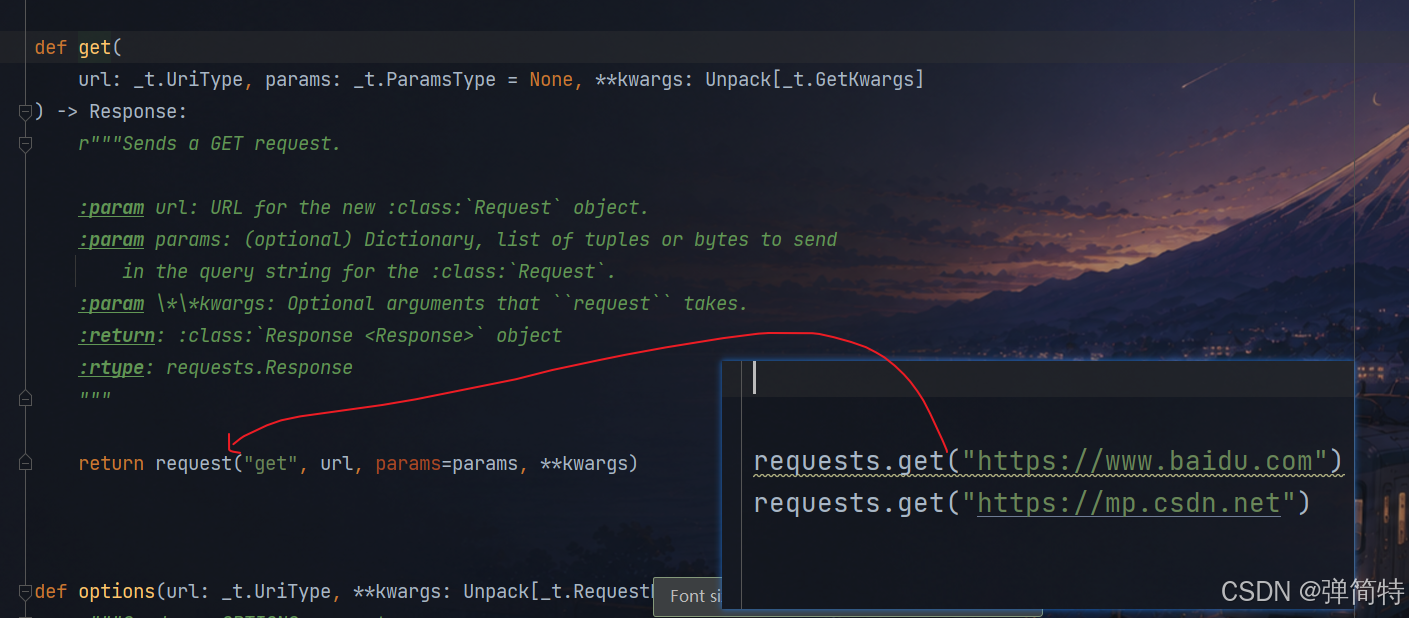
第二种方法:requests.request(构造请求)他底层在实例化我们的session对象,所以他实际上在调用我们的第三种方法
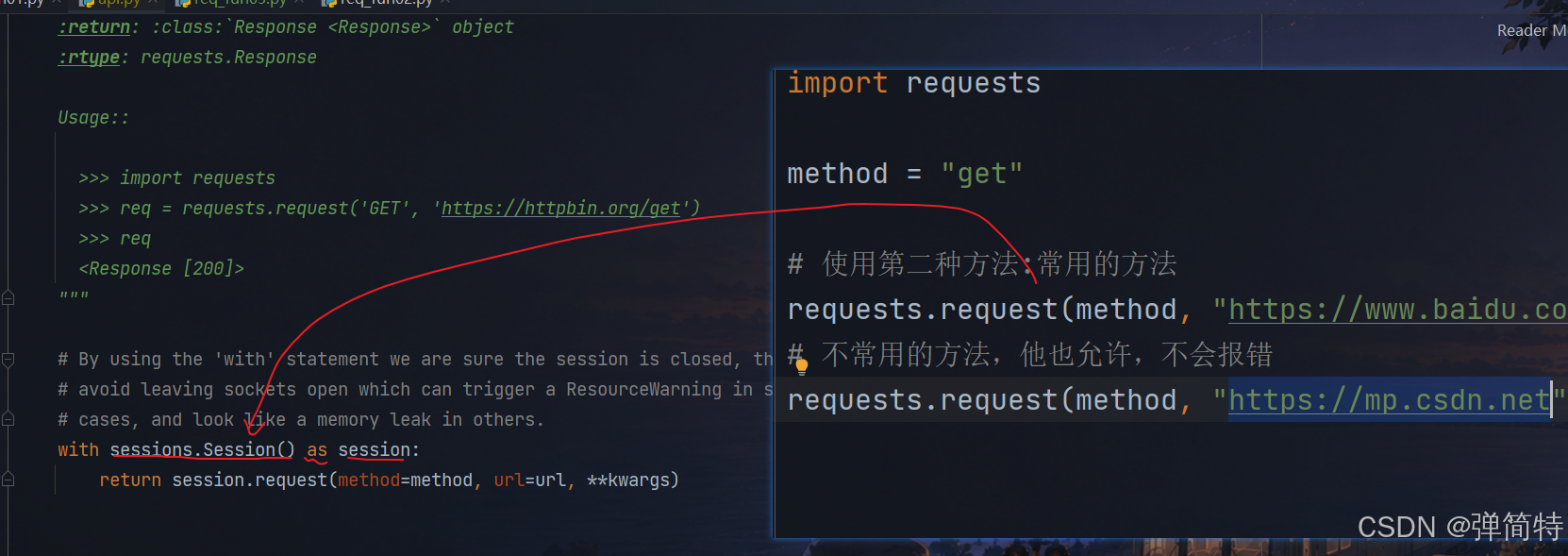
最后我们第三种方法才是真正的最底层最本质的内容:所以我们说掌握第三种,因为第三种是最底层,最本质的,掌握他其他的自然就掌握了
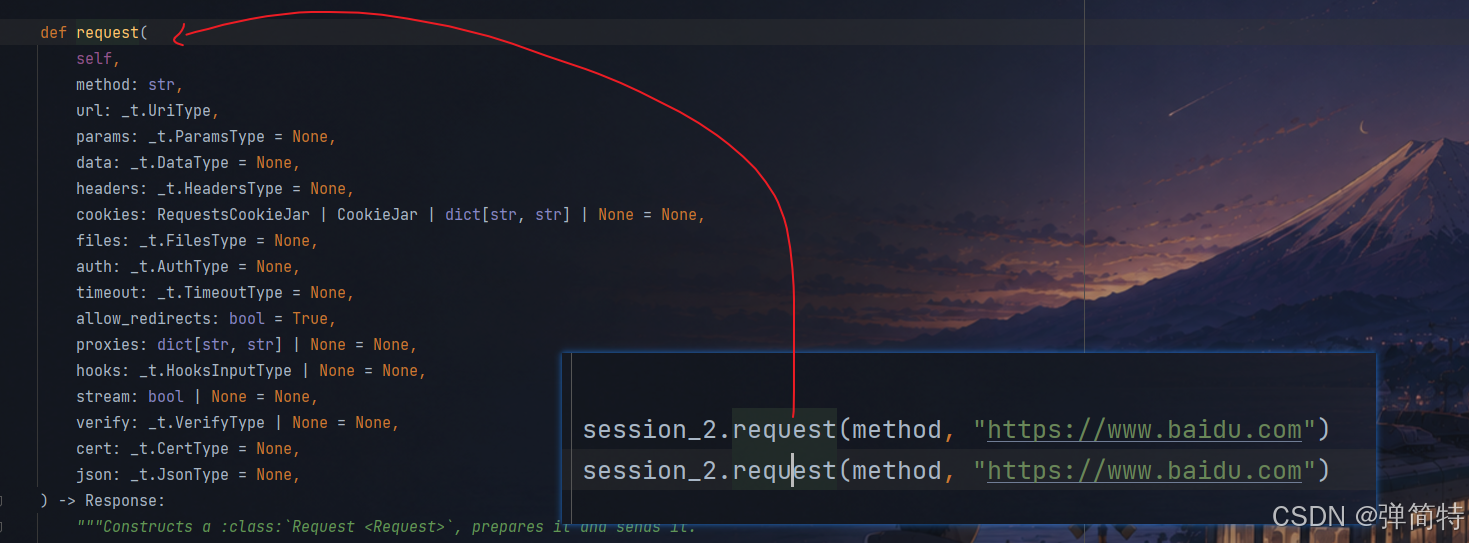
第三种底层源码:
py
def request(
self, # 对象自己
method, # 请求方法(必填参数)
url, # 接口地址(必填参数)
params=None, # 查询字符串,会成为URL的一部分
data=None, # 表单参数
headers=None, # 请求头
cookies=None, # cookies
files=None, # 文件上传
auth=None, # 鉴权类
timeout=None, # 超时时间
allow_redirects=True, # 允许重定向
proxies=None, # 设置代理
hooks=None, # 钩子,响应之后调用
stream=None, # 流式传输
verify=None, # 验证SSL证书
cert=None, # 自定义SSL证书
json=None, # JSON参数
):- auth=None, # 鉴权类 这里面有它预设的一些鉴权类,我们一般用不到
- timeout=None, # 超时时间 可以自己设置一个时间,超过制定时间就会报错,但是我们基本不用,因为我们接口的时间是波动的。
- allow_redirects=True, # 允许重定向 它默认是为真的,所以默认的情况下接口是重定向的,那他就会自己去处理。
- proxies=None, # 设置代理 用的不多,因为我们不一定都在代码里设置代理,也可以给系统设置代理。
- hooks=None, # 钩子,所谓的钩子就是满足一定一的条件之后,它会自动的调用,此处我们用的不多,因为他只有响应之后会调用,而有时候我们在响应之前是需要去做一些事情,所以到时候我们会自己去重新封装我们自己的来用。
