写 PyTorch 的人,最常见的一句代码是 loss.backward()。
看起来很短。
但它背后不是一个函数那么简单,而是一整套动态计算图系统。
前向时,它记录每一步计算。反向时,它沿着计算图倒着走,用链式法则把梯度传回每一个参数。
这就是 Autograd。
1. 先把自动求导说成人话
模型训练,本质上是在问一个问题:
参数应该往哪个方向改,才能让 loss 变小?
这个"方向",就是梯度。
以前手写梯度,很痛苦。模型一复杂,公式就爆炸。PyTorch 的做法很直接:你只管写前向计算,反向梯度它帮你算。
可以把 Autograd 想成一本账。
前向计算时,每一步都记账:谁参与了计算,产生了什么结果,反向时该怎么还梯度。
调用 backward() 时,它从 loss 开始倒着翻账本,一层层把梯度算回去。
2. Autograd 解决了什么问题
神经网络训练有三件事:
第一,前向计算,得到预测值。
第二,计算 loss,知道错了多少。
第三,反向传播,算出每个参数应该怎么改。
Autograd 负责第三件事。
它不负责设计模型。
它不负责更新参数。
它只负责一件事:根据前向计算过程,自动计算梯度。
3. requires_grad:自动求导的开关
Tensor 默认只是一块数据。
如果你希望 PyTorch 追踪它参与的运算,就要打开 requires_grad。
import torch
x = torch.tensor(2.0, requires_grad=True)
