- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊
文章目录
- [1. 简介 & 数据集介绍](#1. 简介 & 数据集介绍)
- [2. 环境](#2. 环境)
- [3. 代码实现](#3. 代码实现)
-
- [3.1 前期准备](#3.1 前期准备)
-
- [3.1.1 设置GPU & 导入库](#3.1.1 设置GPU & 导入库)
- [3.1.2 数据集统计与预览](#3.1.2 数据集统计与预览)
- [3.2 数据预处理](#3.2 数据预处理)
-
- [3.2.1 数据集划分与预处理](#3.2.1 数据集划分与预处理)
- [3.2.2 类别识别](#3.2.2 类别识别)
- [3.2.3 可视化](#3.2.3 可视化)
- [3.2.4 整体数据检查](#3.2.4 整体数据检查)
- [3.3 模型建立与训练](#3.3 模型建立与训练)
-
- [3.3.1 预训练模型加载](#3.3.1 预训练模型加载)
- [3.3.2 不同优化器训练](#3.3.2 不同优化器训练)
- [4. 不同优化器对比评估](#4. 不同优化器对比评估)
-
- [4.1 绘制训练集与验证集的 Accuracy 和 Loss 趋势图](#4.1 绘制训练集与验证集的 Accuracy 和 Loss 趋势图)
- [4.2 不同优化器最终模型评估表](#4.2 不同优化器最终模型评估表)
1. 简介 & 数据集介绍
利用 TensorFlow,通过构建 VGG-16 网络实现明星识别,对比四种优化器的训练效果。数据集中有 Angelina Jolie, Brad Pitt, Denzel Washington, Hugh Jackman, Jennifer Lawrence, Johnny Depp, Kate Winslet, Leonardo DiCaprio, Megan Fox, Natalie Portman, Nicole Kidman, Robert Downey Jr, Sandra Bullock, Scarlett Johansson, Tom Cruise, Tom Hanks, Will Smith 17个明星图片,每类数据 100 张左右的图片。
2. 环境
- 语言环境:Python 3.12.7
- 编译器:Jupyter Notebook
- 深度学习环境:TensorFlow 2.21.0
3. 代码实现
3.1 前期准备
3.1.1 设置GPU & 导入库
导入必要的库并配置 GPU 显存增长,以解决在 Windows 环境下可能出现的显存占用或驱动兼容性问题。
python
import tensorflow as tf
from tensorflow.keras.layers import Dropout,Dense,BatchNormalization
from tensorflow.keras.models import Model
from datetime import datetime
from matplotlib.ticker import MultipleLocator
from tensorflow import keras
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
import warnings,os,PIL,pathlib
warnings.filterwarnings("ignore")
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
gpus = tf.config.list_physical_devices("GPU")
if gpus:
gpu0 = gpus[0]
tf.config.experimental.set_memory_growth(gpu0, True)
tf.config.set_visible_devices([gpu0],"GPU")3.1.2 数据集统计与预览
通过 pathlib 扫描本地目录统计 1800 张图像。
python
data_dir = "./Data/48-data/"
data_dir = pathlib.Path(data_dir)
image_count = len(list(data_dir.glob('*/*')))
print("图片总数为:",image_count)
3.2 数据预处理
3.2.1 数据集划分与预处理
设置统一的图像尺寸(336x336)和批大小(16)。通过 image_dataset_from_directory 将数据集划分为训练集和验证集(本块为训练集,占 80%),并指定了随机种子以确保结果可复现。
python
batch_size = 16
img_height = 336
img_width = 336
train_ds = tf.keras.preprocessing.image_dataset_from_directory(data_dir, validation_split=0.2, subset="training", seed=12, image_size=(img_height, img_width), batch_size=batch_size)
