开篇介绍:
hello 大家,那么在前面的学习中,我们成功的将信号这一座大山拿下,那随着我们学习完了信号,我们对于Linux系统部分的学习也就所剩不多,而接下来,摆在我们面前的就是Linux中的又一座大山------线程!!!线程是什么?它和进程有什么关系呢?我们往下看~
一、Linux 线程:进程内的 "轻量级执行单元"
1.1 什么是线程?------ 不止是 "执行路线",更是内核的 "调度最小单位"
线程(Thread)的官方定义是 "进程内部的控制序列",但要真正理解它,必须结合 Linux 内核的实现逻辑:Linux 中没有专门的 "线程结构体",线程本质是 "共享大部分资源的进程"------ 内核通过task_struct(进程控制块 PCB)来描述线程,只是这些task_struct会指向同一个虚拟地址空间、文件描述符表等核心资源。
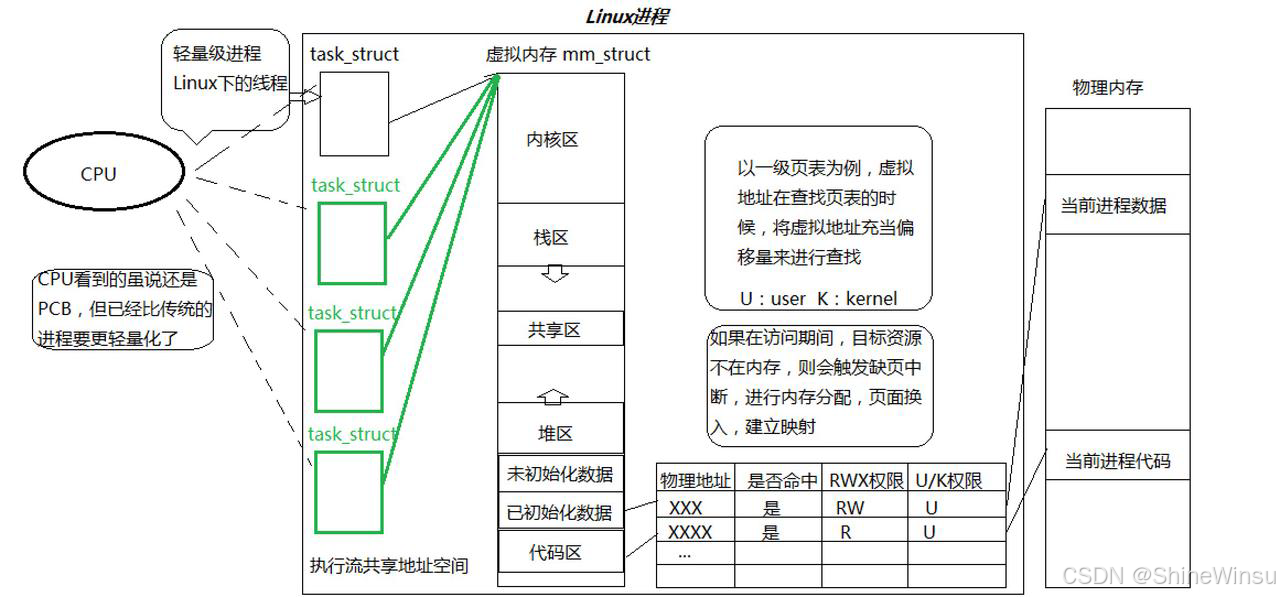
用更生动的类比:
- 进程是 "一家完整的公司":有独立的办公大楼(虚拟地址空间)、营业执照(进程 ID)、全套设备(文件描述符、内存资源);
- 线程是 "公司里的部门团队":共享公司的大楼、设备、资质,但有自己的工作任务(执行流)、负责人(线程 ID)、工作记录(寄存器上下文);
- 一个公司至少有一个部门(主线程),也可以有多个部门(多线程),每个部门协同完成公司的整体业务(进程任务)。
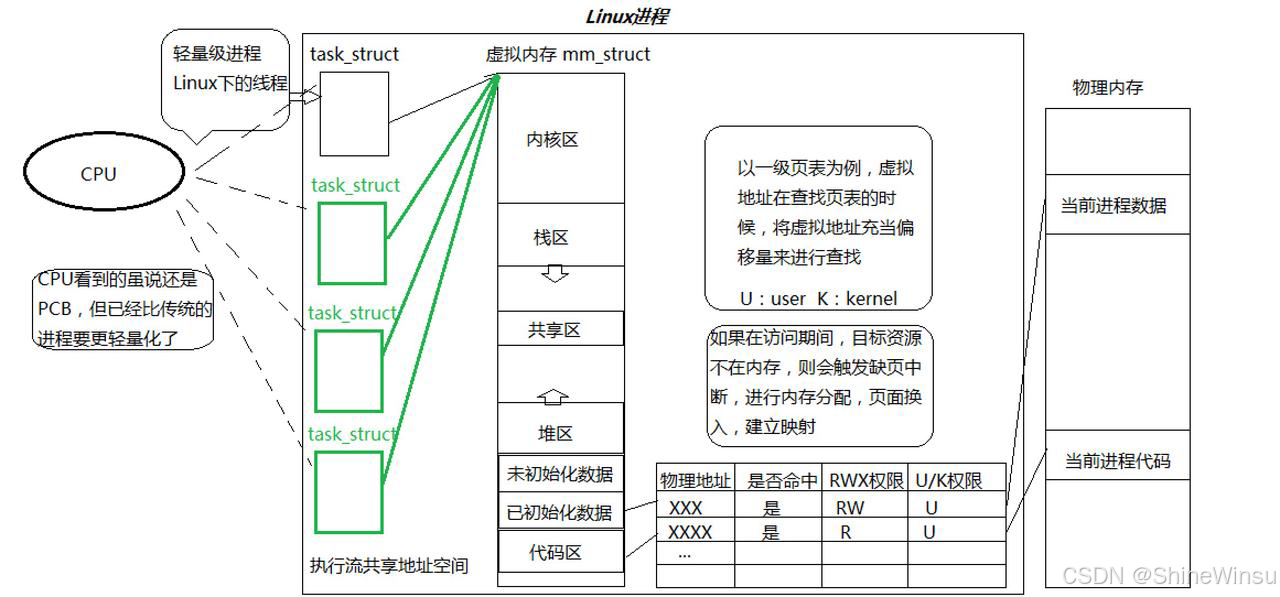
那么大家可能会有所好奇,我们之前学的进程又是什么呢?其实我们之前学的进程,主要是单线程进程,我们首先要知道,进程本质上是内核数据结构加所指向的数据和代码,而PCB,也就是task_struct是内核数据结构,仅凭它可不能代表是一个进程哦,一个进程应该是task_struct加上虚拟地址空间(mm_struct、vm_area_struct)再加上页表再加上所指向的物理内存,这才是真正的进程,大家可以看下面这个图:
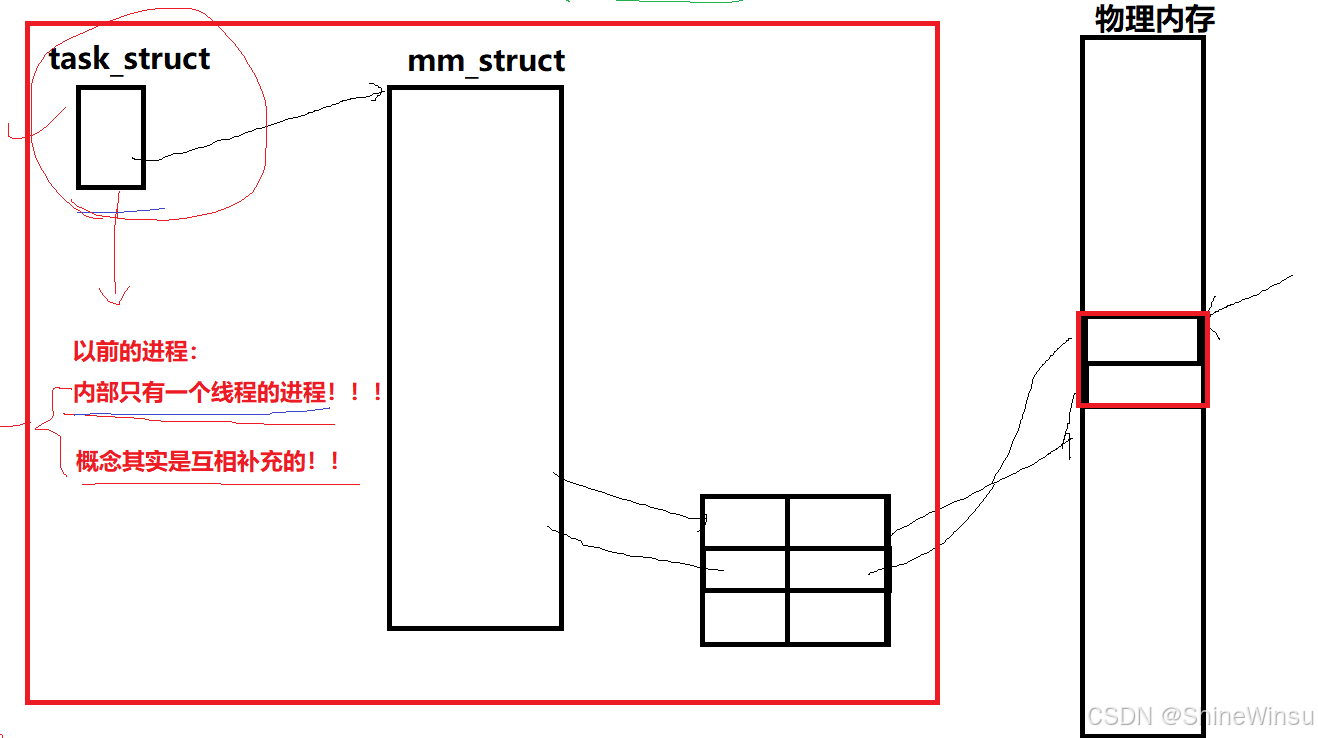
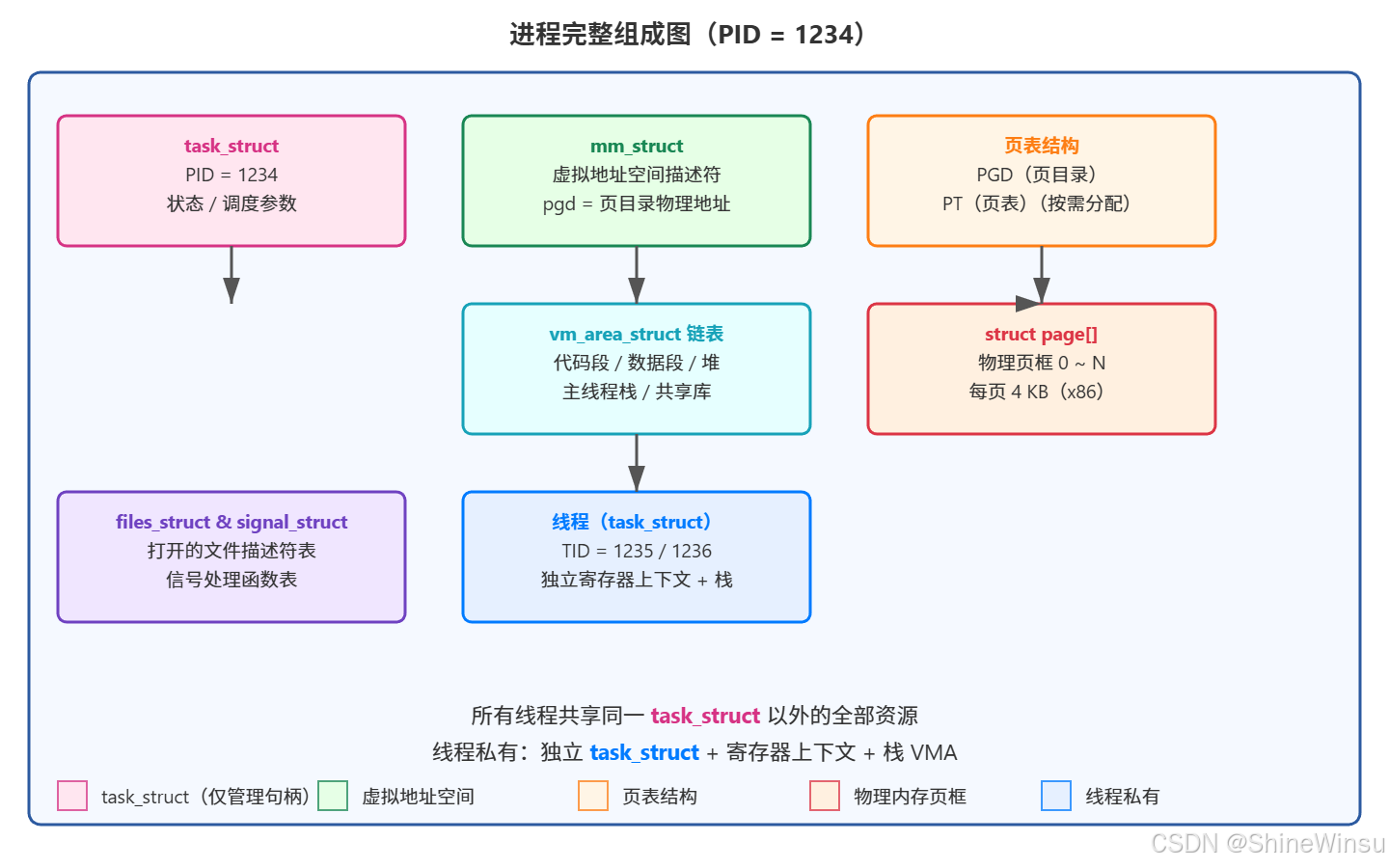
而线程,在Linux中,其实被化作了task_struct,也就是说有多个task_struct指向虚拟内存,它们共享总共的一个进程的资源,那么就可以又多个task_struct进行处理,这就叫作线程,概念是比较难懂的,所以大家可以结合着图像来进行理解。
核心细节补充(内核视角):
- 每个线程对应一个
task_struct结构体(和进程的 PCB 完全相同),但多个线程的task_struct会共享:mm指针:指向同一个内存描述符(struct mm_struct),即共享虚拟地址空间;files指针:指向同一个文件描述符表(struct files_struct);signal指针:指向同一个信号处理结构体;
- 线程独有的字段在
task_struct中:tid:线程 ID(区别于进程 IDpid);thread_info:线程私有数据(如栈指针、寄存器值);priority:线程调度优先级;signal_mask:线程专属的信号屏蔽字。
| 资源项 | 进程(独立) | 线程(共享) | 备注 |
| task_struct | 每个进程独立 | 每个线程独立 | 内核调度的基本单位 |
| mm_struct | 独立(1 份) | 共享(同一 mm) | 虚拟地址空间描述符 |
| vm_area_struct 链表 | 独立 | 共享 | 内存区域定义 |
| 页表(PGD/PT) | 独立 | 共享 | 地址映射关系 |
| 物理页框 | 独立 | 共享 | 代码 / 数据 / 堆共享 |
| 文件描述符表 | 独立 | 共享 | 打开的文件句柄 |
| 信号处理表 | 独立 | 共享 | 信号处理函数 |
| 线程栈 | 主线程有 | 每个线程独立 | 唯一不共享的内存区域 |
| 寄存器上下文 | 独立 | 每个线程独立 | 程序计数器、栈指针等 |
|---|
1.2 线程为什么 "轻量"?------ 与进程的底层差异对比
线程被称为 "轻量级进程(LWP)",核心原因是创建、切换、销毁的开销远低于进程,这背后是资源共享带来的效率提升:
| 操作 | 进程(独立资源) | 线程(共享资源) |
|---|---|---|
| 创建时 | 需分配全新的虚拟地址空间、页表、文件描述符表等,内核要初始化大量mm_struct、files_struct等结构体 |
