学习笔记:
主要关注,api-key,base-url,model-name
熟练使用LangChain4j框架进行大语言模型应用开发,熟悉@AiService注解与聊天模型配置;
掌握多LLM模型集成方案,通过工厂模式实现OpenAI、通义千问(Qwen)等模型的灵活切换;
熟悉AI聊天应用开发,了解聊天记忆(ChatMemory)机制与持久化存储方案;
环境准备
<!--前后端分离的测试工具-->
<knife4j.version>4.4.0</knife4j.version>
<!--前后端分离的测试工具-->
<dependency>
<groupId>com.github.xiaoymin</groupId>
<artifactId>knife4j-openapi3-jakarta-spring-boot-starter</artifactId>
<version>{knife4j.version}</version>
</dependency>
<!--引入SpringBoot依赖管理清单-->
<spring-boot.version>3.2.6</spring-boot.version>
<dependencyManagement>
<dependencies>
<!--引|入SpringBoot依赖管理清单-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-dependencies</artifactId>
<version>${spring-boot.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<!--基于open-ai的 langchain4j接口:ChatGPT、deepseek都是open-ai 标准下的大模型-->
<langchain4j.version>1.15.0</langchain4j.version>
(二选一)
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-open-ai</artifactId>
</dependency>
注意,这里如果引用错误会导致注入失效,无法创建bean
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-open-ai-spring-boot-starter</artifactId>
</dependency>
dependencyManagement>
<dependencies>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-bom</artifactId>
<version>${langchain4j.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
