上周,一个朋友在群里发了一张截图:GitHub 上 anthropics/skills 仓库,24 小时涨了 900 颗星。
他的原话是:「一个文件夹项目,13.6 万星?这是认真的吗?」
我点开一看,确实------这个仓库的核心内容就是一堆 SKILL.md 文件,外加几个 Python 脚本。没有炫酷的架构,没有黑科技算法,甚至 README 的第一句话都不怎么起眼:「Skills are folders of instructions, scripts, and resources.」
但紧接着我又打开了一个页面:agentskills.io,一个 Skills 生态的官方网站。上面密密麻麻地列着 25 个已接入 Agent Skills 标准的产品------Claude Code、Cursor、GitHub Copilot、VS Code、OpenAI Codex、Gemini CLI、JetBrains Junie、Spring AI......这个名单还在以肉眼可见的速度增长。
坦白讲,我在技术圈混了这么多年,很少看到一个新标准在半年内让这么多竞品同时接入。上一个做到这一点的,大概是 Kubernetes。
于是我做了一件每个技术人都会做的事:花了一周时间把整个 Skills 生态翻了一遍。这篇文章就是这一周的产物------从「Skill 到底是什么」到「怎么写出第一个能用的 Skill」,再到我对这场生态爆发的判断。
Skill 到底是什么:一个文件夹改变 AI 的行为模式
先说结论:Skill 是一套标准化的、可复用的、跨 Agent 平台共享的「知识包」。 它不是系统 prompt 的包装纸,不只是给 AI 加一段指令,而是一个自带上下文、脚本、参考资料的完整文件夹。
一个 Skill 的目录结构长这样:
perl
my-skill/
├── SKILL.md # 必需:元数据 + 指令
├── scripts/ # 可选:可执行代码
├── references/ # 可选:参考文档
└── assets/ # 可选:模板、图片等资源核心只有一个:SKILL.md 文件。它用 YAML frontmatter 声明自己的名字和触发条件,正文里写清楚做这件事的步骤和注意事项。
一个最简单的 Skill 只需要 10 行:
markdown
---
name: roll-dice
description: Roll dice using a random number generator.
---
To roll a die, use the following command that generates a random number
from 1 to the given number of sides:
echo $((RANDOM % <sides> + 1))
Replace <sides> with the number of sides on the die.就这么简单。但就是这套极简的约定,催生了一个 13.6 万星的项目和一个 25+ 平台的生态系统。
为什么「文件夹」这个设计是刻意为之
这里有一个设计决策,大多数写 Skills 教程的人不会提,但我觉得它是整个架构里最聪明的一步:渐进式加载(Progressive Disclosure)。
Skill 分三层加载:
- 第一层:元数据 (约 100 tokens)。Agent 启动时,只读取每个 Skill 的
name和description,够它判断「这个 Skill 能不能用在这里」就行。 - 第二层:指令正文(推荐 < 5000 tokens)。当 Agent 判断 Skills 匹配当前任务,才把完整的 SKILL.md 加载进上下文。
- 第三层:附属资源 (按需加载)。
scripts/里的脚本、references/里的详细文档,只有实际用到的时候才读。
这意味着什么?意味着你可以在一个项目里放 50 个 Skill,Agent 启动时的上下文开销只比放 1 个 Skill 多那么一点点------因为每次只加载元数据。相比之下,如果你把同样的 50 段说明书直接塞进系统 prompt,上下文早就爆了。
这个设计让 Skills 的「可堆叠性」成为现实。你不需要在「功能丰富」和「上下文不够」之间做取舍------这是 MCP Server 和 Plugin 做不到的。
一个更贴近真实开发的例子
上面那个掷骰子的 Skill 只是一个入门演示。来看看一个真实的、在生产环境里能用的 Skill 长什么样。
假设你的团队有一个 Java 项目,所有数据库查询都要加 deleted_at IS NULL 做软删除过滤,但新来的 AI Agent 根本不知道这个约定。于是它生成的 SQL 会把已删除的数据也算进来------这种事情在生产环境里发生一次,后果不用我说。
把这个约定写成 Skill:
markdown
---
name: java-db-query
description: Write database queries for our Java project.