- stream=None, # 流式传输,也就是说你上传或下载一个特别大的文件的时候,那就不适合把整个文件都放到内存里面,此时我们就一点一点的放到内存中,然后我再发到接口,然后再一点一点的放到内存出来,再一点一点的发到接口,就不断的放,知道成功。
我们的request方法中有这么多的参数,这些参数都是供我们去构造请求的。
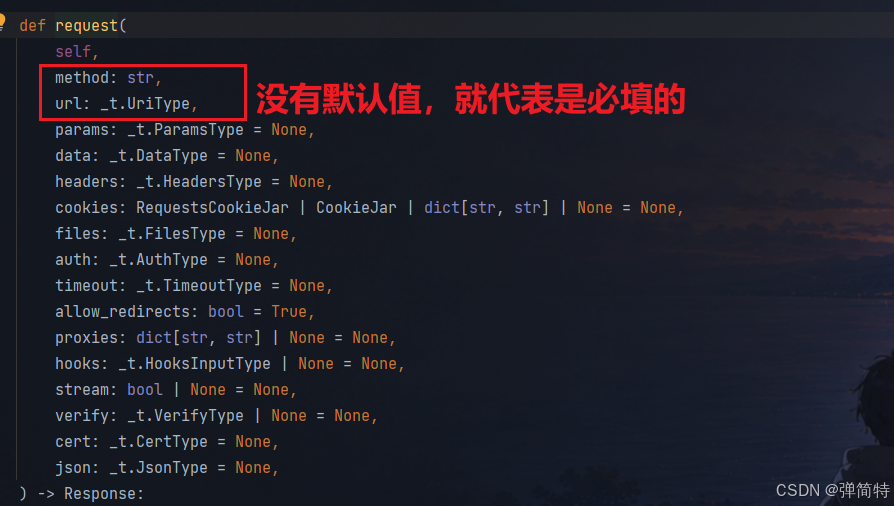
注意: 由于表单参数和JSON都是在请求体中,所以表单data参数和JSON的JSON参数不能共存,也就是不能同时存在
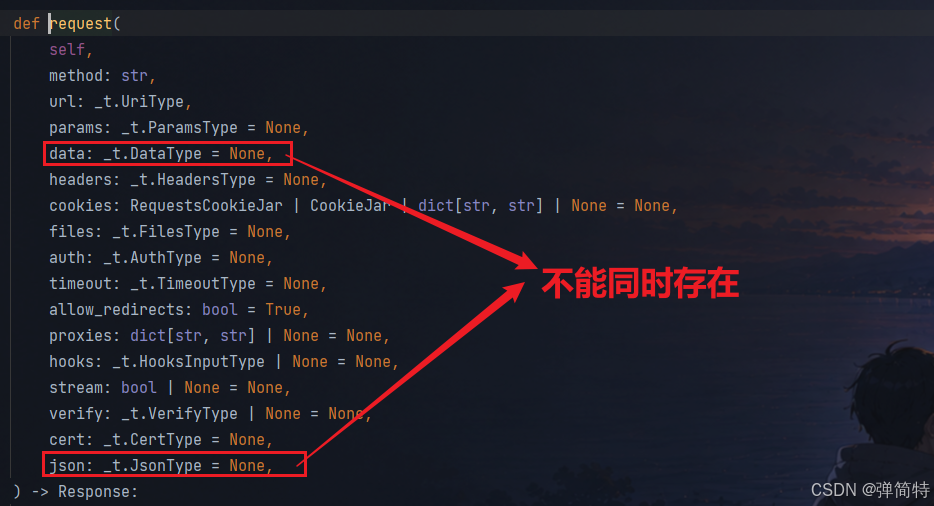
常用的参数:
py
method, # 请求方法(必填)
url, # 接口地址
params = None, # 查询字符串
data = None, # 表单参数
headers = None, # 请求头
cookies = None, # cookies
files = None, # 文件上传
json = None, # json参数总结:
- 上述三种方式本质都是通过session发送请求的,只是封装的程度不同。
- 前两种方式每次请求都会新建会话,请求相互隔离;第三种基于同一个 Session,可以实现请求共享与接口关联。
- 仅执行单次请求可使用第一种;需要多次请求、接口关联的场景,推荐使用第三种。
3、详细介绍requests发送请求的参数
3.1 查询字符串
查询字符串有两种方式:两种方式效果都是一样的
方式1: 直接使用?拼在URL后面
py
import requests
session = requests.session()
session.request(
method = "get",
url="https://www.baidu.com?name=弹简特",
)方式2:
py
import requests
session = requests.session()
session.request(
method = "get",
url="https://www.baidu.com",
params={
"name": "弹简特"
}
)3.2 表单参数
如何判断,一个参数是表单参数呢?
