干开发10 年了,说出来不怕你们笑话,前 3 年我对进程调度的认知,就停留在 top 命令里那个 PR 和 NI 值上。那时候总觉得,不就是给进程改个 nice 值,调个优先级,内核照着分配 CPU 嘛,有什么好深入研究的。天天捣鼓高并发、微服务、K8s打交道,觉得自己挺牛的?直到有一次线上服务器CPU软中断飙到80%,我像个无头苍蝇一样改了半天的线程池参数------屁用没有。最后被一个内核组的老哥轻描淡写地说了句"你调下进程调度策略试试?",我当场就懵了。
调度?调度啥?我连进程和线程的区别都背得滚瓜烂熟,但调度器到底在忙什么,我竟然答不上来。
那一刻我意识到,这3年我写的代码,全是在人家内核的"地盘"上蹦跶,却连地主的规矩都没搞明白。
什么是进程调度?
说白了,进程调度就是内核里的"包工头"。你想想啊,咱们写代码的每天在各个需求之间反复横跳,内核不也一样吗?它面对的是成百上千个进程排队等着干活,可 CPU 核心就那么几个。调度器得决定谁先上、谁后上,像个和事佬一样,让每个进程都觉得自己没被亏待。
以前的老内核(2.4 时代)比较野蛮,直接给每个进程分时间片。你 10 毫秒,我 20 毫秒,分完拉倒。结果呢?高优先级的进程如果是个"死循环",低优先级的进程就得活活饿死。这就像公司里那些大项目组,把资源全占了,我们这种边缘小业务连口汤都喝不上,这能行吗?
所以到了 CFS 时代,内核变聪明了。它引入了一个叫 vruntime(虚拟运行时间)的概念。
简单说,就是谁跑得少,谁的 vruntime 就小,内核就越倾向于让它接着跑。这逻辑是不是很眼熟?
这不就是咱们职场里的"按劳分配"反过来嘛------谁被冷落了,谁就优先安排。内核在后台维护着一棵红黑树,把所有的进程都挂在上面,左边是跑得少的,右边是跑得多的。每次调度,内核就去最左边掏出一个进程:嘿,兄弟,轮到你表演了。
这种设计简直是天才。它不再硬性规定你跑多久,而是追求一种"动态的平衡"。
但别忘了,这种平衡是有代价的哈。
