对应教材:陈封能《数据挖掘导论》第3章(扩展)
核心问题:如何用决策树的方法预测连续数值(如房价、温度、销售额)?
一、从分类到回归:目标变了!
1.1 分类树 vs 回归树 ------ 一张表看懂
| 对比维度 | 分类树 | 回归树 |
|---|---|---|
| 目标变量类型 | 离散类别(如"是/否"、"猫/狗") | 连续数值(如"253,000元"、"37.5℃") |
| 树的分裂准则 | 使子节点纯度最高(信息增益↑、基尼↓) | 使子节点方差最小(均方误差↓) |
| 叶节点的输出 | 多数表决(出现最多的类别) | 该区域所有样本的平均值 |
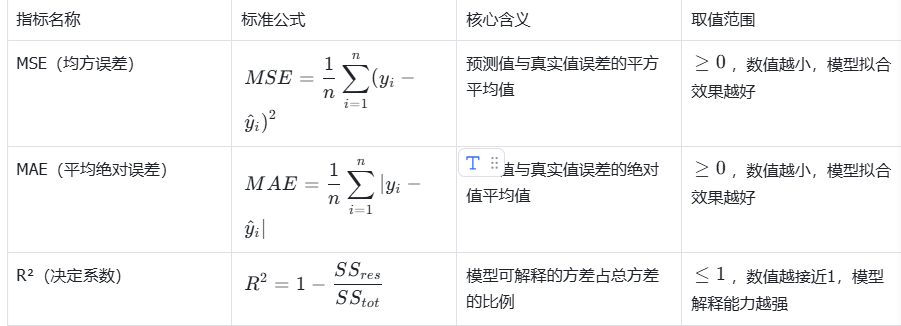
| 评估指标 | 准确率、精确率、召回率、F1、AUC | 均方误差(MSE)、平均绝对误差(MAE)、R² |
💡 一句话理解:分类树问"这是A还是B?",回归树问"这个值大概是多少?"
1.2 为什么需要回归树?线性回归不够用
-
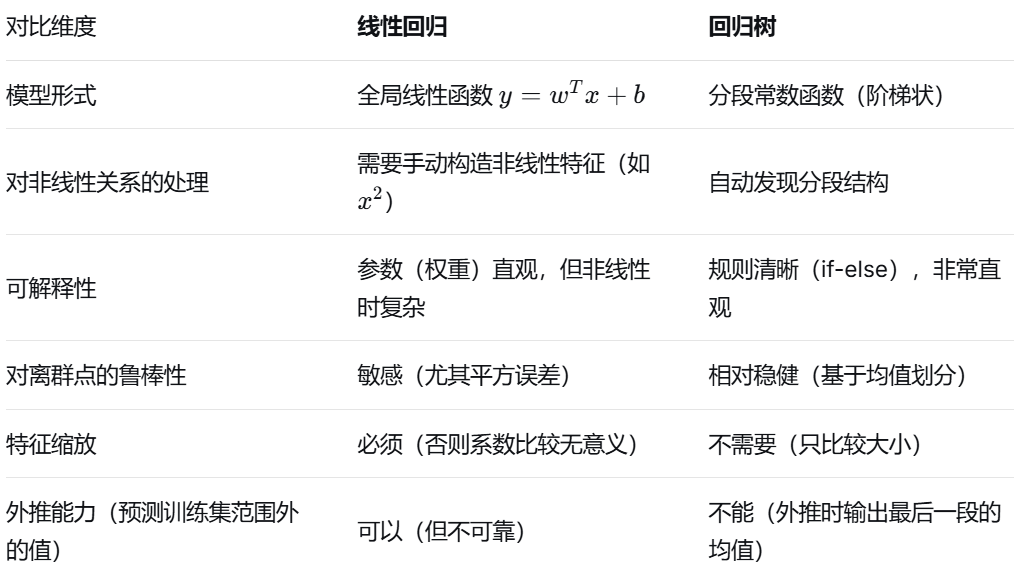
线性回归的局限:假设数据是直线关系,但真实世界往往是非线性的(如房价与面积:小面积时单价高,中等面积性价比高,豪宅单价再次飙升)。
-
回归树的优势:
-
自动发现数据中的分段结构(如"面积<50㎡"一个规则,"50-120㎡"另一个规则,">120㎡"又一个规则)。
-
无需手动做特征工程(如不用自己去构造面积平方项)。
-
模型结果易于解释(相当于一系列 if-else 规则)。
-
-
典型应用:房价预测、医疗费用估算、广告点击率预测、库存需求预测。
二、回归决策树的核心原理
2.1 问题定义

2.2 如何找到最优划分?------ 平方误差最小化

🧠 通俗解释 :我们尝试每个特征、每个可能的分割点,计算分割后左半边的数值方差 + 右半边的数值方差。哪个分割点让这个和最小,就选哪个。
2.3 回归树生成算法(四步流程)