两种判断方法:
1)他是一个网页中的form表单,比如:
html
<form action="http://www.baidu.com" method="POST">
<p>用户名:<input type="text" name="username" /></p>
<p>密码:<input type="password" name="password" /></p>
<input type="submit" value="Submit" />
</form>2)他的请求头里面有:x-www-form-urlencoded、multipart/form-data(文件就是通过表单上传的)
有上述两种特点的,那么他的参数就是表单参数。
此时我们构造请求的时候,对于表单参数使用如下所示:
py
import requests
session = requests.session()
session.request(
method = "post",
url="https://www.baidu.com",
data={ # 表单参数
"name": "弹简特"
},
)3.3 json参数
如何判断,一个参数是json参数呢?
有两种判断依据:
1)在请求头中是:application/json
2)根据请求的内容来判断,比如:
js
{
"username": "test_user01",
"password": "123456abc",
"rememberMe": true,
"captcha": "a1b2",
"deviceId": "web-pc-2026"
}有上述两种特点的,那么他的参数就是json参数。
此时我们构造请求的时候,对于json参数使用如下所示:
py
import requests
session = requests.session()
session.request(
method = "post",
url="https://www.baidu.com",
json={ # json参数
"name": "弹简特"
},
)3.4 文件参数
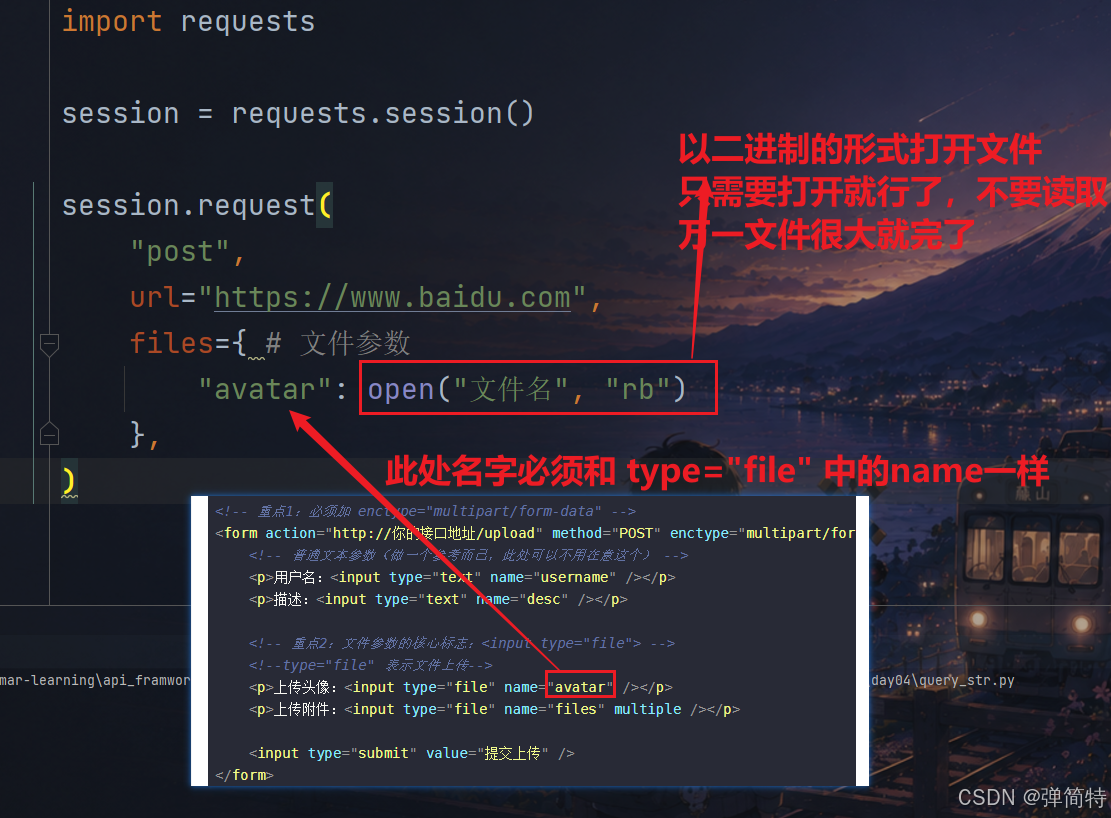
如何判断,一个参数是文件参数呢?