y = x * x + 3 * x
y.backward()
print(x.grad) # tensor(7.)
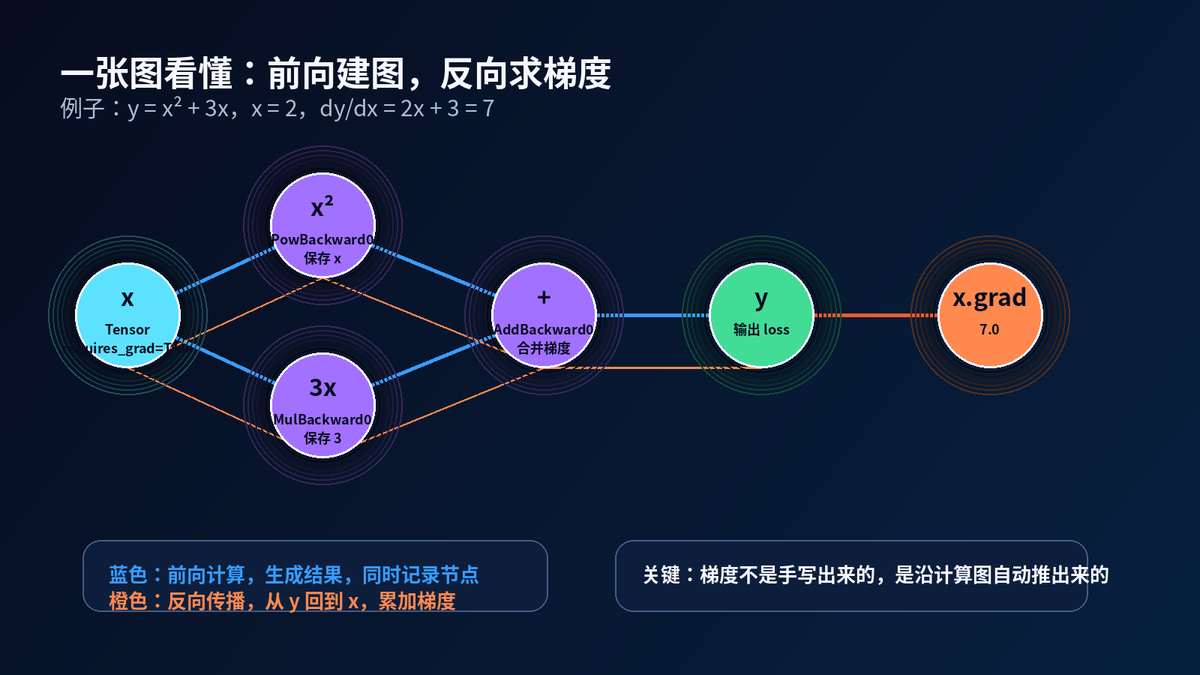
这里 x=2,y=x²+3x。
dy/dx = 2x+3。
所以当 x=2 时,梯度就是 7。
你没有手写求导公式。PyTorch 自动做了。

只要参与运算的输入里有一个 Tensor 需要梯度,输出通常也会被纳入计算图。
但如果你在 no_grad 或 inference_mode 里执行,PyTorch 就不会记录这段历史。
4. grad_fn:反向图的入口
打开 requires_grad 后,计算结果上通常会出现一个属性:grad_fn。
x = torch.tensor(2.0, requires_grad=True)
y = x * x + 3 * x
print(y.grad_fn)
<AddBackward0 ...>
这个 grad_fn 很关键。
它不是装饰品。
它指向创建这个 Tensor 的反向函数。
比如加法产生 AddBackward0,乘法产生 MulBackward0,矩阵乘法产生 MmBackward0。
前向计算像是在搭积木,grad_fn 就是每块积木背后的拆解说明。
反向传播时,Autograd Engine 就沿着这些 grad_fn 和 next_functions 往回走。
5. 叶子节点和非叶子节点
