
🔥草莓熊Lotso: 个人主页
❄️个人专栏: 《C++知识分享》 《Linux 入门到实践:零基础也能懂》
✨生活是默默的坚持,毅力是永久的享受!
🎬 博主简介:

文章目录
- 前言:
- [一. stream () 同步流式传输](#一. stream () 同步流式传输)
-
- [1.1 基础使用](#1.1 基础使用)
- [1.2 AIMessageChunk 详解](#1.2 AIMessageChunk 详解)
- [二. astream () 异步流式传输](#二. astream () 异步流式传输)
-
- [2.1 异步编程基础](#2.1 异步编程基础)
- [2.2 异步流式传输实现](#2.2 异步流式传输实现)
- [三. 自定义流式输出格式](#三. 自定义流式输出格式)
-
- [3.1 使用 StrOutputParser](#3.1 使用 StrOutputParser)
- [3.2 按句子流式输出](#3.2 按句子流式输出)
- [四. 深度探索流式传输原理](#四. 深度探索流式传输原理)
-
- [4.1 SSE 协议详解](#4.1 SSE 协议详解)
- [4.2 LangChain 流式传输流程分析](#4.2 LangChain 流式传输流程分析)
- [五. 使用 LangSmith 跟踪 LLM 应用](#五. 使用 LangSmith 跟踪 LLM 应用)
-
- [5.1 LangSmith 简介](#5.1 LangSmith 简介)
- [5.2 配置 LangSmith](#5.2 配置 LangSmith)
- [5.3 查看跟踪结果](#5.3 查看跟踪结果)
- 结尾
前言:
在构建大语言模型(LLM)应用时,用户体验是决定产品成败的关键因素之一。传统的
invoke()调用方式会等待模型生成完整响应后才一次性返回结果,当生成长文本时,用户会面临长时间的空白等待,这严重影响了交互体验。流式传输(Streaming)技术正是为了解决这个问题而生的。它允许模型在生成内容的过程中逐块返回结果,让用户能够实时看到输出,就像真人在打字一样。本文将深入解析 LangChain 中流式传输的实现原理,从同步流式到异步流式,从基础使用到底层协议分析,并介绍如何使用 LangSmith 这一强大工具来监控和调试你的 LLM 应用。
一. stream () 同步流式传输
1.1 基础使用
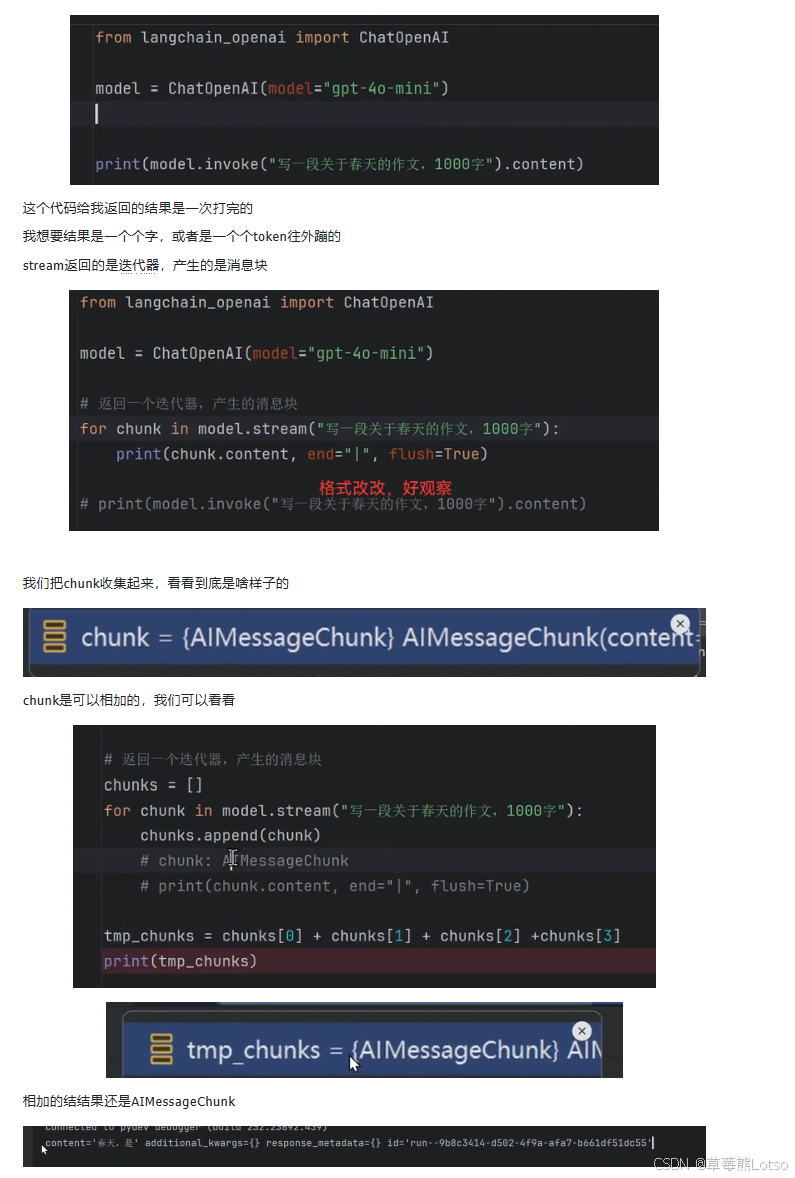
LangChain 的聊天模型实现了标准的 Runnable 接口,因此天然支持流式传输。最简单的流式传输方式是使用 .stream() 方法,它返回一个迭代器,每次产生一个 AIMessageChunk 对象。
