频谱分析入门:从 DFT 到 FFT
这是一篇关于「混合信号 / DSP 测试」中频谱分析基础的入门博客。
我会把离散傅里叶变换(DFT)和快速傅里叶变换(FFT)背后的原理一步一步讲清楚,
并且用 Python 把每一个结论都亲手验证一遍 ------不背公式,跑代码看结果。
读完之后,你应该能回答:频谱到底是什么、它是怎么算出来的、为什么实信号的频谱是对称的、
什么是相干采样、什么是混叠、以及 SNR/THD/SINAD/SFDR 这些指标分别在量什么。
0. 为什么测试工程师离不开频谱分析
我们身边最典型的混合信号器件就是 ADC(模数转换器) 和 DAC(数模转换器)。
- 在测试中,模拟激励信号通常由**任意波形发生器(AWG)**产生,而 AWG 内部就是一个 DAC:先用数学方法算出一串数字样本,再把它们转成模拟电压。
- 被测的模拟信号则由数字化仪 / 采样器测量,它内部是一个 ADC:把模拟波形采样成一串数字。
也就是说,激励信号是「用数学算出来的」,测量信号是「用数学处理的」,整个流程都建立在数字信号处理(DSP) 之上------所以这类测试方法常被称为 DSP-based testing(基于 DSP 的测试)。
在 ATE(自动测试设备)领域,可以说99% 的信号分析就是频谱分析。而把一段时域波形变成频谱,最核心、最常用的工具就是 DFT,以及它的「涡轮加速版」FFT。
小提醒:在 IC 设计领域,"DFT" 有时指 Design For Test(可测试性设计)。本文里 DFT 始终指 Discrete Fourier Transform(离散傅里叶变换),别搞混了。
下面我们从「一个实数正弦信号」开始,一步步搭出 DFT。
1. 实信号 = 一对共轭旋转矢量
测试里我们处理的信号都是实数。一个正弦信号通常写成:
x ( t ) = A cos ( ω t + φ ) x(t) = A\cos(\omega t + \varphi) x(t)=Acos(ωt+φ)
它是实数。但有一个非常关键的恒等式(欧拉公式)能把它拆成两个复数之和:
A cos ( ω t + φ ) = A 2 e + j ( ω t + φ ) + A 2 e − j ( ω t + φ ) (1) A\cos(\omega t + \varphi) = \frac{A}{2}e^{+j(\omega t+\varphi)} + \frac{A}{2}e^{-j(\omega t+\varphi)} \tag{1} Acos(ωt+φ)=2Ae+j(ωt+φ)+2Ae−j(ωt+φ)(1)
这个式子的几何意义是:一个实数余弦信号 = 一对旋转矢量的和。
- 一个矢量以角速度 + ω +\omega +ω 向正方向旋转;
- 另一个以 − ω -\omega −ω 向负方向旋转。
- 当 ω = 2 π f \omega = 2\pi f ω=2πf 时,这对矢量对应的频率分别是 + f +f +f 和 − f -f −f。
- 这两个矢量用复数 A 2 e + j ( ω t + φ ) \frac{A}{2}e^{+j(\omega t+\varphi)} 2Ae+j(ωt+φ) 和 A 2 e − j ( ω t + φ ) \frac{A}{2}e^{-j(\omega t+\varphi)} 2Ae−j(ωt+φ) 表示,它们永远互为共轭。
两个共轭复数相加,虚部正好抵消,结果回到实数------这正是实信号能写成式 (1) 的原因。
结论:实信号的频谱一定是「复共轭对称」的------正频率分量和负频率分量的实部相等、虚部大小相等但符号相反。这是后面所有内容的基石。
我们用 Python 直接看一眼:左边是时域 3 周期余弦,右边是它的双边频谱,能量恰好分布在 + 3 +3 +3 和 − 3 -3 −3 两个 bin 上,且高度相等(各为 A / 2 = 0.5 A/2 = 0.5 A/2=0.5)。
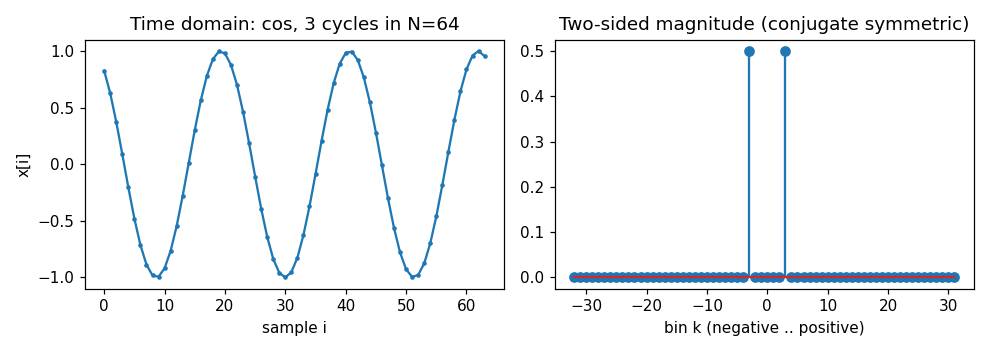
2. 频谱分析的本质:相关运算(correlation)
「频谱」回答的问题是:测试信号里各个频率成分各占多少?
