在高可用分布式系统架构设计时,可以通过冗余部署、消息队列消峰等手段来提供系统高可用性,这些方法本质上都是在于提供系统抗压能力。而限流的核心思想时从入口处进行流量控制,从而减少对系统压力。
限流算法的核心目标就是,统计单位时间内的流量,并加以约束。
以下均以1秒100QPS的需求进行限流说明
固定窗口算法(计数器)
这种算法是最简单、最易落地的限流算法,其核心逻辑围绕"时间切片"展开,无需复杂的数据结构,仅通过简单的计数和时间判断,就能实现基础的流量控制。
该算法本质上就是对于单位时间内,流量数量的计算。例如:
将时间划分为固定长度的"窗口"(例如1秒、1分钟),每个窗口内维护一个请求计数器。当请求到达时,判断当前窗口的计数器是否超过预设阈值:若未超过,则计数器加1,允许请求通过;若已超过,则直接拒绝请求。当窗口结束(进入下一个时间切片),计数器清零,重新开始计数。
public class Counter {
// 固定窗口大小ms
private int windowSize;
// 固定容量 100
private int windowCount;
// 初始时间
private Long startTime;
// 当前请求数量
private AtomicInteger currentCount;
public Counter(int windowSize, int windowCount) {
this.windowSize = windowSize;
this.windowCount = windowCount;
this.startTime = System.*currentTimeMillis*();
this.currentCount = new AtomicInteger(0);
}
public void allowPass(){
// 清理旧窗口容量,并更新时间,DCL,避免不必要竞争
if(System.*currentTimeMillis*() - startTime > windowSize){
synchronized (this) {
if(System.*currentTimeMillis*() - startTime > windowSize){
currentCount.set(0);
startTime = System.*currentTimeMillis*();
}
}
}
// 保障原子性
int count = currentCount.incrementAndGet();
if(count <= windowCount){
// 自增
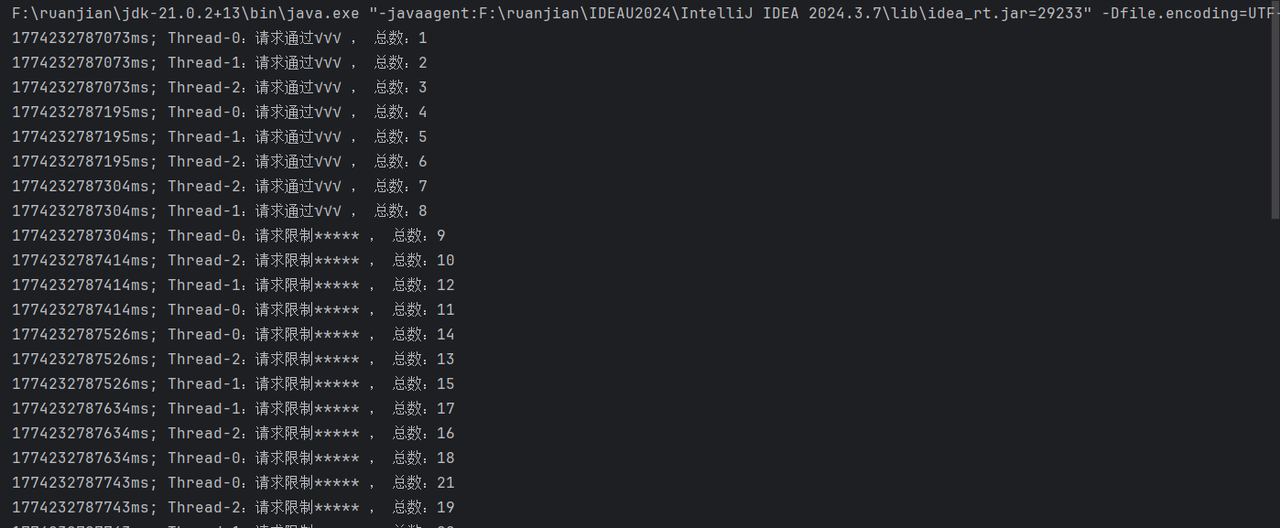
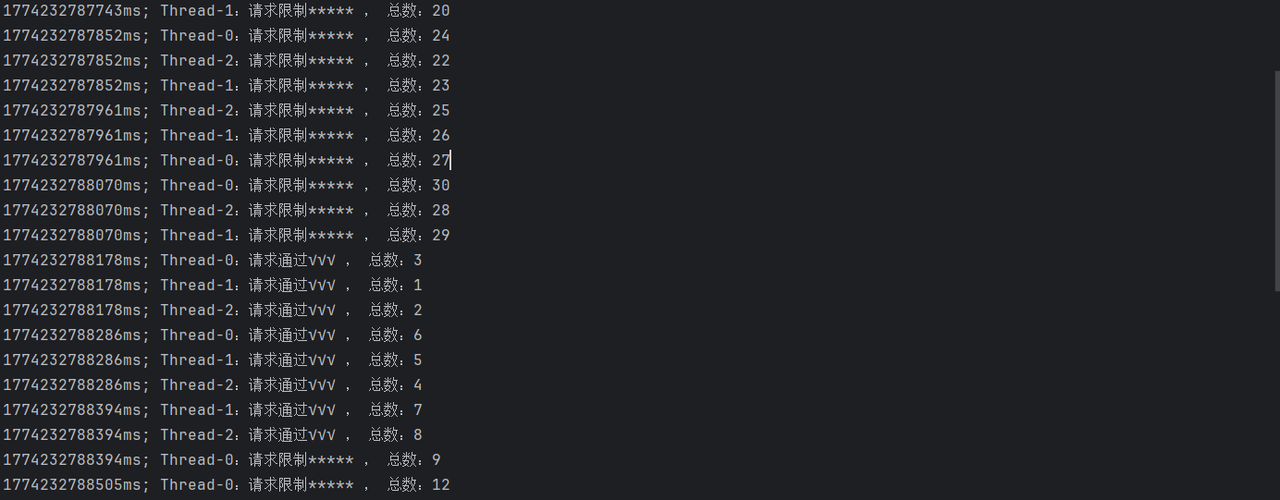
System.*out*.println((System.*currentTimeMillis*()) + "ms; "+Thread.*currentThread*().getName() + ":请求通过√√√ , 总数:" + currentCount.get());
}else{
System.*out*.println((System.*currentTimeMillis*()) + "ms; "+Thread.*currentThread*().getName() + ":请求限制***** , 总数:" + currentCount.get());