python
from langchain_openai import ChatOpenAI
# 初始化大模型
model = ChatOpenAI(model="gpt-4o-mini")
# 流式输出
for chunk in model.stream("写一段关于春天的作文,1000字"):
print(chunk.content, end="", flush=True)运行这段代码,你会看到文本逐字逐句地显示在屏幕上,而不是等待几秒钟后一次性出现。
1.2 AIMessageChunk 详解
.stream() 方法返回的每个元素都是一个 AIMessageChunk 对象,它代表了 AIMessage 的一部分。AIMessageChunk 有一个非常重要的特性:可以直接相加。
python
chunks = []
for chunk in model.stream("写一段关于春天的作文,1000字"):
chunks.append(chunk)
# 将所有消息块相加,得到完整的消息
full_message = chunks[0]
for chunk in chunks[1:]:
full_message += chunk
print(full_message.content)相加后的结果仍然是一个 AIMessageChunk 对象,它包含了所有块的内容和元数据。这个特性在我们需要缓存完整响应或进行后续处理时非常有用。
二. astream () 异步流式传输
2.1 异步编程基础
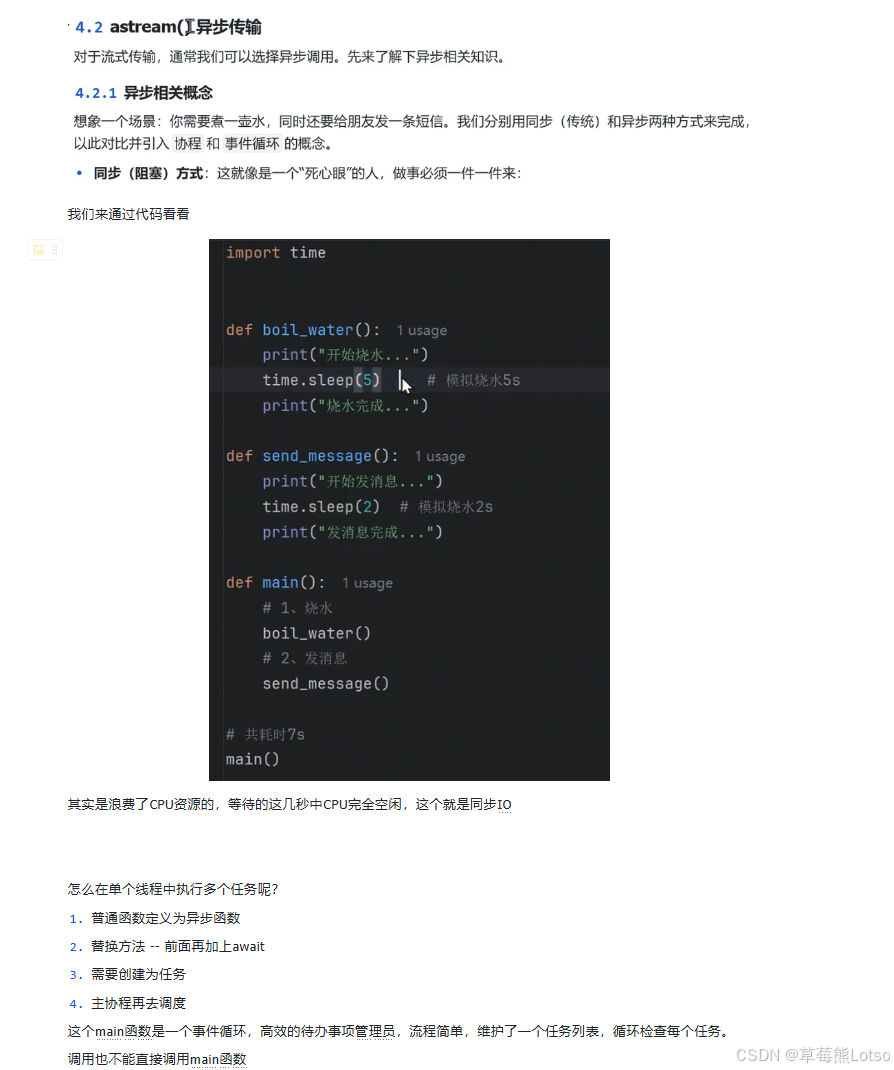
在讲解异步流式传输之前,我们先通过一个生活中的例子来理解同步和异步的区别。
想象你需要煮一壶水,同时还要给朋友发一条短信:
- 同步方式:先花 5 分钟煮水,水开了再花 2 分钟发短信,总共耗时 7 分钟。在煮水的 5 分钟里,你什么也做不了,只能干等着。
- 异步方式:开始煮水后,立刻去发短信,2 分钟短信发完了,再等 3 分钟水开,总共耗时 5 分钟。在煮水的等待时间里,你可以去做其他事情。
在 Python 中,我们使用 asyncio 库来实现异步编程,核心概念包括:
- 协程(Coroutine) :使用
async def定义的函数,可以在执行过程中暂停并稍后恢复。 - await:用于暂停协程的执行,等待异步操作完成。
- 事件循环(Event Loop):负责调度和管理协程的执行。
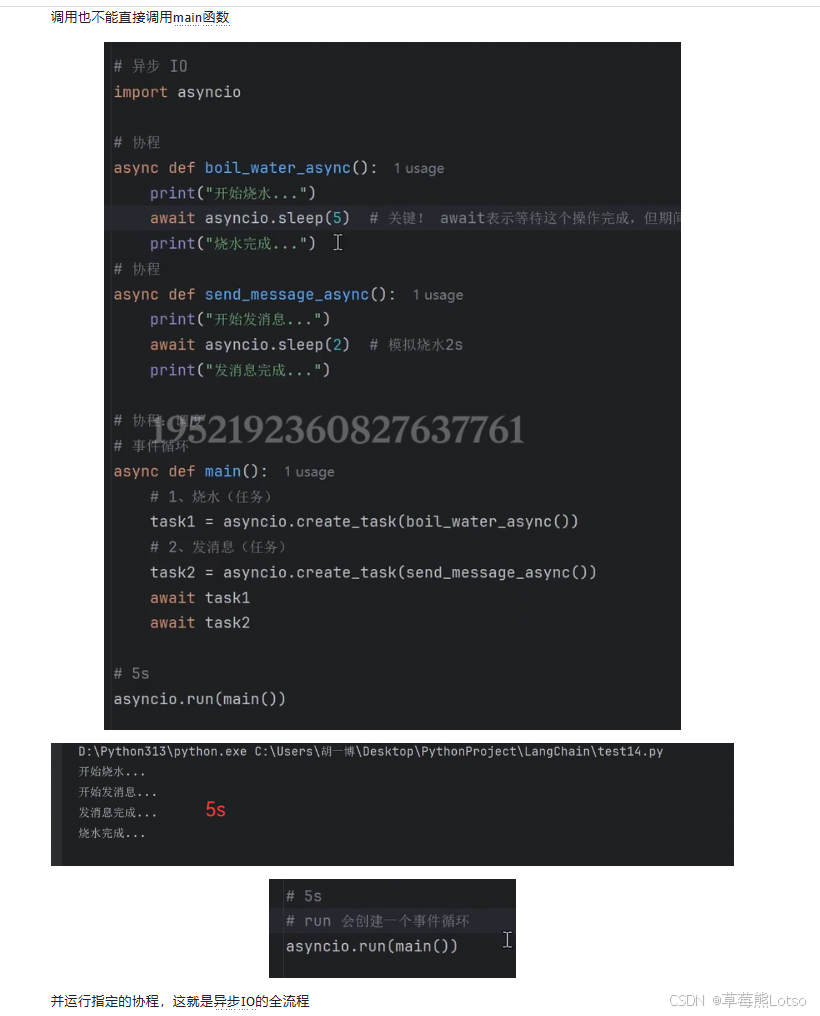
python
import asyncio
# 定义协程
async def boil_water_async():
