很多 Java 团队开始做大模型应用时,第一反应是去看 Python 生态。LangChain、LlamaIndex 很成熟,示例也多,但当系统真正要接入登录态、权限、订单、工单、知识库、审计和发布流程时,问题往往不在"怎么调一次模型",而在"怎么把模型能力放进已有后端工程"。
Spring AI 解决的正是这件事。它把常见 AI 能力抽象成 Spring 项目里可以配置、注入和替换的组件:聊天模型、Embedding 模型、向量库、Prompt、结构化输出、工具调用、RAG、观测等。你仍然写 Controller、Service、Repository,仍然用 Bean、Auto Configuration、Starter 和属性配置,只是业务流程里多了一个"模型参与"的环节。
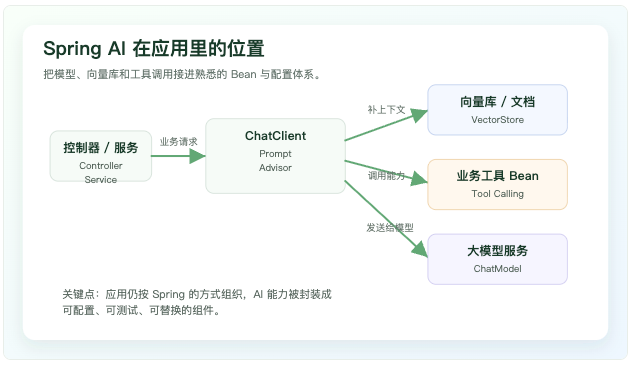
Spring AI 更像应用里的 AI 接入层,而不是另起一套后端架构
先看它放在哪一层
在普通 Spring Boot 项目里,请求通常从 Controller 进入 Service,再访问数据库、缓存、消息队列或外部服务。Spring AI 可以放在 Service 层附近:业务代码准备问题、用户上下文和检索条件,交给 ChatClient 组织 Prompt,再由底层 ChatModel 调用模型。需要知识库时接 VectorStore,需要实时业务数据时接 Tool,需要聊天历史时接 Memory Advisor。
这层抽象的价值在于"隔离变化"。模型厂商会变,模型名称会变,向量库可能从本地 Chroma 换到 PGvector 或 Milvus,Prompt 也会反复调。Spring AI 把这些变化收进配置和组件边界里,业务代码不必到处散落 HTTP 请求、鉴权头、JSON 拼装和响应解析。
写 Spring AI 应用时,不要先问"模型能不能回答",更应该先问"模型需要哪些上下文,哪些动作必须交还给系统执行"。
ChatClient 是日常入口
Spring AI 的 ChatClient 类似 WebClient、RestClient 的风格,提供链式 API。它把 System Message、User Message、模板变量、Advisor、工具和返回格式放在一个比较顺手的调用模型里。对于大多数业务场景,直接从 ChatClient 开始就够了。
String answer = chatClient.prompt()
.system("你是公司内部知识库助手,回答要准确、简洁。")
.user(u -> u
.text("解释一下 {topic} 的处理流程")
.param("topic", "退款审核"))
.call()
.content();这段代码看起来简单,但它比手写 HTTP 调模型多做了几件工程化的事:Prompt 构造有明确边界,模型响应可以统一处理,后面加流式输出、Advisor、结构化输出或工具调用,不需要推翻前面的写法。
如果希望模型返回 Java 对象,可以用结构化输出。实际项目里这点很有用,例如把用户一句自然语言解析成查询条件、工单分类、摘要对象或风险标签。但要注意:结构化输出不是数据库约束,仍然需要校验字段、兜底空值和记录原始响应,尤其不要让模型直接决定高风险业务动作。
RAG 是知识库问答的主干
企业内部问答最常见的坑,是把所有资料塞进 Prompt,或者让模型凭记忆回答。前者成本高、上下文窗口有限,后者容易答得像真的。RAG 的做法更朴素:先把文档切成片段,生成向量写入向量库;用户提问时先做相似度检索,把相关片段带给模型,再让模型基于这些片段回答。
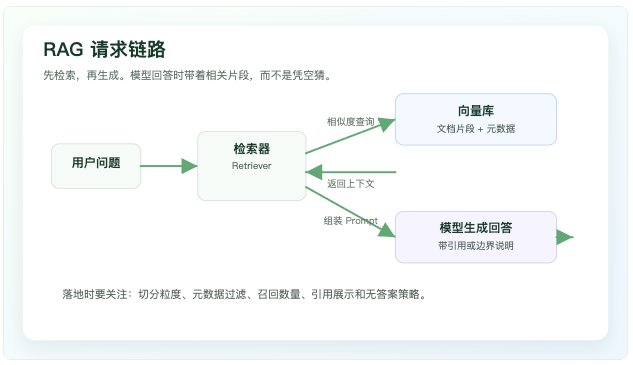
RAG 的重点不是"向量库"三个字,而是检索质量、上下文组织和回答边界
Spring AI 提供 VectorStore 抽象,官方文档列出的向量库覆盖 PGvector、Redis、Qdrant、Milvus、Elasticsearch、OpenSearch、MongoDB Atlas、Neo4j 等。选型时不用一开始就追最复杂的方案:团队已经有 PostgreSQL,先用 PGvector 验证流程通常更快;数据量和召回要求上来后,再考虑专门的向量数据库。
Advisor ragAdvisor = RetrievalAugmentationAdvisor.builder()
.documentRetriever(VectorStoreDocumentRetriever.builder()