配置:application.yml
langchain4j:
open-ai:
chat-model:
api-key: demo
base-url: http://langchain4j.dev/demo/openai/v1
model-name: gpt-4o-mini
log-request: true
log-response: true
工厂模式集成多模态大模型
创建一个工厂LLMFactoy,
包含枚举项,接受枚举类型,选择调用大模型接口,返回接口类型
创建一个接口LLMService,一个方法use
创建实现类,openai实现类,qwen实现类
声明一个私有、不可变(final)的成员变量
构造器调用大模型,重写方法(传入prompt提示,返回回答)
等等
Aiservice智能代理
解决的问题:通过定义一个接口和几行注解,就能得到一个 "带持久化记忆、绑定指定模型、可直接调用" 的 AI 对话服务。
直接在这里面定义所需要解决问题的对话方法即可
<!-- langchain4j高级功能 -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-spring-boot-starter</artifactId>
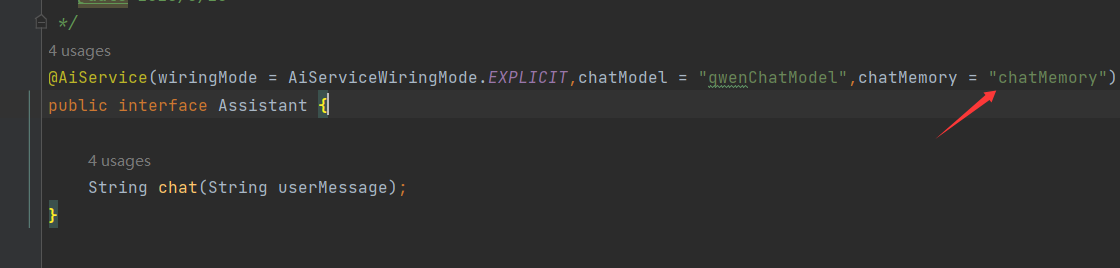
@AiService(
wiringMode = EXPLICIT ,
chatModel = "qwenChatModel",
chatMemoryProvider = "chatMemoryMySqlProvider"
)
public interface Assistant {
String chat(String userMessage);
}
- wiringMode = EXPLICIT 手动指定要用哪个 Bean,解决多模型冲突问题。
- chatModel = "qwenChatModel" 指定AI 模型(比如通义千问)。
- chatMemoryProvider = "..." 指定对话记忆存储器(这里是存在 MySQL 里)。
聊天记忆(优化构建过程)
过程纲要:
从导入大模型,然后遇到问题,每次对话都是新的对话,然后去了解如何存储聊天记忆。
聊天记忆ChatMemorye(存储的会话是存在内存中的)
测试大模型有没有记忆功能
聊天记忆的简单实现
使用ChatMemory实现聊天记忆
通过AlService实现聊天记忆
ChatMemory高阶功能:
方法1:
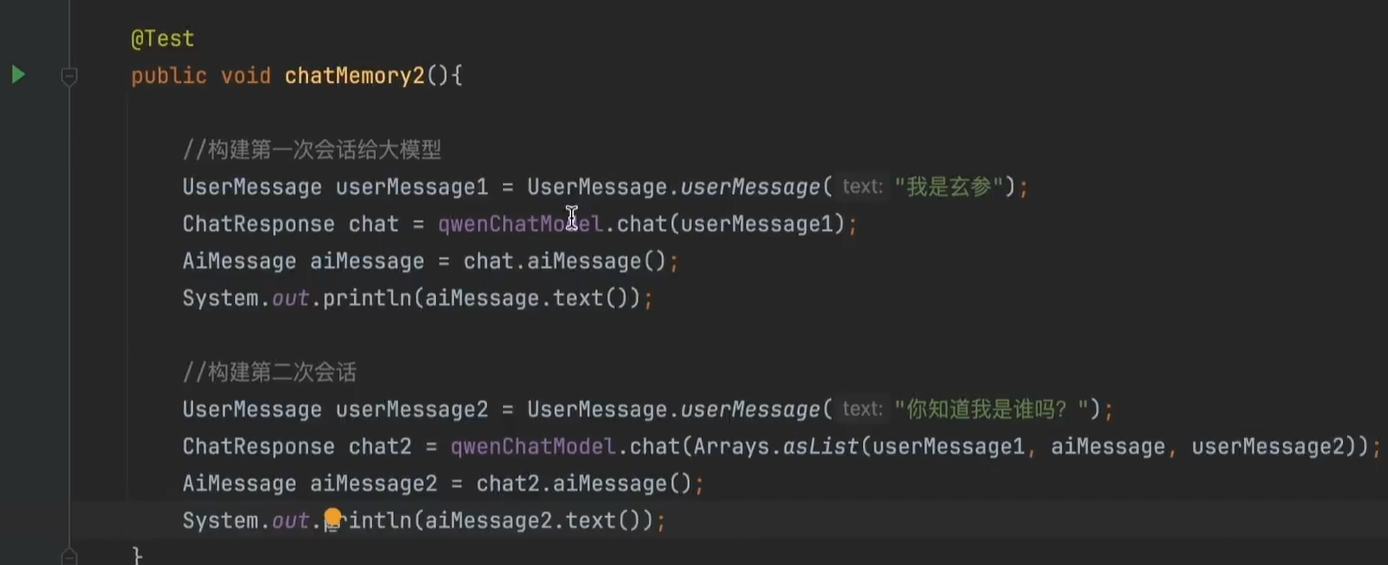
收集
userMessage:用户给的信息
aiMessage:AI返回的信息
应用
第二次会话把第一次会话的信息全部给到第二次会话。