}
}
public static void main(String[] args) throws InterruptedException {
// 设定每秒8QPS限制
Counter counter = new Counter(1000, 8);
for (int i = 0; i < 3; i++) {
new Thread(new Runnable() {
@Override
public void run() {
while(true){
counter.allowPass();
try {
Thread.*sleep*(100);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}
}).start();
}
}
}
优点:落地简单
缺点:存在临界值问题
这个问题核心为两个方面:
- 无法保障任意一个1s内的请求量均为10以内。
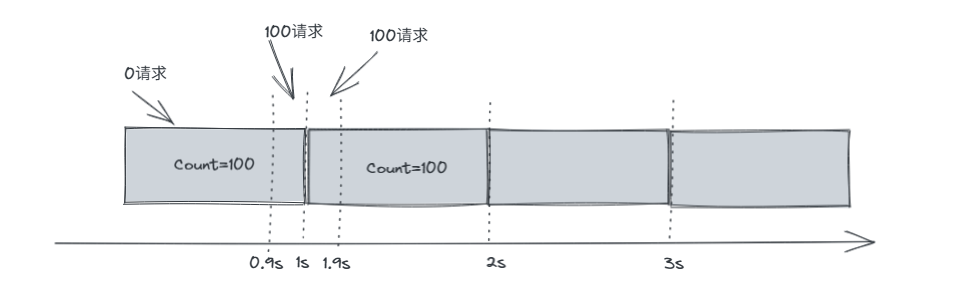
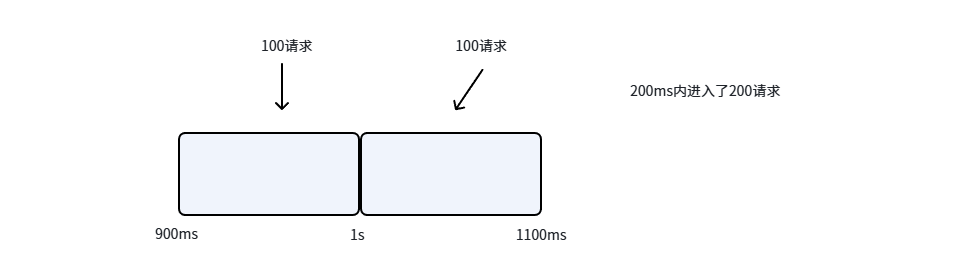
例如我们规定了每1秒可以通过的请求量为100,但是如果0~0.9秒时,没有请求,而在0.9~1秒时,进来了100请求,从算法上我们是由允许的。而在之后的1秒~1.1秒又进来了100请求,1.1~2秒为0请求。
在这种情况下,从算法层面来说时允许的,但是我们发现在0.9s~1.1秒之间进来了200请求,这相当于1000QPS,这种不平滑的"临界"情况,可能瞬间将系统打垮。
- 无法避免流量突刺情况
即使我们可以控制任意1秒内的请求量为1000,但是它整体并不是平滑分布了,例如仅在某1个10ms内涌进来1000请求,这种瞬发流量也会导致服务奔溃。
使用场景
固定窗口计数器算法因其简单性,适合用于"非核心、低并发、对限流精度要求低"的场景,典型案例如下:
-
后台管理系统接口限流:后台管理系统用户量少、请求频率低,且多为人工操作,无需高精度限流。例如,限制"用户查询接口"1秒内最多10次请求,避免人为误操作(如频繁刷新)导致的无效压力,使用固定窗口算法即可满足需求,无需复杂实现。
-
第三方接口调用兜底限流:调用外部第三方接口时,若第三方未提供限流机制,可在本地用固定窗口算法做兜底。例如,调用第三方短信接口,限制1分钟内最多发送50条,避免因业务异常导致短信发送量暴增,产生额外费用。
滑动窗口算法
滑动窗口算法 是基于计数器算法 的改良核心就是通过**"细粒度时间切片 + 滑动统计"**,解决了固定窗口算法的"临界区"问题:
注意:滑动窗口是 "统计型限流",不是 "平滑型限流",它管的是一段时间总量,不管单位时间内的请求分布是否均匀,所以必然存在瞬时突刺。
- 首先通过滑动窗口形式,解决任意1s内1000请求量的限制(控制临界值问题)
这个窗口可以理解为,固定时间窗口内的请求量数据,随着时间的推移,窗口内容旧时间的数据清除,加入新时间的数据,整体保证容量不变。
例如定义一个窗口大小为1s,容量为1000的窗口,来记录每个请求进来的时间戳。随着时间的推移,旧时间戳的请求会被清理
这样就能确保任意1s内,不会超过1000QPS,控制了"临界值问题"
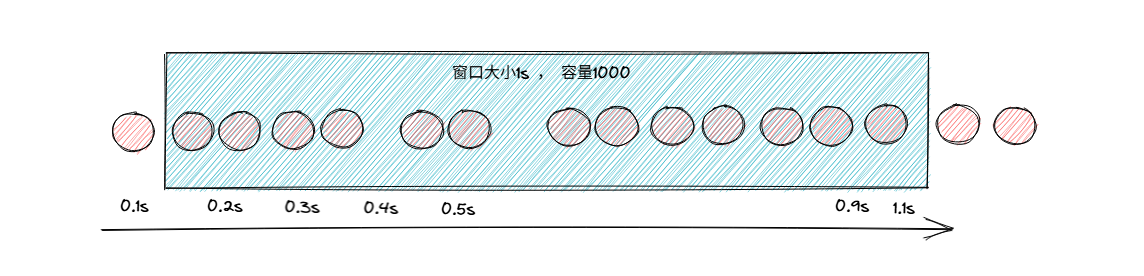
但是这种方式虽然保证了任意1s的请求限制,但是也没有避免某一时刻的流量问题,例如在0~0.9秒内没有请求,在0.9秒这时进来了1000请求,这也是不允许的。因此还需要加当前算法中,加入更小的窗口,来解决"流量突刺"问题。大
