文章目录
-
- 引言
- [1 模型架构的演进](#1 模型架构的演进)
-
- [1.1 核心挑战:连续剂量信号容易被淹没](#1.1 核心挑战:连续剂量信号容易被淹没)
- [1.2 初步尝试:多头架构扩展(Dragonnet 扩展版)](#1.2 初步尝试:多头架构扩展(Dragonnet 扩展版))
- [1.3 升级 1:DRNet 引入"特征强注"](#1.3 升级 1:DRNet 引入"特征强注")
- [1.4 升级 2:VCNet 引入"变系数网络"](#1.4 升级 2:VCNet 引入"变系数网络")
- [2 Loss 函数的演进](#2 Loss 函数的演进)
-
- [2.1 核心挑战:观测数据中的混杂偏差](#2.1 核心挑战:观测数据中的混杂偏差)
- [2.2 朴素估计(Naive):提取了混杂特征,但估计依然有偏](#2.2 朴素估计(Naive):提取了混杂特征,但估计依然有偏)
- [2.3 目标正则化(TR):逆概率加权入梯度,实现主动纠偏](#2.3 目标正则化(TR):逆概率加权入梯度,实现主动纠偏)
- [2.4 泛函目标正则化(FTR):VCNet 的连续扩展与大样本理论保证](#2.4 泛函目标正则化(FTR):VCNet 的连续扩展与大样本理论保证)
- [2.5 工程实战:两阶段训练策略](#2.5 工程实战:两阶段训练策略)
- [3 实验验证与对比](#3 实验验证与对比)
-
- [3.1 合成数据集设计](#3.1 合成数据集设计)
-
- [3.1.1 设计思路](#3.1.1 设计思路)
- [3.1.2 计算 ground-truth ADRF](#3.1.2 计算 ground-truth ADRF)
- [3.2 评估指标:MISE](#3.2 评估指标:MISE)
- [3.3 实验配置](#3.3 实验配置)
-
- [3.3.1 模型变体](#3.3.1 模型变体)
- [3.4 仿真结果分析](#3.4 仿真结果分析)
-
- [3.4.1 定量结果:MISE 对比](#3.4.1 定量结果:MISE 对比)
- [3.4.2 定性结果:ADRF 曲线对比](#3.4.2 定性结果:ADRF 曲线对比)
- [3.4.3 消融分析:架构 vs Loss 的独立贡献](#3.4.3 消融分析:架构 vs Loss 的独立贡献)
- [3.4.4 实践建议](#3.4.4 实践建议)
- 总结
- 参考文献
引言
上一篇文章中,我们探讨了 Dragonnet 等模型如何将深度学习与因果推断结合,解决二元干预(如"发券"与"不发券")的效应估计问题。
但现实业务中,干预变量往往是连续的------外卖折扣率可以是 1%~10% 之间的任意值,给药剂量也是连续变化的。面对连续干预,原有的二元模型无法直接适用。
为此,学术界提出了 DRNet 和 VCNet 等模型。理解这类连续因果推断模型,核心是两个维度:
- 模型架构:如何让神经网络有效建模连续剂量效应、输出平滑曲线?