print("开始烧水...")
await asyncio.sleep(5) # 模拟烧水5秒
print("水开了!")
async def send_message_async():
print("开始发短信...")
await asyncio.sleep(2) # 模拟发短信2秒
print("短信发送成功!")
async def main():
# 创建任务并交给事件循环调度
task1 = asyncio.create_task(boil_water_async())
task2 = asyncio.create_task(send_message_async())
# 等待所有任务完成
await task1
await task2
# 运行主协程
asyncio.run(main())运行结果:
Plain
开始烧水...
开始发短信...
短信发送成功!
水开了!可以看到,总耗时只有 5 秒,而不是 7 秒,这就是异步编程的优势。
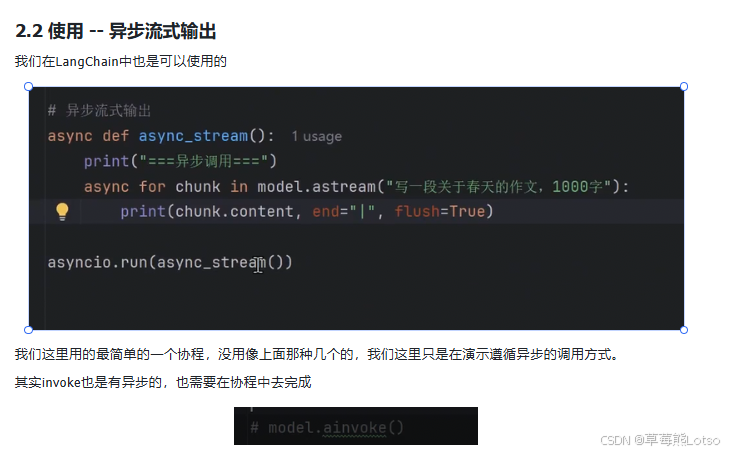
2.2 异步流式传输实现
LangChain 提供了 .astream() 方法来支持异步流式传输,这在构建 Web 服务(如 FastAPI)时特别有用,可以避免阻塞服务器的事件循环。
python
from langchain_openai import ChatOpenAI
import asyncio
model = ChatOpenAI(model="gpt-4o-mini")
async def async_stream():
print("=== 异步调用 ===")
async for chunk in model.astream("写一段关于春天的作文,1000字"):
print(chunk.content, end="", flush=True)
asyncio.run(async_stream())

三. 自定义流式输出格式
3.1 使用 StrOutputParser
默认情况下,.stream() 方法返回的是 AIMessageChunk 对象,我们通常只需要其中的文本内容。这时可以使用 StrOutputParser 来提取文本内容。
python
from langchain_openai import ChatOpenAI
from langchain_core.output_parsers import StrOutputParser
model = ChatOpenAI(model="gpt-4o-mini")
parser = StrOutputParser()
# 构建链
chain = model | parser