方法2:
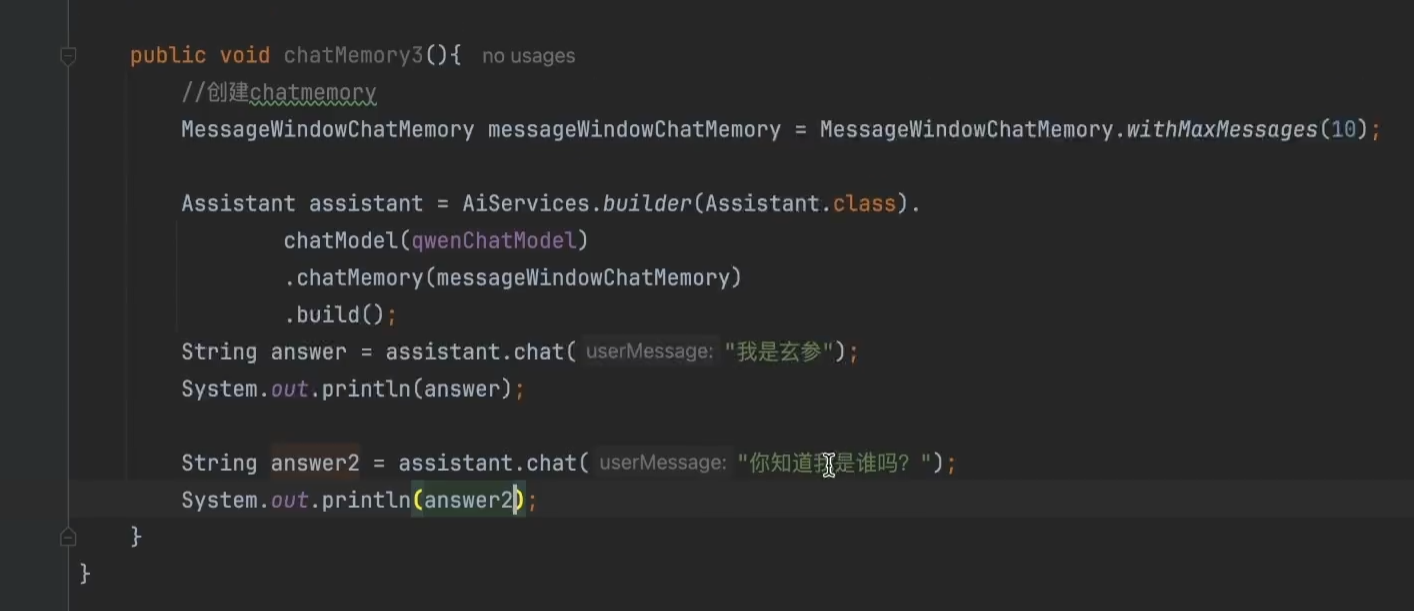
通过AIservice智能代理
关键在于创建 MessageWindowChatMemory 存储会话
优化(简化了代码,使得代码更加清晰)
通过注解@AiService实现管理
构建一个config组件
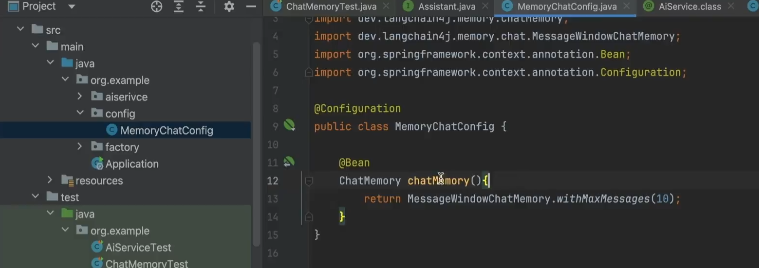
这里使用的方法就是上面组件构建的
然后测试成功
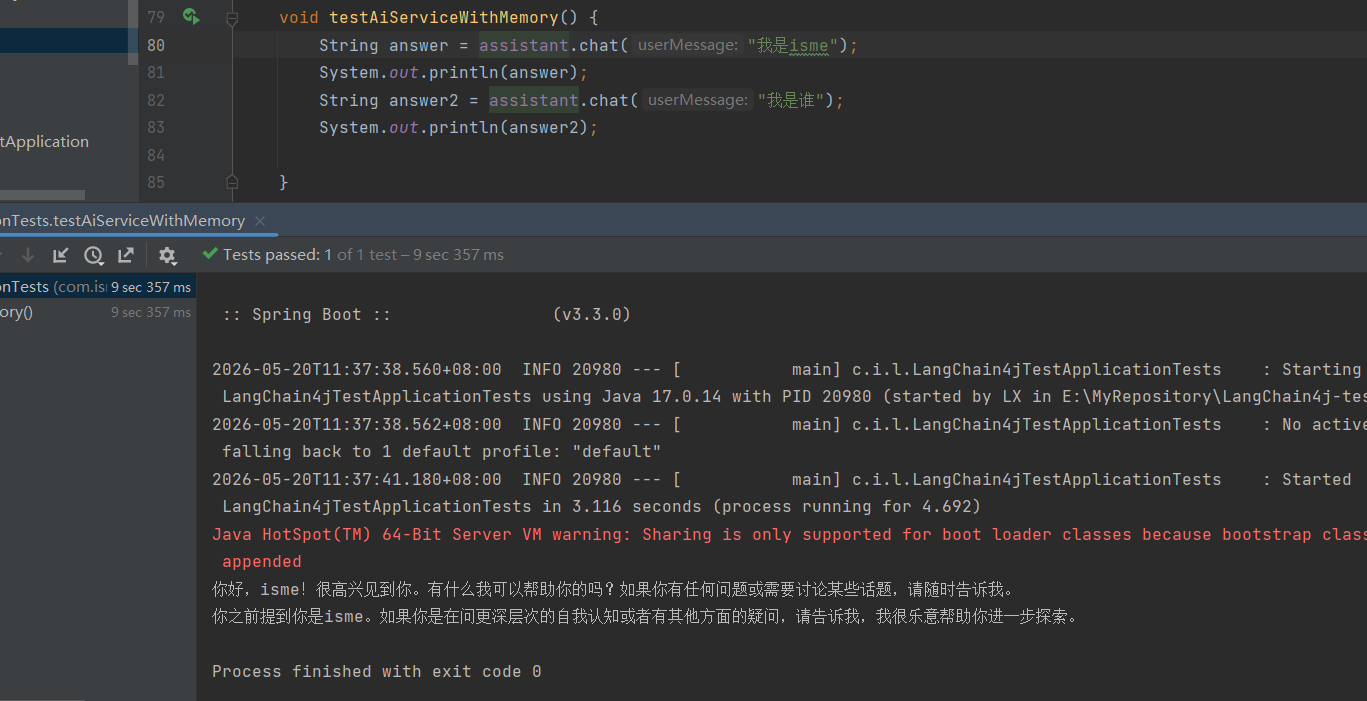
会话隔离机制(对于不同的会话,进行存储)
主要就是通过MessageWindowChatMemory (消息窗口对话记忆)专门用来控制对话上下文长度的核心组件,来实现
可以决定是否存在在内存还是数据库中。
1.把chatMemory改成chatMemoryProvider
chat方法加入@MemoryId(用于标识对话的id),@UserMessage标识参数
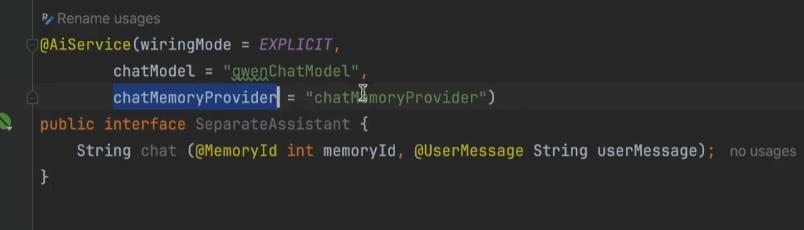
2.创建SeparateAssistantConfig类,定义chatMemoryProvider方法,保证调用大模型时给大模型打上编号。
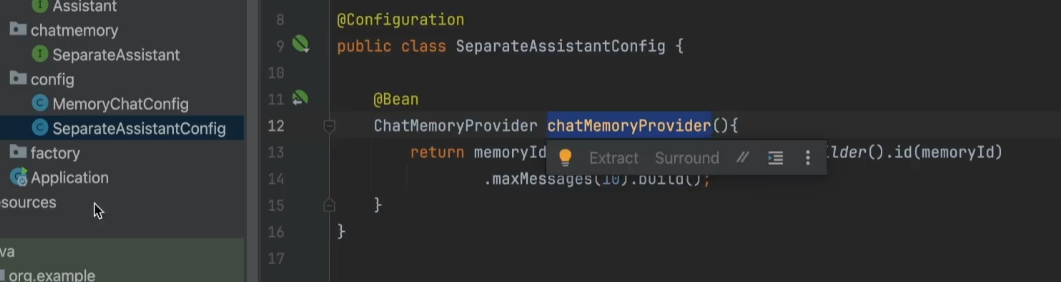
测试
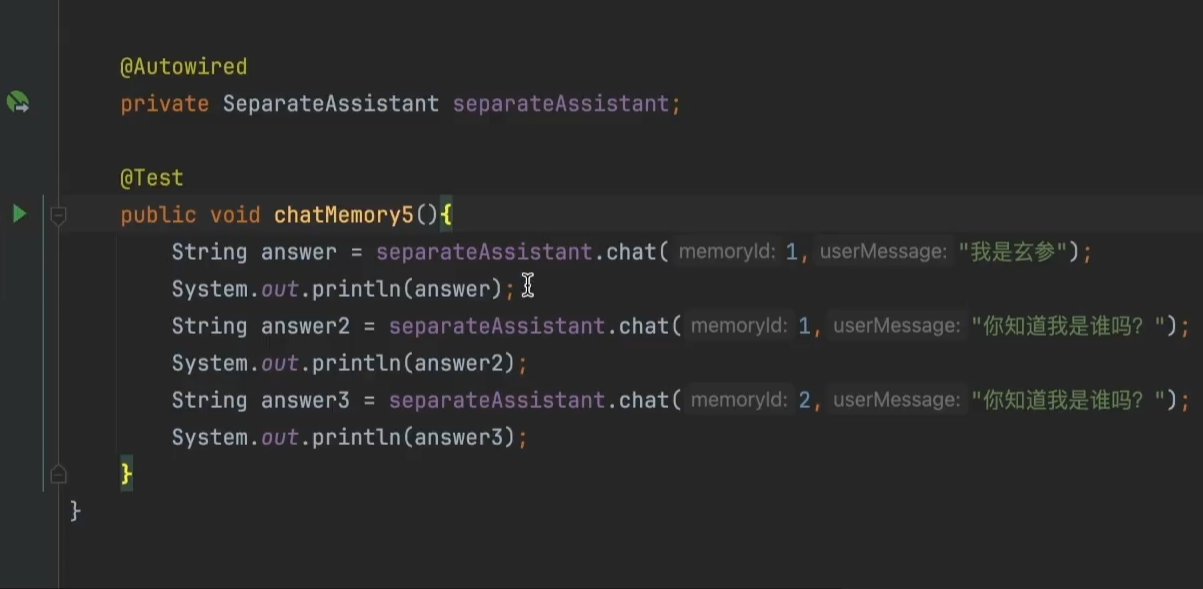
前面那些会话都是存在内存里的,是十分有问题的,那么如何把他们存到数据库里面呢
1、首先导入相关依赖
<!-- MySQL 驱动(新版推荐) -->
<dependency>
<groupId>com.mysql</groupId>
<artifactId>mysql-connector-j</artifactId>
<version>8.0.33</version>
<scope>runtime</scope>
</dependency>
<!-- Hutool 工具包 -->
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.8.30</version>
</dependency>
</dependencies>
2、配置数据库
hutool的数据库要在db.setting里面配置
3、数据库建表
CREATE TABLE chat_msg(
id INT PRIMARY KEY AUTO_INCREMENT COMMENT '主键ID',
uid INT NOT NULL COMMENT '用户ID',
message VARCHAR(2048) NOT NULL COMMENT '聊天消息内容',
create_time DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