- Loss 函数:如何在连续空间下消除混杂偏差、保证因果效应估计准确?
下面分别拆解这两个维度的底层逻辑。
1 模型架构的演进
1.1 核心挑战:连续剂量信号容易被淹没
直接将 1 维的剂量 T T T 与高维用户特征 X X X 拼接输入, T T T 的信号极易被淹没,模型难以捕捉剂量的细微变化。
针对这一问题,架构经历了三次关键演进:
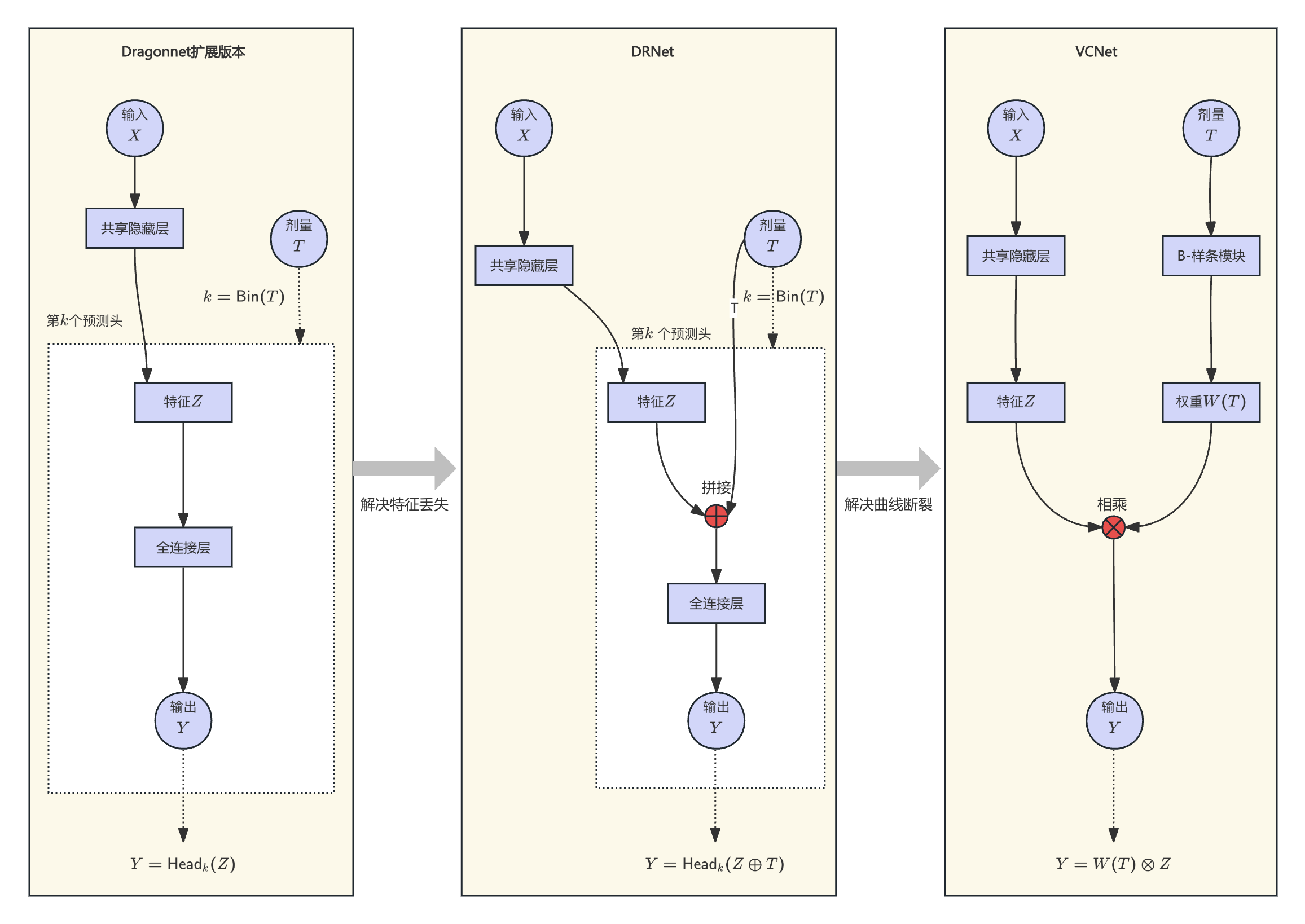
1.2 初步尝试:多头架构扩展(Dragonnet 扩展版)
最直观的解法是"离散化":将连续区间等分为若干个桶,扩展出对应数量的预测头。
假设剂量 T ∈ 0 , 1 T \in 0,1 T∈0,1,将其等分为 K K K 个桶,每桶宽度 Δ = 1 / K \Delta = 1/K Δ=1/K(如 K = 5 K=5 K=5 时 Δ = 0.2 \Delta=0.2 Δ=0.2)。剂量 T T T 充当路由开关,通过 k = ⌊ T / Δ ⌋ k = \lfloor T / \Delta \rfloor k=⌊T/Δ⌋ 将样本硬分配到对应区间,激活第 k k k 个预测头,输出 Y = H e a d k ( Z ) Y = \mathrm{Head}_k(Z) Y=Headk(Z)(其中 Z Z Z 为底层网络对 X X X 提取的共享特征表示)。
根本缺陷 :进入预测头后,具体剂量数值被丢弃,网络只能输出区间内所有样本的平均效应,输出曲线呈阶梯状水平线。 T = 0.22 T=0.22 T=0.22 和 T = 0.38 T=0.38 T=0.38 同属第 1 桶(编号从 0 起,对应区间 [ 0.2 , 0.4 ) [0.2, 0.4) [0.2,0.4)),但两者的药效显然不同,模型却给出完全相同的预测值------边际效应信息彻底丢失。
1.3 升级 1:DRNet 引入"特征强注"
DRNet 的思路直接:既然连续信息被丢弃,进入预测头后再把它拼回来。
样本进入第 k k k 个预测头后,DRNet 将 T T T 的具体数值与特征 Z Z Z 强行拼接(图中红色 ⊕ \oplus ⊕),预测变为 Y = H e a d k ( Z ⊕ T ) Y = \mathrm{Head}_k(Z \oplus T) Y=Headk(Z⊕T)。
连续信息保留了,区间内部有了变化趋势。但结构性问题依然存在 :各预测头参数相互独立,剂量从 T = 0.399 T=0.399 T=0.399 变为 T = 0.401 T=0.401 T=0.401 时模型瞬间切换预测头,没有任何约束保证交界处输出连续,曲线在边界处必然发生断裂跳跃。
此外,将 T T T 拼入特征向量末尾是一种"软性"引入方式,能否被网络有效利用,完全依赖数据驱动------并无结构上的保证。
1.4 升级 2:VCNet 引入"变系数网络"
VCNet 引入统计学经典工具 B-样条(B-splines),用基函数的连续加权替代离散分桶,从根本上解决曲线断裂问题。
什么是 B-样条?
