目录
前言
在 K8s 集群监控领域,prometheus-kube-stack 长期是企业标准,但随着集群规模扩大,它的问题也越来越明显:Prometheus 单机存储瓶颈、高基数指标下内存暴涨、长期存储需要额外对接 Thanos/Cortex/VictoriaMetrics 才能解决,整体架构越来越重。相较之下,victoria-metrics-k8s-stack 直接将高可用、长期存储、低资源占用这些能力内置到监控栈本身,开箱即用,不需要再额外堆组件,是目前中小企业 K8s 监控场景下更轻量、更务实的选择。
victoria-metrics-k8s-stack 是一套以 VictoriaMetrics 为核心的监控栈,完全兼容 Prometheus 生态,同时在多个关键维度上有明显优势:
性能与资源占用:VictoriaMetrics 在相同数据量下内存占用通常只有 Prometheus 的 1/3 到 1/7,CPU 消耗更低,在资源紧张的测试环境或边缘节点上优势尤为明显。以同等规模的 K8s 集群为例,横向对比大致如下:
| 组件 | CPU 占用 | 内存占用 |
|---|---|---|
| Prometheus(prometheus-kube-stack) | 300m~800m | 2G~8G |
| VictoriaMetrics(victoria-metrics-k8s-stack) | 100m~300m | 256Mi~1G |
实际资源消耗因集群规模和指标数量而异,但 VictoriaMetrics 在资源效率上的优势在大规模场景下会更加显著。
存储效率:VictoriaMetrics 采用自研压缩算法,磁盘占用比 Prometheus TSDB 低 5 到 10 倍,同样的磁盘空间可以存更长时间的数据,长期存储成本大幅降低。
