NCCL 测试报告的性能指标
NCCL 测试报告以毫秒(ms)为单位的平均操作时间,以及以GB/s为单位的两种带宽:算法带宽和总线带宽。本文档解释了这些数字的含义以及在不同硬件上的预期表现。
时间
时间指标在小数据量时 非常有用,可用于衡量 与操作相关的恒定开销overhead(或延迟latency)。
在大数据量时,时间与数据量呈线性关系(因为时间大致等于开销 + 数据量 / 带宽),此时时间不再仅衡量延迟,还包含了带宽与数据量的乘积。
因此,在大数据量时 ,查看带宽指标更有意义。
带宽
算法带宽 【algbw】
算法带宽使用最常用的带宽公式:数据量(S ) / 时间(t )。
作用:它可用于通过简单地将 操作数据量 除以 算法带宽 来计算任何大型操作所需的 时间。
algbw = S/t
适用场景:适用于 点对点P2P操作, 此时算法带宽 等于 总线带宽。
不适用于衡量 集合操作 操作的带宽,对于集合操作,理论峰值算法带宽 不等于硬件峰值带宽 ,算法带宽会随着rank数量的变化而变化(并随着rank数量的增加而降低)。
总线带宽【busbw】
表示 硬件总线带宽,反映GPU间通信速度,通过算法带宽按照计算公式计算得到。
总线带宽,我们可以将其与硬件峰值带宽进行比较,而不受所使用rank数量的影响。
公式取决于集合操作的类型。
AllReduce
AllReduce操作对N个数组(输入i_X和输出o_X,每个都位于rank X上)的每个元素执行以下操作:
o_0 = o_1 = o_2 = ... = o_{n-1} = i_0 + i_1 + i_2 + ... + i_{n-1}
注意:这与使用的算法(环形、树形或其他)无关,只要它们使用点对点操作(发送/接收)即可。
环形算法会按照环形顺序执行该操作:
i_0 + i_1 + ... + i_{n-1} -> o_{n-1} -> o_0 -> o_1 -> .. -> o_{n-2}
树形算法会按层次结构执行:
(((((i_{n-1} + i_{n-2}) + (i_{n-3} + i_{n-4})) + ... + (i_1 + i_0))))) -> o_0 -> (o_{n/2} -> (o_{3n/4} ...))
在所有情况下,我们需要对每个元素执行n-1次加法和n次赋值。由于除了可能的一步(最后一个输入和第一个输出)外,每一步都在不同的rank【GPU】上,
因此执行AllReduce操作需要2(n-1)次数据传输(乘以元素数量)。
以AllReduce sum操作,nRank=4 为例:
- 前 (n-1) = 3 次 传输,获得累加和 a0+b0+c0+d0
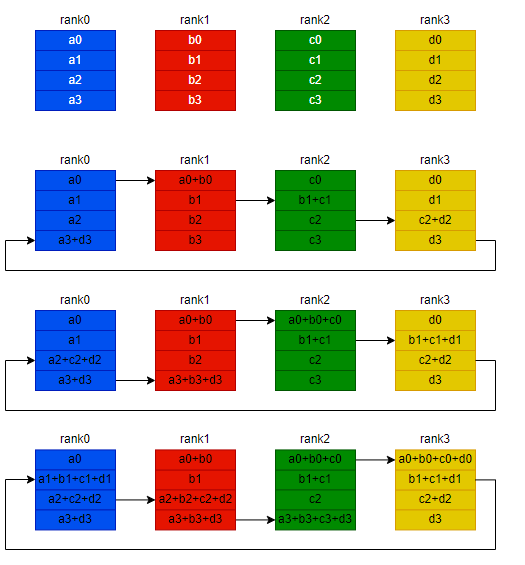
- 后 (n - 1) 次传输,将 累加和结果 传回给 其他 rank。目前结果在rank3,依次将结果发给 rank0, rank1, rank2
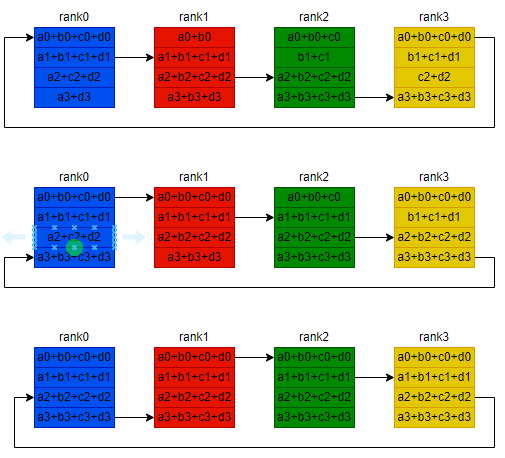
考虑到每个rank与外部世界的带宽为 B ,执行数据量为 S 的AllReduce操作的最佳时间为:
t = (S*2*(n-1)) / (n*B)