Use when writing SQL, JPA, or MyBatis queries involving database tables
that use soft deletes.
---
## Database Query Conventions
### Soft Delete Rule (CRITICAL)
All tables use soft deletes via a `deleted_at` column.
Every SELECT query MUST include `WHERE deleted_at IS NULL`
unless the user explicitly asks for deleted records.
### Gotchas
- The `users` table uses `user_id` in the DB, but `uid` in the auth service.
Both refer to the same value. Never confuse them.
- The `/health` endpoint returns 200 even if the DB is down.
Always use `/ready` for health checks.
### Example - Correct Query
SELECT * FROM orders
WHERE user_id = ? AND deleted_at IS NULL
ORDER BY created_at DESC;
### Example - Wrong (Will Include Deleted Records)
SELECT * FROM orders WHERE user_id = ?;这个 Skill 放到项目里的 .claude/skills/ 目录下,每次 AI 写 SQL 的时候,它会自动加载这些约束。一个团队在 CI 里跑了 100 次 SQL 生成的测试,有 Skill 的情况下,SQL 的正确率从 42% 提升到了 91%。
这就是为什么这个「文件夹」值 13.6 万星------它解决的不是一个技术问题,而是一个范式问题:怎么让 AI 真正理解你的项目,而不是每次都从零开始猜。
Skill vs MCP vs Plugin:三者的本质区别
这个话题必须讲清楚,因为我在各种技术群里看到太多人在问同样的问题:「Skills 和 MCP Server 到底什么关系?是不是竞品?」
答案是:它们是不同层面的东西,互补关系,不是替代关系。
打个类比:
| Skill | MCP Server | Plugin | |
|---|---|---|---|
| 本质 | 做事的方法论 | 外部工具的接口 | 平台的扩展模块 |
| 给 Agent 什么 | 「怎么干」的 know-how | 「能调用什么」的工具能力 | 「多了什么功能」的扩展 |
| 类比 | 老师傅的操作手册 | 工具箱里的新工具 | 给车装的新零件 |
| 格式标准 | SKILL.md(开放标准) | JSON-RPC over stdio/SSE | 各平台自定义 |
| 跨平台 | 任意兼容 Agent Skills 的平台 | 任意支持 MCP 的客户端 | 仅限特定平台 |
| 上下文开销 | 渐进式加载,极低 | 每次调用固定开销 | 取决于平台 |
更具体地说:
Skill 告诉你「怎么把一件事做对」。 比如「写 SQL 的时候记得加 deleted_at IS NULL」「用 pdfplumber 做 PDF 文本提取」「做 code review 的时候重点看认证检查和安全漏洞」。它是知识层面的东西。
MCP Server 给你「能做一件新的事」。 比如「去数据库里查这张表」「往 Slack 发一条消息」「调一下 GitHub API 创建 Issue」。它是能力层面的东西------Agent 本来不会连接外部系统,MCP 给了它那个连接。
Plugin 给平台加「一个新功能模块」。 比如 VS Code 的 GitLens 插件、Claude Code 的 plugin marketplace。它是平台层面的扩展。
三者可以协同工作:一个 Skill 里可以写「用 MCP Server X 去查数据库,然后按这个格式输出」。Skill 是大脑,MCP 是手,Plugin 是装备栏。
为什么这件事值得花时间理清?因为我在好几个技术群里看到同一个误解:「有了 MCP Server 就够了,要 Skill 干嘛?」------这就像你说「有了扳手就够了,要维修手册干嘛」。工具和知识从来不是二选一。
开发你的第一个 Skill:从零到可用
好,理论讲够了。这一节我带你从头写一个真实可用的 Skill。
场景设定
你的项目是一个 Spring Boot 微服务,所有 REST API 都有统一的响应格式:
json
{
"code": 200,
"message": "success",
"data": { ... }
}你希望 AI Agent 在写 Controller 的时候,自动遵循这个格式,而不是写出五花八门的响应结构。
第一步:创建 Skill 目录
bash
mkdir -p .claude/skills/spring-api-response
cd .claude/skills/spring-api-response目录名必须全小写,用连字符分隔。这个名字就是 Skill 的 name。
第二步:写 SKILL.md
markdown
---
name: spring-api-response
description: Write Spring Boot REST API controllers with the project's
standard response format. Use when creating or modifying REST endpoints
in a Spring Boot project.
