半监督目标检测(SSOD)
- 随着视频在智能交通,公共安全,无人系统,医疗监测等领域的快速增长 ,逐帧标注成本极高,数据集标注不完整使视频目标检测面临数据瓶颈。
- 半监督目标检测通过给没有标签的数据 主成伪标签,可在大幅降标注成本的同时实现高精度检测,是当前的重要研究方向。

半监督目标检测技术框架
SSOD的主流技术框架围绕 "自训练""一致性正则化""协同训练" 三大思路展开,其中自训练应用最广泛,三者相互补充,提升模型性能。
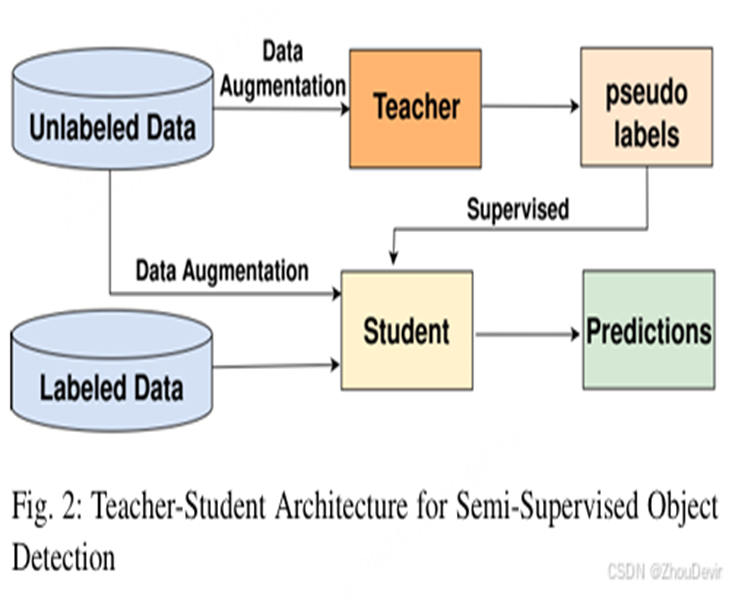
- 自训练核心流程:先用少量标注数据训练"教师模型"和"学生模型",再用教师模型对无标注数据预测生成带置信度的伪标签,筛选高置信度伪标签与标注数据结合,训练"学生模型",多轮迭代优化两者性能。
- 一致性正则化:通过数据增强等方式,约束模型对同一数据的预测结果保持一致,挖掘无标注数据信息。
伪标签训练流程
- 为没有标签的数据生成伪标签,选出可靠的伪标签和已经有标签的数据一起喂给模型学习。
- 假设你正在尝试教会计算机区分猫和狗的照片,但只有少数照片是打上了"猫"或"狗"的标签,大部分照片都没有标签。这时候,半监督学习就闪亮登场了,它是一种使用大量未标注主数据和少量标注数据进行学习的方法,旨在提高学习效率和准确性。
