识别音频声音 ,转换不是很准
python
# encoding: utf-8
# 版权所有 2026 ©涂聚文有限公司™ ®
# 许可信息查看:言語成了邀功盡責的功臣,還需要行爲每日來值班嗎
# 描述:pip install moviepy SpeechRecognition pip install openai-whisper
# Author : geovindu,Geovin Du 涂聚文.
# IDE : PyCharm 2024.3.6 python 3.11
# os : windows 10
# database : mysql 9.0 sql server 2019, postgreSQL 17.0 Oracle 21c Neo4j
# Datetime : 2026/6/14 17:40
# User : geovindu
# Product : PyCharm
# Project : Pysimple
# File : MP4totextdest.py
import warnings
warnings.filterwarnings("ignore")
warnings.filterwarnings("ignore", category=RuntimeWarning)
from moviepy import VideoFileClip
import speech_recognition as sr
import os
import whisper
import numpy as np
import wave
import audioop
import whisper.audio
VIDEO_FILE = "20260614_102306.mp4"
TEMP_WAV = "temp_audio.wav"
OUTPUT_TXT = "完整演讲文稿_带时间戳.txt"
# 1. 提取视频音频
print("正在提取音频...")
video = VideoFileClip(VIDEO_FILE)
# 导出16位单声道标准wav,适配识别
video.audio.write_audiofile(TEMP_WAV, codec="pcm_s16le", fps=16000)
video.close()
# 2. 原生Python读取wav,彻底绕过ffmpeg
def load_audio_without_ffmpeg(path):
with wave.open(path, 'rb') as wav_file:
n_channels = wav_file.getnchannels()
width = wav_file.getsampwidth()
frames = wav_file.readframes(wav_file.getnframes())
# 双声道转单声道
if n_channels == 2:
frames = audioop.tomono(frames, width, 0.5, 0.5)
# 转浮点音频数组
audio_np = np.frombuffer(frames, dtype=np.int16).flatten().astype(np.float32) / 32768.0
return audio_np
# 覆盖whisper自带读取函数,不再调用ffmpeg
import whisper.audio
whisper.audio.load_audio = load_audio_without_ffmpeg
# 3. 加载最轻量模型 tiny(速度最快,中文演讲够用)
print("加载离线语音模型 tiny ...")
model = whisper.load_model("tiny")
# 4. 开始识别,开启分段时间戳
print("开始逐段识别演讲内容,请等待...")
result = model.transcribe(
audio=TEMP_WAV,
language="zh",
verbose=False,
word_timestamps=True
)
# 5. 格式化带时间戳文稿,实时打印每一段
full_content = "=== EV录屏 第十八届海峡论坛苏恒演讲 完整转写稿 ===\n\n"
print("\n====================识别结果====================")
for seg in result["segments"]:
start_min = int(seg["start"] // 60)
start_sec = int(seg["start"] % 60)
end_min = int(seg["end"] // 60)
end_sec = int(seg["end"] % 60)
seg_text = seg["text"].strip()
line = f"[{start_min:02d}:{start_sec:02d} - {end_min:02d}:{end_sec:02d}] {seg_text}"
print(line) # 实时控制台打印每一段文字
full_content += line + "\n"
# 6. 保存本地文本
with open(OUTPUT_TXT, "w", encoding="utf-8") as f:
f.write(full_content)
# 清理临时音频文件
os.remove(TEMP_WAV)
print(f"\n================================================")
print(f"✅ 全部识别完成!文稿已保存至:{OUTPUT_TXT}")
输出:
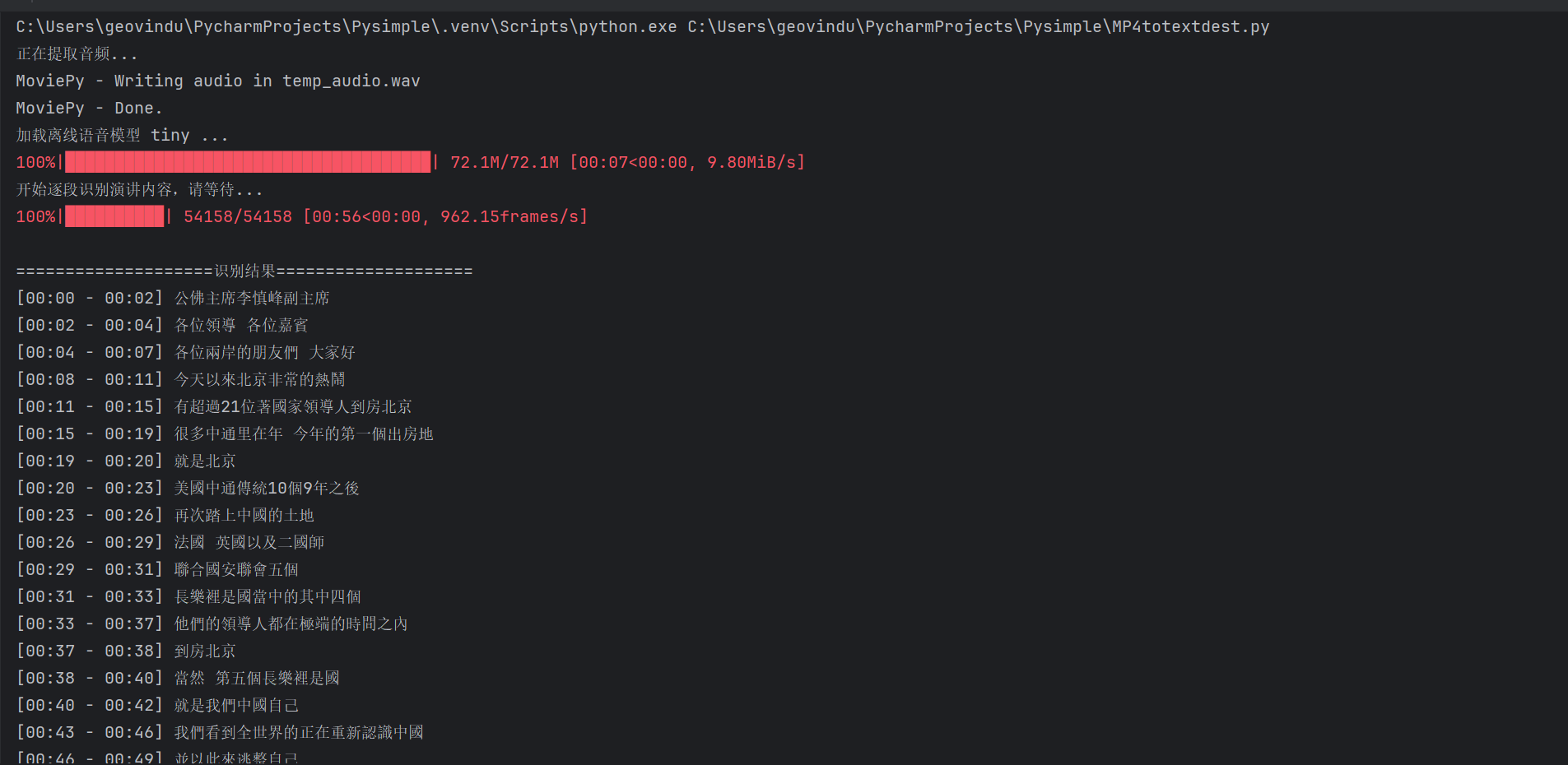
python