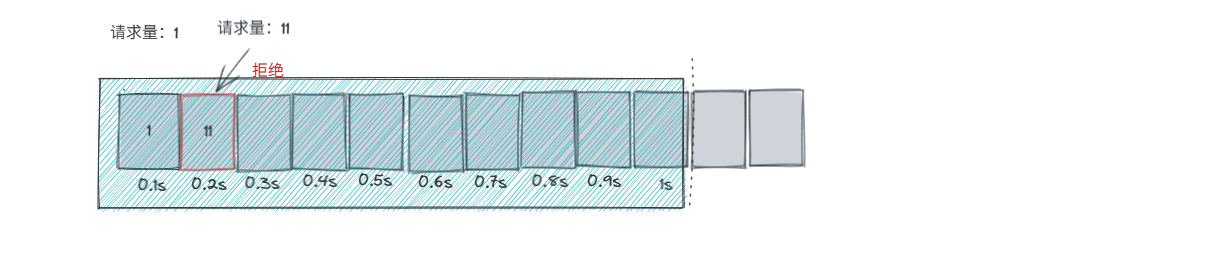
- 小窗口,实现更精准的流量统计,更细粒度控制突刺问题,但无法彻底解决
通俗的说,就是再定义小窗口用于统计和约束每100ms的流量约束
总结:大滑动窗口用于约束每秒请求量,避免边界问题,小滑动窗口用于约束更细粒度的请求,减少和控制流量突刺。
也是Sentinel、Hystrix等主流限流框架的默认算法之一。
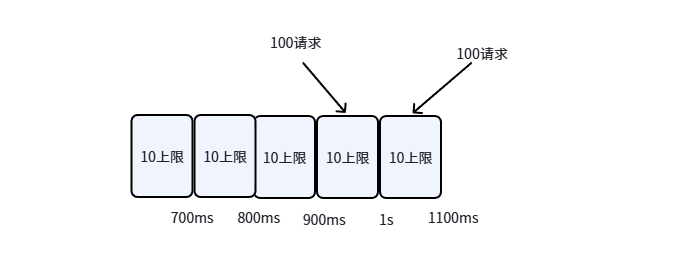
例如:大窗口1秒,拆分为10个100毫秒小窗口,阈值100QPS。0~100ms接收10个请求,100~200ms接收10个请求......以此类推,任意连续10个小窗口(即1秒)的请求总数不超过100。即使在临界区(如0.9~1.1秒),也只会统计最近1秒的请求,避免突刺。
-
小窗口控制 ,即每100ms内,只能进来10个请求以内,否则直接拒绝。
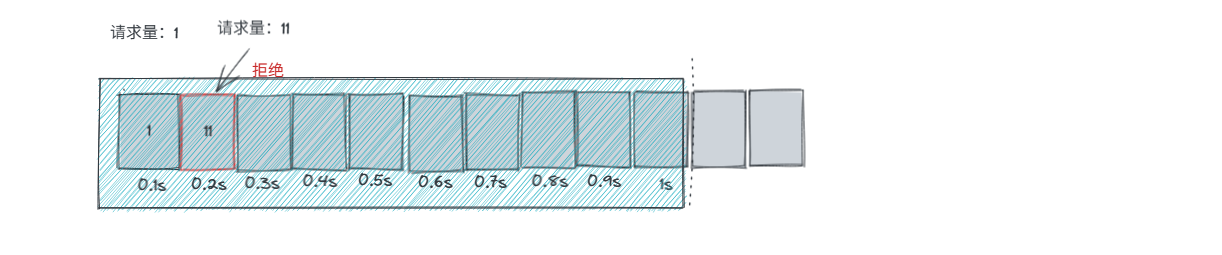
-
大窗口等于小窗口的请求和
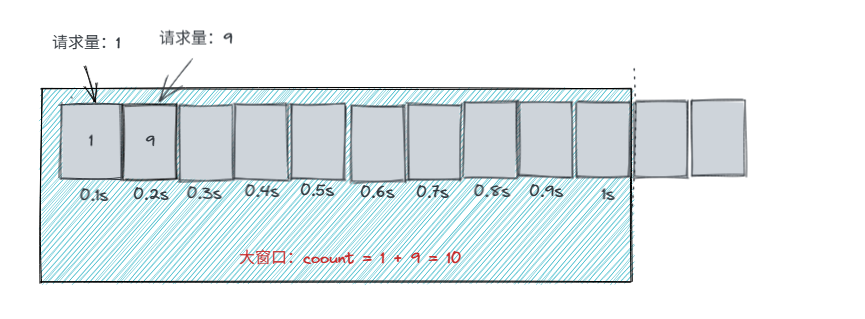
- 大窗口滑动:当时间来到了1.1s时,大窗口会向后滑动,count会减去滑出的小窗口数量
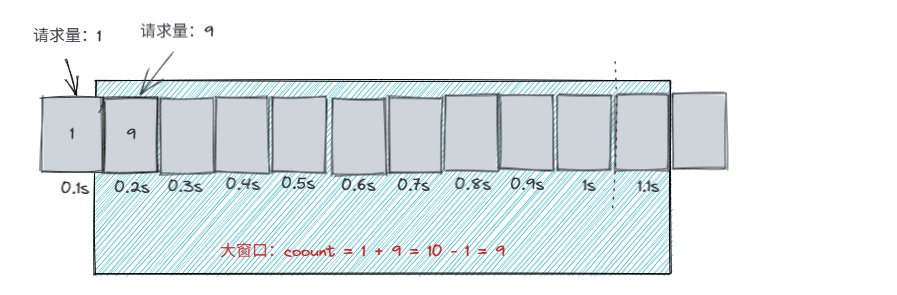
如何解决"临界区"问题
假如还是在0.9~1s中时,进来100请求,此时是允许的。
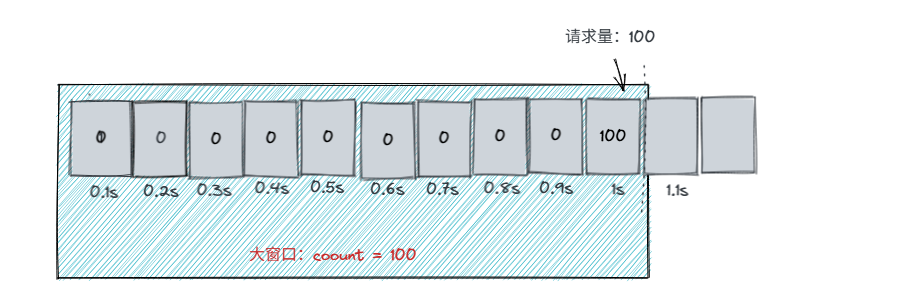
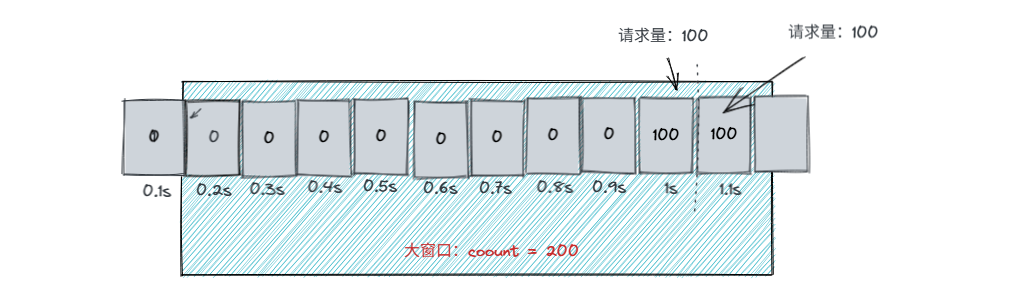
但是在1.1秒时,在此进入100请求时,并不会通过,而是拒绝,因为大窗口滑动后,减去0.1s的请求量后,count仍然为100,因此1.1s进来100请求后,总数为200,达到了限流条件。因此只有到将0.9s的100请求滑出之后才能允许请的请求通过。
滑动窗口具体实现算法有多种
基于Deque版本
**原理:**记录每个请求的时间戳,每次到来时清理过期的请求。 双窗口:
大窗口:控制整体 1 秒请求量,解决固定窗口的边界叠加问题。
小窗口:控制短时间流量突刺(比如 100ms 内的请求),缓解瞬发洪峰。
特点:
按实际时间戳统计,统计精度高更加平滑,能缓解短时间突刺 ,但粒度受限于 小窗口大小 (比如 100ms)。但是每个请求都记录时间戳,容易造成内存占用大
package com.cmm.flowalgorithm.window;
import com.cmm.flowalgorithm.counter.Counter;
import java.util.ArrayDeque;
import java.util.Deque;
public class Window {
// 大窗口大小 1s
private int bigWindowSize;
// 大窗口容量 1000
private int bigWindowCount;
// 小窗口大小 100ms
private int smallWindowSize;
// 小窗口容量 100
private int smallWindowCount;
// 大滑动窗口
private Deque<Long> bigWindowQueue;
