写在前面
这是第六篇博客。经过前五篇的铺垫,项目的基础架构和核心功能已经基本成型。本篇不再赘述项目背景和基础搭建过程,而是聚焦于后端成功运行后,前后端联调阶段遇到的真实问题与解决方案------从SSE流式通信的跨端适配,到AI服务的反序列化陷阱,再到数据一致性的深度修复。这些内容代表了项目从"能跑"到"好用"的关键跨越。
本文建议在以下位置插入一张应用整体运行截图,例如AI对话页面或学情报告页面的完整运行截图,展示最终效果。图片说明可写为:计科智伴应用核心功能运行效果。
一、App端SSE流式通信的跨端适配
1.1 问题背景
AI对话模块采用SSE(Server-Sent Events)实现流式响应,后端逐字输出AI回复内容。在H5和小程序端,使用uni.request的enableChunked: true可以正常接收流数据,但在App端却出现了"数据憋到最后一次性出来"的现象------用户发送消息后长时间无响应,然后所有内容瞬间显示,完全失去了流式的意义。
1.2 根因分析
经过排查发现,uni-app的App端底层网络请求走的是Android OkHttp或iOS NSURLSession原生库。这些原生网络库对分块传输有自带的缓冲策略,会等待数据积累到一定量才向上层传递,导致enableChunked配置在App端形同虚设。
1.3 解决方案:renderjs + XMLHttpRequest桥接
既然原生网络层无法绕过,那就退回到浏览器层。uni-app的App端视图层实际运行在Webview中,可以直接使用浏览器原生的XMLHttpRequestAPI。通过renderjs机制,在视图层发起XHR请求,利用xhr.onprogress事件实现真正的流式数据接收。
核心思路是创建一个无UI的桥接组件AppSseBridge.vue,它包含两个部分:
逻辑层 :接收父组件传递的请求参数,通过$emit将chunk/done/error事件传回父组件。
renderjs层 :监听prop变化,用XMLHttpRequest发起POST请求,在onprogress回调中实时截取新增内容。
// renderjs层核心逻辑
setupSSEConnection(payload, ownerInstance) {
const xhr = new XMLHttpRequest();
xhr.open(payload.method, payload.url, true);
xhr.setRequestHeader('Content-Type', 'application/json');
// 关键:通过onprogress实现流式接收
xhr.onprogress = (event) => {
const newText = xhr.responseText.substring(this._cursor);
this._cursor = xhr.responseText.length;
if (newText) {
// 将新增内容传回逻辑层
ownerInstance.callMethod("onSSEChunk", newText);
}
};
xhr.send(JSON.stringify(payload.data));
