
📣读完这篇文章里你能收获到
- 📁 看懂为什么 PDF 解析是 RAG 知识库的第一道命门
- 🐍 跑通 OpenDataLoader PDF 的最小安装和解析 Demo
- 🌐 理清 local 模式、hybrid 模式和 LangChain 接入方式
- 🖥️ 学会用 Benchmark 数据判断 PDF 解析工具是否适合你的项目
- 🔧 避开表格、阅读顺序、溯源坐标这几个高频坑点
文章目录
- 前言
- [一、RAG 为什么经常死在 PDF 解析上](#一、RAG 为什么经常死在 PDF 解析上)
-
- [1.1 三个最常见的翻车点](#1.1 三个最常见的翻车点)
- [1.2 OpenDataLoader 的思路](#1.2 OpenDataLoader 的思路)
- [二、OpenDataLoader 到底强在哪](#二、OpenDataLoader 到底强在哪)
-
- [2.1 Benchmark 数据怎么理解](#2.1 Benchmark 数据怎么理解)
- [2.2 local 和 hybrid 怎么选](#2.2 local 和 hybrid 怎么选)
- [2.3 和常见工具的差异](#2.3 和常见工具的差异)
- [三、从安装到 LangChain 接入](#三、从安装到 LangChain 接入)
-
- [3.1 安装 OpenDataLoader PDF](#3.1 安装 OpenDataLoader PDF)
- [3.2 最小解析 Demo](#3.2 最小解析 Demo)
- [3.3 LangChain 接入思路](#3.3 LangChain 接入思路)
- [四、落地时最容易忽略的 5 个细节](#四、落地时最容易忽略的 5 个细节)
-
- [4.1 不要只看解析出来的 Markdown 好不好看](#4.1 不要只看解析出来的 Markdown 好不好看)
- [4.2 先做小样本评估,再批量导入](#4.2 先做小样本评估,再批量导入)
- [4.3 表格不要随便切碎](#4.3 表格不要随便切碎)
- [4.4 坐标信息要进 metadata](#4.4 坐标信息要进 metadata)
- [4.5 不是所有 PDF 都值得进知识库](#4.5 不是所有 PDF 都值得进知识库)
- 总结
前言
做 RAG 知识库的时候,很多人第一反应是:模型换强一点、向量库换高级一点、Embedding 再调一调。
但真跑过项目的人都知道,最先把你绊倒的往往不是模型,而是 PDF。
一份财报、论文、合同或者产品手册丢进去,表格变乱码,双栏论文顺序乱飞,页眉页脚混进正文,图片里的文字直接消失。最后向量库里塞进去的不是「知识」,而是一堆半残的数据。模型再聪明,也只能基于这些脏数据一本正经地胡说八道。
这次要聊的 OpenDataLoader PDF,就是专门冲着这个入口问题来的:开源、本地优先、无需 GPU,能把 PDF 转成 Markdown、JSON、HTML,并且 JSON 里带 bounding box 坐标,方便后续做答案溯源。官方 Benchmark 里,OpenDataLoader hybrid 综合分 0.907,表格提取 0.928,本地模式速度可以到 0.015 秒/页。
这篇文章不打算空喊「很强」,我们直接从 RAG 为什么卡在 PDF、OpenDataLoader 到底强在哪、怎么跑起来、什么时候该选它这几件事讲清楚。
一、RAG 为什么经常死在 PDF 解析上
很多知识库效果差,看起来像是模型回答不行,实际往前倒一层,问题通常出在数据入口。