很多人第一次学 Autograd,会被 .grad 搞晕。
为什么有的 Tensor 有 grad,有的 Tensor 没有?
答案在叶子节点。
用户直接创建、需要优化的 Tensor,通常是叶子节点。模型参数就是典型叶子节点。
由运算产生的中间结果,是非叶子节点。它们参与反向传播,但默认不会把梯度留在 .grad 字段里。
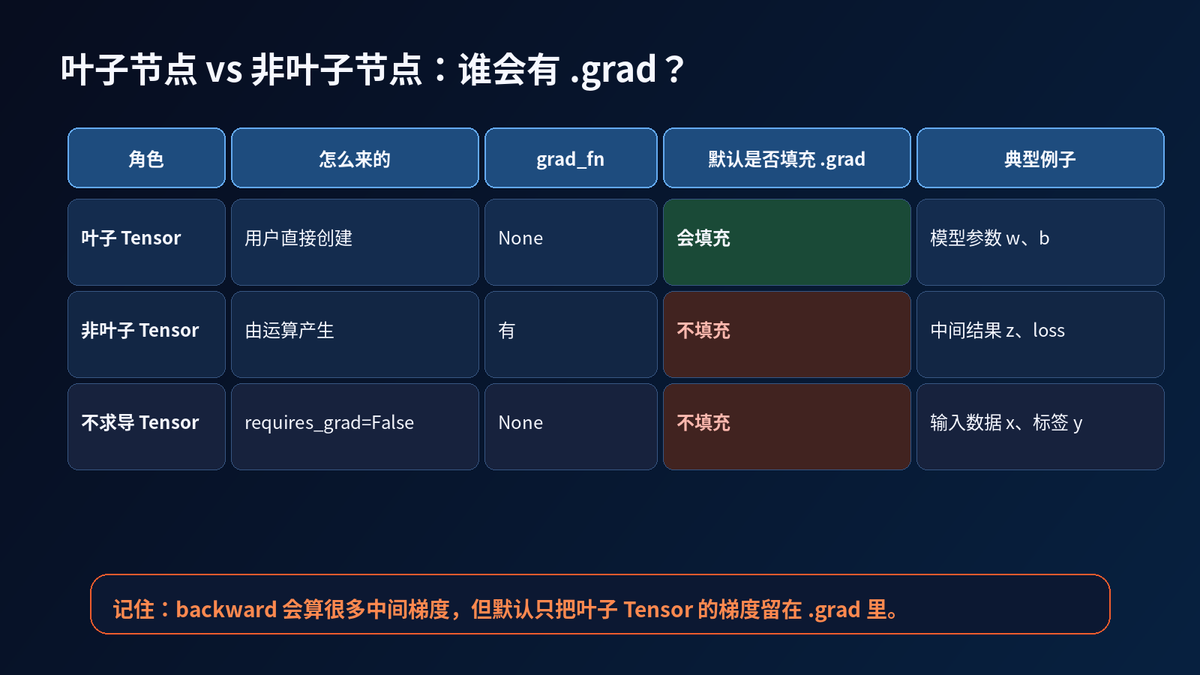
一句话记住:
Autograd 会计算中间梯度,但默认只把叶子 Tensor 的梯度保存下来。
如果你确实想查看中间节点的梯度,可以调用 retain_grad()。
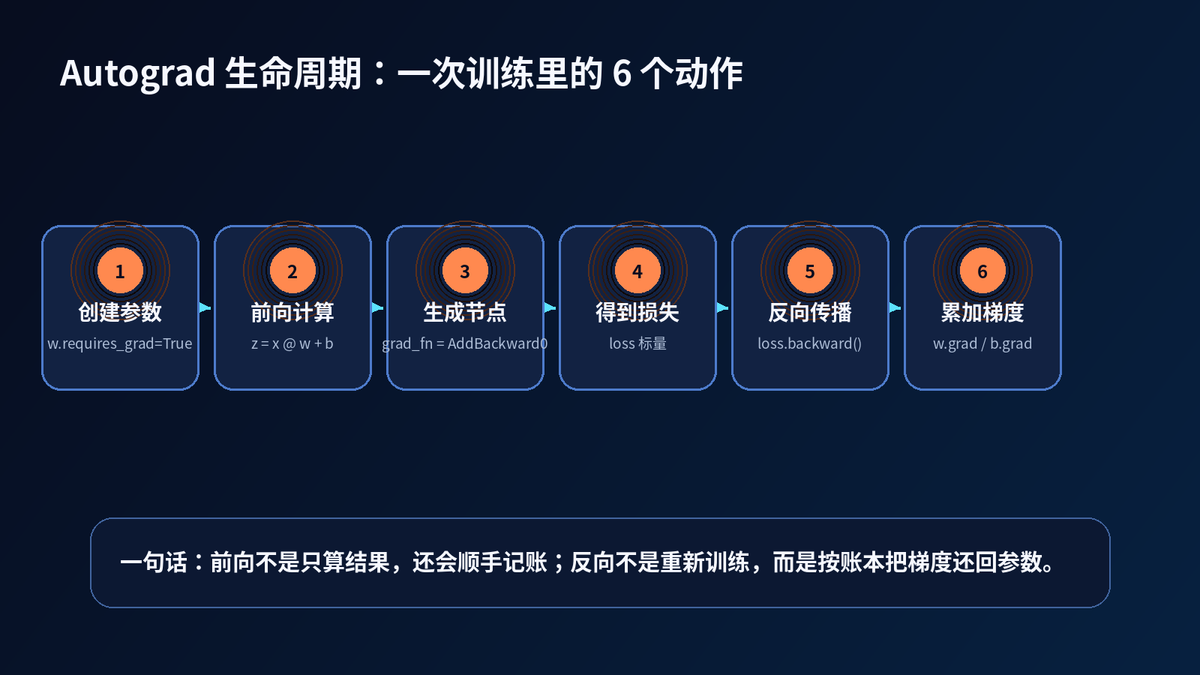
6. backward() 到底做了什么
loss.backward() 不是"重新跑一遍模型"。
它是从 loss 这个根节点开始,沿计算图反向遍历。
每经过一个节点,就调用这个节点对应的 backward 逻辑。
最后,把梯度累加到叶子 Tensor 的 .grad 里。
典型训练片段
optimizer.zero_grad() # 清空上一轮梯度
pred = model(x) # 前向:构建计算图
loss = loss_fn(pred, y) # loss:图的根节点
loss.backward() # 反向:计算梯度
optimizer.step() # 更新:优化器修改参数
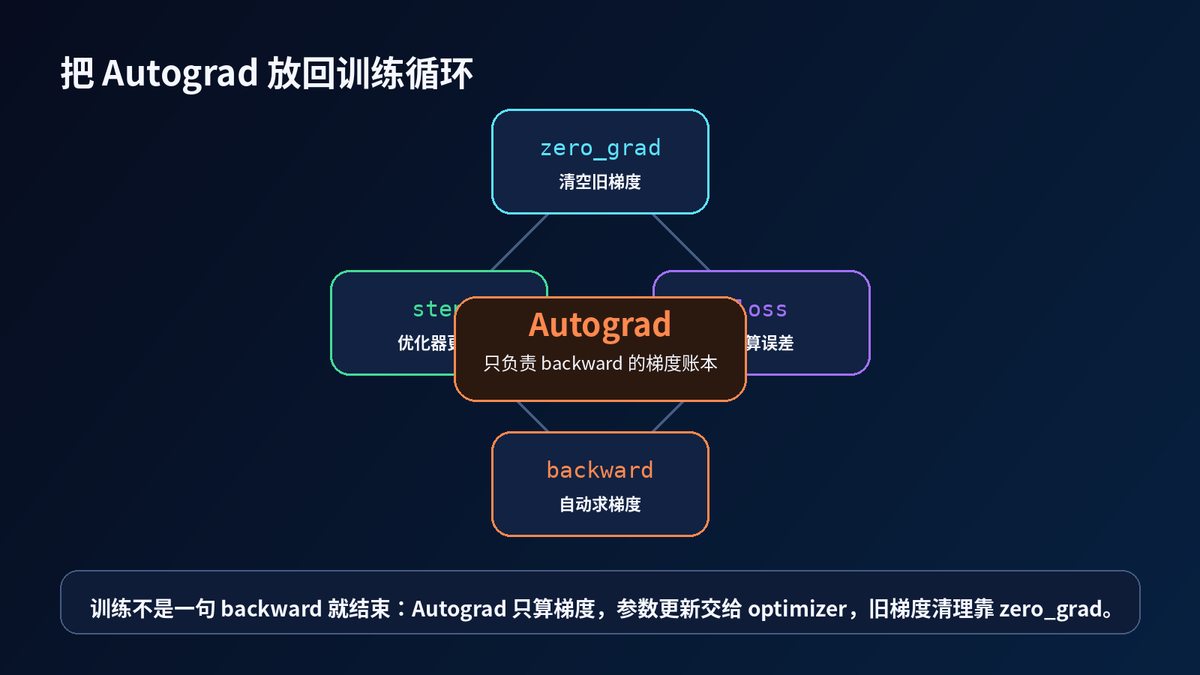