}在request.js中通过条件编译实现平台分支:
export function sseRequest(url, data, callbacks) {
// #ifdef APP-PLUS
// App端:使用renderjs桥接方案
return createAppSseBridge(url, data, callbacks)
// #endif
// #ifndef APP-PLUS
// H5/小程序:使用uni.request + enableChunked
return createUniRequestSse(url, data, callbacks)
// #endif
}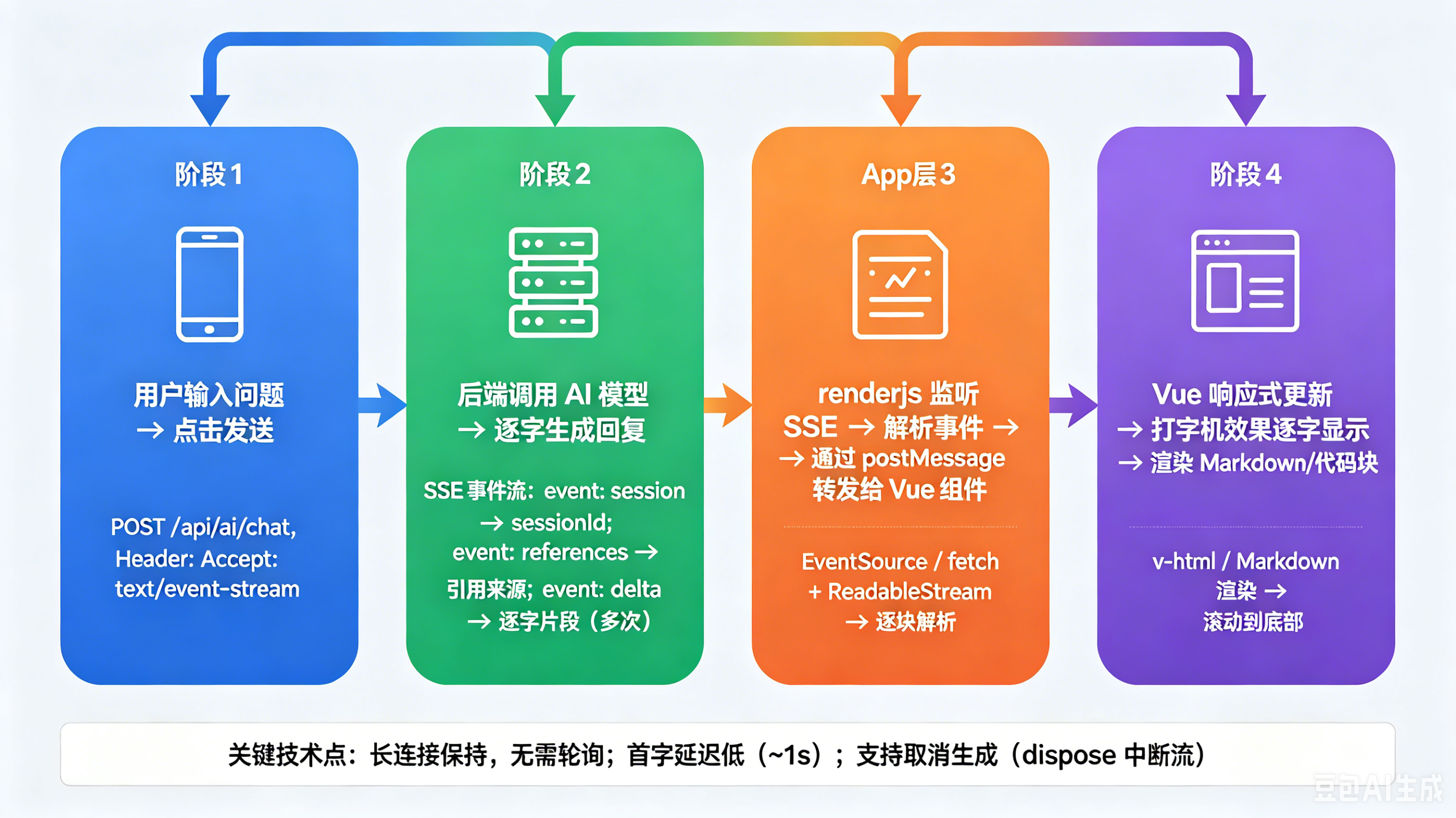
1.4 SSE数据解析修复
在实现过程中还发现一个细节问题:后端返回的SSE数据包含多种事件类型(如event:session_id、event:delta),如果简单累积所有data:字段,会导致多余内容混入AI回复。
修复方案是跟踪event:类型声明,只处理event:delta对应的数据行,忽略其他事件类型。这确保了AI回复内容的纯净性。
二、Markdown渲染与代码高亮
2.1 需求来源
AI对话返回的内容包含Markdown格式(标题、列表、代码块等),直接以纯文本显示效果很差。特别是代码块,没有语法高亮和格式化,可读性极差。
2.2 实现方案
引入marked作为Markdown解析器,highlight.js作为代码高亮引擎。在markdown.js中配置marked使用highlight.js进行代码块渲染:
import { marked } from 'marked'
import hljs from 'highlight.js'
marked.setOptions({
highlight: function(code, lang) {
if (lang && hljs.getLanguage(lang)) {
return hljs.highlight(code, { language: lang }).value
}
return hljs.highlightAuto(code).value
},
breaks: true, // 换行符转为<br>
gfm: true // 启用GitHub Flavored Markdown
})在chat.vue中,AI消息使用<rich-text>组件渲染生成的HTML:
<view class="message-bubble" v-if="msg.role === 'assistant'">
<rich-text :nodes="msg.renderedHtml"></rich-text>
</view>代码高亮采用Catppuccin Mocha配色方案,关键字紫色、字符串绿色、注释灰色、函数蓝色,整体风格统一且舒适。
三、AI错题识别的Jackson反序列化陷阱
3.1 问题现象
用户上传题目图片进行智能错题识别时,后端调用AI接口直接崩溃:
UnrecognizedPropertyException: Unrecognized field "text_tokens"