原生集群模式:vmcluster 将写入(vminsert)、查询(vmselect)、存储(vmstorage)三个组件独立拆分,可以单独扩缩容,天然支持副本和数据去重,不需要像 Prometheus 那样额外引入 Thanos 才能做高可用。
兼容性好:完全兼容 PromQL,Grafana 数据源直接替换,原有的 Dashboard 和告警规则无需修改即可复用。
相同的自动发现机制:victoria-metrics-k8s-stack 同样基于 Operator 模式,通过 VMServiceScrape、VMPodScrape 等 CRD 实现服务自动发现,使用体验和 prometheus-operator 的 ServiceMonitor、PodMonitor 几乎一致,原有的采集配置可以平滑迁移,不需要重新学习一套新的配置体系。
Operator 驱动:通过 victoria-metrics-operator 管理所有组件的 CRD,配置方式和 prometheus-operator 类似,迁移成本低。
环境
| Ip | 主机名 | cpu | 内存 |
|---|---|---|---|
| 192.168.10.12 | master01 | 4c | 6G |
| 192.168.10.13 | node1 | 4c | 6G |
| 192.168.10.14 | node2 | 4c | 6G |
| 192.168.10.100 | nfs | 2c | 2g |
| 组件 | 版本 |
|---|---|
| Ubuntu | Ubuntu 26.04 server |
| containerd | v2 2.2.2 |
| Kubernetes | v1.36.1 |
链接: k8s部署过程