B-样条是一种基函数展开------用一组"山包状"的局部函数叠加来拟合曲线,和 RBF 核(高斯函数)的思路类似:在 SVM 或高斯过程中,我们也是用一组高斯"山包"的加权组合来拟合复杂函数。B-样条的形式如下:
W ( T ) = ∑ l = 1 L a l ⋅ ϕ l ( d ) ( T ) W(T) = \sum_{l=1}^L a_l \cdot \phi_l^{(d)}(T) W(T)=l=1∑Lal⋅ϕl(d)(T)
a l a_l al 是训练时学习的系数; ϕ l ( d ) ( T ) \phi_l^{(d)}(T) ϕl(d)(T) 是训练前预先构造好的基函数,上标 d d d 为阶数,下标 l l l 为编号。两个超参数相互独立、含义不同:
- L L L(数量):用多少个"山包"拼合曲线,由结点(knots)的划分方式决定;
- d d d(阶数) :每个山包自身的形状------是阶跃还是平滑曲线。阶数是构造参数,训练前固定,不参与梯度优化;只有 a l a_l al 才在训练中更新。
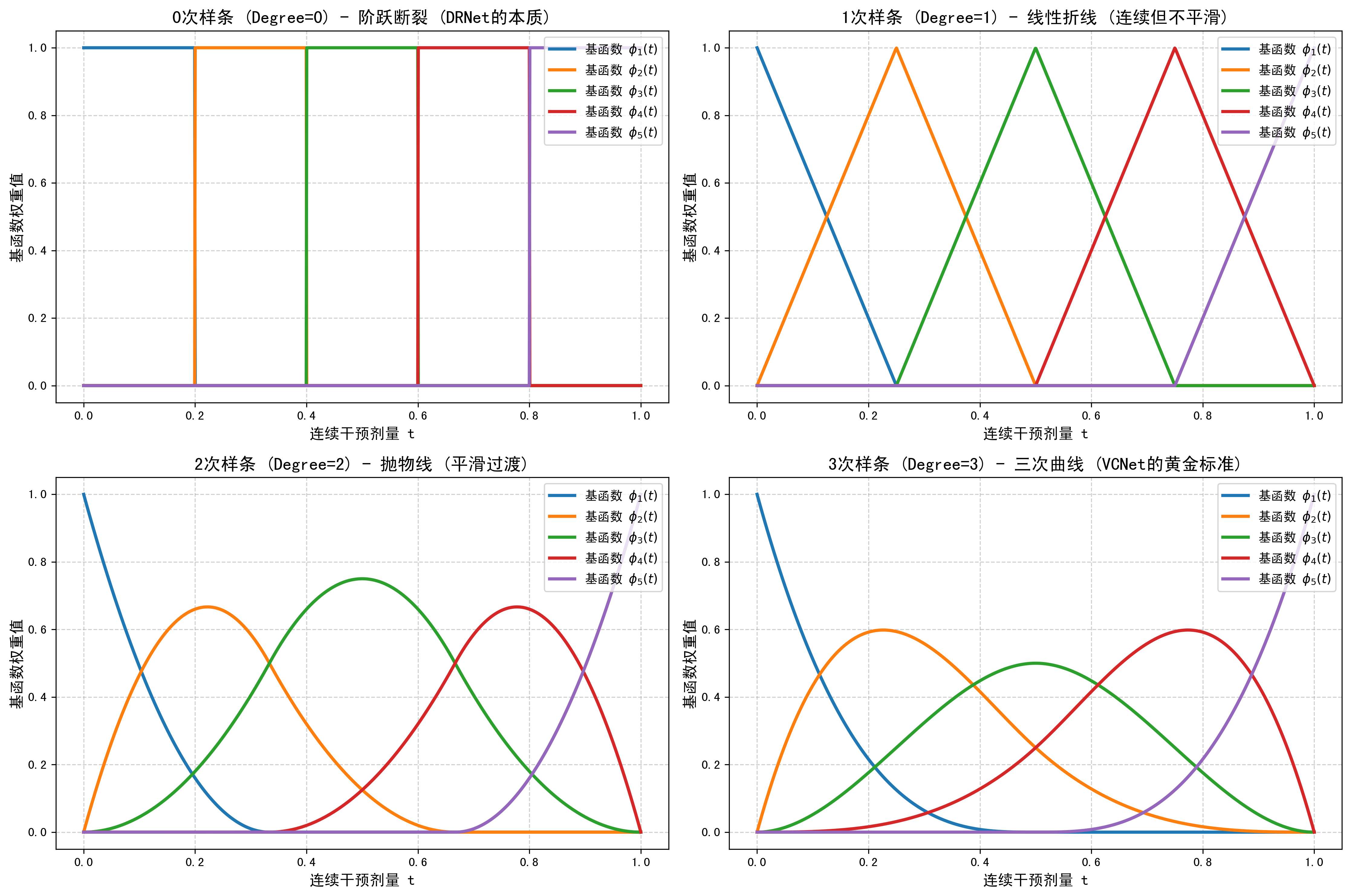
- 阶数为 0:极窄的指示函数(图左上角),区间内为 1,区间外严格为 0,互不交叠;
- 阶数为 3:平滑交叠的 S 形曲线(图右下角),分段三次多项式,底座跨越多个相邻子区间,保证曲率连续。
为什么用 B-样条,不用高斯函数?
既然思路相似,为什么不直接用高斯函数,非要用 B-样条?B-样条有两个高斯函数不具备的数学性质:
- 真正的局部控制 :高斯函数尾巴无限延伸( e − x 2 e^{-x^2} e−x2 永不为 0),调整一处权重会干扰全局。B-样条具有紧支撑性质(即每个基函数只在有限的剂量区间内非零,出了这段区间就严格等于 0),调整某个 a l a_l al 只影响对应区间的曲线,互不干扰。
- 自带归一化 :B-样条满足"单位分解"定理: ∑ l = 1 L ϕ l ( d ) ( T ) ≡ 1 \sum_{l=1}^L \phi_l^{(d)}(T) \equiv 1 ∑l=1Lϕl(d)(T)≡1。这使 W ( T ) W(T) W(T) 本质上是各权重矩阵的凸组合,数值范围天然有界,不会出现梯度爆炸。
VCNet 的计算逻辑
以 5 个 3 次样条基函数为例,网络学习 5 个基础权重矩阵 A 1 A_1 A1~ A 5 A_5 A5。输入 T = 0.35 T = 0.35 T=0.35 时,B-样条模块计算出各基函数的激活值------假设落在第 2、3 个基函数的交叠处,分别为 0.3 和 0.7,则动态组合出专属权重矩阵:
W ( 0.35 ) = 0.3 × A 2 + 0.7 × A 3 W(0.35) = 0.3 \times A_2 + 0.7 \times A_3 W(0.35)=0.3×A2+0.7×A3
再用 W ( 0.35 ) W(0.35) W(0.35) 与用户特征 Z Z Z 做矩阵乘法(图中红色 ⊗ \otimes ⊗),即 Y = W ( T ) ⋅ Z Y = W(T) \cdot Z Y=W(T)⋅Z。
"动态权重"与"特征拼接"的本质差异
| DRNet | VCNet | |
|---|---|---|
| T T T 的角色 | 拼接到特征向量末尾 | 融合到预测层权重里 |
| 平滑性保证 | 无,靠数据驱动学习 | 有,B-样条结构归纳偏置 |
| 边界行为 | 切换预测头时可能断裂 | 权重连续过渡,天然平滑 |
从特例的角度理解
将 B-样条阶数设为 0,基函数退化成阶跃函数,剂量从 T = 0.399 T=0.399 T=0.399 变为 T = 0.401 T=0.401 T=0.401 时两个取值分属不同基函数区间,权重矩阵在相邻基函数之间瞬间跳变------在数学上与多头分桶架构完全等价。多头分桶架构是变系数网络在平滑度极低时的特例。
2 Loss 函数的演进
2.1 核心挑战:观测数据中的混杂偏差
好的架构只解决了曲线表达能力的问题。观测数据中还存在严重的混杂偏差------病情越重的患者往往被开具越大剂量的药物,如果不消除这种相关性,模型学到的只是表面相关,而非因果效应。
Loss 函数也因此经历了三次演进:
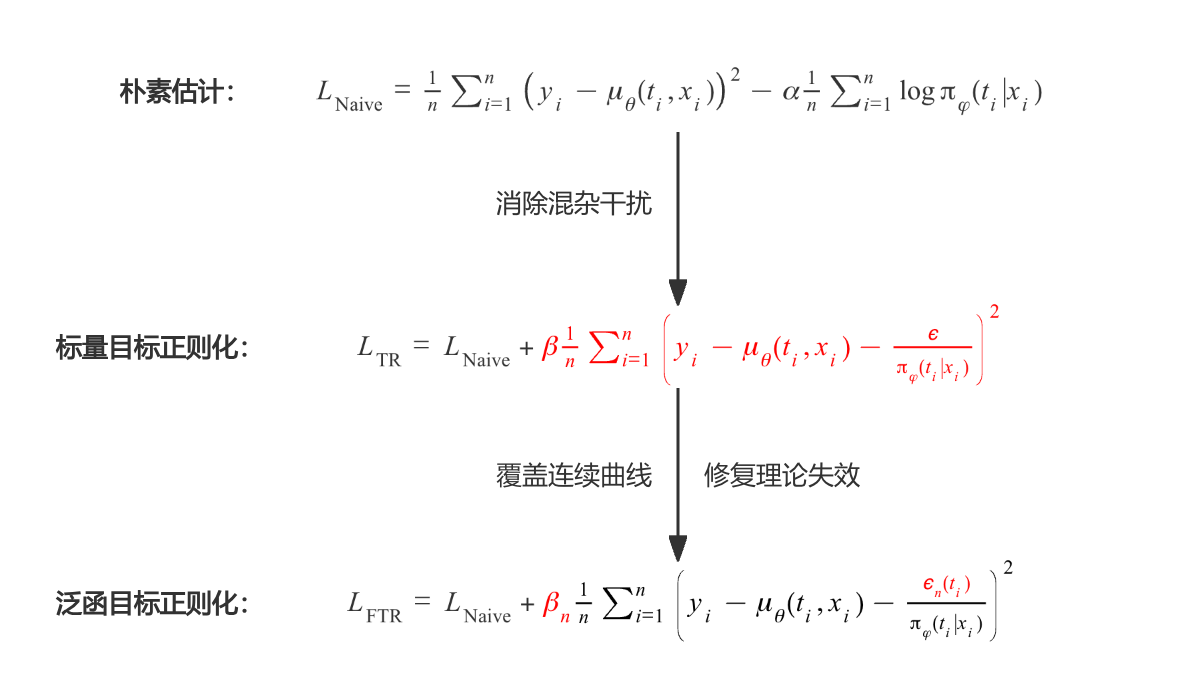