(class PromptTokensDetails), not marked as ignorable3.2 根因定位
Spring AI 1.0.0-M6的PromptTokensDetails类只定义了audio_tokens和cached_tokens两个字段,但我们使用的sophnet.com OpenAI兼容API返回了额外的text_tokens字段。Jackson默认对未知字段采取严格模式,遇到未定义的字段就抛出异常。
3.3 修复方案
从两个层面解决这个问题:
全局配置 :在application.yml中关闭Jackson的未知字段失败策略:
spring:
jackson:
deserialization:
fail-on-unknown-properties: false代码层面 :为RestClient.Builder和WebClient.Builder配置自定义的ObjectMapper,确保所有HTTP客户端都忽略未知字段:
ObjectMapper mapper = Jackson2ObjectMapperBuilder.json()
.featuresToDisable(DeserializationFeature.FAIL_ON_UNKNOWN_PROPERTIES)
.build();
converters.add(0, new MappingJackson2HttpMessageConverter(mapper));这里converters.add(0, ...)将自定义converter放在列表首位,确保优先于Spring Boot默认的converter生效。
四、UI全面优化:从功能到体验
4.1 AI对话页面优化
在功能跑通后,对AI对话页面进行了系统性的视觉升级:
顶部导航栏 :添加毛玻璃效果(backdrop-filter: blur(20rpx))和sticky定位,滚动时固定在顶部,底部边框改为半透明细线,整体更精致。
消息气泡:
-
用户消息采用渐变背景
linear-gradient(135deg, #4F6EF7, #8B5CF6),文字白色,视觉层次更清晰 -
AI消息使用白色背景配合柔和阴影和细边框
-
添加
messageIn入场动画,消息出现时从下方淡入
欢迎区域 :机器人头像添加float浮动动画(上下轻微浮动),标题和描述文字添加fadeInUp入场动画,页面加载时更有仪式感。
输入区域:修复bottom定位偏差,优化输入框聚焦态边框颜色,发送按钮添加渐变背景。
.msg-user .message-bubble {
background: linear-gradient(135deg, #4F6EF7 0%, #8B5CF6 100%);
box-shadow: 0 6rpx 16rpx rgba(79, 110, 247, 0.25);
color: #FFFFFF;
}
@keyframes fadeInUp {
from { opacity: 0; transform: translateY(20rpx); }
to { opacity: 1; transform: translateY(0); }
}
4.2 错题页面优化