注意:backward 只负责算梯度。
参数真正被修改,是 optimizer.step() 做的。
旧梯度清空,是 optimizer.zero_grad() 做的。
7. 从 Python 进入 C++ Engine
从源码角度看,Autograd 分两层。
上层是 Python API,负责让你调用起来方便。
底层是 C++ Autograd Engine,负责真正执行计算图。
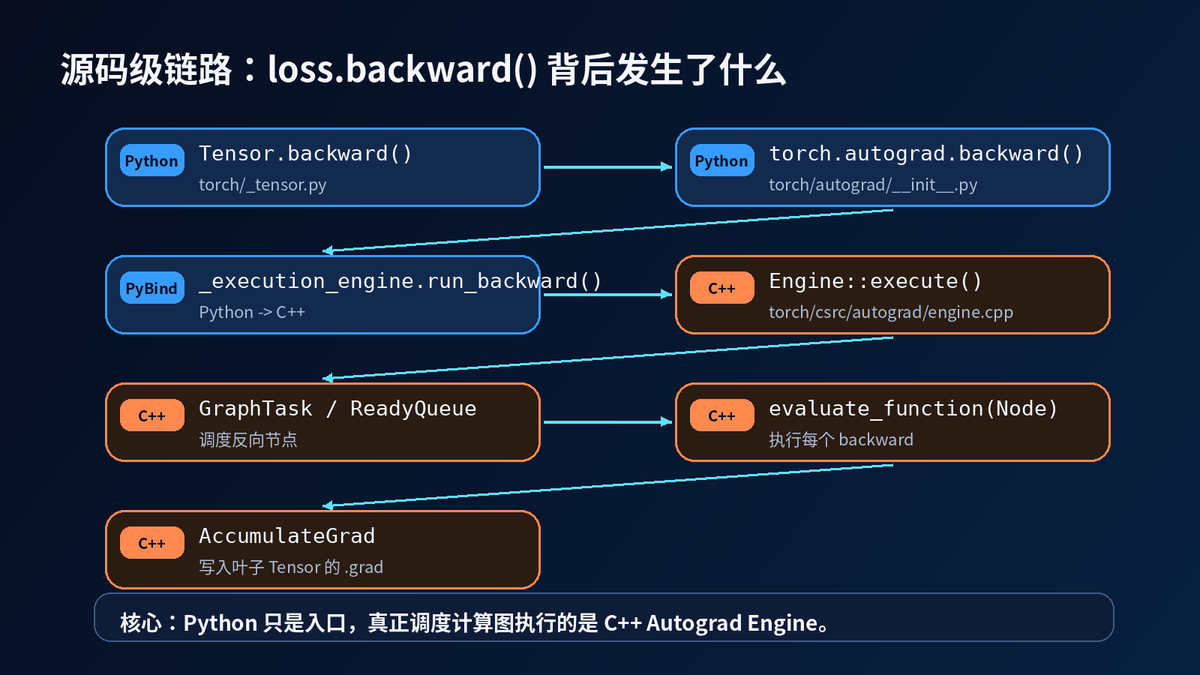
一条典型链路是:
Tensor.backward() 调用 torch.autograd.backward()。
torch.autograd.backward() 整理输出 Tensor、外部梯度、retain_graph 等参数。
然后进入 _execution_engine.run_backward()。
这里开始从 Python 切到 C++。
C++ Engine 会创建 GraphTask,分析依赖关系,把可以执行的 Node 放进 ReadyQueue,再由 worker thread 调用 evaluate_function 执行每个反向节点。
最后,AccumulateGrad 节点把梯度写到叶子 Tensor 的 .grad 里。
所以,Autograd 不是简单递归。
它是一个带任务调度、依赖分析、线程队列和梯度累加的执行引擎。
8. Saved Tensors:为什么反向要占显存