采用与构建训练集完全相同的参数和随机种子(seed=123),从同一个目录中划分出剩余的20%(680 张图片)作为验证数据集,以确保训练集和验证集互不重叠,用于评估模型性能。
python
val_ds = tf.keras.preprocessing.image_dataset_from_directory(data_dir, validation_split=0.2, subset="validation", seed=12, image_size=(img_height, img_width), batch_size=batch_size)
3.2.2 类别识别
从创建好的训练数据集中提取并打印了分类的类别名称。
python
class_names = train_ds.class_names
print(class_names)
3.2.3 可视化
对数据集进行归一化处理并优化读取性能,绘制示意图。将图像像素值从 0, 255 缩放到 0, 1 之间(有助于模型收敛)。同时,使用 .cache() 在内存中缓存数据,.shuffle() 打乱顺序,以及 .prefetch() 在 GPU 训练时预先加载下一批数据,这些操作能显著提升训练速度。
python
plt.figure(figsize=(10, 8))
plt.suptitle("数据展示")
for images, labels in train_ds.take(1):
for i in range(15):
plt.subplot(4, 5, i + 1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
# 显示图片
plt.imshow(images[i])
# 显示标签
plt.xlabel(class_names[labels[i]-1])
plt.show()
3.2.4 整体数据检查
通过打印第一个批次中图像和标签的维度(shape)来验证数据结构的正确性,输出显示图像张量维度为 (16, 336, 336, 3),标签张量维度为(16,)。
python
for image_batch, labels_batch in train_ds:
print(image_batch.shape)
print(labels_batch.shape)
break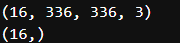
3.3 模型建立与训练
3.3.1 预训练模型加载
定义 create_model 函数,构建基于VGG16的迁移学习模型:加载预训练VGG16(不含顶层),冻结其权重;添加全连接层(170个神经元)、批归一化、Dropout和softmax输出层;编译模型,支持不同优化器。
python
def create_model(optimizer='adam'):
# 加载预训练模型
vgg16_base_model = tf.keras.applications.vgg16.VGG16(weights='imagenet',
include_top=False,
input_shape=(img_width, img_height, 3),
pooling='avg')
for layer in vgg16_base_model.layers:
layer.trainable = False
X = vgg16_base_model.output
X = Dense(170, activation='relu')(X)
X = BatchNormalization()(X)
X = Dropout(0.5)(X)
output = Dense(len(class_names), activation='softmax')(X)
vgg16_model = Model(inputs=vgg16_base_model.input, outputs=output)
vgg16_model.compile(optimizer=optimizer,
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
return vgg16_model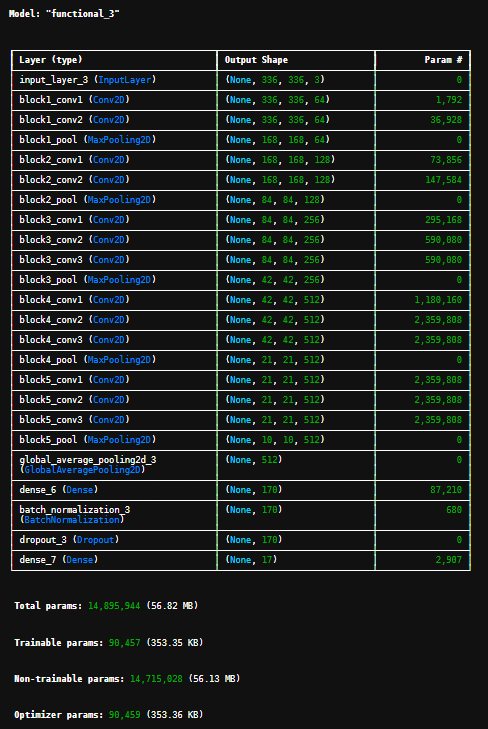
3.3.2 不同优化器训练
对四种优化器(Adam、SGD、RMSprop、Adagrad)分别训练模型,每个训练20个epoch。训练过程中输出每个epoch的loss和accuracy,以及验证集的loss和accuracy。
python
# 1. 定义优化器字典
optimizers_dict = {
'Adam': tf.keras.optimizers.Adam(),
'SGD': tf.keras.optimizers.SGD(),
'RMSprop': tf.keras.optimizers.RMSprop(),
'Adagrad': tf.keras.optimizers.Adagrad()
}
# 2. 循环创建并训练模型,将 history 存储起来
histories = {}
trained_models = {}
NO_EPOCHS = 20
for name, opt in optimizers_dict.items():
print(f"开始训练使用 [{name}] 优化器的模型...")