# 流式输出
for chunk in chain.stream("写一段关于爱情的歌词,需要5句话"):
print(chunk, end="|", flush=True)输出结果:
Plain
|在|星|光|下|我|们|相|拥|,|心|跳|如|歌|轻|轻|动|;|
|岁|月|如|流|水|般|匆|匆|,|爱|意|却|在|时|光|中|永|恒|。|
|你|的|笑|容|是|我|梦|中|,|温|暖|我|每|一|个|孤|单|的|瞬|间|;|
|就|算|风|雨|再|大|,|也|愿|与|君|同|舟|共|渡|;|
|只|愿|携|手|一|生|,|共|享|这|无|尽|的|爱|。|||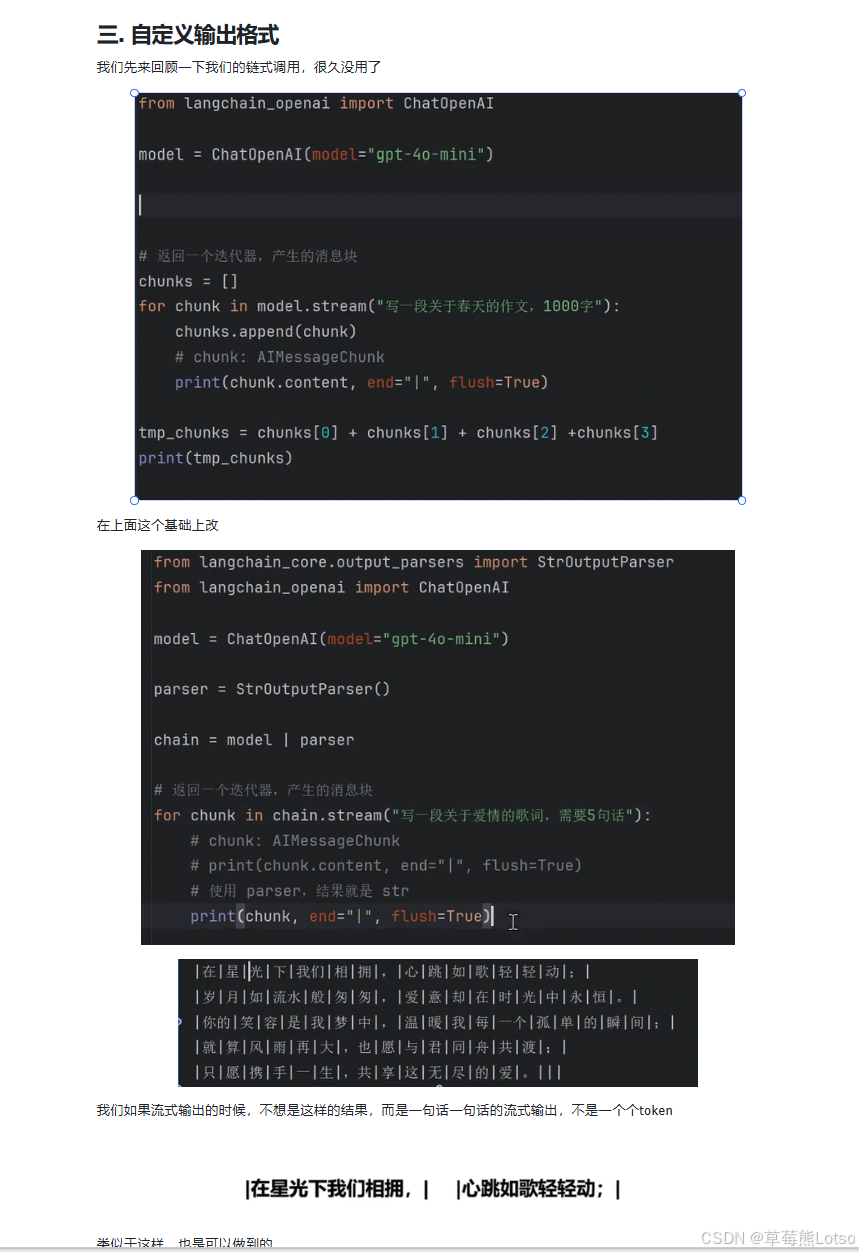
3.2 按句子流式输出
有时候我们不希望逐字输出,而是希望一句话一句话地输出。这可以通过自定义生成器来实现。
python
from langchain_openai import ChatOpenAI
from langchain_core.output_parsers import StrOutputParser
from typing import Iterator, List
model = ChatOpenAI(model="gpt-4o-mini")
parser = StrOutputParser()
# 自定义生成器:按句号分割文本
def split_into_sentences(input: Iterator[str]) -> Iterator[List[str]]:
buffer = ""
for chunk in input:
buffer += chunk
# 只要缓冲区中有句号,就分割出一个句子
while "。" in buffer:
stop_index = buffer.index("。")
# 产出一个句子
yield [buffer[:stop_index].strip() + "。"]
# 更新缓冲区,保留句号之后的内容
buffer = buffer[stop_index + 1:]
# 处理缓冲区中剩余的内容
if buffer.strip():
yield [buffer.strip()]
# 构建链
chain = model | parser | split_into_sentences
# 流式输出
for chunk in chain.stream("写一段关于爱情的歌词,需要5句话,每句话用中文句号隔开。"):
print(chunk, end="\n", flush=True)输出结果:
Plain
['在夜空下与你相拥,星光闪烁如我们的梦。']
['心跳声如同旋律,伴随风儿轻轻送。']