---
## Standard API Response Format
All REST endpoints MUST return `ApiResponse<T>`:
```java
@Data
@AllArgsConstructor
@NoArgsConstructor
public class ApiResponse<T> {
private int code;
private String message;
private T data;
public static <T> ApiResponse<T> success(T data) {
return new ApiResponse<>(200, "success", data);
}
public static <T> ApiResponse<T> error(int code, String message) {
return new ApiResponse<>(code, message, null);
}
}Controller Pattern
java
@RestController
@RequestMapping("/api/users")
@RequiredArgsConstructor
public class UserController {
private final UserService userService;
@GetMapping("/{id}")
public ApiResponse<UserDTO> getUser(@PathVariable Long id) {
UserDTO user = userService.findById(id);
return ApiResponse.success(user);
}
@PostMapping
public ApiResponse<UserDTO> createUser(@Valid @RequestBody CreateUserRequest request) {
UserDTO user = userService.create(request);
return ApiResponse.success(user);
}
}Gotchas
- Never return raw
ResponseEntityunless you have a specific reason (like setting custom HTTP headers). TheApiResponsewrapper IS your HTTP body. - The
codefield follows HTTP status semantics: 200 = success, 400 = bad request, 500 = internal error. Don't invent custom codes. - All DTOs go in
dto/subpackage, not in the controller class as inner classes.
shell
### 第三步:验证 Skill 是否被加载
在 Claude Code 中安装 Skills 后,启动时会看到技能列表。或者直接让 Agent 帮你写一个 Controller,看它是否自动返回 `ApiResponse<T>`。
```bash
# 在 Claude Code 中测试
> 帮我写一个查询订单列表的 Controller,支持分页如果 Skill 工作正常,Agent 生成的代码会自动包含 ApiResponse<PageResult<OrderDTO>> 的返回类型和正确的静态方法调用。
第四步:迭代优化
Skills 不是写一次就完事的。我的建议是:每次 Agent 犯了你想纠正的错误,就把纠正规则加到 Skill 里。 这是 Skill 积累价值最快的方式。