仅需创建新的task_struct,共享父线程的mm、files等指针,无需分配新资源,初始化成本极低 |
| 切换时 | 需切换虚拟地址空间(更新 CR3 寄存器指向新页目录)、刷新 TLB(快表)、保存 / 恢复全套资源上下文 | 无需切换虚拟地址空间(CR3 寄存器不变),仅需保存 / 恢复线程私有数据(寄存器、栈指针),TLB 不刷新 |
| 销毁时 | 需释放所有分配的资源(内存、文件、信号等),内核要回收多个结构体 | 仅需回收自身的task_struct和私有栈,共享资源由进程统一释放(最后一个线程销毁时) |
切换开销的直观对比(举例):
- 进程切换的开销约为几十到几百个 CPU 时钟周期(主要耗时在页表切换和 TLB 刷新);
- 线程切换的开销仅为几个到十几个 CPU 时钟周期(仅需操作寄存器和栈指针);
- 这也是多线程并发效率远高于多进程的核心原因 ------ 比如 Web 服务器用多线程处理请求,每秒可处理数千个连接,而多进程可能仅能处理数百个。
1.3 线程的创建底层流程(以pthread_create为例)
用户态调用pthread_create创建线程时,底层流程如下:
- 调用
clone系统调用(区别于fork),传入CLONE_VM(共享虚拟内存)、CLONE_FILES(共享文件描述符表)、CLONE_SIGHAND(共享信号处理)等参数; - 内核创建新的
task_struct结构体,将其mm、files等指针指向父线程的对应结构体; - 为新线程分配独立的栈空间(默认大小为 2MB,可通过
pthread_attr_setstacksize调整); - 初始化线程的寄存器上下文(程序计数器 PC 指向线程函数入口);
- 将新线程加入调度队列,等待 CPU 调度执行。
代码示例:clone系统调用创建线程(底层实现简化版)
cpp
#define _GNU_SOURCE
#include <stdio.h>
#include <sched.h>
#include <unistd.h>
#include <stdlib.h>
// 线程栈大小(2MB)
#define STACK_SIZE (2 * 1024 * 1024)
// 线程函数
void* thread_func(void* arg) {
printf("子线程:TID=%ld,共享父进程的PID=%d\n", (long)pthread_self(), getpid());
sleep(3);
return NULL;
}
int main() {
// 分配线程栈(栈空间需对齐)
char* stack = (char*)malloc(STACK_SIZE);
if (!stack) {
perror("malloc stack failed");
exit(1);
}
char* stack_top = stack + STACK_SIZE; // 栈是向下生长的,栈顶为高地址
// 调用clone创建线程,共享虚拟内存、文件描述符、信号处理
pid_t tid = clone((int (*)(void*))thread_func, stack_top,
CLONE_VM | CLONE_FILES | CLONE_SIGHAND | CLONE_THREAD, NULL);
if (tid == -1) {
perror("clone failed");
exit(1);
}
printf("父线程:PID=%d,创建的子线程TID=%ld\n", getpid(), (long)tid);
waitpid(tid, NULL, __WALL); // 等待子线程结束
free(stack);
return 0;
}二、分页存储管理:虚拟内存的 "底层魔法"
分页存储管理是虚拟内存的核心实现机制,本质是 **"把内存切成固定大小的块,用'映射表'解决物理内存碎片化和地址冲突"**
2.1 先搞懂:没有分页的世界有多 "坑"?
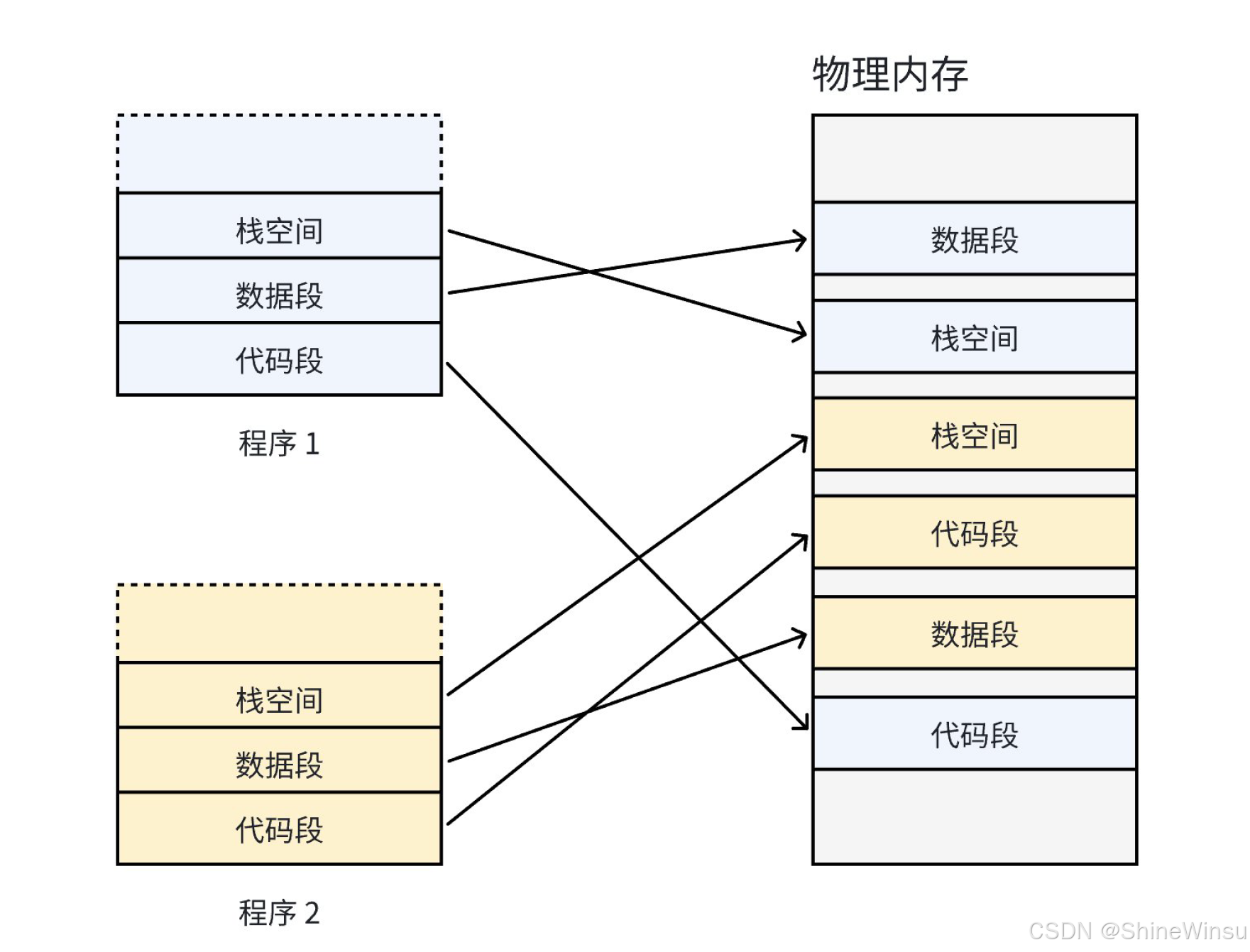
在分页技术出现前,程序直接使用物理内存,就像 "大家共用一个没有格子的大仓库":
- 内存碎片问题:你要放 10 箱货物(程序 A 需要 10MB 内存),仓库里总共有 20MB 空闲,但分散成了 3 个 5MB、1 个 5MB 的小空间(碎片),你没法把 10 箱货物堆在不连续的地方,只能放弃;
- 地址冲突问题:你把货物放在仓库的 "第 10 排第 5 列"(物理地址 0x12345678),另一个人(程序 B)也想把货物放这,结果你的货物被覆盖,全乱了!