2.2 朴素估计(Naive):提取了混杂特征,但估计依然有偏
联合训练结果预测模型 μ θ \mu_{\theta} μθ 和倾向得分模型 π φ \pi_{\varphi} πφ(预测采取特定剂量的概率密度):
L Naive = 1 n ∑ i = 1 n ( y i − μ θ ( t i , x i ) ) 2 − α 1 n ∑ i = 1 n log π φ ( t i ∣ x i ) L_{\text{Naive}} = \frac{1}{n} \sum_{i=1}^n \big( y_i - \mu_{\theta}(t_i, x_i) \big)^2 - \alpha \frac{1}{n} \sum_{i=1}^n \log \pi_{\varphi}(t_i | x_i) LNaive=n1i=1∑n(yi−μθ(ti,xi))2−αn1i=1∑nlogπφ(ti∣xi)
(第二项为负对数似然,最小化 L Naive L_{\text{Naive}} LNaive 等价于同时最大化倾向得分的对数似然。)
为什么要带上 π \pi π? 只用 MSE 预测 Y Y Y 时,网络会丢弃对 Y Y Y 影响小、但影响干预分配 T T T 的特征(即混杂因子)。加入 π φ \pi_{\varphi} πφ 的预测,强迫网络提取并保留混杂特征。
但问题没有真正解决 : π φ \pi_{\varphi} πφ 只在训练时辅助特征提取,推断时直接输出 μ θ ( t , x ) \mu_{\theta}(t, x) μθ(t,x), π \pi π 对最终预测没有任何直接影响,混杂偏差并未在数学上被纠正,结果依然有偏。
2.3 目标正则化(TR):逆概率加权入梯度,实现主动纠偏
Dragonnet 在 L Naive L_{\text{Naive}} LNaive 基础上引入一个标量纠偏项 ϵ \epsilon ϵ(针对二元干预设计),结合倾向得分的逆概率构成 TR 项:
L TR = L Naive + β 1 n ∑ i = 1 n ( y i − μ θ ( t i , x i ) − ϵ π φ ( t i ∣ x i ) ) 2 L_{\text{TR}} = L_{\text{Naive}} + \beta \frac{1}{n} \sum_{i=1}^n \left( y_i - \mu_{\theta}(t_i, x_i) - \frac{\epsilon}{\pi_{\varphi}(t_i|x_i)} \right)^2 LTR=LNaive+βn1i=1∑n(yi−μθ(ti,xi)−πφ(ti∣xi)ϵ)2
ϵ \epsilon ϵ 由独立的 TargetReg 模块学习,与 μ θ \mu_\theta μθ、 π φ \pi_\varphi πφ 一起端到端训练,用于吸收 μ θ \mu_\theta μθ 尚未修正的残余偏差。训练收敛时,若 μ θ \mu_\theta μθ 已足够无偏, ϵ \epsilon ϵ 自然趋向 0,正则化项消失。
为什么 Naive 有 π \pi π 却不能纠偏,TR 可以? L Naive L_{\text{Naive}} LNaive 的两项是加法分离的------MSE 项只更新 μ θ \mu_\theta μθ,对数似然项只更新 π φ \pi_\varphi πφ,两者没有耦合, π \pi π 的信息无法渗透到 μ \mu μ 的预测中。
TR 项则不同:对 μ θ \mu_\theta μθ 求梯度时,残差 ( y i − μ θ − ϵ π φ ) \left(y_i - \mu_\theta - \frac{\epsilon}{\pi_\varphi}\right) (yi−μθ−πφϵ) 中含有 1 / π φ 1/\pi_\varphi 1/πφ。倾向得分小的样本 (即实际剂量与患者特征"不匹配"的稀少组合,如轻症患者被给予高剂量)残差会被放大,反向传播时对 μ θ \mu_\theta μθ 施加更强的修正压力------本质是逆概率加权 在梯度层面的体现,强迫 μ \mu μ 修正混杂偏差。
推断时 :纠偏已在训练阶段通过梯度流完成, μ θ \mu_{\theta} μθ 本身已是无偏估计器,直接丢弃 ϵ \epsilon ϵ 和 π \pi π,只输出 μ θ ( t , x ) \mu_{\theta}(t, x) μθ(t,x)。