换个说法,频率分析等价于把信号和各个「标准频率成分」做相关运算------信号里含某个频率越多,它和那个频率的参考波形相关性就越强。
2.1 一个观测周期里能装下多少个频率?
我们把一段观测窗口叫做 UTP(Unit Test Period,单位测试周期) 。假设 UTP 里有 N N N 个采样点,那么:
- 它能容纳的正弦波周期数,从 1 个周期一直到 ( N / 2 − 1 ) (N/2-1) (N/2−1) 个周期;
- 如果把正频率和负频率都算上,范围是 − ( N / 2 − 1 ) -(N/2-1) −(N/2−1) 到 ( N / 2 − 1 ) (N/2-1) (N/2−1),再加上 0 周期(DC 直流 )和位于 N / 2 N/2 N/2 的奈奎斯特分量,总数恰好是 N N N;
- 这中间大多数分量其实都是「一对余弦 + 正弦」波形(而 DC 和奈奎斯特这两根是纯实数的特例)。
「总数恰好 N N N」不是巧合:我们有 N N N 个采样点( N N N 个已知实数),频域里就对应 N N N 个独立的实数自由度,所以最多能解出 N N N 个独立的频率系数------不多也不少。
2.2 一个 bin 是怎么算出来的(以 bin #3 为例)
假设我们要求出第 3 个 bin(3 周期成分)的频谱,做法是:
- bin #0(DC) :把信号所有样本直接求和再求平均,得到的均值就是直流分量,对应 bin #0。
- bin #3 实部 :取「3 周期余弦」参考波,逐点乘以测试信号,再求平均 ------这个平均值就是 bin #3 的实部。
- bin #3 虚部 :取「3 周期正弦」参考波,逐点相乘再求平均(取负号)------这就是 bin #3 的虚部。
一句话记住:用余弦相关得到实部,用正弦相关得到虚部。
下图复现了这个过程:(a) 是测试信号,(b) 是 3 周期的参考余弦/正弦,©/(d) 是逐点相乘后的波形,红色虚线是它们的平均值------这两个平均值就构成了 bin #3 的复数频谱。
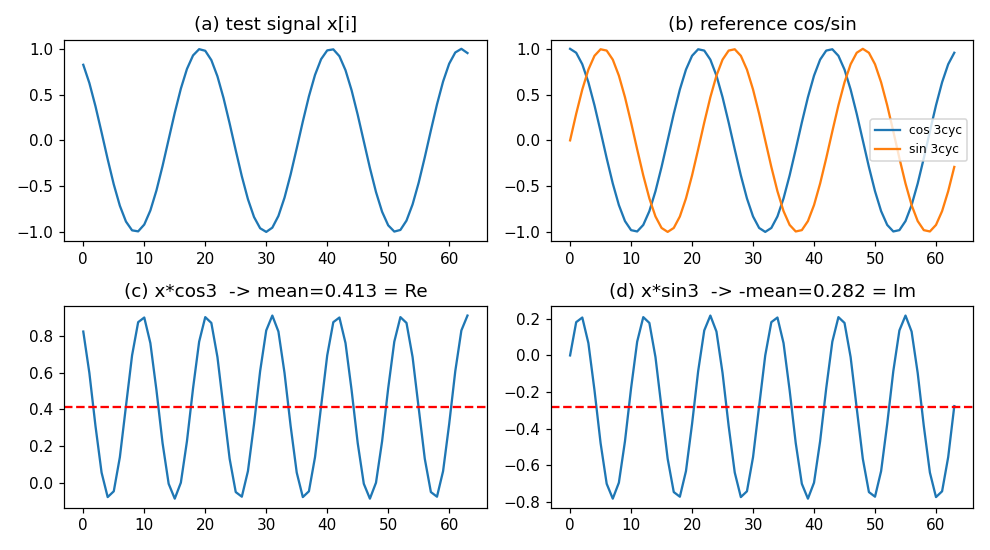
把这件事对所有 bin 各做一遍,就得到了完整频谱。因为是实信号,结果必然呈现第 1 节说的共轭对称形状。
3. 写出 DFT 的定义式
把上面的「相关运算」用一个公式概括,就是 DFT 的定义:
X k = 1 N ∑ i = 0 N − 1 x i cos ( 2 π i k N ) − j sin ( 2 π i k N ) (2) X_k = \frac{1}{N}\sum_{i=0}^{N-1} x_i \left\\cos\\!\\left(\\frac{2\\pi i k}{N}\\right) - j\\sin\\!\\left(\\frac{2\\pi i k}{N}\\right)\\right \tag{2} Xk=N1i=0∑N−1xicos(N2πik)−jsin(N2πik)(2)
其中:
- k = − N / 2 到 ( N / 2 − 1 ) k = -N/2 \ \text{到}\ (N/2-1) k=−N/2 到 (N/2−1),是频率 bin 的编号;
- { x i } \{x_i\} {xi} 是时域里采样得到的离散数据序列, N N N 是它的长度;
- X k X_k Xk 是「余弦/正弦参考波乘上数据后求得的均值」, { X k } \{X_k\} {Xk} 这个序列就代表了信号的频谱。
注意式 (2) 里那个 1 N \frac{1}{N} N1 ------它就是「求平均」这一步。(提醒:很多库如 NumPy 的 fft 不带 1 / N 1/N 1/N,需要自己除,详见下面验证。)
3.1 自己手写一个 DFT
DFT 的定义如此简单,你完全可以自己写一个。下面是按式 (2) 直白翻译出来的 Python 版本(逻辑等价于经典的双重 for 循环实现):
python
import numpy as np
def my_dft(x):
N = len(x)
X = np.zeros(N, dtype=complex)
p = 2.0 * np.pi / N
for k in range(N): # 遍历每个频率 bin
re = 0.0
im = 0.0
for i in range(N): # 对每个样本做相关求和
q = i * k * p
re += x[i] * np.cos(q) # 余弦相关 -> 实部
im -= x[i] * np.sin(q) # 正弦相关 -> 虚部(注意负号)
X[k] = (re + 1j * im) / N # 除以 N = 求平均