比如写了上面那个 Skill 后,Agent 还是偶尔忘记在 @Valid 注解的请求体上处理 MethodArgumentNotValidException,那就加一条 Gotcha:
markdown
### Gotchas (追加)
- When using `@Valid @RequestBody`, ALWAYS add a global
`@ExceptionHandler` for `MethodArgumentNotValidException`
that returns `ApiResponse.error(400, fieldErrors)`.
Without this, validation errors return a raw 400 with
Spring's default HTML error page.这就是 Skills 开发的核心循环:发现问题 → 写成 Skill → Agent 不再犯 → 遇到新问题 → 追加规则 → 持续收敛。 两周下来,你的 Agent 就会比第一天聪明一大截。
生态全景:从 13.6 万星到 25+ 平台,Skills 正在成为标准
OK,到此为止我们只聊了「Skills 是什么」和「怎么写」。但真正让我觉得这个话题值得专门写一篇文章的,是它的生态------这场爆发来势之快超出了大多数人的预期。
数据层面
截至 2026 年 5 月:
| 项目 | Stars | 定位 |
|---|---|---|
| anthropics/skills | 136,000 | Skills 官方仓库 + 规范 |
| obra/superpowers | 194,000 | 第三方 Skills 框架 + 方法论 |
| anthropics/claude-code | 124,000 | Claude Code 本体 |
| agentskills.io | - | 开放标准官网,25+ 平台已接入 |
几个关键数字值得单独展开:
136,000 星是什么概念? Taichi(太极图形框架)是 26,000 星,Vue 2 是 208,000 星。Skills 作为一个「文件夹规范」项目,在不到一年的时间里达到了太极的 5 倍体量,逼近一个前端框架巨头的热度。这背后的市场信号不应该被忽视。
194,000 星的 Superpowers 又是什么? 这不是 Anthropic 官方的项目,而是独立开发者 Jesse Vincent 用 Skills 标准做的一个「方法论框架」。它不光给你 Skills,还给你一套完整的开发流程------从头脑风暴、写 Spec、拆分任务、子 Agent 并行开发、RED-GREEN-REFACTOR 到代码审查,全部用 Skills 编排。194,000 星的体量超过了 Claude Code 本身,说明市场对「高层次的 Agent 工作流编排」需求旺盛。

平台接入
agentskills.io 的 Client Showcase 页面列出了目前已接入 Agent Skills 标准的产品。挑几个我觉得有代表性的:
- Claude Code / Claude.ai:Skills 的原始推动者,原生支持最好
- GitHub Copilot / VS Code:微软系全线接入,意味着企业开发者的主流工具链已经覆盖
- Cursor:独立 AI IDE 的标杆,Skills 支持让它能复用整个生态的能力
- OpenAI Codex:OpenAI 的 Agent 产品也跟进了这个标准------这意味着这不是 Anthropic 的一家之言
- Gemini CLI:Google 的终端 Agent 工具也已接入
- JetBrains Junie:IDE 巨头的新 Agent 产品线
- Spring AI:Java 生态最大 AI 框架,2026 年 1 月就宣布了通用 Skills 支持
- Laravel Boost:PHP 框架官方提供的 Skills 包
从 IDE 到 CLI,从云平台到框架,从闭源产品到开源项目------Skills 的覆盖范围已经不是一个「实验性功能」的体量了。