# 创建模型
model = create_model(optimizer=opt)
# 训练模型并将结果存入字典
history = model.fit(train_ds, epochs=NO_EPOCHS, verbose=1, validation_data=val_ds)
histories[name] = history
trained_models[name] = model
bash
开始训练使用 [Adam] 优化器的模型...
Epoch 1/20
90/90 ━━━━━━━━━━━━━━━━━━━━ 271s 3s/step - accuracy: 0.1715 - loss: 2.7549 - val_accuracy: 0.1333 - val_loss: 2.7073
Epoch 2/20
90/90 ━━━━━━━━━━━━━━━━━━━━ 276s 3s/step - accuracy: 0.3708 - loss: 2.0135 - val_accuracy: 0.2083 - val_loss: 2.4650
Epoch 3/20
90/90 ━━━━━━━━━━━━━━━━━━━━ 265s 3s/step - accuracy: 0.4389 - loss: 1.7242 - val_accuracy: 0.3028 - val_loss: 2.2385
Epoch 4/20
90/90 ━━━━━━━━━━━━━━━━━━━━ 264s 3s/step - accuracy: 0.5285 - loss: 1.4821 - val_accuracy: 0.3444 - val_loss: 2.1071
Epoch 5/20
90/90 ━━━━━━━━━━━━━━━━━━━━ 271s 3s/step - accuracy: 0.5882 - loss: 1.3217 - val_accuracy: 0.4056 - val_loss: 1.8477
Epoch 6/20
90/90 ━━━━━━━━━━━━━━━━━━━━ 286s 3s/step - accuracy: 0.6306 - loss: 1.1918 - val_accuracy: 0.4083 - val_loss: 1.8187
Epoch 7/20
90/90 ━━━━━━━━━━━━━━━━━━━━ 284s 3s/step - accuracy: 0.6660 - loss: 1.0989 - val_accuracy: 0.4889 - val_loss: 1.6662
Epoch 8/20
90/90 ━━━━━━━━━━━━━━━━━━━━ 263s 3s/step - accuracy: 0.6826 - loss: 1.0032 - val_accuracy: 0.5111 - val_loss: 1.6264
Epoch 9/20
90/90 ━━━━━━━━━━━━━━━━━━━━ 12220s 137s/step - accuracy: 0.7153 - loss: 0.9275 - val_accuracy: 0.5306 - val_loss: 1.3795
Epoch 10/20
90/90 ━━━━━━━━━━━━━━━━━━━━ 294s 3s/step - accuracy: 0.7271 - loss: 0.8463 - val_accuracy: 0.5000 - val_loss: 1.5793
Epoch 11/20
90/90 ━━━━━━━━━━━━━━━━━━━━ 241s 3s/step - accuracy: 0.7410 - loss: 0.8033 - val_accuracy: 0.4833 - val_loss: 1.6852
Epoch 12/20
90/90 ━━━━━━━━━━━━━━━━━━━━ 247s 3s/step - accuracy: 0.7681 - loss: 0.7277 - val_accuracy: 0.4722 - val_loss: 1.7769
Epoch 13/20
90/90 ━━━━━━━━━━━━━━━━━━━━ 232s 3s/step - accuracy: 0.7965 - loss: 0.6881 - val_accuracy: 0.4250 - val_loss: 1.9349
Epoch 14/20
90/90 ━━━━━━━━━━━━━━━━━━━━ 227s 3s/step - accuracy: 0.8111 - loss: 0.6251 - val_accuracy: 0.5139 - val_loss: 1.7767
Epoch 15/20
90/90 ━━━━━━━━━━━━━━━━━━━━ 223s 2s/step - accuracy: 0.8181 - loss: 0.6162 - val_accuracy: 0.4889 - val_loss: 1.7488
Epoch 16/20
90/90 ━━━━━━━━━━━━━━━━━━━━ 226s 3s/step - accuracy: 0.8410 - loss: 0.5366 - val_accuracy: 0.5278 - val_loss: 1.6702
Epoch 17/20
90/90 ━━━━━━━━━━━━━━━━━━━━ 242s 3s/step - accuracy: 0.8271 - loss: 0.5729 - val_accuracy: 0.5694 - val_loss: 1.5885
Epoch 18/20
90/90 ━━━━━━━━━━━━━━━━━━━━ 223s 2s/step - accuracy: 0.8562 - loss: 0.4837 - val_accuracy: 0.5667 - val_loss: 1.4105
Epoch 19/20
90/90 ━━━━━━━━━━━━━━━━━━━━ 230s 3s/step - accuracy: 0.8819 - loss: 0.4350 - val_accuracy: 0.5833 - val_loss: 1.5348
Epoch 20/20
90/90 ━━━━━━━━━━━━━━━━━━━━ 237s 3s/step - accuracy: 0.8674 - loss: 0.4282 - val_accuracy: 0.4722 - val_loss: 1.8784
开始训练使用 [SGD] 优化器的模型...