['每一次温柔的呼唤,都是对你深深的承诺。']
['时间静止在这一刻,爱在彼此眼中流动。']
['无论未来多么遥远,牵手同行是我唯一的愿望。']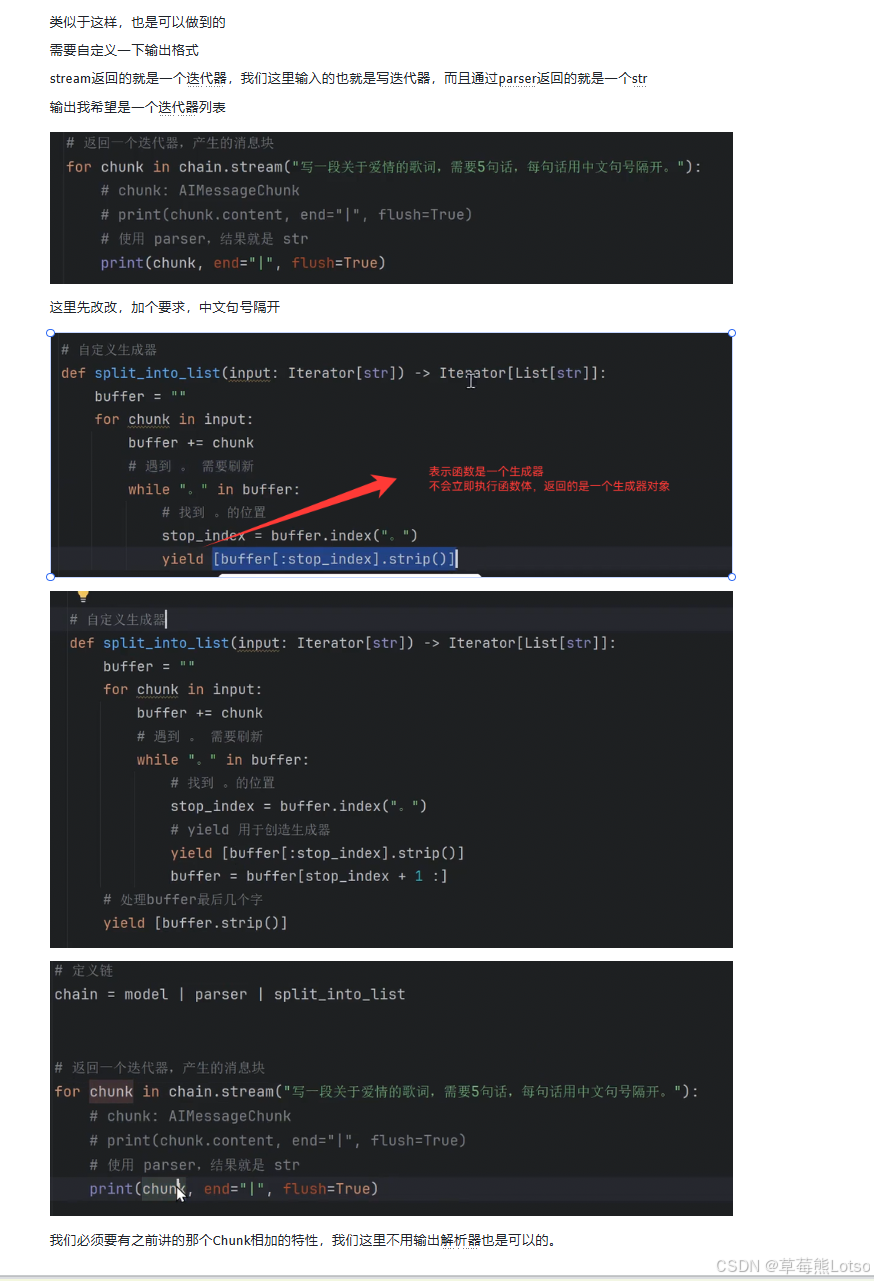
四. 深度探索流式传输原理
4.1 SSE 协议详解
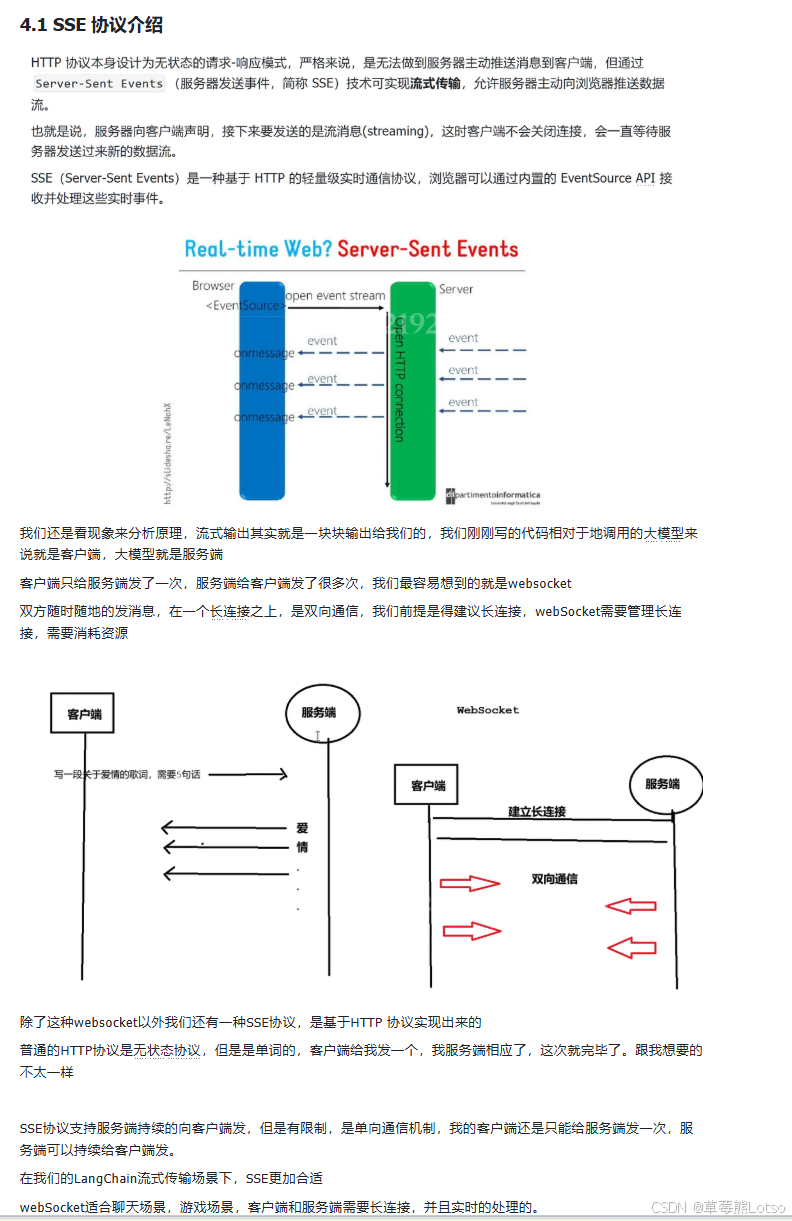
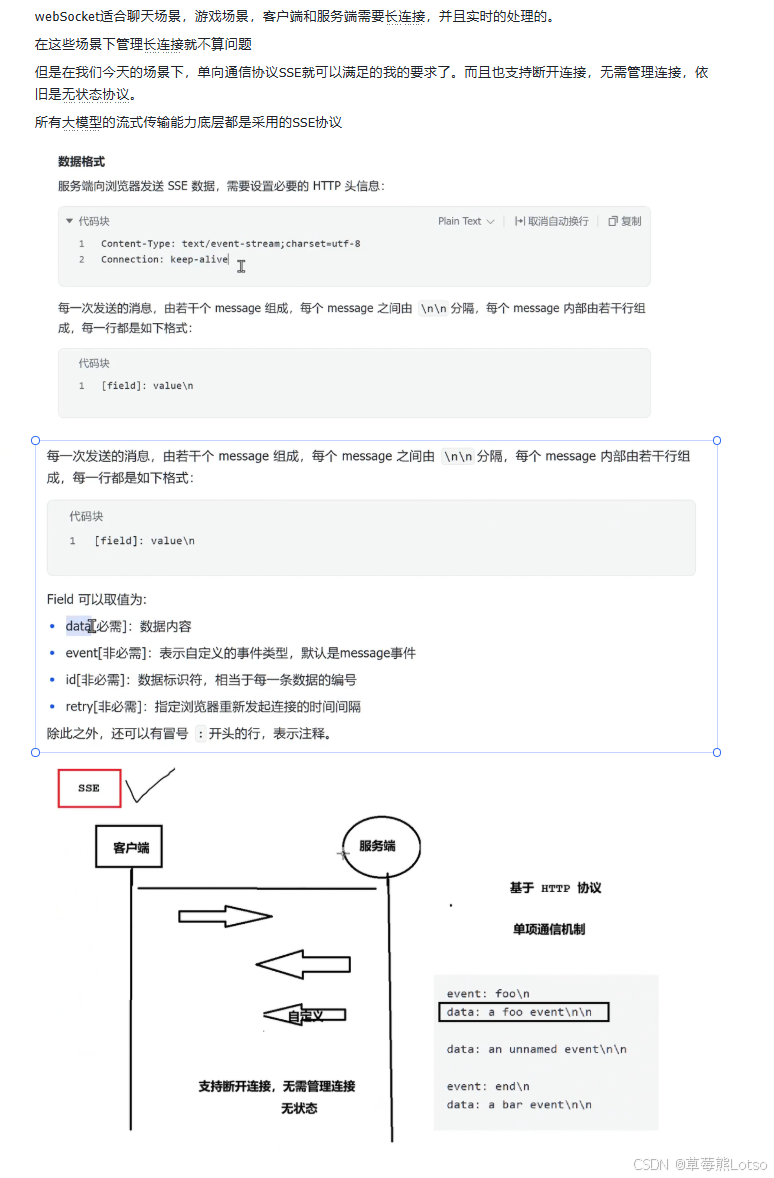
你可能会好奇,流式传输底层是如何实现的?为什么服务器可以持续不断地向客户端发送数据?答案就是 SSE(Server-Sent Events,服务器发送事件) 协议。
SSE 是一种基于 HTTP 的轻量级实时通信协议,它允许服务器主动向客户端推送数据流。与 WebSocket 不同,SSE 是单向通信,只能由服务器向客户端发送数据。
| 特性 | SSE | WebSocket |
|---|---|---|
| 协议基础 | HTTP | 独立的 WebSocket 协议 |
| 通信方向 | 单向(服务器→客户端) | 双向 |
| 连接管理 | 自动重连 | 需要手动管理 |
| 数据格式 | 文本 | 文本和二进制 |
| 使用场景 | 实时通知、流式输出 | 聊天、游戏、实时协作 |
在 LLM 流式传输场景下,SSE 是最合适的选择,因为我们只需要服务器向客户端推送生成的文本,不需要客户端向服务器发送额外的数据。
SSE 数据格式
SSE 的数据格式非常简单,每个消息由若干行组成,每行的格式为 [field]: value\n,消息之间用 \n\n 分隔。
Plain
data: 你好\n\n
data: 我是\n
data: 一个AI助手\n\n
event: end\n
data: 对话结束\n\n常用的字段包括:
data:必需,数据内容event:可选,自定义事件类型id:可选,数据标识符retry:可选,指定浏览器重新发起连接的时间间隔
4.2 LangChain 流式传输流程分析
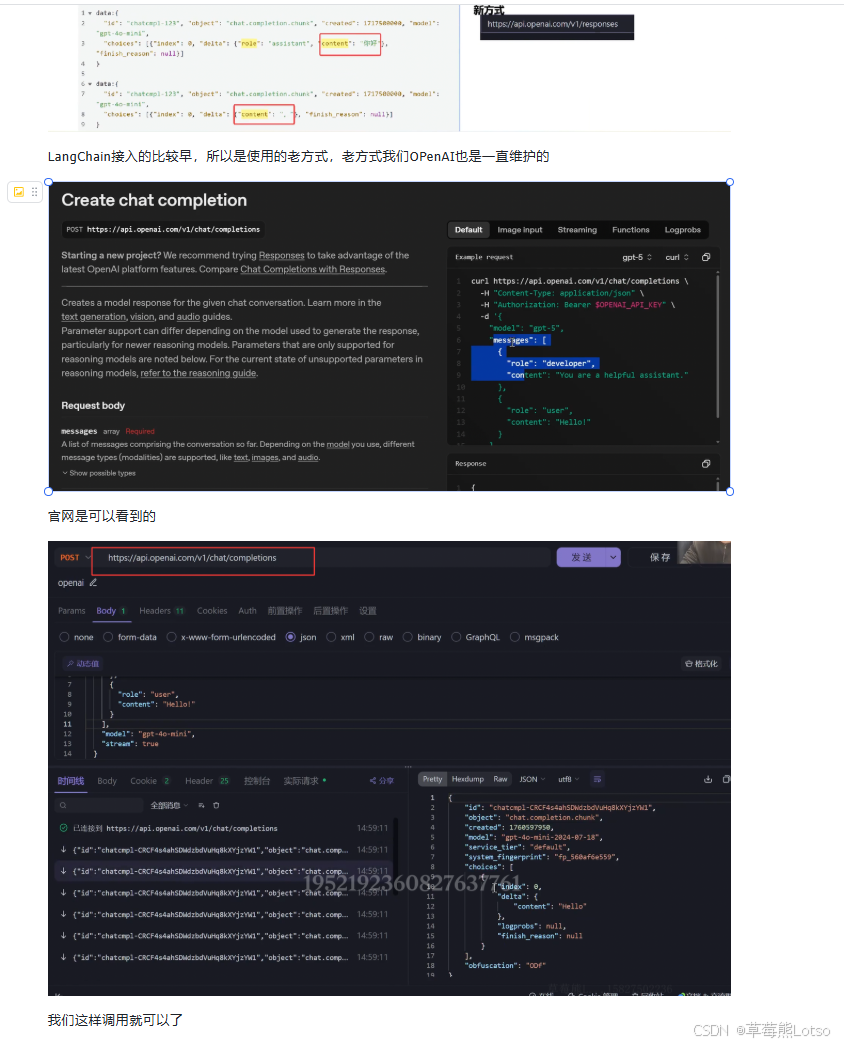
LangChain 本身并不提供底层的网络传输协议,它只是封装了大模型供应商提供的 SDK。以 OpenAI 为例,LangChain 的流式传输流程如下:
- 发起请求 :LangChain 调用 OpenAI SDK 的
chat.completions.create()方法,并设置stream=True。 - 建立连接 :OpenAI SDK 向