两种判断方法:
1)他的HTML代码是文件表单,如下:
html
<!-- 重点1:必须加 enctype="multipart/form-data" -->
<form action="http://你的接口地址/upload" method="POST" enctype="multipart/form-data">
<!-- 普通文本参数(做一个参考而已,此处可以不用在意这个) -->
<p>用户名:<input type="text" name="username" /></p>
<p>描述:<input type="text" name="desc" /></p>
<!-- 重点2:文件参数的核心标志:<input type="file"> -->
<!--type="file" 表示文件上传-->
<p>上传头像:<input type="file" name="avatar" /></p>
<p>上传附件:<input type="file" name="files" multiple /></p>
<input type="submit" value="提交上传" />
</form>2)在请求头中是:multipart/form-data
有上述两种特点的,那么他的参数就是文件参数。
此时我们构造请求的时候,对于文件参数使用如下所示:
py
import requests
session = requests.session()
session.request(
method="post",
url="https://www.baidu.com",
files={ # 文件参数
"avatar": open("文件路径", "rb")
},
)
4、requests响应对象的介绍
上述我们介绍完如何构造一个请求,那请求发送到服务器之后,服务器会返回一个响应,这个响应我们封装在Response实例对象中:
Response常用的属性和方法:
py
import requests
session = requests.session()
resp = session.request(
method="post",
url="https://www.baidu.com",
)
# 1. 状态码:服务器返回的HTTP状态码(如200成功、404不存在、500服务器错误)
print('状态码', resp.status_code)
# 2. 状态说明:HTTP状态码对应的文字描述(如"OK"对应200,"Not Found"对应404)
print('状态说明', resp.reason)
# 3. 响应头:服务器返回的响应头信息(包含Content-Type、Set-Cookie等关键信息)
print('响应头', resp.headers)
# 4. 响应Cookies:服务器设置的Cookies(后续请求可携带这些Cookies维持会话)
print('响应Cookies', resp.cookies)
# 5. 响应体(字节):原始二进制响应内容(下载文件、图片等非文本内容时常用,都是字节,你看不懂)
print('响应体(字节)', resp.content)
# 6. 响应体(字符串):自动按编码解码后的文本响应(处理普通文本/HTML时用)
print('响应体(字符串)', resp.text)
# 7. 响应体(JSON):将响应体解析为Python字典/列表(接口返回JSON时用,非JSON会报错)
print('响应体(JSON)', resp.json()) # 可能会报错,所以此处就设置为了方法
# 8. 响应时间:从请求发起到收到响应的耗时(可用于接口性能测试)
print('响应时间', resp.elapsed)
# 9. 字符编码:requests自动识别的响应内容编码(影响resp.text的解码结果)
print('字符编码', resp.encoding)四、接口自动化-接口关联
其实接口关联的概念我们在之前的接口测试工具中也有介绍过:
1、是什么是接口关联
接口关联: 就是从第1个接口的响应中获取内容,用来作为第2个接口的请求参数。
所以接口关联一定是涉及两个接口的,如果是一个接口的话,就不叫接口关联了。
实现思路:
第一步:在第一个接口返回的响应中提取出需要的参数,保存到变量中(对于我们怎么去提取,我们后续会介绍)
第二步:将第一步中提取到的值在拿到我们的响应中带到服务器
2、提取响应中的值的方式
2.1 正则提取
正则提取:适用于所有字符串形式的响应 (包括HTML文本、普通文本、JSON字符串等),使用Python自带的 re 模块实现,无需额外安装依赖。但在处理JSON数据时,写法相对复杂,维护成本较高。
2.2 JSONPATH提取
JSONPath 提取:专门适用于结构化的JSON数据 (需先将响应解析为Python字典/列表),需要安装第三方库(如 jsonpath-ng),优点是写法简洁、可读性强,是接口测试中提取JSON字段的主流方式。
3、案例演示
我们接下里就微信各种平台的一个例子
该例子的准备阶段参考博客:接口关联
我们的第一个接口:
py
https://api.weixin.qq.com/cgi-bin/token?grant_type=client_credential&appid=wx9335efa56e8cbb64&secret=0750c9411423c510fd0c2a1acdc32aa4他会返回我们的鉴权码,这个鉴权码就好比是我们的身份证,我们后续其他所有的接口都需要带上这个身份证才可以请求。