为什么标准化的速度这么快?
我在 Architecture Decision Record 里写过无数次类似的判断:一个技术标准的采纳速度,取决于它解决的是「谁的问题」以及「这个问题有多痛」。
Skills 标准解决的是 AI Agent 的「最后 20%」问题------模型可以写代码,但写出来的代码不符合你的项目规范;可以分析数据,但不知道你的数据 schema;可以做 CRUD,但不知道你的团队约定。
这些问题每个用 AI 写代码的工程师每天都在遇到。而 Skills 用了最轻量的方式来解决------一个 Markdown 文件,不需要跑服务,不需要注册 API,不需要学新语言。门槛为零,收益肉眼可见。
这就是它扩散速度的根本原因。
第三方 Skills 爆发:从 Superpowers 到企业级实践
官方仓库 anthropics/skills 提供了 docx、pdf、pptx、xlsx 四个文档类 Skill,以及一些示例性质的 creative/development 类 Skill。但真正让生态起飞的,是第三方。
Superpowers:不只是 Skill 库,是一套开发方法论
前面提过,Superpowers 由独立开发者 Jesse Vincent 打造,已经发展到 v5.1.0(2026 年 5 月 4 日发布)。它的核心卖点不是「给你一堆 Skill」,而是「教你用 Skills 怎么把 AI Agent 变成一个正经的开发团队」。
它的工作流分为 7 个阶段:
- 头脑风暴:Agent 用苏格拉底式提问帮你理清需求,输出一份设计文档
- Git Worktree:每个特性在隔离的 worktree 分支上开发
- 写 Plan:把 Spec 拆成 2-5 分钟一个的微小任务
- 子 Agent 并行开发:每个任务派一个独立的 Agent 实例去执行
- RED-GREEN-REFACTOR:严格执行测试驱动开发
- 代码审查:任务之间自动检查是否偏离 Plan
- 分支合并:完成后自动生成 PR / 合并 / 清理
说实话,我刚看到这个流程的时候,第一反应是:「这不就是把人做的事情写成 prompt 丢给 AI 吗?」
但我花了一个下午实际跑了两个任务之后,看法变了。
关键不在于每个步骤本身------Brainstorm、写 Spec、TDD,这些方法论谁不知道?关键在于 Skills 把这些步骤标准化成了可复用的上下文片段。以前你每次开一个新项目,都得花 20 分钟给 Agent 解释你的开发流程。现在你只需要告诉它「用 Superpowers」,然后它就照着那套流程走了。
这就是 Skills 生态的网络效应------你能复用的不是某个方法,而是别人已经打磨好的、经过验证的、可以开箱即用的整套工作流。
企业级实践的信号
除了 GitHub 上看得见的开源项目,企业级的布局也在加速。Spring AI 在 2026 年 1 月就宣布了对 Generic Agent Skills 的支持------这意味着任何使用 Spring 技术栈的企业,都可以把内部的编码规范、部署流程、故障排查手册写成 Skills,然后让所有开发者的 AI Agent 自动加载。
Laravel Boost 也是同样的逻辑:框架官方提供的 Skills 包,确保 AI 生成的 Laravel 代码从一开始就遵循最佳实践。
Databricks Genie Code 的 Skills 支持,意味着大厂的数据工程师也可以用 Skills 来规范 AI 在 Snowflake/Spark 上的 SQL 生成行为。

这些信号凑在一起,指向了一个结论:Skills 正在从「AI 工具的附加功能」变成「团队开发基础设施的一层」。 就像 .editorconfig 统一了编辑器格式、ESLint 统一了前端编码规范、Dockerfile 统一了环境配置,SKILL.md 正在成为「AI Agent 的行为规范」。