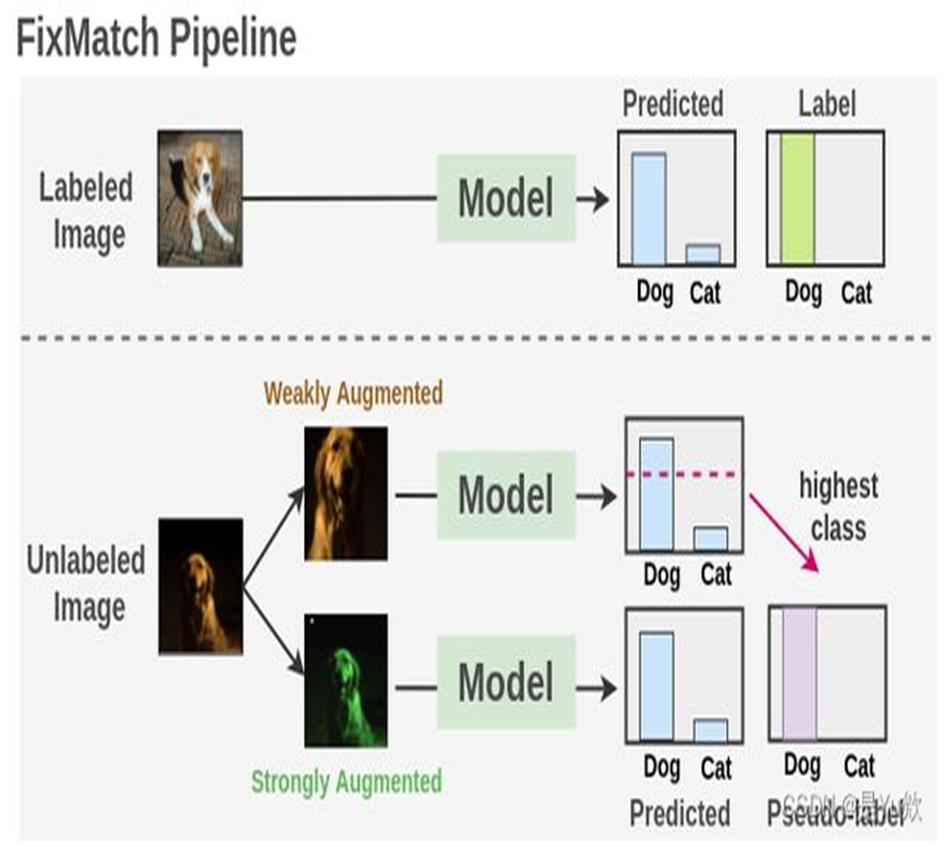
数据增强和EMA机制
| 增强类型 | 适用对象 | 具体操作 | 核心原则 | 设计目的 |
|---|---|---|---|---|
| 弱增强 | 教师模型(Teacher) | 1. 轻微缩放变换 2. 随机水平翻转 3. 轻微亮度调整 | 不改变图像结构,保持目标形状清晰完整 | 为教师模型提供高质量输入,确保生成准确可靠的伪标签 |
| 强增强 | 学生模型(Student) | 1. 随机遮挡(CutOut/CutMix) 2. 大幅度颜色抖动 3. 高斯模糊 | 对图像进行严重变换,引入多样化干扰 | 迫使学生模型学习更鲁棒的特征,提升泛化能力和抗干扰性 |
基于EMA更新教师模型的公式如下:
θema=α⋅θema+(1−α)⋅θstudent\theta_{ema} = \alpha \cdot \theta_{ema} + (1 - \alpha) \cdot \theta_{student}θema=α⋅θema+(1−α)⋅θstudent
其中 α 通常取值接近 1,如 0.999、0.9999,(接近于1)意味着 Teacher 更新得很慢,保持稳定。
半监督视频目标检测(SSVOD)
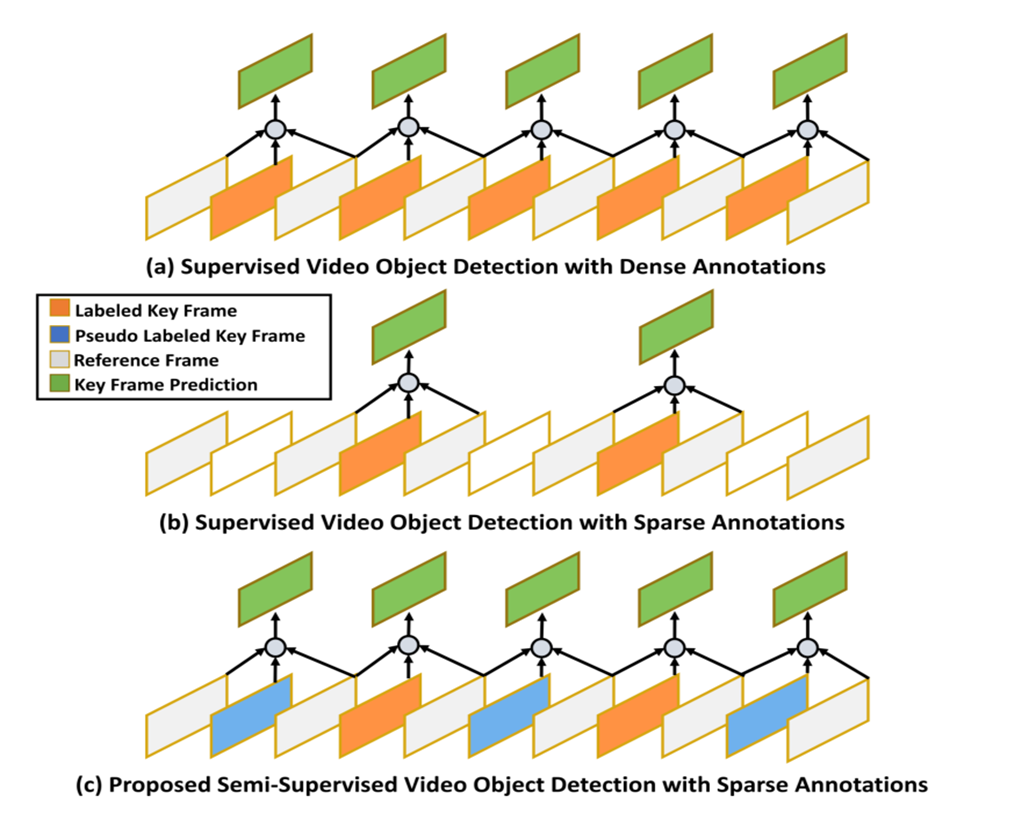