return X编程小技巧:理论上 k k k 从 − N / 2 -N/2 −N/2 到 N / 2 − 1 N/2-1 N/2−1,但程序里让 k k k 从 0 0 0 到 N − 1 N-1 N−1 更省事。
因为 − π -\pi −π 到 + π +\pi +π 区间的正弦波形,和 0 0 0 到 2 π 2\pi 2π 的完全等价。
代价是:频谱的左右两半被对调了 ------下标 N / 2 N/2 N/2 到 N − 1 N-1 N−1 这一段,实际对应的是「负频率」部分。
3.2 验证:手写 DFT == NumPy FFT,且满足共轭对称、Parseval 能量守恒
python
N, M, A, phi = 64, 3, 1.0, 0.4
i = np.arange(N)
x = A * np.cos(2*np.pi*M*i/N + phi) # 相干的 3 周期余弦
X_mine = my_dft(x)
X_np = np.fft.fft(x) / N # NumPy 不带 1/N,需手动除
print(np.max(np.abs(X_mine - X_np))) # 两者是否一致实际跑出来的结果(节选):
1) my_dft vs numpy.fft (max abs diff): 3.5e-15 # 和 NumPy 完全一致
2) 共轭对称 X[k]==conj(X[N-k]) 最大误差: 3.7e-15
bin#3 real=0.4605 imag=+0.1947
bin#N-3 real=0.4605 imag=-0.1947 # 实部相等、虚部反号 -> 印证第1节
3) bin0 用求平均得到的 DC == X[0].real
bin3 用 cos 相关得到的实部 == X[3].real
bin3 用 sin 相关得到的虚部 == X[3].imag # 印证第2节
4) 还原出的幅度 = 1.0 (真值 A=1.0),相位 = 0.4 (真值 phi=0.4)
5) mean(x^2)=0.5 sum|X|^2=0.5 # Parseval:时域能量 == 频域能量四件事一次性被证实:
- 手写 DFT 和成熟库结果完全一致(误差是浮点级 10 − 15 10^{-15} 10−15);
- 实信号频谱确实共轭对称;
- bin 的实部/虚部确实就是余弦/正弦相关的平均值;
- 时域总能量 = 频域总能量(Parseval 定理)。
3.3 只算左半边就够了:幅度与相位
既然 X k X_k Xk 和 X N − k X_{N-k} XN−k 互为共轭,右半边完全是冗余的 ,可以由左半边推出来。所以做频谱分析时,只保留 bin #0 到 bin # ( N / 2 − 1 ) (N/2-1) (N/2−1) 这左半边就足够了。
在「半边模式」里,人们通常不看实部/虚部,而是看更直观的幅度 和相位:
∣ X k ∣ half = 2 R e 2 + I m 2 , ϕ k = atan2 ( I m , R e ) |X_k|_{\text{half}} = 2\sqrt{\mathrm{Re}^2 + \mathrm{Im}^2}, \qquad \phi_k = \operatorname{atan2}(\mathrm{Im}, \mathrm{Re}) ∣Xk∣half=2Re2+Im2 ,ϕk=atan2(Im,Re)
注意那个 系数 2 :因为我们把右半边(负频率)的能量丢掉了,需要把幅度翻倍,才能让单边谱的总功率和双边谱保持一致。这也正是频谱分析仪上常见的显示方式。
上面验证里 还原出的幅度 = 1.0、相位 = 0.4 正好等于我们设定的 A A A 和 φ \varphi φ,说明这套「幅度翻倍 + atan2 求相位」是对的。
3.4 小结:DFT 能告诉你什么
DFT 就是 3.1 那段简单的数据处理,但它能给出测试信号的全部信息:
- 含有哪些频率成分;
- 每个成分的幅度 和相位;
- 进而看出信号中的失真、噪声、杂散(spurious)。
对要和混合信号打交道的应用工程师来说,DFT/FFT 是必须吃透的工具:知道它在算什么、怎么算、有哪些限制。
4. 从 DFT 到 FFT:同样的结果,快几百倍
DFT 的过程很简单,但你注意到 3.1 的代码里是双重循环 ------外层 N N N 个 bin,内层 N N N 个样本,总运算量正比于 N 2 N^2 N2。数据量一大,处理时间就「爆炸」。