第二个接口:获取我们创建过的标签,要求带上第一个接口的鉴权码作为参数
bash
https://api.weixin.qq.com/cgi-bin/tags/get?access_token=第一个接口的鉴权码3.1 正则提取
导入正则模块:import re
响应数据形如:
text
{
"access_token": "104_pJh004zniW3I9Q0AZika1qpJd-eI14vSoeq1aYjXfAN5kNeTow64zOJaVv4gbjbJc1K-sGpkQNP7t9-WVWMwMaHXPNMhqJhUtXend_KWMrOywx2sCB0ua21xRqINWVjAHAFON",
"expires_in": 7200
}方式1:使用search
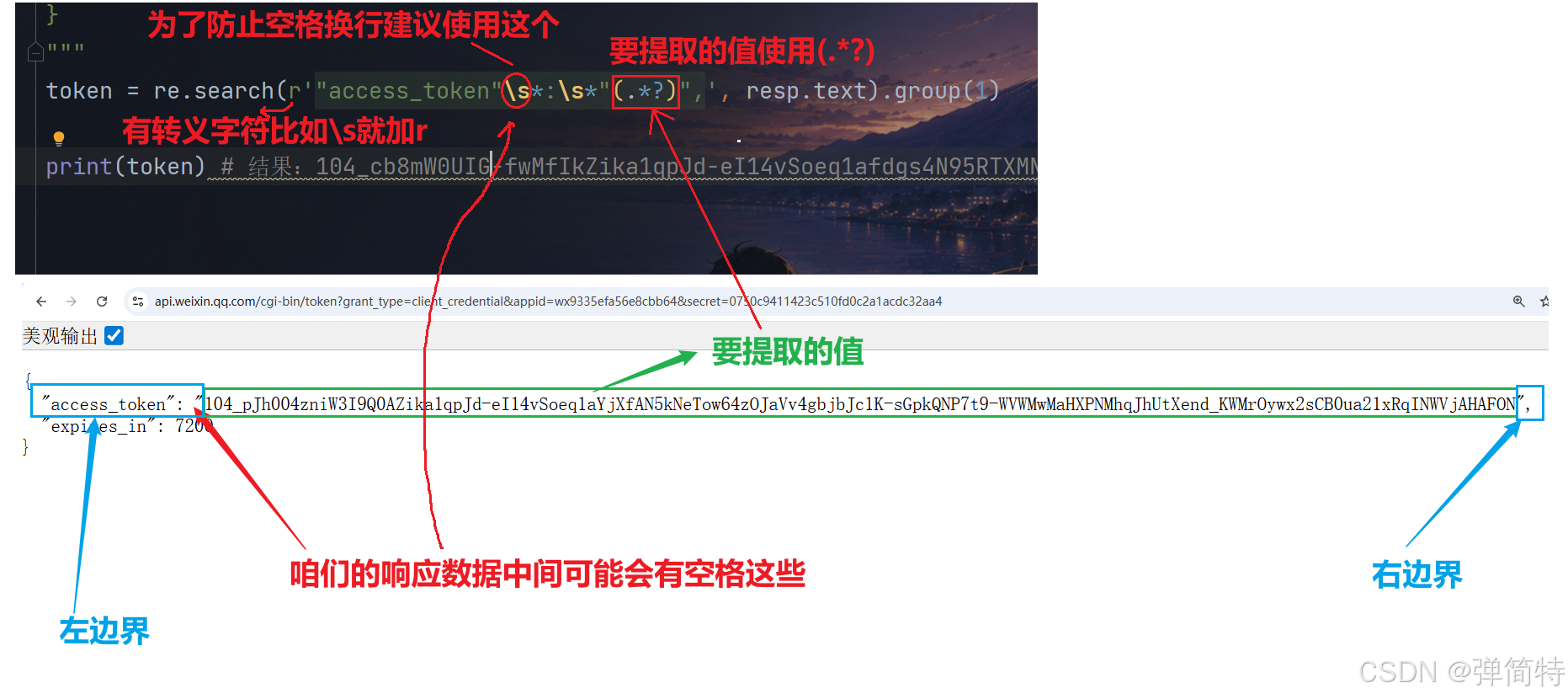
使用正则搜索方式:re.search("正则表达式", 从响应结果中提取)
用法:re.search("正则表达式", 目标字符串),第一个参数是正则,第二个参数是要匹配的字符串(如 resp.text)。
正则提取常用语法:左边界(.*?)右边界,用 () 包裹要提取的内容。
提取结果是 Match 对象,需用 .group(1) 取出括号内的内容;如果没匹配到,结果为 None。
示例:
py
# 导入正则
import re
# 导入requests
import requests
# 方式1:使用search的方式
# 构造请求
session = requests.session()
# 第一个接口
resp = session.request(
method="get",
url="https://api.weixin.qq.com/cgi-bin/token?grant_type=client_credential&appid=wx9335efa56e8cbb64&secret=0750c9411423c510fd0c2a1acdc32aa4"
)
"""
响应数据形如:
{
"access_token": "104_pJh004zniW3I9Q0AZika1qpJd-eI14vSoeq1aYjXfAN5kNeTow64zOJaVv4gbjbJc1K-sGpkQNP7t9-WVWMwMaHXPNMhqJhUtXend_KWMrOywx2sCB0ua21xRqINWVjAHAFON",
"expires_in": 7200
}
"""
token = re.search(r'"access_token"\s*:\s*"(.*?)",', resp.text).group(1)
print(token) # 结果:104_cb8mW0UIG-fwMfIkZika1qpJd-eI14vSoeq1afdgs4N95RTXMN9erWhxOBfownZxEb0DP2wHU1oXzP8_qzWai2IHDmscXCQDwMxYqijNqVkRNptTheLL8trBiFUCSUjAHATJL
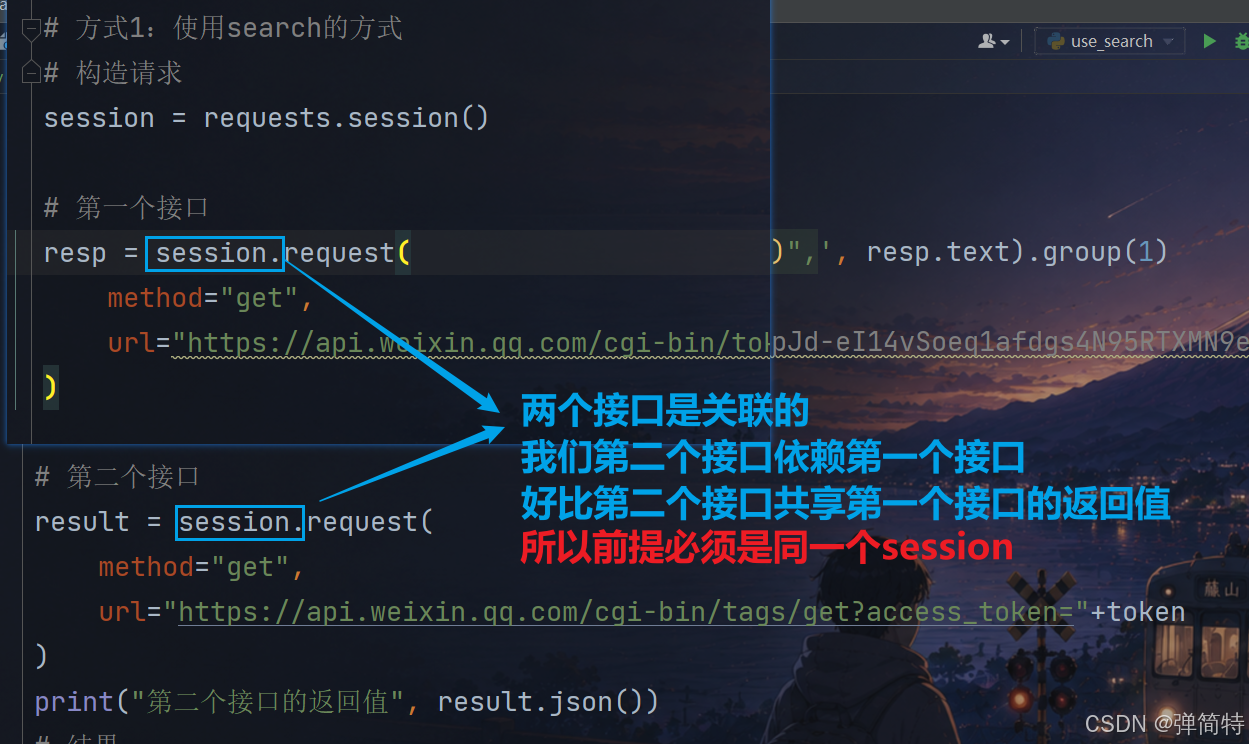
# 第二个接口
result = session.request(
method="get",
url="https://api.weixin.qq.com/cgi-bin/tags/get?access_token="+token
)
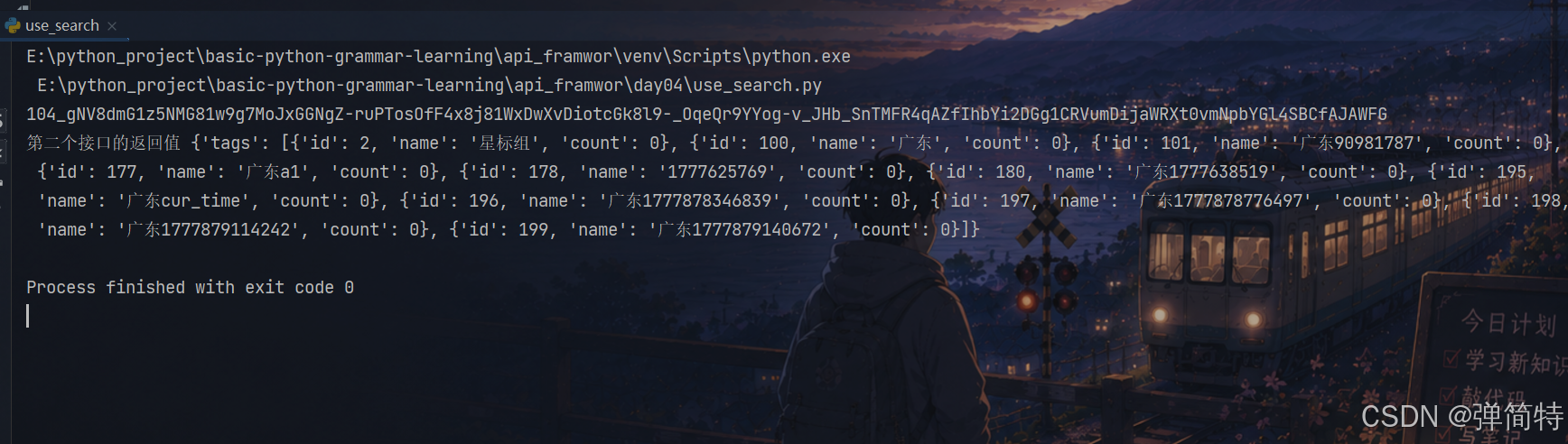
print("第二个接口的返回值", result.json())
# 结果:
"""
第二个接口的返回值 {'tags': [{'id': 2, 'name': '星标组', 'count': 0},
{'id': 100, 'name': '广东', 'count': 0},
{'id': 101, 'name': '广东90981787', 'count': 0},
{'id': 177, 'name': '广东a1', 'count': 0},
{'id': 178, 'name': '1777625769', 'count': 0},
{'id': 180, 'name': '广东1777638519', 'count': 0},
{'id': 195, 'name': '广东cur_time', 'count': 0},
{'id': 196, 'name': '广东1777878346839', 'count': 0},
{'id': 197, 'name': '广东1777878776497', 'count': 0},
{'id': 198, 'name': '广东1777879114242', 'count': 0},
{'id': 199, 'name': '广东1777879140672', 'count': 0}]}
"""
方式2:使用findall
用法:re.findall("正则表达式", 目标字符串),会返回一个列表 ,包含所有匹配到的括号内的内容,可以直接用下标(如 [0])取值。
py
# 导入正则
import re
# 导入requests
import requests
# 方式2:使用findall的方式
# 构造请求
session = requests.session()