已经安装helm+storageclass+helm


操作
添加victoria的helm仓库
powershell
helm repo add vm https://victoriametrics.github.io/helm-charts/
helm repo update
tee values.yaml << 'EOF'
vmsingle: #关闭单节点,启动群集
enabled: false
vmcluster:
enabled: true
spec:
retentionPeriod: "14d"
replicationFactor: 2
vmstorage:
replicaCount: 3
storage:
volumeClaimTemplate:
spec:
storageClassName: nfs-client
resources:
requests:
storage: 10Gi
resources:
requests: { cpu: 100m, memory: 384Mi } #根据自己环境来调整
limits: { memory: 768Mi }
extraArgs:
dedup.minScrapeInterval: 30s
vmagent:
enabled: true
spec:
externalLabels:
cluster: test #群集标签
resources:
requests: { cpu: 100m, memory: 256Mi }
limits: { memory: 512Mi }
vmalert:
enabled: true
alertmanager:
enabled: true
defaultRules:
create: true
prometheus-node-exporter:
enabled: true
kube-state-metrics:
enabled: true
kubeControllerManager: #k8s组件默认监听127.0.0.1,暂时先不监控
enabled: false
kubeScheduler:
enabled: false
kubeEtcd:
enabled: false
kubeProxy:
enabled: false
grafana:
enabled: true
adminPassword: admin123
persistence:
enabled: true
storageClassName: nfs-client #写storageclass
size: 2Gi
EOF
helm install vmks vm/victoria-metrics-k8s-stack \
-n monitoring --create-namespace \
-f values.yaml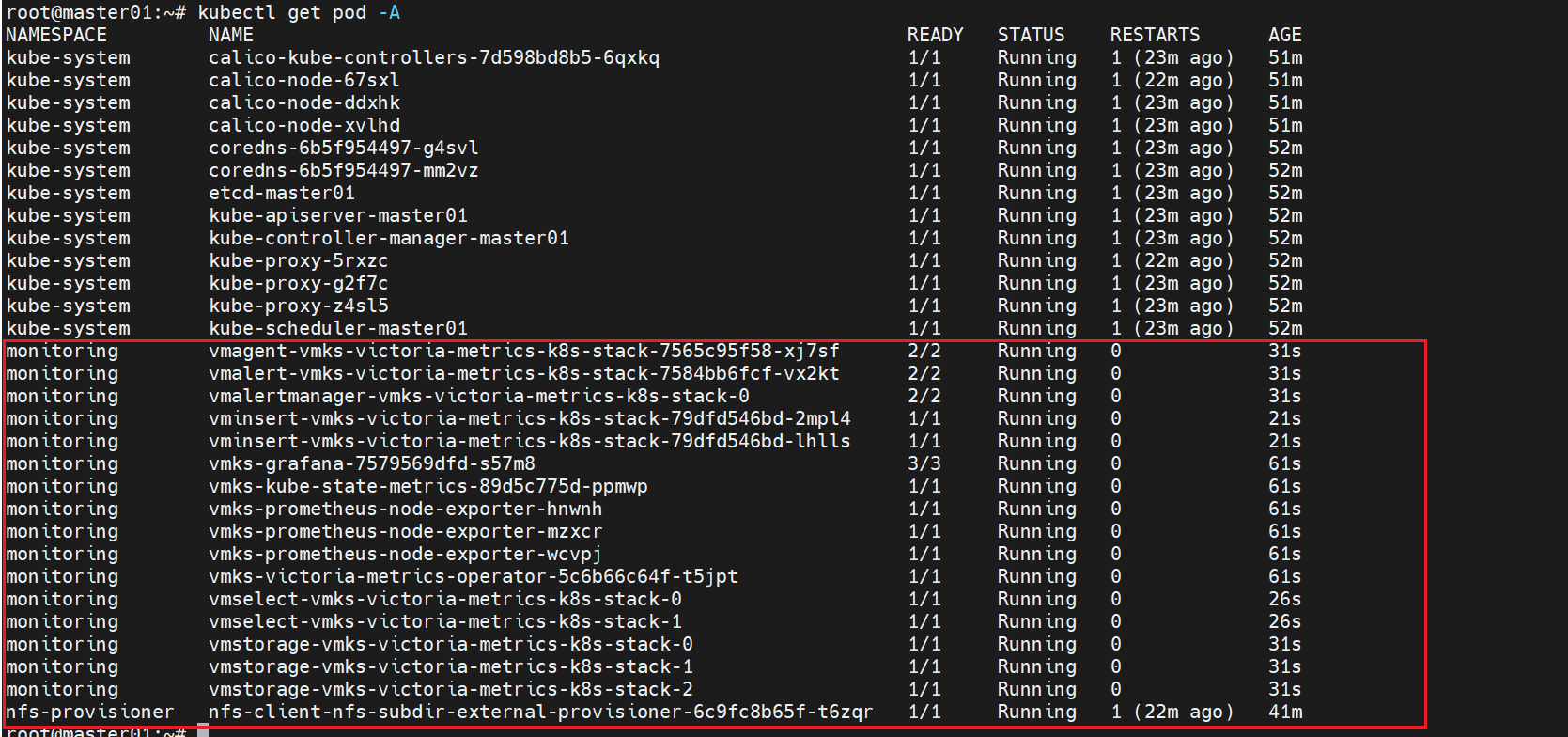
grafana展示
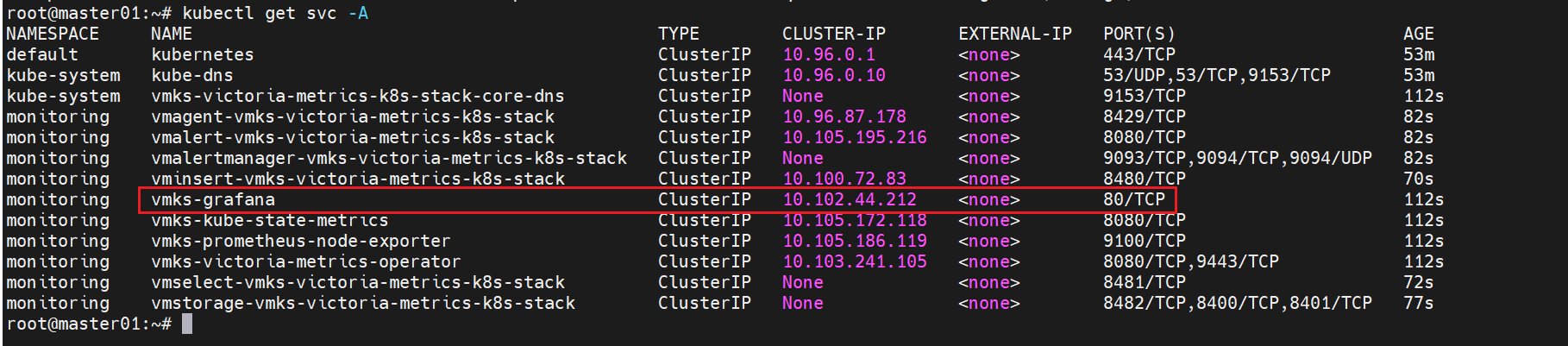
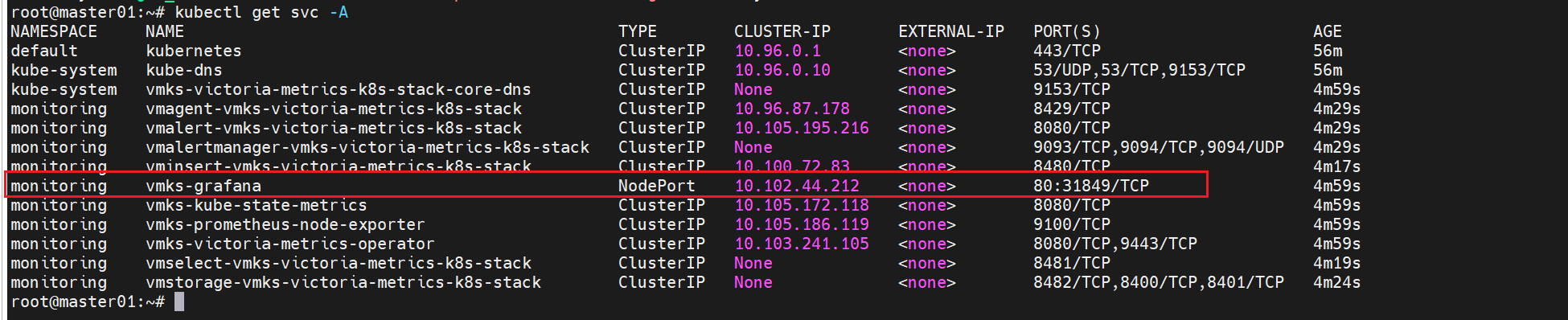
把vmks-grafana这个从cluster改成nodeport模式,方便本地访问
powershell
kubectl edit svc -n monitoring vmks-grafana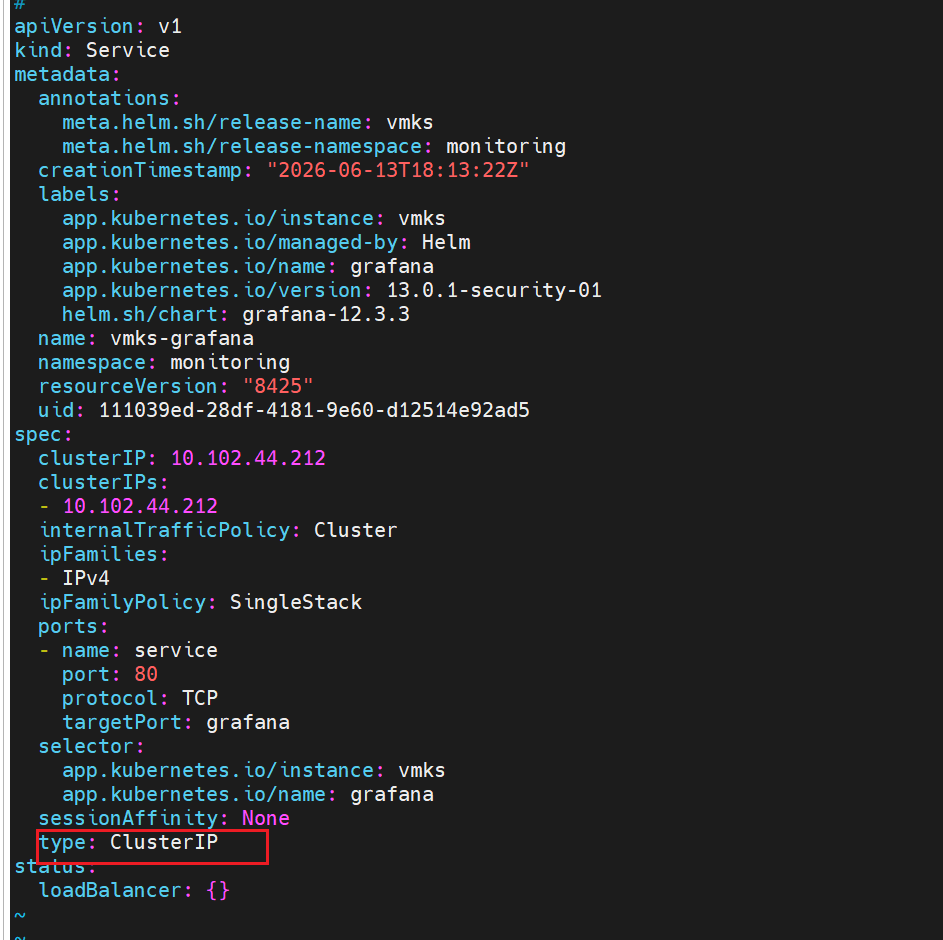
这里改成NodePort,注意大小写
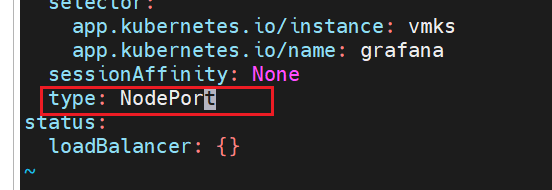
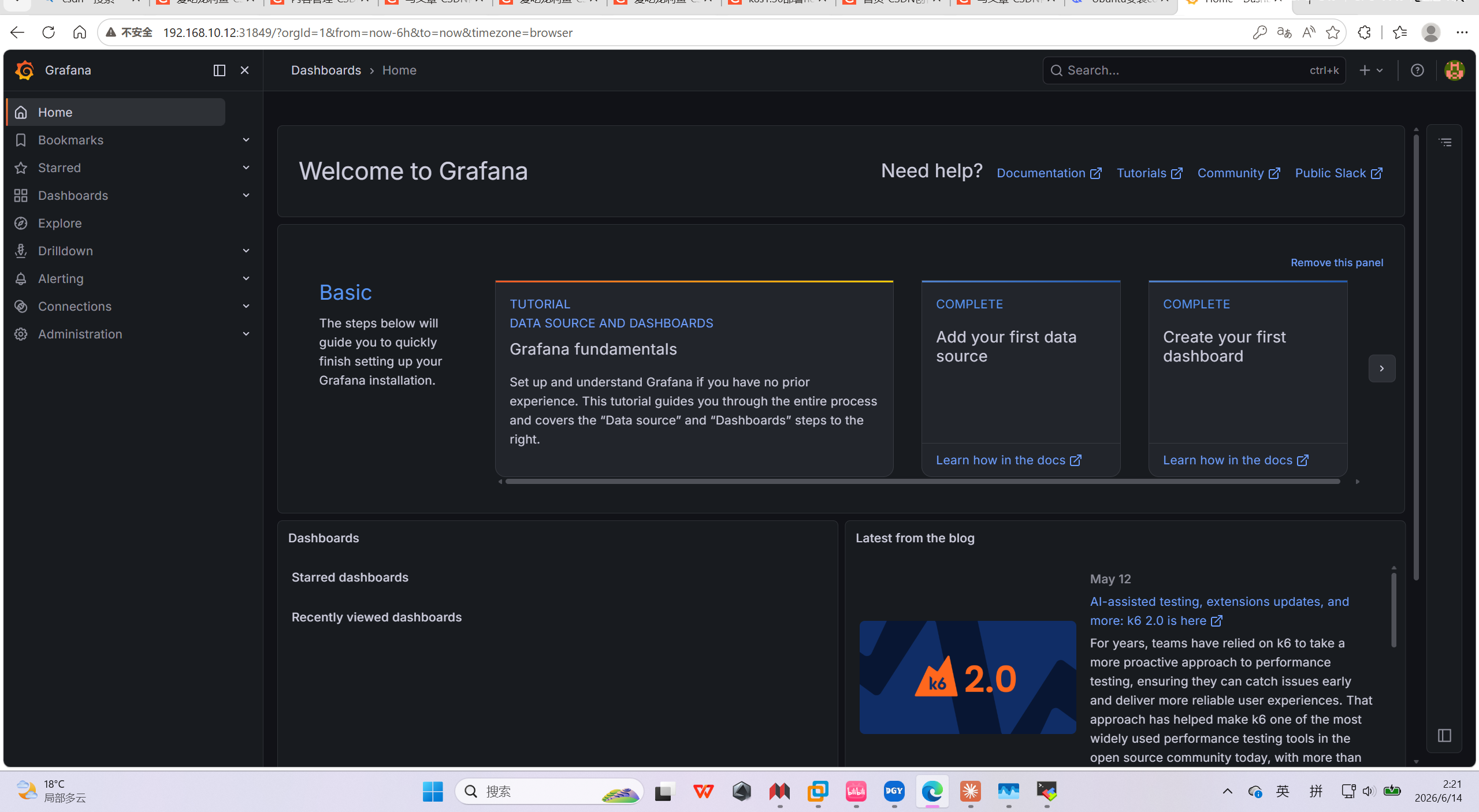
浏览器访问本地ip+端口