你得知道,每当内核决定把进程 A 踢下去、换进程 B 上来时,那可是个大工程。寄存器得保存吧?页表得换吧?内核栈得切吧?这就像你正写着一段极其复杂的递归逻辑,突然产品经理拍你肩膀说:"线上出 Bug 了,先看这个!"你得花半天时间保存现在的思路,等处理完 Bug 回来,你还记得刚才写到哪了吗?
这就是"上下文切换"的开销。在内核代码里,context_switch 函数干的就是这脏活。如果这种切换发生得太频繁,CPU 绝大部分时间都在装载、卸载,真正干活的时间反而没多少了。所以啊,别动不动就搞什么多线程压测,有时候线程多了,反倒是累死骆驼的最后一根稻草呢。
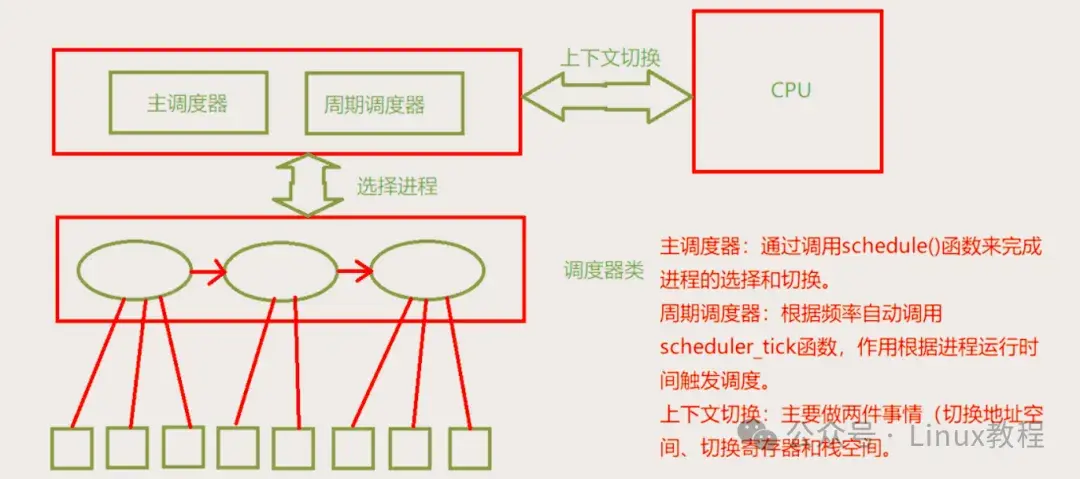
CFS完全公平调度器
很多人刚接触调度的时候,总觉得内核要做的就是把 CPU 榨干,要把利用率跑满,学 CFS,上来就啃一堆结构体定义,红黑树原理,学的人云里雾里。其实真没必要,对我们大部分做业务开发的人来说,你不用管内核用什么数据结构存进程,你只要搞懂它的核心逻辑,就够了。CFS 这东西,说穿了其实特别朴素,内核就认一个死理:大家都是进程,要公平,谁过去占用 CPU 的时间最少,谁就先上 CPU 跑。
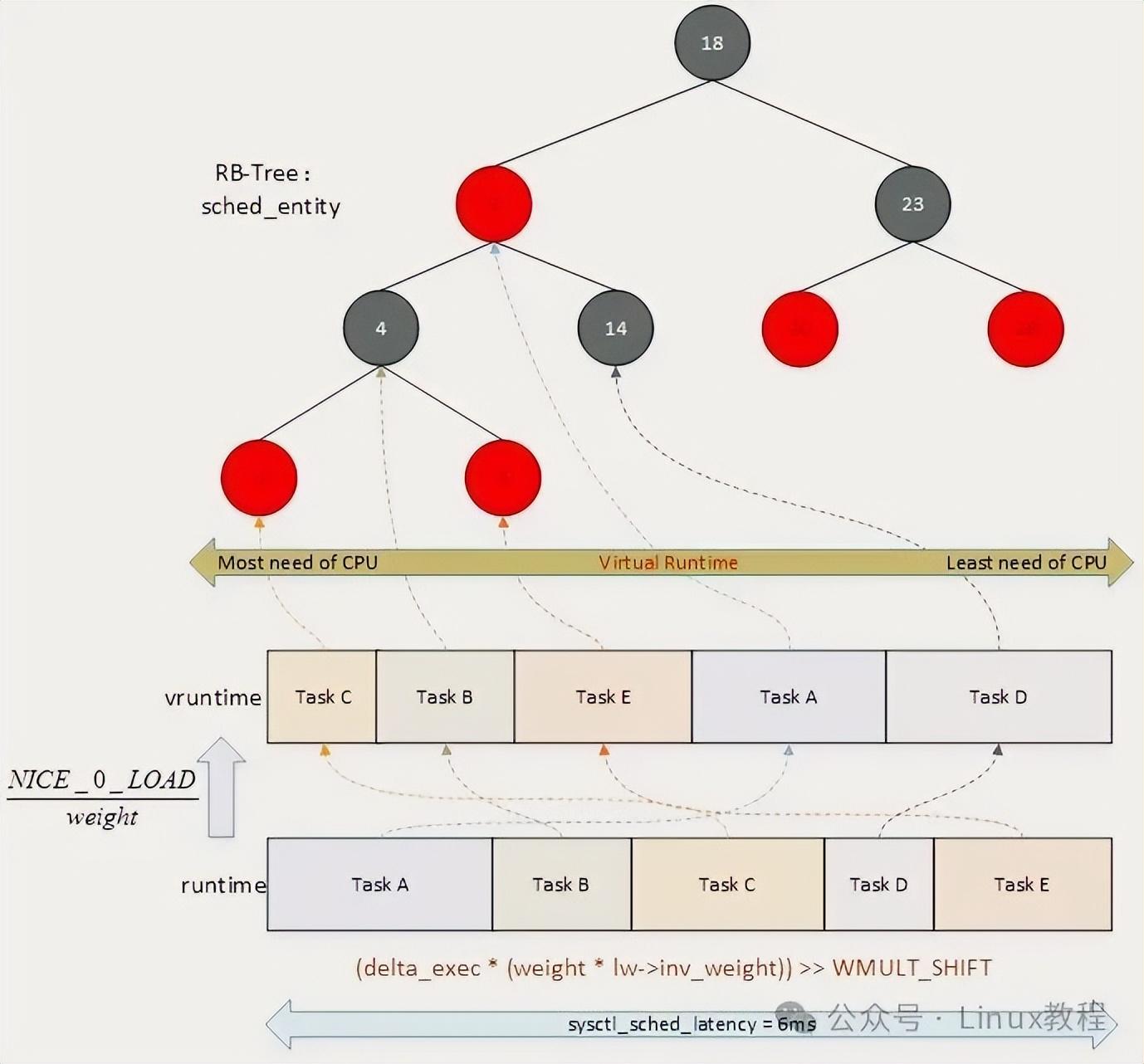
说起这个,我得吐槽一下 Linux 里的 Nice 值。
名字叫 Nice,听起来挺礼貌的,对吧?值越高,优先级越低。我刚写内核模块那阵子,总觉得把任务的 Nice 值调高点(也就是变得更"Nice"一点),把 CPU 让给别人,是种美德。
结果有一次,一个负责数据同步的后台进程被我调成了 Nice 19。好家伙,等到凌晨业务高峰一过,我发现数据全同步失败了。为啥?因为那天晚上系统太忙,内核觉得这进程太"Nice"了,简直是个圣人,于是就真的几乎没给它分 CPU。
这就是现实,太懂事的人是真的会被忽略的,在内核的世界里也同样如此o(╥﹏╥)o
现在的内核调度算法虽然已经进化到了极致,连 NUMA 架构(非一致存储访问)都考虑进去了,尽量让进程留在离它内存近的 CPU 核心上,减少跨片访问的延迟。但说到底,它依然在做一种权衡。
CFS怎么保证每个进程都能分到时间呢?
