Cloud_Shy 陪你解读《Effective Python 3rd Edition》:从练气到老魔

第七章 Classes and Interfaces(类与接口)
作为一种面向对象编程语言,Python 支持各种特性,如继承、多态和封装。在 Python 中完成任务通常需要编写新的类,并定义它们如何通过接口和关系进行交互。
类与继承机制使得用对象来表述 Python 程序的预期行为变得十分简便。它们使您能够随着时间的推移不断完善和扩展功能。在需求不断变化的环境中,这些机制提供了灵活性。熟练掌握类与继承的使用方法,有助于您编写易于维护的代码。
Python 也是一种多范式语言 ,它鼓励采用函数式编程 风格。函数对象属于第一类,这意味着它们可以像普通变量一样被传递。Python 还允许你在同一程序中使用混合的面向对象风格与函数式风格特性,这种方式可能比各自独立使用任何一种风格都更为强大。
Item 48:接受函数而非类来实现简单接口
Python 中的许多内置 API 都允许你通过传递一个函数来定制其行为。这些 hook (钩子)被 API 用于在代码执行过程中进行回调调用。例如,列表类型的 sort 方法会接受一个可选的 key 参数,该参数用于确定每个索引在排序时的值(详情请参阅 Item 100:"使用 key 参数按复杂条件进行排序")。在此示例中,我通过将内置函数 len 作为 keyhook 来根据名称的长短对列表进行排序:
names = ["Socrates", "Archimedes", "Plato", "Aristotle"]
names.sort(key=len)
print(names)
>>>
['Plato', 'Socrates', 'Aristotle', 'Archimedes']
在其他语言中,你或许会认为钩子是由一个抽象类来定义的。而在 Python 中,许多钩子实际上只是无状态函数,这些函数拥有经过详细文档说明的参数和返回值。函数非常适合作为钩子,因为相较于类而言,它们更易于描述且更易于实现。函数之所以能够充当钩子,是因为 Python 具备 first-class 函数的特性:函数与方法可以像语言中的其他任何值一样被传递和引用。
例如,假设我想自定义 defaultdict 类的行为(请参阅 Item 27:"优先使用 defaultdict 而不是 setdefault 来处理内部状态中的缺失项" 了解详情)。此数据结构允许您提供一个函数,每次访问丢失的键时都会不带参数地调用该函数。该函数必须返回字典中缺少的键应具有的默认值。这里我定义了一个钩子,记录每次键丢失的情况,并返回 0 作为默认值:
def log_missing():
print("Key added")
return 0给定一个初始字典和一组所需的增量值后,我便可使 log_missing 函数运行并打印两次(分别针对 "红色" 和 "橙色"):
from collections import defaultdict
current = {"green": 12, "blue": 3}
increments = [
("red", 5),
("blue", 17),
("orange", 9),
]
result = defaultdict(log_missing, current)
print("Before:", dict(result))
for key, amount in increments:
result[key] += amount
print("After: ", dict(result))
>>>
Before: {'green': 12, 'blue': 3}
Key added
Key added
After: {'green': 12, 'blue': 20, 'red': 5, 'orange': 9}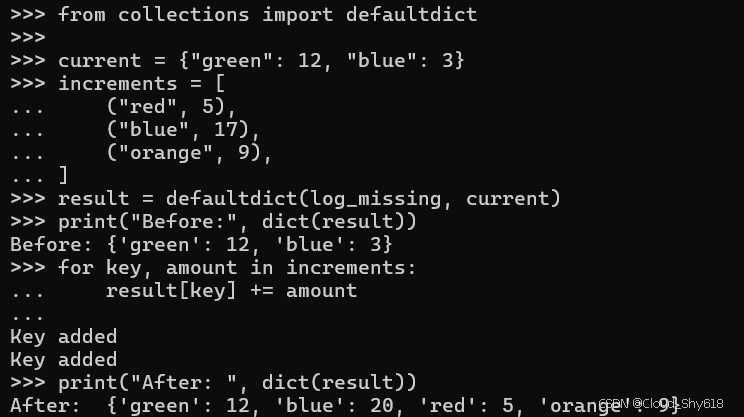
启用诸如 log_missingto 这样的功能有助于 API 将副作用与确定性行为区分开来。例如,假设我现在希望将默认值钩子传递给 defaultdict 以统计缺失键的总数。实现这一目标的一种方法是使用具有状态特性的闭包(详情请参阅 Item 33:"了解闭包与变量作用域及 nonlocal 的交互方式")。在此处,我定义了一个辅助函数,该函数使用此类闭包作为默认值钩子:
def increment_with_report(current, increments):