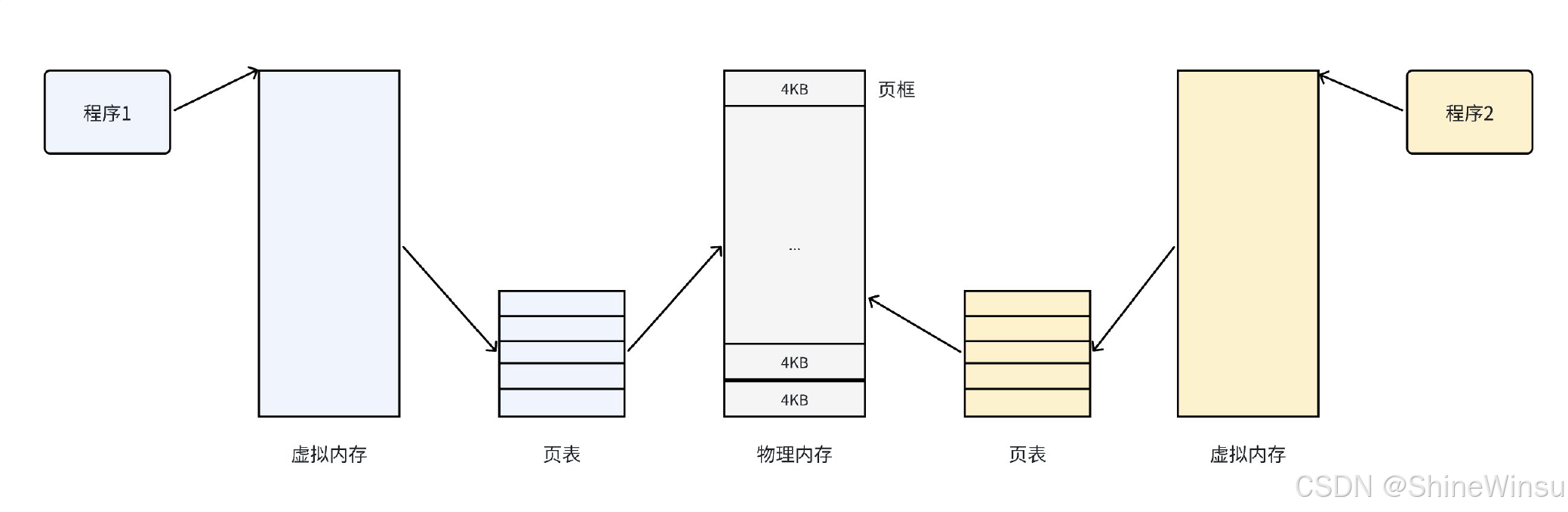
分页技术的核心就是给仓库 "加格子 + 做编号映射":
- 把仓库(物理内存)切成大小相同的 "格子"(物理页框),每个格子有唯一编号(页框号);
- 给每个程序分配独立的 "虚拟货架号"(虚拟地址),程序只知道自己的虚拟货架号,不知道实际物理格子号;
- 操作系统手里有一张 "虚拟货架号→物理格子号" 的映射表(页表),程序要取货物时,操作系统通过映射表找到实际格子,既不会冲突,也能利用分散的格子。
生活类比:快递驿站的取件逻辑
- 你(进程)寄快递时,驿站给你一个快递单号(虚拟地址),你不用管包裹实际放在哪个货架(物理地址);
- 驿站(操作系统)的电脑里有 "单号→货架号" 的表格(页表),哪怕货架是分散的(物理内存碎片化),也能快速找到包裹;
- 不同人的快递单号不会重复(虚拟地址隔离),货架可以重复用(物理内存共享),完美解决了 "冲突" 和 "碎片" 问题。
2.2 页框与页:内存的 "标准快递盒"(固定大小是关键)
分页的核心是 "按固定大小拆分内存",这两个概念必须分清,用 "快递盒" 类比一看就懂:
| 概念 | 通俗理解 | 核心细节 |
|---|---|---|
| 物理页框(Page Frame) | 物理内存的 "标准快递盒" | - 大小固定(x86_32 位系统默认 4KB);- 是物理内存的最小分配单位,不能拆分;- 每个页框有唯一编号(页框号),比如 0 号、1 号、2 号... |
| 虚拟页(Page) | 进程虚拟地址空间的 "标准快递盒" | - 大小和物理页框完全一致(4KB);- 是虚拟地址的最小映射单位,进程的虚拟地址空间被拆成一个个连续的虚拟页;- 每个虚拟页有唯一编号(虚拟页号),比如 0 号、1 号、2 号... |
**关键问题:为什么选 4KB 作为页大小?(平衡艺术)**页大小不是随便定的,是 "避免浪费" 和 "管理高效" 的平衡:
- 页太大(比如 8KB):像用大盒子装小物件,浪费空间(比如你只放 1KB 数据,却占 8KB 盒子,浪费 7KB,这叫 "页内碎片");
- 页太小(比如 1KB):盒子太多,管理起来麻烦(比如 4GB 虚拟地址空间需要 4096 万个 1KB 的页,对应的映射表(页表)会非常大,占 16MB 内存,内核管理不过来);
- 4KB 是最优解:x86_32 位系统中,4KB 页对应 "4GB/4KB=1048576 个虚拟页",每个虚拟页的映射信息(页表项)占 4 字节,整个页表只占 4MB 内存(1048576×4 字节),既不浪费太多空间,也不会让页表过于庞大。
数值直观感受:
- 一个 10MB 的程序,用 4KB 页大小拆分,需要 10MB/4KB=2560 个虚拟页;
- 这些虚拟页可以映射到物理内存中 2560 个不连续的页框(比如物理页框 100-200 号、500-1000 号、2000-3360 号),程序看起来是连续的,实际物理内存是分散的。
2.3 单级页表:最简单的 "映射表"(但有点浪费内存)
单级页表是最基础的映射方式,本质就是一个 "数组"------ 数组下标是虚拟页号,数组元素(页表项 PTE)是对应的物理页框号 + 属性(比如 "这个页是否在内存中""是否可读写")。
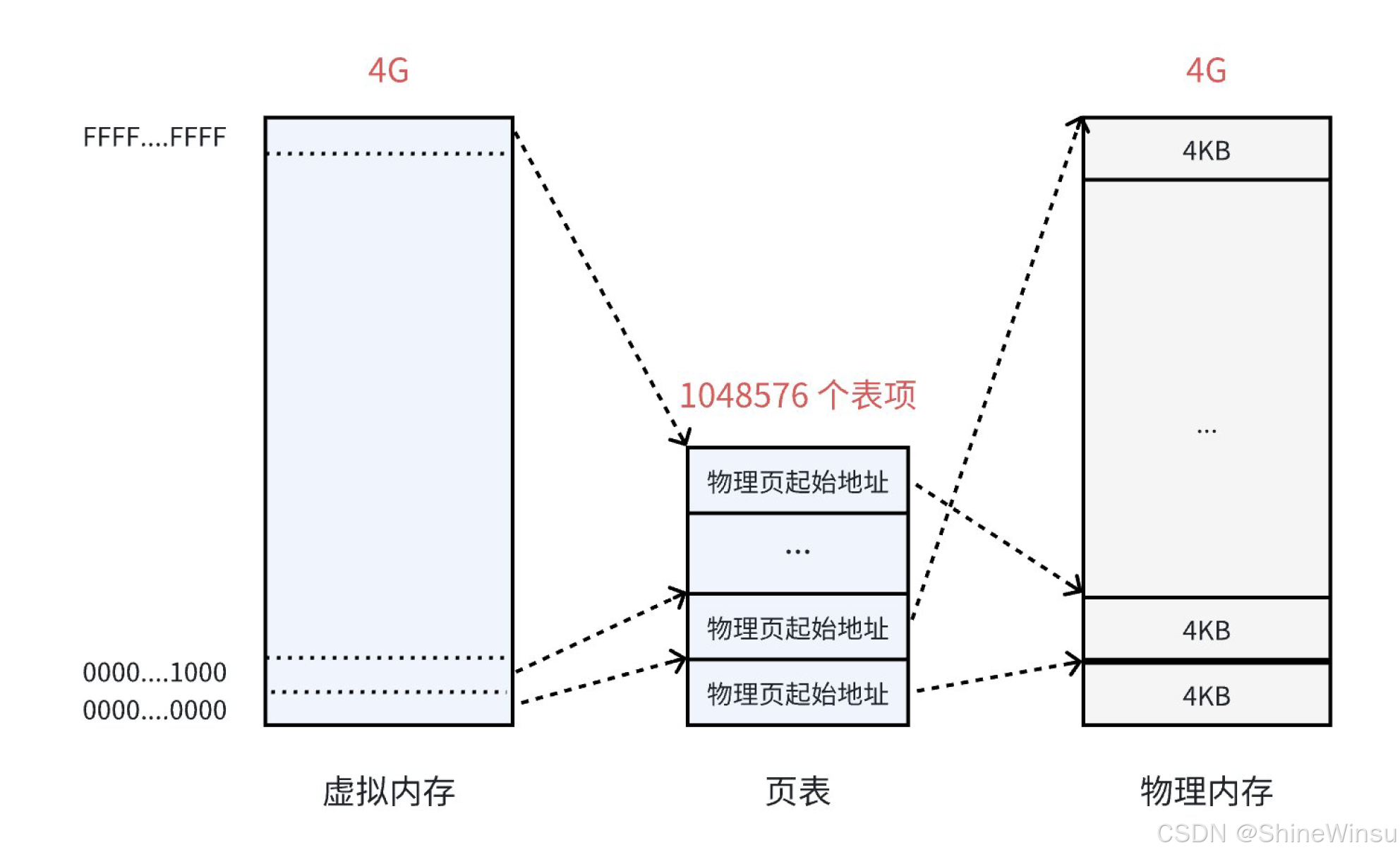
2.3.1 单级页表的结构(x86_32 位系统,4KB 页)
我们用具体数值拆解,让你看得明明白白:
-
虚拟地址:32 位(范围 0x00000000~0xFFFFFFFF,共 4GB);
-
虚拟地址拆分:32 位 ="虚拟页号(20 位)"+"页内偏移(12 位)";
- 页内偏移:因为页大小是 4KB=2^12 字节,所以用 12 位就能表示页内的每个字节(0~4095);
- 虚拟页号:剩下的 20 位表示虚拟页的编号(0~2^20-1=1048575),对应 1048576 个虚拟页;
-
页表项(PTE):4 字节(32 位),结构如下:
- 高 20 位:物理页框号(因为物理页框也是 4KB 对齐,低 12 位是 0,所以 20 位足够表示所有页框);
位位置(bit) 标志位名称 通俗含义 & 作用 0 P(Present) 存在位:1 = 虚拟页已映射到物理页框(在内存中);0 = 未映射(触发缺页异常) 1 R/W(Read/Write) 读写位:1 = 页面可读写;0 = 页面只读 / 执行(用户态写会触发 #PF 异常) 2 U/S(User/Supervisor) 用户 / 内核位:1 = 用户态可访问;0 = 仅内核态可访问(用户态访问触发 #PF 异常) 3 PWT(Page-Level Write-Through) 写透位:1 = 使用写透缓存策略(写数据同时写内存);0 = 写回策略(先写缓存,满了再写内存) 4 PCD(Page-Level Cache Disable) 缓存禁用位:1 = 禁用该页的 CPU 缓存;0 = 启用缓存(内核访问设备内存时常用 1) 5 A(Accessed) 访问位:1 = 该页最近被访问过;0 = 未访问(页面置换算法如 LRU 依据此位判断活跃度) 6 D(Dirty) 修改位:1 = 该页数据被修改过(脏页);0 = 未修改(换出时脏页需写回磁盘,干净页直接丢弃) 7 PAT(Page Attribute Table) 页属性表位:配合 PWT/PCD 定义内存类型(如普通内存、设备内存) 8 G(Global) 全局位:1 = 该页是全局页(所有进程共享,TLB 刷新时不失效);0 = 普通页(进程切换时 TLB 失效) 9-11 可用位 操作系统自定义使用(如 Linux 用这些位存储页的类型:匿名页 / 文件页)
2.3.2 单级页表的问题:太占内存!