update_time DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
INDEX idx_uid (uid) COMMENT '用户ID索引,便于按用户查询聊天记录'
) COMMENT = '聊天记录表';
4、自定义ChatMessageStore实现,
ChatMemoryStore 就是专门用来「持久保存对话历史」的地方。
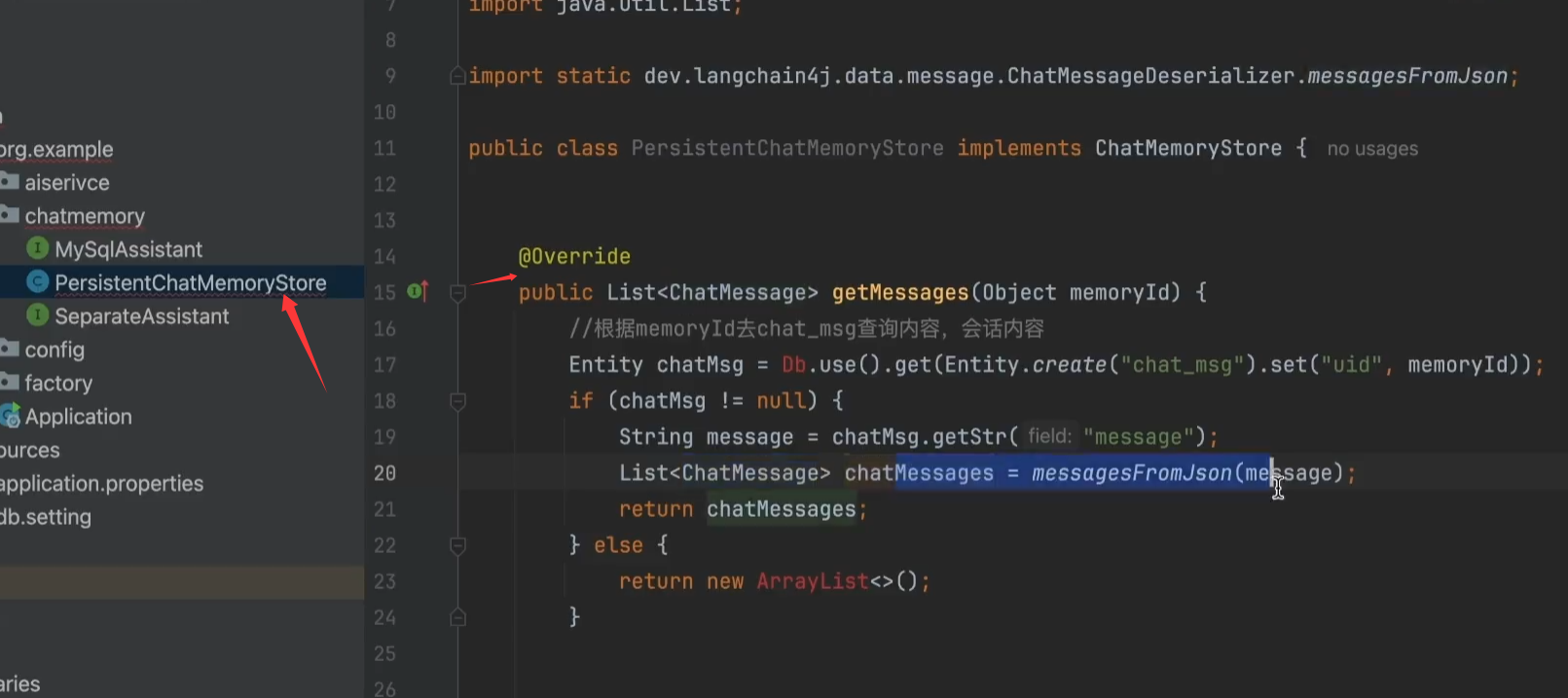
核心方法:
getMessages(Object memoryId)
updateMessages(Object memoryId, List<ChatMessage> messages)
deleteMessage(Object memoryId)
简单来讲:
- 实现 ChatMemoryStore 接口 :自定义PersistentChatMemoryStore 处理数据库读写,使用Hutool的 Db 工具类简化JDBC操作
- 依赖注入 :通过Spring的 @Bean 和 @Component 管理组件
- 框架集成 :LangChain4j的 @AiService 自动调用 ChatMemoryProvider
- 序列化机制 :使用LangChain4j自带的序列化工具处理消息
格式序列化 : messagesToJson(messages) 将消息列表转为JSON字符串
反序列化 : messagesFromJson(json) 将JSON字符串转回消息列表
5、自定义ChatMemoryProvider注册
ChatMemoryProvider 是一个 工厂接口 ,用于为每个会话(memoryId)创建独立的 ChatMemory 实例。
它就像一个"聊天记忆生成器",为每个用户创建专属的聊天记忆空间。
LangChain4j 默认提供的是 内存存储 ( InMemoryChatMemoryStore ),但你可能需要:
- 持久化存储 :将聊天记录保存到 MySQL、Redis 等
- 自定义策略 :控制保留多少条消息、如何组织消息等
- 多租户隔离 :不同用户的数据独立存储
定义SeparateMySqlAssistant 的AI助手入口
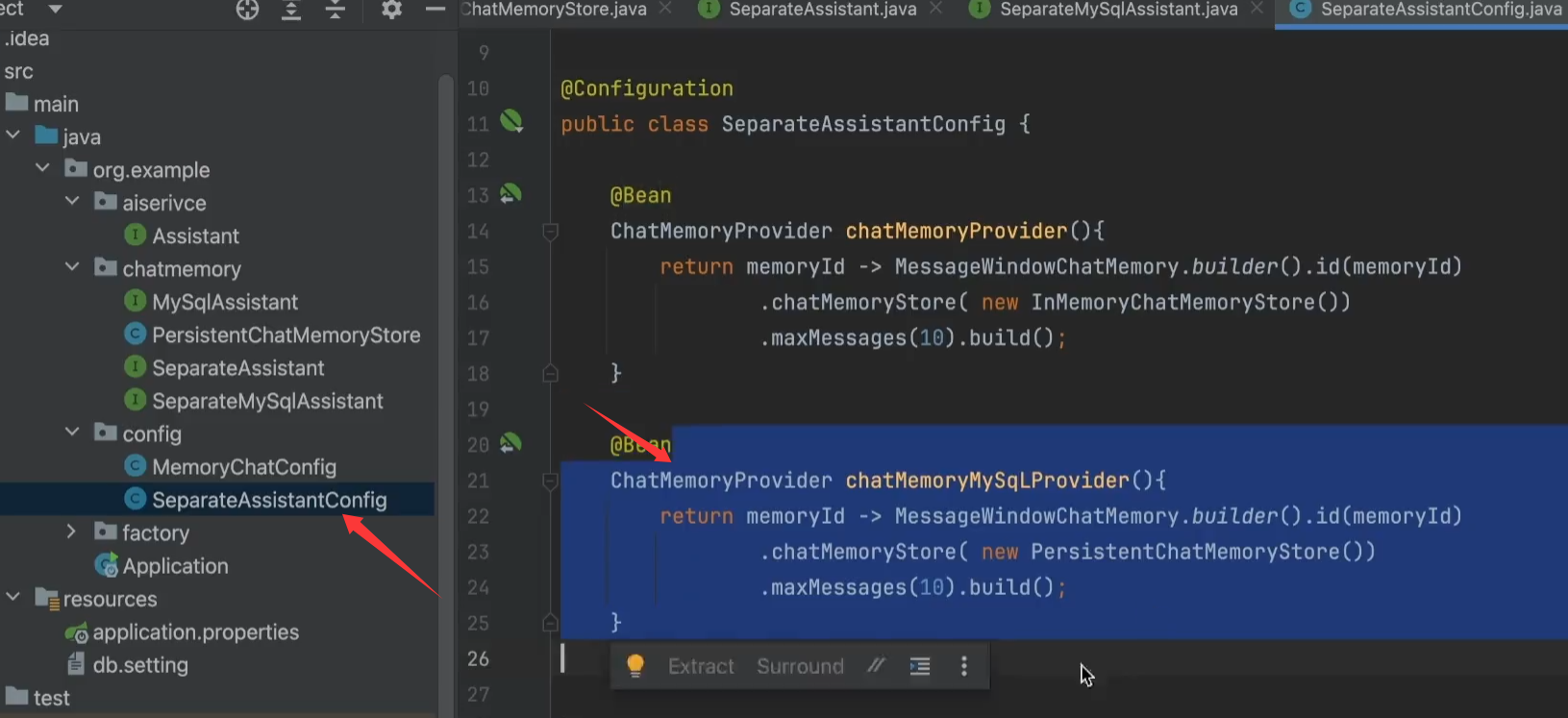
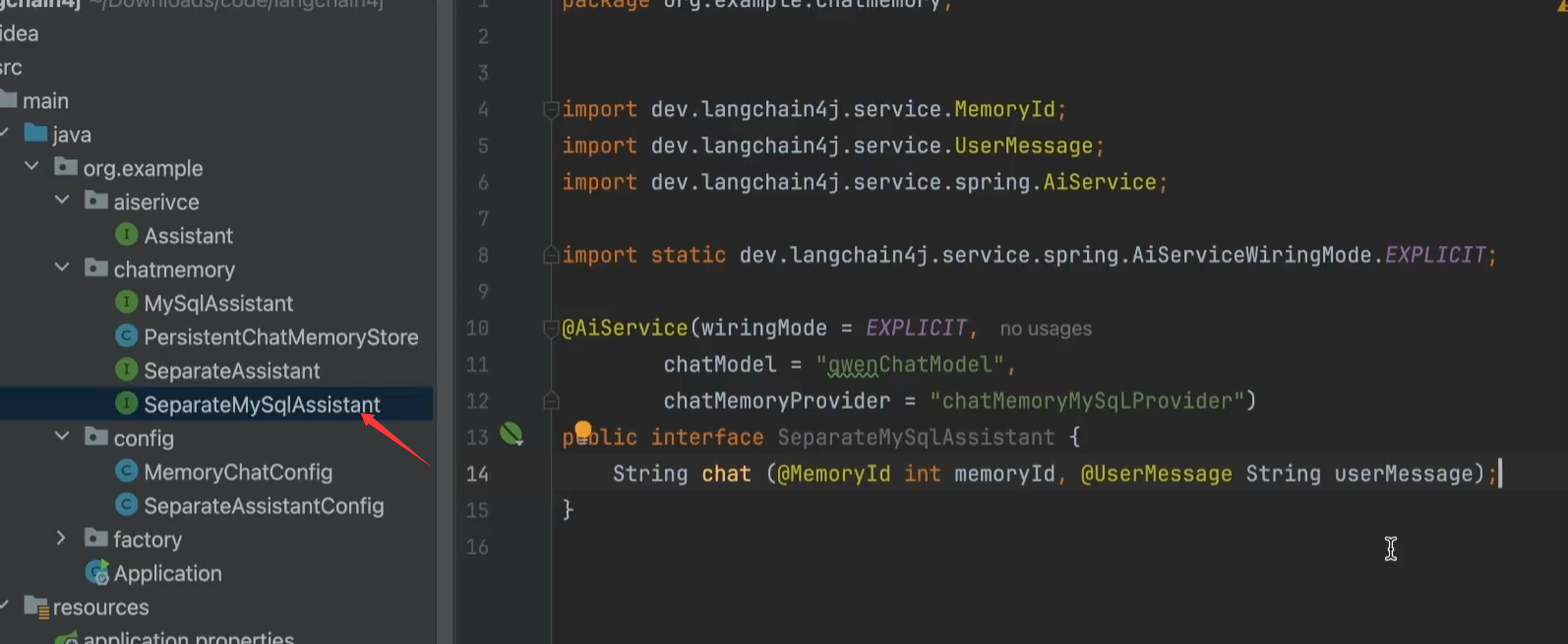
6、SeparateAssistantConfig(配置类)
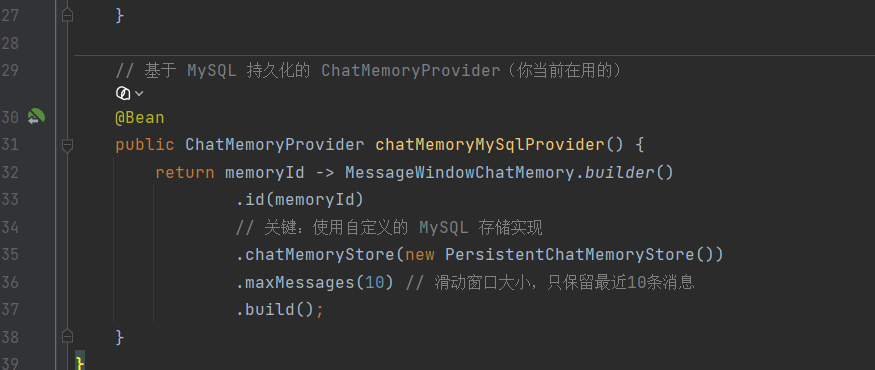
基于 MySQL 持久化的 ChatMemoryProvider
提示词prompt
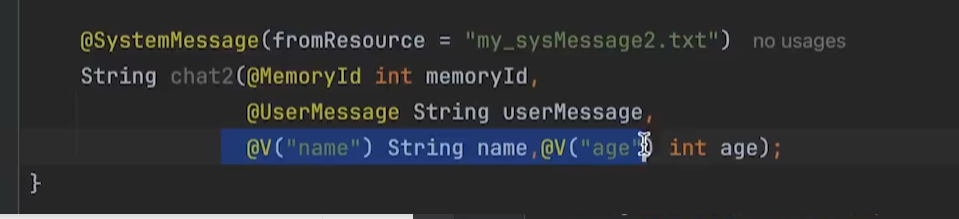