// 小滑动窗口
private Deque<Long> smallWindowQueue;
Window(int bigWindowSize, int bigWindowCount, int smallWindowSize, int smallWindowCount) {
this.bigWindowSize = bigWindowSize;
this.bigWindowCount = bigWindowCount;
this.smallWindowSize = smallWindowSize;
this.smallWindowCount = smallWindowCount;
this.bigWindowQueue = new ArrayDeque<>();
this.smallWindowQueue = new ArrayDeque<>();
}
public synchronized void allowPass() {
Long now = System.currentTimeMillis();
// 滑动清理,大窗口中的非最新1s的数据
while (true) {
Long bigPeek = bigWindowQueue.peekFirst();
if (bigPeek == null) {
break;
}
if (now - bigPeek <= bigWindowSize) {
break;
}
bigWindowQueue.pollFirst();
}
// 滑动清理,小窗口中的非最新100ms的数据
while (true) {
Long smallPeek = smallWindowQueue.peekFirst();
if (smallPeek == null) {
break;
}
if (now - smallPeek <= smallWindowSize) {
break;
}
smallWindowQueue.pollFirst();
}
if (bigWindowQueue.size() >= bigWindowCount) {
System.out.println((now) + "ms; " + Thread.currentThread().getName() + ":请求限制, 大窗口总数:" + bigWindowQueue.size());
return;
}
if (smallWindowQueue.size() >= smallWindowCount) {
System.out.println((now) + "ms; " + Thread.currentThread().getName() + ":请求限制,小窗口总数:" + smallWindowQueue.size());
return;
}
bigWindowQueue.add(now);
smallWindowQueue.add(now);
System.out.println((now) + "ms; " + Thread.currentThread().getName() + ":请求通过,大窗口总数:" + bigWindowQueue.size());
}
public static void main(String[] args) throws InterruptedException {
// 设定每秒8QPS限制
Window window = new Window(1000, 8, 100, 2);