FFT(Fast Fourier Transform,快速傅里叶变换) 就是为解决这个问题诞生的:它把数据点数限制为 2 n 2^n 2n (2 的整数次幂),利用对称性把重复计算合并,得到一个极快、极高效的 DFT 算法。运算量从 O ( N 2 ) O(N^2) O(N2) 降到 O ( N log N ) O(N\log N) O(NlogN)。
FFT 算出来的结果和 DFT 完全一样,只是快得多。 我们用 4096 点验证:
python
import time
N = 4096 # = 2^12
x = np.random.randn(N)
def naive_dft(x): # O(N^2) 矩阵实现
n = np.arange(len(x)); k = n.reshape(-1, 1)
return np.exp(-2j*np.pi*k*n/len(x)) @ x
Xd = naive_dft(x) # 朴素 DFT
Xf = np.fft.fft(x) # FFT
print(np.max(np.abs(Xd - Xf))) # 结果是否一致实测输出:
1) FFT vs DFT max diff: 2.3e-10 # 结果一致(浮点误差级别)
naive DFT time: 0.5723s | FFT time: 0.003041s | speedup ~188x同样 4096 点,朴素 DFT 用了约 0.57 秒,FFT 只用 0.003 秒,快了约 188 倍------而且点数越多,差距越夸张。这就是为什么实际测试里几乎总是用 FFT。
一个实用区别:FFT 类算法都要求输入是 2 n 2^n 2n 点 。如果由于某种原因你没法凑齐 2 n 2^n 2n 个点,那就只能退回到通用 DFT(任意点数都行,但慢),或者只算少数几个你关心的 bin(比如基波和 2、3 次谐波),来避免漫长的全谱计算。
5. 看懂一张频谱图:关键量与坐标
要读懂频谱,先认识几个关键量:
| 符号 | 含义 |
|---|---|
| F s F_s Fs | 采样 / 数字化频率(sampling frequency) |
| N N N | 总采样点数 |
| F t F_t Ft | 测试信号频率 |
| M M M | UTP 内正弦波的周期数(cycles) |
| UTP | 单位测试周期,也就是观测时长 |
| F r e s l n F_{resln} Fresln | 频率分辨率,即bin 间距 |
5.1 时域和频域的对应关系
- 时域:一段 UTP 里采了 N N N 个点,其中恰好包含 M M M 个完整周期的正弦波;
- 频域:频谱共有 N / 2 N/2 N/2 个 bin ,下标从 0 开始;
- bin #0 = DC(直流);
- bin 间距(频率分辨率)= UTP 的倒数 ,即 F r e s l n = 1 / UTP = F s / N F_{resln} = 1/\text{UTP} = F_s/N Fresln=1/UTP=Fs/N;
- 最后一个 bin 是 bin # ( N / 2 − 1 ) (N/2-1) (N/2−1);
- 信号谱线就落在 bin # M M M 上。
请把这几个量的关系刻进脑子里: F t , F s , M , N , UTP , F r e s l n F_t,\ F_s,\ M,\ N,\ \text{UTP},\ F_{resln} Ft, Fs, M, N, UTP, Fresln。它们之间满足
F t = M ⋅ F r e s l n = M ⋅ F s N . F_t = M\cdot F_{resln} = M\cdot\frac{F_s}{N}. Ft=M⋅Fresln=M⋅NFs.
6. 相干采样(Coherent Sampling):DSP 测试的铁律
时域图里,「 N N N 个点中恰好装下整数个 M M M 周期」这件事,可以写成一个极其重要的条件:
F t F s = M N (相干条件) \frac{F_t}{F_s} = \frac{M}{N} \tag{相干条件} FsFt=NM(相干条件)
这叫 相干条件(coherent condition) ,在 DSP-based 测试里至关重要。其中:
- M M M 和 N N N 都是整数;
- 而且 M M M 和 N N N 没有公约数(互质,mutually prime)。
为什么要互质?因为如果 M M M 和 N N N 有公约数,那实际被采到的不同相位点就会重复,等效采样点变少,浪费了分辨率。互质能保证 N N N 个采样点落在正弦波一个周期内 N N N 个互不相同的相位上。