核心三大注解
- @UserMessage → 给 AI 看的提问模板
- @V("xxx") → 把你代码 / 数据库里的数据,填进模板的 xxx 位置
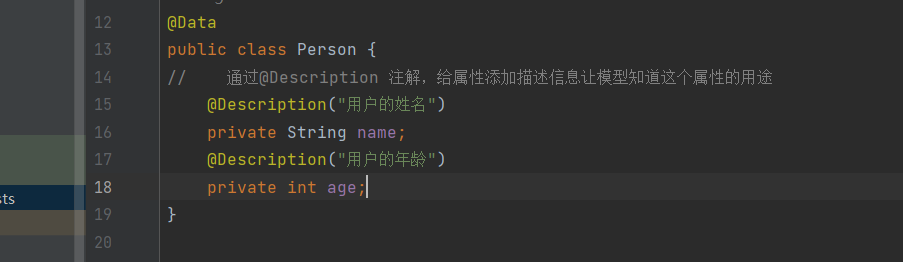
- @Description → 告诉 AI 这个字段存什么、是什么意思
注解总结
- @UserMessage → 给 AI 看的提问模板
- @V("xxx") → 把你代码 / 数据库里的数据,填进模板的 xxx 位置
- @Description → 告诉 AI 这个字段存什么、是什么意思
- @P = 给 AI 看的参数说明
- @SystemMessage 是给 AI 的 "宪法",定全局规则
方法1
@SystemMessage 是给 AI 的 "宪法",定全局规则
@UserMessage是给用户的 "指令",定单次任务,会用户跟大模型每次会话的时候加角色的限制

问题1:
但是如果更改了系统提示词之后,ai记忆会出现错误,导致不记得前面的对话了。
问提2:如果没有提示大模型是不知道日期的
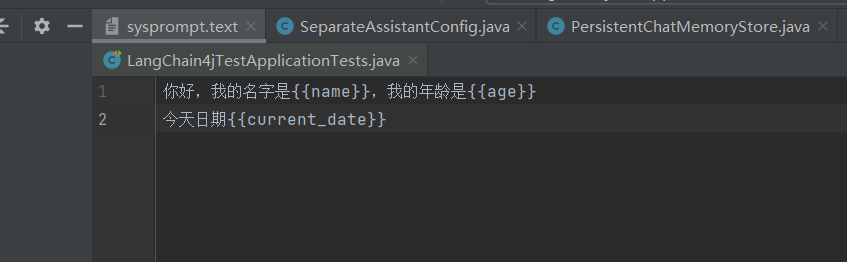
通过添加提示词{{current_date}}可以实现

通过模版文件去实现系统提示词的实现
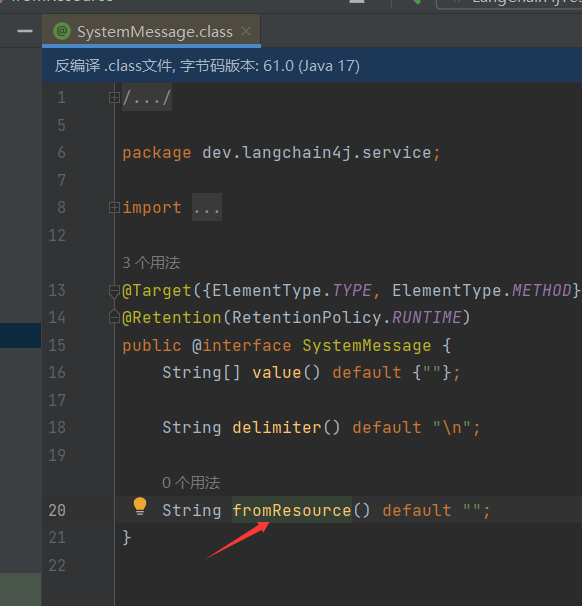
注解SystemMessage里有个方法fromResource

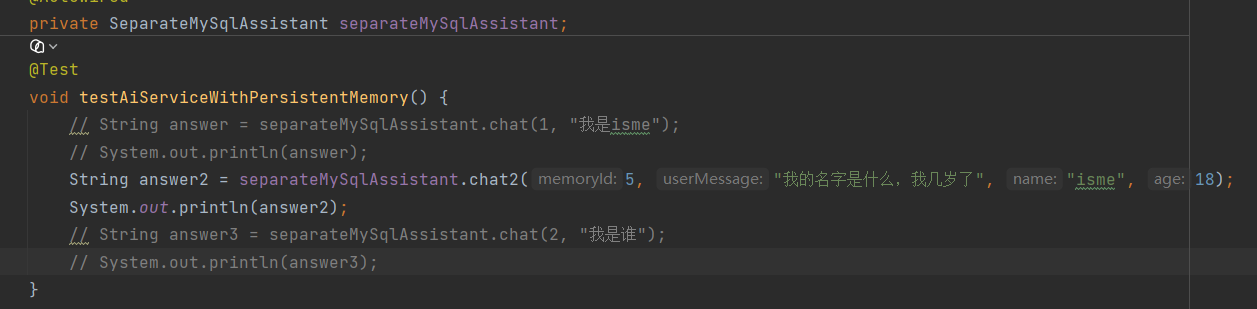
通过用户在数据库中的已有信息实现对用户问题的精确回答
通过读取数据库中用户相关信息已实现回复的精确。
提取用户对话中的的相关信息并返回
1、对话中的数字
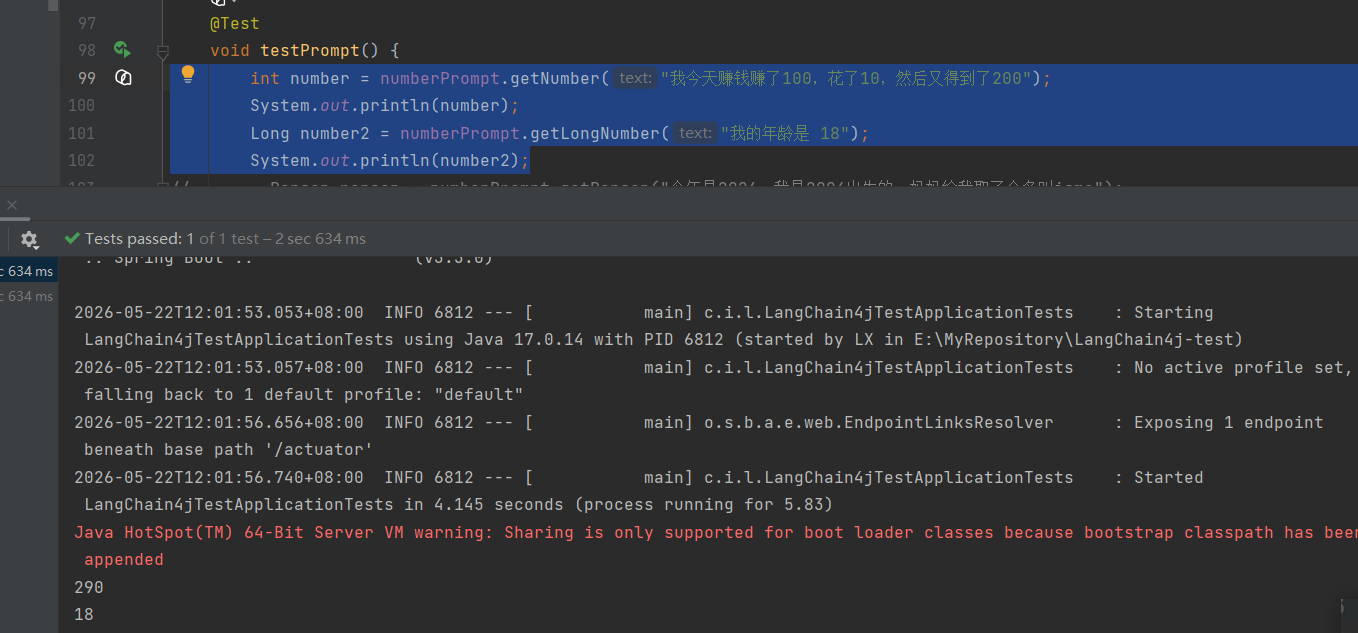
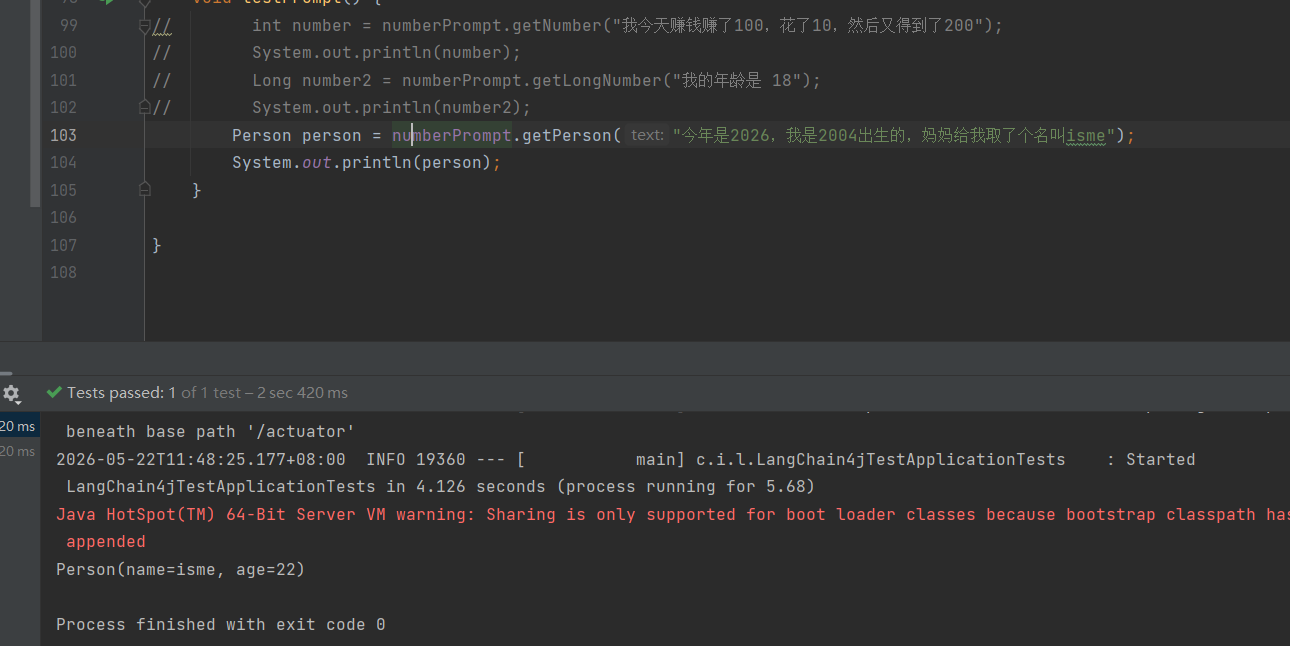
2、返回对象的数据
通过对话提取所要返回的对象数据的相关信息
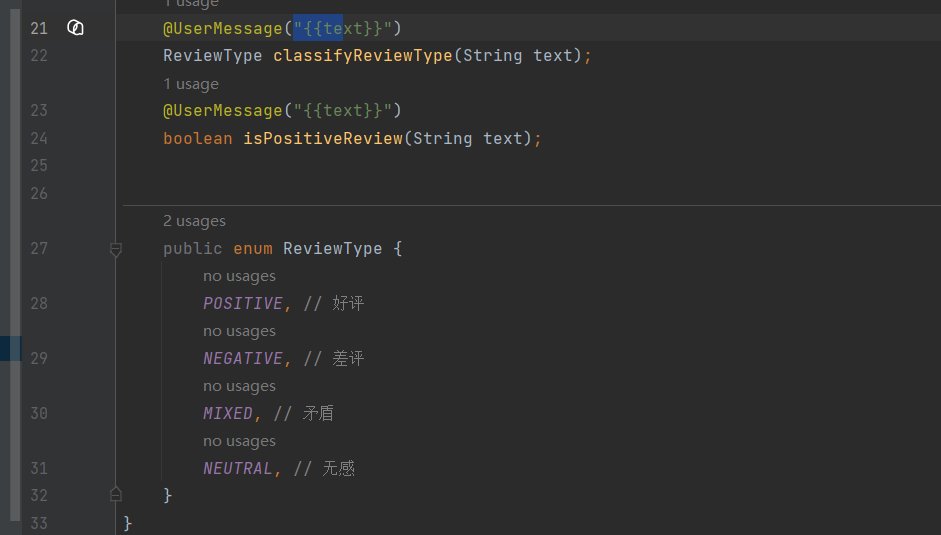
3、自定义枚举类
通过对话判断是什么枚举类
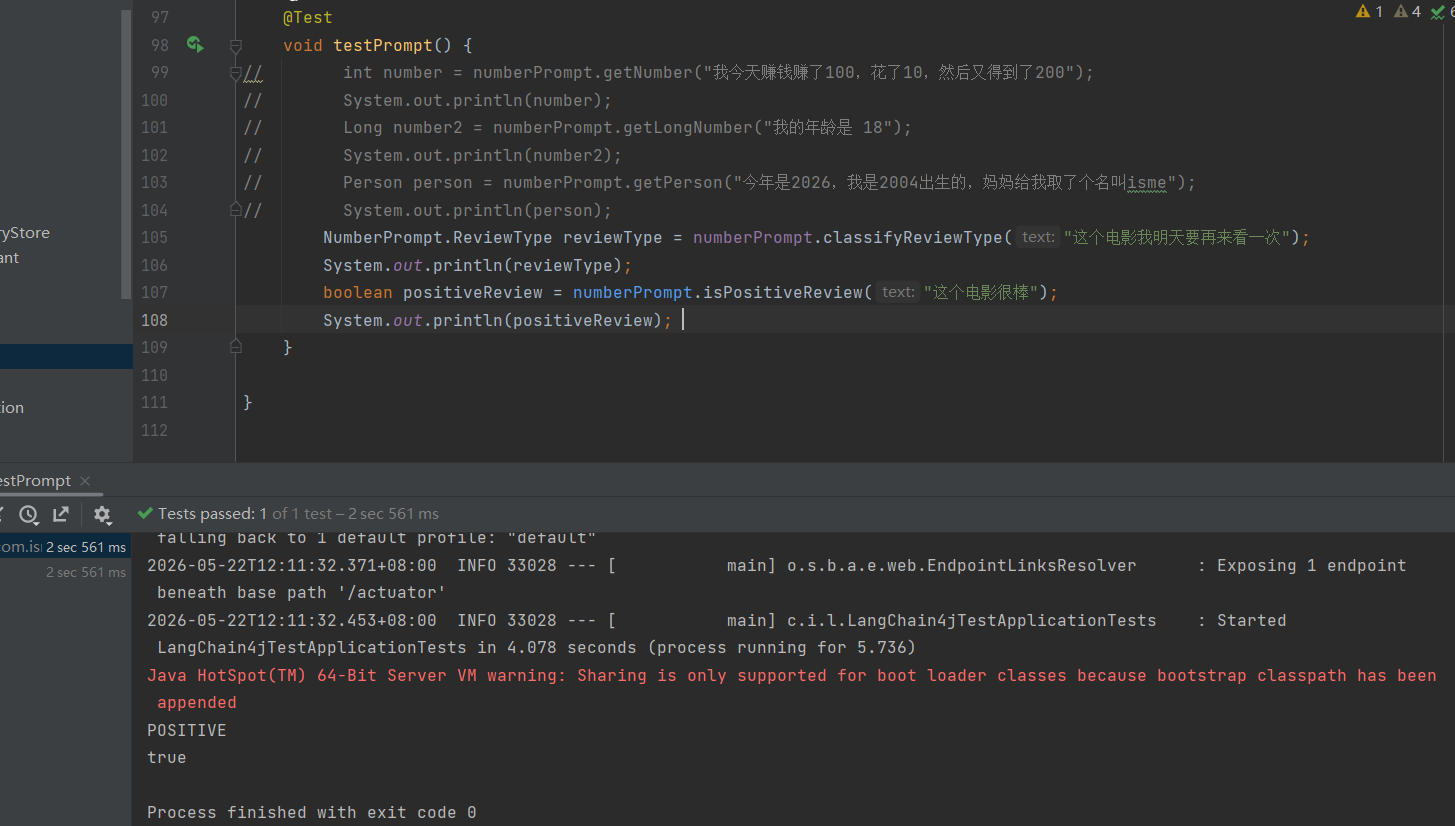
案例1:基于提示词构建一个专业的法律咨询助手
1、创建相关的aiservice代理
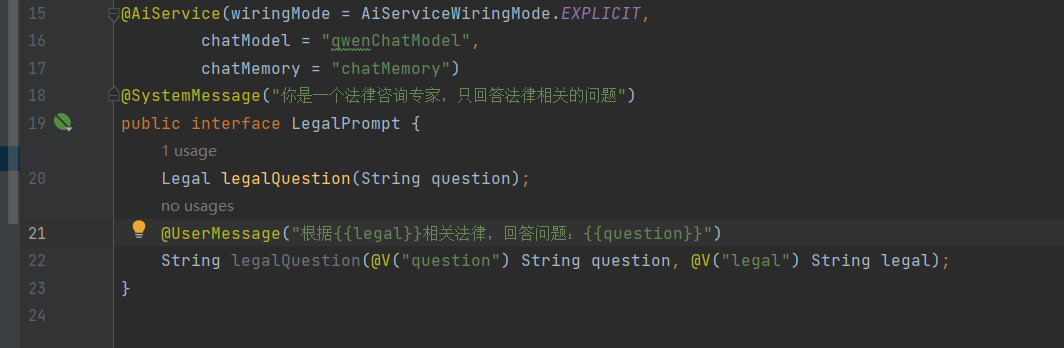
@UserMessage("根据{{legal}}相关法律,回答问题:{{question}}")
这是用户提示词模板注解,作用是:
定义大模型收到的用户消息的固定格式
{{变量名}} 是占位符,会被方法参数动态替换
模板的内容,就是用户发给大模型的 "指令"
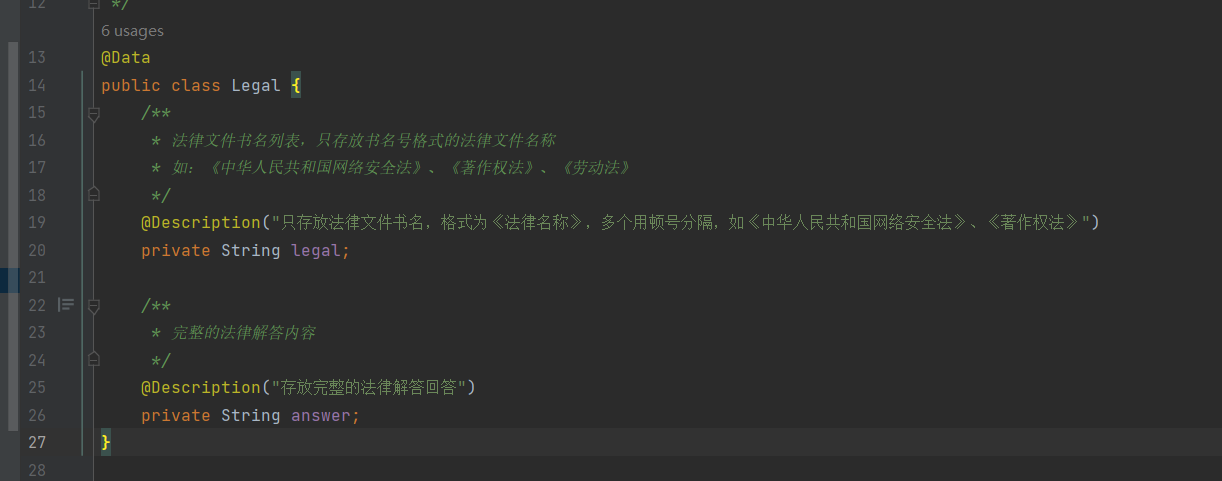