每个进程都需要独立的单级页表,而单级页表不管进程实际用了多少虚拟页,都要分配完整的数组:
- 比如一个进程只用到 10 个虚拟页(40KB 内存),但单级页表还是要分配 1048576 个页表项,占 4MB 内存;
- 如果系统有 100 个这样的进程,光页表就占 400MB 内存,这是巨大的浪费!
- 另外,4MB 的页表需要 1024 个连续的 4KB 页框来存储(因为每个页框存 4KB 数据),如果物理内存碎片化,可能找不到连续的 1024 个页框,页表都没法存放。
这就像 "你只需要查 10 个联系人的电话,却要印一本完整的电话簿",既浪费纸,又不好携带。
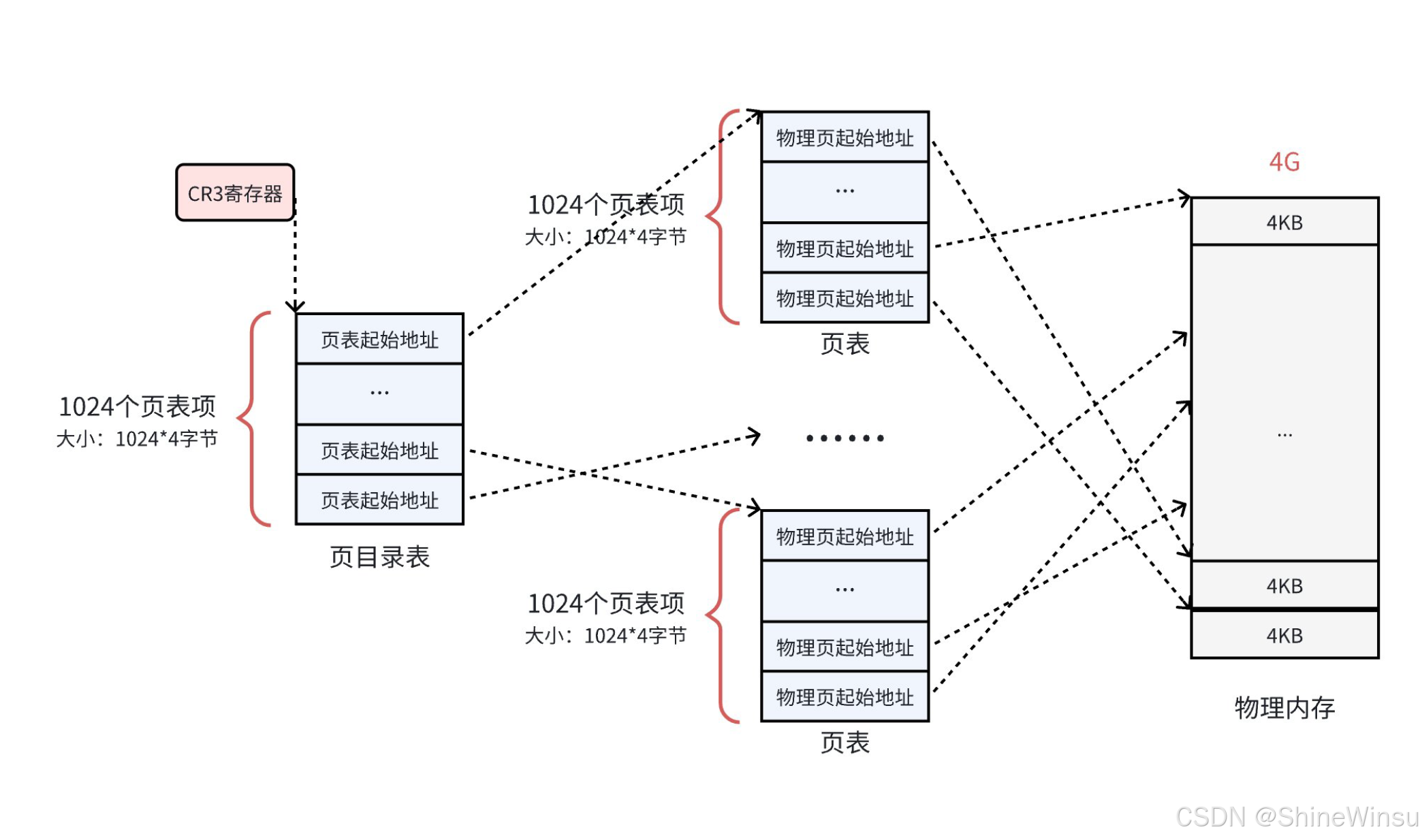
2.4 二级页表:解决浪费的 "聪明方案"(按需分配)
二级页表的核心思路是 "把电话簿拆成'目录 + 子电话簿',只印你需要的子电话簿"------ 把单级页表拆成两级,只有用到的虚拟页对应的子页表才分配内存,大幅节省空间。
2.4.2 二级页表的结构(x86_32 位系统,4KB 页)
还是用具体数值拆解,一步一步看:
-
虚拟地址拆分(关键变化):32 位虚拟地址拆成三部分:
- 页目录索引(10 位):指向 "页目录" 中的一个条目;
- 页表索引(10 位):指向 "子页表" 中的一个条目;
- 页内偏移(12 位):和单级页表一样,指向页内的具体字节;(10+10+12=32 位,刚好覆盖 4GB 虚拟地址空间)
-
页目录(Page Directory):相当于 "子电话簿的目录"
- 大小:4KB(1 个物理页框),刚好能存 1024 个页目录项(PDE),每个 PDE 占 4 字节(1024×4=4096 字节 = 4KB);
- 页目录项(PDE)结构:和页表项类似,高 20 位是 "子页表的物理基地址",低 12 位是属性标志位(比如 P 位:子页表是否在内存中);
- 每个进程只有 1 个页目录,是必须分配的(占 4KB 内存)。
-
子页表(Page Table):相当于 "子电话簿"
- 大小:4KB(1 个物理页框),存 1024 个页表项(PTE),每个 PTE 占 4 字节;
- 一个页目录项对应一个子页表,只有当进程访问到该子页表对应的虚拟页时,才会分配这个子页表(按需分配);
- 比如进程访问的虚拟页号对应 "页目录索引 0",就只分配 "页目录 0" 对应的子页表,其他页目录对应的子页表暂时不分配。
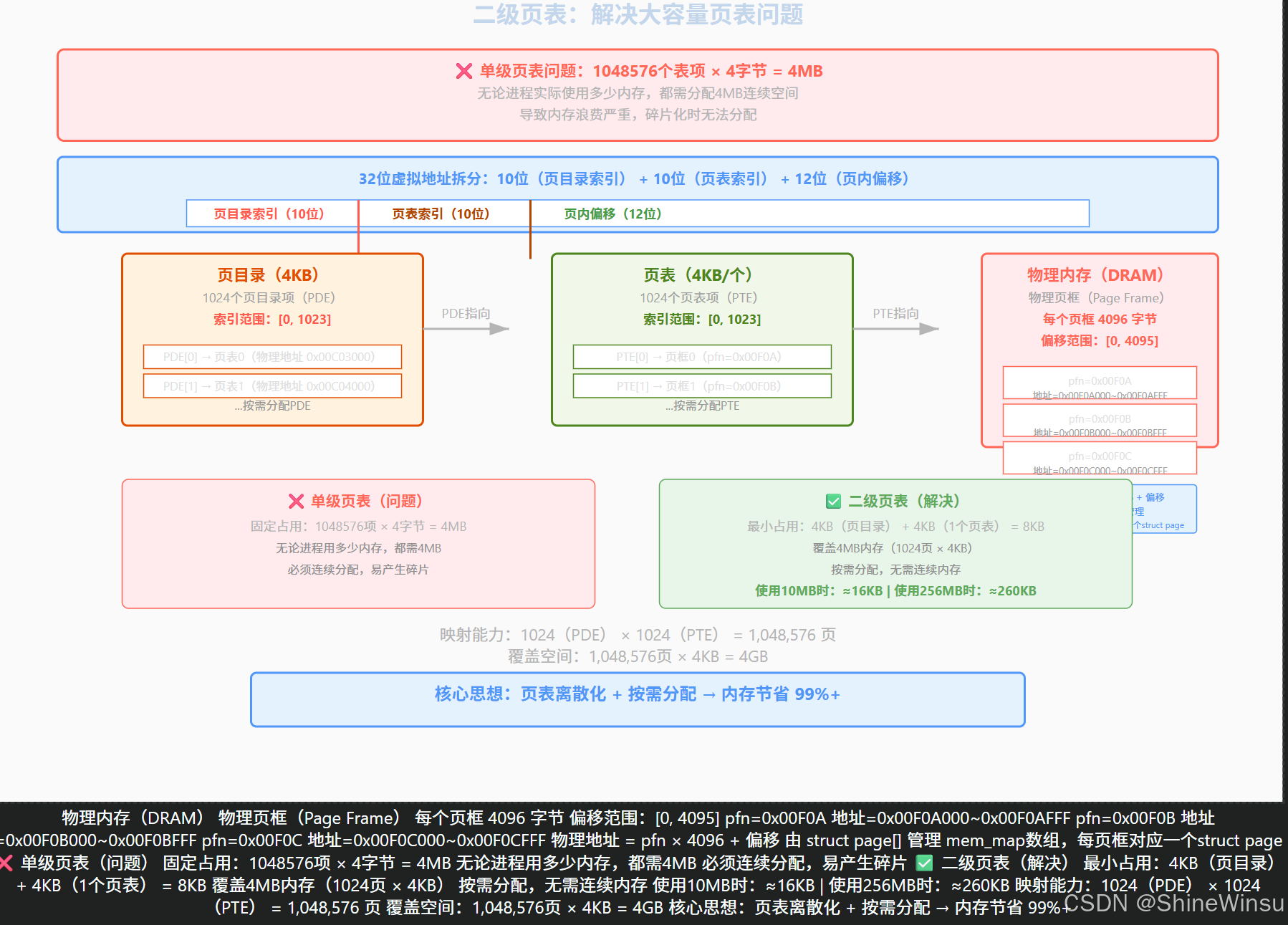
2.4.2 二级页表的优势:省内存!
我们用之前的例子对比:
- 进程只用到 10 个虚拟页(40KB 内存):
- 单级页表:需要 1048576 个页表项,占 4MB 内存;
- 二级页表:10 个虚拟页需要多少子页表?每个子页表能存 1024 个页表项,所以 10 个虚拟页只需要 1 个子页表(1024≥10);
- 二级页表总内存:页目录(4KB)+ 1 个子页表(4KB)= 8KB,比单级页表的 4MB 节省了 512 倍!