# 第一个接口
resp = session.request(
method="get",
url="https://api.weixin.qq.com/cgi-bin/token?grant_type=client_credential&appid=wx9335efa56e8cbb64&secret=0750c9411423c510fd0c2a1acdc32aa4"
)
"""
响应数据形如:
{
"access_token": "104_pJh004zniW3I9Q0AZika1qpJd-eI14vSoeq1aYjXfAN5kNeTow64zOJaVv4gbjbJc1K-sGpkQNP7t9-WVWMwMaHXPNMhqJhUtXend_KWMrOywx2sCB0ua21xRqINWVjAHAFON",
"expires_in": 7200
}
"""
token = re.findall(r'"access_token"\s*:\s*"(.*?)",', resp.text)[0]
print(token) # 结果:104_gNV8dmG1z5NMG81w9g7MoJxGGNgZ-ruPTosOfF4x8j81WxDwXvDiotcGk8l9-_OqeQr9YYog-v_JHb_SnTMFR4qAZfIhbYi2DGg1CRVumDijaWRXt0vmNpbYGl4SBCfAJAWFG
# 第二个接口
result = session.request(
method="get",
url="https://api.weixin.qq.com/cgi-bin/tags/get?access_token="+token
)
print("第二个接口的返回值", result.json())
# 结果:
"""
第二个接口的返回值
{'tags': [
{'id': 2, 'name': '星标组', 'count': 0},
{'id': 100, 'name': '广东', 'count': 0},
{'id': 101, 'name': '广东90981787', 'count': 0},
{'id': 177, 'name': '广东a1', 'count': 0},
{'id': 178, 'name': '1777625769', 'count': 0},
{'id': 180, 'name': '广东1777638519', 'count': 0},
{'id': 195, 'name': '广东cur_time', 'count': 0},
{'id': 196, 'name': '广东1777878346839', 'count': 0},
{'id': 197, 'name': '广东1777878776497', 'count': 0},
{'id': 198, 'name': '广东1777879114242', 'count': 0},
{'id': 199, 'name': '广东1777879140672', 'count': 0}
]}
"""
search()和findall()的核心区别
| 方法 | 结果类型 | 作用 |
|---|---|---|
re.search() |
Match 对象/None |
只找第一个匹配项,找到就停止 |
re.findall() |
列表 | 找所有匹配项,返回所有括号里的内容 |
3.2 JSONPath提取
基础说明
JSONPath 专门用来提取接口返回的 JSON 结构化数据,Python 没有内置该功能,属于第三方库,必须手动安装、导入后才能使用。
第一步:安装依赖库
目前有两个常用包,区分主流版本和老旧版本:
- 主流推荐(工作/测试常用)
bash
pip install jsonpath-ng
- 老旧版本(不推荐,仅了解即可)
bash
pip install jsonpath
第二步:导入模块
根据安装的库,选择对应导入方式:
python
# 方式1:使用 jsonpath-ng(主流)
from jsonpath_ng import parse
# 方式2:使用旧版 jsonpath(少用)
import jsonpath第三步:使用前提(必看)
JSONPath 不能直接操作字符串,使用前必须满足 2 个条件:
- 拿到接口响应对象
resp; - 调用
resp.json(),把JSON 字符串转换成 Python 字典/列表(JSON 对象)。
对比正则:正则直接操作
resp.text(字符串),无需转换。
准备测试数据(全程共用示例 JSON)
使用微信获取access_token接口作为测试接口,后续所有例子都基于该接口返回数据:
python
import requests
# 微信获取token接口地址
url = "https://api.weixin.qq.com/cgi-bin/token?grant_type=client_credential&appid=wx9335efa56e8cbb64&secret=0750c9411423c510fd0c2a1acdc32aa4"
resp = requests.get(url)
# 核心步骤:转为 Python 字典(JSON 对象)
json_data = resp.json()
print(json_data)
"""
接口返回结构:
{