for (int i = 0; i < 3; i++) {
new Thread(new Runnable() {
@Override
public void run() {
while (true) {
window.allowPass();
try {
Thread.sleep(100);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}
}).start();
}
}
}此时出来的效果就是,平滑的
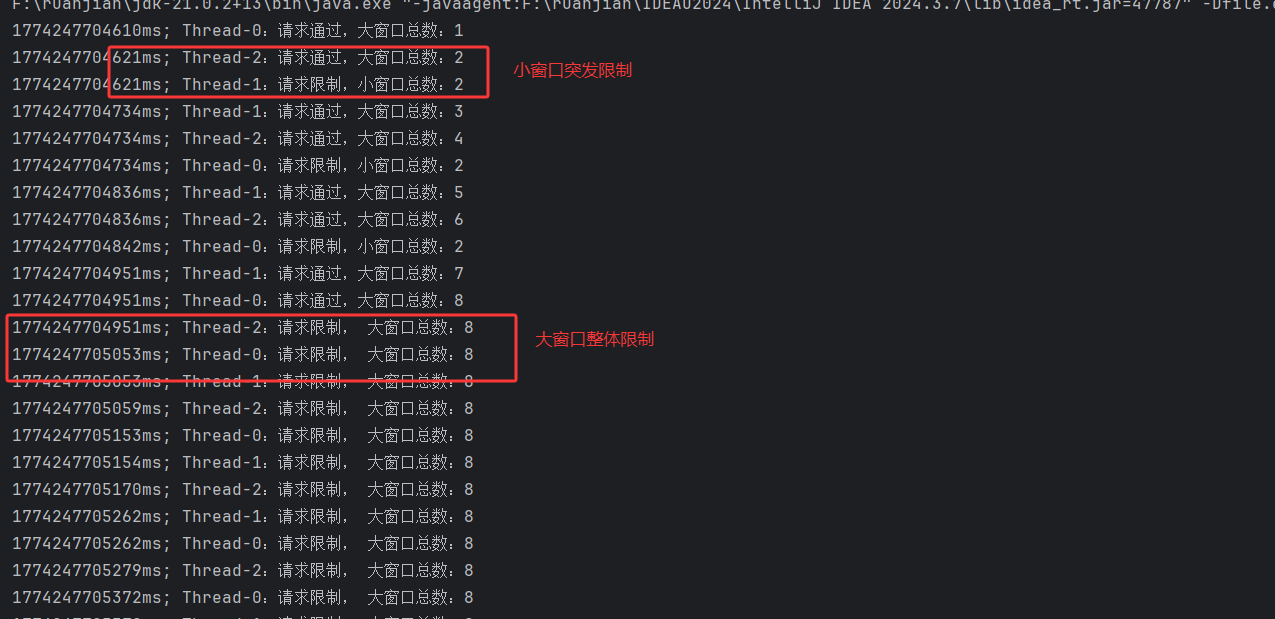
基于Bucket"桶"的版本
原理:
-
将 1 秒拆成若干个固定时间片(例如拆10 个,每个 100ms)。
-
每个桶记录该时间片内的请求数。
-
到来的请求落入对应的桶,通过取模计算 index。
-
过期的桶清零。
-
通过统计所有桶总量判断是否超过限制。
桶版本是滑动窗口的 优化实现,减少内存占用,提高性能,但仍然无法彻底消除瞬发洪峰问题
package com.cmm.flowalgorithm.window;
import java.util.ArrayDeque;
import java.util.Deque;
public class WindowBuckets {
// 大窗口容量 1000
private int bigWindowCount;
int[] buckets;
long[] times;
WindowBuckets(int bigWindowCount) {
this.bigWindowCount = bigWindowCount;
// 将1s的1000请求,拆分为10个捅,每个捅记录某段100ms的请求量
this.buckets = new int[10];
// 记录每个捅的时间戳
this.times = new long[10];
}
public synchronized void allowPass() {
Long now = System.currentTimeMillis();
// 计算当前请求时间,坐落在哪个捅,通过取模算法,得到
int index = (int) (( now / 100) % 10);
// 当前桶对应的时间戳
Long time = times[index];
// 如果该桶记录的时间已经超过1s,则代表该桶已经过期
if(now - time > 1000) {
buckets[index] = 0;
times[index] = now;
}
// 计算桶的总数
int total = 0;
for (int count : buckets) {
total += count;
}
if (total >= bigWindowCount) {
System.out.println((now) + "ms; " + Thread.currentThread().getName() + ":请求限制,大窗口总数:" + total);
return;
}
// 计算单个桶数据量
int oneBucket = buckets[index]++;
if(oneBucket > bigWindowCount/10) {
System.out.println((now) + "ms; " + Thread.currentThread().getName() + ":请求限制,当个桶总数======:" + oneBucket);