added_count = 0
def missing():
nonlocal added_count # Stateful closure
added_count += 1
return 0
result = defaultdict(missing, current)
for key, amount in increments:
result[key] += amount
return result, added_count运行此函数会得出预期结果(2),尽管默认字典实例并不知道缺失钩子会在 added_count 闭包变量中维护状态:
result, count = increment_with_report(current, increments)
assert count == 2为状态式钩子定义闭包的问题在于,它比无状态函数示例更难理解。另一种方法是定义一个小型类,该类可以封装你想要追踪的状态:
class CountMissing:
def __init__(self):
self.added = 0
def missing(self):
self.added += 1
return 0在其他语言中,你或许会认为现在需要对 defaultdict 进行修改,以适应 CountMissing 的接口。但在 Python 中,得益于 first-class 函数的特性,你可以直接在对象上引用 CountMissing.missing 方法,并将其作为默认值挂钩传递给 defaultdict 。让一个对象实例的方法满足函数接口的操作可谓轻而易举:
counter = CountMissing()
result = defaultdict(counter.missing, current) # Method ref
for key, amount in increments:
result[key] += amount
assert counter.added == 2使用此辅助类来展现状态性闭包的行为,要比如上所述使用 increment_with_report 函数更加清晰明了。然而,单独来看,我们仍难以立即明确理解 CountMissing 类的用途。谁会创建 CountMissing 对象?谁会调用 missing 方法?未来是否还需要添加其他公共方法到该类中?只有在看到其与 defaultdict 的结合使用时,我们才能对该类有更清晰的认识。
为了阐明这一情况,Python 类可以定义 __call__ 特殊方法。__call__ 允许对象被像调用函数一样进行调用。它还会使可调用内置函数针对此类实例返回 True,就像对待普通函数或方法一样。所有能够以这种方式执行的对象均被称为可调用对象:
class BetterCountMissing:
def __init__(self):
self.added = 0
def __call__(self):
self.added += 1
return 0
counter = BetterCountMissing()
assert counter() == 0
assert callable(counter)在此处,我使用 BetterCountMissing 作为 defaultdict 的默认值钩子,用于追踪已添加的缺失键的数量:
counter = BetterCountMissing()
result = defaultdict(counter, current) # Relies on __call__
for key, amount in increments:
result[key] += amount
assert counter.added == 2
这与 CountMissing.missing 相比要清晰得多。__call__ 方法表明,一个类的实例将在某些地方被使用,而函数参数也可能会在此处派上用场(例如 API 钩子)。它引导代码的新读者关注负责该类主要行为的入口点。这有力地暗示了该类的目标在于充当一个具有状态特性的闭包。
最棒的是,当您使用 __call__ 方法时,默认字典(defaultdict)仍无法洞悉其中的运作情况。默认字典所要求的只是为默认值挂钩提供一个可调用对象。Python 提供了多种不同的方式来实现一个简单的函数接口,您可以根据自身需求选择最合适的一种。
注意:
- 在 Python 中,你通常无需定义和实例化类,而是可以直接使用函数来实现组件之间的简单接口。
- 在 Python 中,对函数和方法的引用属于第一类,这意味着它们可以像其他任何类型一样被用于表达式中。