我这里是192.168.10.12:31849
账密是上面设置的admin/admin123
生产环境不要写弱密码,公司里博主已经被安全部门吊过很多次了,测试环境就无所谓了
这是进来的页面
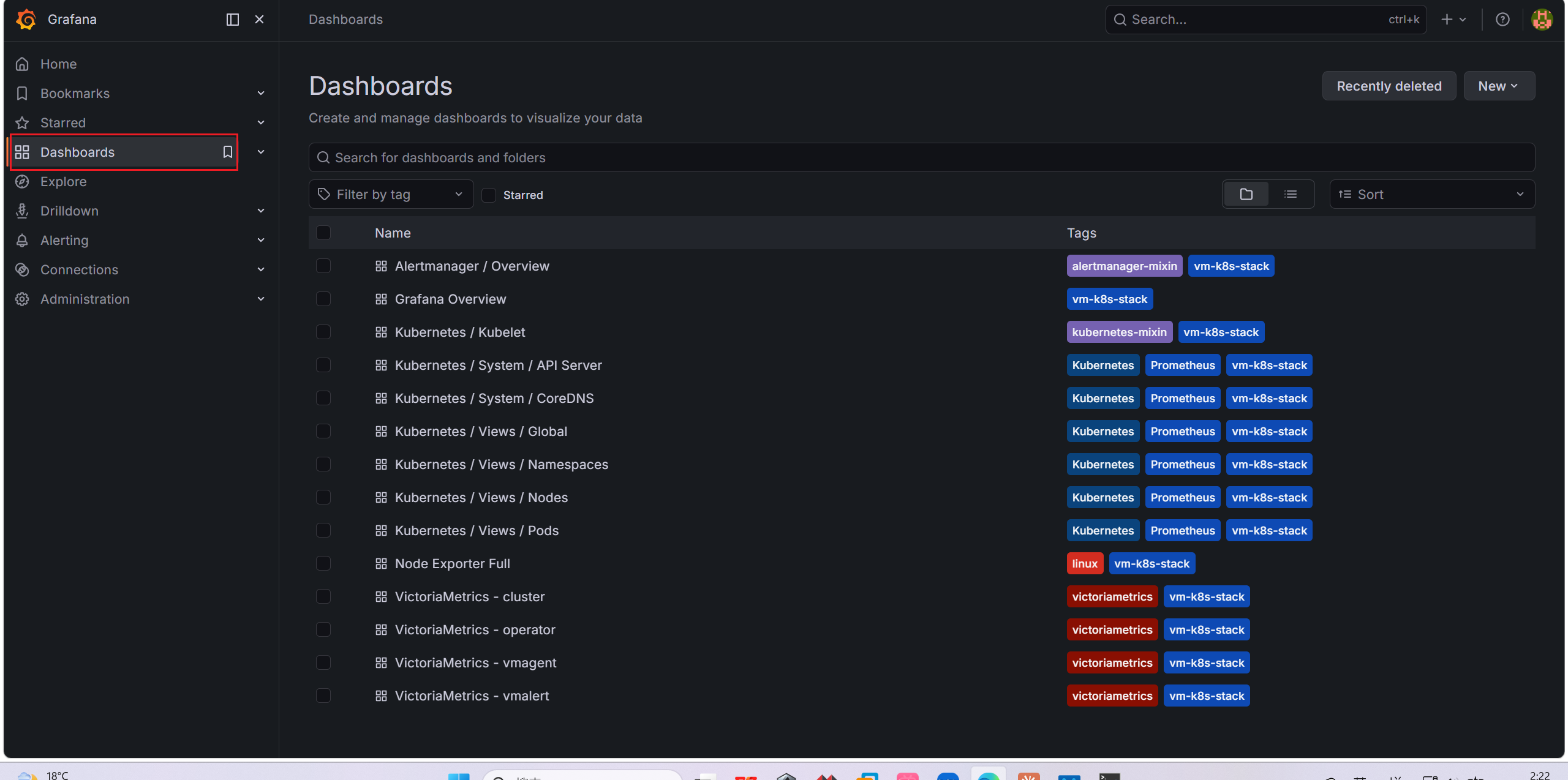
Dashboards里有默认的grafana模块
我们可以点一个进去看下
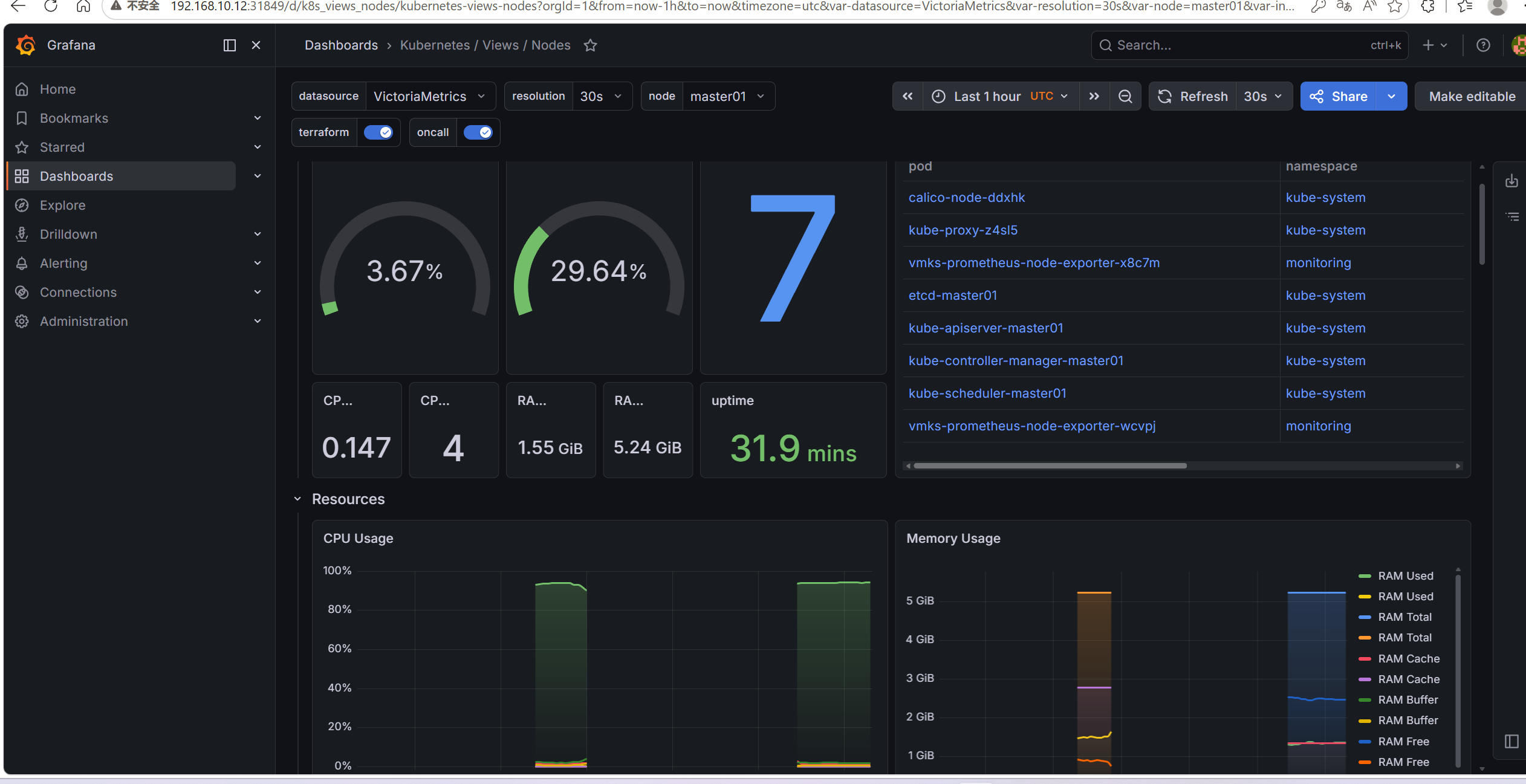
vmselect-条件搜索
因为vmselect被operator控制的,所以没办法把clusterip模式改成nodeport,但是我们可以新建一个svc来指向vmselect的pod
powershell
cat << 'EOF' | kubectl apply -f -
apiVersion: v1
kind: Service
metadata:
name: vmselect-nodeport
namespace: monitoring
spec:
type: NodePort
selector:
app.kubernetes.io/component: monitoring
app.kubernetes.io/instance: vmks-victoria-metrics-k8s-stack
app.kubernetes.io/name: vmselect
managed-by: vm-operator
ports:
- name: http
port: 8481
targetPort: 8481
nodePort: 31481
protocol: TCP
EOF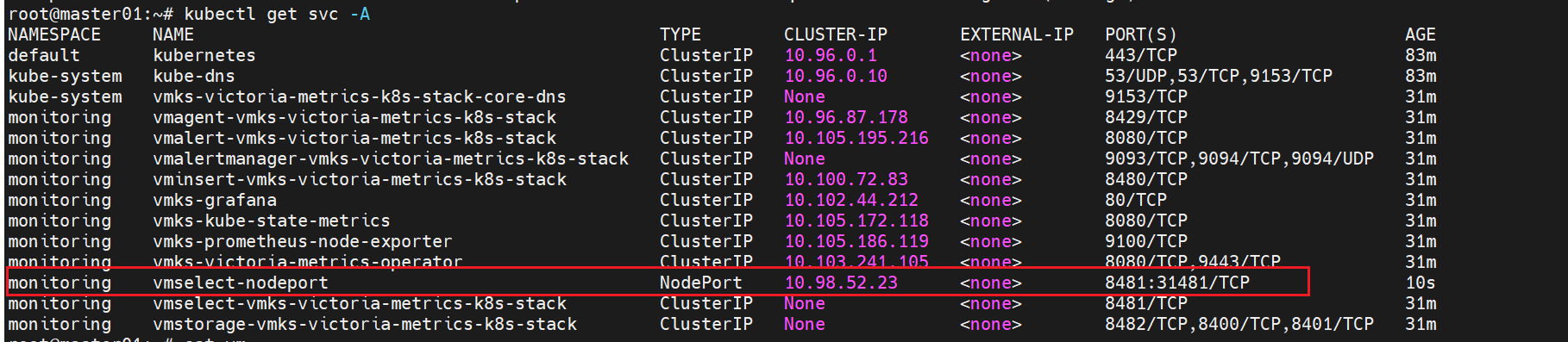
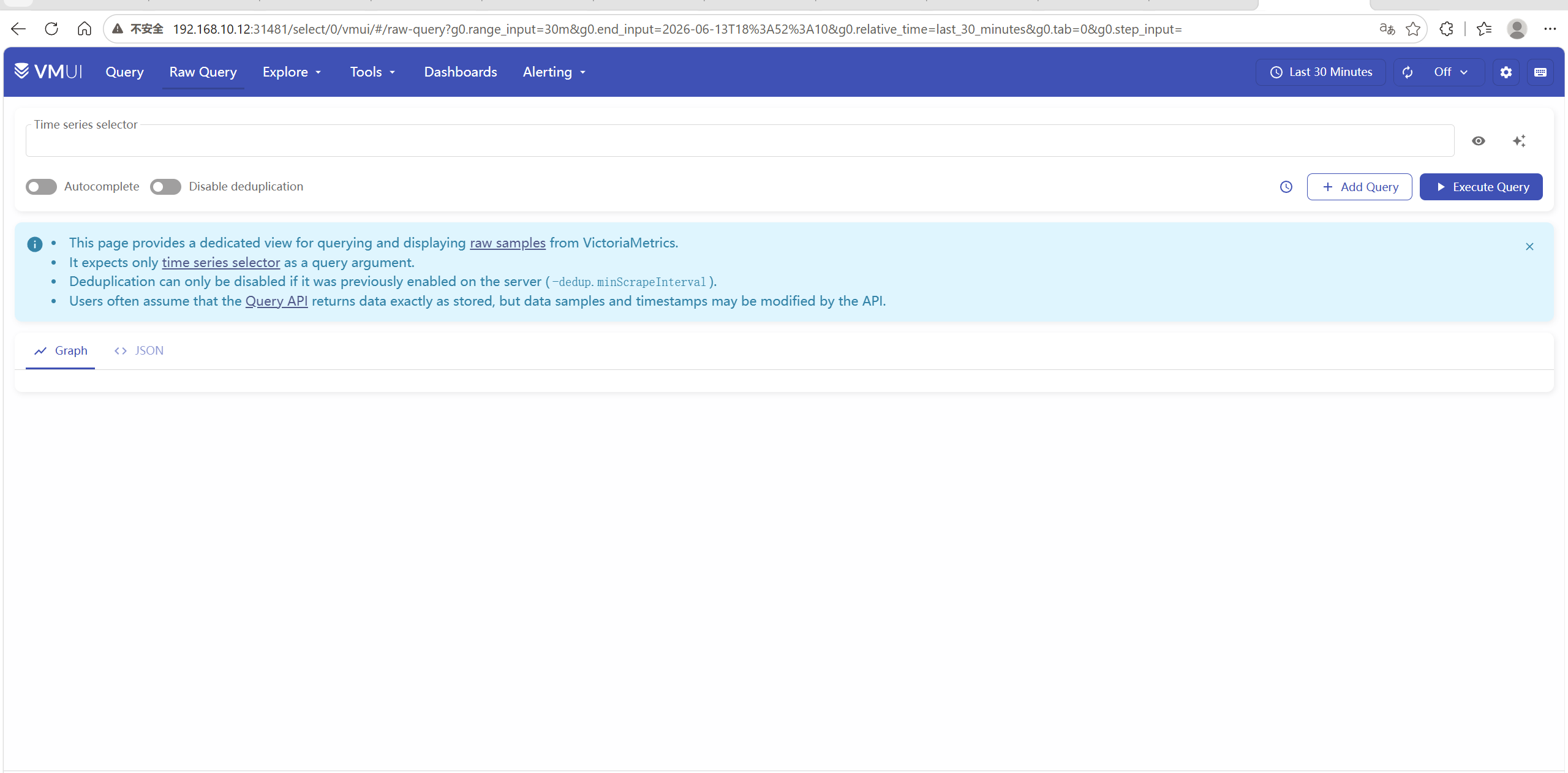
web页面