Epoch 1/20
90/90 ━━━━━━━━━━━━━━━━━━━━ 236s 3s/step - accuracy: 0.1028 - loss: 3.0755 - val_accuracy: 0.1167 - val_loss: 2.7552
Epoch 2/20
90/90 ━━━━━━━━━━━━━━━━━━━━ 238s 3s/step - accuracy: 0.1951 - loss: 2.5181 - val_accuracy: 0.1944 - val_loss: 2.6110
Epoch 3/20
90/90 ━━━━━━━━━━━━━━━━━━━━ 226s 3s/step - accuracy: 0.2757 - loss: 2.2528 - val_accuracy: 0.2194 - val_loss: 2.4371
Epoch 4/20
90/90 ━━━━━━━━━━━━━━━━━━━━ 230s 3s/step - accuracy: 0.3160 - loss: 2.1193 - val_accuracy: 0.2750 - val_loss: 2.2823
Epoch 5/20
90/90 ━━━━━━━━━━━━━━━━━━━━ 235s 3s/step - accuracy: 0.3674 - loss: 1.9379 - val_accuracy: 0.3694 - val_loss: 2.0557
Epoch 6/20
90/90 ━━━━━━━━━━━━━━━━━━━━ 229s 3s/step - accuracy: 0.4139 - loss: 1.8241 - val_accuracy: 0.4083 - val_loss: 1.8756
Epoch 7/20
90/90 ━━━━━━━━━━━━━━━━━━━━ 221s 2s/step - accuracy: 0.4458 - loss: 1.7117 - val_accuracy: 0.3806 - val_loss: 1.8377
Epoch 8/20
90/90 ━━━━━━━━━━━━━━━━━━━━ 218s 2s/step - accuracy: 0.4611 - loss: 1.6734 - val_accuracy: 0.4111 - val_loss: 1.7870
Epoch 9/20
90/90 ━━━━━━━━━━━━━━━━━━━━ 214s 2s/step - accuracy: 0.4833 - loss: 1.5912 - val_accuracy: 0.4417 - val_loss: 1.6708
Epoch 10/20
90/90 ━━━━━━━━━━━━━━━━━━━━ 215s 2s/step - accuracy: 0.5132 - loss: 1.5323 - val_accuracy: 0.4528 - val_loss: 1.7007
Epoch 11/20
90/90 ━━━━━━━━━━━━━━━━━━━━ 1105s 12s/step - accuracy: 0.5424 - loss: 1.4442 - val_accuracy: 0.3944 - val_loss: 1.7710
Epoch 12/20
90/90 ━━━━━━━━━━━━━━━━━━━━ 207s 2s/step - accuracy: 0.5396 - loss: 1.4210 - val_accuracy: 0.4333 - val_loss: 1.6953
Epoch 13/20
90/90 ━━━━━━━━━━━━━━━━━━━━ 227s 3s/step - accuracy: 0.5465 - loss: 1.3914 - val_accuracy: 0.4944 - val_loss: 1.5952
Epoch 14/20
90/90 ━━━━━━━━━━━━━━━━━━━━ 225s 3s/step - accuracy: 0.5729 - loss: 1.3365 - val_accuracy: 0.4944 - val_loss: 1.5479
Epoch 15/20
90/90 ━━━━━━━━━━━━━━━━━━━━ 224s 2s/step - accuracy: 0.5688 - loss: 1.3085 - val_accuracy: 0.4667 - val_loss: 1.5894