__call__特殊方法使类实例能够像普通 Python 函数一样被调用,并顺利通过可调用性检查。- 当您需要一种函数来维护状态时,请考虑定义一个提供
__call__方法的对象类,而非实现一个具有状态的闭包函数。
Item 49:优先使用面向对象的多态而非带有 isinstance 检查的函数
想象一下,我想要开发一款袖珍计算器,它能接收简单的公式作为输入并计算出结果。为实现这一目标,我通常会先将所提供的文本进行分词和解析,并创建一个抽象语法树(AST)来表示需要执行的运算,这与 Python 编译器在加载程序时所做的操作类似。例如,这里我定义了三类 AST 对象,用于处理两个整数的加法和乘法运算:
class Integer:
def __init__(self, value):
self.value = value
class Add:
def __init__(self, left, right):
self.left = left
self.right = right
class Multiply:
def __init__(self, left, right):
self.left = left
self.right = right对于像 2 + 9 这样的基础方程式,我可以通过直接实例化对象来生成 AST(绕过词法分析和解析过程)
tree = Add(
Integer(2),
Integer(9),
)可以使用递归函数来计算 AST,如下所示。对于可能遇到的每种类型的操作,我需要向一个复合 if 语句添加另一个分支。我可以使用 isinstance 内置函数根据正在评估的 AST 对象的类型来指导控制流(请参阅 Item 9:"在流程控制中考虑 match 解构;避免使用 if 语句就足够了",了解执行此操作的另一种方法):
def evaluate(node):
if isinstance(node, Integer):
return node.value
elif isinstance(node, Add):
return evaluate(node.left) + evaluate(node.right)
elif isinstance(node, Multiply):
return evaluate(node.left) * evaluate(node.right)
else:
raise NotImplementedError事实上,这种解释 AST 的方法(通常称为树行走)的效果符合预期:
print(evaluate(tree))
>>>
11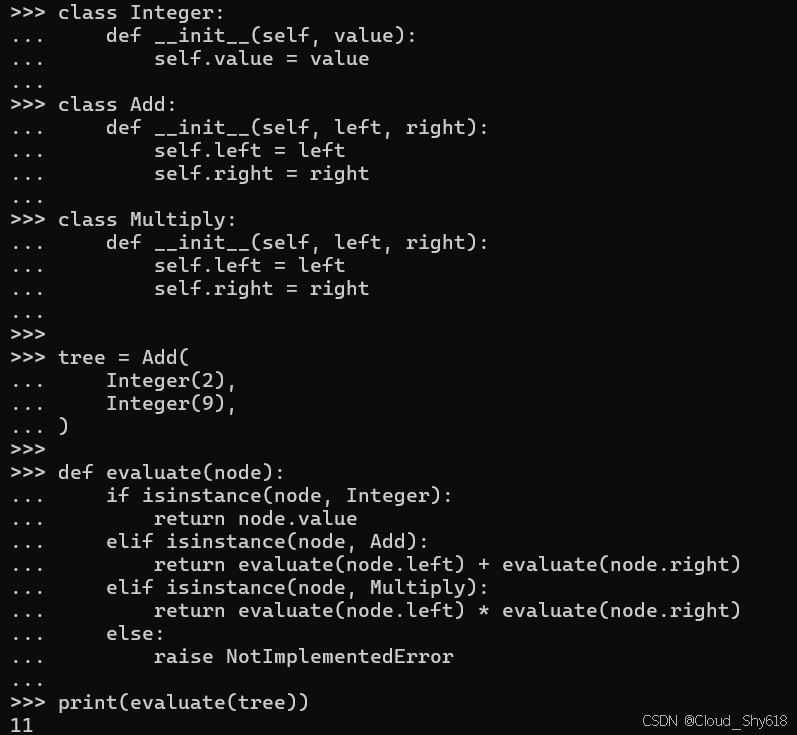
通过为每种类型的节点调用相同的 evaluate 函数,系统可以支持任意嵌套,而不会增加复杂性。例如,这里我为方程 (3 + 5) * (4 + 7) 定义了一个AST 并对其求值,而无需进行任何其他代码更改:
tree = Multiply(
Add(Integer(3), Integer(5)),
Add(Integer(4), Integer(7)),
)
print(evaluate(tree))
>>>
88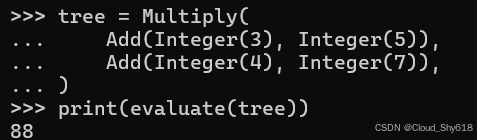
现在,想象一下我需要在树中考虑的节点数量明显多于三个。我需要处理减法、除法、对数等等。数学具有巨大的表面积,可能有数百种节点类型。如果我需要在这个 evaluate 函数中完成所有事情,那么它会变得非常长。即使我添加辅助函数并在 elif 块内调用它们,整个 if compound 语句也会很大。因此,一定有更好的方法。
解决这个问题的一种常见方法是面向对象编程(OOP)。您无需使用一个函数为所有类型的对象执行所有操作,而是将每种类型的功能封装在其数据旁边(在方法中)。然后,您依靠多态在运行时动态地将方法调用分派给正确的子类实现。这与 if compound 语句和 isinstance 检查具有相同的效果,但其方式不需要在一个巨大的函数中定义所有内容。
对于这个袖珍计算器示例,使用 OOP 将从定义一个超类(参见 Item 53:"使用 super 初始化父类"了解背景)开始,其方法在 AST 中的所有对象中应该是通用的:
class Node:
def evaluate(self):
raise NotImplementedError每种类型的节点都需要实现评估方法来计算与对象中包含的数据相对应的结果。这里我为整数定义了这个方法:
class IntegerNode(Node):
def __init__(self, value):
self.value = value
def evaluate(self):
return self.value下面的是加法和乘法运算的 evaluate 的实现:
class AddNode(Node):
def __init__(self, left, right):
self.left = left
self.right = right
def evaluate(self):
left = self.left.evaluate()
right = self.right.evaluate()
return left + right
class MultiplyNode(Node):
def __init__(self, left, right):
self.left = left
self.right = right
def evaluate(self):
left = self.left.evaluate()
right = self.right.evaluate()
return left * right和以前一样,创建表示 AST 的对象很简单,但这次我可以直接调用树对象上的 evaluate 方法,而不必使用单独的辅助函数:
tree = MultiplyNode(
AddNode(IntegerNode(3), IntegerNode(5)),
AddNode(IntegerNode(4), IntegerNode(7)),
)
print(tree.evaluate())
>>>
88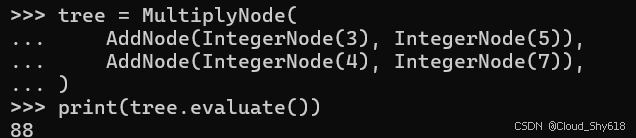
其工作方式是,对 tree.evaluate 的调用将使用树实例调用 MultiplyNode.evaluate 方法。然后,将为左节点调用 AddNode.evaluate 方法,该方法又为值 3 和 5 调用 IntegerNode.evaluate。之后,为右节点调用 AddNode.evaluate 方法,该方法类似地为值 4 和 7 调用 IntegerNode.evaluate。至关重要的是,为每个 Node 子类调用哪个评估方法实现的所有决定都在运行时发生。这是面向对象多态的主要好处。
稍后,我可能需要扩展袖珍计算器以提供更多功能。例如,我可以添加计算器打印输入的公式的功能,但格式一致且易于阅读。使用 OOP,我可以通过向超类添加另一个抽象方法并在每个子类中实现它来实现这一点。在这里,我为这个新目标添加了 pretty 方法:
class NodeAlt:
def evaluate(self):
raise NotImplementedError
def pretty(self):
raise NotImplementedError整数的实现非常简单:
class IntegerNodeAlt(NodeAlt):
def __init__(self, value):
self.value = value
def evaluate(self):
return self.value
def pretty(self):
return repr(self.value)加法和乘法运算下降到其左右分支以产生格式化结果:
class AddNodeAlt(NodeAlt):
def __init__(self, left, right):
self.left = left
self.right = right
def evaluate(self):
left = self.left.evaluate()
right = self.right.evaluate()
return left + right
def pretty(self):
left_str = self.left.pretty()
right_str = self.right.pretty()
return f"({left_str} + {right_str})"
class MultiplyNodeAlt(NodeAlt):
def __init__(self, left, right):
self.left = left
self.right = right
def evaluate(self):
left = self.left.evaluate()
right = self.right.evaluate()
return left + right