2、创建实体类决定要存储的信息
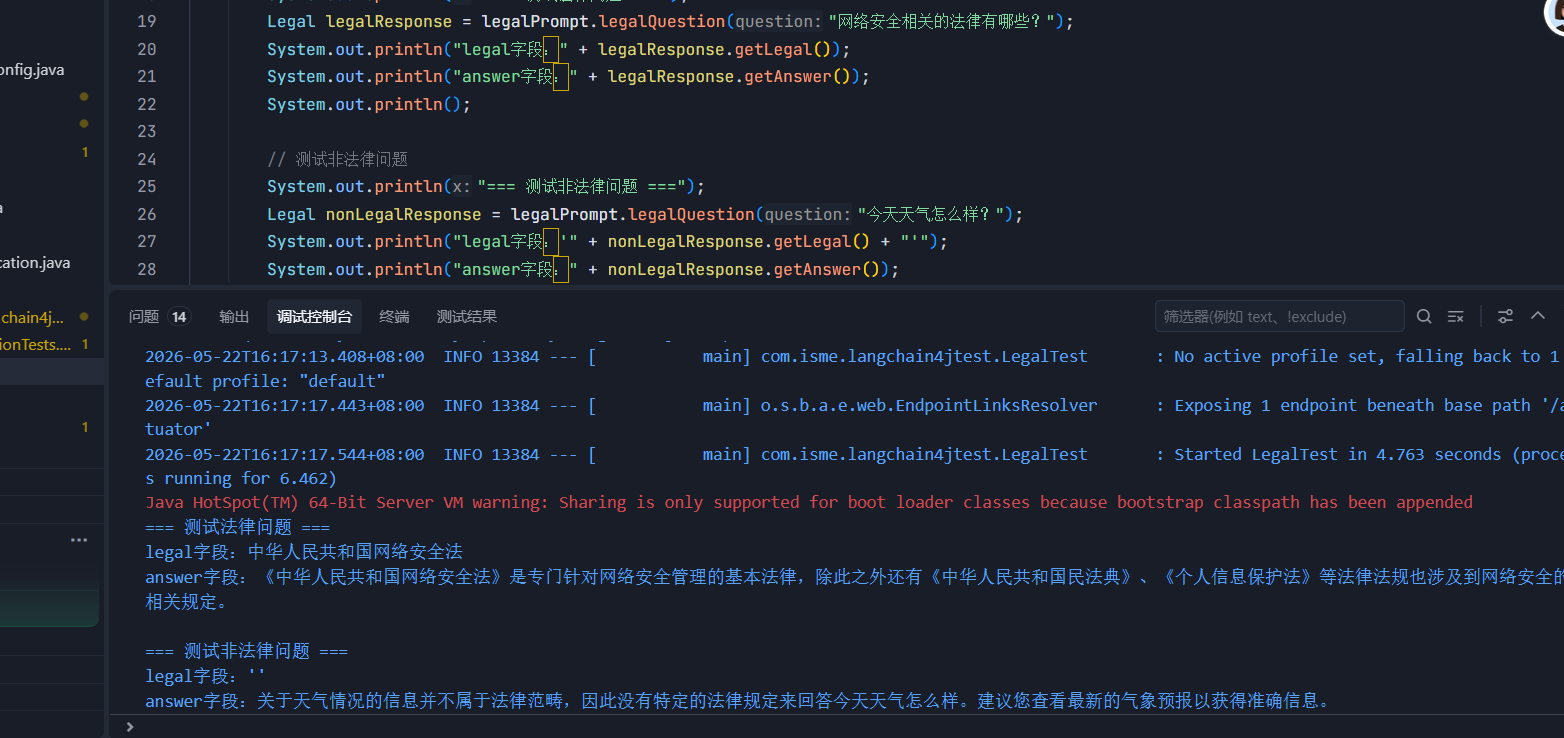
Tool外部能力集成
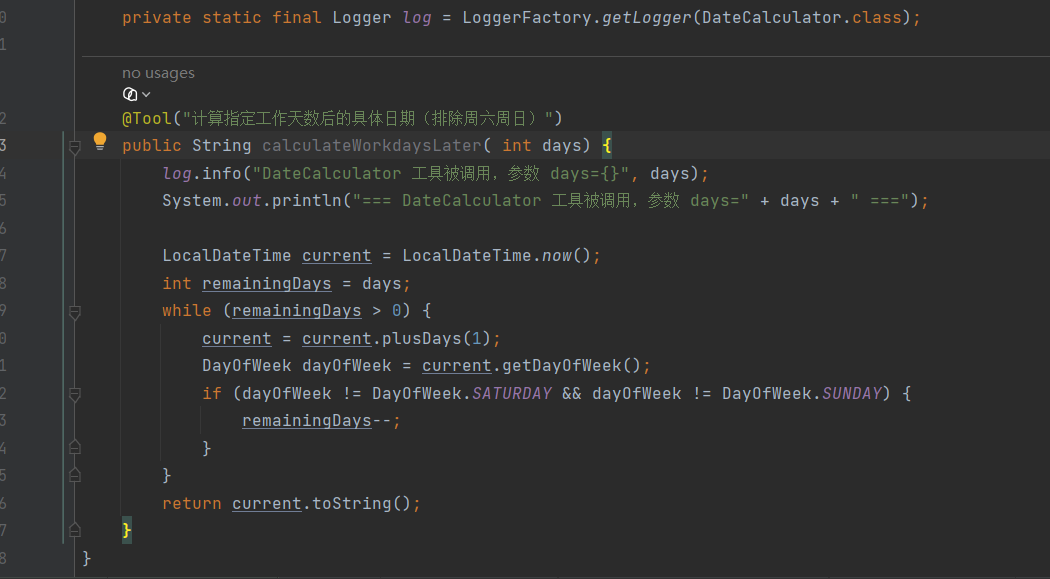
解决的问题:当面对一些因为大模型本身缺陷,计算能力不足时,可以使用此方式辅助大模型计算并输出
构建一个计算类,标注@Tool,可以在标注后给定一些描述如(计算两个整数的和,返回它们的加法结果),效果更好
优化:有时候大模型并能够完全理解工具方法的意思
则需要输入的参数也进行提示标注,以助大模型更好的理解
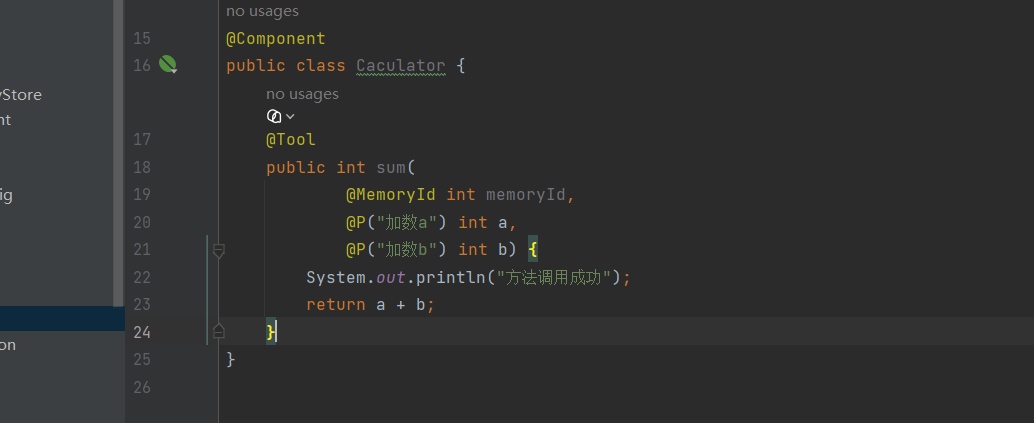
创建相关aiservice,实现计算类调用
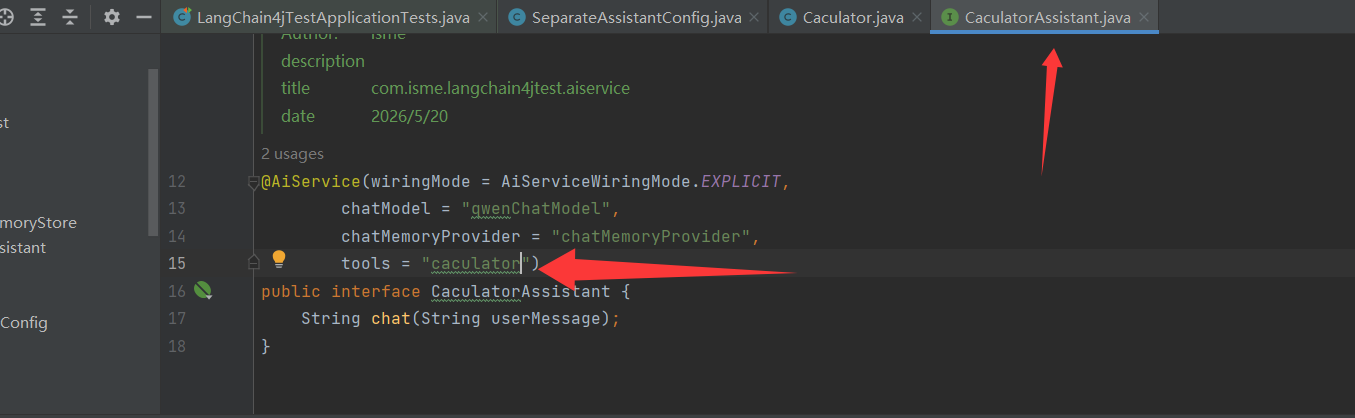
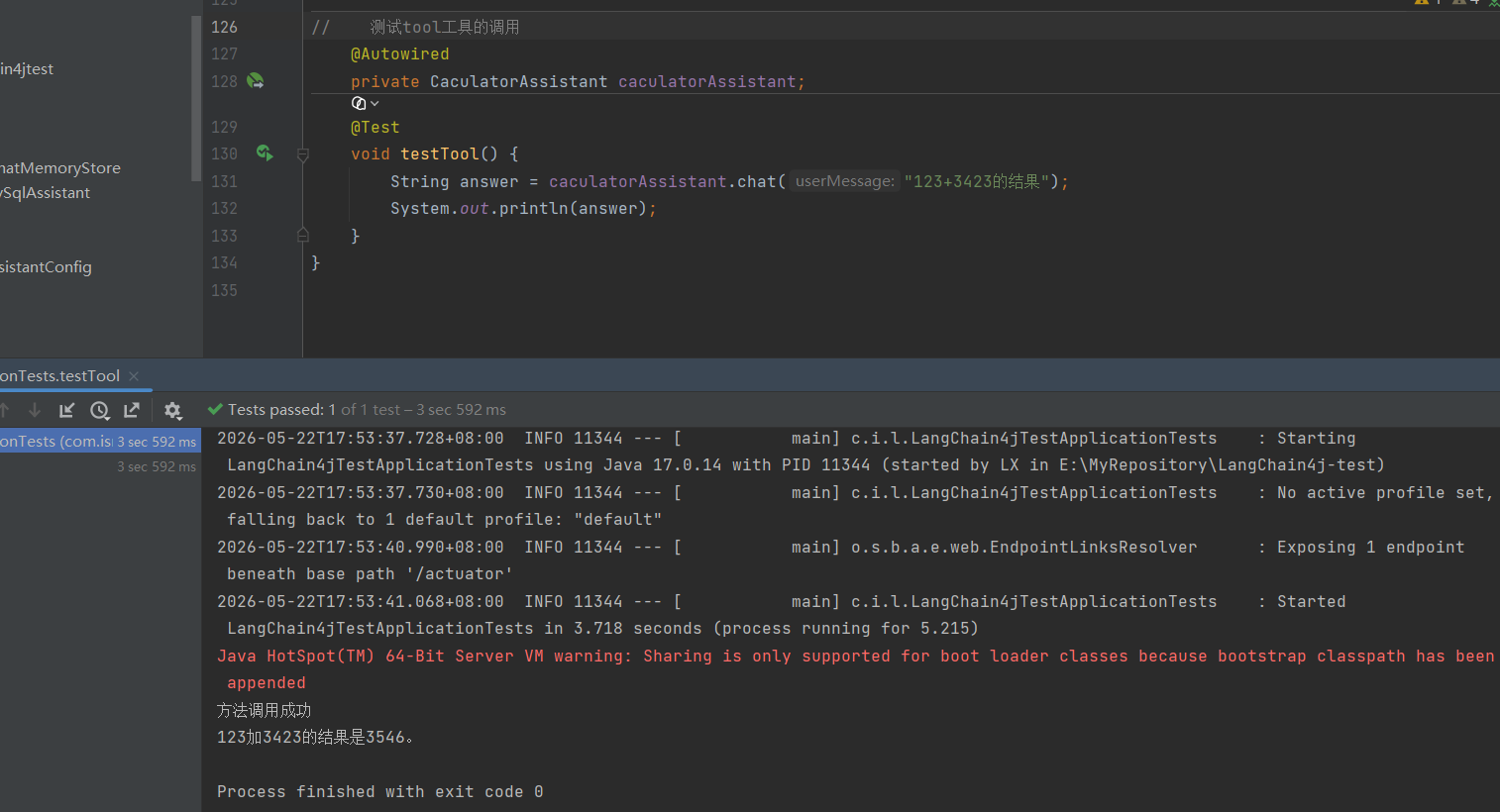
案例2:基于提示词+函数调用实现+聊天记忆实现电商平台智能助手
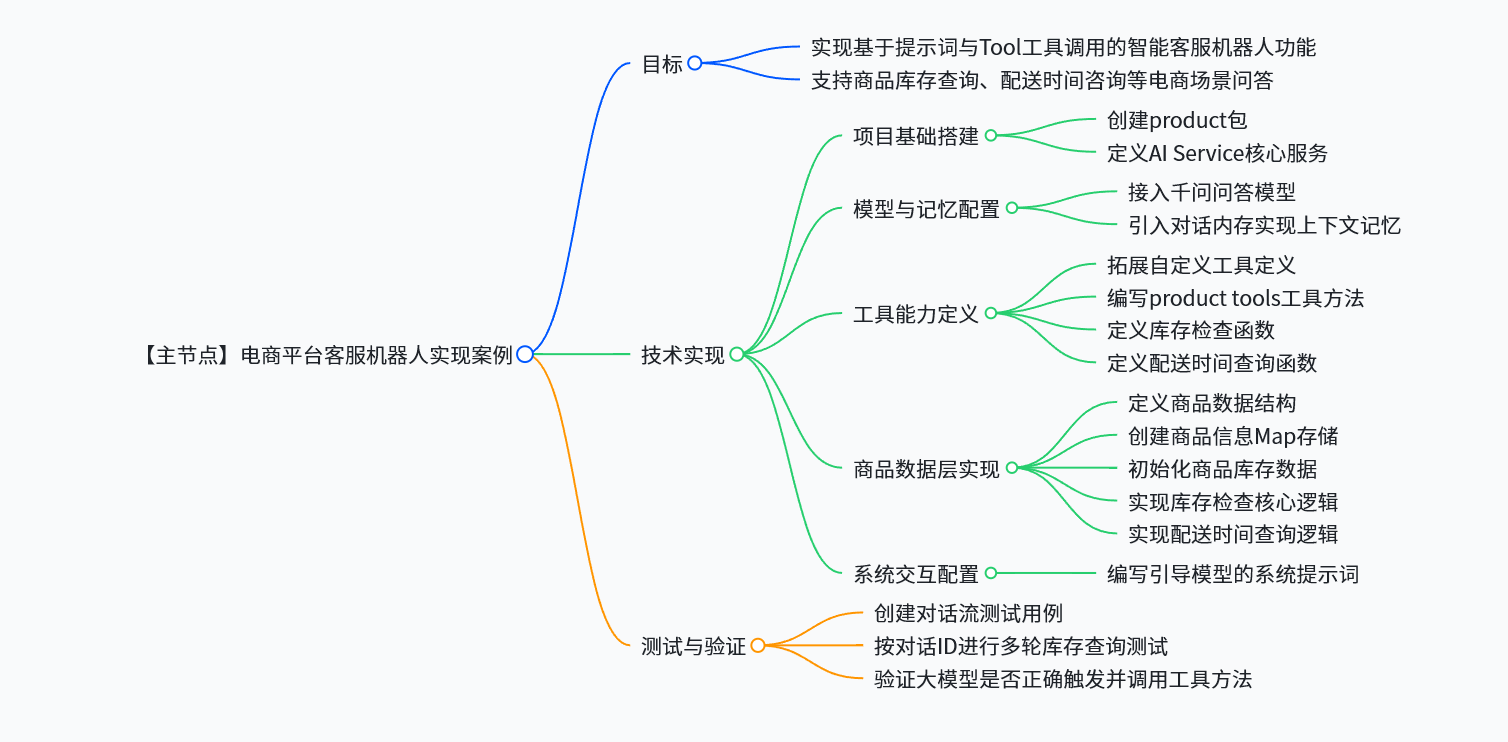
技术要点:
- 工具链设计 :实现商品库存查询、配送时间计算等自定义 Tool,通过
@Tool注解封装业务逻辑,让大模型具备结构化数据查询能力; - 对话记忆优化:引入对话内存模块,维护用户上下文状态,支持多轮对话中历史意图的关联理解;
- 提示词工程:设计场景化系统提示词,引导模型精准识别电商业务意图,按规范格式生成工具调用请求,降低误调用率;
- 业务闭环实现:构建从用户提问→意图识别→工具调用→结果返回的完整对话流程,解决了传统客服无法处理复杂业务查询的痛点,提升用户咨询体验。
RAG检索增强生成
( Retrieval-Augmented Generation )
索引:
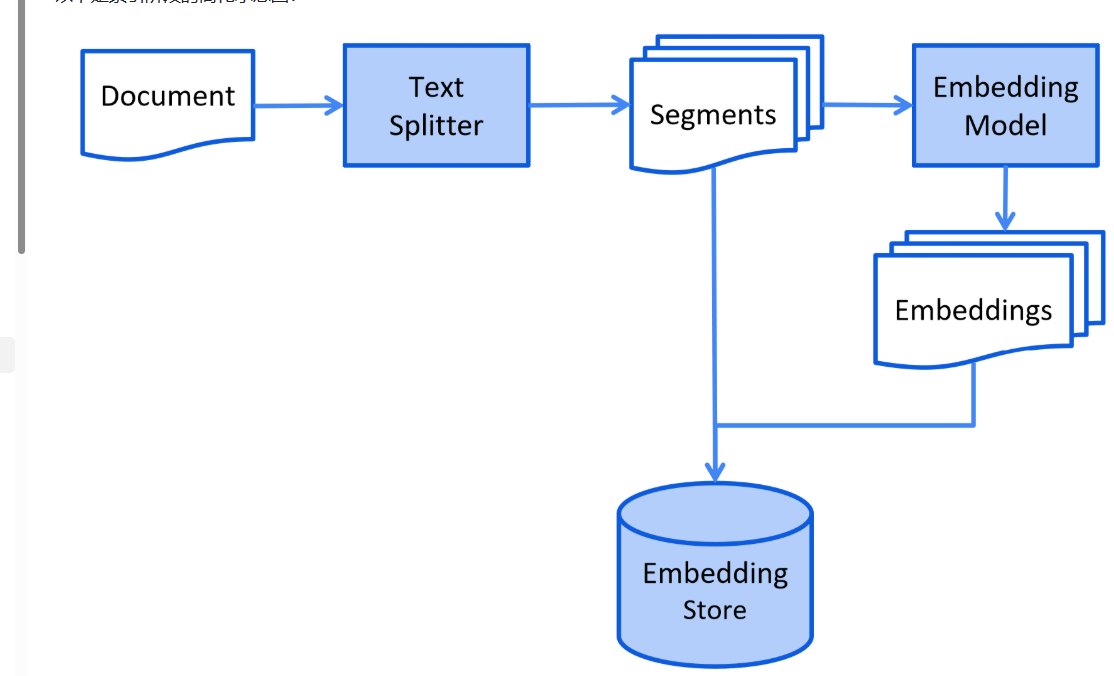
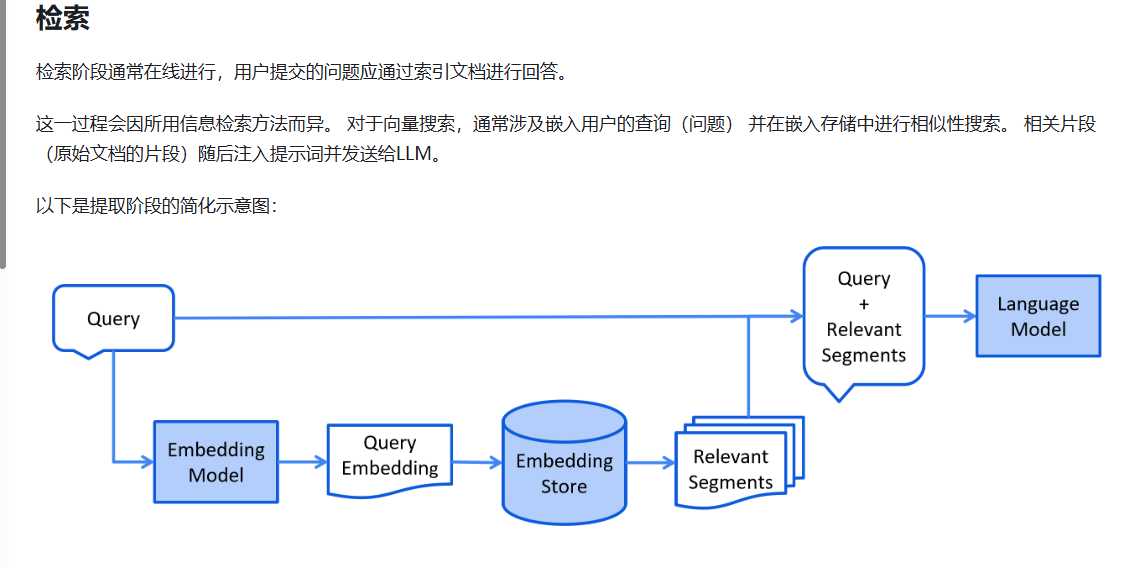
检索:
主要步骤:
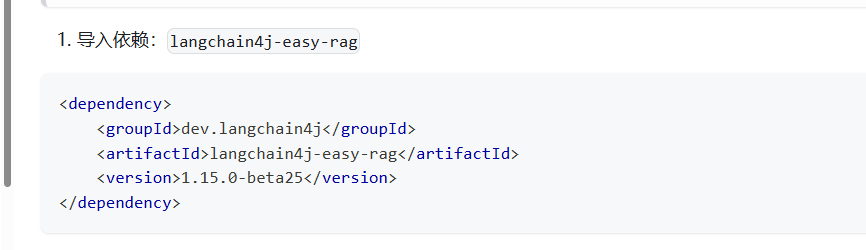
引入相关依赖:
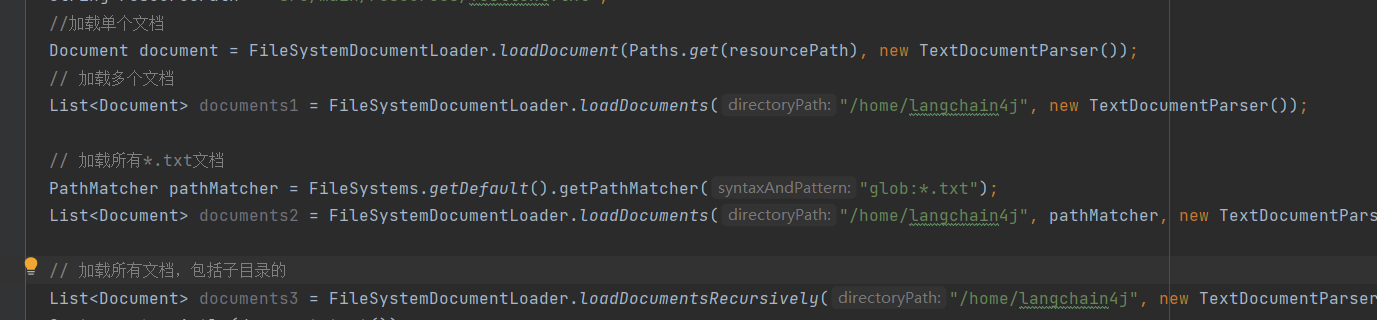
加载文档
langchain4j提供了加载解析文档的工具
文档加载器loader**= 读取文件(来源)**
文档解析器parser = 解析内容(格式)

分割文档(Splitter)
文本向量化(Embedding)
原始分割文档和文本向量化数据进行存储(EmbeddingStore)
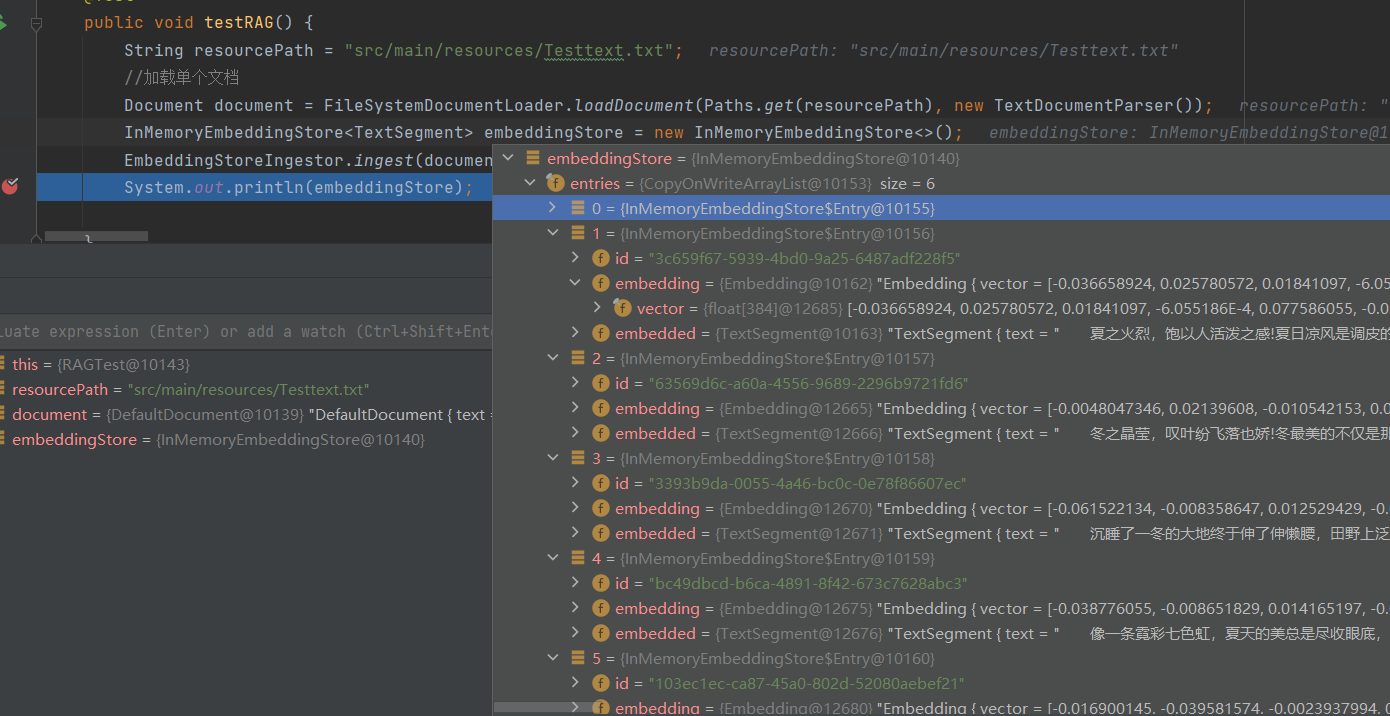
自定义文档分割器,以免太大或太小
- 重叠切块:块与块重叠 10%~20%,防止语义被一刀切断
- 按语义切:优先按标题、段落、句号分割,别硬按字数砍