return;
}
System.out.println((now) + "ms; " + Thread.currentThread().getName() + ":请求通过,大窗口总数:" + total);
}
public static void main(String[] args) throws InterruptedException {
// 设定每秒100QPS限制
WindowBuckets window = new WindowBuckets( 20);
for (int i = 0; i < 3; i++) {
new Thread(new Runnable() {
@Override
public void run() {
while (true) {
window.allowPass();
try {
Thread.sleep(10);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}
}).start();
}
}
}总结
核心是"细粒度时间切片 + 滚动统计",通过将大窗口拆分,让流量统计从"粗粒度"变为"细粒度",实现"实时滚动、平滑统计"。其核心目标是"在简单实现的基础上,提升限流精度,解决临界区突刺问题",兼顾落地成本和限流效果。
相对于固定窗口算法,滑动窗口算法通过滑动滚动的方式,实现了任意时间范围内的请求量限制,有效削弱但无法彻底解决临界突刺问题。从原理上看,滑动窗口本质是把大时间窗口切分成更小粒度的分片窗口不断滑动统计,例如将 1 秒拆分为 10 个 100 毫秒的小窗口。它同样存在边界临界值叠加,但风险量级已经大幅收敛,不再像固定窗口那样难以接受。
- 固定窗口场景下,如果在 0.9 秒进来 100 请求,又在 1.1 秒进来 100 请求,短时间内就会形成接近 1000QPS 的瞬时击穿风险;
- 滑动窗口:而滑动窗口上限被分片限制为每 100 毫秒最多 10 请求,即便极限边界叠加,最多也只会在 200 毫秒内涌入 20 请求,约 200QPS,属于系统可容忍的毛刺压力。同时可以看出,分片切得越细,流量曲线越平滑、瞬时峰值越小,但只要仍然采用分段累加计数,就永远无法彻底消除相邻分片边界叠加带来的瞬发流量问题。
- 无论是什么方式,只要是计数器类型的计算方式,永远解决不了瞬发流量问题。
使用场景
滑动窗口算法因"精准、平滑、无突刺"的特点,是分布式架构中核心接口的首选,典型案例如下:
-
微服务核心接口限流:电商系统的"商品详情接口""下单接口",是高并发核心接口,要求限流精准且无毛刺。例如,用滑动窗口算法限制下单接口1秒1000QPS,避免瞬时流量突刺导致接口超时,这也是Sentinel默认采用该算法的核心原因。
-
API网关限流:Spring Cloud Gateway、Zuul等网关层,对所有入口请求进行统一限流。例如,网关层限制单个服务的入口流量1秒500QPS,使用滑动窗口算法保证流量统计精准,避免因网关限流不准导致后端服务压力过载。
秒杀活动基础限流:秒杀活动的预热阶段,用滑动窗口算法限制用户请求频率(如1秒10次请求),避免恶意刷单导致系统提前宕机,为后续峰值流量做铺垫。
漏桶算法
上面所介绍的两种算法都不能非常平滑的过渡,即无法解决瞬发流量问题,下面就是漏桶算法登场了。
什么是漏桶算法?