生活类比:图书馆找书(二级目录)
- 图书馆(物理内存)有很多书(数据),每本书放在固定书架(物理页框);
- 你(进程)要找《操作系统》(虚拟地址),先看图书馆总目录(页目录),找到 "计算机类" 对应的子目录位置(页目录索引);
- 再看 "计算机类" 子目录(子页表),找到《操作系统》对应的书架号(物理页框号);
- 最后根据书架号 + 书的页码(页内偏移),找到这本书;
- 图书馆只打印有人借的子目录(按需分配子页表),没人借的子目录不打印(不分配内存),节省纸张(内存)。
2.5 地址转换流程:从虚拟地址到物理地址的 "五步走"
MMU(内存管理单元,CPU 内置的硬件)负责把虚拟地址转换成物理地址,整个过程是 "硬件自动完成 + 操作系统辅助",我们用二级页表为例,带具体数值拆解每一步,让你跟着走就能懂。
前提条件(固定参数)
- 虚拟地址:32 位,示例虚拟地址 = 0x12345678(二进制:0001 0010 0011 0100 0101 0110 0111 1000);
- 页大小:4KB=2^12 字节,页内偏移 = 12 位;
- 二级页表拆分:页目录索引(10 位)+ 页表索引(10 位)+ 页内偏移(12 位);
- CR3 寄存器:存储当前进程的 "页目录物理基地址",示例 CR3=0x00001000(页目录存在物理页框 0x00001 对应的位置)。
五步转换流程(一步一拆解)
步骤 1:拆分虚拟地址(拿到三个关键部分)
把示例虚拟地址 0x12345678 拆成三部分:
- 页目录索引(前 10 位):0x12345678 的前 10 位二进制是 "0001001000",转换成十进制 = 72;
- 页表索引(中间 10 位):中间 10 位二进制是 "1101000101",转换成十进制 = 845;
- 页内偏移(后 12 位):后 12 位二进制是 "011001111000",转换成十进制 = 1656;(验证:72×1024×4096 + 845×4096 + 1656 = 0x12345678,拆分正确)
步骤 2:查页目录,找到子页表的物理基地址
- MMU 先读取 CR3 寄存器的值 = 0x00001000(页目录的物理基地址);
- 计算页目录项(PDE)的物理地址:页目录基地址 + 页目录索引 ×4 字节(每个 PDE 占 4 字节);
- PDE 物理地址 = 0x00001000 + 72×4=0x000011C0;
- MMU 访问物理地址 0x000011C0,读取 PDE 的值(示例 PDE=0x00002001);
- PDE 的高 20 位 = 0x00002(子页表的物理基地址 = 0x00002000,因为页框是 4KB 对齐,低 12 位补 0);
- PDE 的低 12 位 = 0x001(P 位 = 1,说明子页表在物理内存中,有效)。
步骤 3:查子页表,找到物理页框基地址
- 计算页表项(PTE)的物理地址:子页表物理基地址 + 页表索引 ×4 字节;
- PTE 物理地址 = 0x00002000 + 845×4=0x00002D54;
- MMU 访问物理地址 0x00002D54,读取 PTE 的值(示例 PTE=0x00003007);
- PTE 的高 20 位 = 0x00003(物理页框基地址 = 0x00003000);
- PTE 的低 12 位 = 0x007(P 位 = 1,R/W=1,U/S=1,说明该页在内存中,可读写,用户态可访问)。
步骤 4:计算最终物理地址
- 物理地址 = 物理页框基地址 + 页内偏移;
- 示例物理地址 = 0x00003000 + 1656=0x00003678;
步骤 5:验证权限,访问物理内存
- MMU 检查 PTE 的权限(比如是否可读写、是否允许用户态访问),如果权限合法,就访问物理地址 0x00003678,读取或写入数据;
- 如果权限不合法(比如用户态进程访问内核态地址),MMU 会触发 "权限错误" 中断,操作系统会终止进程(比如段错误)。
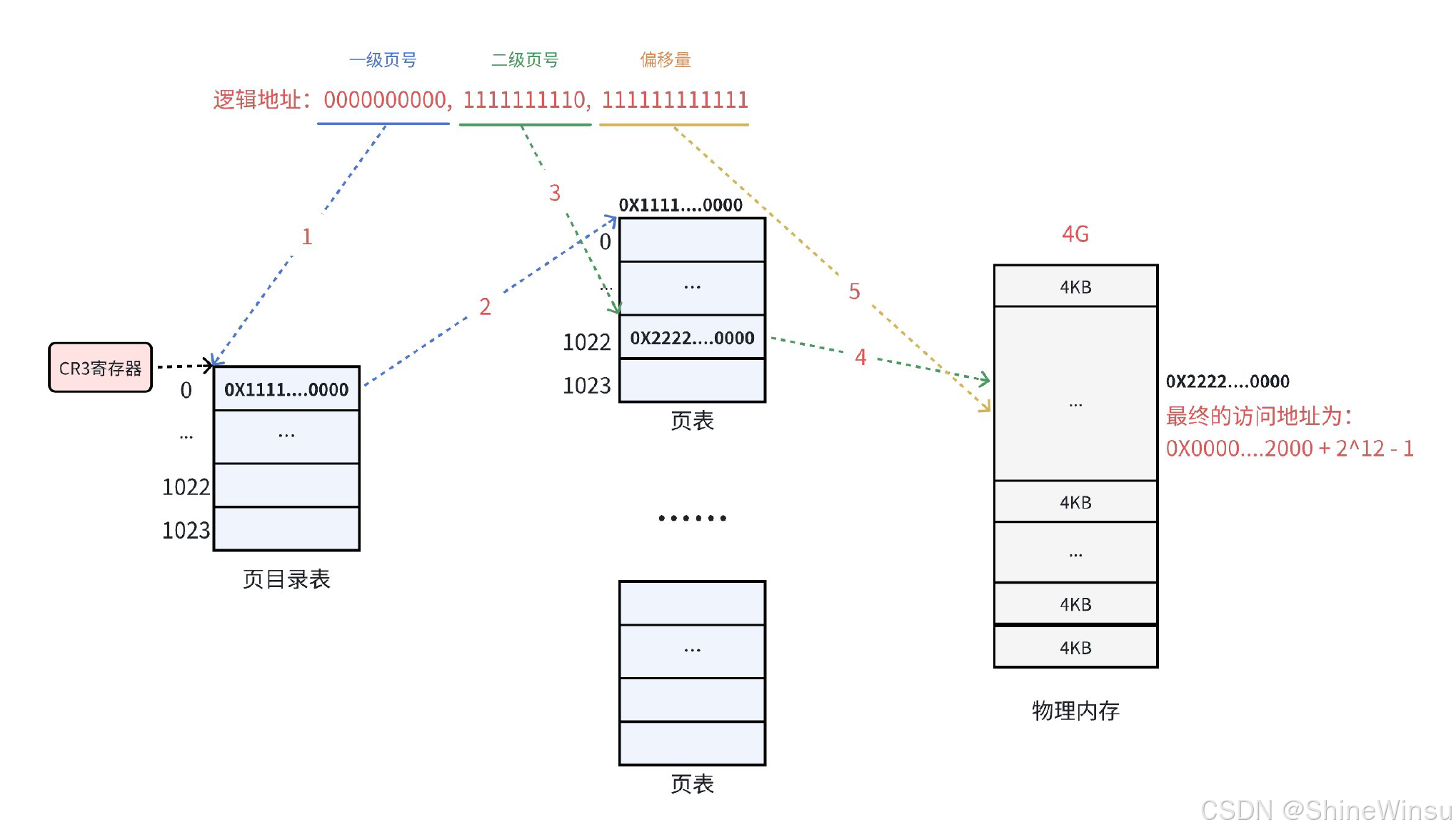
总结:整个过程就像 "按地址找快递"
- 虚拟地址 ="小区号(页目录索引)+ 楼栋号(页表索引)+ 门牌号(页内偏移)";
- CR3="小区总地址";
- 先按小区总地址 + 小区号,找到楼栋的位置(子页表基地址);
- 再按楼栋位置 + 楼栋号,找到单元门(物理页框基地址);
- 最后按单元门 + 门牌号,找到具体的快递(数据)。
2.6 快表(TLB):地址转换的 "加速器"(为什么线程切换比进程快?)
二级页表解决了内存浪费问题,但每次地址转换都要访问两次物理内存(查页目录、查子页表),如果每次访问数据都要走这两步,速度会很慢(物理内存访问速度是 CPU 的千分之一)。
TLB(转译后备缓冲器)就是 "给页表项加的缓存"------CPU 把最近访问过的 "虚拟页号→物理页框号" 映射关系存在 TLB 里,下次再访问同一个虚拟页时,直接从 TLB 里取,不用再查页表。
TLB 的工作流程(通俗版)
- CPU 收到虚拟地址后,先查 TLB:"这个虚拟页号我之前存过吗?";
- 如果存过(TLB 命中):直接从 TLB 里拿物理页框号,加上页内偏移就是物理地址,整个过程只需要 1-2 个 CPU 时钟周期(和访问 CPU 缓存一样快);
- 如果没存过(TLB 未命中):按二级页表的流程查页目录、子页表,找到物理地址后,把 "虚拟页号→物理页框号" 的映射关系存入 TLB(替换掉最近最少用的映射),方便下次访问。
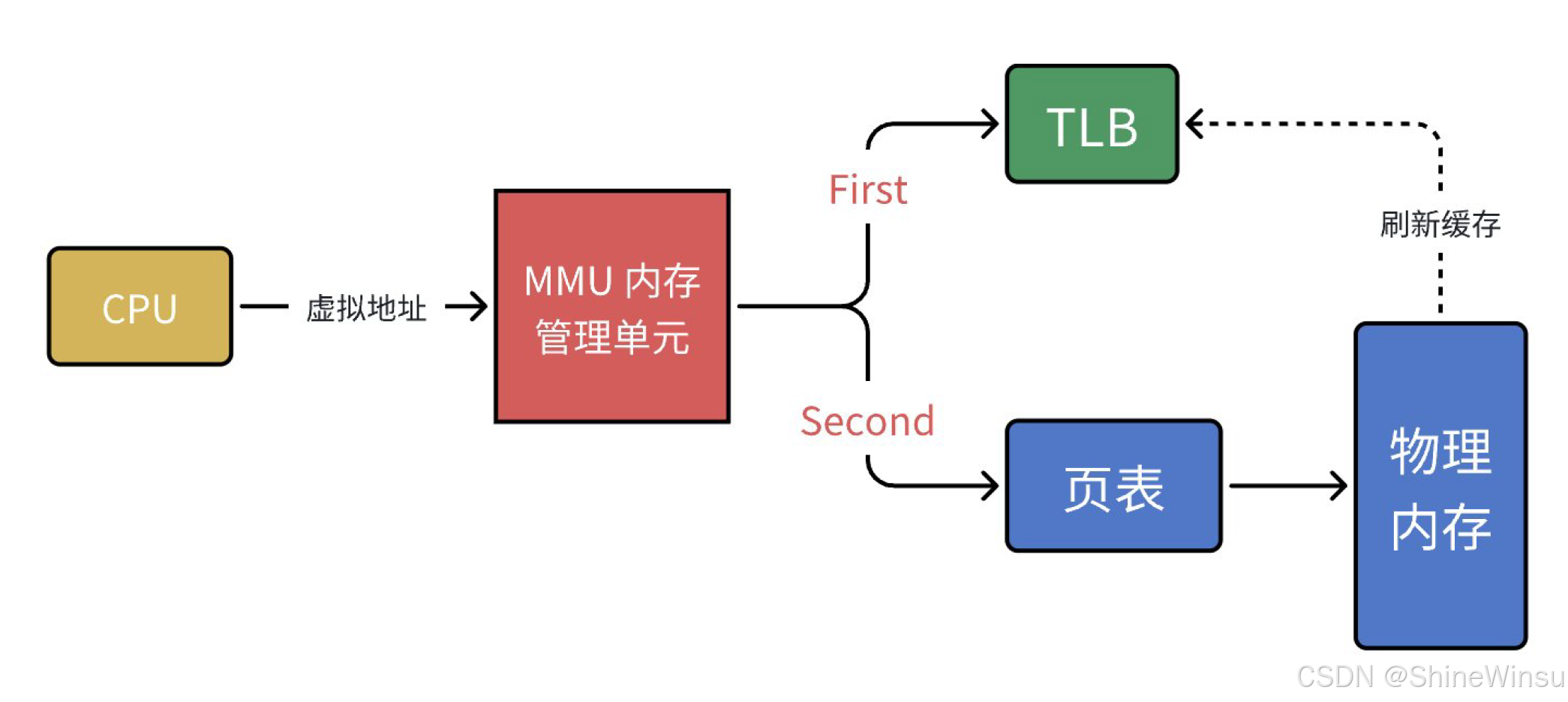
关键特性:TLB 为什么能加速线程切换?