它有一个参数叫sched_latency ,默认是6ms。也就是说,CFS的目标是在这6ms内,把所有可运行的进程都跑一遍。假如当前有3个进程,每个分2ms;假如有6个进程,每个分1ms。那如果有100个进程呢?每个分0.06ms?切得太细了,上下文切换的开销反而更大。所以CFS还有个最小粒度的概念,默认0.75ms,进程再多也得保证每个至少跑0.75ms,那总的调度周期就会拉长。
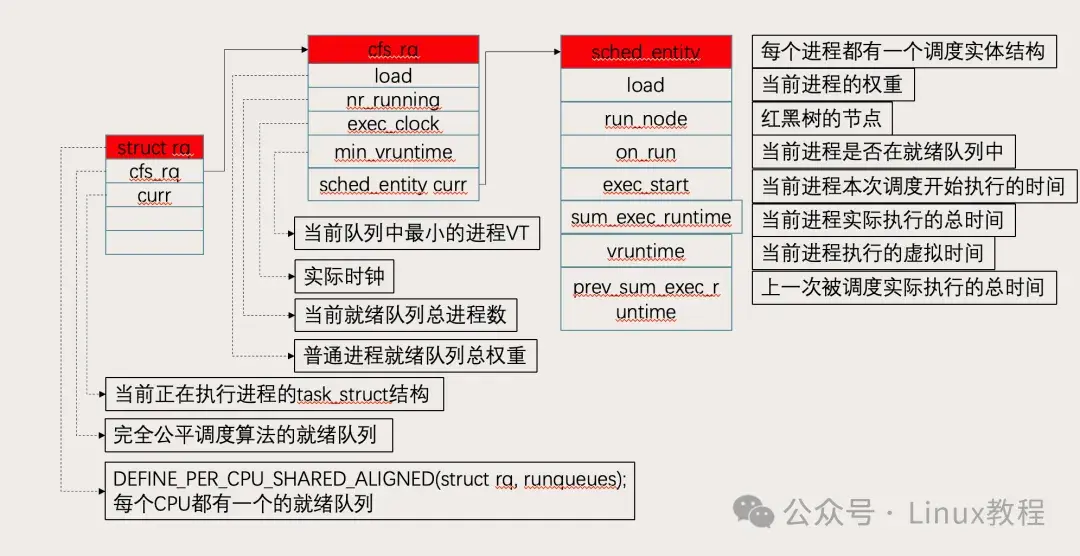
那些年我们误解的"实时"
很多人以为Linux是实时操作系统------拜托,别做梦了。真正的实时系统比如VxWorks,人家能保证中断响应时间在微秒级。Linux呢?它只是支持实时调度策略,比如SCHED_FIFO和SCHED_RR,但它本身不是硬实时的。
我有个做工业控制的哥们儿,信了网上的邪,把他们的机器人控制系统跑在打了RT补丁的Linux上,结果有一次电机控制的线程被一个内核驱动卡住了几百毫秒,机器差点把生产线给砸了。后来老老实实换成了带硬件实时核的方案。
所以你得清楚SCHED_FIFO(先进先出)这种实时策略,只要一个高优先级进程不主动让出CPU,其他进程就别想碰。这玩意儿用好了是神器,用砸了就是系统卡死的元凶。
抢占了又怎样?