- 对于视频来说,情况会更复杂,新增了时间这一维度,每一视频帧都有时间关联性。而且标注工作会更复杂,(例如一个10秒的视频(30帧/秒)就是300帧,如一果每帧都要人工标注几十个框,那成本是纯图像检测的几十倍。)
- 从图像检测扩展到视频检测, 我们可以用类似想法只标注少量帧 (比如每个视频标几帧),利用大量未标注帧的视觉与时间信息, 让模型自己学习其他帧的检测规律。

解决视频冗余:关键帧选取
- 真实场景视频通常包含大量冗余帧,若逐帧生成伪标签不仅计算开销巨大,还容易产生低质量伪标签干扰训练。
- 综上所述,需要从长序列中自动选取能代表核核心内容,具有较高学习价值的关键帧 ,以确保时序覆盖的同时降低伪标签生成与训练成本,提升整体检测效率与性能。
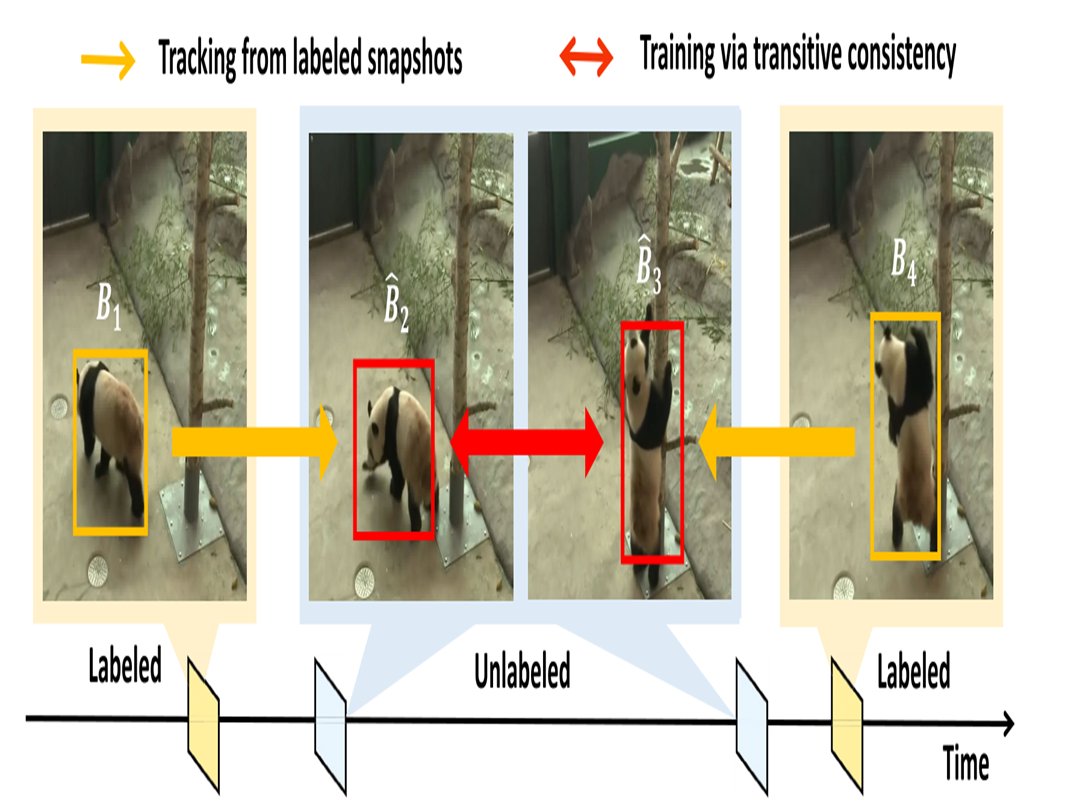
对于冗余信息利用跟踪方法进行辅助
- 黄色是已经标注的关键帧,红色是模型自己在剩余帧预测的结果。相邻帧中的检测结果应该一致。
- 如果模型在帧t检测到熊猫,那么在帧t+1也应该在相似位置检测则到它;用光流(Optical Flow)或跟踪算法(Tracking)将前一帧目标位置传播到下一帧,强制模型的勺输出在这种传播前后保持一致。利用这样的跟踪思想来为更多的见频帧生成伪标签可以大大减少算力。