- 小文档偏偏小切块 ,长篇大文偏偏大切块
自定义切割的实际意义在于:
- 切太小碎话残缺,切太大杂讯干扰,按完整语义切中等块 + 少量重叠,RAG 效果最稳。
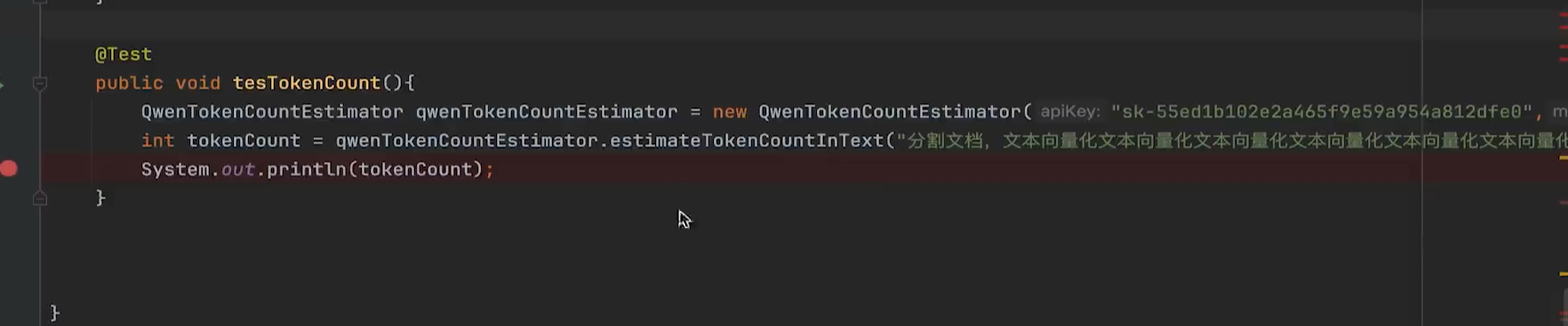
token计算
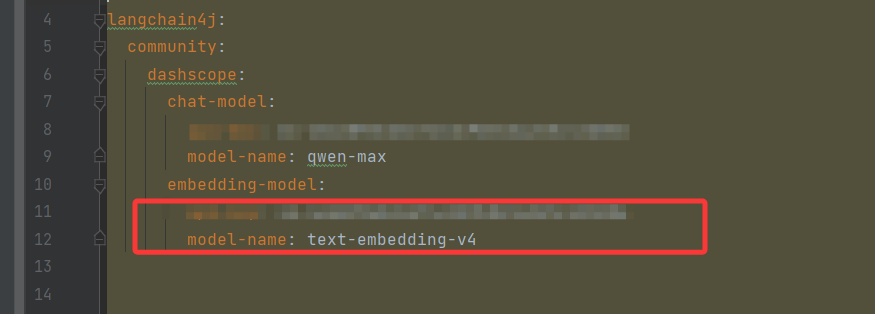
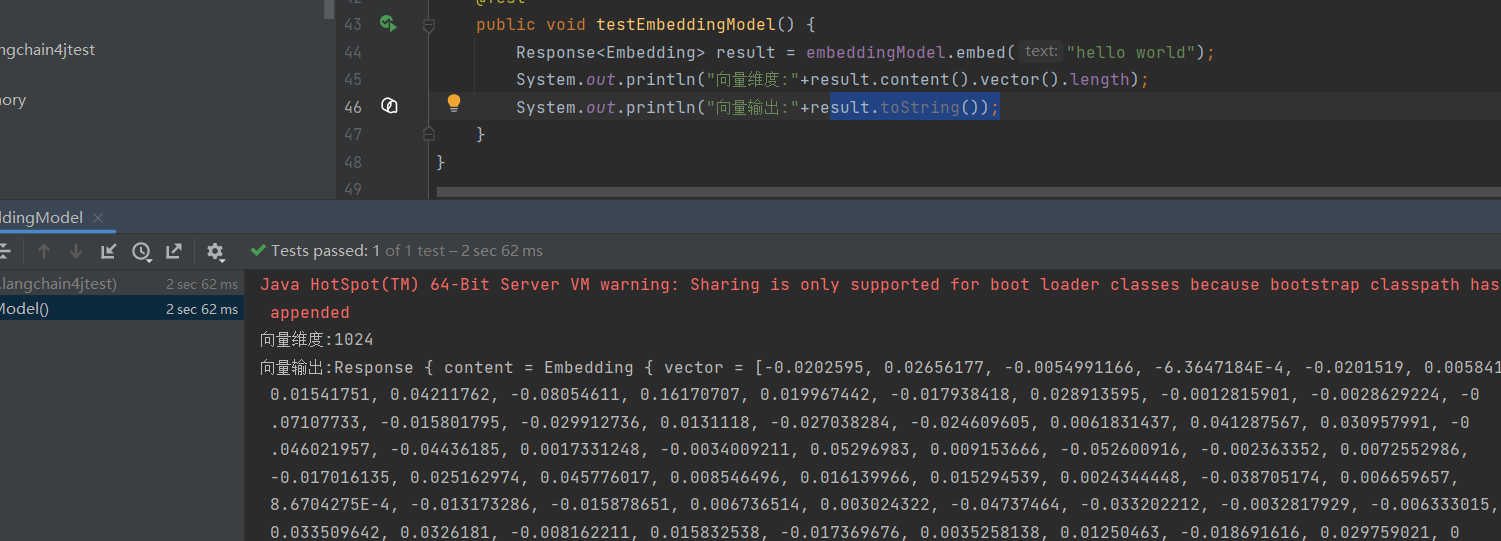
接入阿里百炼embedding向量模型
目的在于: 维度越高 → 语义细节越丰富 → 相似文本更容易被精准找到
向量数据库
pinecone
全球标杆,RAG 体验最好,但贵、数据出境敏感
1、导入相关依赖

强制指定Protobuf版本,解决Pinecone/Milvus向量数据库依赖版本冲突

pcsk_3r3hre_Pc7ejxiXQjwywean2s3F76Sa2yXJ9NVqQPNJim5ABnaaDhGkMX1Q3Fnvmxt7vVU
2、自定义向量数据库的配置
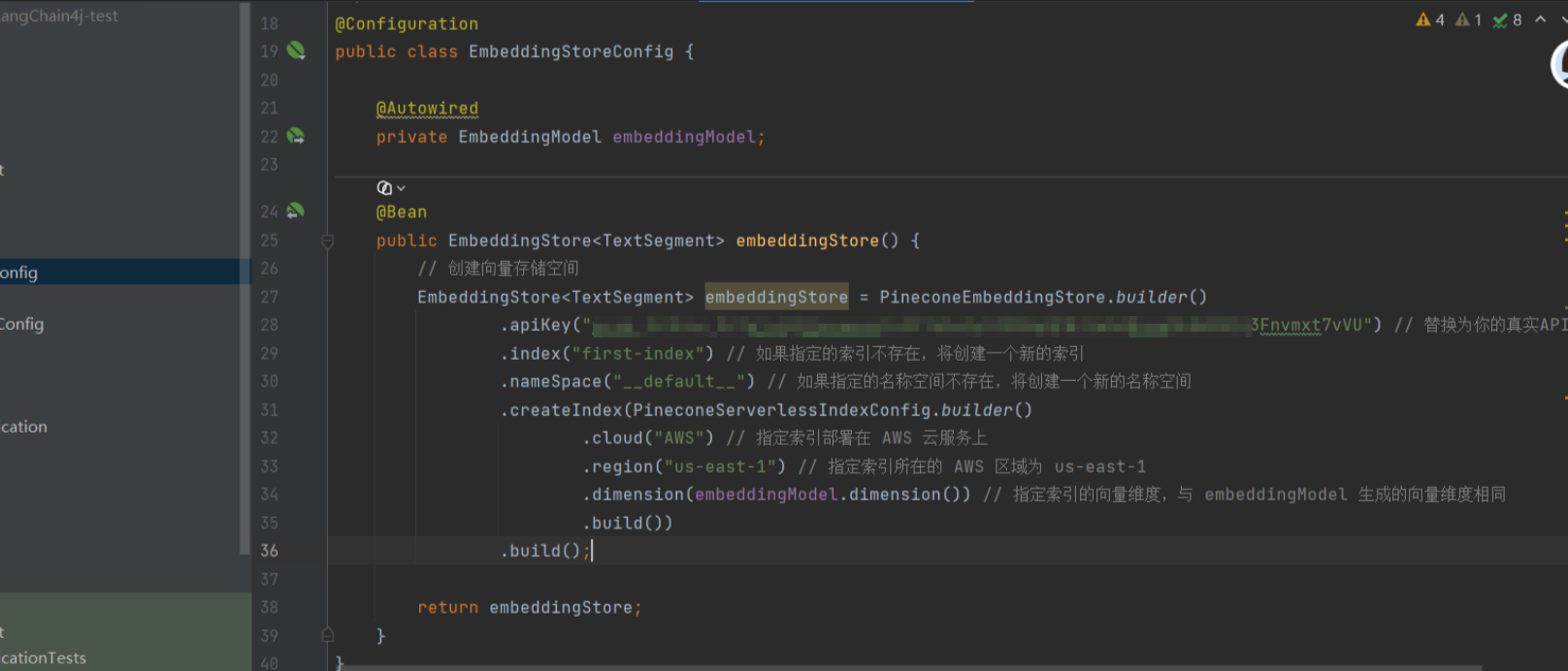
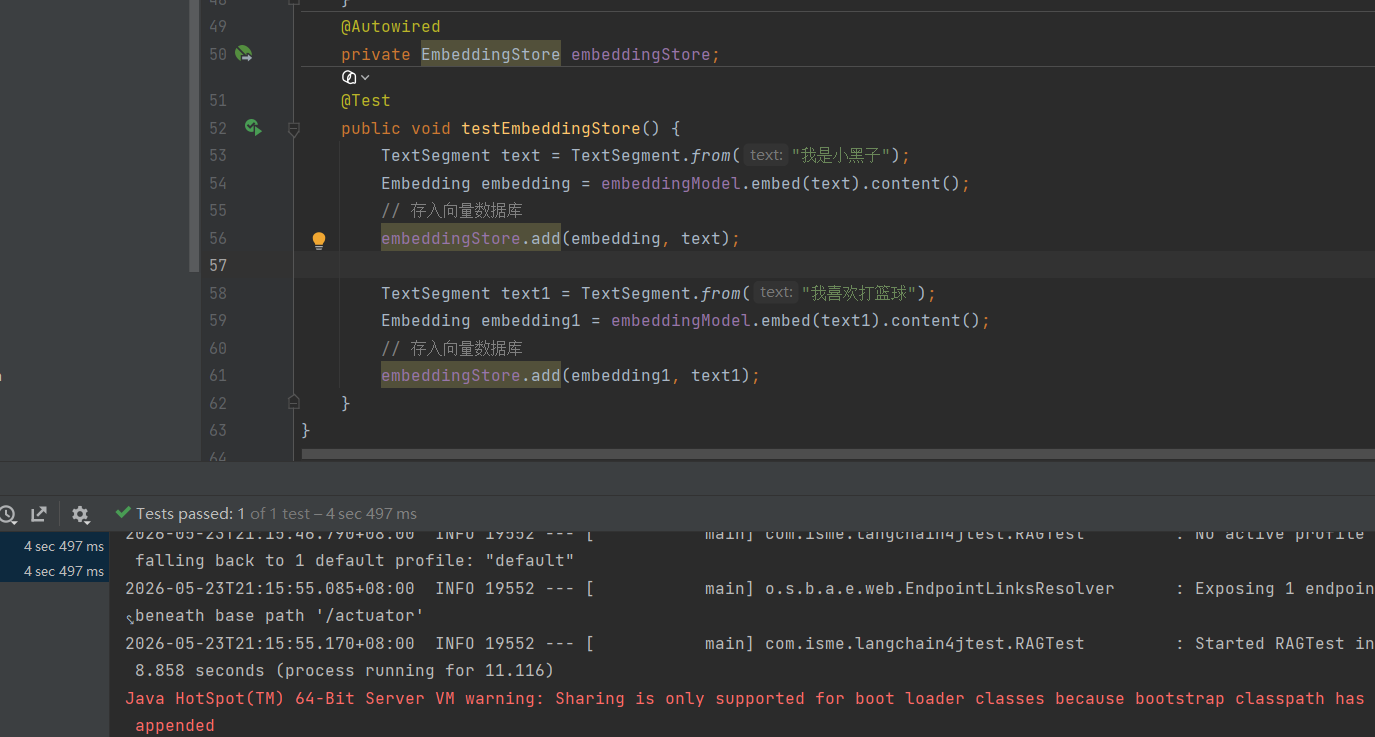
测试,把建立好索引的向量存入向量数据库中
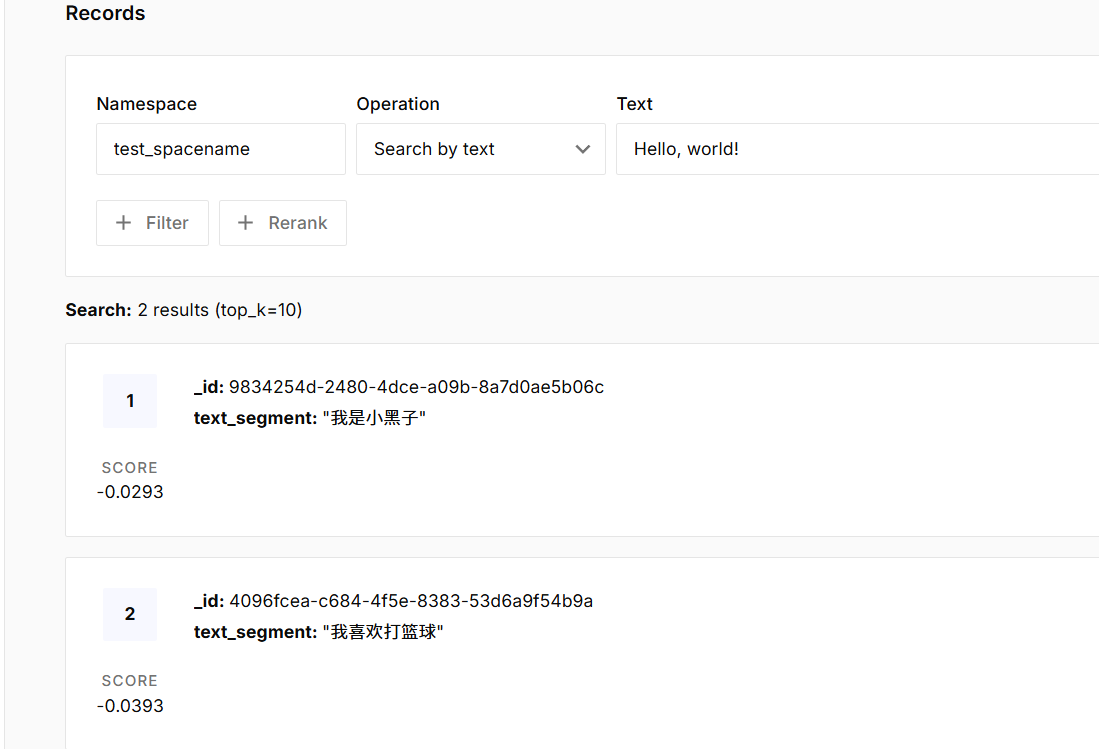
3、通过提问去向量数据库中检索相似度最高的向量
意义:使得ai在回答问题的时候能够更加精准,更能够挖掘用户的意向,使得业务开展更加的顺利。
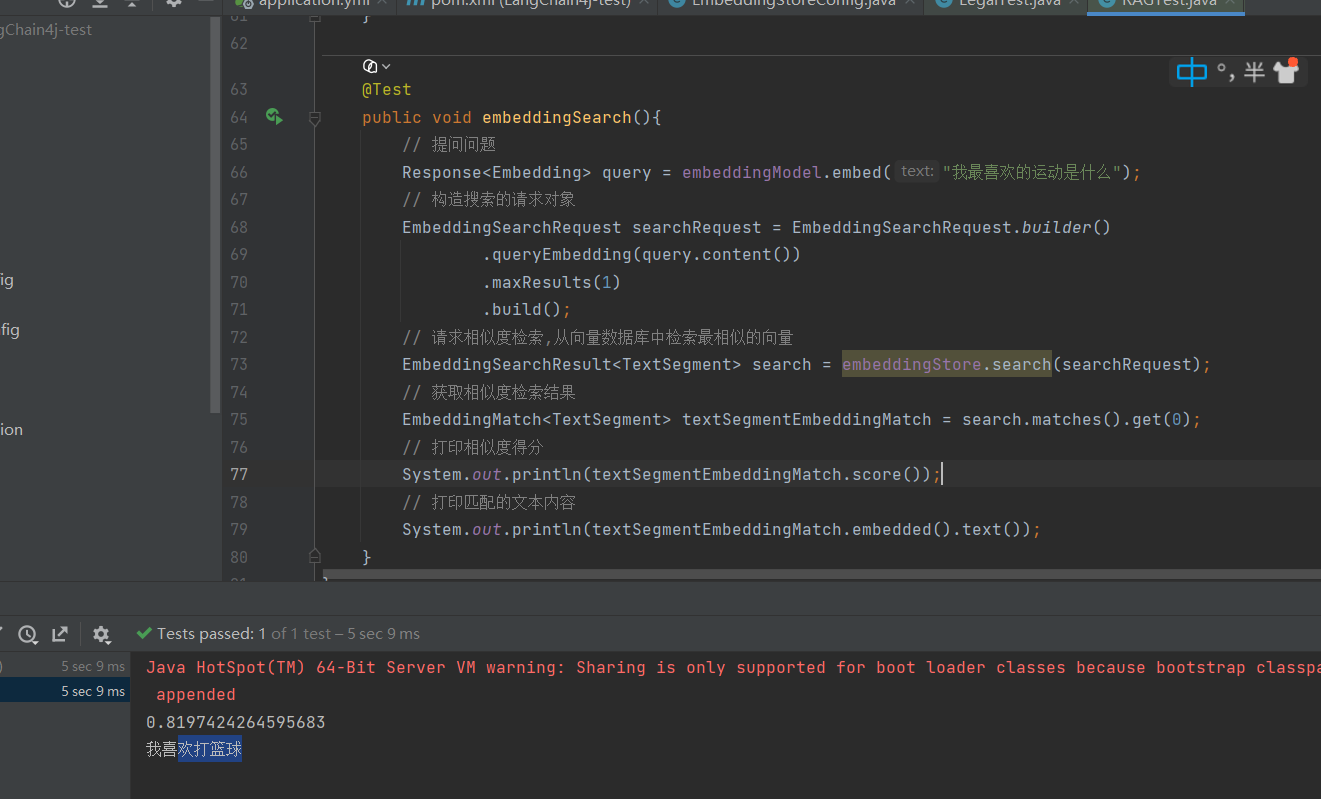
案例:仿京东外卖客服
解决的问题:使得客服回答能够更加贴合业务,而不会答非所问,充分利用公司所拥有的数据,提高业务效率
第一部分:
自定义一个文本分割器
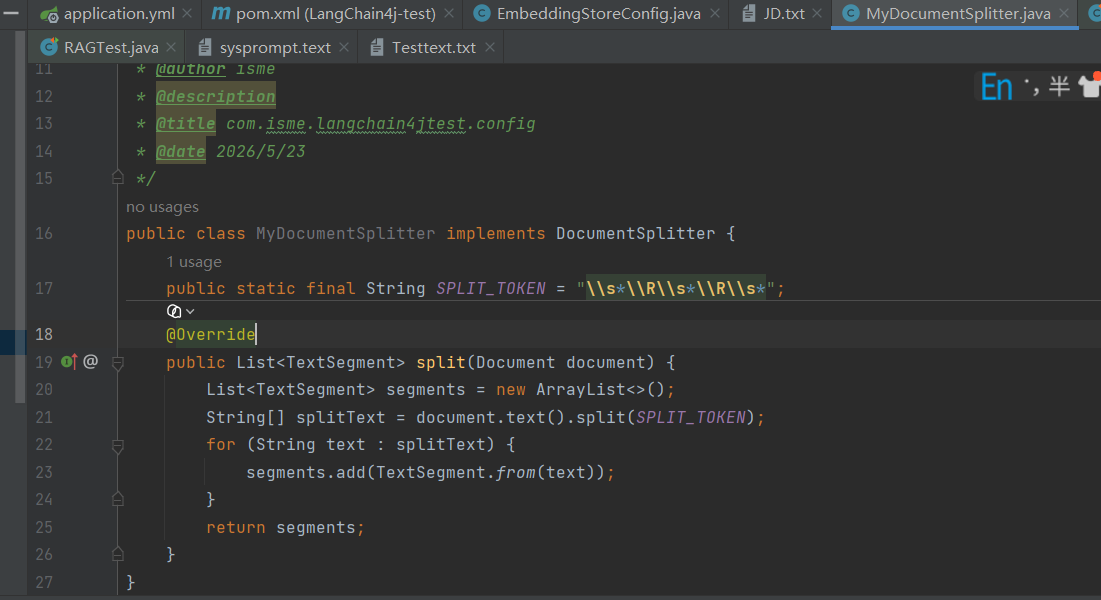
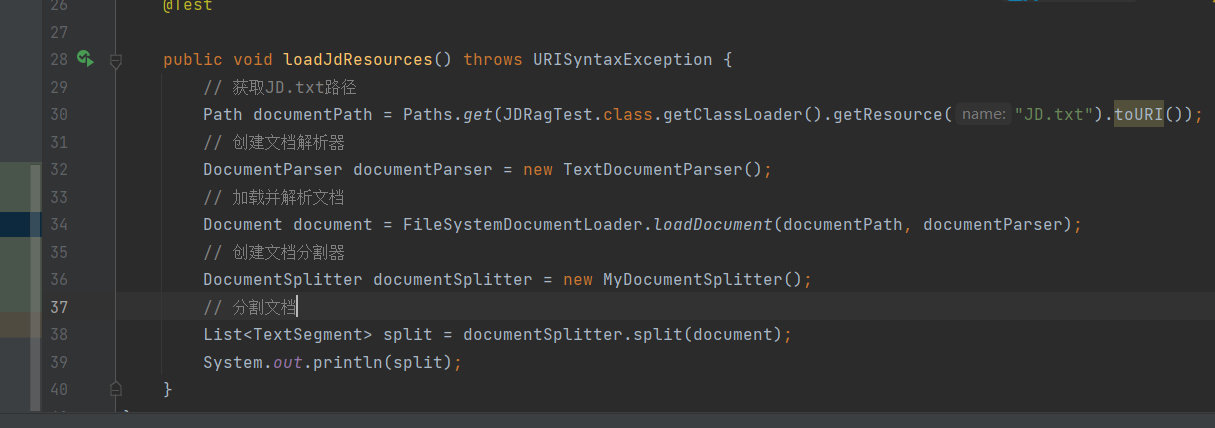
获取文档路径
创建文档解析器
加载并解析文档
创建文档分割器
分割文档
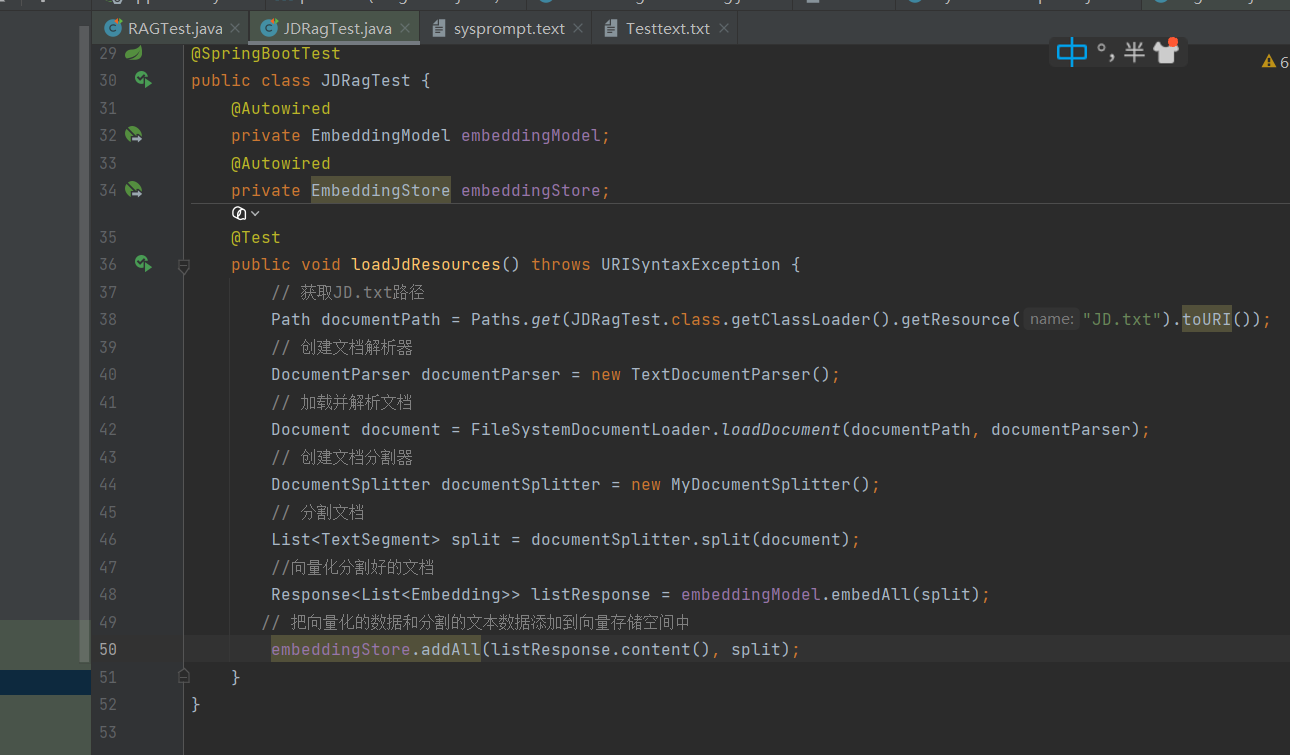
向量化分割好的文档
将向量化的数据和分割的文本数据添加到向量存储空间中
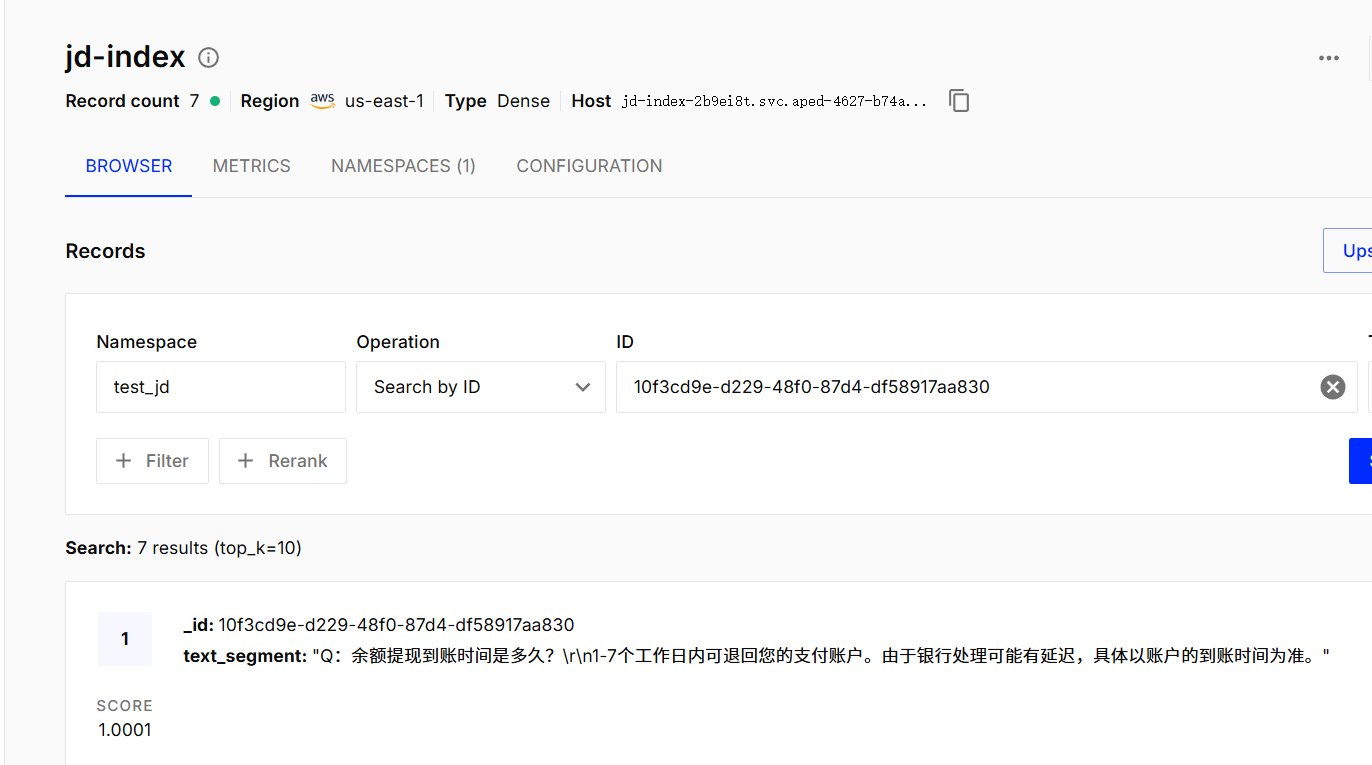
第二部分:
检索实现
问题转换成向量数据
创建搜索向量的请求对象EmbeddingSearchRequest
向量数据库进行检索embeddingStore.search
获取检索结果(取出第0索引)search.matches().get(0)
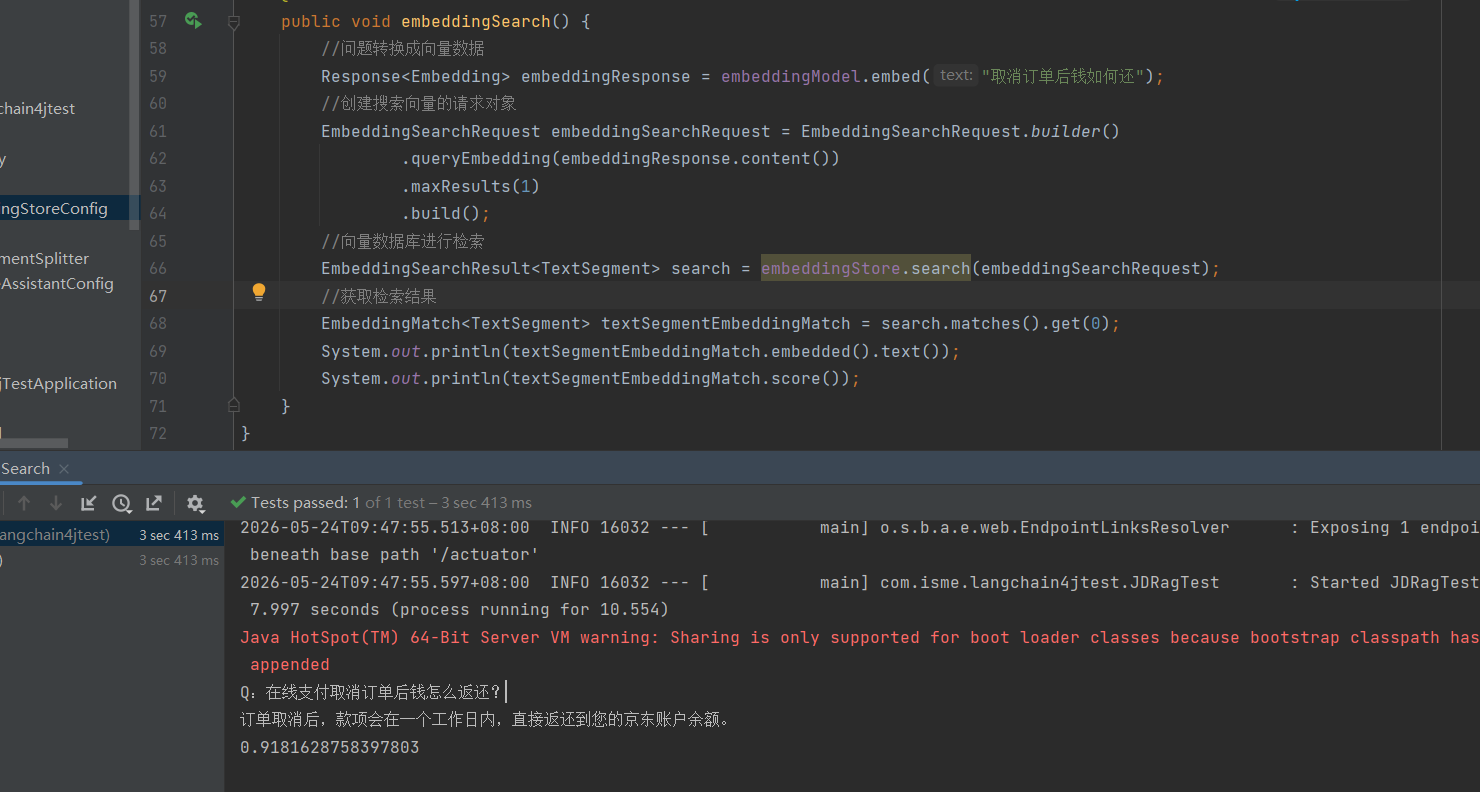
第三部分:(RAG+大模型)
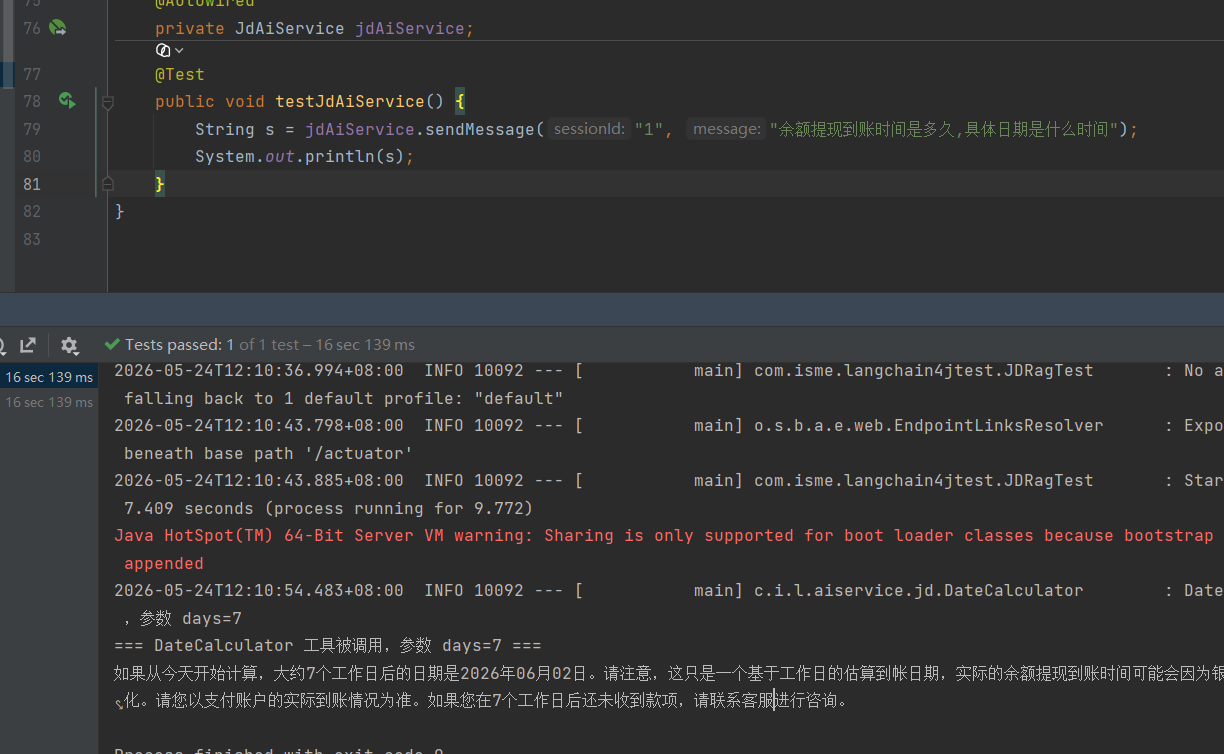