PDF 不是天然结构化文档。它更像一张排版结果图:文字块在哪里、表格边界在哪里、两栏文章先读左边还是右边,这些信息对人眼很明显,但对程序不一定明显。
1.1 三个最常见的翻车点
第一个是阅读顺序错。
典型场景是双栏论文。人眼知道先读左栏,再读右栏,但普通解析器可能按坐标从上到下扫,结果左栏第一段后面接右栏第一段,再接左栏第二段。这样的文本切块后进入向量库,召回结果自然会很飘。
第二个是表格结构丢失。
财报、实验数据、政府报告里经常有复杂表格。很多解析工具只能把单元格粗暴拼成文本,列名、行名、合并单元格关系都没了。后续问「2024 年第二季度净利润是多少」,模型可能连对应数字属于哪一列都判断不准。
第三个是无法溯源。
RAG 项目上线后,业务方最常问的一句话是:「这个答案从哪来的?」如果解析阶段没有保留页码、坐标、文本块位置,后面就很难做高可信引用。你只能告诉用户「根据文档」,但说不清具体在第几页第几块。

1.2 OpenDataLoader 的思路
OpenDataLoader PDF 的核心不是简单「把 PDF 变成文字」,而是把 PDF 变成适合 LLM 使用的结构化数据。
它提供几类关键输出:
text
Markdown:适合直接做 chunking 和向量化
JSON:带文本块、类型、页码和 bounding box 坐标
HTML:保留一定排版结构,方便预览或二次处理
Tagged PDF / PDF/UA:面向无障碍合规场景这里最值得关注的是 JSON 坐标。对 RAG 来说,它意味着你可以把「答案片段」映射回原 PDF 的具体位置。后续做引用高亮、原文定位、审计追踪,都会轻松很多。
二、OpenDataLoader 到底强在哪
判断一个 PDF 解析工具,不建议只看「能不能转 Markdown」。真正落到 RAG 项目里,至少要看四个维度:阅读顺序、表格结构、标题层级、速度和成本。
2.1 Benchmark 数据怎么理解
OpenDataLoader 官方 Benchmark 使用 200 份真实 PDF,包含多栏排版、科研论文、财务报告等场景,评估项包括:
text
Reading Order:文本阅读顺序是否正确
Table Fidelity:表格结构是否被准确还原
Heading Hierarchy:标题层级是否保留
Speed:完整解析耗时,单位秒/页公开结果里,OpenDataLoader hybrid 的综合分是 0.907,阅读顺序 0.934,表格 0.928,标题 0.821,速度 0.463 秒/页。local 模式综合分 0.831,速度 0.015 秒/页。
这个差异很好理解:local 模式更快、更确定、更适合批量跑普通文档;hybrid 模式会在复杂页面上引入 AI 增强,准确率更高,但速度会慢一些。
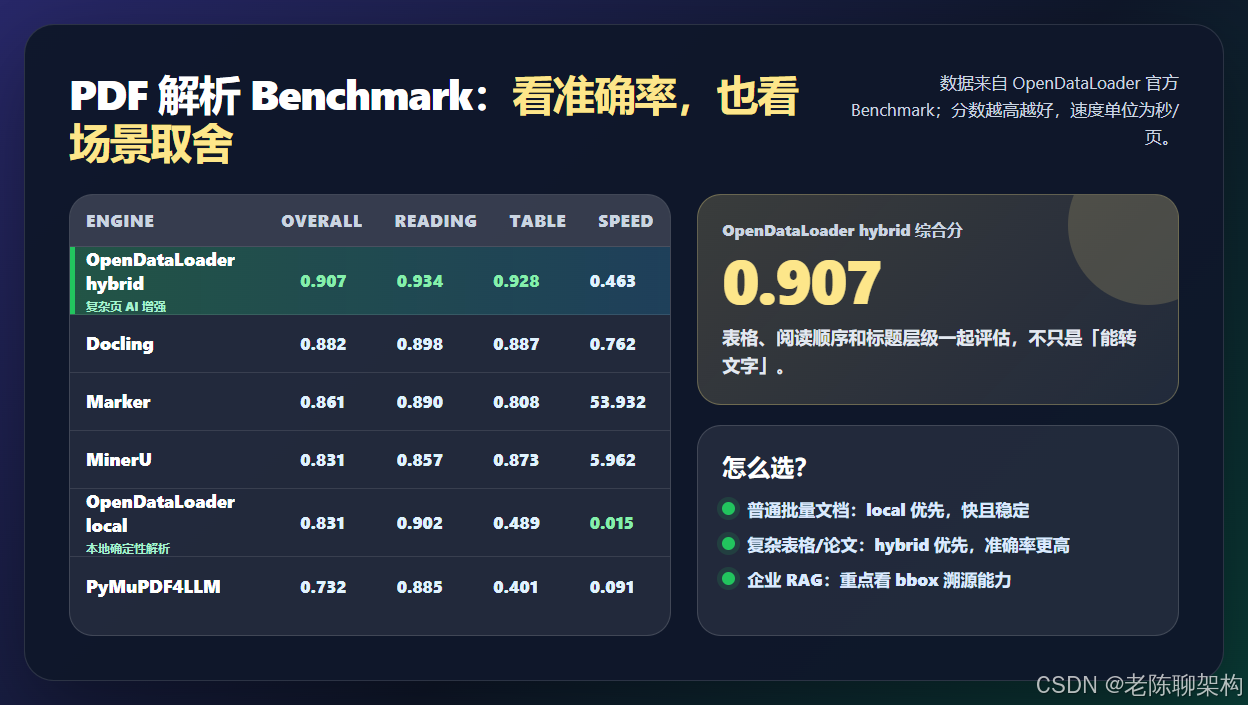
2.2 local 和 hybrid 怎么选
我建议用一个很朴素的原则:
普通 PDF、批量导入、对成本敏感,优先 local。
论文、财报、扫描件、复杂表格、公式密集文档,再考虑 hybrid。
local 模式最大的优势是确定性强。相同输入多次解析,输出稳定,不容易出现 LLM 式随机波动。对于企业知识库,这一点很重要,因为你希望数据管道可复现,而不是今天跑一版,明天又变一版。
hybrid 模式适合处理更难啃的页面,比如跨页表格、低质量扫描、公式和图表较多的论文。它不是拿 AI 替代所有解析,而是把 AI 用在复杂区域增强识别,这比全程大模型解析更容易控制成本。
2.3 和常见工具的差异
如果你之前用过 Docling、Marker、Unstructured、PyMuPDF4LLM 这类工具,可以这样理解:
OpenDataLoader 的亮点在于「RAG 入口」这个定位更集中。
它不是只做文本抽取,也不是只做漂亮 Markdown,而是把 reading order、table、bounding box、LangChain 集成、本地运行这几件事一起考虑了。尤其 bounding box 对可溯源问答很关键,这点在企业场景里非常加分。
当然,它也不是所有场景都无脑替代。比如你只处理纯文本 PDF,PyMuPDF4LLM 这类轻量方案可能已经够用;如果你已经在 IBM Docling 生态里做了深度集成,也没必要为了追新全部推翻。
技术选型最怕的是「看到一个高分工具就全量迁移」。更稳的方式是拿自己的 20~50 份代表性 PDF 做小样本评估,看表格、标题、顺序和召回效果有没有实际提升。
三、从安装到 LangChain 接入
下面给一个最小可运行路径。以下示例以 Python 环境为主,适合先在本地验证效果。
3.1 安装 OpenDataLoader PDF
先准备 Python 环境,建议使用虚拟环境:
bash
python -m venv .venv
.venv\Scripts\activate
pip install opendataloader-pdf如果你要接 LangChain,可以额外安装集成包:
bash
pip install langchain-opendataloader-pdf注意:不同版本的 API 可能会有细节变化,实际项目里建议以官方文档和当前包版本为准。文章里的代码更适合作为「验证路径」。
3.2 最小解析 Demo
一个常见目标是把 PDF 转成 Markdown,后续直接做切块:
python
from opendataloader_pdf import OpenDataLoaderPDF
loader = OpenDataLoaderPDF()
result = loader.load("demo.pdf", output_format="markdown")
with open("demo.md", "w", encoding="utf-8") as f:
f.write(result)如果你更关注溯源,建议输出 JSON:
python
from opendataloader_pdf import OpenDataLoaderPDF
import json
loader = OpenDataLoaderPDF()
result = loader.load("demo.pdf", output_format="json")
with open("demo.json", "w", encoding="utf-8") as f:
json.dump(result, f, ensure_ascii=False, indent=2)JSON 里重点看页码、元素类型、文本内容和 bounding box 坐标。后面你可以把这些元信息写入向量库 metadata,在回答时把引用位置带出来。
3.3 LangChain 接入思路
如果你的 RAG 管道已经用 LangChain,可以用官方 loader 思路接入:
python
from langchain_opendataloader_pdf import OpenDataLoaderPDFLoader
loader = OpenDataLoaderPDFLoader(
file_path="demo.pdf",
format="markdown"
)
documents = loader.load()