.vectorStore(vectorStore)
.similarityThreshold(0.50)
.build())
.build();
String answer = chatClient.prompt()
.advisors(ragAdvisor)
.user(question)
.call()
.content();真正影响效果的细节常常在代码外面。文档切分太粗,检索回来一大段无关内容;切得太碎,模型看不到完整语义。元数据没有设计好,就很难按租户、部门、权限、文档版本过滤。检索不到内容时也要明确策略:是回答"资料中没有找到",还是转人工,还是允许模型用通用知识补充。这个边界需要产品和工程一起定。
工具调用让模型"提出动作",不是"直接掌权"
模型本身不知道你的订单状态、库存、优惠规则,也不应该直接操作数据库。Tool Calling 的思路是:把可调用的业务能力声明成工具,模型在需要时提出工具名和参数,应用侧执行工具,把结果再交给模型生成最终回答。
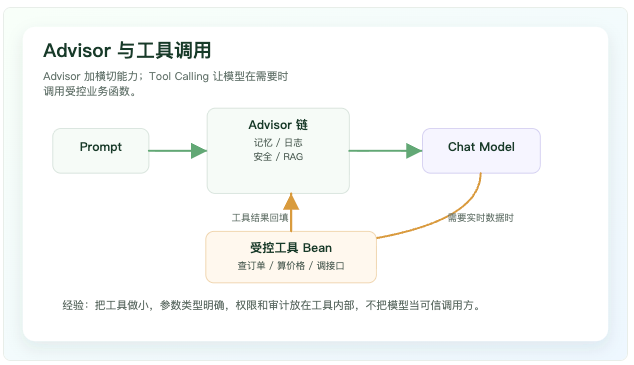
工具调用适合查实时数据、做确定性计算、触发受控流程
class OrderTools {
@Tool(description = "根据订单号查询订单状态,只返回当前登录用户有权限查看的订单")
OrderStatus getOrderStatus(String orderNo) {
return orderService.findVisibleOrderStatus(orderNo);
}
}
String reply = chatClient.prompt()
.user("帮我查一下订单 A1024 现在到哪了")
.tools(new OrderTools())
.call()
.content();这里最重要的不是注解,而是边界。工具方法要小,参数要清楚,返回值要稳定。权限检查、审计日志、幂等控制、限流和异常处理都应该在工具内部或调用链上完成,不能因为"是模型发起的"就绕过原有安全设计。
Advisor 则更像 ChatClient 调用链上的横切能力。它可以处理聊天记忆、RAG、日志、观测、安全过滤等逻辑。顺序很关键:先改写问题还是先检索,先加历史还是先做安全处理,都会影响模型看到的上下文。把这些能力做成 Advisor,比散落在业务方法里更容易维护。
版本和依赖别拍脑袋
截至 2026 年 6 月 7 日,Spring AI 官方参考文档页面显示的稳定版本是 1.1.7 和 1.0.8,预览版本有 2.0.0-RC1。生产项目建议优先用稳定线,按官方 BOM 管理版本,再引入具体模型或向量库 starter。预览线适合验证新能力,不适合在没有升级预算的系统里直接铺开。
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-bom</artifactId>
<version>${spring-ai.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>如果只是做一个内部知识库问答,最小闭环可以这样搭:Spring Boot 3.4 或 3.5,选一个 Chat Model starter,选一个 Embedding Model,选一个 VectorStore;离线或启动时完成文档解析、切分、向量化和入库;在线请求用 ChatClient 加 RAG Advisor;最后补上权限过滤、引用来源、日志、超时、重试和成本统计。
落地时最容易低估的部分
Spring AI 能把接入方式变得顺手,但它不会自动解决产品判断。哪些问题允许回答,哪些问题必须引用来源,哪些回答需要免责声明,哪些工具只能读不能写,哪些调用要走人工确认,这些都要在系统设计里明确。
观测也要尽早做。模型调用和普通 RPC 不一样,除了延迟和错误率,还要看 token 用量、召回片段、工具调用次数、命中来源、拒答比例、用户追问率。没有这些数据,后面调 Prompt、调切分、换模型,很容易变成凭感觉。
还有一个现实问题:大模型应用不是一次上线就结束。文档会更新,模型会升级,Prompt 会被真实用户问法打穿,工具参数会暴露边界条件。把 Spring AI 当成工程层,而不是一次性 Demo 框架,才更接近它的正确用法。
**文章概要:**Spring AI 把聊天模型、Embedding、向量库、RAG、工具调用和观测接入 Spring Boot。适合 Java 团队在已有工程中构建知识库问答、智能助手和受控业务操作,重点在组件边界、上下文质量、安全权限与可观测性。