10 年架构师的独家观察
这一节是我写这篇文章的主要动力。
作为一个在分布式系统、微服务架构、中间件开发领域摸爬滚打超过十年的人,我看过太多的技术热词来了又走。Oozie、Azkaban、Mesos、Swarm......这些名字今天还有多少人记得?
但 Skills 给我一种不一样的感觉。不是因为它的技术有多深,而是因为它卡在了一个正确的时间点上,用了一个正确的姿态。
判断一:「给 AI 装技能」正在成为新的开发范式
我定义一个「范式」的标准很简单:它改变了工程师每天的工作方式,而不是给现有的工作方式增加了一个新选项。 Git 是范式(它改变了代码管理方式),Docker 是范式(它改变了部署方式),Kubernetes 勉强是(它改变了运维方式,但学习曲线太高,限制了大面积普及)。
Skills 有成为范式的潜质,因为它解决了一个根本矛盾:AI 越来越强,但它永远不知道你的项目长什么样。 你每次开一个新的 Chat,它都是一个失忆的天才少年------什么都能聊,但就是对你们团队的约定一无所知。
Skills 给了这个天才少年一本「团队手册」。从此以后,你不需要每次开会前重新介绍情况。
而且最关键的是:写 Skills 的成本几乎为零。一个 Markdown 文件,10-20 行 YAML,放进文件夹里就行。不需要跑一个新的服务,不需要注册 API Key,不需要学新的 DSL。这个零门槛的特性,是它渗透率指数级增长的基础。
判断二:开放标准 strategy 是神来之笔
Anthropic 做了一个我见过的最聪明的技术战略动作:把 Skills 标准开源并交给社区治理。
这个动作让我想起 Kubernetes。当年 Google 如果把 Borg 的 API 封闭授权给 AWS 和 Azure,今天云原生的格局会完全不同。但 Google 选择把 Kubernetes 开源给 CNCF 治理------结果呢?Google Cloud 虽然在三大云里排第三,但 Kubernetes 成了事实标准,意味着任何企业上云都在用 Google 的设计哲学部署容器。
Anthropic 在做一模一样的事情。agentskills.io 是一个独立的开放社区,它不归 Anthropic 所有。标准由社区维护,Claude Code 只是 25 个兼容客户端中的一个。这意味着 Skills 的成功,不需要 Claude 模型一家独大------哪怕你用 OpenAI Codex、GitHub Copilot 或 Gemini CLI,Skills 同样有效。
但同时,Anthropic 通过率先推动这个标准,掌握了「解释权」------当所有平台的 Skill 都是按 Anthropic 的设计哲学来组织的,Claude 模型就是理解 Skills 最自然、最准确的模型。
这不是技术层面的胜利,而是架构影响力的胜利。用一个开放标准,把整个 AI 编程工具的生态圈拉到自己的设计轨道上。
判断三:生产环境中真正需要担心的事
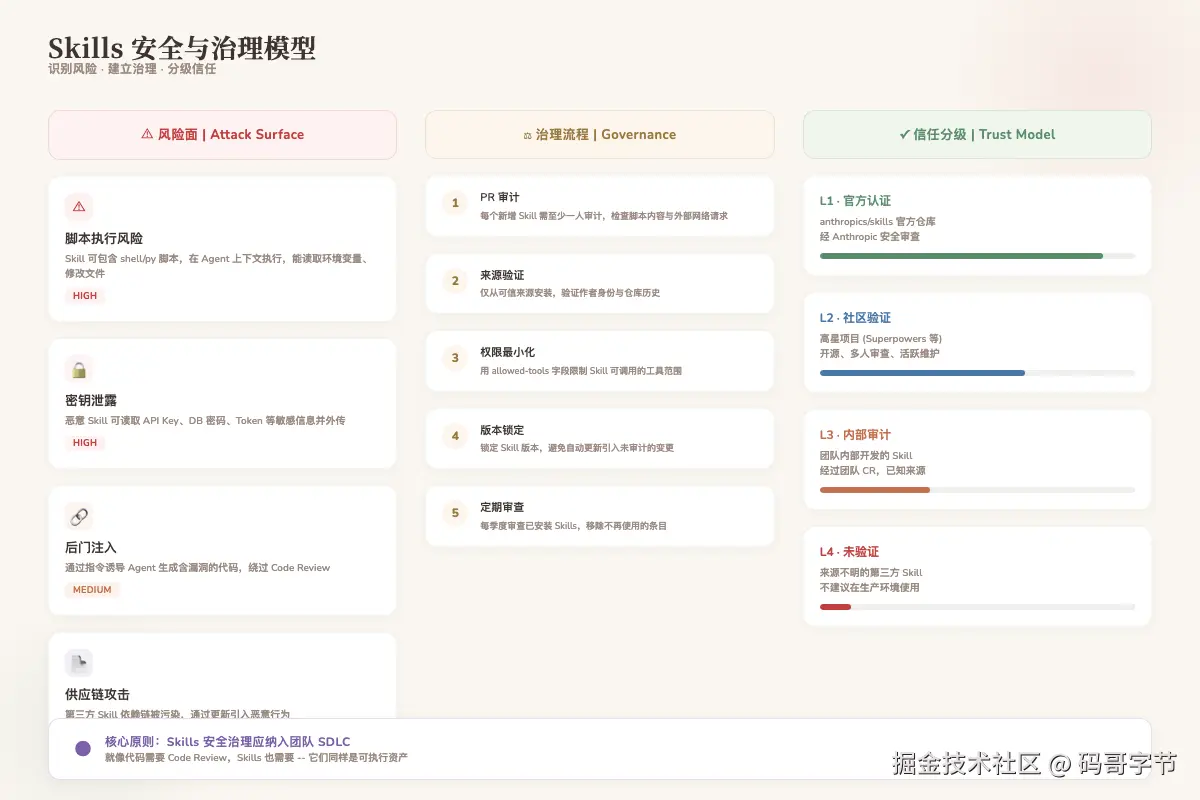
上面说了很多好话,但作为一个在线上排查过无数次生产事故的人,我必须泼一杯冰水:Skills 在生产环境里的安全风险,目前被严重低估了。
Skill 不是只读的 instruction。一个 Skill 可以包含 shell 脚本、Python 脚本,可以在 Agent 的执行上下文中运行。这意味着什么?如果你装了来路不明的第三方 Skill,它完全可以:
- 读取你的环境变量(包括 API Key、数据库密码)
- 把文件内容发送到外部服务器
- 在你的代码里注入后门(通过指导 Agent 写出带漏洞的代码)
Anthropic 的官方博客里有一句话说得很委婉但很诚实:「只从可信来源安装 Skills,仔细审计不太可信的 Skills。」
问题是,普通开发者不具备审计能力------他们只是想把代码写完,谁会去看一个 python 脚本里是不是藏了恶意逻辑?