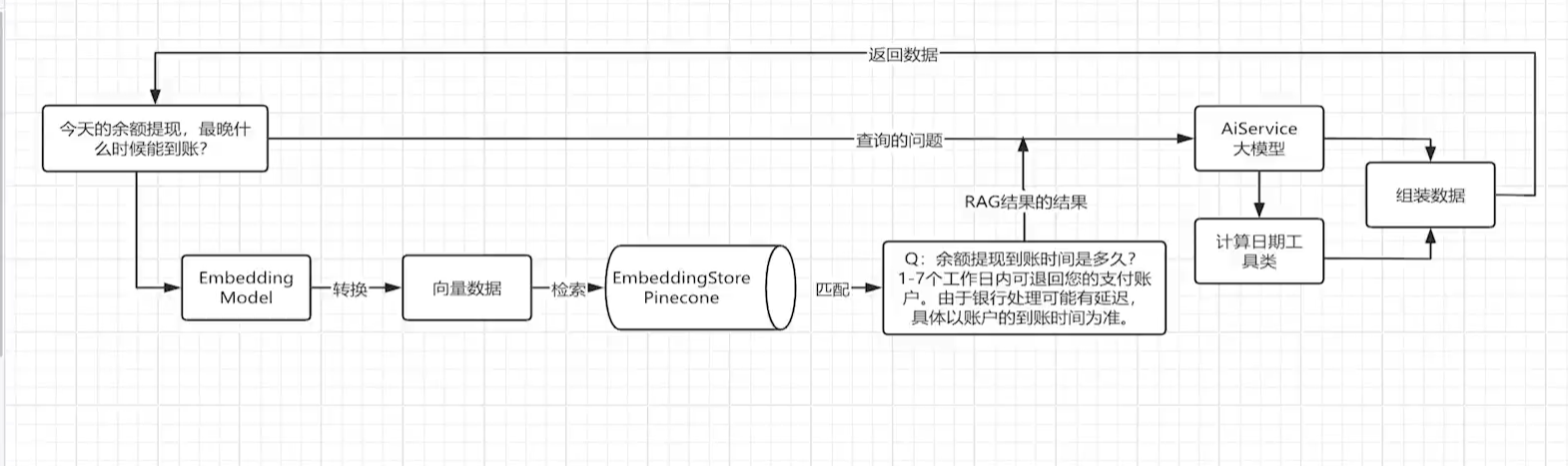
为了使得客服在回答例如快递发货什么时候能够到达时,不是前篇一律的2-7个工作日,我们就需要通过tool 让 AI 能调用外部功能实现结合实际时间推算送达日期。
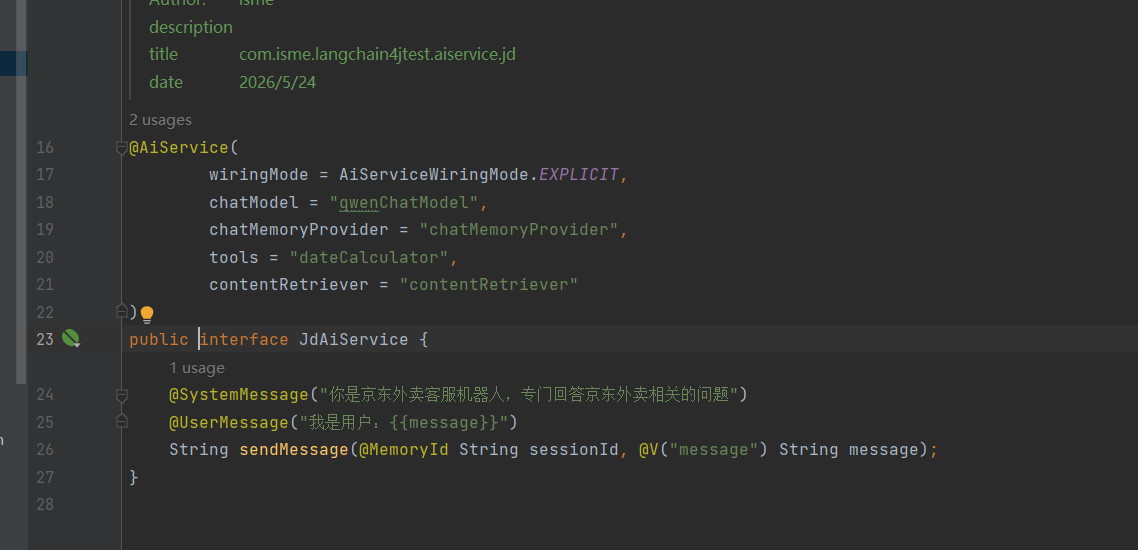
1、创建AIService ,基于 LangChain4j 框架定义的一个 AI 服务接口,用来快速创建一个「带记忆、带工具、可对话」的京东客服机器人。
- 之前的
AgentConfig是配置「知识库检索器」 - 而这个
JdAiService是把这些东西整合起来的「入口」
你可以这样理解:
JdAiService 是 AI 的「大脑中枢」,它会根据用户的问题,自动决定要不要调用工具(比如日期计算)、要不要检索知识库,然后生成回答。
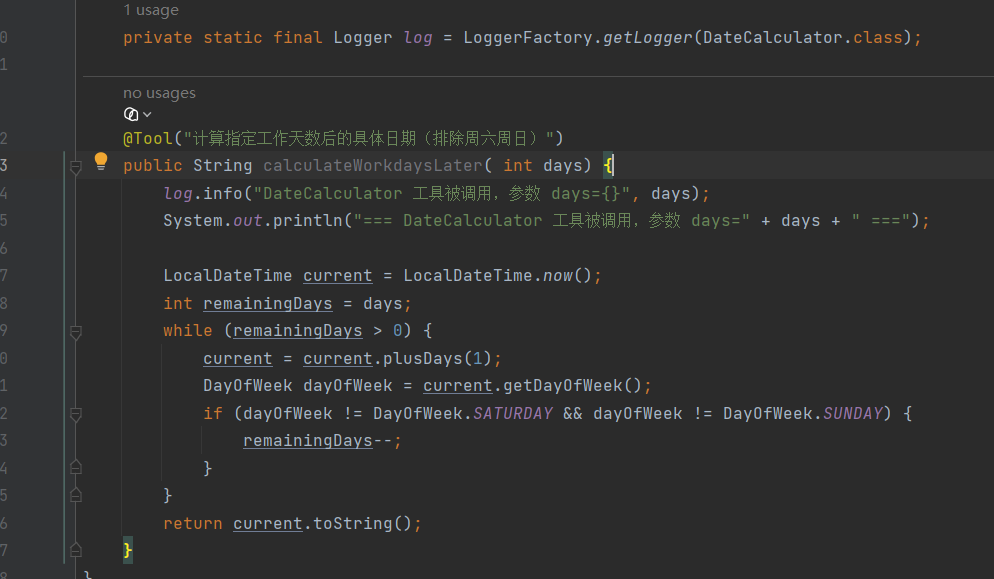
2、创建工具类DataCalculator, 给 AI 智能体调用的工具(Tool)
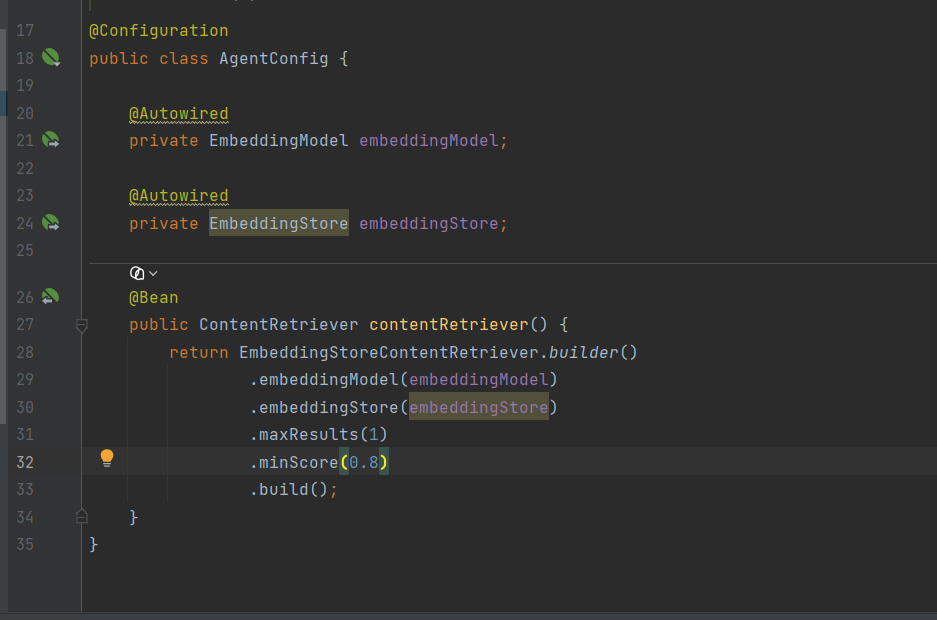
3、 创建并配置一个 ContentRetriever**(内容检索器)** Bean,给你的 RAG 智能体用
- 这是 RAG(检索增强生成)流程里的关键一环。
- 后续你的
AiService智能体,可以直接注入这个ContentRetriever,调用它来:
-
- 把用户问题转成向量
- 去向量库找最相似的知识库片段
- 把片段作为上下文喂给大模型,生成基于知识库的回答
简单说,这个类就是给 AI 装好了 "从知识库找答案" 的能力。
4、测试成功
实现流程图
所遇到的问题
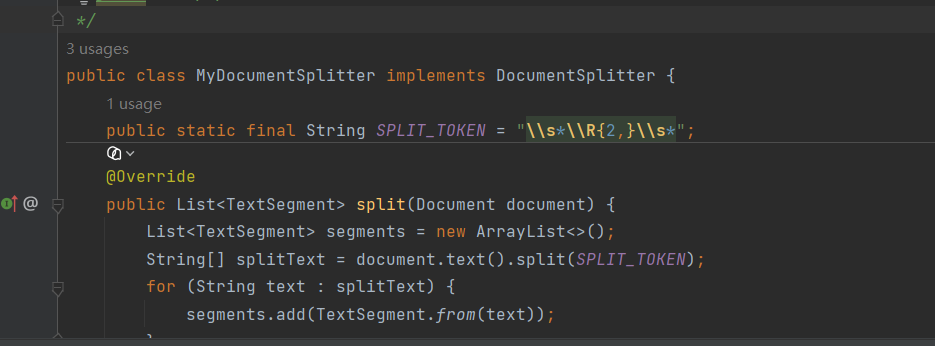
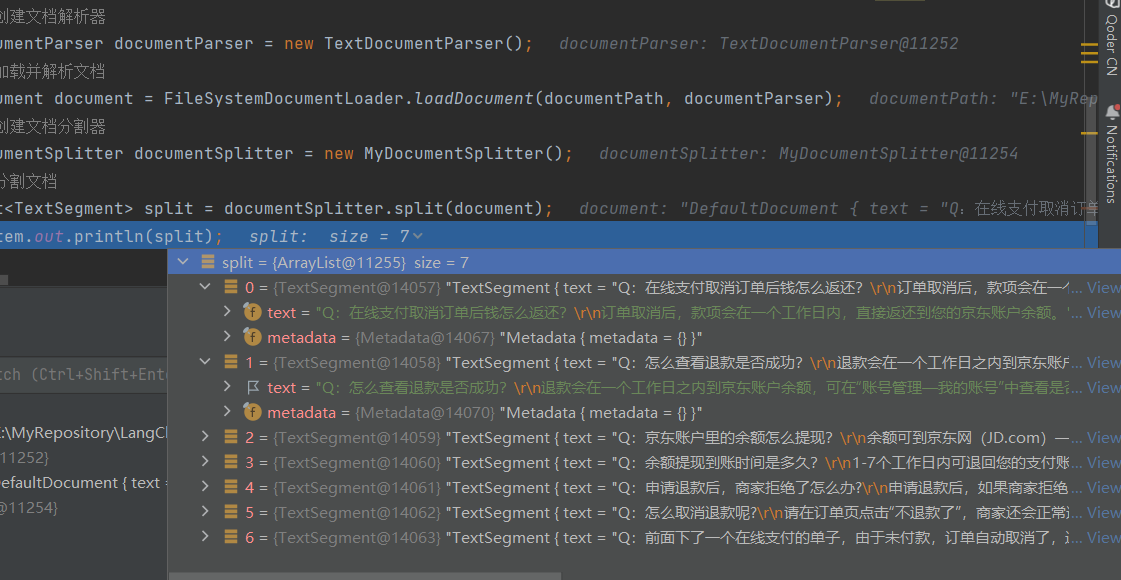
1、分段需要注意文本书写问题,否则就是这样
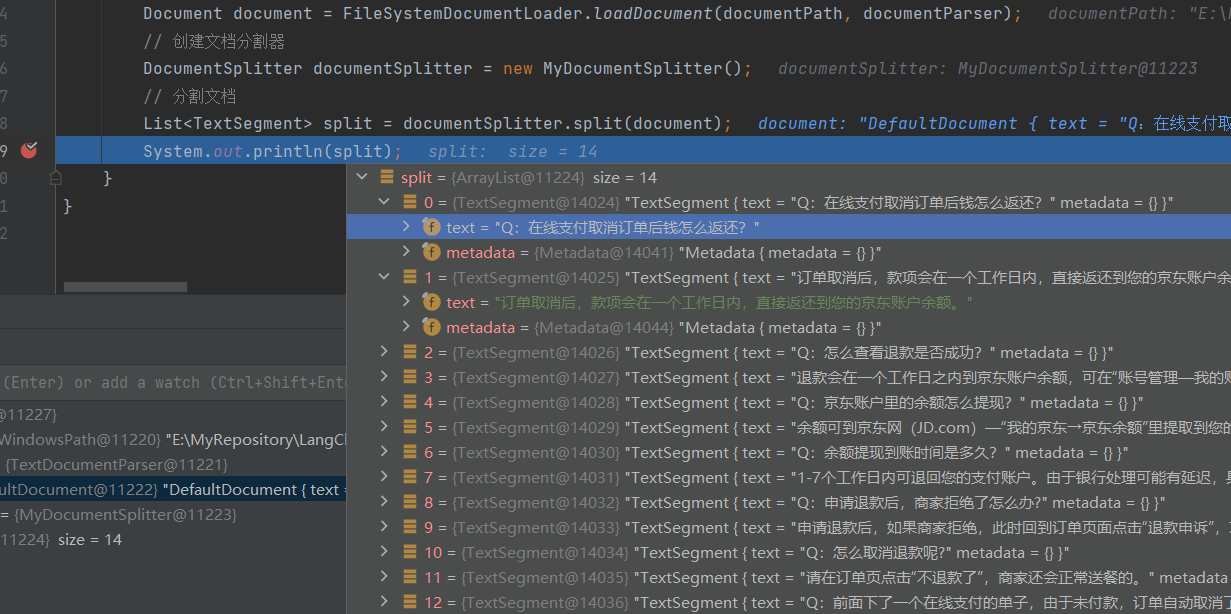
问题在于
是文本里藏了看不见的空格!
导致前面的切割方式出现了差错,因此修改成匹配:任意空白 + 2 次以上换行 + 任意空白 从而实现正确的切割
2、关于bean的默认名称
就是一个大小写问题:
- 类:DataCalculator
- 默认 bean 名:dataCalculator
- 你写的:datecalculator不匹配 → 报错
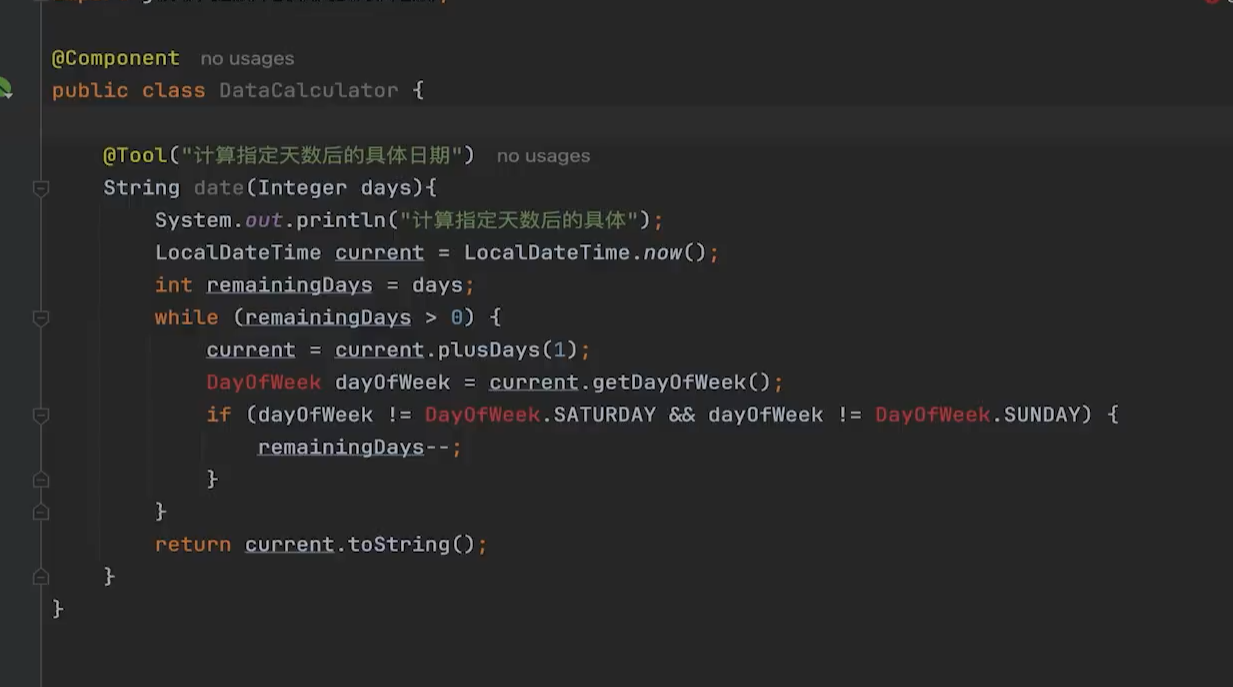
3、tool工具类老是调用不上
可能得原因以及解决办法
大模型认为不需要调用工具,问题可能不需要日期计算
工具描述不够清晰,改进 @Tool 描述,让大模型知道何时使用
参数类型解析问题 改用基本类型 int'
修改前
修改后