反向传播不可能凭空算梯度。
有些算子的 backward 需要用到前向阶段的中间结果。
比如 y=x²,反向公式是 dy/dx=2x。
如果反向时不知道前向的 x 是多少,就算不出梯度。
所以某些操作会在前向阶段保存必要的 Tensor。

这也是训练显存比推理显存高的重要原因。
推理只要前向结果。
训练还要保存反向所需的中间值。
后面讲混合精度、梯度检查点、FSDP 时,这个概念会反复出现。
9. detach、no_grad、retain_graph:三个容易混的点
学 Autograd,最容易踩坑的不是 backward,而是"什么时候不该记录图"。

detach() 是对某个 Tensor 切断历史。
no_grad() 是对一段代码关闭建图。
retain_graph=True 是 backward 后不释放图。
zero_grad() 是清空上一轮已经累积的梯度。
这几个东西看起来都和梯度有关,但作用完全不同。
训练代码里最常见的 bug,就是在错误的位置用了 no_grad 或 detach,导致模型不更新。
10. 为什么梯度会累加
PyTorch 的梯度默认是累加的。
也就是说,连续调用两次 backward,如果中间不清空梯度,.grad 会把两次结果加起来。
x = torch.tensor(2.0, requires_grad=True)
y = x * x
y.backward()
print(x.grad) # tensor(4.)