错题页面的优化重点在于信息层次和交互反馈:
统计头部 :添加装饰性圆形背景元素(::before伪元素),统计卡片添加点击缩放效果。
筛选栏:改为sticky定位配合毛玻璃效果,滚动时始终可见。筛选标签间距从20rpx缩小到12rpx,更紧凑。
错题卡片:
-
添加
cardIn入场动画 -
题目内容添加独立背景框(浅灰色+圆角+细边框),与卡片主体区分
-
操作按钮改为水平排列,间距更合理
-
已掌握卡片透明度从0.6调整为0.65,保持可读性
.mistake-question-box {
background: #F9FAFB;
border-radius: 12rpx;
padding: 20rpx;
margin-bottom: 20rpx;
border: 1rpx solid #F3F4F6;
}@keyframes cardIn {
from { opacity: 0; transform: translateY(10rpx); }
to { opacity: 1; transform: translateY(0); }
}
4.3 移动端图片自适应修复
AI对话页面上传图片后,在移动端屏幕下图片超出消息气泡范围。根因是图片使用width: auto,当原图宽度超过容器时不会自动缩放。
修复方案:将width: auto改为width: 100%,添加box-sizing: border-box,配合父容器的overflow: hidden实现双重保护。
.message-image {
width: 100%; /* 改为100%,确保不超出容器 */
max-width: 100%;
height: auto;
box-sizing: border-box; /* padding/border不导致溢出 */
}五、知识前测与AI画像生成
5.1 动态出题机制
Onboarding流程中的知识前测从固定题目改为动态出题。用户选择课程后,系统调用GET /api/onboarding/quiz接口,根据所选课程从题库中随机抽取5道题目。
前端需要处理后端返回的题目格式:options可能是string[]或{label, content}[],需要统一转换为前端可用的格式。同时题目上方显示课程名和知识点名标签,让用户清楚当前题目所属范围。
5.2 AI学情建议生成
前测提交后,后端统计正确率,结合用户画像信息(学习目标、每日学习时间、期望分数等),调用AI接口生成约300字的学情分析报告。
提示词设计要点:
-
提供用户基本信息:学习目标、时间偏好、学习偏好
-
提供测试结果:各知识点正确率
-
要求输出:综合分析,指出优势和薄弱领域,给出具体学习路径建议
前端在学情报告页面将AI建议按行拆分,逐行渲染,每条建议独立成段,阅读体验更好。
// 将AI建议按行拆分
computed: {
parsedSuggestions() {
if (!this.aiSuggestions) return []
return this.aiSuggestions
.split('\n')
.filter(line => line.trim())
.map(line => line.replace(/^[\d\.\-\*]\s*/, ''))