还有一个概念被很多人忽略------抢占 。内核并不是只有在时间片用完才切换进程。CFS支持可抢占,也就是说,当一个更高优先级的进程变成可运行状态(比如从磁盘读数据回来了),它会立刻把当前进程踢出去。
这就是为什么你敲键盘的时候感觉系统"响应快"------键盘中断触发了输入法的进程,它立马抢占了编译程序之类的后台任务。没有抢占?那你按下一个键可能要等好几秒才能看到屏幕上出现字母。
但抢占也不是免费的。频繁的抢占意味着频繁的上下文切换------保存当前进程的寄存器、页表、内核栈指针,再恢复下一个进程的。这些开销虽然单次很小,但量大了也够喝一壶的。我见过有人把内核的抢占频率调得过高,结果系统吞吐量掉了30%。
调度器到底在想什么?
你以为调度器是个莫得感情的代码?其实它细腻得很。
它得分辨哪些是 I/O 密集型进程(比如数据库、网页服务器),哪些是 CPU 密集型进程(比如视频转码、挖矿脚本)。I/O 进程经常睡大觉(等待磁盘、网络),一旦醒来,内核得赶紧给它高优先级,让它赶紧处理完,好继续去睡。不然,用户点个网页卡半天,那是会砸电脑的呀。
而那些 CPU 密集型的,内核就冷酷多了:反正你有的忙,慢慢排队去吧。
这种"重交互、轻计算"的偏心,才是 Linux 桌面用起来还算丝滑的原因。
写了这么多年代码,我有时觉得咱们这些程序员,其实就是运行在公司这个巨型内核里的进程。老板是调度器,KPI 是 vruntime。有些人在红黑树的最左边拼命卷,争取那点调度时间;有些人则像僵尸进程一样,占着坑不干活,还得等父进程来收尸。
你说,要是哪天内核也跟咱们一样,心情不好直接来个 Panic,这世界是不是就安静了?
那我们现在该怎么玩?
写到这里,你可能觉得------进程调度这潭水太深了。但搞了十年业务,我最大的感悟是:大部分时候你不需要深入了解调度器,但你得知道什么时候需要。
比如你遇到以下问题:
- 为什么我的实时任务偶尔会卡一下?
- 为什么CPU利用率没满,但我的QoS就是上不去?
- 为什么我把进程绑核了反而更慢了?
这些问题背后的答案,十有八九跟调度有关。
给你几个我吃了亏之后总结的小建议吧:
- 别在同一个核上混跑计算密集型和I/O密集型任务------I/O密集的进程经常主动让出CPU,看起来"友善",但计算密集型的会把它饿得死死的。
- 实时策略慎用------除非你真的知道SCHED_FIFO的优先级数字越小优先级越高(跟nice相反,别记混了),并且你能确保进程不会死循环。
- 学会看/proc/sched_debug------这个文件里藏着调度器所有的秘密,哪个进程被抢占了多少次,vruntime是多少,一清二楚。我当年要是早点知道这个文件,能少熬三个通宵。
- 容器环境注意CPU shares------K8s里配的CPU limit和request,底层就是靠CFS的调度参数实现的。别以为配了4个核就能真的用满4个核,调度器有自己的想法。
到了这儿,继续聊聊 NUMA 调度优化。现在多路服务器都是 NUMA 架构,CPU 访问本地内存快,访问远端内存慢。Linux 调度器有 NUMA 感知,尽量把进程和它用的内存页放在同一个节点上。内核还有个"自动 NUMA 平衡",后台慢慢迁移页。可问题它有时瞎折腾,大规模内存迁移造成性能风暴。我们线上直接关闭了这个特性,用 numactl --membind 手动绑内存,"粗暴"但有效,少掉好多头发。
再往前看,异构计算场景,比如 Intel 的 P-core/E-core(大小核),有的核强有的核弱,CFS 靠一套 vruntime 公平逻辑显然不够用了。内核社区已经在推 EAS(能效感知调度)等机制,根据算力差異决定进程放哪儿。容器化环境下,对毫秒级延迟敏感的服务,如何跟批处理任务安全混部?未来调度器可能要变得更"懂业务",甚至引入一些启发式策略。十年前我笑称"哪天调度器用上机器学习",现在看,也不是完全没可能,是吧?
就这样吧,别扯远了。进程调度这个话题,讲个三天三夜也讲不完。我写这篇的时候,我的笔记本风扇又呼呼转了------也不知道是Chrome在搞鬼还是内核调度器又在跟谁较劲。不过这次我不会骂它了,我只会轻轻敲下top,然后对着那列NI值,露出一丝苦笑。
毕竟,理解了调度,才算是跟内核打了个照面。虽然我可能一辈子也不会去改调度器的源码。