"access_token": "104_pJh004zniW3I9Q0AZika1qpJd-eI14vSoeq1aYjXfAN5kNeTow64zOJaVv4gbjbJc1K-sGpkQNP7t9-WVWMwMaHXPNMhqJhUtXend_KWMrOywx2sCB0ua21xRqINWVjAHAFON",
"expires_in": 7200
}
"""补充:JSONPath 提取的时候基础符号说明
| 符号 | 作用 |
|---|---|
$ |
代表JSON根节点,所有表达式必须以此开头 |
. |
层级连接符,用于访问下一级字段 |
[索引] |
数组下标,从0开始取值 |
[*] |
通配符,匹配数组内所有元素 |
.. |
递归匹配,跨多层级查找字段 |
方式1:旧版 jsonpath(简单易懂,入门首选)
1. 基础语法格式
python
# 固定写法
jsonpath.jsonpath(待提取的字典数据, JSONPath表达式)- 参数1:
json_data→resp.json()解析后的字典 - 参数2:JSONPath 表达式,
$代表整个 JSON 根节点 - 返回值:列表 ,匹配不到数据返回
False
实战示例
需求:提取根节点下的 access_token 字段
- 表达式写法:
$.access_token - 完整代码
第一个接口:
python
import jsonpath
# 导入requests
import requests
# 构造请求
session = requests.session()
# 第一个接口
resp = session.request(
method="get",
url="https://api.weixin.qq.com/cgi-bin/token?grant_type=client_credential&appid=wx9335efa56e8cbb64&secret=0750c9411423c510fd0c2a1acdc32aa4"
)
"""
响应数据形如:
{
"access_token": "104_pJh004zniW3I9Q0AZika1qpJd-eI14vSoeq1aYjXfAN5kNeTow64zOJaVv4gbjbJc1K-sGpkQNP7t9-WVWMwMaHXPNMhqJhUtXend_KWMrOywx2sCB0ua21xRqINWVjAHAFON",
"expires_in": 7200
}
"""
# 使用JSON提取值
token = jsonpath.jsonpath(resp.json(), "$.access_token")
print(token)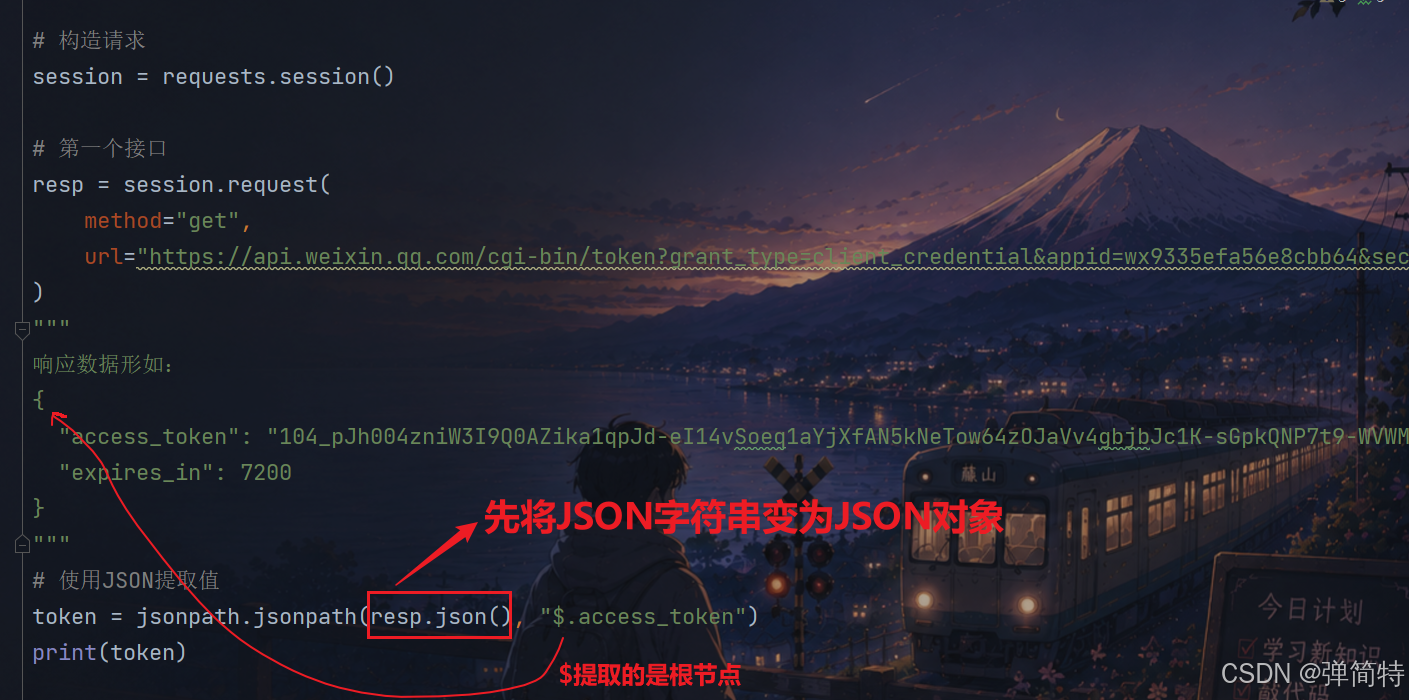
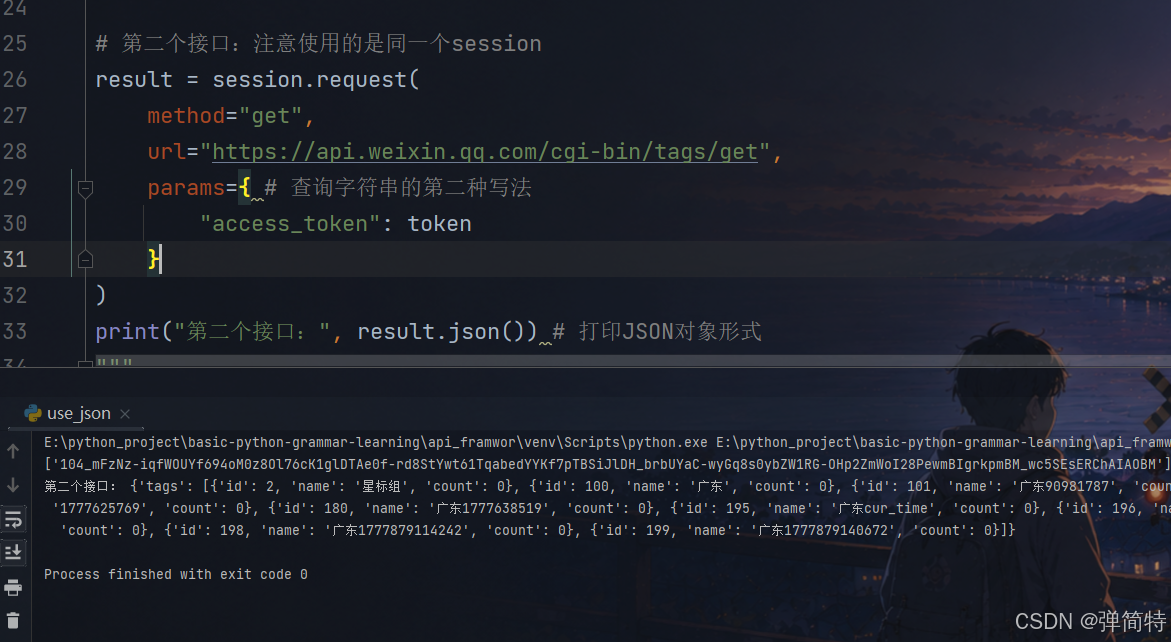
第二个接口:
py
# 第二个接口:注意使用的是同一个session
result = session.request(
method="get",
url="https://api.weixin.qq.com/cgi-bin/tags/get",
params={ # 查询字符串的第二种写法
"access_token": token
}
)
print("第二个接口:", result.json()) # 打印JSON对象形式
"""
结果:
第二个接口:
{'tags':
[{'id': 2, 'name': '星标组', 'count': 0},
{'id': 100, 'name': '广东', 'count': 0},
{'id': 101, 'name': '广东90981787', 'count': 0},
{'id': 177, 'name': '广东a1', 'count': 0},
{'id': 178, 'name': '1777625769', 'count': 0},
{'id': 180, 'name': '广东1777638519', 'count': 0},
{'id': 195, 'name': '广东cur_time', 'count': 0},
{'id': 196, 'name': '广东1777878346839', 'count': 0},
{'id': 197, 'name': '广东1777878776497', 'count': 0},
{'id': 198, 'name': '广东1777879114242', 'count': 0},
{'id': 199, 'name': '广东1777879140672', 'count': 0}]}
"""
方式2:主流 jsonpath-ng(企业/自动化测试常用)
1. 分步语法(固定两步)
- 用
parse()解析 JSONPath 表达式 - 用
find()去字典中匹配数据,再遍历取值
2. 实战示例(同上面需求,提取 access_token)
具体的解释,看代码的注释
python
import requests
# 构造请求会话
session = requests.session()
# 第一个接口:获取 access_token
resp = session.request(
method="get",
url="https://api.weixin.qq.com/cgi-bin/token?grant_type=client_credential&appid=wx9335efa56e8cbb64&secret=0750c9411423c510fd0c2a1acdc32aa4"