满足相干条件 时,信号能量会干净地落在单一 bin(bin #M) 上;不满足时,能量会「泄漏(leakage)」到周围一大片 bin,把弱小的谐波/杂散淹没掉。
我们用 1024 点验证。相干情形取 M = 29 M=29 M=29( gcd ( 29 , 1024 ) = 1 \gcd(29,1024)=1 gcd(29,1024)=1,互质);非相干情形故意取 29.5 个周期:
python
N = 1024; i = np.arange(N)
xc = np.cos(2*np.pi*29.0*i/N) # 相干:29 个完整周期
xn = np.cos(2*np.pi*29.5*i/N) # 非相干:29.5 个周期输出:
2) gcd(M=29, N=1024) = 1 # ==1 即互质/相干
coherent : peak at bin 29 | bins above -60dB = 1 # 能量集中在 1 个 bin
noncoherent (29.5 cyc): bins above -60dB = 513 # 泄漏到 500 多个 bin!左图(相干)是一根干净的谱线;右图(非相干)能量糊成一片,这就是频谱泄漏:
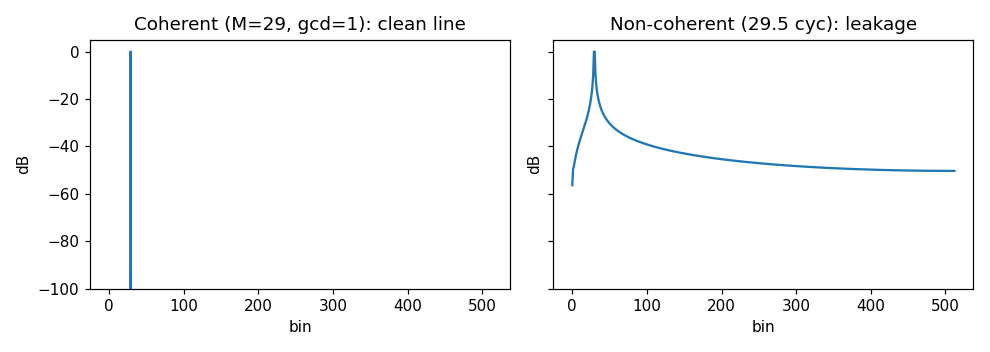
后续还有专门讨论:相干条件、加窗(windowing)、欠采样(under-sampling)等。加窗正是用来「抢救」非相干情况的手段,本文不展开。
7. 奈奎斯特定理与混叠(Aliasing)
频谱分析有一条物理底线------奈奎斯特(Nyquist)定理:
测试信号频率 F t F_t Ft 必须限制在 F s / 2 F_s/2 Fs/2 以内。
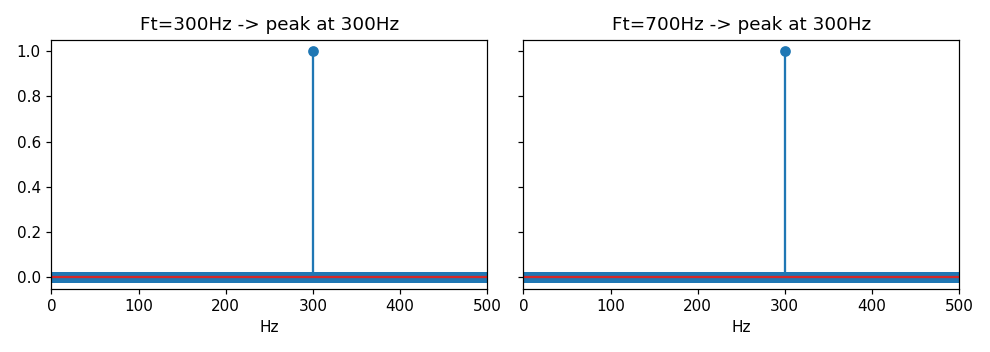
如果 F t > F s / 2 F_t > F_s/2 Ft>Fs/2,信号频谱就会混叠(aliased) ,「折叠」回到基带( 0 ∼ F s / 2 0 \sim F_s/2 0∼Fs/2)里,于是你丢失了真实的频率信息 。这种 F t > F s / 2 F_t > F_s/2 Ft>Fs/2 的情形被称为欠采样(under-sampling)------它在混合信号测试里其实是一种重要而有趣的方法(有专门文章讨论),但前提是你要知道它在发生。
验证: F s = 1000 Hz F_s = 1000\,\text{Hz} Fs=1000Hz(奈奎斯特 = 500 Hz),故意送一个 700 Hz 的音调进去:
python
Fs, N = 1000.0, 1000
n = np.arange(N)
xs = np.cos(2*np.pi*700*n/Fs) # 700Hz 超过 500Hz 奈奎斯特
f = np.fft.rfftfreq(N, 1/Fs)
print(f[np.argmax(np.abs(np.fft.rfft(xs)))]) # 它出现在哪里?输出:
3) Nyquist=500Hz, true Ft=700Hz -> appears (aliased) at 300Hz # 折叠到 300Hz700 Hz 的信号冒充 成了 300 Hz( ∣ 700 − 1000 ∣ = 300 |700-1000|=300 ∣700−1000∣=300)。如果事先不知道,你会误以为被测件有一个 300 Hz 的成分------这就是混叠的陷阱。下图左边是正常的 300 Hz,右边是 700 Hz 折叠后的「假 300 Hz」,频谱图上看起来一模一样:
8. 频谱里的术语:基波、谐波、杂散、SFDR
看一张典型频谱图,要能叫出各部分的名字:
- 基波(fundamental) :最突出的那根谱线,就是测试信号本身,位于 bin # M M M。
- 谐波(harmonics) :如果被测件线性度不完美,会在 M M M 的整数倍 位置出现失真------bin # 2 M 2M 2M 是二次谐波,bin # 3 M 3M 3M 是三次谐波,以此类推。
- 杂散(spurious / spurs):那些既不是基波、也不落在谐波位置的、比较显眼的噪声谱线。
- 其余的谱线基本上就是噪声。
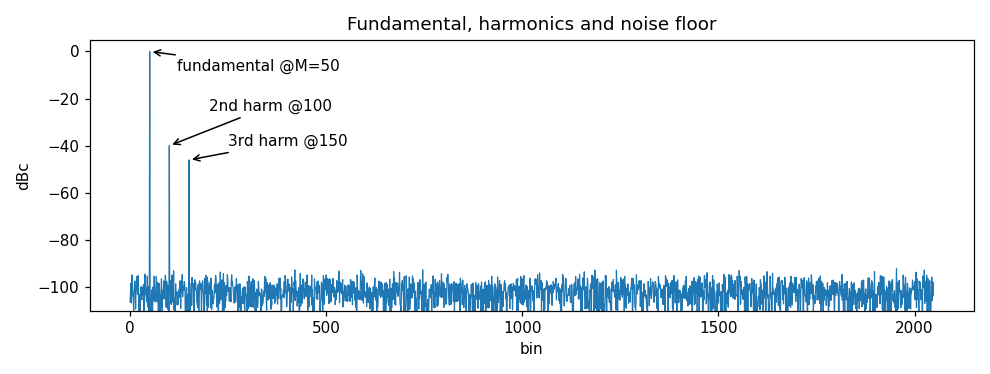
SFDR(Spurious Free Dynamic Range,无杂散动态范围) 是频谱分析里的关键指标之一:
SFDR = 基波电平 到 最大杂散电平 之间的幅度差。
这个「最大杂散」可能包含也可能不包含谐波失真 ,取决于器件规格定义。如果被测件是 ADC,SFDR 有时会以满量程电平 而非基波电平作参考------单位会写成 [dBFS](相对满量程)或 [dBc](相对载波/基波)来表明定义。