http://<节点IP>:31481/select/0/vmui/
我这里是
http://192.168.10.12:31481/select/0/vmui
进来就是类似于prometheus的web页面,比promethues更轻量化
用浏览器的翻译功能翻译下
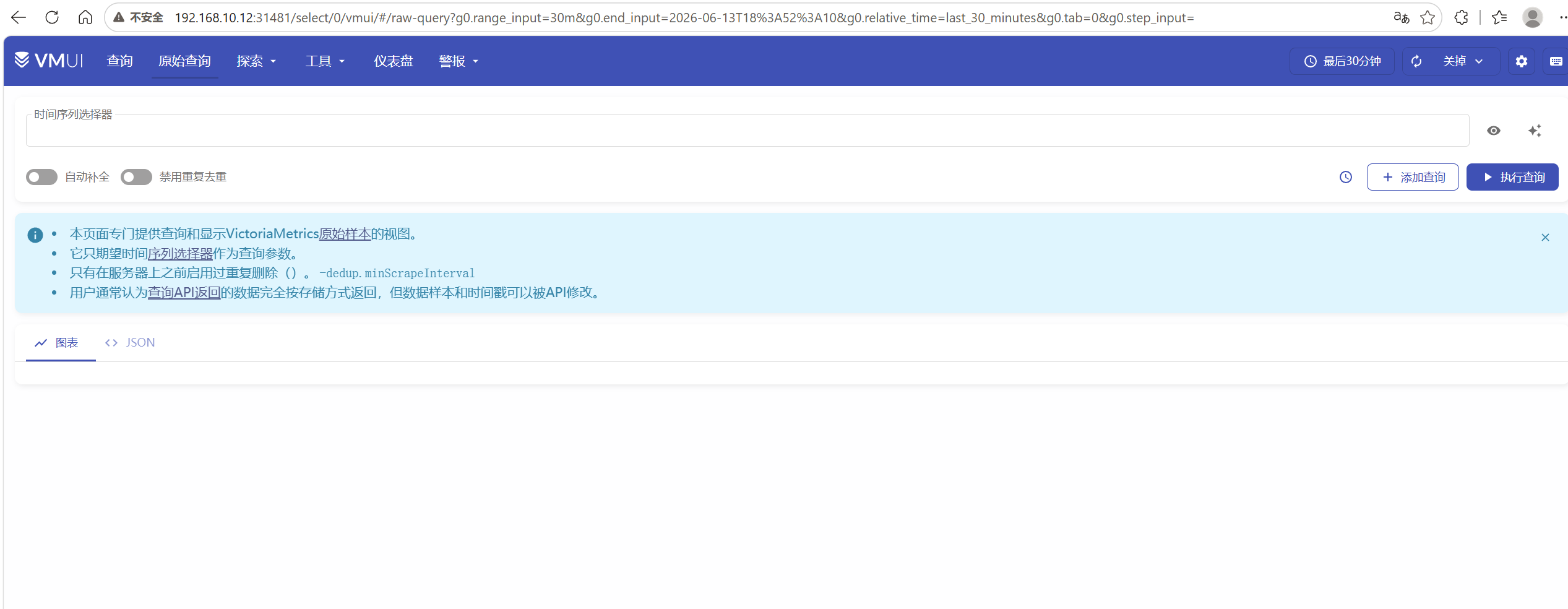
我们可以来试下他的查询功能
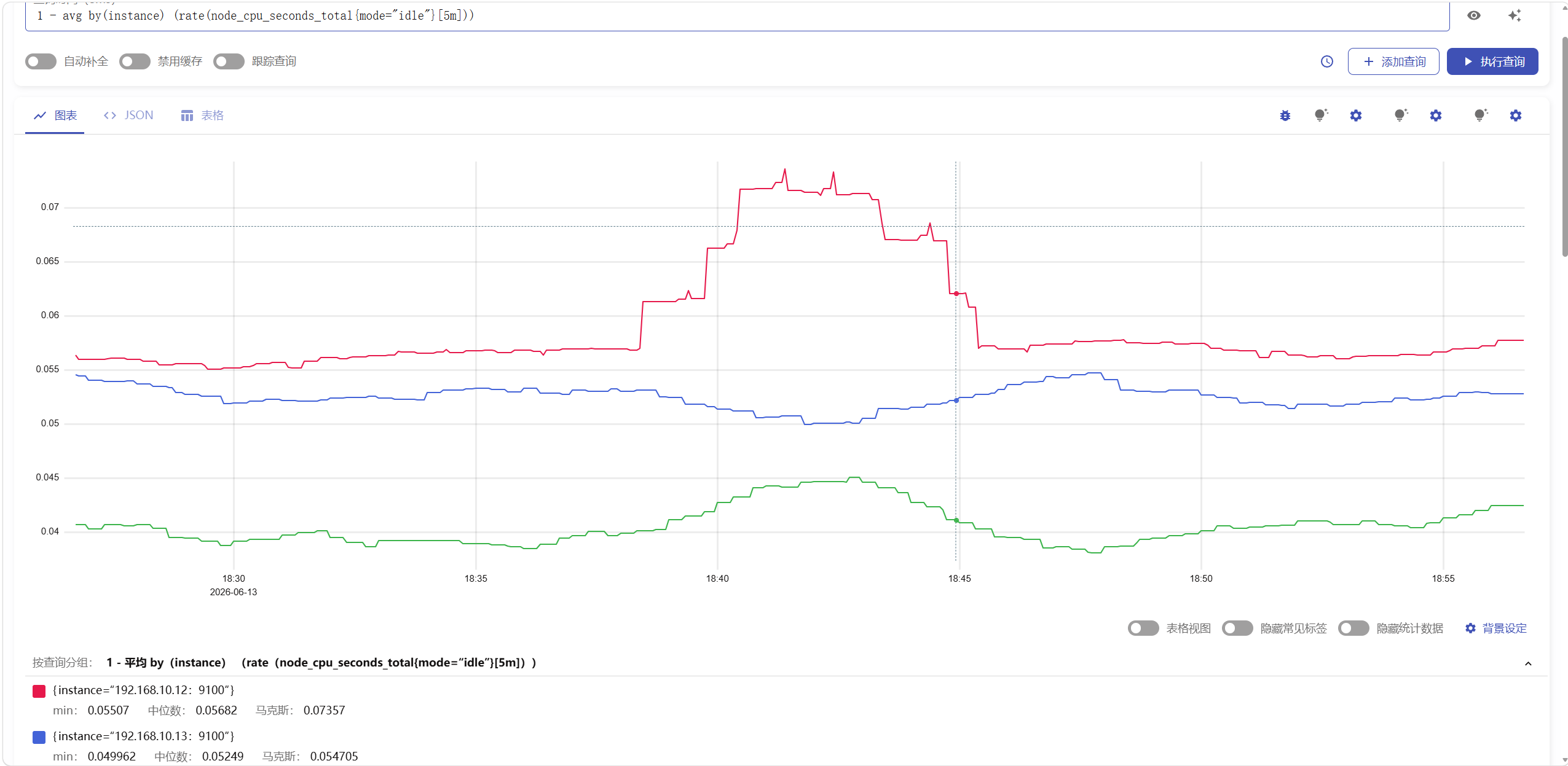
举例1
查询 CPU 使用率
powershell
1 - avg by(instance) (rate(node_cpu_seconds_total{mode="idle"}[5m]))可以将查询结果输出为图标/json/表格
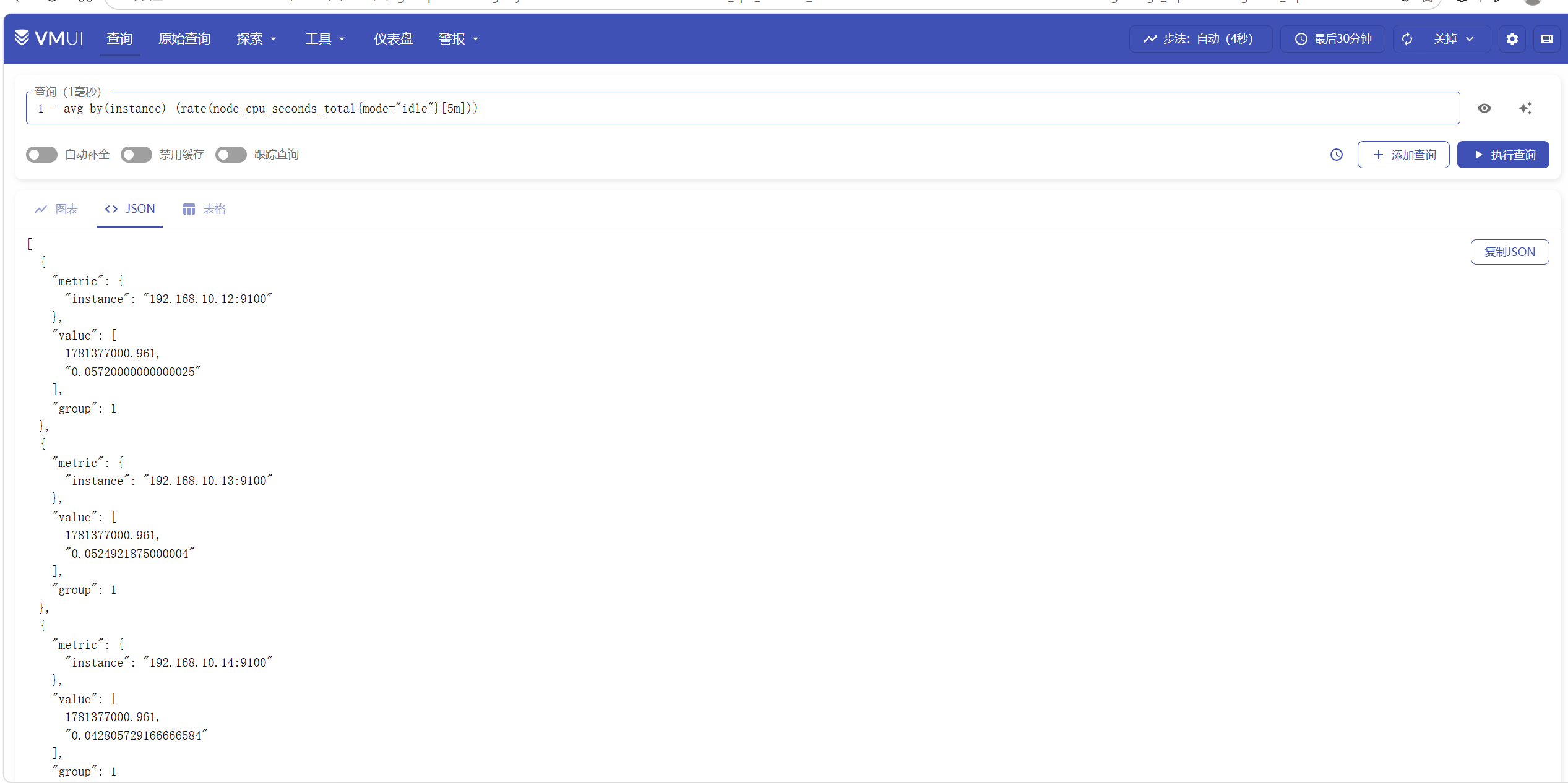
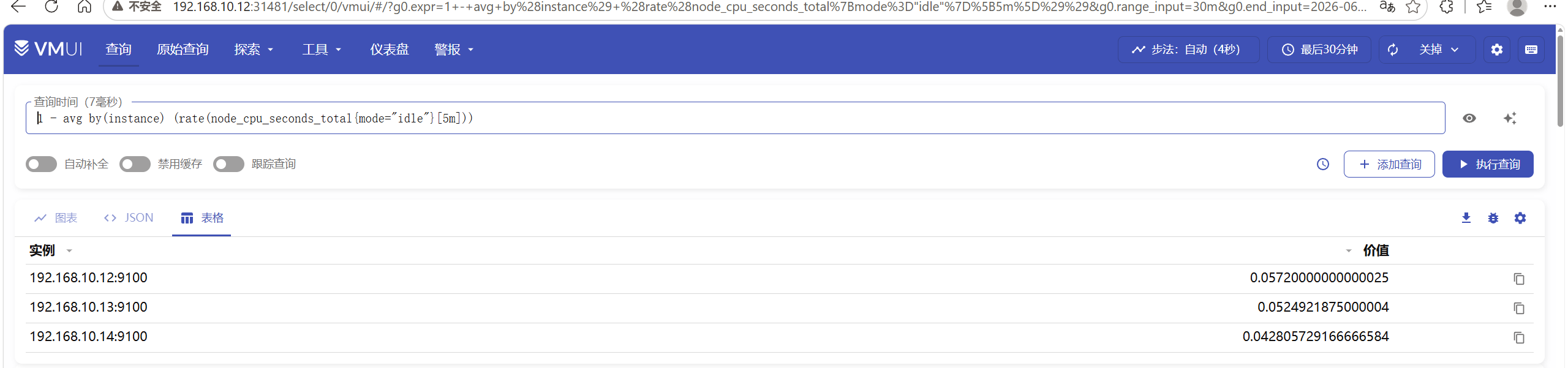
还有简单的仪表盘
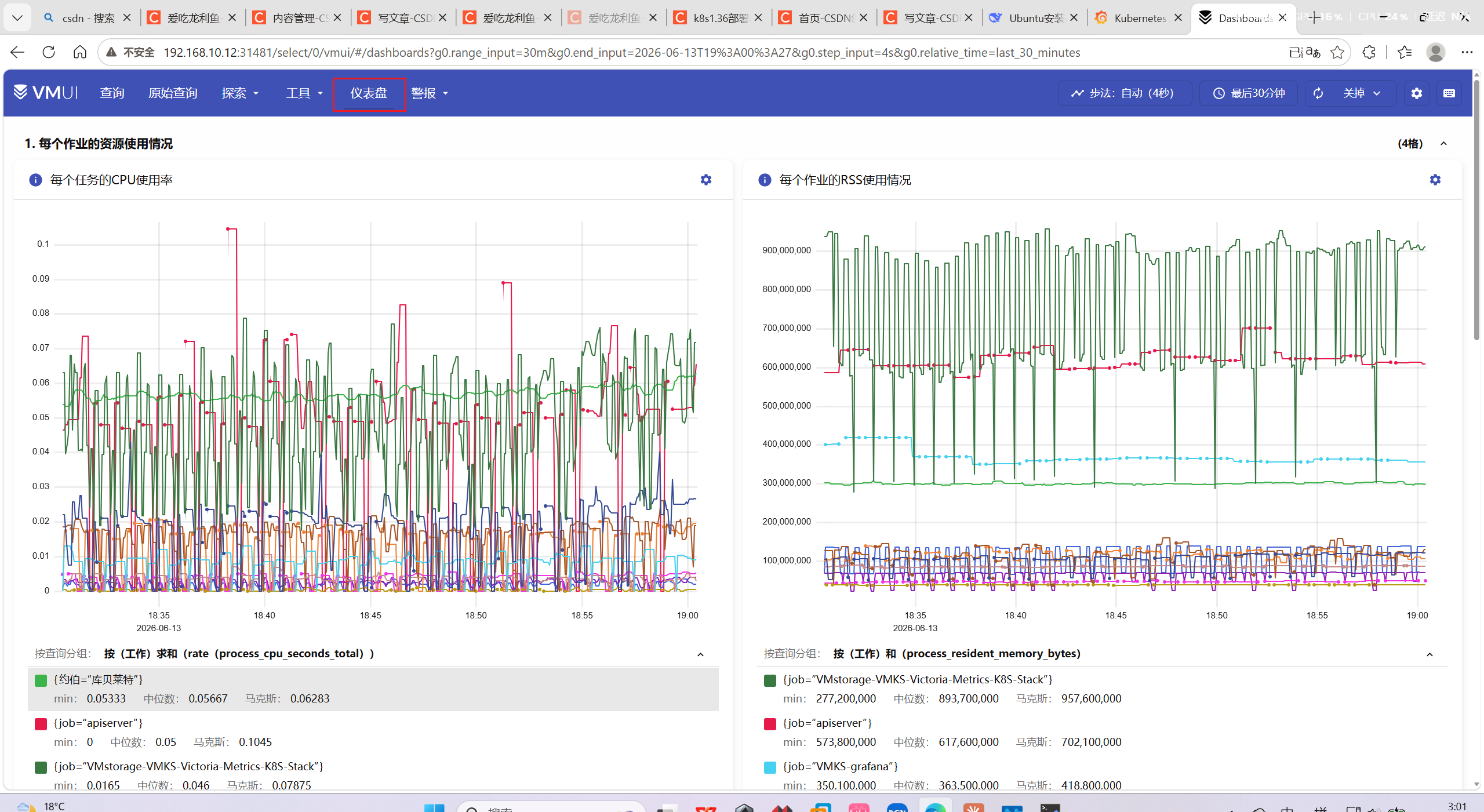
vmagent-采集目标状态
同上,创建新的svc
powershell
cat << 'EOF' | kubectl apply -f -
apiVersion: v1
kind: Service
metadata:
name: vmagent-nodeport
namespace: monitoring
spec:
type: NodePort
selector:
app.kubernetes.io/component: monitoring
app.kubernetes.io/instance: vmks-victoria-metrics-k8s-stack
app.kubernetes.io/name: vmagent
