100种动物语义分割数据集(A100-Seg)
代码详见:https://github.com/xiaozhou-alt/100-Class-Animal-Segmentation-Dataset-A100-Seg-
文章目录
- 100种动物语义分割数据集(A100-Seg)
-
- [1. 数据集概述](#1. 数据集概述)
-
- [1.1 数据集背景与意义](#1.1 数据集背景与意义)
- [1.2 数据集基本信息](#1.2 数据集基本信息)
- [2. 数据获取与标注流程](#2. 数据获取与标注流程)
-
- [2.1 图片获取](#2.1 图片获取)
- [2.2 标注流程](#2.2 标注流程)
-
-
- [2.2.1 标注工具:ISAT](#2.2.1 标注工具:ISAT)
- [2.2.2 配置参数](#2.2.2 配置参数)
- [2.2.3 具体步骤](#2.2.3 具体步骤)
-
- [3. 数据集结构](#3. 数据集结构)
- [4. 标注文件示例](#4. 标注文件示例)
-
- [4.1 PNG 掩码(`antelope_001.png`)](#4.1 PNG 掩码(
antelope_001.png)) - [4.2 ISAT JSON 文件(`antelope_001.json`)](#4.2 ISAT JSON 文件(
antelope_001.json))
- [4.1 PNG 掩码(`antelope_001.png`)](#4.1 PNG 掩码(
- [5. 模型训练效果](#5. 模型训练效果)
- [6. 数据集使用说明](#6. 数据集使用说明)
1. 数据集概述
1.1 数据集背景与意义
语义分割是计算机视觉的核心任务之一,在自动驾驶、医学影像分析、智能监控、生态系统监测等领域具有广泛应用。然而,针对动物的细粒度语义分割数据集仍十分稀缺。现有主流分割数据集(如COCO-Stuff、ADE20K、Cityscapes)中动物类别较少,且多为"stuff"背景类别,缺乏对动物个体轮廓的高质量像素级标注。
为了推动动物分割领域的研究,我们构建了 A100-Seg 数据集,其核心特点如下:
- 大规模动物种类 :包含 100 种常见及珍稀动物,覆盖哺乳类、鸟类、爬行类等。
- 充足样本量 :每种动物 100~150 张 图像,总计 超过 11,000 张,保证模型训练的泛化能力。
- 高精度像素级标注 :采用 SAM-ViT-B 自动预分割 + ISAT 人工精细修正,确保掩码边缘准确。
- 纯净场景 :每张图像仅包含 一种动物,无多类别干扰,适合聚焦于动物轮廓分割。
- 丰富标注格式 :同时提供 ISAT 原始 JSON (含多边形轮廓)和 PNG 二值掩码,方便二次处理。
目前公开数据集中,尚缺乏同时满足"100 种以上动物、每类≥100 张、像素级分割标注"的数据集,A100-Seg 填补了这一空白。
数据集下载:100种动物语义分割数据集
如果您使用了本项目的数据集,请使用如下方式进行引用:
tex
ZHOU Haojing. 100种动物语义分割数据集[DS/OL]. V1. Science Data Bank, 2026[2026-06-13]. https://doi.org/10.57760/sciencedb.38760. DOI:10.57760/sciencedb.38760.或
tex
@misc{实例分割,
author = {ZHOU Haojing},
title = {100种动物语义分割数据集},
year = {2026},
doi = {10.57760/sciencedb.38760},
url = {https://doi.org/10.57760/sciencedb.38760},
note = {CSTR: 31253.11.sciencedb.38760},
publisher = {ScienceDB}
}1.2 数据集基本信息
| 属性 | 说明 |
|---|---|
| 动物种类 | 100 种(详见 class.txt,按字母顺序排列) |
| 图像总数 | 11354张图片 |
| 图像格式 | PNG(RGB 彩色) |
| 掩码格式 | PNG(单通道,前景=255,背景=0) |
| 标注工具 | ISAT(基于 SAM-ViT-B 自动标注 + 人工修正) |
| 标注配置 | 轮廓模式:保存所有轮廓;背景组号=0;动物组号=1 |
| 文件结构 | images/动物名/图片.png annotations/masks/动物名/同名.png annotations/json/动物名/同名.json |
对比现有公开数据集(COCO-Stuff、ADE20K、Oxford Pet、Stanford Dogs 等),A100-Seg 具有以下显著优势:
| 对比项 | A100-Seg(本数据集) | COCO-Stuff | ADE20K | Oxford Pet |
|---|---|---|---|---|
| 动物种类 | 100 种 | ~30 种动物 | ~50 种动物 | 仅猫、狗 |
| 总样本量 | 11,000+ | ~10,000(含动物) | ~20,000(含非动物) | ~7,400 |
| 每类样本量 | 100~150 | 不均衡(少则几十) | 不均衡 | 约 200 |
| 标注粒度 | 像素级轮廓 | 像素级 | 像素级 | 像素级 |
| 标注质量 | SAM+人工精修 | 多边形 | 多边形 | 多边形 |
| 场景纯净度 | 单种动物 | 多目标混合 | 复杂场景 | 单种动物 |
| 提供格式 | PNG 掩码 + JSON | JSON | JSON | PNG 掩码 |
| 适用任务 | 动物分割、细粒度识别 | 通用分割 | 场景解析 | 宠物分割 |
2. 数据获取与标注流程
2.1 图片获取
本数据集所有图片均从必应图片搜索获取,严格遵循版权规范,具体流程如下:
-
访问必应图片搜索页面,使用筛选器选择"Free to modify, share, and use"(可修改、分享及使用)权限,确保图片使用合规;
-
以羚羊(antelope)为例,搜索链接,按此方式依次搜索100种动物的图片;
-
使用Microsoft Edge浏览器扩展插件ImageAssistant,批量提取当前搜索页面的图片并下载;
-
人工清洗:剔除模糊、分辨率过低、动物主体不明确或存在版权争议的图片,确保每一张图片的可用性。
2.2 标注流程
采用 "AI 预标注 + 人工精修" 的半自动流程,兼顾效率与精度。
2.2.1 标注工具:ISAT
ISAT(Image Segmentation Annotation Tool)是一款支持交互式分割的标注工具,内置 SAM 模型,可大幅提升多边形标注效率。
2.2.2 配置参数
- 分割模型 :
SAM-ViT-B(精度与速度平衡的最佳选择) - 轮廓模式 :保存所有轮廓(保留每个连通区域的多边形,避免丢失细节)
- 组号设置 :
__background__组号固定为 0(背景像素)- 所有动物类别组号统一为 1(前景像素,不同动物通过 label 名称区分)
注:由于每张图片仅包含一种动物,因此组号 1 对应唯一的前景类别,组内不同 label 仅用于标识物种名称。
2.2.3 具体步骤
- 自动预标注:加载原始图像,调用 SAM-ViT-B 模型生成初始分割掩码。
- 人工修正 :
- 对自动生成的轮廓进行 添加、删除、移动 控制点,修正边缘误差。
- 若模型漏标,使用多边形工具手动添加。
- 若模型误标背景区域,使用"擦除"工具删除。
- 保存标注 :
- 保存为 ISAT 原始 JSON 文件(包含多边形点集、类别名称、组号等)。
- 同时导出 PNG 二值掩码(前景=白色,背景=黑色)。
标注结果展示:

3. 数据集结构
数据集采用清晰的层级文件夹结构,便于用户快速定位和使用数据,整体结构如下:
makefile
A100-Seg/ # 主文件夹
├─ images/ # 原始图像文件夹
│ ├─ antelope/ # 动物名称子文件夹(与class.txt一致)
│ │ ├─ antelope_001.png
│ │ ├─ antelope_002.png
│ │ └─ ...
│ ├─ bear/
│ │ └─ ...
│ └─ ...(共100个动物子文件夹)
├─ annotations/ # 标注文件夹
│ ├─ masks/ # 二值分割掩码(PNG格式)
│ │ ├─ antelope/
│ │ │ ├─ antelope_001.png
│ │ │ └─ ...
│ │ └─ ...
│ └─ json/ # ISAT原始标注文件(JSON格式)
│ ├─ antelope/
│ │ ├─ antelope_001.json
│ │ └─ ...
│ └─ ...
├─ pic/ # 说明文档用图片
├─ class.txt # 100种动物名称清单(每行一种)
├─ README.md
└─ README-zh.md说明:
-
原始图像 :
{动物名}_{三位序号}.png,例如antelope_001.png。 -
掩码图像 :与原始图像完全相同 的文件名,放置在
annotations/masks/{动物名}/下。 -
JSON 标注 :与原始图像完全相同 的文件名,放置在
annotations/json/{动物名}/下。
4. 标注文件示例
4.1 PNG 掩码(antelope_001.png)
txt
- 尺寸:与原始图像一致(宽度 × 高度)。
- 像素值:0(背景)或 255(前景动物)。
- 可视化:前景为白色,背景为黑色。4.2 ISAT JSON 文件(antelope_001.json)
json
<?xml version="1.0" ?>
<annotation> {
"info": {
"description": "ISAT",
"folder": "../images/antelope",
"name": "antelope_001.png",
"width": 1640,
"height": 1025,
"depth": 3,
"note": ""
},
"objects": [
{
"category": "antelope",
"group": 1,
"segmentation": [
[
776.0,
124.0
],
...
[
778.0,
124.0
]
],
"area": 202595.0,
"layer": 1.0,
"bbox": [
371.0,
124.0,
942.0,
960.0
],
"iscrowd": false,
"note": ""
},
{
"category": "__background__",
"group": 0,
"segmentation": [
[
508.0,
714.0
],
...
[
502.0,
715.0
]
],
"area": 984.5,
"layer": 2.0,
"bbox": [
496.0,
714.0,
518.0,
771.0
],
"iscrowd": false,
"note": ""
}
]
}5. 模型训练效果
本数据集已在一系列分割模型上进行初步训练,以下为模型性能指标:
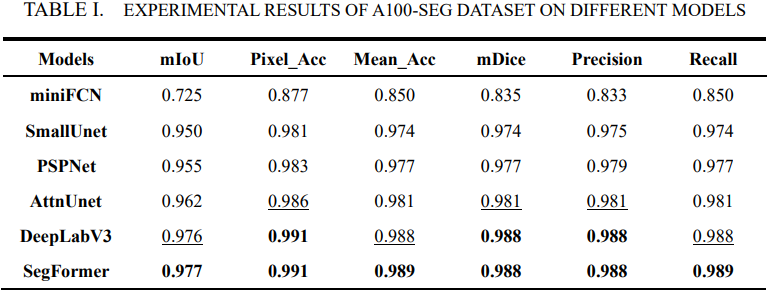
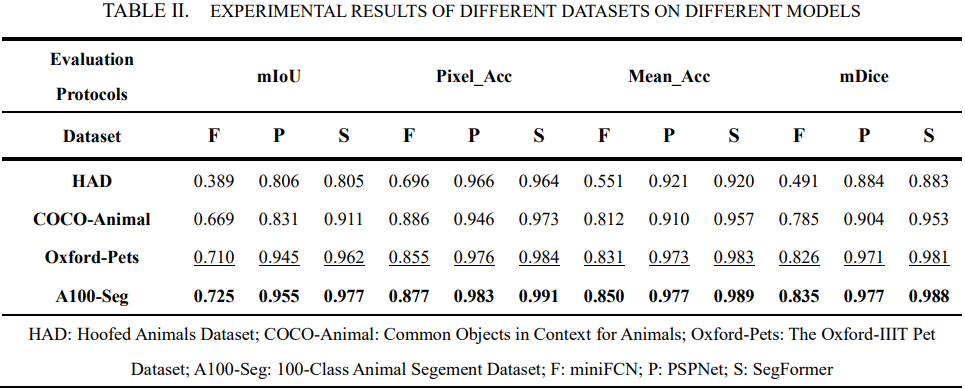
此处仅以 SegFormer 为例,展示训练输出部分图像,更多请详见后文 Kaggle 链接:
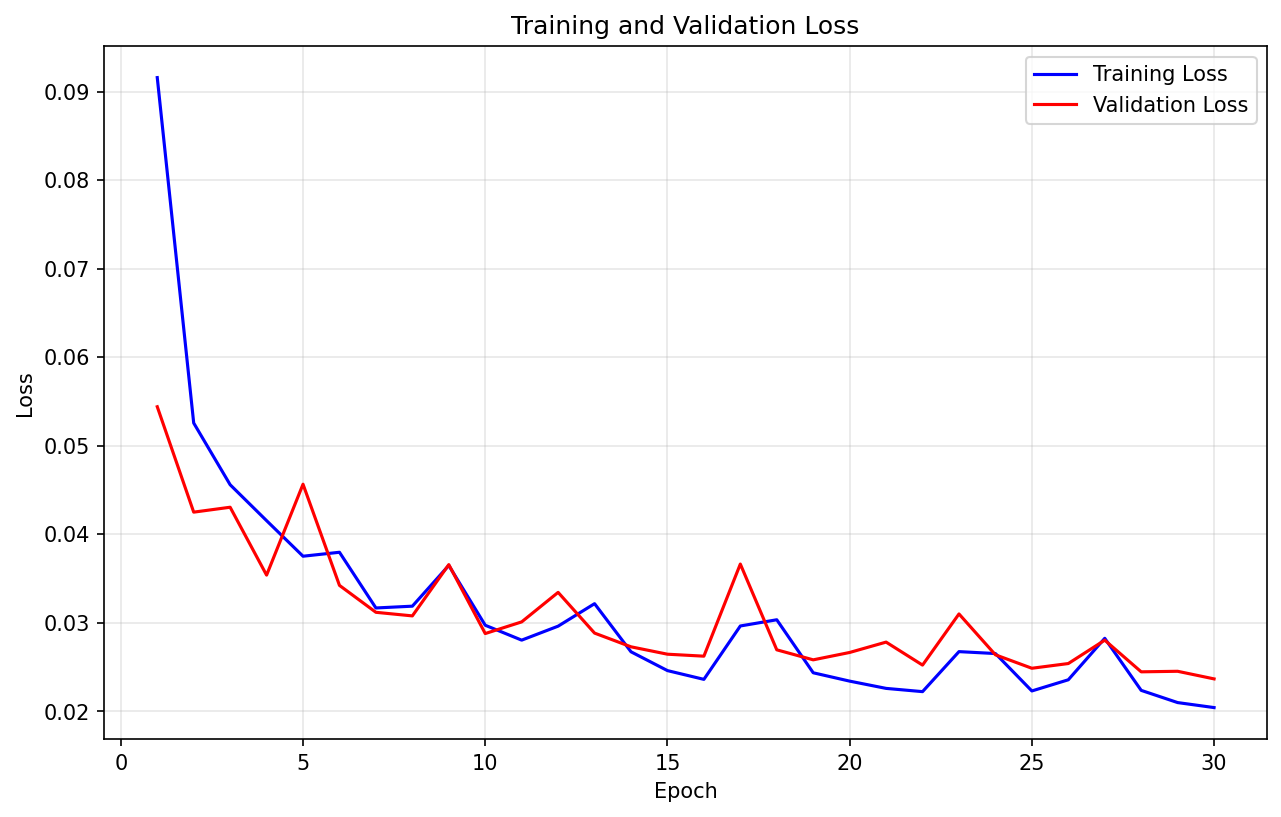
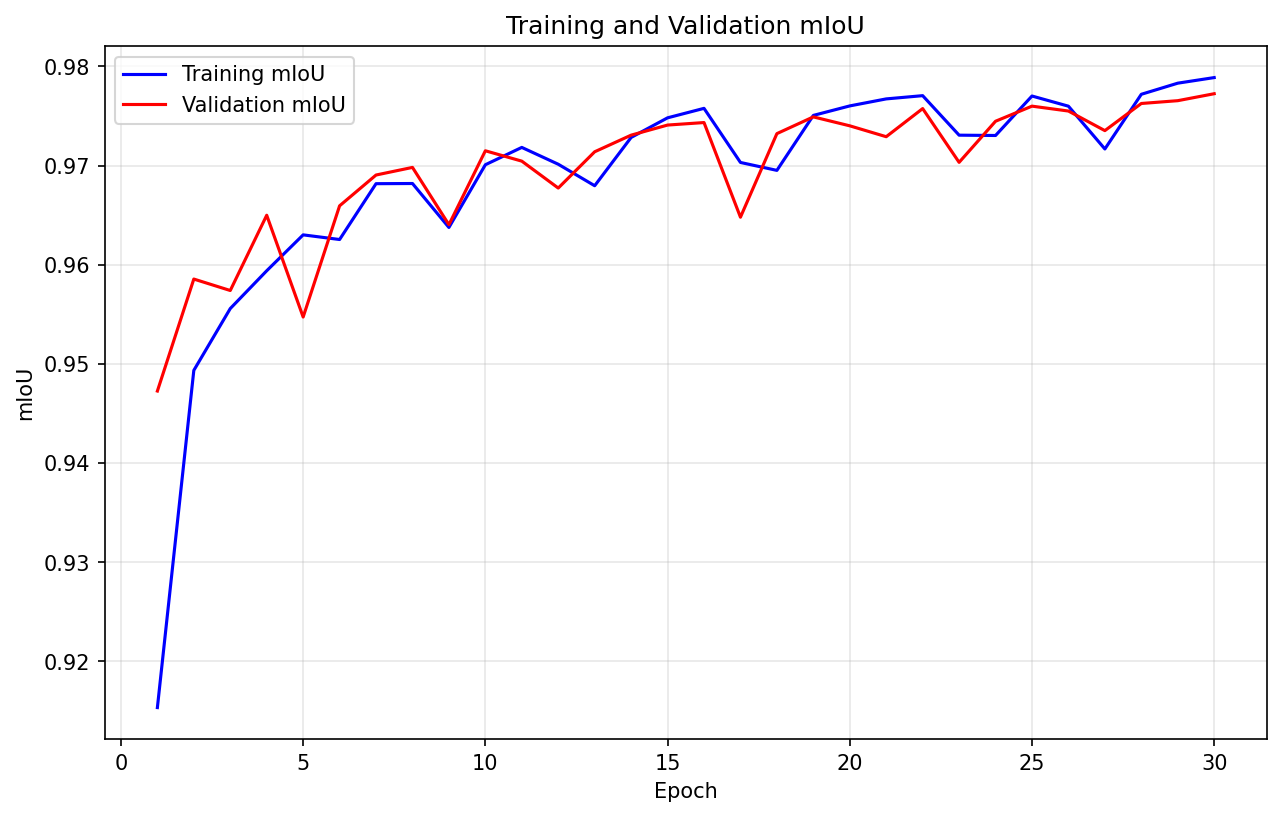
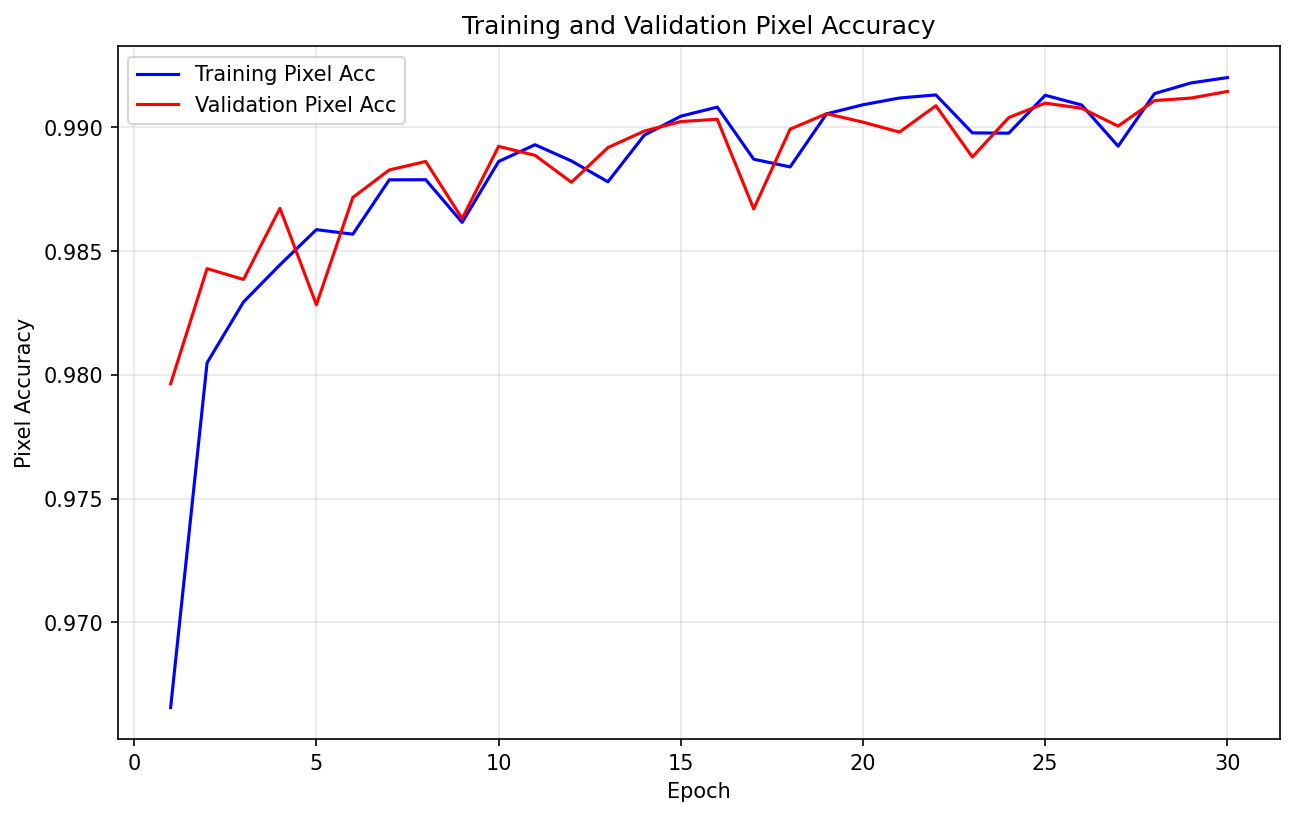