https://api.openai.com/v1/chat/completions发送 HTTP 请求,请求头中包含Accept: text/event-stream。 - 接收响应:OpenAI 服务器以 SSE 格式持续返回数据块。
- 转换格式 :LangChain 将 OpenAI 返回的原始数据块转换为
AIMessageChunk对象。 - 返回结果 :通过迭代器将
AIMessageChunk对象逐个返回给用户。
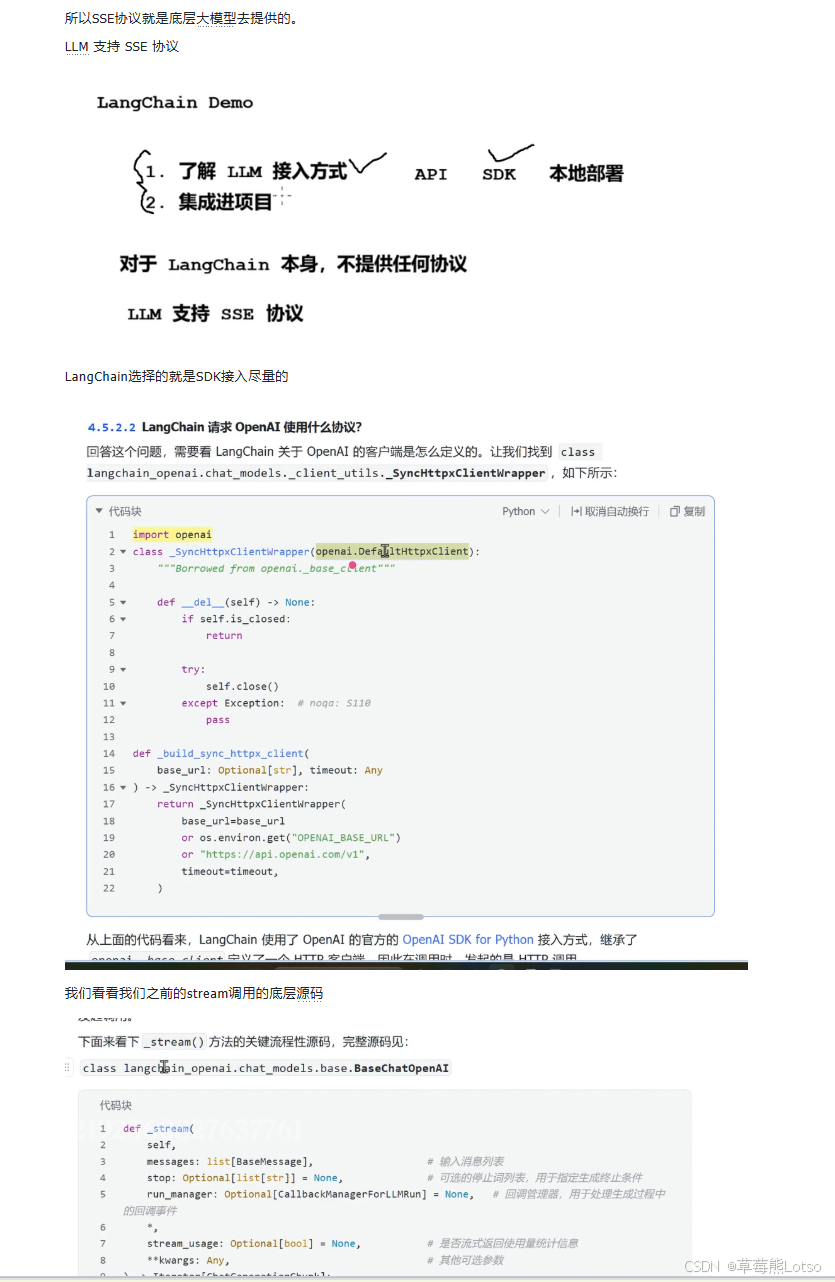
源码解析:_stream () 方法
BaseChatOpenAI 类中的 _stream() 方法是流式传输的核心实现:
python
def _stream(
self,
messages: list[BaseMessage],
stop: Optional[list[str]] = None,
run_manager: Optional[CallbackManagerForLLMRun] = None,
**kwargs: Any,
) -> Iterator[ChatGenerationChunk]:
# 1. 强制启用流式模式
kwargs["stream"] = True
# 2. 构建请求 payload
payload = self._get_request_payload(messages, stop=stop, **kwargs)
# 3. 发起调用
response = self.client.create(**payload)
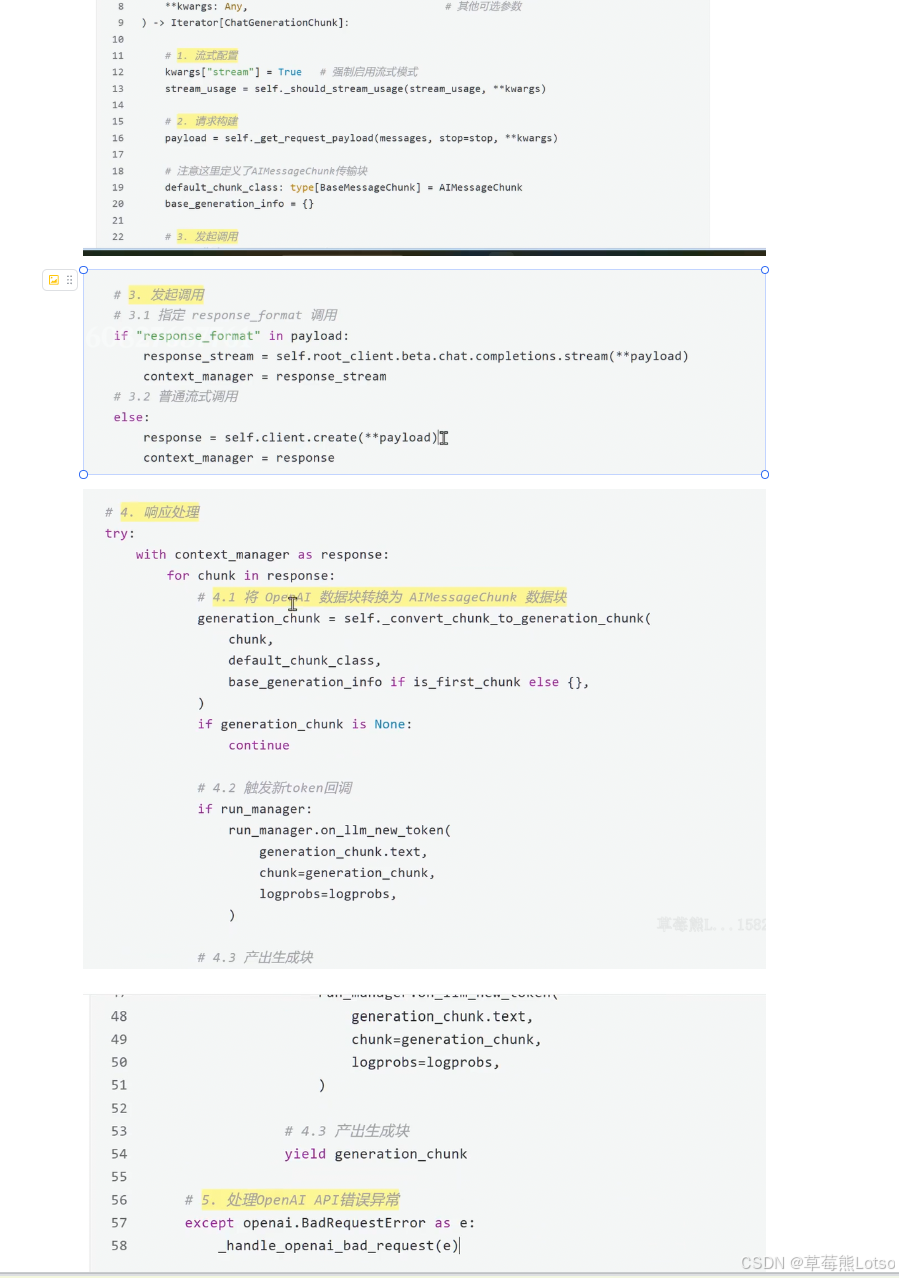
# 4. 处理响应
with response as response:
for chunk in response:
# 将 OpenAI 数据块转换为 AIMessageChunk
generation_chunk = self._convert_chunk_to_generation_chunk(
chunk,
AIMessageChunk,
{}
)
if generation_chunk is None:
continue
# 触发回调
if run_manager:
run_manager.on_llm_new_token(
generation_chunk.text,
chunk=generation_chunk,
)
# 产出生成块
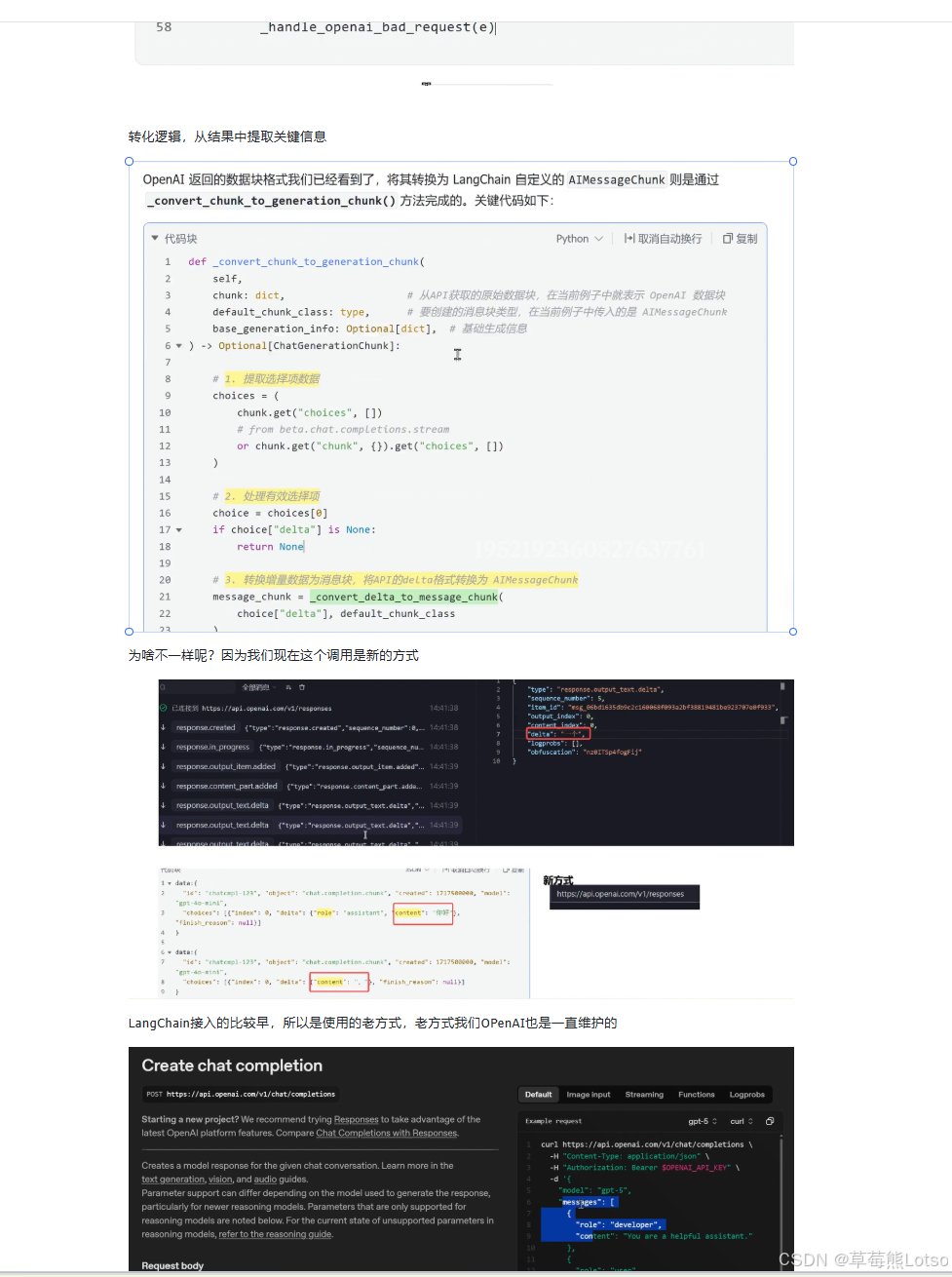
yield generation_chunk源码解析:_convert_chunk_to_generation_chunk () 方法
这个方法负责将 OpenAI 返回的原始数据块转换为 LangChain 的 AIMessageChunk 对象:
python
def _convert_chunk_to_generation_chunk(
self,
chunk: dict,
default_chunk_class: type,
base_generation_info: Optional[dict],
) -> Optional[ChatGenerationChunk]:
# 提取选择项数据
choices = chunk.get("choices", [])
if not choices:
return None
choice = choices[0]
if choice["delta"] is None:
return None
# 将 delta 格式转换为 AIMessageChunk
message_chunk = _convert_delta_to_message_chunk(
choice["delta"], default_chunk_class
)
# 构建生成块
generation_chunk = ChatGenerationChunk(
message=message_chunk,
generation_info=base_generation_info
)
return generation_chunk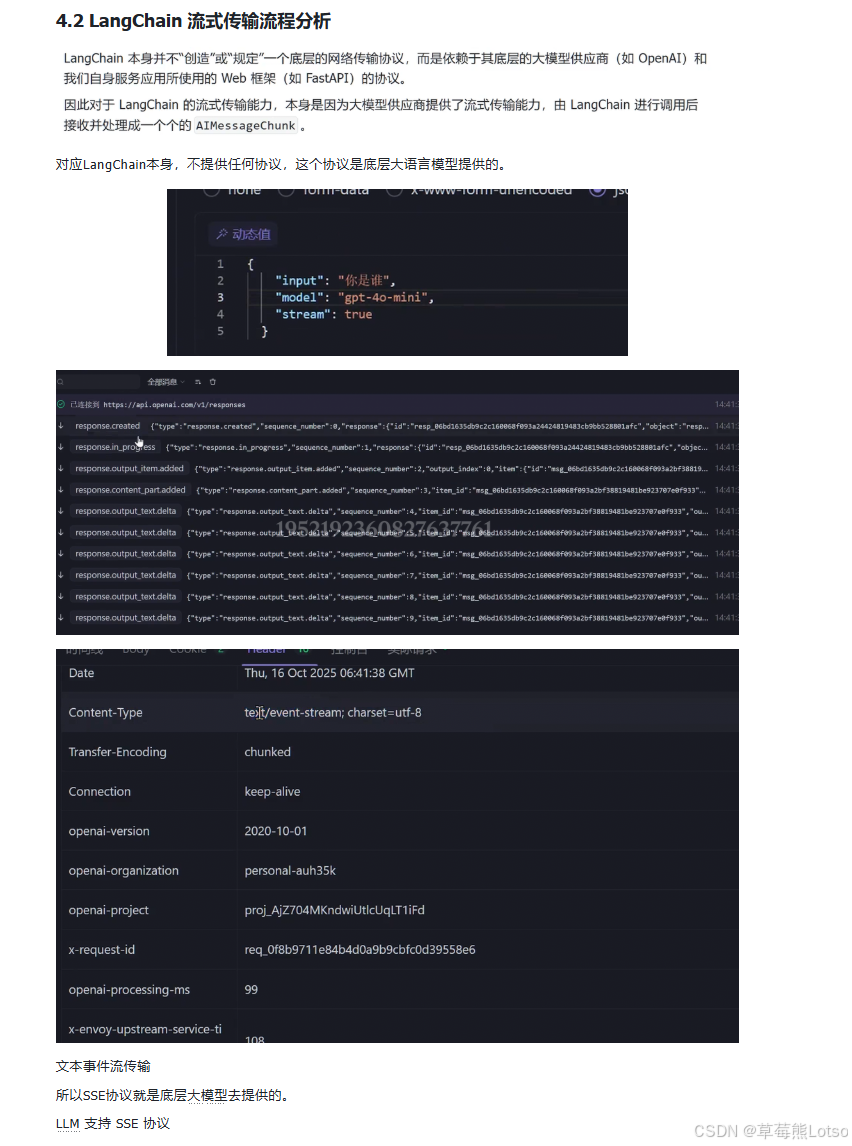
五. 使用 LangSmith 跟踪 LLM 应用
5.1 LangSmith 简介
随着 LLM 应用变得越来越复杂,包含多个步骤和多次 LLM 调用,调试和监控变得越来越困难。LangSmith 是 LangChain 官方推出的一个用于构建生产级 LLM 应用的平台,它提供了强大的跟踪、监控和评估功能。
LangSmith 的主要特点:
- 框架无关:可以与 LangChain、LangGraph 一起使用,也可以单独使用
- 全链路跟踪:记录应用中每一步的输入、输出和耗时
- 可视化界面:以瀑布流形式展示调用流程
- 评估功能:自动评估 LLM 应用的性能和准确性
5.2 配置 LangSmith
使用 LangSmith 非常简单,只需要配置两个环境变量即可,不需要修改任何代码。
-
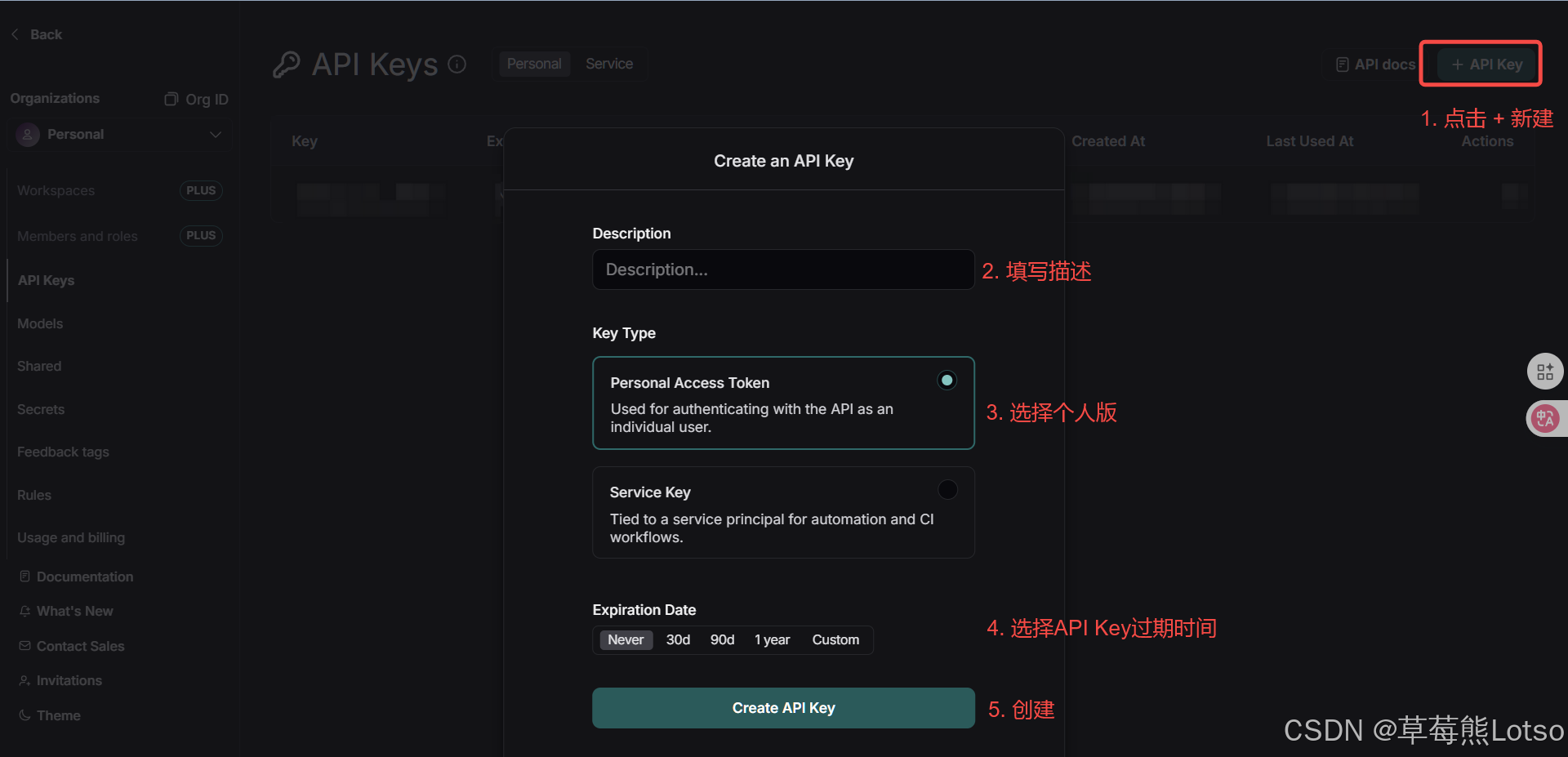
申请 API Key :
- 访问 LangSmith 官网 并注册账号
- 点击左侧的 "Settings",然后点击 "Create API Key"
- 保存生成的 API Key
-
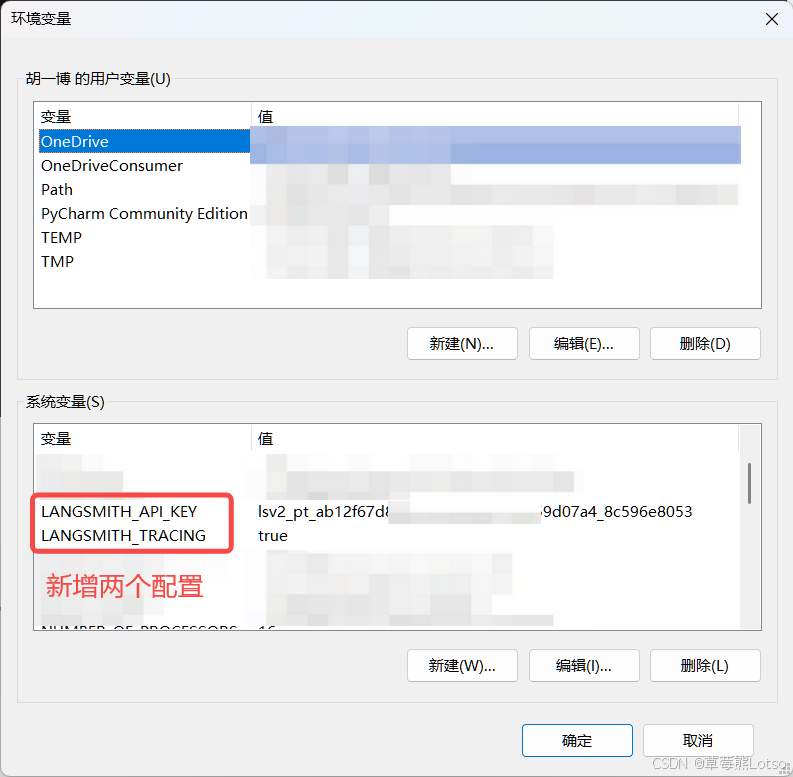
配置环境变量 : 在系统环境变量中添加以下两个变量:
1.PlainLANGSMITH_TRACING="true" LANGSMITH_API_KEY="你的 LangSmith API Key"
5.3 查看跟踪结果
配置完成后,运行任何 LangChain 代码,LangSmith 都会自动跟踪调用过程。
python
from langchain_openai import ChatOpenAI
from langchain_core.output_parsers import StrOutputParser
model = ChatOpenAI(model="gpt-4o-mini")
parser = StrOutputParser()
chain = model | parser
result = chain.invoke("写一段关于爱情的歌词,需要5句话")
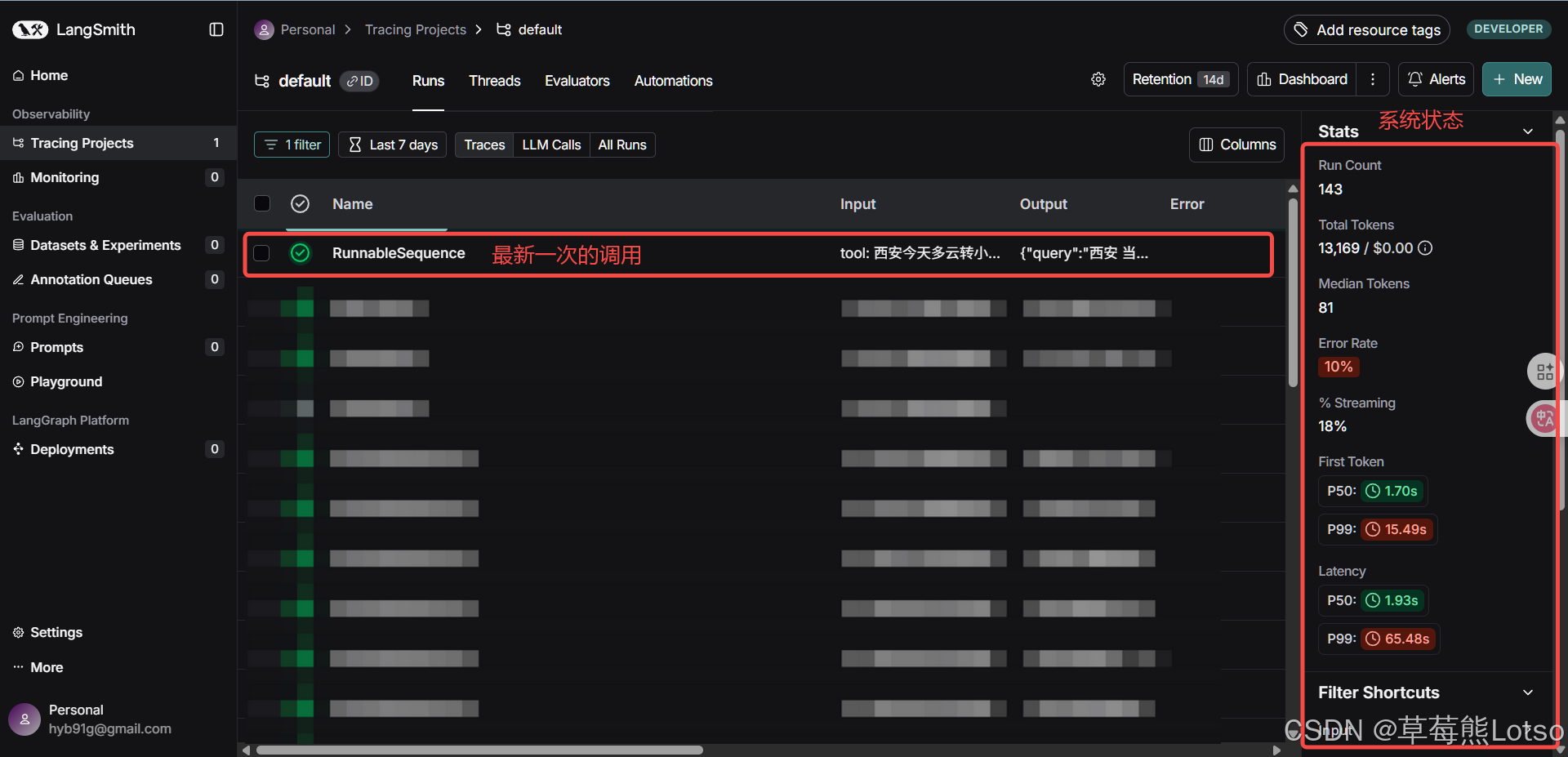
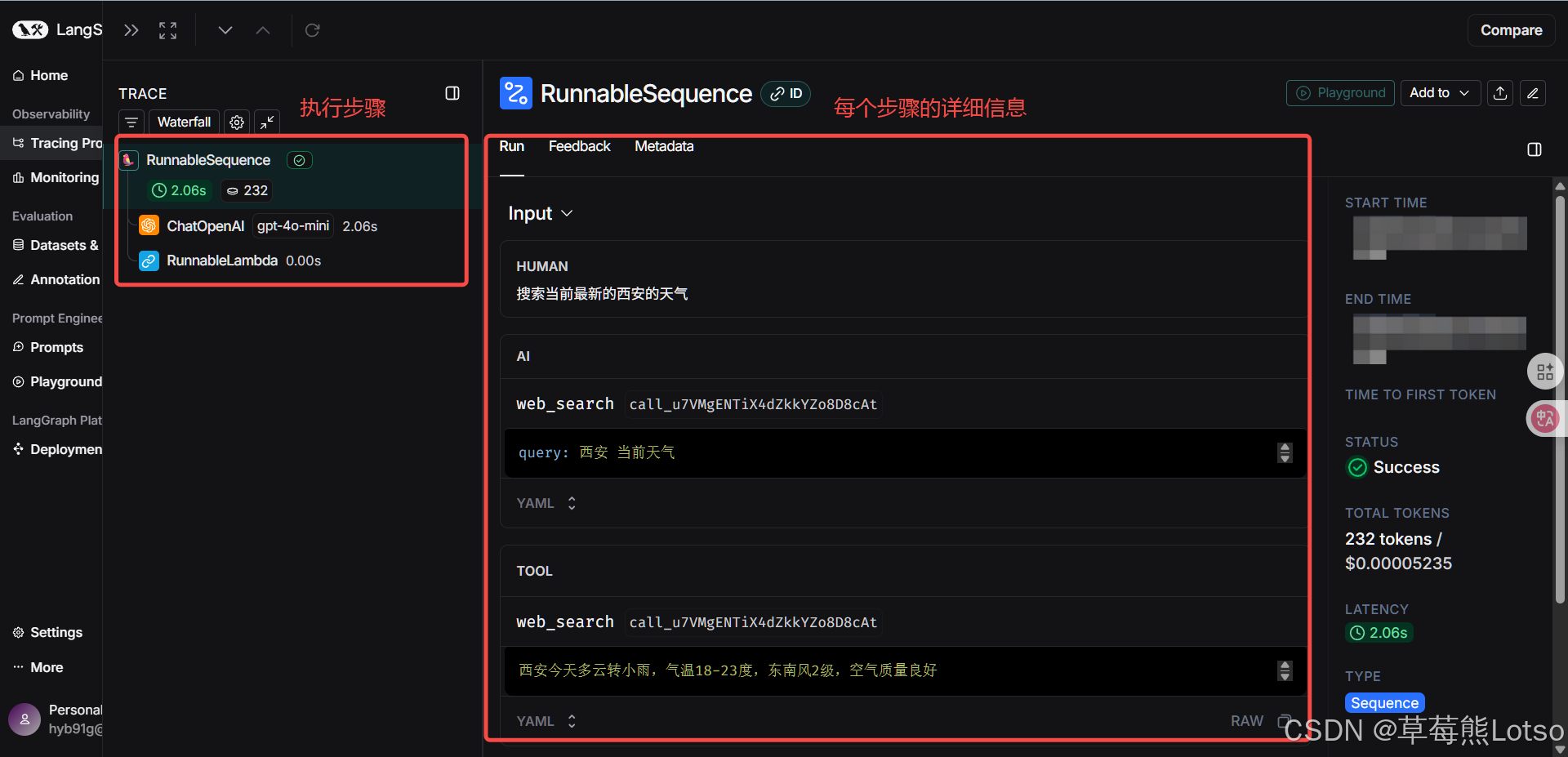
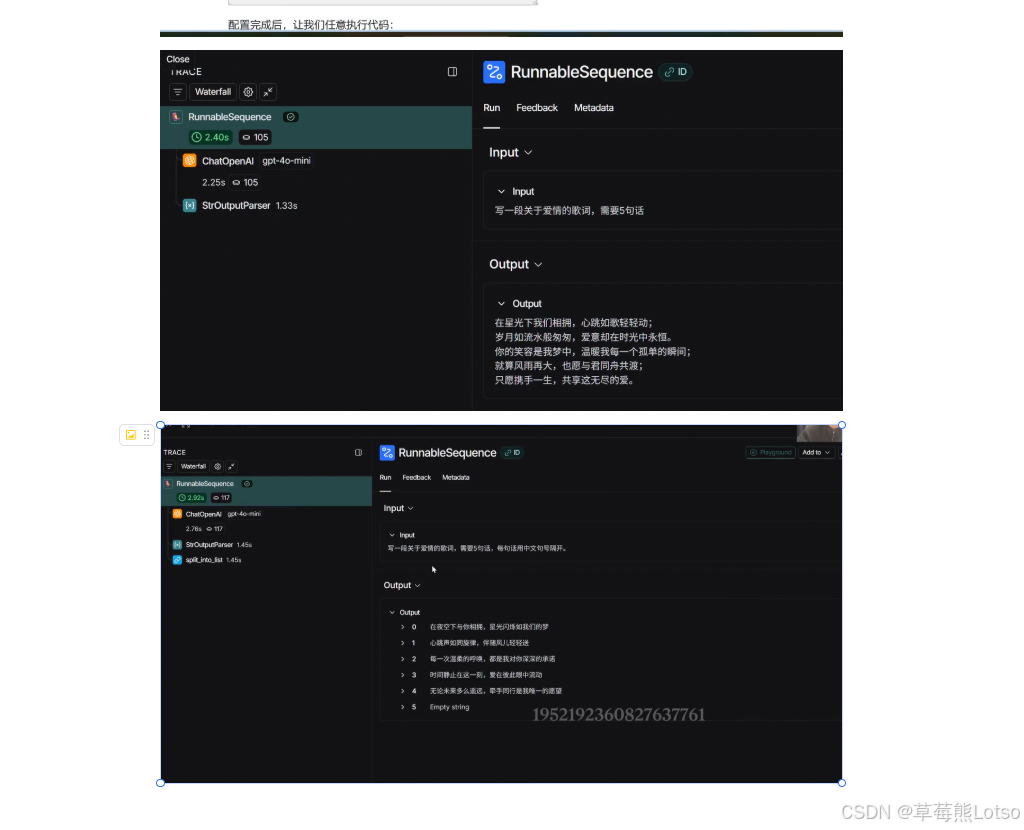
print(result)运行代码后,访问 LangSmith 平台,你会看到最新的跟踪记录。点击进入详情页,可以看到:
- 瀑布流视图:展示调用的完整流程和每个步骤的耗时
- 输入输出:查看每个步骤的输入和输出内容
- 元数据:包括模型名称、token 使用量、响应时间等
结尾
html
🍓 我是草莓熊 Lotso!若这篇技术干货帮你打通了学习中的卡点:
👀 【关注】跟我一起深耕技术领域,从基础到进阶,见证每一次成长
❤️ 【点赞】让优质内容被更多人看见,让知识传递更有力量
⭐ 【收藏】把核心知识点、实战技巧存好,需要时直接查、随时用
💬 【评论】分享你的经验或疑问(比如曾踩过的技术坑?),一起交流避坑
🗳️ 【投票】用你的选择助力社区内容方向,告诉大家哪个技术点最该重点拆解
技术之路难免有困惑,但同行的人会让前进更有方向~愿我们都能在自己专注的领域里,一步步靠近心中的技术目标!结语:流式传输是提升 LLM 应用用户体验的关键技术,它基于 SSE 协议实现,允许模型在生成内容的过程中逐块返回结果。LangChain 提供了简单易用的 API,支持同步和异步两种流式传输方式,并且允许我们自定义输出格式。LangSmith 则是调试和监控 LLM 应用的必备工具,它能够记录应用中每一步的详细信息,帮助我们快速定位问题和优化性能。在实际开发中,我们应该始终使用流式传输来提升用户体验,并利用 LangSmith 来监控应用的运行状态。这两个技术的结合,能够帮助我们构建出更加流畅、稳定和可靠的 LLM 应用。
✨把这些内容吃透超牛的!放松下吧✨ ʕ˘ᴥ˘ʔ づきらど