三、手算示例 ------ 完整过程(一维特征)
假设我们有一个特征 xx 和对应的连续目标值 yy(10个样本):
| 序号 | x | y |
|---|---|---|
| 1 | 1 | 5.56 |
| 2 | 2 | 5.70 |
| 3 | 3 | 5.91 |
| 4 | 4 | 6.40 |
| 5 | 5 | 6.80 |
| 6 | 6 | 7.05 |
| 7 | 7 | 8.90 |
| 8 | 8 | 8.70 |
| 9 | 9 | 9.00 |
| 10 | 10 | 9.05 |

3.3 所有切分点的损失值(PPT已给出)
| 切分点 s | 损失 L(s) |
|---|---|
| 1.5 | 15.72 |
| 2.5 | 12.07 |
| 3.5 | 8.36 |
| 4.5 | 5.78 |
| 5.5 | 3.91 |
| 6.5 | 1.93(最小!) |
| 7.5 | 4.05 |
| 8.5 | 7.33 |
| 9.5 | 14.71 |
最优切分点:s=6.5s=6.5,损失 = 1.93。
3.4 第一次划分结果

之后对左右子节点递归执行相同操作,得到更细的划分。
3.5 不同深度的拟合效果
-
深度=1:只有一刀 → 两个常数(6.24 和 8.91),拟合粗糙。
-
深度=3:切多刀 → 多个常数段,更接近真实数据。
-
线性回归:一条直线,无法捕捉中间突变的阶梯形状。
🔍 直观理解 :回归树相当于用分段常数去逼近任意函数。深度越深,常数段越多,拟合越精细,但也越容易过拟合。
四、剪枝与正则化(防止过拟合)
4.1 回归树的两类剪枝策略
| 策略 | 做法 | 参数示例 | 优缺点 |
|---|---|---|---|
| 预剪枝 | 生长过程中提前停止 | max_depth, min_samples_split, min_samples_leaf |
简单高效,但可能过早停止 |
| 后剪枝 | 先充分生长,再自底向上合并 | ccp_alpha(代价复杂度剪枝) |
效果更好,但计算量稍大 |
代价复杂度剪枝(CCP)原理:
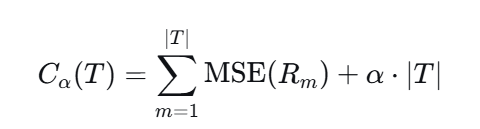
-
第一项:所有叶节点的 MSE 之和(拟合误差)
-
第二项:叶节点个数(模型复杂度惩罚)
-
αα 越大,惩罚越强,树越小。
4.2 回归树常用评估指标
五、回归树 vs 线性回归(关键对比)
实践建议:
-
先用线性回归作为基线模型(简单、快速)。
-
再用回归树,如果回归树的 MSE 显著更低,说明数据存在明显的非线性或分段结构。
-
也可以使用随机森林回归、梯度提升回归等集成方法,进一步提升效果。
六、Python 实战(sklearn 回归树)
6.1 基本代码(加州房价数据集为例)
python
from sklearn.datasets import fetch_california_housing
from sklearn.tree import DecisionTreeRegressor
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error, r2_score
# 加载数据
housing = fetch_california_housing()
X, y = housing.data, housing.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
# 创建回归树模型(限制深度防过拟合)
reg_tree = DecisionTreeRegressor(max_depth=5, random_state=42)
reg_tree.fit(X_train, y_train)
# 预测
y_pred = reg_tree.predict(X_test)
# 评估
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
print(f"MSE: {mse:.4f}, R²: {r2:.4f}")6.2 重要参数说明
| 参数 | 作用 | 常用值 |
|---|---|---|
max_depth |
最大深度 | 3~10,根据数据量调整 |
min_samples_split |
内部节点再划分所需最少样本数 | 5~20 |
min_samples_leaf |
叶节点最少样本数 | 2~10 |
ccp_alpha |
代价复杂度剪枝参数 | 通过网格搜索确定 |
6.3 特征重要性
python
importances = reg_tree.feature_importances_
for name, imp in zip(housing.feature_names, importances):
print(f"{name}: {imp:.3f}")特征重要性 = 该特征在所有分裂中减少的 MSE 之和(归一化到 0,1)。
七、本章核心总结(速记卡片)
| 概念 | 一句话解释 |
|---|---|
| 回归树 | 用 if-else 规则将特征空间分成多个矩形区域,每个区域输出均值 |
| 分裂准则 | 最小化左右子节点的**均方误差(MSE)**之和 |
| 叶节点输出 | 该区域所有样本目标值的平均值 |
| 与分类树的区别 | 目标连续 vs 离散;分裂用方差 vs 纯度 |
| 过拟合控制 | 预剪枝(限制深度) + 后剪枝(CCP) |
| 评估指标 | MSE、MAE、R² |
| 与线性回归对比 | 回归树擅长非线性、分段关系,可解释性强,但不能外推 |