2.4 泛函目标正则化(FTR):VCNet 的连续扩展与大样本理论保证
Dragonnet 的 TR 中 ϵ \epsilon ϵ 是针对二元干预的标量,无法直接用于连续干预。VCNet 对此做出两处原创性扩展,提出泛函目标正则化(FTR):
L FTR = L Naive + β n 1 n ∑ i = 1 n ( y i − μ θ ( t i , x i ) − ϵ n ( t i ) π φ ( t i ∣ x i ) ) 2 L_{\text{FTR}} = L_{\text{Naive}} + \beta_n \frac{1}{n} \sum_{i=1}^n \left( y_i - \mu_{\theta}(t_i, x_i) - \frac{\epsilon_n(t_i)}{\pi_{\varphi}(t_i|x_i)} \right)^2 LFTR=LNaive+βnn1i=1∑n(yi−μθ(ti,xi)−πφ(ti∣xi)ϵn(ti))2
扩展一: ϵ → ϵ n ( t ) \epsilon \to \epsilon_n(t) ϵ→ϵn(t)
将标量扩展为关于剂量 t t t 的连续函数,参数化方式与架构部分相同,用 B-样条展开:
ϵ n ( t ) = ∑ l = 1 L ′ c l ⋅ ϕ l ( d ) ( t ) \epsilon_n(t) = \sum_{l=1}^{L'} c_l \cdot \phi_l^{(d)}(t) ϵn(t)=l=1∑L′cl⋅ϕl(d)(t)
c l c_l cl 是独立于 θ \theta θ、 φ \varphi φ 的一组可学习系数,由 TargetReg 模块持有,与主网络一起端到端训练。与架构里 W ( T ) W(T) W(T) 输出权重矩阵不同, ϵ n ( t ) \epsilon_n(t) ϵn(t) 输出的是标量,直接加到残差中起纠偏作用。这一设计使不同剂量区间拥有各自独立的纠偏量,而非原始 TR 那样对所有剂量共用一个 ϵ \epsilon ϵ。"泛函(Functional)"一词由此而来------优化对象从固定标量变为随样本量 n n n 扩展的函数族。
扩展二: β → β n \beta \to \beta_n β→βn
引入随样本量 n n n 增加而衰减的系数(典型形式 β n = O ( 1 / n ) \beta_n = O(1/\sqrt{n}) βn=O(1/n ), n → ∞ n \to \infty n→∞ 时 β n → 0 \beta_n \to 0 βn→0)。直觉很简单:样本少时正则化强力介入辅助纠偏;样本趋于无穷时数据已足够自证,正则化权重自动归零。这同时修复了 TR 固定 β \beta β 的隐患------原论文理论分析指出,固定 β \beta β 在 μ \mu μ 拟合遇到瓶颈时,网络可能转而调整 π \pi π 来满足正则化约束,导致双重鲁棒性失效; β n \beta_n βn 归零则从根本上规避这一风险。
定理保证 :在大样本极限下,只要 μ θ \mu_{\theta} μθ 或 π φ \pi_{\varphi} πφ 其中之一能收敛到真实值 ,整条因果曲线就能精准逼近真实物理规律------即连续空间下的双重鲁棒性。
2.5 工程实战:两阶段训练策略
L FTR L_{\text{FTR}} LFTR 中含有 1 / π φ 1/\pi_{\varphi} 1/πφ 项,网络随机初始化时分母极易接近 0,直接训练会导致 Loss 爆炸(NaN)。
VCNet 采用预热(Warm-up)+ 联合微调两阶段策略:
- 预训练 :仅用 L Naive L_{\text{Naive}} LNaive 训练,让 μ \mu μ 和 π \pi π 达到合理的初始状态;
- 联合优化 :引入 TargetReg 模块,开启完整 L TR L_{\text{TR}} LTR 或 L FTR L_{\text{FTR}} LFTR,所有参数端到端联合优化,不冻结任何权重。
3 实验验证与对比
前两部分分别拆解了架构演进(Dragonnet → DRNet → VCNet)和 Loss 演进(Naive → TR → FTR)的逻辑。实验要回答的核心问题是:两者各自贡献了多少?叠加后是否产生协同效应?