9. 功率与四大指标:SINAD、THD、SNR、SFDR
频谱图通常以 dB 显示。计算这类「比值型」指标时,本质上是在算功率比。
如果某根 bin 的幅度(电压维度)记为 V ( bin# ) V(\text{bin\#}) V(bin#),那么:
- 信号功率 = V ( M ) 2 = V(M)^2 =V(M)2(基波那根)
- 谐波功率 = V ( 2 M ) 2 + V ( 3 M ) 2 + ... = V(2M)^2 + V(3M)^2 + \dots =V(2M)2+V(3M)2+...(各次谐波之和)
- 噪声功率 = = = 除 DC 和基波外其余所有 bin 的 V 2 V^2 V2 之和
提示:dB 是功率比的对数,对电压而言 dB = 20 log 10 ( ⋅ ) \text{dB} = 20\log_{10}(\cdot) dB=20log10(⋅),对功率而言 dB = 10 log 10 ( ⋅ ) \text{dB} = 10\log_{10}(\cdot) dB=10log10(⋅)。
四个核心指标的定义(都是功率比):
| 指标 | 全称 | 定义 | 单位 |
|---|---|---|---|
| SINAD (SND) | Signal to Noise And Distortion | 信号功率 ÷ 除基波外的全部噪声功率(含谐波) | dB |
| THD | Total Harmonic Distortion | 总谐波功率 ÷ 信号功率 | dB(音频里也用 %) |
| SNR | Signal to Noise Ratio | 信号功率 ÷ 不含谐波的噪声功率 | dB |
| SFDR | Spurious Free Dynamic Range | 基波 到 最大杂散 的幅度差(见第 8 节) | dB |
⚠️ 特别注意 SNR 和 SINAD 的区别:
- "SNR" 这个词经常被当作 SINAD 的同义词,很容易混淆。
- 一般约定:当 SINAD 和 SNR 同时给出 时,SNR 不包含谐波;
- 如果规格里只给了 SNR、没给 SINAD,那这个 SNR 多半就等同于 SINAD(即包含谐波)。
- 用之前一定先确认它的定义。
我们造一个带 2、3 次谐波和少量噪声的信号来验证这几个指标:
python
N, M = 4096, 50
i = np.arange(N)
sig = (np.cos(2*np.pi*M*i/N)
+ 0.01 *np.cos(2*np.pi*2*M*i/N) # 二次谐波,相对基波 -40 dB
+ 0.005*np.cos(2*np.pi*3*M*i/N)) # 三次谐波
sig += 0.0003*np.random.default_rng(0).standard_normal(N) # 少量噪声
X = np.fft.rfft(sig)/N; m = np.abs(X); m[1:] *= 2; p = m**2
fund = p[M]
harm = p[2*M] + p[3*M] + p[4*M] + p[5*M]
total = np.sum(p[1:]) - fund # 除 DC、基波外的全部
noise = total - harm # 再去掉谐波
print(10*np.log10(harm/fund), 10*np.log10(fund/total),
10*np.log10(fund/noise))输出:
6) THD=-39.0 dB SINAD=39.0 dB SNR=67.5 dB SFDR=40.0 dB
(2nd harmonic 0.01 -> 20log10(0.01)= -40 dBc check)注意几点能互相印证的地方:
- 二次谐波幅度设为 0.01,理论上是 20 log 10 ( 0.01 ) = − 40 dBc 20\log_{10}(0.01)=-40\,\text{dBc} 20log10(0.01)=−40dBc,而测出的 SFDR ≈ 40 dB(最大杂散正是这根二次谐波)------吻合;
- THD ≈ -39 dB:总谐波功率略大于单根二次谐波(还叠加了三次),合理;
- SINAD(39 dB)远小于 SNR(67.5 dB):因为 SINAD 把谐波也算进「坏成分」,而 SNR 不算谐波------完美体现了第 9 节强调的定义差异。
10. 计算 SNR 时的三个坑
SNR 看着简单,实际算的时候有几个必须注意的点。
10.1 定义:到底等不等于 SINAD?