- 线程共享虚拟地址空间:同一个进程的线程,虚拟地址空间是一样的,所以 TLB 里的映射关系对所有线程都有效;
- 线程切换时,TLB 不用刷新:线程切换只需要切换线程的私有数据(寄存器、栈),虚拟地址空间没变,TLB 里的映射关系依然能用,下次访问数据时 TLB 命中率高;
- 进程切换时,TLB 必须刷新:进程切换会换虚拟地址空间,TLB 里的映射关系全失效了,需要重新查页表填充 TLB,这也是进程切换比线程切换慢的重要原因之一。
生活类比:TLB = 你手机里的 "常用联系人电话"
- 你经常给 "妈妈" 打电话(访问某个虚拟页),不用每次都翻电话簿(查页表),直接从手机通讯录(TLB)里找,秒拨;
- 你第一次给 "客户" 打电话(首次访问虚拟页),需要翻电话簿(查页表),然后把客户电话存到通讯录(TLB),下次再打就快了;
- 你换了手机卡(进程切换,虚拟地址空间变了),通讯录里的电话全失效了(TLB 刷新),需要重新存常用联系人。
2.7 缺页异常:"页不在内存" 时的补救措施
当 MMU 查页表时,发现页表项的 "存在位(P)=0",说明这个虚拟页没有映射到物理页框(不在内存中),这时候会触发 "缺页异常"------ 这不是错误,是操作系统的 "正常补救流程",相当于 "快递还没到驿站,驿站帮你去仓库调货"。
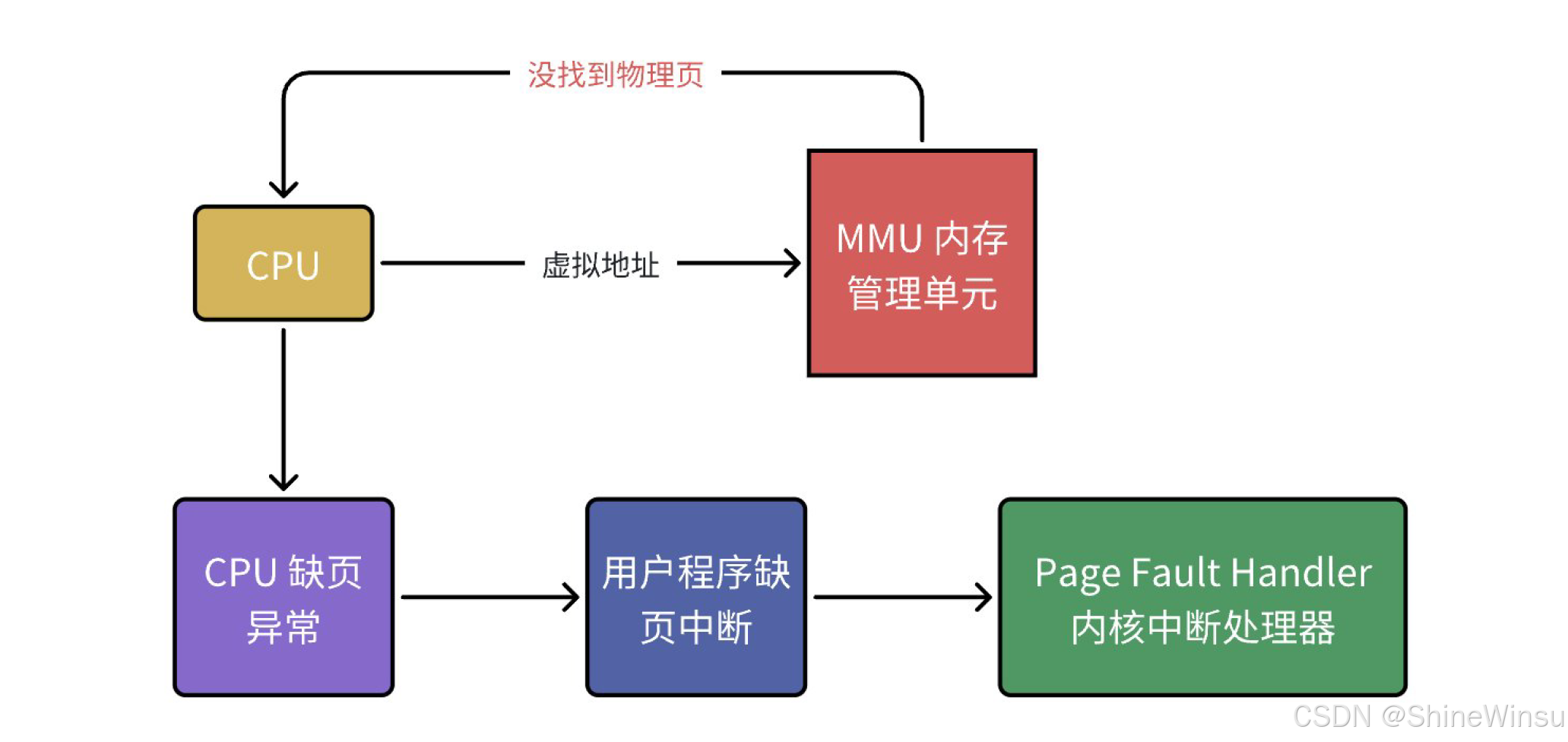
缺页异常的三种场景(结合编程实际)
场景 1:软缺页(页已在内存,只是没映射)------ 快速处理
- 例子:多个进程共享同一个共享库(比如 libc.so),进程 A 已经把 libc.so 加载到物理内存了,进程 B 首次调用 libc.so 的函数时,虚拟页对应的 PTE 的 P 位 = 0,但物理内存中已经有这个页了;
- 处理流程(毫秒级):
- 操作系统检查物理内存,发现该页已存在(通过 struct page 结构体的引用计数判断);
- 给进程 B 的页表项填写物理页框号,把 P 位置 1;
- 恢复进程 B 执行,不用访问磁盘,速度很快。
场景 2:硬缺页(页不在内存,需要从磁盘加载)------ 慢速处理
- 例子:你调用 malloc (1024) 分配内存,操作系统只是在虚拟地址空间预留了一块区域,没分配物理页框;当你第一次写入内存(比如 * ptr=1)时,触发硬缺页;
- 处理流程(秒级,因为要访问磁盘):
- 操作系统在物理内存中找一个空闲的页框;
- 从磁盘(比如程序文件、Swap 分区)把该页的数据读到空闲页框;
- 给进程的页表项填写物理页框号,把 P 位置 1;
- 恢复进程执行。
场景 3:非法缺页(访问了不该访问的虚拟地址)------ 进程崩溃
- 例子:数组下标溢出(int arr 10; arr 100=0)、空指针解引用(int* ptr=NULL; *ptr=1);
- 处理流程:
- 操作系统检查虚拟地址,发现该地址不在进程的虚拟地址映射范围内(比如超出了堆、栈的范围);
- 触发 "段错误(SIGSEGV)" 信号;
- 进程收到信号后,默认行为是终止并生成 core dump 文件(用于调试)。
编程关联:malloc 的 "延迟分配"(为什么 malloc 后内存没被占用?)