我们选择 6 个模型变体,严格覆盖两条演进主线:
| 模型 | 架构 | Loss | 验证目标 |
|---|---|---|---|
| Dragonnet | 多头网络 | Naive | 基线 |
| Dragonnet+TR | 多头网络 | TR | Loss 升级效果(架构不变) |
| DRNet | 多头网络 + DR 分桶 | Naive | 架构升级效果(Loss 不变) |
| DRNet+TR | 多头网络 + DR 分桶 | TR | 架构升级 + Loss 升级 |
| VCNet | 变系数网络 | Naive | 架构终极形态(Loss 不变) |
| VCNet+FTR | 变系数网络 | FTR | 架构终极 + Loss 终极 |
3.1 合成数据集设计
3.1.1 设计思路
评估连续因果模型的核心,是看模型能否准确估计剂量-反应函数(ADRF) ------固定剂量 t t t,对所有个体取期望后的平均响应曲线:
μ ( t ) = E X Y ( t , X ) \mu(t) = \mathbb{E}_XY(t, X) μ(t)=EXY(t,X)
真实数据中无法同时观测同一个人在不同剂量下的结果,因此需要构造函数形式已知的合成数据集,让 ground-truth ADRF 可以精确计算。
借鉴 IHDP 数据集的设计思路(用已知函数构造 treatment 和 outcome,从而获得可验证的 ground-truth),构建一个全合成数据集:训练集 500 条、测试集 200 条 ,协变量 X X X 为 6 维 ,从 0 , 1 0,1 0,1 均匀分布独立采样。数据集刻意引入三个挑战:
python
import numpy as np
n_train, n_test = 500, 200
X_train = np.random.uniform(0, 1, (n_train, 6))
X_test = np.random.uniform(0, 1, (n_test, 6))
# 剂量 T:X 的非线性函数,经 sigmoid 映射到 [0,1]
def generate_t(X):
propensity = (
0.5 * X[:, 0] + 0.3 * X[:, 1] * X[:, 2] +
0.4 * np.sin(np.pi * X[:, 3]) + 0.2 * X[:, 4] ** 2
)
return 1 / (1 + np.exp(-(propensity + np.random.normal(0, 0.1, X.shape[0]))))
T_train = generate_t(X_train)
T_test = generate_t(X_test)
# 结果 Y:非单调、非线性、有个体异质性
def true_outcome(t, X, noise_std=0.1):
mu = np.cos((t - 0.5) * 2 * np.pi) * (
t ** 2 + (4 * np.maximum(X[:, 0], X[:, 5]) ** 3) / (1 + 2 * X[:, 2] ** 2) * np.sin(X[:, 3])
)
return mu + np.random.normal(0, noise_std, t.shape)
Y_train = true_outcome(T_train, X_train)
Y_test = true_outcome(T_test, X_test)- 混淆偏差 : T T T 由 X X X 的非线性函数生成(含乘积项、三角函数和平方项),使倾向得分本身就难以估计------若 T T T 和 X X X 关系过于简单,TR/FTR 的纠偏机制将失去用武之地;
- 非单调性 : cos ( ( T − 0.5 ) × 2 π ) \cos((T-0.5) \times 2\pi) cos((T−0.5)×2π) 使 Y Y Y 在 T = 0.5 T=0.5 T=0.5 处取极大值,在 T = 0 T=0 T=0 和 T = 1 T=1 T=1 两端取极小值,构成先升后降的非单调响应曲线,充分检验各架构的非线性建模能力;
- 个体异质性 : Y Y Y 的完整结构为 cos ( ⋅ ) × ( t 2 + 4 ⋅ max ( X 1 , X 6 ) 3 1 + 2 X 3 2 ⋅ sin ( X 4 ) ) \cos(\cdot) \times \left(t^2 + \frac{4 \cdot \max(X_1, X_6)^3}{1 + 2 X_3^2} \cdot \sin(X_4)\right) cos(⋅)×(t2+1+2X324⋅max(X1,X6)3⋅sin(X4)),其中异质性项使不同协变量组合的个体对同一剂量响应截然不同。
3.1.2 计算 ground-truth ADRF
python
T_grid = np.linspace(0, 1, 100)