managed-by: vm-operator
ports:
- name: http
port: 8429
targetPort: 8429
nodePort: 31429
protocol: TCP
EOF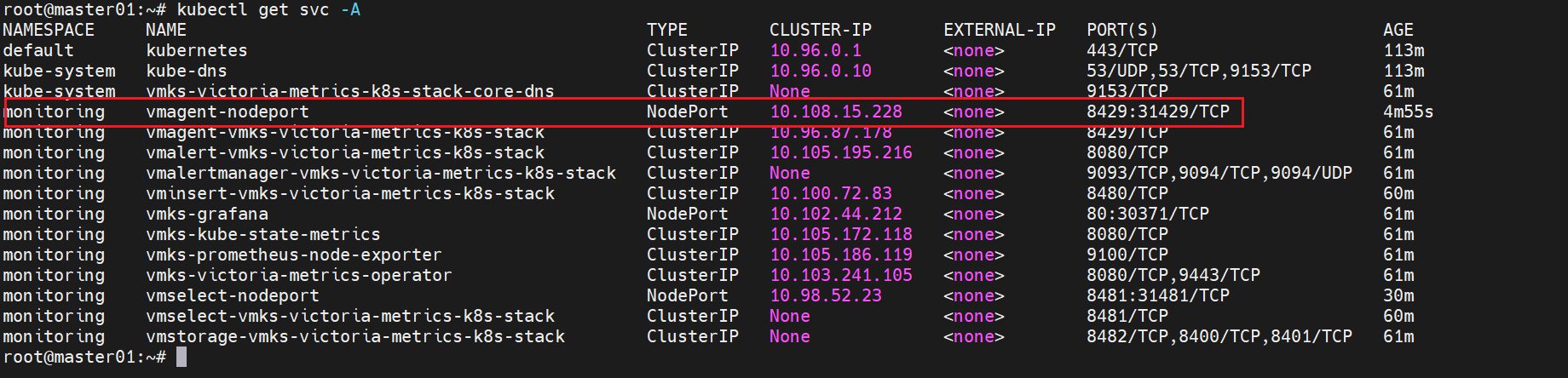
访问方式
http://<节点IP>:31429/targets # 查看采集 target 状态
能看到所有采集目标的状态
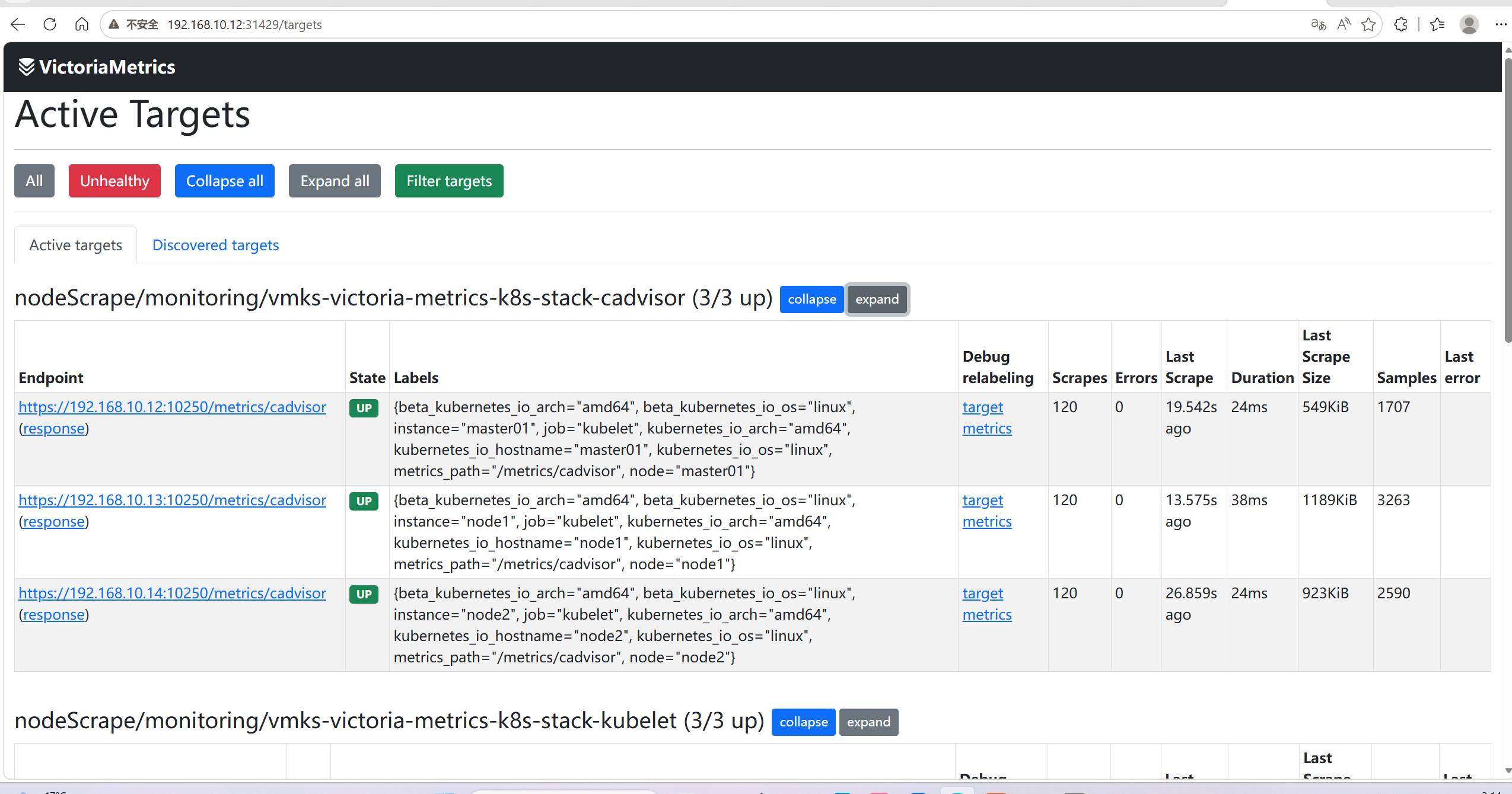
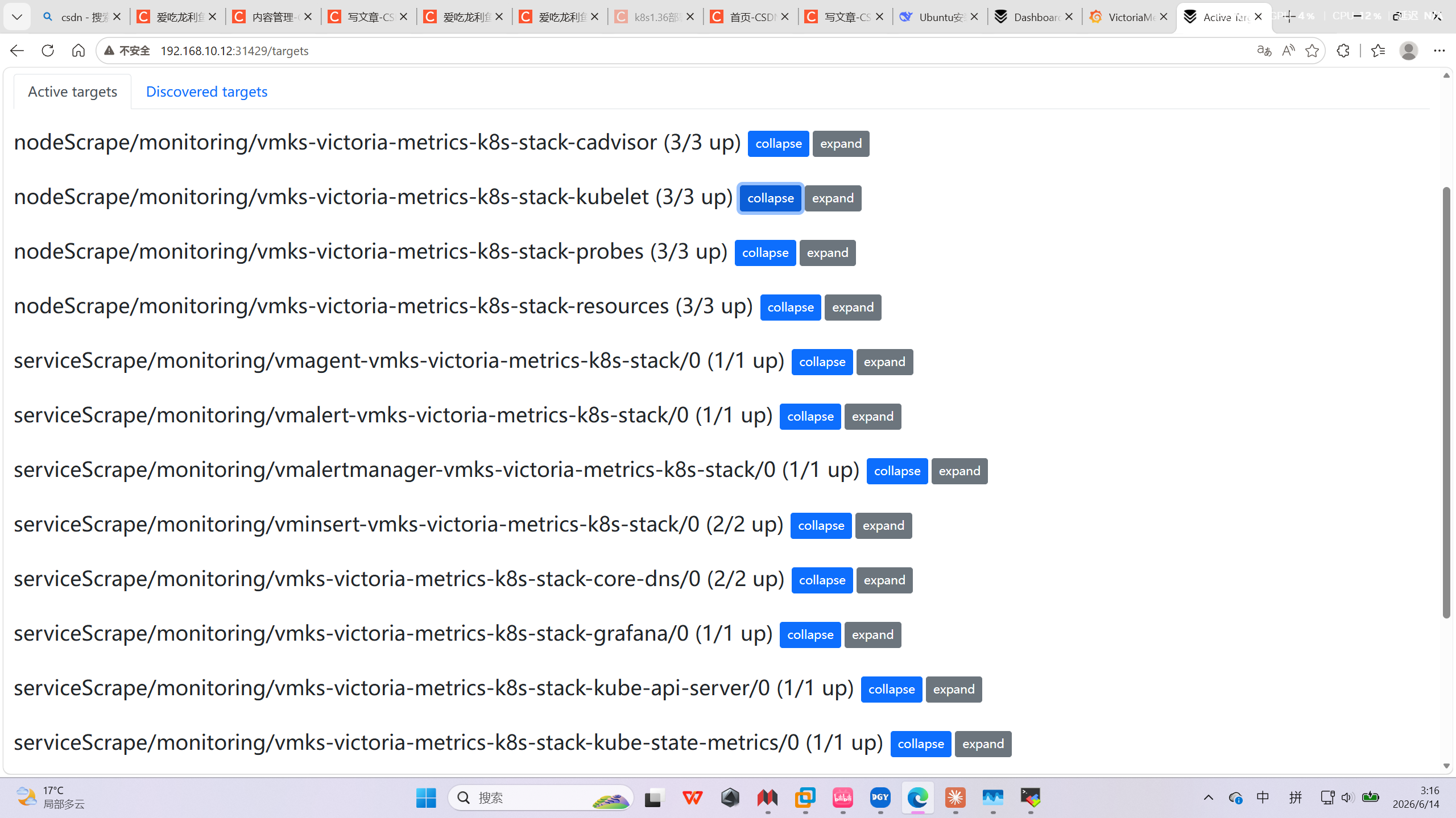
http://<节点IP>:31429/metrics # 自身指标
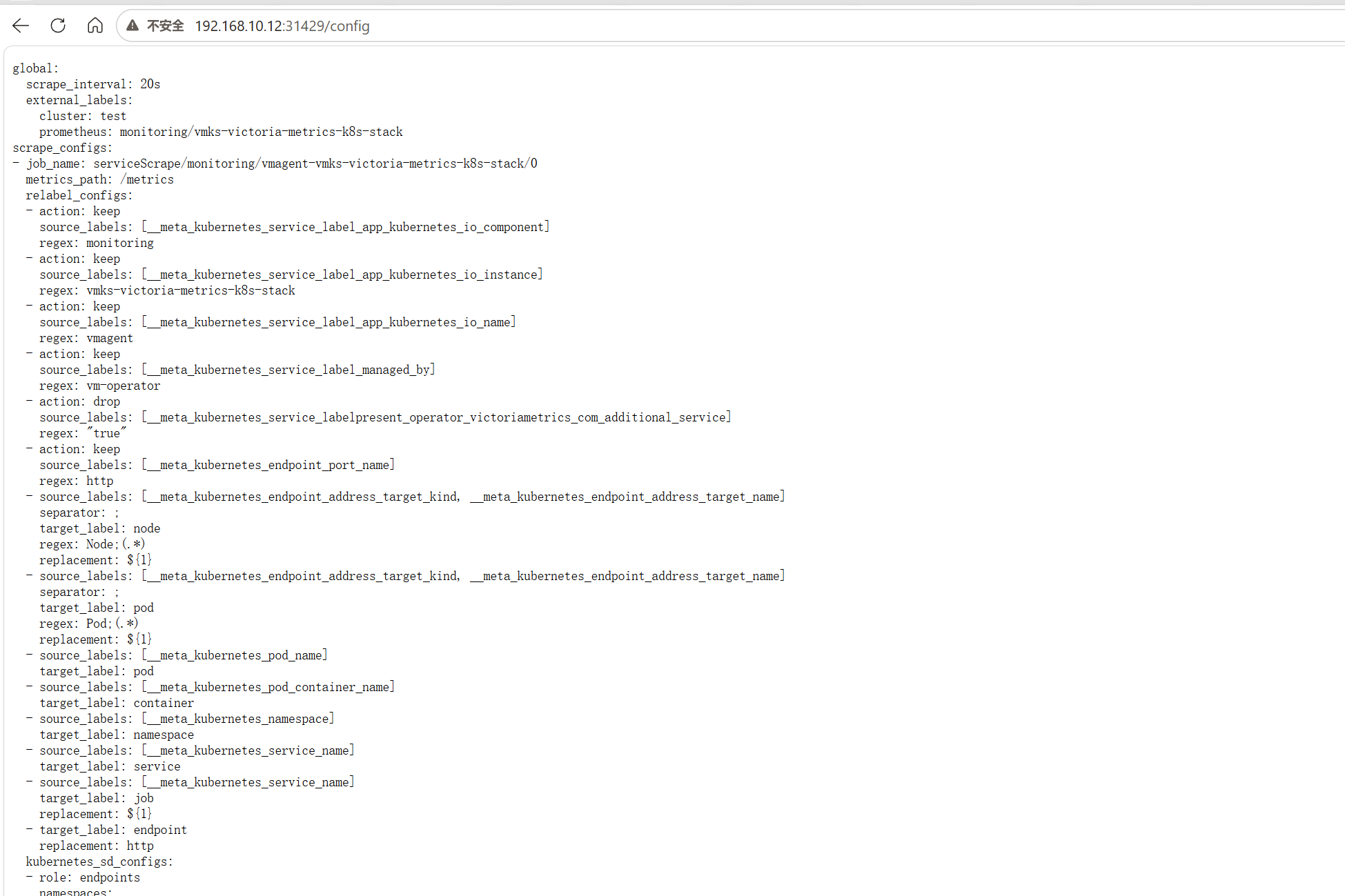
http://<节点IP>:31429/config # 当前采集配置
vmalert-查看告警规则
powershell
cat << 'EOF' | kubectl apply -f -
apiVersion: v1
kind: Service
metadata:
name: vmalert-nodeport
namespace: monitoring
spec:
type: NodePort
selector:
app.kubernetes.io/name: vmalert
app.kubernetes.io/instance: vmks-victoria-metrics-k8s-stack
managed-by: vm-operator
ports:
- name: http
port: 8080
targetPort: 8080
nodePort: 31080
protocol: TCP