很多人疑惑:为什么调用 malloc (1024) 后,用 free 命令看进程内存占用没增加?这就是 "延迟分配",和硬缺页密切相关:
- malloc (1024) 只是告诉操作系统:"我需要 1KB 内存,你在我的虚拟地址空间里留一块区域";
- 操作系统更新进程的内存映射表(比如堆的范围扩大 1KB),但不会立即分配物理页框;
- 当你第一次写入该内存(*ptr=1)时,触发硬缺页异常;
- 操作系统才分配物理页框,建立虚拟地址到物理页框的映射;
- 这时候用 free 命令看,进程的物理内存占用才会增加。
关于缺页中断,我们以前也有讲过,不知道大家还记得多少呢哈哈哈。
2.8 物理内存管理:struct page 结构体 ------ 每个页框的 "身份证"
操作系统需要管理所有物理页框(比如 "哪个页框空闲""哪个页框被占用""被哪个进程占用"),核心数据结构是 struct page------ 每个物理页框对应一个 struct page,相当于给每个页框发了一张 "身份证",记录它的所有信息。
struct page 的关键字段(通俗解释)
struct page {
unsigned long flags; // 页框的"状态标签"(比如是否被锁定、是否修改过)
atomic_t _mapcount; // 页框的"引用计数"(被多少个进程的页表引用)
void* virtual; // 页框的"内核虚拟地址"(内核访问该页框时用)
struct list_head lru; // 页框的"LRU链表节点"(页面置换时用)
struct address_space* mapping; // 页框的"文件关联"(比如该页是从哪个文件加载的)
pgoff_t index; // 页框在文件中的"偏移量"(比如是文件的第几个页)
};用 "身份证信息" 类比每个字段:
- flags:页框的 "状态"(比如是否已婚、是否有驾照),每一位代表一种状态:
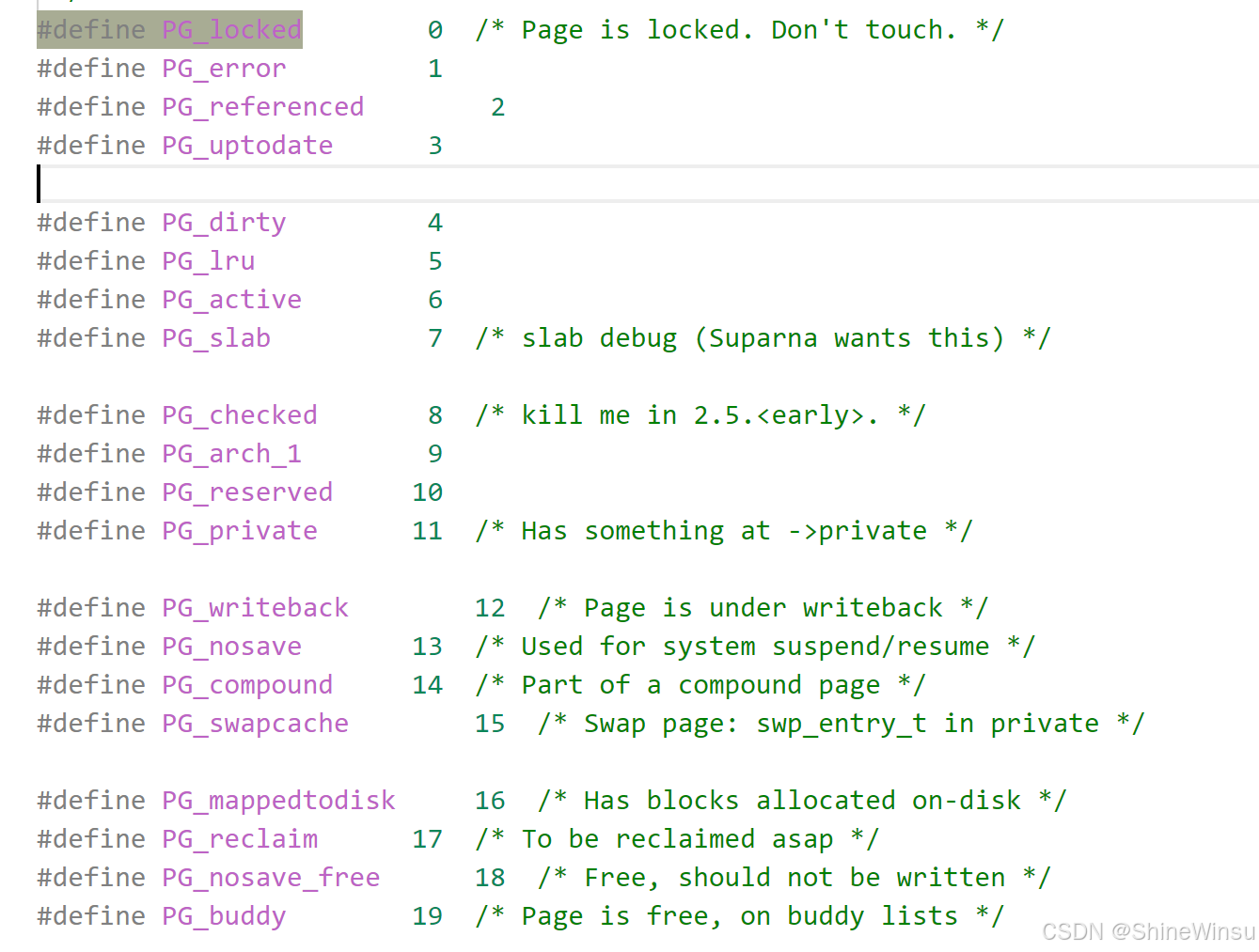
- PG_locked:页框被锁定(比如正在读写磁盘,不能被置换);
- PG_dirty:页框的数据被修改过(脏页,换出时需要写回磁盘);
- PG_uptodate:页框的数据已从磁盘读取完成,可用;
- _mapcount:页框的 "使用人数"(比如房子被几个人合租),_mapcount=-1 表示没人用(空闲),_mapcount=2 表示被 2 个进程共享;
- virtual:页框的 "内核访问地址"(比如身份证上的 "户籍地址",内核要访问该页框时,用这个地址);
- lru:页框的 "活跃度标签"(比如身份证上的 "最近居住记录"),页面置换算法(比如 LRU,最近最少使用)通过这个链表判断哪个页框最久没被用,优先换出;
- mapping+index:页框的 "来源"(比如身份证上的 "出生地"),记录该页框的数据是从哪个文件的哪个位置加载的(比如共享库 libc.so 的第 5 个页)。
struct page 的内存开销(为什么不浪费?)
很多人担心:每个页框都有一个 struct page,会不会占用太多内存?我们计算一下:
- 假设 struct page 占用 40 字节(实际 Linux 内核中约 32-64 字节,这里取中间值);
- x86_32 位系统,4GB 物理内存,页框大小 4KB,总页框数 = 4GB/4KB=1048576 个;
- 所有 struct page 的总内存开销 = 1048576×40 字节 = 41943040 字节≈40MB;
- 40MB 相对于 4GB 物理内存,只占 1%,完全可以接受,是 "用少量内存管理大量内存" 的高效方案。
2.9 总结:分页存储管理的 "核心价值"
分页存储管理的本质是 "以'固定大小的页'为单位,通过'二级页表 + TLB 缓存',实现虚拟地址到物理地址的高效映射",最终解决了三个核心问题:
- 物理内存碎片化:虚拟地址连续,物理地址可以离散,充分利用分散的物理页框;
- 地址冲突:每个进程有独立的虚拟地址空间,页表隔离,不会互相干扰;
- 内存高效利用:按需分配(二级页表、延迟分配)+ 缓存加速(TLB),既不浪费内存,又不影响访问速度。
程序运行时的内存访问全流程(串联所有知识点):
- 你写的代码:
int a = 1;(变量 a 的虚拟地址 = 0x12345678); - CPU 执行时,把虚拟地址 0x12345678 发给 MMU;
- MMU 先查 TLB,看有没有该虚拟页的映射:
- 命中:直接拿物理页框号,计算物理地址,访问物理内存,写入 1;
- 未命中:查二级页表(页目录→子页表),找到物理页框号;
- 如果页表项的 P 位 = 0(缺页):
- 触发缺页异常,操作系统分配物理页框,从磁盘加载数据(如果需要);
- 更新页表项,把映射关系存入 TLB;
- MMU 拿到物理地址,访问物理内存,完成数据写入;
- 操作系统通过 struct page 管理物理页框的状态(比如标记为脏页)。
三、进程与线程的资源:共享与独占的 "清晰边界"
3.1 核心原则:进程是 "资源分配单位",线程是 "调度执行单位"
- 资源分配:操作系统以 "进程" 为单位分配资源(内存、文件描述符、信号处理方式等),进程是资源的 "容器";
- 调度执行:操作系统以 "线程" 为单位调度 CPU 执行,线程是执行的 "最小单元"------ 一个进程可以有多个线程,这些线程共享进程的资源,轮流使用 CPU。
3.2 线程共享的进程资源(详细清单 + 实例)
同一进程的所有线程共享以下资源,意味着一个线程对资源的修改会影响其他线程:
- 虚拟地址空间 :
- 代码段(Text Segment):比如线程 A 定义的函数
func(),线程 B 可以直接调用; - 数据段(Data Segment):全局变量、静态变量(如
int g_count = 0,线程 A 和线程 B 修改的是同一个变量); - 堆(Heap):
malloc/new分配的内存(如线程 Amalloc的内存,线程 B 可以free)。
- 代码段(Text Segment):比如线程 A 定义的函数
- 文件描述符表 :
- 线程 A 打开的文件(如
int fd = open("test.txt", O_RDONLY)),线程 B 可以用fd读写该文件; - 管道、socket 等 I/O 资源也共享(如线程 A 创建的 socket,线程 B 可以用它接收数据)。
- 线程 A 打开的文件(如
- 信号处理方式 :
- 进程注册的信号处理函数(如
signal(SIGINT, handler)),对所有线程生效; - 信号的忽略(SIG_IGN)、默认(SIG_DFL)行为,所有线程共享。
- 进程注册的信号处理函数(如
- 其他进程级资源 :
- 当前工作目录(
chdir修改后,所有线程的工作目录都改变); - 用户 ID(UID)、组 ID(GID);
- 共享库(如
libc.so,所有线程共享同一个库的代码和数据)。
- 当前工作目录(
实例:线程共享全局变量
cpp
#include <iostream>
#include <pthread.h>
using namespace std;
int g_count = 0; // 全局变量,所有线程共享
void* thread_incr(void* arg) {
for (int i = 0; i < 10000; ++i) {
g_count++; // 线程A修改全局变量
}
return NULL;
}
void* thread_decr(void* arg) {
for (int i = 0; i < 10000; ++i) {
g_count--; // 线程B修改全局变量
}
return NULL;
}
int main() {
pthread_t tid1, tid2;
pthread_create(&tid1, NULL, thread_incr, NULL);
pthread_create(&tid2, NULL, thread_decr, NULL);
pthread_join(tid1, NULL);
pthread_join(tid2, NULL);
cout << "g_count最终值:" << g_count << endl; // 可能不是0!
return 0;
}- 问题:
g_count++和g_count--不是原子操作(分 "读 - 改 - 写" 三步),线程 A 和线程 B 可能同时修改,导致数据不一致; - 解决:需要用互斥锁(
pthread_mutex_t)保护共享资源,确保同一时间只有一个线程修改g_count。
3.3 线程的私有资源(详细清单 + 实例)
每个线程有自己的私有资源,其他线程无法访问或修改,确保线程执行的独立性:
- 线程 ID(TID) :
- 区别于进程 ID(PID),是线程的唯一标识(如
pthread_self()返回的线程 ID); - 同一进程内的线程 TID 唯一,不同进程的线程 TID 可能重复。
- 区别于进程 ID(PID),是线程的唯一标识(如
- 寄存器上下文 :
- 包括程序计数器(PC,记录下一条要执行的指令地址)、栈指针(SP)、通用寄存器(eax、ebx 等);
- 线程切换时,内核会保存当前线程的寄存器上下文,恢复下一个线程的上下文,确保线程能从暂停的地方继续执行。
- 独立的栈空间 :
- 每个线程有自己的栈(默认 2MB),用于存储局部变量、函数调用参数、返回地址;
- 线程的栈空间是独立的,一个线程的栈溢出不会影响其他线程。
- errno 变量 :
- 记录线程的错误码(如
open失败时,errno会被设置为ENOENT表示文件不存在); - 每个线程有自己的
errno副本,避免一个线程的错误码覆盖另一个线程的。
- 记录线程的错误码(如
- 信号屏蔽字 :
- 线程可以单独屏蔽某些信号(如
pthread_sigmask(SIG_BLOCK, &set, NULL)),被屏蔽的信号不会触发该线程; - 进程的信号处理方式是共享的,但信号屏蔽字是线程私有的。
- 线程可以单独屏蔽某些信号(如
- 调度优先级 :
- 线程可以有自己的调度优先级(如
pthread_attr_setschedparam设置),优先级高的线程更容易被 CPU 调度; - 进程的调度属性是共享的,但线程可以单独设置优先级。
- 线程可以有自己的调度优先级(如
实例:线程私有栈空间
cpp
#include <iostream>
#include <pthread.h>
using namespace std;
void* thread_func(void* arg) {
int local_var = 10; // 局部变量,存储在线程私有栈中
cout << "子线程:local_var地址=" << &local_var << endl;
sleep(3);
return NULL;
}
int main() {
int main_var = 20; // 主线程局部变量,存储在主线程栈中
cout << "主线程:main_var地址=" << &main_var << endl;
pthread_t tid;
pthread_create(&tid, NULL, thread_func, NULL);
pthread_join(tid, NULL);
return 0;
}- 输出结果:主线程和子线程的局部变量地址相差很大(属于不同的栈空间),证明线程栈是独立的;
- 若线程栈溢出(如递归调用过深),会触发 "栈溢出" 信号(SIGSEGV),该线程崩溃,但其他线程(如主线程)可以继续执行。
四、线程的优缺点与实际应用场景
4.1 线程的优点:为什么选择多线程?