}
}5.3 数据流设计
用户选课程 → 调用GET /api/onboarding/quiz获取题目
→ 用户答题 → 前端判断正确性 → 调用POST /api/onboarding/submit-quiz
→ 后端统计正确率 → 构建画像 → AI生成建议 → 入库
→ 前端接收画像数据 → 保存到本地+Pinia store → 跳转首页
→ 进入报告页 → 从store获取aiSuggestions → 渲染展示六、数据库与题库全面补充
6.1 知识点覆盖
查询发现16门课程没有关联知识点,包括离散数学、操作系统、数据库、算法设计与分析等核心课程。编写SQL脚本为每门课程添加5个核心知识点,共80个新知识点(kp_id 23-102)。
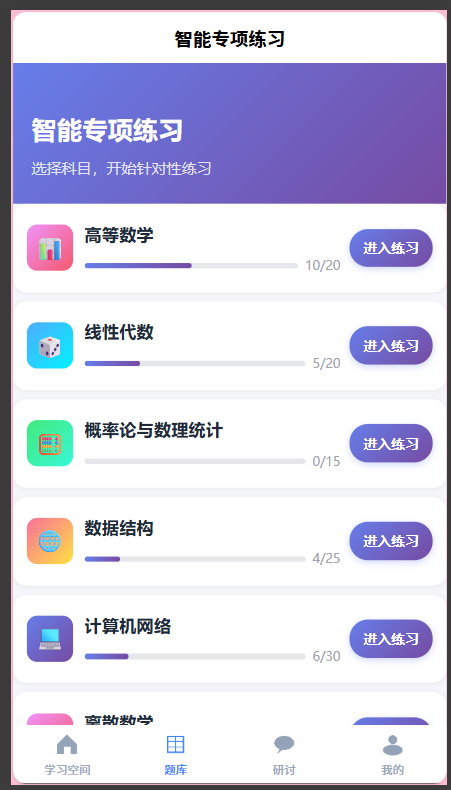
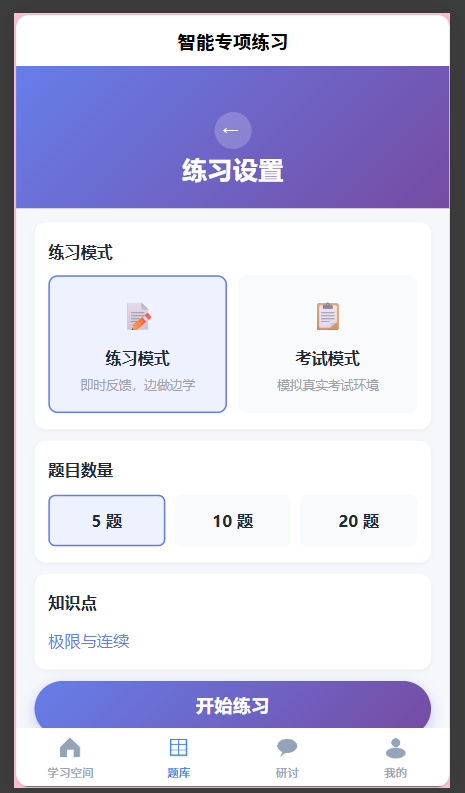
6.2 题库补充
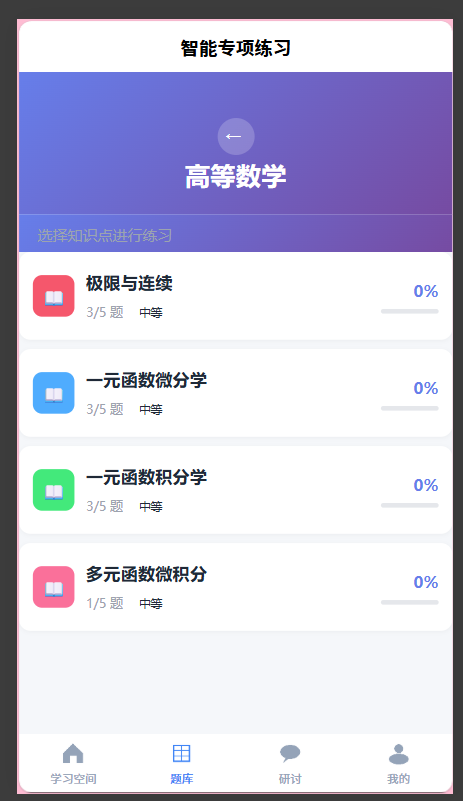
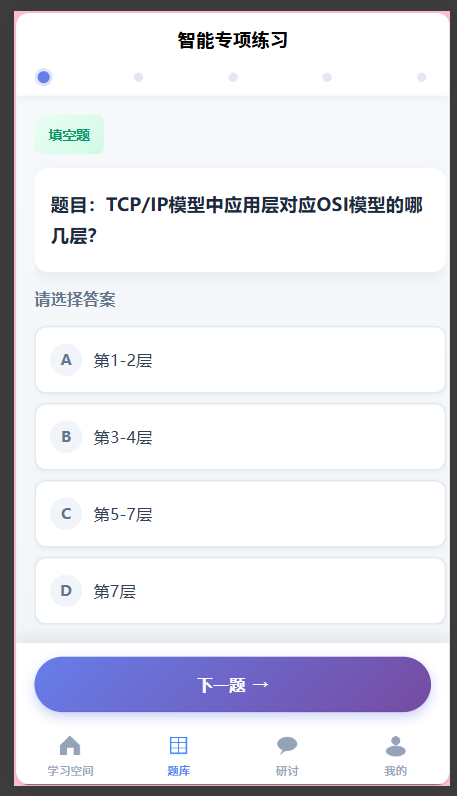
为80个新知识点各补充5道题目,共400道新题目。至此,21门课程全部有关联知识点,102个知识点每个都有5道题目,前测可覆盖所有课程的所有知识点。
6.3 数据库表结构同步
队友导入数据库时出现中文乱码和部分表缺失问题。使用pg_dump重新导出完整数据库(UTF-8编码),包含20张表的完整DDL结构和种子数据,使用--clean --if-exists支持安全覆盖导入。
七、数据一致性修复
7.1 个人主页编辑刷新不生效
问题:用户在个人主页编辑资料后,刷新页面仍显示旧数据。
根因 :profile-info-edit.vue的initForm()方法只在store中所有字段都为空时才调用fetchUserInfo()。由于Pinia store配置了persist持久化,store中始终有旧数据,导致条件永远不满足。
修复:改为每次进入页面都从后端获取最新数据:
// 修改前:只有所有字段为空时才获取
if (!info.name && !info.school && !info.major && !info.grade) {
await this.userStore.fetchUserInfo()
}
// 修改后:每次都获取最新数据
await this.userStore.fetchUserInfo()7.2 学情画像编辑后数据不同步
问题:用户在个人主页编辑学情画像后,其他页面看不到更新的数据。
根因:保存成功后只调用了后端接口写入数据库,没有更新Pinia store。
修复 :保存成功后调用profileStore.fetchUserProfile(userId)刷新store数据。同时在store中新增profile对象存储画像基础信息,配置persist持久化,确保数据在各页面间同步。
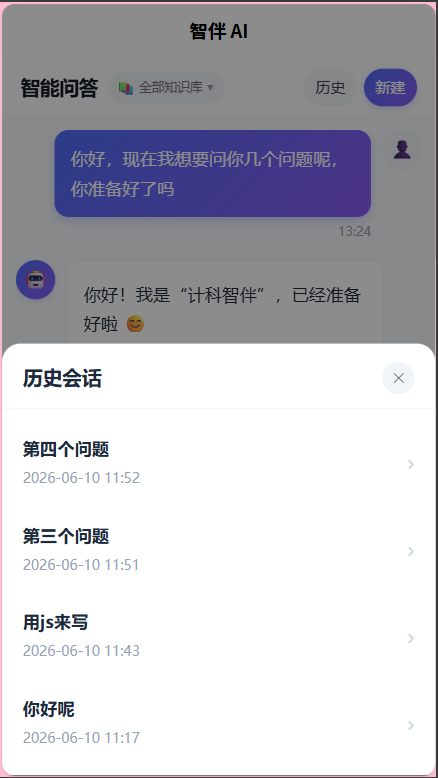
7.3 聊天历史消息渲染修复
问题:API返回历史消息包含assistant和user两条消息,但前端只显示了user消息,assistant消息内容为空。