def pretty(self):
left_str = self.left.pretty()
right_str = self.right.pretty()
return f"({left_str} * {right_str})"与上面的 evaluate 方法非常相似,我可以在树根上调用 pretty 方法,以便将整个 AST 格式化为字符串:
tree = MultiplyNodeAlt(
AddNodeAlt(IntegerNodeAlt(3), IntegerNodeAlt(5)),
AddNodeAlt(IntegerNodeAlt(4), IntegerNodeAlt(7)),
)
print(tree.pretty())
>>>
((3 + 5) * (4 + 7))
使用 OOP,您可以随着程序需求的增长添加越来越多的 AST 方法和子类。没有必要通过数十次 isinstance 检查来维护一个庞大的函数。每种类型都可以有自己独立的实现,这使得代码相对容易组织、扩展和测试。Python 还提供了许多附加功能,使多态代码更有用(请参阅 Item 52:"使用 @class 方法多态性一般地构造对象"和 Item 57:"从 collections.abc 类继承自定义容器类型")。
然而,了解 OOP 在解决某些类型的问题时具有严重的局限性也很重要,尤其是在大型程序中(请参阅 Item 50:"考虑使用 functools.singledispatch 进行函数式编程而不是面向对象的多态")。
注意:
- Python 程序可以使用 isinstance 内置函数根据对象的类型改变运行时的行为。
- 多态性是一种面向对象编程 (OOP) 技术,用于在运行时将方法调用分派给最具体的子类实现。
- 在许多类之间使用多态而不是 isinstance 检查的代码可以更容易阅读、维护、扩展和测试。
Item 50:考虑使用 functools.singledispatch 进行函数式编程而不是面向对象的多态性
在 Item 49 的袖珍计算器示例中,展示了面向对象的编程 (OOP) 如何能够更轻松地根据对象的类型来改变行为。 最后,得到了具有不同方法实现的类的层次结构,如下所示:
class NodeAlt:
def evaluate(self):
raise NotImplementedError
def pretty(self):
raise NotImplementedError
class IntegerNodeAlt(NodeAlt):
def __init__(self, value):
self.value = value
def evaluate(self):
return self.value
def pretty(self):
return repr(self.value)
class AddNodeAlt(NodeAlt):
...
class MultiplyNodeAlt(NodeAlt):
...这使得可以在代表要执行的计算的抽象语法树(AST)的根上调用递归方法 evaluate 和 pretty:
tree = MultiplyNodeAlt(
AddNodeAlt(IntegerNodeAlt(3), IntegerNodeAlt(5)),
AddNodeAlt(IntegerNodeAlt(4), IntegerNodeAlt(7)),
)
print(tree.evaluate())
print(tree.pretty())
>>>
((3 + 5) * (4 + 7))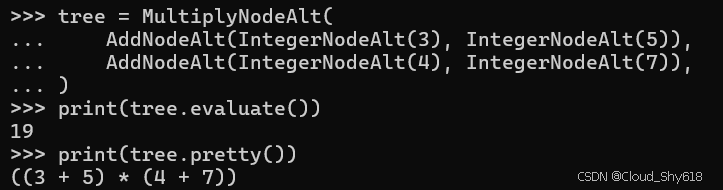
现在,想象一下超类需要 25 个方法,而不是 2 个: 一种方法可以简化方程;一种方法可以简化方程;另一个会检查未定义的变量;还有一个可以计算导数;还有一个会产生 LaTeX 语法;等等。在典型的 OOP 方法中,我会向每个包含节点类型数据的类添加 25 个新方法。这将使类定义变得非常大,特别是考虑到可能需要的所有辅助函数和支持数据结构。对于如此多的代码,我希望将这些节点类定义拆分到多个模块(例如,每个节点类型一个文件)以改进代码组织:
class NodeAlt2:
def evaluate(self):
...
def pretty(self):
...
def solve(self):
...
def error_check(self):
...
def derivative(self):
...