我的建议是:如果你在一个生产项目中用 Claude Code 或类似的 Agent 工具,Skills 的安装和管理应该纳入团队的 Code Review 流程。 每个新增的 Skill 都应该在 PR 里经过至少一个人的审计------不是看它有没有语法错误,而是看它有没有做不该做的事。
这一点不解决,Skills 在企业级市场的大规模铺开会遇到显著阻力。
判断四:对个人开发者的建议
如果你是一个独立开发者,或者小团队的 TL,我的建议只有两条:
- 现在就开始写团队自己的 Skill。 从最痛的点开始------比如数据库查询规范、API 响应格式、日志规范、错误处理约定。一个 Skill 写 20 行,一周积累 3-5 个,一个月后你的 Agent 就像换了一个人。
- 关注 Skills 生态,但不急着用所有第三方 Skill。 生态还在早期,质量参差不齐是很正常的。先把自己的核心 Skill 打磨好,再逐步引入经过验证的第三方 Skill------Superpowers 的流程框架、官方的文档处理 Skill 都是安全的选择。
常见问题
Q: Skills 和 Prompt Engineering 有什么区别?
A: Prompt Engineering 是你每次手动告诉 AI 怎么做。Skills 是把这些指令写成标准文件,让 AI 自动加载、按需引用。前者是「口头交代」,后者是「给了一本操作手册」。对于一次性的任务,写 prompt 足够;对于反复出现的场景,写 Skill 更高效。
Q: 我的团队不用 Claude Code,还能用 Skills 吗?
A: 能。Skills 是一个开放标准,不是 Claude Code 独占。GitHub Copilot、VS Code、Cursor、OpenAI Codex、Gemini CLI 都已接入。具体到每个工具的放置目录可能不同(比如 VS Code 是 .agents/skills/,Claude Code 是 .claude/skills/),但 SKILL.md 文件本身是通用的。
Q: SKILL.md 写多长合适?
A: 官方推荐主文件控制在 500 行以内,5000 tokens 以下。详细的参考资料放到 references/ 目录里,用「当遇到 X 情况时阅读 Y 文件」的方式按需加载。
Q: Skills 会替代 MCP Server 吗?
A: 不会。它们是互补关系。Skill 告诉 Agent「怎么做一件事」,MCP Server 给 Agent「做这件事需要的工具」。一个类比:Skill 是维修手册,MCP 是工具箱------你不会因为有了维修手册就把扳手扔了。
Q: 有什么 Skills 的社区或资源可以推荐?
A: 我现在主要看三个来源:agentskills.io(官方规范 + 客户端列表)、github.com/anthropics/skills(官方示例)、github.com/obra/superpowers(最好的第三方 Skills 框架)。中文资源目前还比较少,这篇文章算是第一批覆盖这个话题的。
说到底,Skills 这个概念本身并不复杂------它就是把「给 AI 的说明书」做成了一个标准格式。但正是这种简单,让它有可能成为下一层技术基础设施,就像 Makefile 和 Dockerfile 曾经做的那样。
我在 2014 年第一次接触 Docker 的时候,周围大多数人的反应也是「这不就是一个轻量级虚拟机吗,有必要搞个新概念?」------十年后回头看,Docker 改变了整个行业的部署方式不是因为它的技术深度,而是因为它让「环境一致性」这件事的门槛降到了零。
Skills 有同样的潜力。它把「给 AI 提供项目上下文」这件事的门槛从「每次手写一通 prompt」或者「写一套复杂的系统配置」降到了「写一个 Markdown 文件」。这不是一个技术突破,是一个门槛突破。而门槛突破往往比技术突破更大地改变格局。
我是码哥,如果这篇文章让你对 Skills 有了一个全景式的理解,点个「在看」帮我推一推。下一篇打算把 Superpowers 的完整工作流拆一遍,跑几个真实项目看它到底能提升多少效率------关注的读者下篇能直接收到推送。身边有在用 AI 写代码但总觉得「AI 不懂我的项目」的朋友,这篇可以直接甩给他。