Epoch 16/20
90/90 ━━━━━━━━━━━━━━━━━━━━ 38515s 433s/step - accuracy: 0.6049 - loss: 1.2493 - val_accuracy: 0.4917 - val_loss: 1.5536
Epoch 17/20
90/90 ━━━━━━━━━━━━━━━━━━━━ 213s 2s/step - accuracy: 0.6049 - loss: 1.2397 - val_accuracy: 0.4611 - val_loss: 1.6453
Epoch 18/20
90/90 ━━━━━━━━━━━━━━━━━━━━ 224s 2s/step - accuracy: 0.6222 - loss: 1.1871 - val_accuracy: 0.4639 - val_loss: 1.5818
Epoch 19/20
90/90 ━━━━━━━━━━━━━━━━━━━━ 231s 3s/step - accuracy: 0.6403 - loss: 1.1718 - val_accuracy: 0.4556 - val_loss: 1.6595
Epoch 20/20
90/90 ━━━━━━━━━━━━━━━━━━━━ 242s 3s/step - accuracy: 0.6285 - loss: 1.1626 - val_accuracy: 0.5250 - val_loss: 1.4709
开始训练使用 [RMSprop] 优化器的模型...
Epoch 1/20
90/90 ━━━━━━━━━━━━━━━━━━━━ 235s 3s/step - accuracy: 0.1840 - loss: 2.7337 - val_accuracy: 0.1889 - val_loss: 2.6534
Epoch 2/20
90/90 ━━━━━━━━━━━━━━━━━━━━ 231s 3s/step - accuracy: 0.3389 - loss: 2.0493 - val_accuracy: 0.2417 - val_loss: 2.4542
Epoch 3/20
90/90 ━━━━━━━━━━━━━━━━━━━━ 224s 2s/step - accuracy: 0.4208 - loss: 1.7812 - val_accuracy: 0.3417 - val_loss: 2.2348
Epoch 4/20
90/90 ━━━━━━━━━━━━━━━━━━━━ 229s 3s/step - accuracy: 0.4812 - loss: 1.6061 - val_accuracy: 0.3778 - val_loss: 2.0295
Epoch 5/20
90/90 ━━━━━━━━━━━━━━━━━━━━ 225s 3s/step - accuracy: 0.5521 - loss: 1.4202 - val_accuracy: 0.4139 - val_loss: 1.8728
Epoch 6/20
90/90 ━━━━━━━━━━━━━━━━━━━━ 222s 2s/step - accuracy: 0.6208 - loss: 1.2390 - val_accuracy: 0.3917 - val_loss: 1.8971
Epoch 7/20
90/90 ━━━━━━━━━━━━━━━━━━━━ 3536s 40s/step - accuracy: 0.6472 - loss: 1.1807 - val_accuracy: 0.4806 - val_loss: 1.6985
Epoch 8/20
90/90 ━━━━━━━━━━━━━━━━━━━━ 237s 3s/step - accuracy: 0.6639 - loss: 1.0573 - val_accuracy: 0.4250 - val_loss: 1.8773
Epoch 9/20
90/90 ━━━━━━━━━━━━━━━━━━━━ 239s 3s/step - accuracy: 0.7028 - loss: 0.9659 - val_accuracy: 0.5083 - val_loss: 1.5542
Epoch 10/20