y = x * x
y.backward()
print(x.grad) # tensor(8.),不是 4,因为累加了
这不是 bug。
这是设计。
因为梯度累加可以支持梯度累计训练。
但普通训练中,每一轮更新前通常要清空旧梯度。
optimizer.zero_grad()
loss.backward()
optimizer.step()
11. Autograd 和动态图的关系
PyTorch 的计算图是动态生成的。
你每执行一次 forward,都会生成一张新的反向图。
这就是为什么你可以在 forward 里写 if、for、递归,甚至根据输入内容改变模型路径。
优点是灵活。
缺点是每次都要重新建图,性能上会有一定开销。
后面讲 torch.compile 时,你会看到 PyTorch 2.x 是怎么把动态图捕获成图,再交给编译器优化的。
12. 从源码角度看 Autograd 的核心对象
源码里,Autograd 的核心不是"Tensor 本身",而是 Tensor 背后的计算历史。
可以抓住这几个对象:
Tensor:保存数据,也带着 autograd metadata。
Node:反向图里的执行节点,每个 Node 知道自己的 backward 逻辑。
Edge:连接 Node 和 Node,表示梯度往哪里流。
GraphTask:一次 backward 的任务上下文。
ReadyQueue:已经满足依赖、可以执行的反向节点队列。
AccumulateGrad:负责把梯度累加到叶子 Tensor 的 .grad。
理解这些,loss.backward() 就不再神秘。
13. 总结
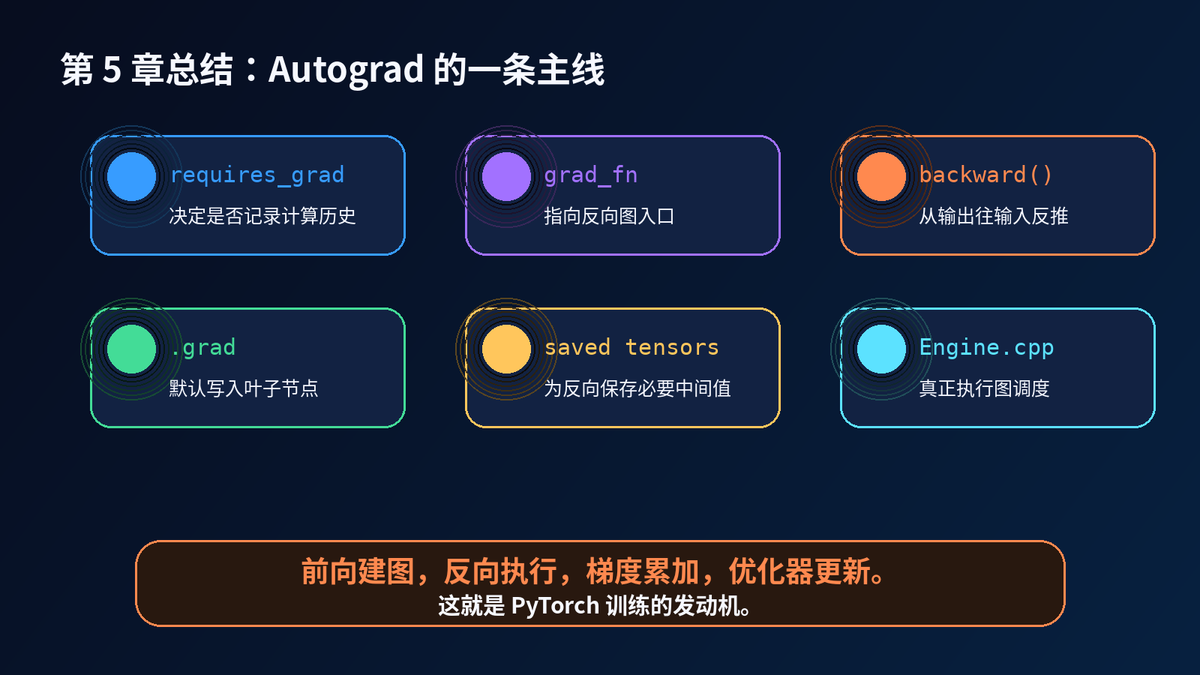
Autograd 是 PyTorch 训练的发动机。
requires_grad 决定是否记录计算。
grad_fn 指向反向图入口。
backward 从 loss 出发反向遍历。
叶子 Tensor 的 .grad 会被填充。
中间节点的梯度默认不保留。
某些算子会保存前向中间值,用于反向计算。
Python API 负责入口,C++ Autograd Engine 负责真正执行。
一句话:
前向建图,反向执行,梯度累加,优化器更新。