for doc in documents[:3]:
print(doc.page_content[:300])
print(doc.metadata)接下来就和普通文档一样,进入切块、Embedding、写入向量库流程:
python
from langchain_text_splitters import RecursiveCharacterTextSplitter
splitter = RecursiveCharacterTextSplitter(
chunk_size=800,
chunk_overlap=120
)
chunks = splitter.split_documents(documents)这一步别急着追求 chunk_size 的「标准答案」。PDF 类型不同,切块策略差很多。财报更依赖表格完整性,论文更依赖章节结构,合同更依赖条款边界。先保结构,再调参数。

四、落地时最容易忽略的 5 个细节
工具强不强是一回事,能不能把它放进稳定流程里,是另一回事。
4.1 不要只看解析出来的 Markdown 好不好看
Markdown 好看不代表 RAG 效果一定好。
你真正要检查的是:标题层级是否合理、表格是否能被模型理解、段落顺序是否符合人类阅读逻辑、metadata 是否足够做追踪。尤其是企业知识库,后续经常要回查原文,坐标和页码比「排版漂亮」更重要。
4.2 先做小样本评估,再批量导入
建议准备一组代表性文件:
text
5 份普通说明书
5 份多栏论文
5 份财务/统计表格
5 份扫描件或图片型 PDF
5 份业务合同/制度文档每类跑一遍 local,再选复杂样本跑 hybrid。对比召回结果、答案引用、表格问答准确率,再决定是否迁移。
4.3 表格不要随便切碎
很多 RAG 项目效果差,是因为把表格按字符数硬切开了。
如果解析结果已经保留表格结构,就尽量让一个表格作为完整块进入向量库,或者把表头和关键行一起保留。否则模型只召回一半表格,回答时很容易张冠李戴。
4.4 坐标信息要进 metadata
如果你计划做「答案可溯源」,不要在切块时把页码、坐标、元素 ID 丢了。
推荐 metadata 至少包含:
json
{
"source": "demo.pdf",
"page": 3,
"element_type": "table",
"bbox": [72, 120, 510, 380]
}后面前端要做原文高亮,或者回答里展示「来源:第 3 页表格」,这些信息都靠 metadata。
4.5 不是所有 PDF 都值得进知识库
这句话有点扎心,但很真实。
如果原文质量极差,比如扫描模糊、页码混乱、表格截图压缩严重,再强的解析器也只能救一部分。对高价值文档,可以加人工抽检;对低价值历史文档,没必要为了追求 100% 完美把成本拉爆。
总结
OpenDataLoader PDF 真正打动我的点,不是「又一个 PDF 转 Markdown 工具」,而是它把 RAG 数据入口里几个最痛的点放在了一起解决:阅读顺序、表格结构、坐标溯源、本地运行、LangChain 接入。
如果你的知识库主要处理 PDF,尤其是论文、财报、合同、制度、手册这类复杂文档,它值得单独拉出来做一次评估。
我的建议是:
text
先用 local 模式跑一批普通文档,看速度和基础结构;
再用 hybrid 模式处理复杂样本,看表格和阅读顺序提升;
最后把页码、bbox、元素类型写进 metadata,别只保存纯文本。到这一步,你的 RAG 不一定马上变成「无敌知识库」,但至少不会再被 PDF 入口拖得满地找牙。
先把数据入口打通,再谈模型调优,这个顺序真的别反了。