# 超高准确率版(适合演讲、新闻、正式发言)
model = whisper.load_model("medium")
python
# encoding: utf-8
# 版权所有 2026 ©涂聚文有限公司™ ®
# 许可信息查看:言語成了邀功盡責的功臣,還需要行爲每日來值班嗎
# 描述:pip install moviepy SpeechRecognition pip install openai-whisper
# Author : geovindu,Geovin Du 涂聚文.
# IDE : PyCharm 2024.3.6 python 3.11
# os : windows 10
# database : mysql 9.0 sql server 2019, postgreSQL 17.0 Oracle 21c Neo4j
# Datetime : 2026/6/14 17:40
# User : geovindu
# Product : PyCharm
# Project : Pysimple
# File : MP4totextdest.py
import warnings
warnings.filterwarnings("ignore")
warnings.filterwarnings("ignore", category=RuntimeWarning)
from moviepy import VideoFileClip
import speech_recognition as sr
import os
import whisper
import numpy as np
import wave
import audioop
import whisper.audio
VIDEO_FILE = "geovindu.mp4"
TEMP_WAV = "temp_audio.wav"
OUTPUT_TXT = "完整演讲文稿_带时间戳medium.txt"
# 1. 提取视频音频
print("正在提取音频...")
video = VideoFileClip(VIDEO_FILE)
# 导出16位单声道标准wav,适配识别
video.audio.write_audiofile(TEMP_WAV, codec="pcm_s16le", fps=16000)
video.close()
# 2. 原生Python读取wav,彻底绕过ffmpeg
def load_audio_without_ffmpeg(path):
with wave.open(path, 'rb') as wav_file:
n_channels = wav_file.getnchannels()
width = wav_file.getsampwidth()
frames = wav_file.readframes(wav_file.getnframes())
# 双声道转单声道
if n_channels == 2:
frames = audioop.tomono(frames, width, 0.5, 0.5)
# 转浮点音频数组
audio_np = np.frombuffer(frames, dtype=np.int16).flatten().astype(np.float32) / 32768.0
return audio_np
# 覆盖whisper自带读取函数,不再调用ffmpeg
import whisper.audio
whisper.audio.load_audio = load_audio_without_ffmpeg
# 3. 加载最轻量模型 tiny(速度最快,中文演讲够用)
print("加载离线语音模型 medium ...")
model = whisper.load_model("medium")
# 4. 开始识别,开启分段时间戳
print("开始逐段识别演讲内容,请等待...")
result = model.transcribe(
audio=TEMP_WAV,
language="zh",
verbose=False,
word_timestamps=True
)
# 5. 格式化带时间戳文稿,实时打印每一段
full_content = "=== EV录屏 2026年6月13日 第十八届海峡论坛苏恒演讲 完整转写稿 ===\n\n"
print("\n====================识别结果====================")
for seg in result["segments"]:
start_min = int(seg["start"] // 60)
start_sec = int(seg["start"] % 60)
end_min = int(seg["end"] // 60)
end_sec = int(seg["end"] % 60)
seg_text = seg["text"].strip()
line = f"[{start_min:02d}:{start_sec:02d} - {end_min:02d}:{end_sec:02d}] {seg_text}"
print(line) # 实时控制台打印每一段文字
full_content += line + "\n"
# 6. 保存本地文本
with open(OUTPUT_TXT, "w", encoding="utf-8") as f:
f.write(full_content)
# 清理临时音频文件
os.remove(TEMP_WAV)
print(f"\n================================================")
print(f"✅ 全部识别完成!文稿已保存至:{OUTPUT_TXT}")输出:
