又到了和DataWhale一起学习的时候咯,这次我们的主题主要围绕ROCm展开
1. 初探ROCm和Gemma4:
今天就先从ROCm和Gemma4来开始吧
1.1: Gemma4是什么?
Gemma 4 是 Google DeepMind 搞出来的基于 Apache 2.0 协议的开源多模态大模型。从底层架构来看,这代模型主要混用了稠密和 MoE 混合专家架构,参数量从适合端侧跑的 E2B 一直覆盖到了中等体量的 31B。这代最大的改动是舍弃了传统的多模态编码器,采用了无编码器直投射方案,让图片或者音频的连续数据直接映射进 Transformer 的骨干网络嵌入层里,这么做不仅把跨模态对齐的特征损耗降到了最低,处理效率也高了不少。为了照顾本地算力吃紧的设备,Gemma4在预训练阶段就深度切入了量化感知训练,在小参数版本的权重和 KV Cache 显存开销压到了 1GB 以下,再配合多 Token 预测技术重构了自回归生成范式,在保住高吞吐量的同时把解码延迟也打下来了。至于高级特性,它除了能吃下 256K 的超长上下文,同时还有一个特点底层原生植入了内置的思考机制和函数调用能力。也就是说模型在吐出最终结果前,会被强制在隐空间里自己走完多步的逻辑推演和工具调度,这让它在搞复杂的底层代码生成或是跑本地全自动化 Agent 工作流的时候,表现会更加好一些。
1.2: Gemma4架构初探:
我们先来看看Gemma4 E4B的整体架构
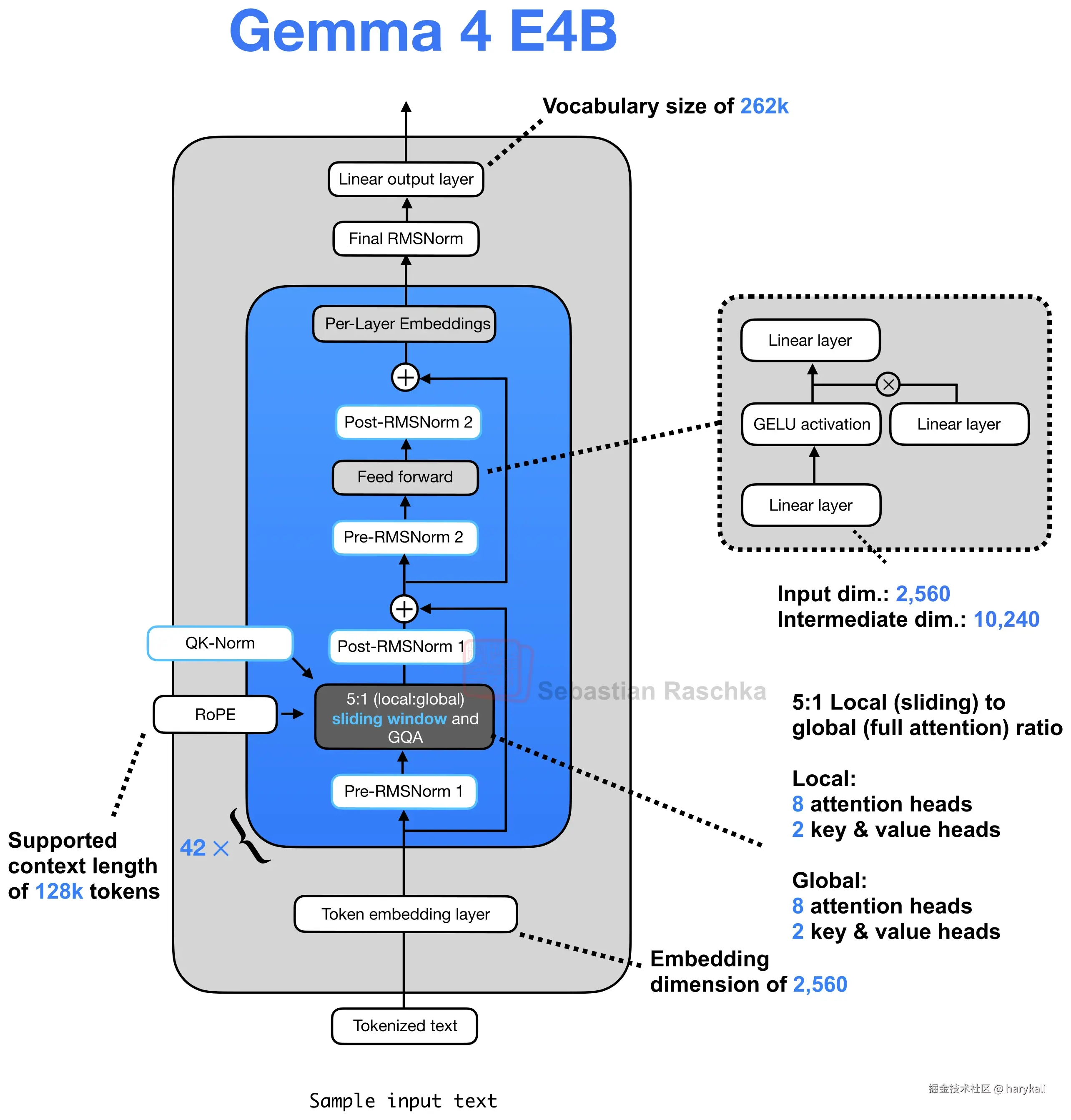
大约可以分为这么几层
1. 输入层
- 文本向量化:原始文本经过分词后进入词嵌入层,在这里被转化为维度为 2560 的基础数据向量,作为大模型计算的起点。
2. 核心解码器层
这是模型的主体结构,一共循环堆叠了 42 次。每一个完整的解码器层内部,数据都需要依次穿过两个核心处理区: 这里我们把处理区分层两层来看会好些
2.1第一处理区:注意力机制
- 前置处理:数据首先经过一次归一化层,平滑数值以稳定计算。
- 混合注意力运算:随后进入注意力计算核心。该模块巧妙地将局部滑动窗口注意力和全局全注意力结合在一起,两者的分布比例为 5 比 1。
- 多头配置:不论是局部还是全局注意力层,都采用了分组查询设计,统一配备 8 个查询头和 2 个键值头。
- 长文本强化:在注意力计算过程中,系统引入了旋转位置编码和特定的注意力归一化技术,专门用来确保超长文本下的注意力分配不会崩溃。
- 后置处理与残差:计算完成后,数据再次经过一次归一化层,然后与进入本区前的原始数据进行相加融合,完成第一阶段的特征提取。
2.2第二处理区:前馈网络与专属嵌入
第二处理区:前馈网络与专属嵌入
- 前置处理:第一区输出的数据先经过一次新的归一化层。
- 前馈网络运算:数据进入前馈网络。在这里,原本 2560 维的数据会被映射放大到 10240 维。该网络采用了主流的双路门控设计,一路通过 GELU 激活函数处理,另一路保持线性计算,两路信号相乘后再经过一次线性变换输出。
- 后置处理:前馈网络输出后,紧跟一次归一化层。
- 残差融合:经过后置归一化的数据,会立刻与进入第二区前的数据进行相加融合。
- 逐层专属嵌入:完成残差相加后,汇流的数据最后会统一穿过一个专门的逐层嵌入模块,用来补充当前层独有的特征信号。以上这套完整的流程会循环 42 次。
3. 输出层
- 全局归一化:经过 42 层深度计算的最终数据,首先进行最后一次整体归一化处理。
- 概率输出:数据进入最后的线性输出层,将 2560 维的深层特征重新映射回 262k 的词表空间中,从而得出下一个可能生成的汉字或单词的概率分布。
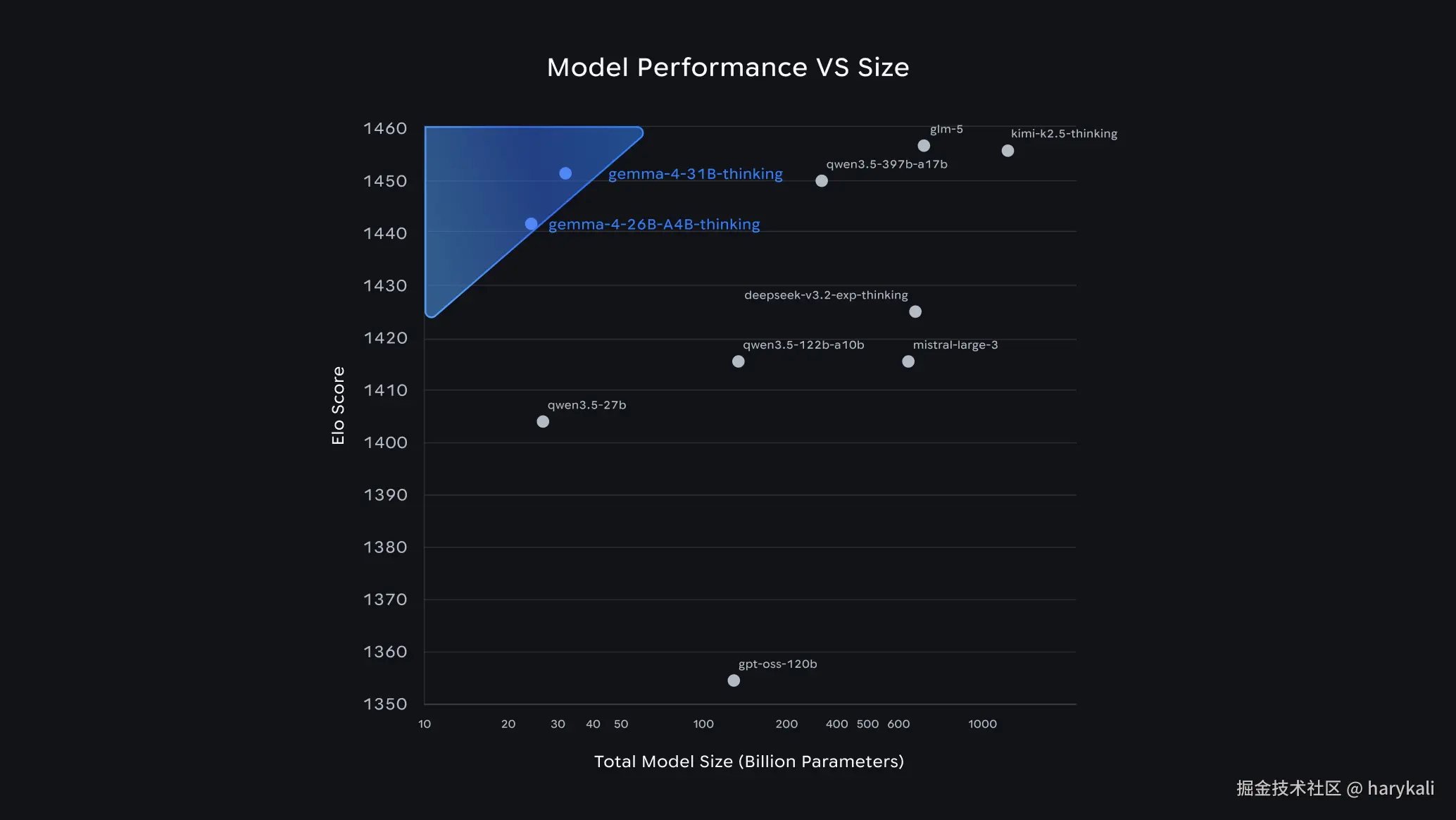
1.3 性能对比:
下图可以看出这一代的性能确实比起Gemma3有了较大的提升。
1.4 ROCm:
这次的实践环节中我们使用了ROCm,我们来看看官方是怎么定义这个平台的
AMD ROCm 是一个开放式软件栈,包含多种驱动程序、开发工具和 API,可为从底层内核到最终用户应用的 GPU 编程提供助力。ROCm 已针对生成式 AI 和 HPC 应用进行了优化,而且能够轻松将现有代码迁移到 ROCm 软件。
简单来说这个东西有点类似CUDA(但是是AMD家的)为PyTorch这些开发框架和主流模型在AMD显卡上运行提供性能支持
2. 动手实践环节
这次的实践环主要是依托Radeon Cloud这个平台来跑一跑Gemma4 E4B这个大模型,这里我们可以留意一下这个平台的amd显卡和ROCm
之后的事情就是经典的操作了,装环境然后下载模型,这里我们用老朋友魔搭下载Gemma 4 E4B这个模型
下载好了之后启动vLLM,看看我们的模型效果如何
这里如果没法正常启动的话可以试试看清理显存,或者限制一下最长上下文后再启动
bash
vllm serve ./models/google/gemma-4-E4B-it/ --served-model-name gemma-4-E4B-it --max-model-len 8192在评鉴Gemma4之前,先插播一下vLLM(LLVM)
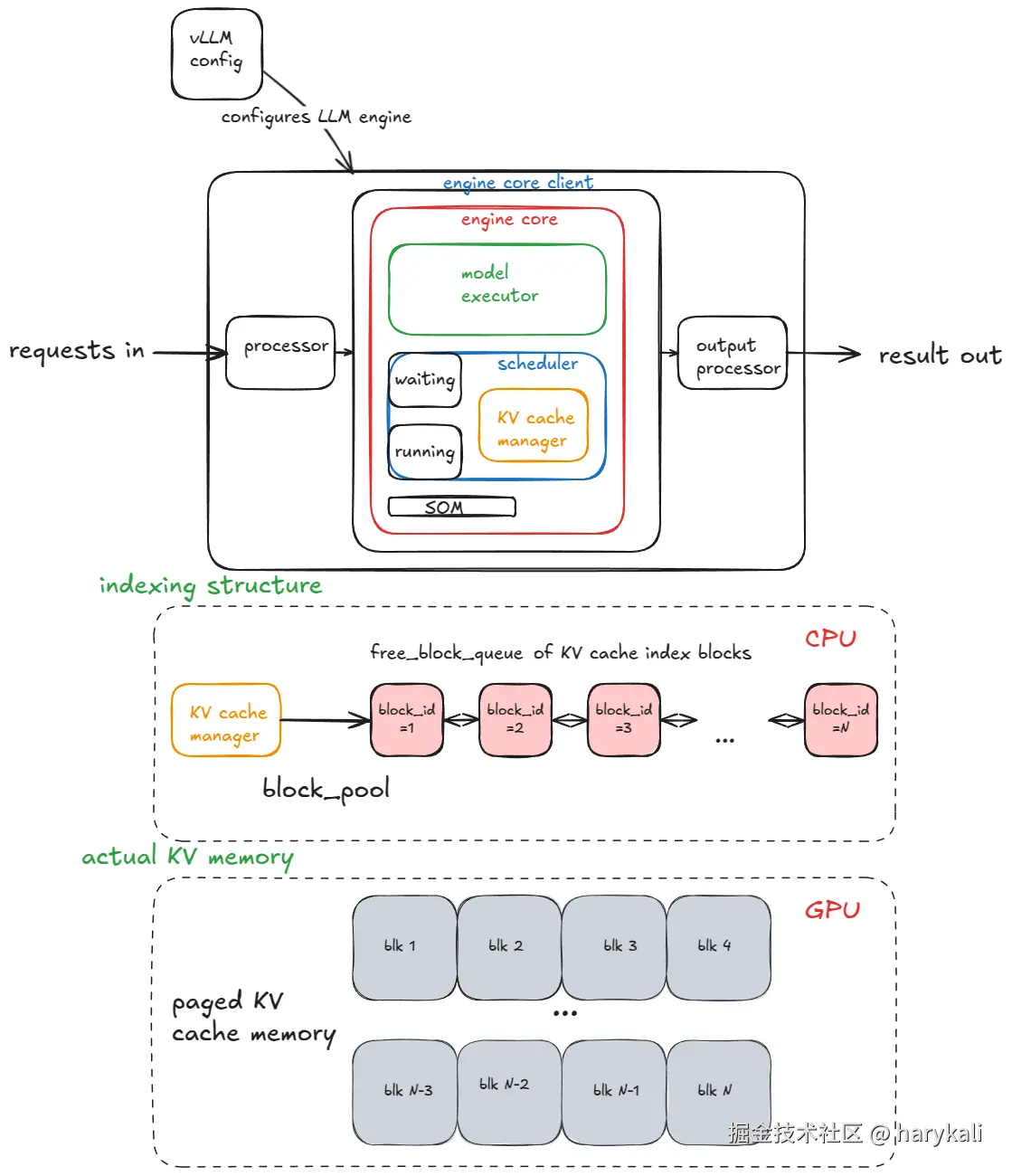
vLLM 类似给大模型找了一个调度员。在用vLLM之前,跑大模型就类似一个产能很低的厨师,一次只能给一个客人做菜,得等上一桌客人彻底吃完、收拾干净才能接下一单,类比到显卡,显卡大部分时间都在空转等待,vLLM 来了以后,它把显存资源(你当是胡萝卜)切成一个个萝卜块填满所有空隙,而且就像餐厅拼桌一样,只要有空位,它立马就能插入新任务,让显卡像流水线一样片刻不停地运转。简单来说,它通过严格管理资源和让任务无缝衔接,提高了显卡的效能
 ok,让我们来问问它可以做什么?
ok,让我们来问问它可以做什么?
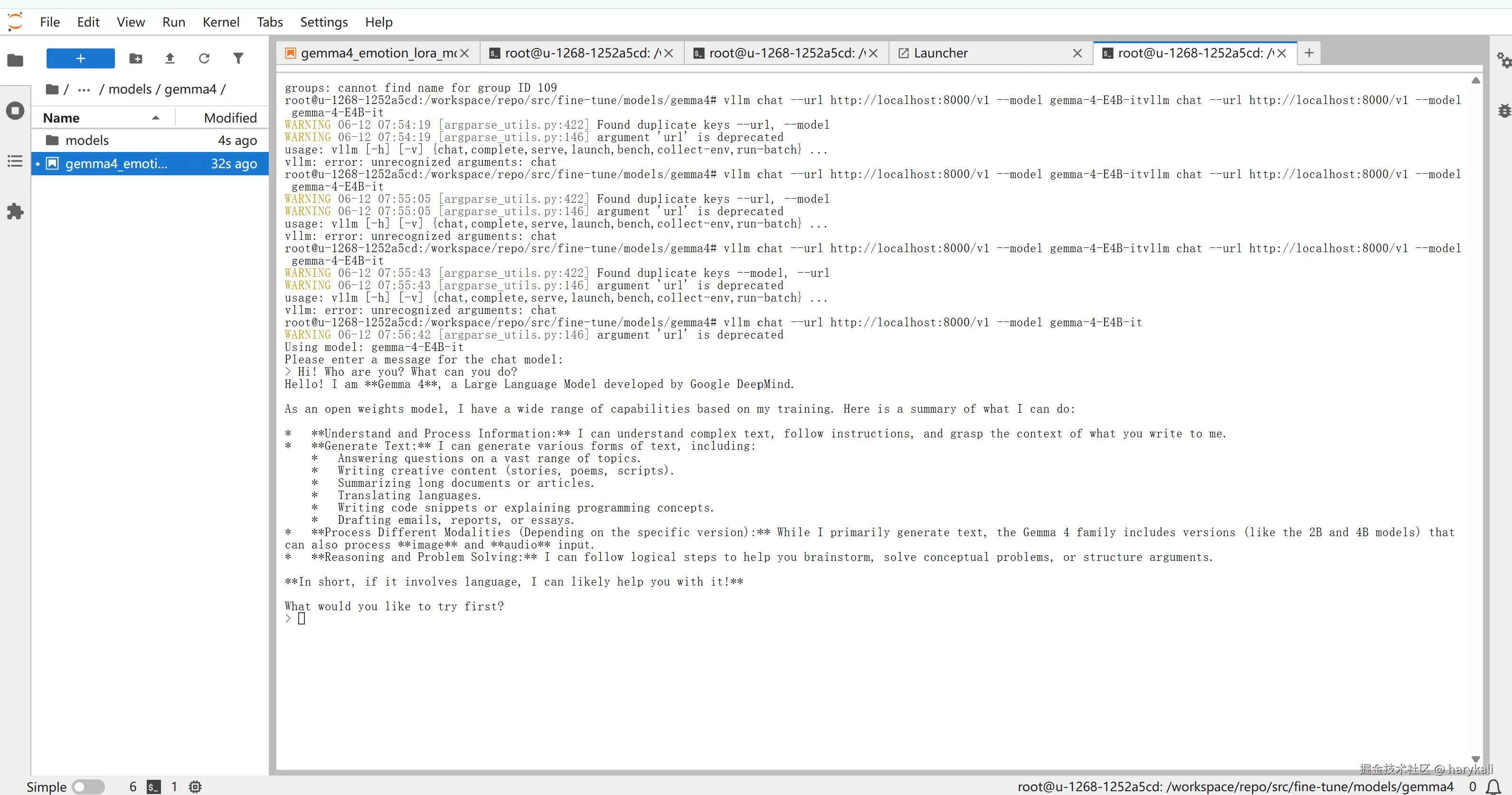
OK,回答的不错,看起来模型本身没啥问题了。