漏桶算法以一个常量限制了出口流量速率**(固定流出)** ,因此漏桶算法可以平滑处理突发的流量。其中漏桶作为流量容器我们可以看做一个FIFO的队列,当入口流量速率大于出口流量速率时,因为流量容器是有限的,当超出流量容器大小时,超出的流量会被丢弃。
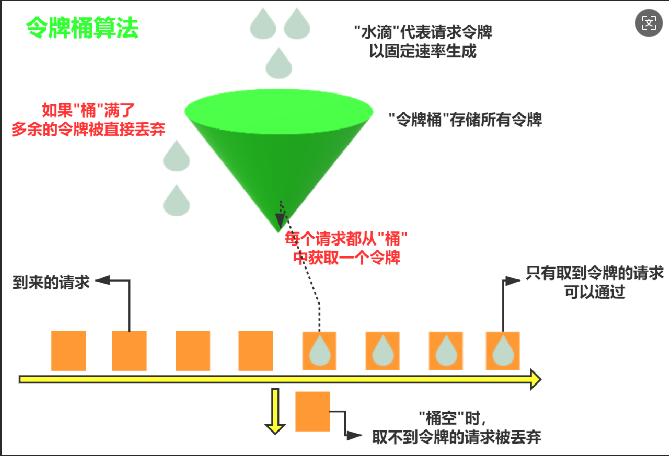
下图比较形象的说明了漏桶算法的原理,其中水龙头是入口流量,漏桶是流量容器,匀速流出的水是出口流量。

漏桶算法的特点(漏桶装的是流量,即请求)
-
漏桶具有固定容量,出口流量速率是固定常量(流出请求)
-
入口流量可以以任意速率流入到漏桶中(流入请求)
-
如果入口流量超出了桶的容量,则流入流量会溢出(新请求被拒绝)
import com.msb.sentinel.exception.BlockException;
import lombok.extern.slf4j.Slf4j;import javax.swing.;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.Objects;
import java.util.concurrent.;
import java.util.concurrent.locks.LockSupport;public class LeakyBucketRateLimit implements RateLimit, Runnable {
/** * 出口限制qps */ private Integer limitSecond; /** * 漏桶队列 */ private BlockingQueue<Thread> leakyBucket; private ScheduledExecutorService scheduledExecutorService; public LeakyBucketRateLimit(Integer bucketSize, Integer limitSecond) { this.limitSecond = limitSecond; this.leakyBucket = new LinkedBlockingDeque<>(bucketSize); scheduledExecutorService = Executors.newSingleThreadScheduledExecutor(); //1 秒=1000000000 纳秒 // 计算出一个请求需要多少纳秒 long interval = (1000 * 1000 * 1000) / limitSecond; scheduledExecutorService.scheduleAtFixedRate(this, 0, interval, TimeUnit.NANOSECONDS); } @Override public boolean canPass() throws BlockException { if (leakyBucket.remainingCapacity() == 0) { throw new BlockException(); } //如果立即可行且不违反容量限制,则将指定的元素插入此双端队列表示的队列中(即此双端队列的尾部), // 并在成功时返回 true;如果当前没有空间可用,则返回 false。 leakyBucket.offer(Thread.currentThread()); //所有请求进来,只要有容量,就会停止到这里 // 如果没有容量,就停止在上行代码 LockSupport.park(); return true; } @Override public void run() { // 以固定的速率去唤醒他,这样执行的速度就固定值 Thread thread = leakyBucket.poll(); if (Objects.nonNull(thread)) { LockSupport.unpark(thread); } }}
总结
核心是"削峰填谷、强制匀速",不允许流量突发,无论上游请求如何波动,下游系统始终收到匀速的请求。其设计初衷是"保护下游系统",避免下游因瞬时流量过大而宕机,适合下游系统处理能力固定、无法应对突发流量的场景。
使用场景
漏桶算法的核心价值是"强制匀速",适合下游系统脆弱、需要严格控速的场景,典型案例如下:
-
第三方接口调用限流:调用第三方支付接口、短信接口时,第三方通常会限制接口调用速率(如1秒50次),此时用漏桶算法强制本地请求匀速发送,避免因突发请求导致第三方接口限流,同时保护第三方系统。
-
数据库写入限流:数据库写入能力有限(如1秒最多写入100条数据),若上游业务突发大量写入请求,会导致数据库锁表、超时。用漏桶算法限制写入速率,将突发写入转化为匀速写入,保护数据库稳定。
-
消息队列生产者限流:当消息队列出现堆积时,用漏桶算法限制生产者发送消息的速率,避免堆积加剧,同时给消费者足够的时间处理消息,实现生产消费平衡。
令牌桶算法
令牌桶算法是漏桶算法的改进版,可以支持突发流量。不过与漏桶算法不同的是,令牌桶算法的漏桶中存放的是令牌而不是流量。
那么令牌桶算法是怎么突发流量的呢?