EOF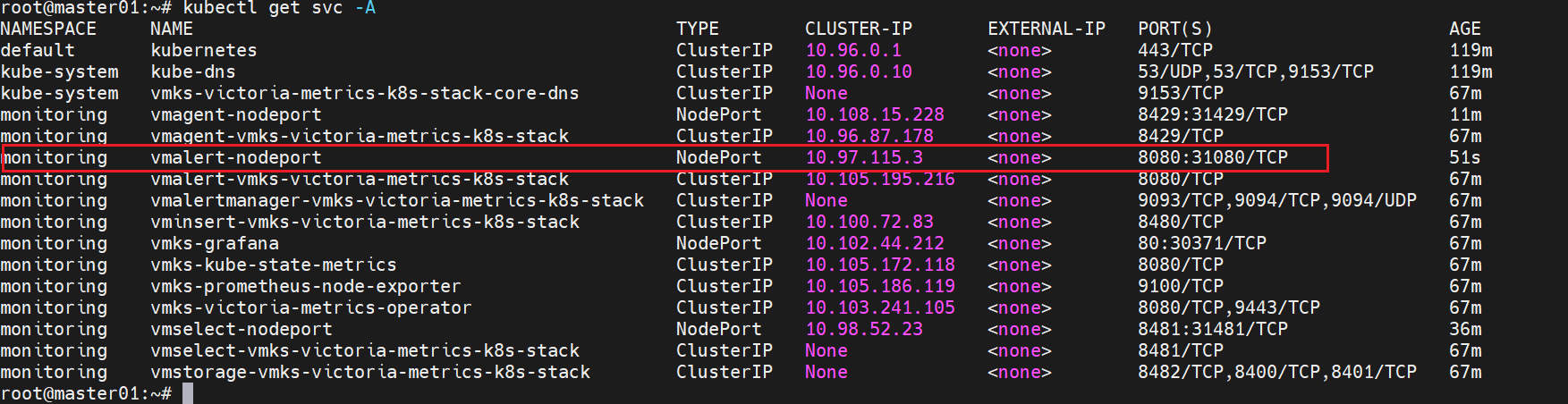
http:// <节点ip> :31080/vmalert/
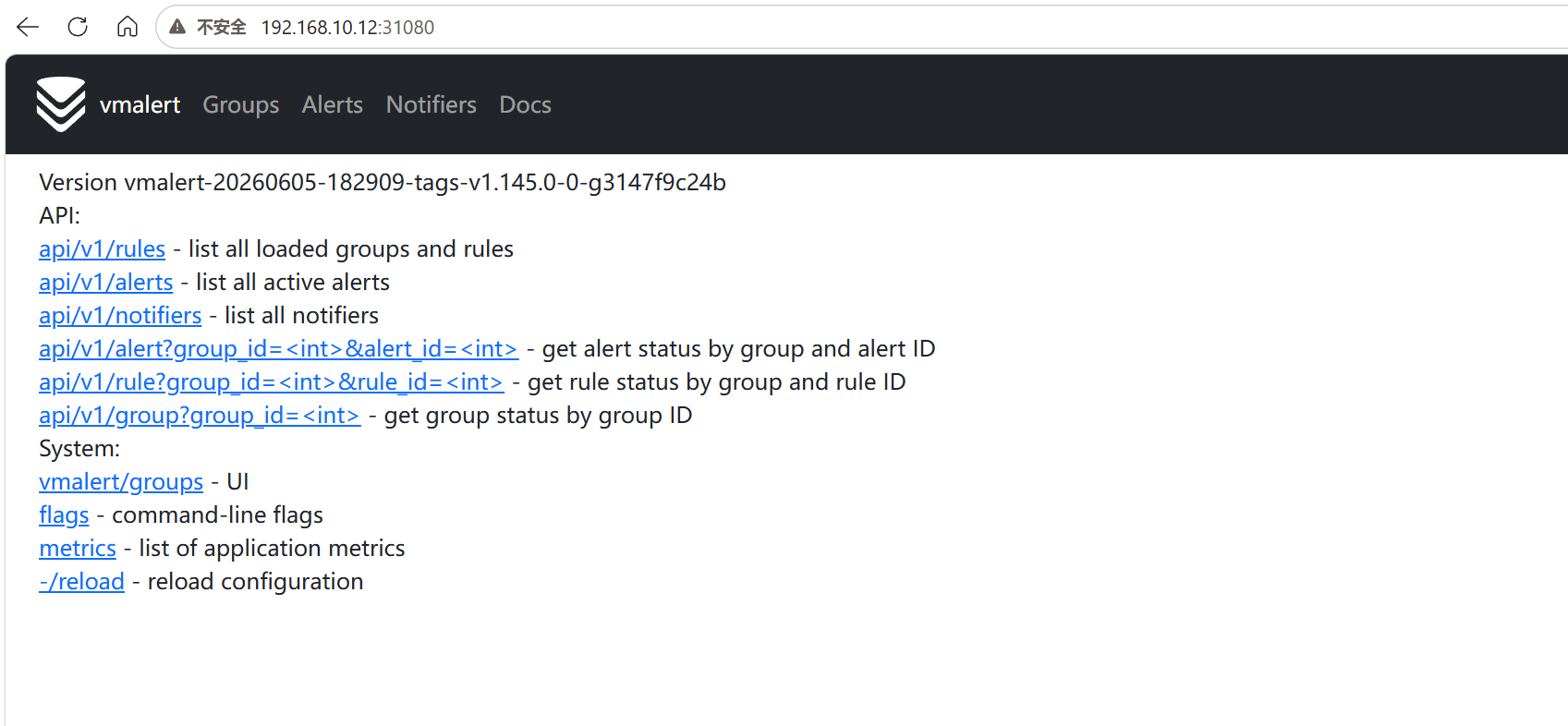
vmalertmanager-管理告警静默
powershell
cat << 'EOF' | kubectl apply -f -
apiVersion: v1
kind: Service
metadata:
name: vmalertmanager-nodeport
namespace: monitoring
spec:
type: NodePort
selector:
app.kubernetes.io/name: vmalertmanager
app.kubernetes.io/instance: vmks-victoria-metrics-k8s-stack
managed-by: vm-operator
ports:
- name: http
port: 9093
targetPort: 9093
nodePort: 31093
protocol: TCP
EOF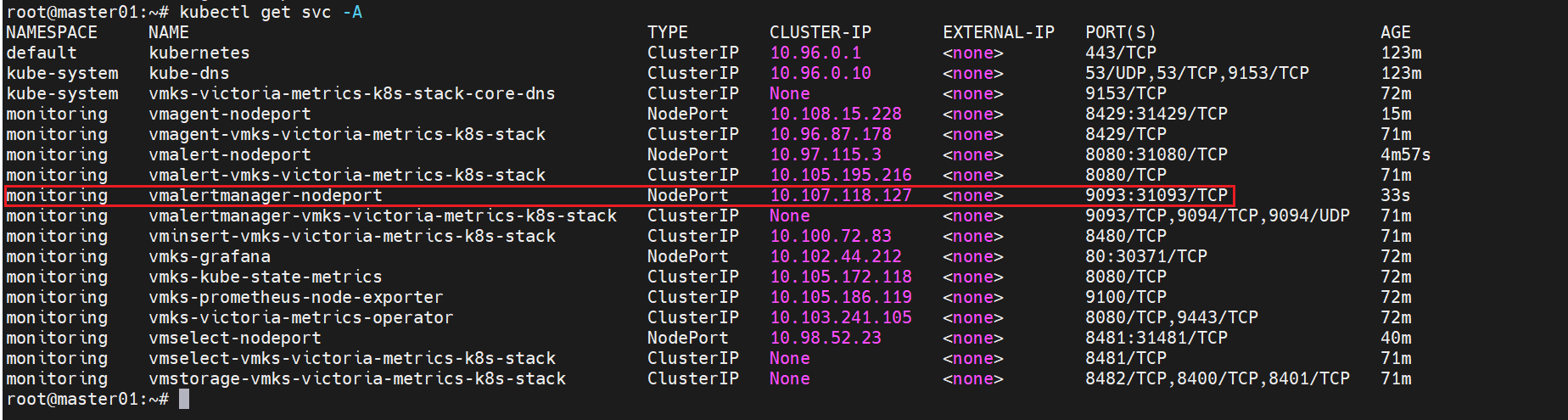
http:// <节点ip> :31093
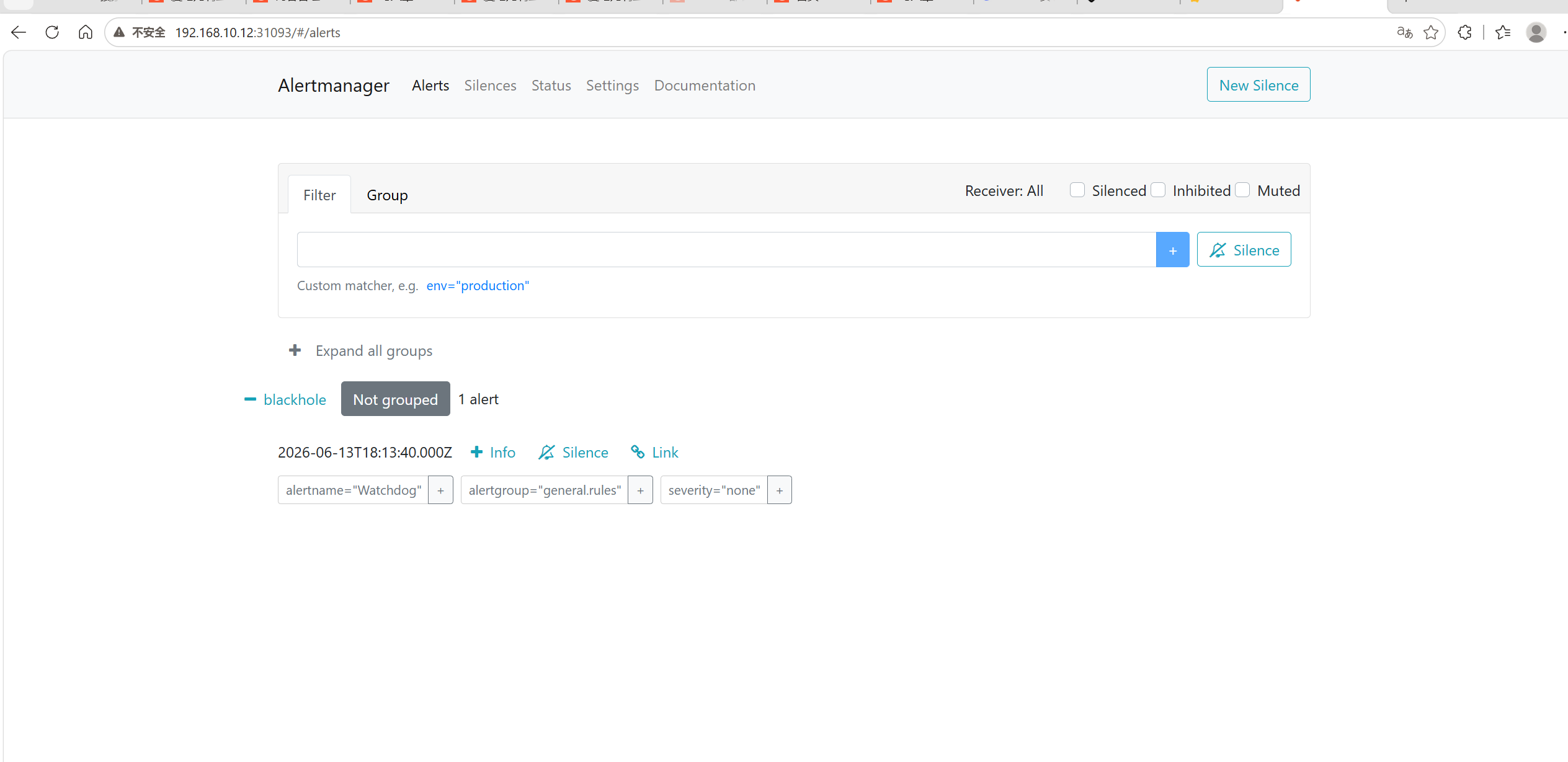
后面我会再出一期把victoria-metrics-k8s-stack的告警模块和grafana替换成国产的夜莺监控,更适配国内的环境
且夜莺监控的Categraf采集器在物理机/虚拟机环境下的使用比export要好的多
在k8s群集+物理机/虚拟机的生产环境下victoria-metrics-k8s-stack+夜莺监控+Categraf应该是目前中小企业最合适的选择