实际上,我们有 S 个元素,每个元素需要2*(n-1)次操作,以及 n 个带宽为 B 的链接来执行这些操作。
重新排列等式,我们发现:
t = (S/B) * (2*(n-1)/n)
因此,为了获得可以与硬件峰值带宽进行比较的AllReduce带宽测量值,我们计算:
B = S/t * (2*(n-1)/n) = algbw * (2*(n-1)/n)
ReduceScatter
ReduceScatter操作只需要执行AllReduce操作的加法部分:
o_K = i_0 + i_1 + i_2 + ... + i_{n-1}
其中K是获得最终结果的rank(K=offset/recvsize)。
rank带宽为B时,ReduceScatter的理想时间为:
t = S*(n-1) / (B*n)
因此,总线带宽计算为:
B = S/t * (n-1)/n = algbw * (n-1)/n
注意:这里的S是总数组的字节大小,对于NCCL,它等于recvcount*sizeof(datatype)*n,因为recvcount参数是每个rank的计数。
AllGather
AllGather操作只需要执行AllReduce操作的赋值部分:
o_0 = o_1 = o_2 = ... = o_{n-1} = i_K
其中K是数据来源的rank(K=offset*sendsize)。
rank带宽为B时,AllGather的理想时间为:
t = S*(n-1) / (B*n)
因此,总线带宽计算为:
B = S/t * (n-1)/n = algbw * (n-1)/n
注意:这里的S是总数组的字节大小,对于NCCL,它等于sendcount*sizeof(datatype)*n,因为sendcount参数是每个rank的计数。
Broadcast
Broadcast操作的表示与AllGather类似:
o_0 = o_1 = o_2 = ... = o_{n-1} = i_R
其中R是操作的根节点。
然而,在这种情况下,由于i_R输入不是均匀分布在各个rank上的,我们无法使用所有N个链接来执行传输操作。
实际上,所有数据都必须从根rank发出,因此瓶颈在根rank上,其输出容量只有B:
t = S/B
因此:
B = S/t
Reduce
Reduce操作执行以下操作:
o_R = i_0 + i_1 + i_2 + ... + i_{n-1}
其中R是操作的根节点。
与Broadcast类似,所有数据都需要发送到根节点,因此:
t = S/B
因此:
B = S/t
总结
为了获得应该与rank数量_n_无关的总线带宽,我们对算法带宽应用修正因子:
- AllReduce:2*(n -1)/n
- ReduceScatter:(n -1)/n
- AllGather:(n -1)/n
- Broadcast:1
- Reduce:1
总线带宽应反映硬件瓶颈的速度:NVLink、PCI、QPI或网络。
AlltoAll,SendRecv,Gather,Scatter 实际用的mcclSend/mcclRecv通过P2P方式实现
AllGather,AllReduce, Broadcast, ReduceScatter,Reduce 通过Ring Collective通信方式实现