根因 :loadChatHistory映射消息时没有为assistant消息生成renderedHtml字段。chat.vue模板中assistant消息使用<rich-text :nodes="msg.renderedHtml">渲染,renderedHtml为undefined时不显示任何内容。
修复 :在消息映射时添加renderedHtml字段,并调用renderMarkdown(content)生成HTML。同时添加.reverse()将后端倒序(最新在前)转为正序(最新在底部)。
this.messages = data.reverse().map((msg, idx) => {
const role = (msg.role || '').toLowerCase() === 'assistant' ? 'assistant' : 'user'
const content = msg.content || ''
return {
id: msg.msgId,
role,
content,
renderedHtml: role === 'assistant' && content ? renderMarkdown(content) : '',
time: formatTime(msg.createTime)
}
})
八、其他关键修复
8.1 新会话记录写入
新会话创建时,streamChat方法中没有调用sessionService将新会话写入数据库,导致listSessions接口查不到任何记录,用户点击历史按钮显示"没有历史会话"。
修复:在新会话创建后立即写入session表,使用try-catch包裹避免影响主流程。
8.2 习题接口适配
后端ExerciseApiController返回的question id是字符串类型,但submitSingleAnswer接口需要Long类型路径参数。同时options格式不匹配(后端string[]vs 前端{label, content}[])。
修复:在前端映射时进行类型转换和格式适配,使用String.fromCharCode(65 + i)自动生成A/B/C/D标签。
8.3 localhost解析问题
Windows hosts文件缺少127.0.0.1 localhost标准配置,部分客户端无法解析localhost。将application.yml中所有服务的localhost改为127.0.0.1(PostgreSQL、Redis、Neo4j、MinIO)。
8.4 Redis客户端恢复
之前因Lettuce在Windows上出现DNS解析问题临时切换为Jedis。现Redis容器稳定运行,恢复默认Lettuce客户端。
总结
本篇记录了后端运行后前后端联调阶段的核心工作。这个阶段的特点是问题驱动------大部分修改都源于实际运行中暴露的bug或体验问题。从SSE流式通信的跨端适配到Jackson反序列化陷阱,从UI全面优化到数据一致性修复,每一步都是对系统稳定性和用户体验的打磨。
下一步将重点关注知识库模块的改造和个性化学习功能的完善,让系统从"能用"真正走向"好用"。