# And 20 more methods...不幸的是,这种类型的按类模块的代码组织可能会在生产系统中导致严重的可维护性问题。关键问题是,所有 25 种新方法实际上可能彼此完全不同,尽管它们在某种程度上与袖珍计算器有关。当您编辑和调试代码时,您需要的视图位于每个较大的独立系统内(例如,求解、错误检查),但使用 OOP 时,这些系统必须在所有类中实现。 这意味着在实践中,对于这个假设的示例,OOP 方法可能会导致您在 25 个不同的文件之间跳转,以完成简单的编程任务。该代码似乎是沿着错误的轴组织的。您几乎永远不需要同时查看单个类的两个独立系统,但这就是源文件的布局方式。
更糟糕的是,OOP 代码组织还混淆了依赖关系。对于此示例,LaTeX 生成方法可能需要导入本机库来处理该格式,公式求解方法可能需要重量级符号数学模块,等等。 如果您的代码组织是以类为中心的,则意味着定义类的每个模块都需要导入所有方法的所有依赖项(有关信息,请参阅 Item 98:"使用动态导入来延迟加载模块以减少启动时间")。这会阻止您创建独立的、精心设计的功能系统,从而妨碍可扩展性、重构和可测试性。幸运的是,OOP 并不是唯一的选择。
Single dispatch
Single dispatch 是一种函数式编程技术,程序根据其中一个参数的类型决定调用函数的哪个版本。它的行为类似于多态,但它也可以避免 OOP 的许多陷阱。您可以从本质上使用 single dispatch 向类添加方法,而无需修改它。为此,Python 在 functools 内置模块中提供了 singledispatch 装饰器。
要使用 singledispatch,首先我需要定义执行调度的函数。这里我创建了一个用于自定义对象打印的函数:
import functools
@functools.singledispatch
def my_print(value):
raise NotImplementedError如果对于第一个参数(值)的类型没有找到更好的选项,则将调用该函数的初始版本作为最后的手段。我可以通过使用调度函数的 register 方法作为装饰器来专门实现特定类型。这里我添加了 int 和 float 内置类型的实现:
@my_print.register(int)
def _(value):
print("Integer!", value)
@my_print.register(float)
def _(value):
print("Float!", value)这些函数使用下划线(_)来表示它们的名称无关紧要,并且不会被直接调用;所有调度都将通过 my_print 函数进行。在这里,我展示了这对于我迄今为止注册的类型的工作原理:
my_print(20)
my_print(1.23)
>>>
Integer! 20
Float! 1.23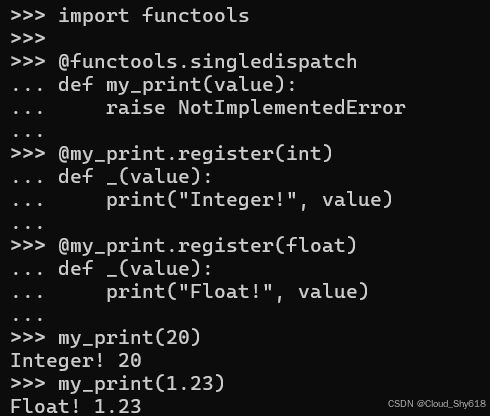
回到袖珍计算器的例子,我可以使用 singledispatch 来实现 evaluate 功能,而无需 OOP。首先,我定义一个新的调度函数:
@functools.singledispatch
def my_evaluate(node):
raise NotImplementedError然后,我为简单整数数据结构添加特定于类型的实现:
class Integer:
def __init__(self, value):
self.value = value
@my_evaluate.register(Integer)
def _(node):
return node.value我为简单的操作数据结构提供了类似的实现。请注意,没有一个数据结构定义任何附加方法:
class Add:
def __init__(self, left, right):
self.left = left
self.right = right
@my_evaluate.register(Add)
def _(node):
left = my_evaluate(node.left)
right = my_evaluate(node.right)
return left + right
class Multiply:
def __init__(self, left, right):
self.left = left
self.right = right
@my_evaluate.register(Multiply)
def _(node):
left = my_evaluate(node.left)
right = my_evaluate(node.right)
return left * right当我调用 my_evaluate 时,这些函数按预期工作:
tree = Multiply(
Add(Integer(3), Integer(5)),
Add(Integer(4), Integer(7)),
)
result = my_evaluate(tree)
print(result)
>>>
88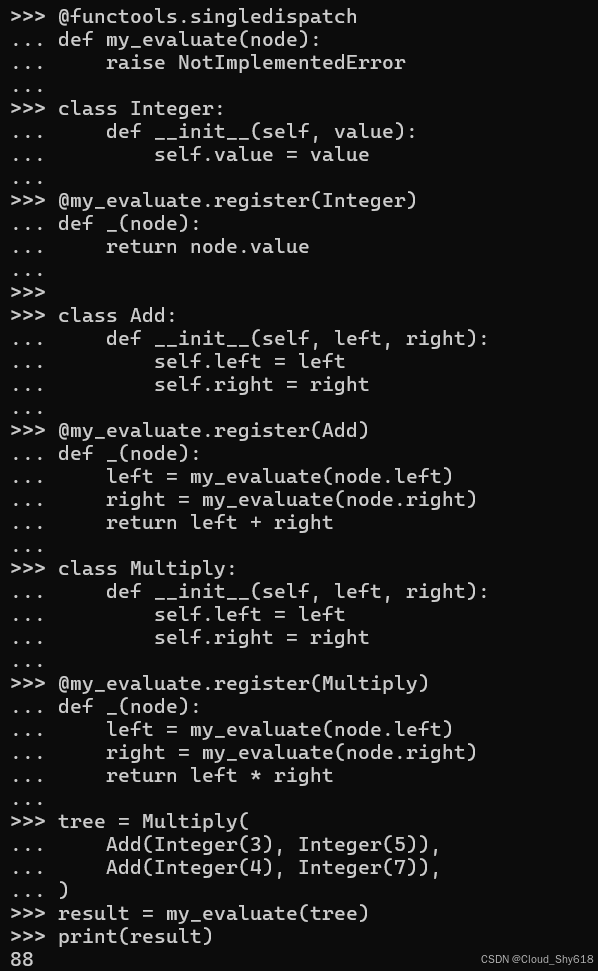
现在,假设我想要实现等式漂亮打印,如 Item 49 中所示,但不使用 OOP。我可以简单地通过定义另一个 singledispatch 函数并为我想要处理的每种类型装饰实现函数来实现此目的:
@functools.singledispatch
def my_pretty(node):
raise NotImplementedError
@my_pretty.register(Integer)
def _(node):
return repr(node.value)
@my_pretty.register(Add)
def _(node):
left_str = my_pretty(node.left)
right_str = my_pretty(node.right)
return f"({left_str} + {right_str})"
@my_pretty.register(Multiply)
def _(node):
left_str = my_pretty(node.left)
right_str = my_pretty(node.right)
return f"({left_str} * {right_str})"再次强调,这在不使用 OOP 的情况下按预期工作:
print(my_pretty(tree))
>>>
((3 + 5) * (4 + 7))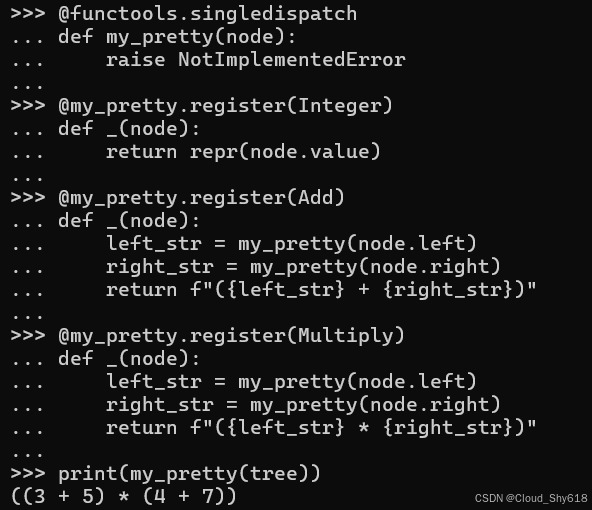