如第 9 节所说,先问自己:这个 SNR 含不含谐波?查规格、对定义,别想当然。
10.2 计算噪声的带宽(over-sampling 的妙用)
通常计算 SNR 会把整个奈奎斯特带宽 都算进去,也就是 bin 1 到 bin ( N / 2 − 1 ) (N/2-1) (N/2−1)。但实际关心的带宽可能远小于奈奎斯特带宽。
举个例子:音频 DVD 的采样率是 48 kHz,对应奈奎斯特带宽 24 kHz。如果我们用一个采样率 768 kHz 的数字化仪去测一个音频 DVD 的 DAC,那么噪声会分布在 DC 到 384 kHz 这么宽的范围里。但我们真正关心的频带只有 24 kHz。
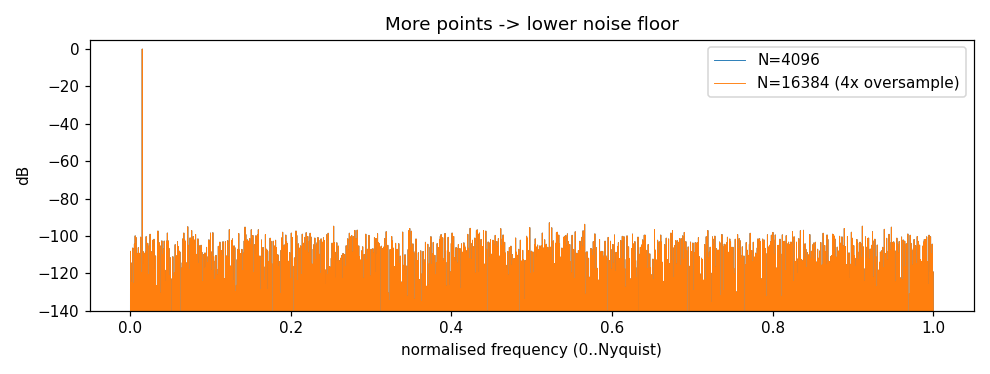
于是我们可以只统计 24 kHz 以内的噪声功率 ,而不是 384 kHz 全带宽------这样算出的 SNR 会好上好几 dB 。这就是 过采样(over-sampling)。
原理:量化噪声的总功率是固定的,点数越多、带宽越宽,这些噪声就被「摊」得越薄,单位带宽里的噪声底就越低。 当你只在感兴趣的窄带里收集噪声时,自然就少算了大量带外噪声,从而获得更大的动态范围、看见更小的信号。代价是:点数变多 → 数据上传和处理时间变长。
理想 n n n 位 ADC 的量化噪声 SNR 有个著名公式:
SNRdB = 6.02 n + 1.76 \text{SNRdB} = 6.02\,n + 1.76 SNRdB=6.02n+1.76
这个值只取决于位数 n n n,和采样率无关(在 (a) 48 ksps 常规采样 和 (b) 768 ksps 过采样 下,基于量化噪声的总 SNR 是一样的)。先验证这个公式:
python
def adc_snr(nbits, N=2**14, M=127):
i = np.arange(N); full = 2**(nbits-1) - 1
sig = full * np.cos(2*np.pi*M*i/N) # 满量程、相干
q = np.round(sig) # 理想均匀量化
X = np.fft.rfft(q)/N; m = np.abs(X); m[1:] *= 2; p = m**2
return 10*np.log10(p[M] / (np.sum(p) - p[0] - p[M]))
for nb in (8, 12, 16):
print(nb, adc_snr(nb), 6.02*nb + 1.76)输出:
4) 8-bit: measured SNR=49.95 dB | theory 6.02n+1.76=49.92 dB
4) 12-bit: measured SNR=74.03 dB | theory 6.02n+1.76=74.00 dB
4) 16-bit: measured SNR=98.05 dB | theory 6.02n+1.76=98.08 dB实测和理论公式几乎完全重合。再验证过采样能在固定关心带宽内提升 SNR------同一个信号,把采样点数变成 4 倍,噪声只统计到原来的带宽:
5) full-band SNR N=4096 : 74.09 dB
same band, oversampled N=16384, noise counted only up to old band: 80.16 dB提升了约 6 dB ------这正好等于 4 倍过采样的理论增益 10 log 10 ( 4 ) ≈ 6.02 dB 10\log_{10}(4)\approx6.02\,\text{dB} 10log10(4)≈6.02dB。下图能直观看到:点数翻 4 倍后,噪声底整体下移:
10.3 加权滤波器(Weighting Filter)
这是一种行业惯例,尤其在音频领域:在算 SNR 前对频谱施加一个特定的加权曲线,常见的有:
- A-weighting:常用于普通音频器件;
- C-message 和 psophometric(嗜音计权):常用于电信音频器件,比如电话 PCM CODEC。
加权一般能让 SNR 数值「好看」约 2~3 dB 。反过来说,如果规格要求加权而你忘了加,测出来的结果就会白白损失 2~3 dB。加权的本质是模拟人耳/电话系统对不同频率噪声的敏感度------对人耳不敏感的频段的噪声「打个折」再统计。
11. 关于「平均(Averaging)」的重要原则
平均通常是获得稳定、可靠结果的好习惯------但对 SNR/噪声测量是个例外。
- SNR 是一种噪声测量,而噪声是随机现象。 如果你对噪声测量做平均,平均次数越多,随机噪声被抵消得越多,SNR 就越「好看」------但这是虚假的改善 。所以不要对噪声 / SNR 测量做平均。
- 相反,THD 和 SFDR 可以做平均 。因为失真(谐波)和杂散不是随机现象 ,它们的位置和大小是确定的;做平均只是去掉了叠加在上面的随机噪声波动,让结果更可重复,而不会人为抬高指标。
记忆口诀:随机的(噪声/SNR)别平均,确定的(THD/SFDR)可以平均。
12. 频谱显示的几种常见标度
实际显示频谱时,常见有这么几种纵轴标度,理解它们能帮你看懂任何一张频谱图:
- 线性电压谱(VOLT) :每根谱线直接显示该成分的电压值,纵轴是伏特。适合直观看各分量的绝对幅度。
- dB 谱(自动参考) :纵轴是 dB。常见做法是自动找出(DC 以外)最大的那根谱线,把它设为 0 dB 参考,其余谱线相对它表示------这样基波永远在 0 dB,方便读各成分相对基波低多少 dBc。
- dB 谱(指定参考电平) :当器件有一个明确的 0 dB 参考时,可以手动指定参考值。
- 例:在 50 Ω 负载上,0 dBm 对应的电压约为 0.3162 V 。把它设为参考,频谱就以 dBm 显示。(推导: 0 dBm = 1 mW 0\,\text{dBm}=1\,\text{mW} 0dBm=1mW, V r m s = P ⋅ R = 0.001 × 50 ≈ 0.2236 V V_{rms}=\sqrt{P\cdot R}=\sqrt{0.001\times50}\approx0.2236\,\text{V} Vrms=P⋅R =0.001×50 ≈0.2236V,对应峰值 ≈ 0.3162 V \approx0.3162\,\text{V} ≈0.3162V。)
- 相对满量程(dBFS) :测 ADC 时常用。例如一个 8 位线性 ADC,理论满量程大小为 255 / 2 = 127.5 255/2 = 127.5 255/2=127.5,把这个值设为参考,频谱就显示相对满量程的幅度。当输入是满量程信号时,基波正好落在 0 dB。
无论哪种标度,背后的频谱数据都是同一份------只是参考点和纵轴单位的选择不同。
13. 术语速查表
| 缩写 | 全称 | 中文 |
|---|---|---|
| DFT | Discrete Fourier Transform | 离散傅里叶变换 |
| FFT | Fast Fourier Transform | 快速傅里叶变换 |
| IFFT | Inverse Fast Fourier Transform | 逆快速傅里叶变换 |
| ADC | Analog to Digital Converter | 模数转换器 |
| DAC | Digital to Analog Converter | 数模转换器 |
| AWG | Arbitrary Waveform Generator | 任意波形发生器 |
| DSP | Digital Signal Processing/Processor | 数字信号处理(器) |
| DUT | Device Under Test | 被测器件 |
| UTP | Unit Test Period | 单位测试周期(观测时长) |
| SFDR | Spurious Free Dynamic Range | 无杂散动态范围 |
| SINAD (SND) | Signal to Noise And Distortion ratio | 信纳比(信号/噪声+失真) |
| THD | Total Harmonic Distortion | 总谐波失真 |
| SNR | Signal to Noise Ratio | 信噪比 |
14. 总结
把全文串成一条主线:
- 实信号 A cos ( ω t + φ ) A\cos(\omega t+\varphi) Acos(ωt+φ) 可拆成一对共轭旋转矢量 ,所以它的频谱天生共轭对称。
- 频谱分析的本质是相关运算 :用余弦相关得实部、正弦相关得虚部、求平均得 DC------把这件事公式化就是 DFT(式 2)。
- DFT 是 O ( N 2 ) O(N^2) O(N2) 的双重循环;限定点数为 2 n 2^n 2n 后得到 O ( N log N ) O(N\log N) O(NlogN) 的 FFT,结果一样但快几百倍。
- 看频谱要掌握 F t , F s , M , N , UTP , F r e s l n F_t, F_s, M, N, \text{UTP}, F_{resln} Ft,Fs,M,N,UTP,Fresln 的关系;信号落在 bin # M M M,bin 间距 = F s / N =F_s/N =Fs/N。
- 相干采样 ( F t / F s = M / N F_t/F_s=M/N Ft/Fs=M/N, M , N M,N M,N 互质)让能量集中在单 bin,否则会泄漏。
- 奈奎斯特定理 : F t < F s / 2 F_t<F_s/2 Ft<Fs/2,否则混叠。
- 四大指标 SINAD / THD / SNR / SFDR 都是功率比,关键是搞清 SNR 含不含谐波。
- 算 SNR 三个坑:定义、带宽(过采样 可在窄带获得更高 SNR)、加权;以及------噪声测量不要做平均。
最重要的一点:这些结论没有一个需要死记。本文每一条都附了十几行 Python,你完全可以自己改参数、跑一遍、看结果。把 NumPy 当成你的「数字示波器 + 频谱仪」,DSP 测试的原理就会从公式变成你手里能拨弄的东西。
附:本文所有验证代码见
verify_dft.py、verify_fft.py,配图生成脚本见make_figs.py,均可直接运行复现。