最开始,令牌桶是空的,我们以恒定速率往令牌桶里加入令牌,令牌桶被装满时,多余的令牌会被丢弃。当请求到来时,会先尝试从令牌桶获取令牌(相当于从令牌桶移除一个令牌),获取成功则请求被放行,获取失败则阻塞或拒绝请求。
这种算法的好处是,在空闲时候,令牌桶会匀速积攒令牌,在瞬发流量到来的时候,会从令牌桶中快速的取到令牌,从而实现高吞吐。
令牌桶算法的特点
-
最多可以存发b个令牌。如果令牌到达时令牌桶已经满了,那么这个令牌会被丢弃
-
每当一个请求过来时,就会尝试从桶里移除一个令牌,如果没有令牌的话,请求无法通过。
令牌桶算法限制的是平均流量,因此其允许突发流量(只要令牌桶中有令牌,就不会被限流)
import org.apache.commons.lang3.StringUtils;
import java.util.concurrent.*;
public class TokenBucketRateLimit implements RateLimit, Runnable {
/**
* token 生成 速率 (每秒)
*/
private Integer tokenLimitSecond;
/**
* 令牌桶队列
*/
private BlockingQueue<String /* token */> tokenBucket;
private static final String TOKEN = "__token__";
private ScheduledExecutorService scheduledExecutorService;
public TokenBucketRateLimit(Integer bucketSize, Integer tokenLimitSecond) {
this.tokenLimitSecond = tokenLimitSecond;
this.tokenBucket = new LinkedBlockingDeque<>(bucketSize);
scheduledExecutorService = Executors.newSingleThreadScheduledExecutor();
long interval = (1000 * 1000 * 1000) / tokenLimitSecond;
scheduledExecutorService.scheduleAtFixedRate(this, 0, interval, TimeUnit.NANOSECONDS);
}
@Override
public boolean canPass() throws BlockException {
String token = tokenBucket.poll();
if (StringUtils.isEmpty(token)) {
throw new BlockException();
}
return true;
}
@Override
public void run() {
if (tokenBucket.remainingCapacity() == 0) {
return;
}
tokenBucket.offer(TOKEN);
}
}总结
需要注意的是,令牌桶算法所谓支持瞬发,本质是支持可控高吞吐 。与滑动窗口不同,它的瞬时流量上限完全可配置锁定:通过调整桶容量,使用者能依据下游真实承载能力精确设定安全脉冲阈值。同时这类瞬发属于低概率短时脉冲,仅在令牌累积充足时才会出现;一旦令牌耗尽,流量立刻回归匀速补给节奏,长期严格受控。
而滑动窗口只能通过切分更多、更小的时间分片来被动削弱瞬时毛刺,无法精准锁定瞬时硬上限;并且分片越精细,统计计算、内存占用与 CAS 竞争损耗越高,存在明显性能取舍代价。
使用场景
令牌桶算法因"灵活、兼顾匀速和突发",是目前互联网架构的首选,典型案例如下:
-
API网关全局限流:Spring Cloud Gateway、Kong等网关,采用令牌桶算法对所有入口请求进行限流。例如,网关限制全局QPS为10000,允许合理的突发流量(如瞬时12000QPS),既保护后端服务,又能充分利用系统资源,是网关限流的标配。
-
电商秒杀峰值限流:秒杀活动的峰值阶段,用令牌桶算法限制请求速率(如1秒5000QPS),同时允许一定的突发流量(如瞬时6000QPS),既避免系统被击垮,又能最大化承接有效请求,提升秒杀成功率。
-
分布式限流场景:结合Redis实现分布式令牌桶限流,用于跨节点、跨服务的全局限流。例如,分布式订单系统,限制全集群下单QPS为2000,用Redis存储令牌桶状态,实现多节点统一限流,保证全局流量可控。
总结
在分布式高可用架构设计中,限流算法的选型核心是"匹配业务场景、平衡精度和成本",给出以下选型建议:
-
固定窗口计数器:非核心、低并发、对精度要求低的场景(如后台管理接口),优先选,成本最低。
-
滑动窗口计数器:核心微服务接口、对精度有要求的高并发场景(如商品详情、下单接口),Sentinel默认,首选。
-
漏桶算法:下游系统脆弱、需要强制匀速的场景(如第三方接口、数据库写入),重点保护下游。
-
令牌桶算法:API网关、需要容忍突发的高并发场景(如秒杀、全局限流),互联网架构首选,兼顾灵活和稳定。
最后需要强调:限流不是"一刀切",而是"按需适配"。在实际架构中,通常会结合多种限流手段(如接口级限流+网关限流+分布式限流),同时配合降级、熔断、冗余部署等方案,才能真正实现系统的高可用。