如果我创建一个新类型,它是我已经注册的类型的子类,它将立即与 my_pretty 一起使用,而无需进行额外的代码更改,因为它遵循方法解析顺序,如继承(请参阅 Item 53:"使用 super 初始化父类")。例如,在这里我添加了 Integer 类型的子类并表明它可以漂亮地打印:
class PositiveInteger(Integer):
pass
print(my_pretty(PositiveInteger(1234)))
>>>
1234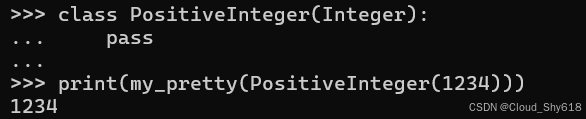
当我创建一个新类时,single dispatch 的困难就出现了。例如,使用新类型的对象调用 my_pretty 函数将引发 NotImplementedError 异常,因为没有注册实现来处理新类型:
class Float:
def __init__(self, value):
self.value = value
print(my_pretty(Float(5.678)))
>>>
Traceback ...
NotImplementedError 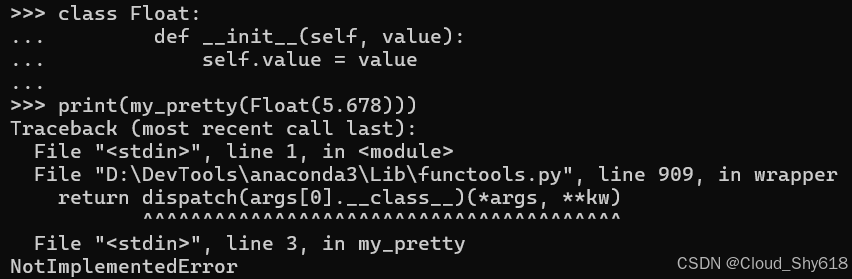
这是使用函数式 single dispatch 的基本权衡:当您向代码中添加新类型时,您需要为您想要支持的每个分派函数添加相应的实现。这可能需要修改程序中的许多或所有独立模块。相比之下,使用面向对象的多态,添加新类似乎更容易------只需实现所需的方法------但向系统添加新方法需要更新每个类。尽管这两种方法都存在一些摩擦,但在我看来,single dispatch 的负担较低,而且好处很多。
通过 single dispatch,您可以在程序中拥有数千个数据结构和数百个行为,而不会用方法污染类定义。这允许您在完全独立的模块中创建独立的行为系统,彼此之间没有相互依赖关系,也没有一组狭窄的外部依赖关系。简单的数据结构可以位于程序依赖树的底部,并在整个代码库中共享,而无需高耦合。使用像这样的 single dispatch 方法可以在正确的轴上组织代码:所有相关行为都在一起,而不是分散在 OOP 类所在的无数模块中。最终,这使得维护、调试、扩展、重构和测试代码变得更加容易。也就是说,当您的类共享通用功能并且较大的系统互连程度更高时,OOP 仍然是一个不错的选择。
这些代码结构之间的选择取决于程序组件的独立程度以及它们共享多少公共数据或行为。您还可以将 OOP 和 single dispatch 混合在一起,以受益于两种风格的最佳属性。例如,您可以将实用程序方法添加到所有独立系统中通用的简单类中。
注意:
- 面向对象的编程导致以类为中心的代码组织,这使得构建和维护大型程序变得困难,因为行为分布在许多模块中。
- Single dispatch 是使用函数而不是方法多态实现动态调度的另一种方法,使得可以在源代码中将相关功能更紧密地结合在一起。
- Python functools 内置模块有一个 singledispatch 装饰器,可用于实现单次调度行为。
- 具有在相同底层数据上运行的高度独立系统的程序可能会受益于 single dispatch 而不是 OOP 的功能风格。