90/90 ━━━━━━━━━━━━━━━━━━━━ 255s 3s/step - accuracy: 0.7271 - loss: 0.8914 - val_accuracy: 0.4472 - val_loss: 1.9159
Epoch 11/20
90/90 ━━━━━━━━━━━━━━━━━━━━ 259s 3s/step - accuracy: 0.7451 - loss: 0.8633 - val_accuracy: 0.4556 - val_loss: 1.9522
Epoch 12/20
90/90 ━━━━━━━━━━━━━━━━━━━━ 237s 3s/step - accuracy: 0.7667 - loss: 0.8074 - val_accuracy: 0.4944 - val_loss: 1.5737
Epoch 13/20
90/90 ━━━━━━━━━━━━━━━━━━━━ 246s 3s/step - accuracy: 0.7722 - loss: 0.7726 - val_accuracy: 0.4361 - val_loss: 1.8424
Epoch 14/20
90/90 ━━━━━━━━━━━━━━━━━━━━ 265s 3s/step - accuracy: 0.7924 - loss: 0.7040 - val_accuracy: 0.5028 - val_loss: 1.7630
Epoch 15/20
90/90 ━━━━━━━━━━━━━━━━━━━━ 245s 3s/step - accuracy: 0.7944 - loss: 0.6767 - val_accuracy: 0.5333 - val_loss: 1.6793
Epoch 16/20
90/90 ━━━━━━━━━━━━━━━━━━━━ 228s 3s/step - accuracy: 0.8222 - loss: 0.6221 - val_accuracy: 0.5111 - val_loss: 1.8175
Epoch 17/20
90/90 ━━━━━━━━━━━━━━━━━━━━ 231s 3s/step - accuracy: 0.8174 - loss: 0.6276 - val_accuracy: 0.5306 - val_loss: 1.6597
Epoch 18/20
90/90 ━━━━━━━━━━━━━━━━━━━━ 221s 2s/step - accuracy: 0.8278 - loss: 0.5837 - val_accuracy: 0.5556 - val_loss: 1.6293
Epoch 19/20
90/90 ━━━━━━━━━━━━━━━━━━━━ 222s 2s/step - accuracy: 0.8340 - loss: 0.5314 - val_accuracy: 0.5000 - val_loss: 1.9162
Epoch 20/20
90/90 ━━━━━━━━━━━━━━━━━━━━ 29164s 328s/step - accuracy: 0.8424 - loss: 0.5143 - val_accuracy: 0.4917 - val_loss: 1.9434
开始训练使用 [Adagrad] 优化器的模型...
Epoch 1/20
90/90 ━━━━━━━━━━━━━━━━━━━━ 220s 2s/step - accuracy: 0.0660 - loss: 3.3061 - val_accuracy: 0.1139 - val_loss: 2.7919
Epoch 2/20
90/90 ━━━━━━━━━━━━━━━━━━━━ 212s 2s/step - accuracy: 0.0958 - loss: 3.0765 - val_accuracy: 0.1444 - val_loss: 2.7432
Epoch 3/20
90/90 ━━━━━━━━━━━━━━━━━━━━ 219s 2s/step - accuracy: 0.1132 - loss: 2.9543 - val_accuracy: 0.1667 - val_loss: 2.6821
Epoch 4/20
90/90 ━━━━━━━━━━━━━━━━━━━━ 230s 3s/step - accuracy: 0.1243 - loss: 2.8499 - val_accuracy: 0.1972 - val_loss: 2.6082
Epoch 5/20
90/90 ━━━━━━━━━━━━━━━━━━━━ 226s 3s/step - accuracy: 0.1479 - loss: 2.7793 - val_accuracy: 0.2056 - val_loss: 2.5312
Epoch 6/20
90/90 ━━━━━━━━━━━━━━━━━━━━ 227s 3s/step - accuracy: 0.1472 - loss: 2.7427 - val_accuracy: 0.2222 - val_loss: 2.4635
Epoch 7/20
90/90 ━━━━━━━━━━━━━━━━━━━━ 232s 3s/step - accuracy: 0.1681 - loss: 2.6728 - val_accuracy: 0.2361 - val_loss: 2.4097
Epoch 8/20
90/90 ━━━━━━━━━━━━━━━━━━━━ 242s 3s/step - accuracy: 0.1868 - loss: 2.6286 - val_accuracy: 0.2472 - val_loss: 2.3677
Epoch 9/20
90/90 ━━━━━━━━━━━━━━━━━━━━ 243s 3s/step - accuracy: 0.1896 - loss: 2.5841 - val_accuracy: 0.2556 - val_loss: 2.3404
Epoch 10/20
90/90 ━━━━━━━━━━━━━━━━━━━━ 240s 3s/step - accuracy: 0.1937 - loss: 2.5410 - val_accuracy: 0.2500 - val_loss: 2.3079
Epoch 11/20
90/90 ━━━━━━━━━━━━━━━━━━━━ 261s 3s/step - accuracy: 0.2271 - loss: 2.4981 - val_accuracy: 0.2611 - val_loss: 2.2920
Epoch 12/20
90/90 ━━━━━━━━━━━━━━━━━━━━ 232s 3s/step - accuracy: 0.2160 - loss: 2.4689 - val_accuracy: 0.2611 - val_loss: 2.2633
Epoch 13/20
90/90 ━━━━━━━━━━━━━━━━━━━━ 238s 3s/step - accuracy: 0.2257 - loss: 2.4456 - val_accuracy: 0.2778 - val_loss: 2.2465
Epoch 14/20
90/90 ━━━━━━━━━━━━━━━━━━━━ 223s 2s/step - accuracy: 0.2236 - loss: 2.4664 - val_accuracy: 0.2778 - val_loss: 2.2270
Epoch 15/20
90/90 ━━━━━━━━━━━━━━━━━━━━ 223s 2s/step - accuracy: 0.2382 - loss: 2.3858 - val_accuracy: 0.2889 - val_loss: 2.2054
Epoch 16/20
90/90 ━━━━━━━━━━━━━━━━━━━━ 219s 2s/step - accuracy: 0.2438 - loss: 2.4062 - val_accuracy: 0.2861 - val_loss: 2.1881
Epoch 17/20
90/90 ━━━━━━━━━━━━━━━━━━━━ 217s 2s/step - accuracy: 0.2562 - loss: 2.3529 - val_accuracy: 0.2917 - val_loss: 2.1760
Epoch 18/20
90/90 ━━━━━━━━━━━━━━━━━━━━ 214s 2s/step - accuracy: 0.2542 - loss: 2.3409 - val_accuracy: 0.2972 - val_loss: 2.1572
Epoch 19/20
90/90 ━━━━━━━━━━━━━━━━━━━━ 217s 2s/step - accuracy: 0.2653 - loss: 2.3486 - val_accuracy: 0.3000 - val_loss: 2.1426