true_adrf = np.array([
np.mean(true_outcome(t * np.ones(n_test), X_test, noise_std=0))
for t in T_grid
])在 100 个剂量网格点上,对所有测试样本求期望响应,即得 ground-truth 曲线。
3.2 评估指标:MISE
沿用 VCNet 原论文的评估指标 MISE(Mean Integrated Squared Error),衡量模型估计的 ADRF 曲线在整个剂量区间上的平均平方偏差:
MISE = ∫ 0 1 μ \^ ( t ) − μ ( t ) 2 d t ≈ 1 M ∑ m = 1 M μ \^ ( t m ) − μ ( t m ) 2 \text{MISE} = \int_0^1 \left \\hat{\\mu}(t) - \\mu(t) \\right^2 dt \approx \frac{1}{M} \sum_{m=1}^{M} \left \\hat{\\mu}(t_m) - \\mu(t_m) \\right^2 MISE=∫01μ\^(t)−μ(t)2dt≈M1m=1∑Mμ\^(tm)−μ(tm)2
单次实验结果方差较大,采用蒙特卡洛仿真:独立生成 100 个数据集,对每个数据集分别训练 6 个模型,报告 MISE 均值和标准差。
3.3 实验配置
3.3.1 模型变体
注:带 TR/FTR 的模型均采用 VCNet 的连续扩展版本( ϵ ( t ) \epsilon(t) ϵ(t) B-样条参数化),Dragonnet 原始 TR 的标量 ϵ \epsilon ϵ 不适用于连续场景。
| 模型 | 架构 | Loss | 关键参数 |
|---|---|---|---|
| Dragonnet | 多头网络 | Naive | α=0.5, lr=0.05 |
| Dragonnet+TR | 多头网络 | TR | α=0.5, β=1.0, lr=0.05, tr_lr=0.001 |
| DRNet | 多头网络 + DR 分桶 | Naive | α=1.0, lr=0.05, isenhance=1 |
| DRNet+TR | 多头网络 + DR 分桶 | TR | α=0.5, β=1.0, lr=0.05, tr_lr=0.001, isenhance=1 |
| VCNet | 变系数网络 | Naive | α=0.5, lr=0.0001, degree=2, knots=0.33,0.66 |
| VCNet+FTR | 变系数网络 | FTR | α=0.5, β_n=1.0, lr=0.0001, tr_lr=0.001, degree=2, knots=0.33,0.66 |
共享超参数:网络结构 cfg = (50, 50, 1, 'relu'), (50, 1, 1, 'id');训练 800 轮;SGD 优化器(momentum=0.9,weight_decay=5e-3);剂量网格 100 个点,覆盖 0 , 1 0,1 0,1。带 TR/FTR 的模型采用两阶段策略:① 预训练阶段仅用 L Naive L_{\text{Naive}} LNaive,让 μ θ \mu_{\theta} μθ 和 π φ \pi_{\varphi} πφ 达到合理初始状态;② 联合优化阶段开启完整 Loss,所有参数端到端梯度下降。
3.4 仿真结果分析
3.4.1 定量结果:MISE 对比
| 模型 | 架构 | Loss | MISE 均值 | MISE 标准差 | 相对基线 |
|---|---|---|---|---|---|
| Dragonnet | 多头网络 | Naive | 0.0450 | 0.0094 | 基线 |
| Dragonnet+TR | 多头网络 | TR | 0.0272 | 0.0088 | -39.8% |
| DRNet | 多头网络 + DR 分桶 | Naive | 0.0425 | 0.0094 | -5.6% |
| DRNet+TR | 多头网络 + DR 分桶 | TR | 0.0267 | 0.0093 | -40.7% |
| VCNet | 变系数网络 | Naive | 0.0175 | 0.0104 | -61.1% |
| VCNet+FTR | 变系数网络 | FTR | 0.0135 | 0.0071 | -70.0% |
VCNet+FTR 以 MISE = 0.0135 位居最优,相较基线 Dragonnet,MISE 降低 70.0%。
3.4.2 定性结果:ADRF 曲线对比
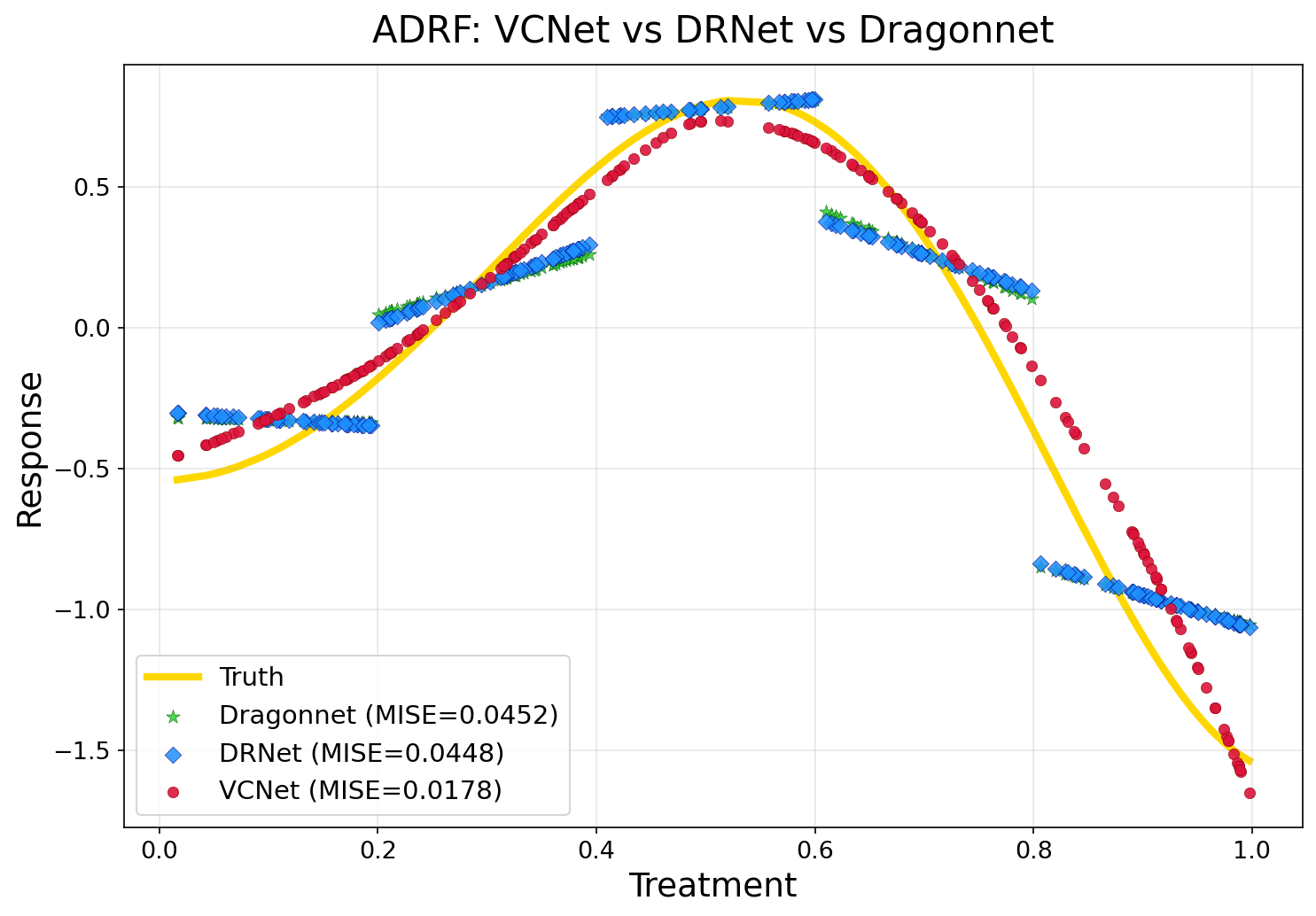
现象一:VCNet 曲线更平滑,多头架构存在断点
红色散点(VCNet)整体贴合黄线,散点分布连续平滑;而蓝色(DRNet)和绿色(Dragonnet)在剂量边界处可以看到明显的跳变,曲线呈阶梯状断裂。这与前文的架构分析完全一致------多头架构各预测头参数独立,分桶边界处没有任何约束保证连续性,断裂是结构上的必然。