)
"""
响应数据形如:
{
"access_token": "104_pJh004zniW3I9Q0AZika1qpJd-eI14vSoeq1aYjXfAN5kNeTow64zOJaVv4gbjbJc1K-sGpkQNP7t9-WVWMwMaHXPNMhqJhUtXend_KWMrOywx2sCB0ua21xRqINWVjAHAFON",
"expires_in": 7200
}
"""
# 1. 将响应转为Python字典:接口返回是 JSON 字符串,这行把它转成 Python 字典,JSONPath 只能操作字典。
json_data = resp.json()
# 2. 解析JSONPath表达式: parse() 作用:把字符串形式的表达式 $.access_token 编译成程序能识别的规则,存到 expr 里。
expr = parse("$.access_token")
# 3. 执行匹配并提取结果: 用上面编译好的规则,去字典里查找内容,返回一组匹配对象(不是直接取值)。这组匹配对象使用match_res存储
match_res = expr.find(json_data)
# 4. 遍历match_res 找出要提取的值
access_token = ""
for item in match_res:
# item是匹配对象
# item.value是匹配对象中的内容
access_token = item.value
print("提取到的access_token:", access_token)
# 第二个接口:复用同一个session,传入上一步拿到的token
result = session.request(
method="get",
url="https://api.weixin.qq.com/cgi-bin/tags/get",
params={ # 查询字符串第二种写法
"access_token": access_token
}
)
print("第二个接口:", result.json()) # 打印JSON对象形式
"""
结果:
第二个接口:
{'tags':
[{'id': 2, 'name': '星标组', 'count': 0},
{'id': 100, 'name': '广东', 'count': 0},
{'id': 101, 'name': '广东90981787', 'count': 0},
{'id': 177, 'name': '广东a1', 'count': 0},
{'id': 178, 'name': '1777625769', 'count': 0},
{'id': 180, 'name': '广东1777638519', 'count': 0},
{'id': 195, 'name': '广东cur_time', 'count': 0},
{'id': 196, 'name': '广东1777878346839', 'count': 0},
{'id': 197, 'name': '广东1777878776497', 'count': 0},
{'id': 198, 'name': '广东1777879114242', 'count': 0},
{'id': 199, 'name': '广东1777879140672', 'count': 0}]}
"""拓展:多层级 / 数组数据提取示例
示例1:提取普通多层字段
模拟嵌套结构JSON:
json
{
"code": 200,
"data": {
"access_token": "abc123",
"expires_in": 7200
}
}提取内层 access_token:
- 表达式:
$.data.access_token
示例2:提取数组内数据(JSON 数组常用)
模拟带数组结构JSON:
json
{
"data": [
{"access_token": "token01", "expires_in": 7200},
{"access_token": "token02", "expires_in": 3600}
]
}- 提取第一条数据的
access_token:表达式$.data[0].access_token - 提取所有数据的
access_token:表达式$.data[*].access_token([*]代表数组所有元素)
总结 正则 vs JSONPath
正则提取(re)
- 依赖:Python自带模块,无需安装
- 适用:所有字符串(普通文本、HTML、JSON字符串等)
- 常用方法
re.search(正则, 目标字符串):返回匹配对象,用.group(下标)取值,只匹配第一个结果re.findall(正则, 目标字符串):返回列表,用下标取值,匹配所有结果
- 通用提取句式:
左边界(.*?)右边界
JSONPath 提取
- 依赖:第三方库 ,必须手动
pip安装 - 适用:仅处理解析后的JSON字典/列表,不支持原始字符串
- 调用形式:传入JSON对象 + JSONPath表达式,统一返回列表,通过下标取值
- 基础句式:
$.层级节点
最后,老铁们,我们本期到此就结束了,我们本期主要就是介绍requests库和接口关联的使用,下一期我们将介绍统一请求封装,如果觉得有用,那么点赞关注,我们下一期继续。