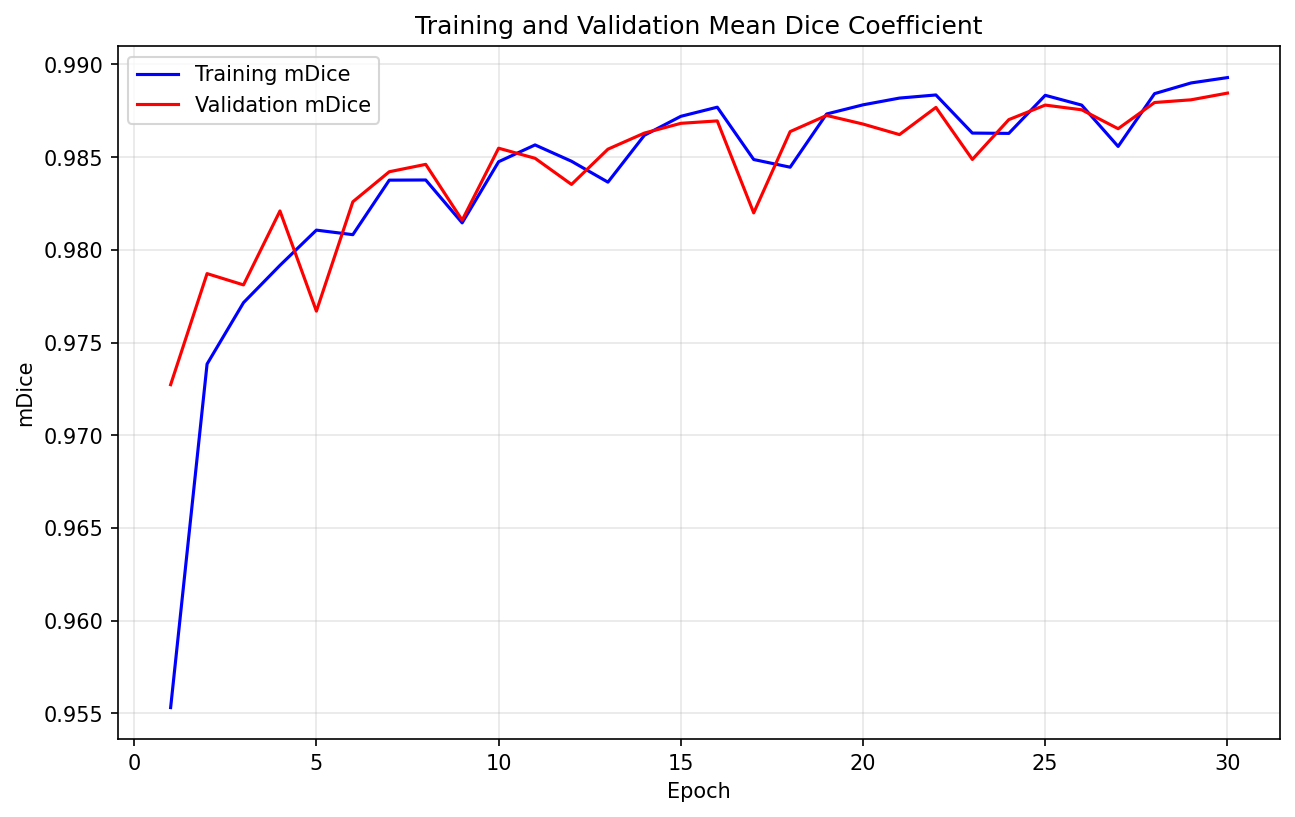
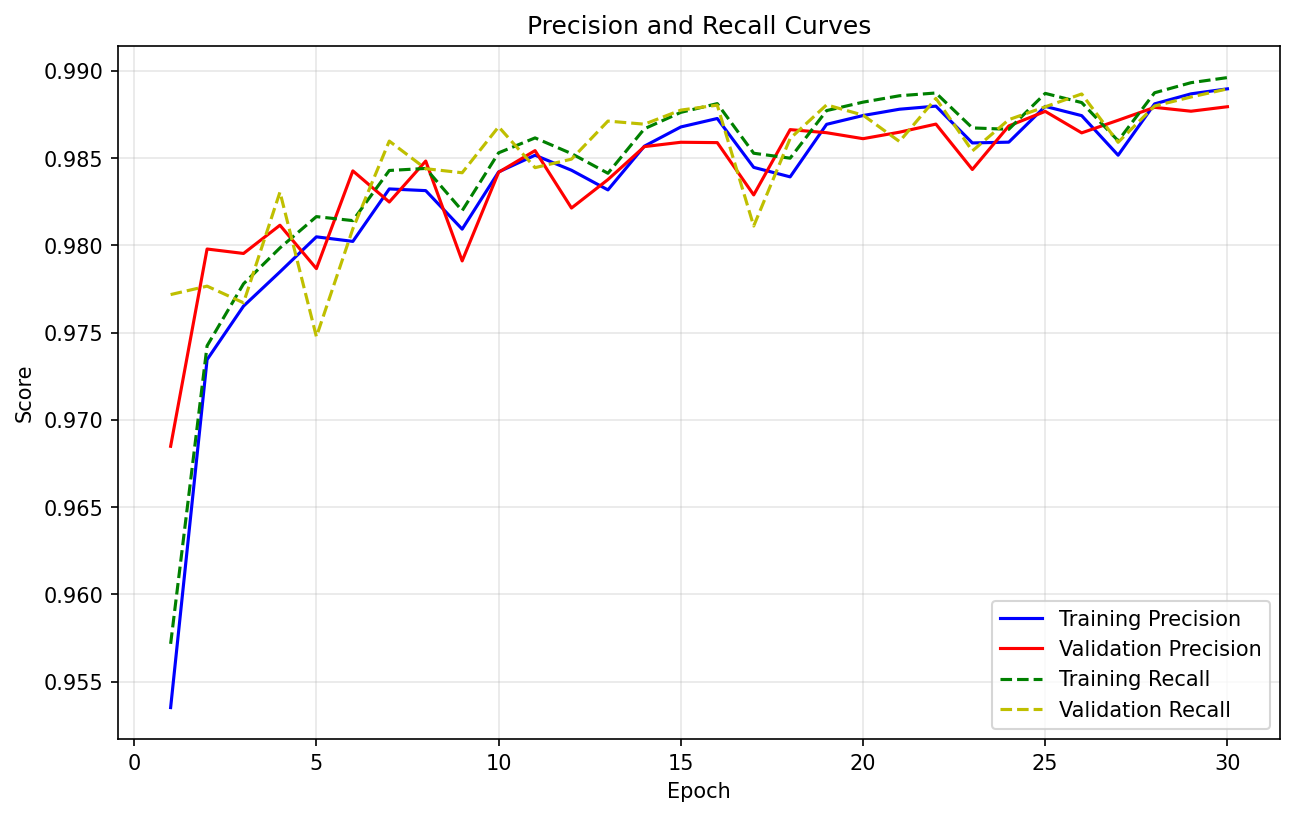
输出展示:
原始图像-标签二值掩码-标签覆盖-预测二值掩码-预测覆盖



6. 数据集使用说明
-
本数据集可直接用于目标检测模型的训练、验证与测试,支持DeepLab系列、SegFormer、UNet等主流模型;
-
使用时需注意:images文件夹与annotations文件夹下的文件一一对应,class.txt为模型训练时的类别配置依据,需确保类别顺序不修改;
Kaggle 训练 log 记录链接:
如果你喜欢我的文章,不妨给小周一个免费的点赞和关注吧!