现象二:三个模型均能定性捕捉非单调性
三个模型都捕捉到了整体的先升后降趋势,说明基本的非线性拟合能力不是瓶颈;VCNet 的优势主要体现在曲线的平滑性和边界处的稳定性上。
3.4.3 消融分析:架构 vs Loss 的独立贡献
Loss 演进的独立贡献(架构固定,引入 TR/FTR)
| 对比组 | 无 TR | 有 TR/FTR | 降幅 |
|---|---|---|---|
| Dragonnet → Dragonnet+TR | 0.0450 | 0.0272 | -39.8% |
| DRNet → DRNet+TR | 0.0425 | 0.0267 | -37.2% |
| VCNet → VCNet+FTR | 0.0175 | 0.0135 | -22.9% |
多头架构(前两者)的 TR 效果最显著(MISE 降低接近 40%),因为多头架构本身对混淆偏差抵抗力弱,TR 的纠偏空间最大。
VCNet 引入 FTR 降幅略小(MISE 降低 22.9%),并非 FTR 效果变差,而是 VCNet 已将基础误差压得很低(0.0175 vs 0.0425),提升空间本就更小。
架构演进的独立贡献(Loss 固定,改变网络架构)
| 对比组 | Dragonnet | DRNet | VCNet |
|---|---|---|---|
| Naive Loss | 0.0450 | 0.0425(-5.6%) | 0.0175(-61.1%) |
| TR/FTR Loss | 0.0272 | 0.0267(-1.8%) | 0.0135(-50.4%) |
最值得关注的发现:Dragonnet → DRNet 几乎没有增益 ,印证了"仅靠特征强注难以带来实质收益"的判断;DRNet → VCNet 使 MISE 降低约 61%,主要归因于 B-样条结构带来的平滑性保证。
两者叠加的协同效应
- 架构贡献(Dragonnet → VCNet,Naive):MISE 降低 ≈ 61.1%
- Loss 贡献(VCNet Naive → VCNet+FTR):MISE 降低 ≈ 22.9%
- 实际总降幅(Dragonnet → VCNet+FTR):MISE 降低 ≈ 70.0%
实际总降幅略小于简单相加------这并不意外:架构已将大部分偏差消除,TR 进一步纠偏的空间随之收窄,两者的总收益自然低于算术叠加。但无论如何,两者结合仍是收益最大化的策略。
3.4.4 实践建议
建议一:架构选择优先于 Loss 调参
在本文合成数据集的实验条件下,架构升级到 VCNet 使 MISE 降低约 61%,远大于引入 TR 带来的 23%~40%。剂量效应曲线复杂时,优先换架构,而非在旧架构上堆正则化。需注意:若真实场景中混杂偏差更强,TR/FTR 的贡献可能更为显著,两类优化的优先级也应随之调整。
建议二:TR 是廉价的保险,默认开启
同一架构下,TR/FTR 可使 MISE 降低 23%~40%,额外成本仅是一个 TargetReg 模块和两阶段训练策略,在大多数场景下默认开启是稳健策略 。(唯一需注意的例外:倾向得分 π \pi π 极难估计时, 1 / π 1/\pi 1/π 的数值不稳定可能放大误差,此时需适当降低 β \beta β 或加强预热阶段。)
总结
本文通过三条主线梳理了连续干预因果推断模型的底层逻辑:
- 架构演进(Dragonnet → DRNet → VCNet):从"离散化硬路由"到"B-样条连续加权",将平滑性直接编码进模型结构;
- Loss 演进 (Naive → TR → FTR):从"被动提取混杂特征"到"主动纠偏 + 大样本理论保证",通过逆概率加权将 π \pi π 的信息干预到 μ \mu μ 的梯度更新中,实现双重鲁棒性;
- 实验验证:100 次蒙特卡洛仿真,定量分解了架构和 Loss 的独立贡献与协同效应。
对于实际应用,两条结论值得记住:架构是效果的天花板,B-样条的结构归纳偏置带来的 MISE 降低远超在旧架构上堆正则化;在此基础上,TR/FTR 是成本极低的额外保险,默认开启是稳健策略。
参考文献
- DRNet :Schwab et al., Learning Counterfactual Representations for Estimating Individual Dose-Response Curves , AAAI 2020. https://arxiv.org/abs/1902.00981
- VCNet :Nie et al., VCNet and Functional Targeted Regularization For Learning Causal Effects of Continuous Treatments , ICLR 2021. https://arxiv.org/abs/2103.07861