Epoch 20/20
90/90 ━━━━━━━━━━━━━━━━━━━━ 213s 2s/step - accuracy: 0.2562 - loss: 2.3189 - val_accuracy: 0.3083 - val_loss: 2.13314. 不同优化器对比评估
4.1 绘制训练集与验证集的 Accuracy 和 Loss 趋势图
提取了 model.fit() 返回的历史训练数据,并使用 Matplotlib 将训练集与验证集的准确率(Accuracy)和损失值(Loss)随时间变化的趋势绘制成了两幅直观的折线图。
python
plt.rcParams['savefig.dpi'] = 300
plt.rcParams['figure.dpi'] = 300
current_time = datetime.now()
epochs_range = range(NO_EPOCHS)
plt.figure(figsize=(16, 6))
# ---- 子图 1:准确率 (Accuracy) ----
plt.subplot(1, 2, 1)
for name, history in histories.items():
plt.plot(epochs_range, history.history['accuracy'], label=f'Train Acc - {name}')
plt.plot(epochs_range, history.history['val_accuracy'], label=f'Val Acc - {name}', linestyle='--')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.xlabel(current_time)
ax = plt.gca()
ax.xaxis.set_major_locator(MultipleLocator(5))
# ---- 子图 2:损失值 (Loss) ----
plt.subplot(1, 2, 2)
for name, history in histories.items():
plt.plot(epochs_range, history.history['loss'], label=f'Train Loss - {name}')
plt.plot(epochs_range, history.history['val_loss'], label=f'Val Loss - {name}', linestyle='--')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
ax = plt.gca()
ax.xaxis.set_major_locator(MultipleLocator(5))
plt.show()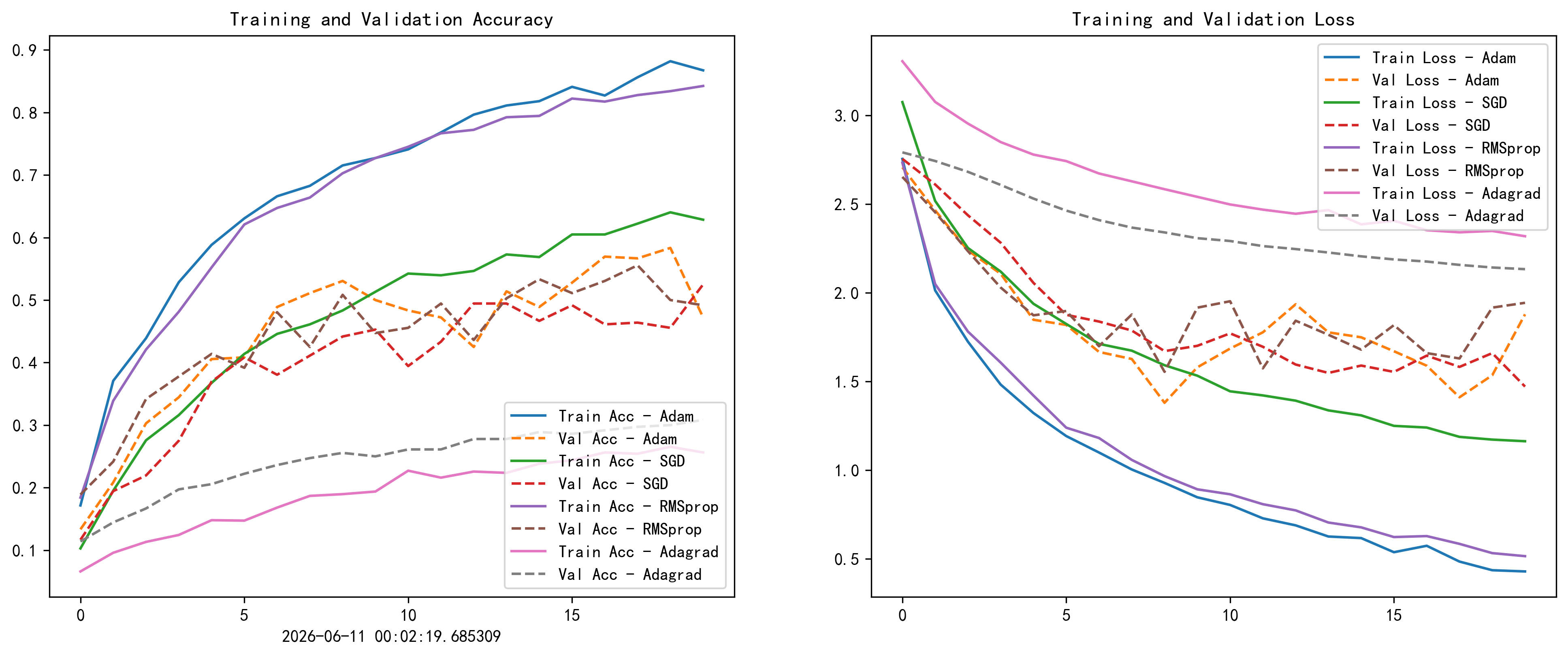
4.2 不同优化器最终模型评估表
循环评估字典中的所有模型,并打印对比报告。
python
def test_accuracy_report(models_dict, val_data):
print("\n" + "="*20 + " 最终模型评估报告 " + "="*20)
print(f"{'优化器 (Optimizer)':<20} | {'损失值 (Loss)':<15} | {'准确率 (Accuracy)':<15}")
print("-" * 60)
for name, model in models_dict.items():
score = model.evaluate(val_data, verbose=0)
# score[0] 是 Loss, score[1] 是 Accuracy
print(f"{name:<20} | {score[0]:<15.4f} | {score[1]:<15.4f}")
print("="*56)
test_accuracy_report(trained_models, val_ds)
针对该模型和数据集,结果:
Adam:训练准确率最高约87%,验证准确率约47--58%。
SGD:训练准确率约64%,验证准确率约52%。
RMSprop:训练准确率约84%,验证准确率约49--55%。
Adagrad:训练准确率约25%,验证准确率约30%。
Adam表现最佳,Adagrad效果较差。