- 创建和切换开销低 :
- 如前所述,线程创建无需分配新资源,切换无需刷新 TLB,开销远低于进程;
- 适合需要频繁创建和销毁执行单元的场景(如 Web 服务器处理短期请求)。
- 资源利用率高 :
- 多线程共享进程资源,无需重复分配内存、文件等,节省系统资源;
- 多核 CPU 环境下,多线程可以并行执行,充分利用 CPU 核心(如 4 核 CPU 可以同时运行 4 个线程)。
- I/O 与计算重叠 :
- 当一个线程等待 I/O 操作(如网络数据接收、磁盘读写)时,其他线程可以执行计算任务,避免 CPU 空闲;
- 比如下载文件时,一个线程负责下载(I/O),另一个线程负责解析文件内容(计算),提升整体效率。
- 简化编程模型 :
- 多线程共享内存,线程间通信无需复杂的 IPC(进程间通信)机制(如管道、消息队列),直接通过全局变量、堆内存交换数据;
- 适合需要频繁通信的场景(如生产者 - 消费者模型)。
4.2 线程的缺点:多线程编程的 "坑"
- 并发安全问题 :
- 多个线程访问共享资源时,容易出现 "竞态条件(Race Condition)",导致数据不一致;
- 需要使用互斥锁、条件变量等同步机制,增加编程复杂度,还可能引入死锁、活锁等新问题。
- 健壮性低 :
- 线程共享进程的虚拟地址空间,一个线程的错误会影响整个进程;
- 比如线程 A 出现野指针,修改了进程的代码段或数据段,会导致整个进程崩溃,所有线程都终止。
- 调试难度大 :
- 多线程的执行顺序是不确定的(受 CPU 调度影响),可能出现 "偶发 bug"(如某些调度顺序下才会触发的竞态条件);
- 调试时难以复现问题,需要使用专门的工具(如 gdb 的
thread命令、Valgrind 的helgrind工具)。
- CPU 密集型任务的性能瓶颈 :
- 对于 CPU 密集型任务(如视频编码、数学计算),线程数超过 CPU 核心数时,线程切换开销会抵消并行带来的收益;
- 比如 4 核 CPU,创建 8 个 CPU 密集型线程,每个线程的实际运行时间会增加(因为需要频繁切换)。
- 与进程之间的切换相比,线程之间的切换需要操作系统做的工作要少很多
- 最主要的区别是线程的切换虚拟内存空间依然是相同的,但是进程切换是不同的。这两种上下文切换的处理都是通过操作系统内核来完成的。内核的这种切换过程伴随的最显著的性能损耗是将寄存器中的内容切换出。
- 另外一个隐藏的损耗是上下文的切换会扰乱处理器的缓存机制。简单的说,一旦去切换上下文,处理器中所有已经缓存的内存地址一瞬间都作废了。还有一个显著的区别是当你改变虚拟内存空间的时候,处理的页表缓冲TLB (快表)会被全部刷新,这将导致内存的访问在一段时间内相当的低效。但是在线程的切换中,不会出现这个问题,当然还有硬件cache。
4.3 线程的典型应用场景
- I/O 密集型任务 :
- 场景:Web 服务器、数据库服务器、文件服务器等,需要处理大量客户端的 I/O 请求;
- 原理:每个客户端请求对应一个线程,线程等待 I/O 时,其他线程可以处理其他请求,提升并发处理能力;
- 示例:Nginx 服务器的 "多线程 + I/O 多路复用" 模型,每秒可处理数万甚至数十万请求。
- CPU 密集型任务 :
- 场景:视频编码、图像处理、科学计算等,需要充分利用多核 CPU;
- 原理:将任务拆分成多个子任务,每个子任务对应一个线程,分配到不同的 CPU 核心并行执行;
- 示例:用 OpenCV 处理一张大图时,将图像分成多个区域,每个线程处理一个区域,提升处理速度。
- 提升程序响应性 :
- 场景:图形界面(GUI)程序、桌面应用等,需要同时处理用户交互和后台任务;
- 原理:主线程处理用户输入(如点击按钮、键盘输入),后台线程处理耗时任务(如文件下载、数据计算),避免界面卡顿;
- 示例:微信客户端,主线程显示聊天窗口,后台线程负责接收消息、下载图片和视频。
- 并行计算 :
- 场景:大数据处理、人工智能训练等,需要对大量数据进行并行运算;
- 原理:利用多线程将数据分片处理,最后合并结果;
- 示例:用 C++ 的
std::thread或 Python 的multiprocessing.dummy(多线程版)处理大规模数据集。
线程到底有啥用?
咱们先抛个核心结论:线程就是给程序开 "分身",让它能 "一心多用",不浪费时间、不耽误事!
用最直白的话讲:你一个人干 10 件事要 10 小时,开 10 个 "分身" 同时干,1 小时就能搞定 ------ 线程就是程序的 "分身术",没有它,现在的微信、抖音、网页都得卡成 "幻灯片"!
一、先搞懂:没有线程的世界,有多 "低效"?
咱们用 2 个生活场景,看看没有线程会有多憋屈:
场景 1:你一个人做饭(单线程)
- 流程:淘米→等水烧开(10 分钟)→煮饭→等饭熟(20 分钟)→切菜→炒菜(15 分钟)
- 问题:等水烧开、等饭熟的 30 分钟里,你只能坐着刷手机,啥也干不了!
- 总耗时:45 分钟(实际干活 15 分钟,浪费 30 分钟)
场景 2:餐厅只有 1 个服务员(单线程)
- 流程:接待顾客 A→下单→站在厨房门口等菜(20 分钟)→端给 A→再接待顾客 B
- 问题:顾客 B 要等 20 分钟才有人理,气得直接走了!
- 结果:餐厅一天只能接几桌客人,早晚会倒闭!
这就是 "单线程程序" 的痛点:遇到 "等待"(比如等水开、等厨房做菜、等网络数据)就只能傻等,CPU 闲着没事干,效率低到离谱!
二、有了线程:给程序开 "分身",效率直接翻倍!
还是上面两个场景,开了 "线程分身" 后,一切都变了:
场景 1:3 个 "分身" 一起做饭(多线程)
- 分身 1:淘米→等水烧开(同时干别的)
- 分身 2:趁水烧开、饭煮熟的时间,切菜、备调料
- 分身 3:饭一熟就炒菜,不用等
- 总耗时:25 分钟(没有一秒浪费,3 个 "分身" 各司其职)
场景 2:餐厅 3 个服务员(多线程)
- 服务员 1:接待顾客 A、下单,然后去接待顾客 B(不用等菜)
- 服务员 2:接待顾客 C、下单,然后去收拾桌子
- 服务员 3:专门在厨房门口等菜,菜好就端给顾客
- 结果:顾客不用等,餐厅一天能接几十桌,生意火爆!
线程的核心作用就是:把 "等待时间" 利用起来,让多个任务并行执行,不浪费 CPU 资源!
三、线程的 3 个核心用途:生活例子 + 实际场景
线程不是 "花架子",咱们日常用的软件,全靠它撑着:
1. 高并发:Web 服务器为啥能同时接待上万人?
- 痛点:如果一个网页服务器是 "单线程",一次只能处理 1 个用户请求(比如查数据要 50ms),1000 个用户就得排队 50 秒,早就没人用了!
- 线程解决方案:给服务器开 1000 个线程,每个用户请求对应一个线程 ------ 当 A 用户的线程在等数据库返回时,B 用户的线程可以直接处理,C 用户的也不耽误。
- 实际效果:每秒能处理上万次请求,你刷抖音、逛淘宝时,从来不用等 "前面的人用完",就是线程的功劳!
- 生活类比:就像银行开了 10 个窗口,100 个人不用排队,哪个窗口空了就去哪个,效率翻倍!
2. 快速度:视频渲染、大数据计算为啥能省时间?
- 痛点:渲染一个 4K 视频,单线程要 4 小时(CPU 只用到 1 个核心,其他 3 个核心在 "摸鱼");处理 100 万条数据,单线程要 1 小时。
- 线程解决方案:开 4 个线程,把视频切成 4 段、数据分成 4 份,每个线程用 1 个 CPU 核心并行处理。
- 实际效果:4 小时的视频 1 小时搞定,1 小时的数据 15 分钟处理完!
- 生活类比:缝一件衣服,1 个人要 4 小时;4 个人分工,1 人裁布、1 人缝袖子、1 人钉扣子、1 人熨烫,1 小时就完工!
3. 不卡顿:微信、VS Code 为啥点了就有反应?
- 痛点:如果微信是 "单线程",你发送一张 100MB 的大图片时,微信会卡住 5 秒 ------ 因为主线程在忙着读图片文件,没时间处理你的 "返回""打字" 操作。
- 线程解决方案:主线程专门负责界面(你点按钮、打字,立刻有反应),开一个 "后台线程" 专门处理图片发送(读文件、传数据),两个线程互不干扰。
- 实际效果:你发图片时,还能正常聊天、刷朋友圈,完全不卡顿!
- 生活类比:你看电视(主线程),同时让家人去厨房煮奶茶(后台线程)------ 你不用暂停看电视等奶茶,奶茶煮好也不耽误你追剧!
四、代码例子:一行行看懂 "单线程" 和 "多线程" 的区别
不用怕代码,咱们看最简化的例子,核心就是 "能不能同时干多件事":
1. 单线程:下载 10 个文件要 100 秒
cpp
// 下载1个文件要10秒
void download_file(int num) {
printf("开始下载文件%d...\n", num);
sleep(10); // 模拟下载等待(比如等网络数据)
printf("文件%d下载完成!\n", num);
}
// 单线程下载:一个一个来
int main() {
for (int i=0; i<10; i++) {
download_file(i); // 先下载0,再下载1...依次等
}
return 0;
}- 运行结果:10 个文件按顺序下载,总耗时 100 秒(中间全是等待时间)。
2. 多线程:下载 10 个文件只要 10 秒
cpp
#include <pthread.h>
#include <stdio.h>
#include <unistd.h>
void* download_file(void* arg) {
int num = *(int*)arg;
printf("开始下载文件%d...\n", num);
sleep(10); // 等待时,其他线程可以干活
printf("文件%d下载完成!\n", num);
return NULL;
}
// 多线程下载:10个分身同时干
int main() {
pthread_t tid[10]; // 10个线程(10个分身)
int nums[10];
// 创建10个线程,同时启动下载
for (int i=0; i<10; i++) {
nums[i] = i;
pthread_create(&tid[i], NULL, download_file, &nums[i]);
}
// 等待所有线程下载完成
for (int i=0; i<10; i++) {
pthread_join(tid[i], NULL);
}
return 0;
}- 运行结果:10 个文件同时开始下载,10 秒后全部完成 ------ 等待时间被 "共享" 了,效率直接 ×10!
五、总结:线程 = 程序的 "效率神器",一句话讲透
- 单线程:一个人干所有事,遇到等待就停工,效率低;
- 多线程:多个人一起干,有人等待时有人干活,不浪费时间。
用 3 个生活比喻,记死线程的作用:
- 线程 = 餐厅的 "多个服务员":不用让顾客排队等,同时接待多人;
- 线程 = 做饭的 "多个分身":等水开、等饭熟的时间,能做别的事;
- 线程 = 手机的 "后台应用":刷视频时,微信能同时收消息,互不干扰。
最后一个小提醒:线程虽好,别贪多!
就像分身太多会 "精神错乱",线程太多也会出问题:
- 比如 CPU 只有 4 个核心,你开 100 个线程,CPU 得不停 "切换分身"(每个线程干 1 秒就换),反而浪费时间;
- 合理线程数:一般是 "CPU 核心数 ×2"(比如 4 核 CPU 开 8 个线程),既能充分利用资源,又不浪费切换时间。
现在你该懂了吧?线程就是现代软件的 "效率基石"------ 没有它,就没有能同时聊天、刷视频的手机,没有能同时接待上万人的网站,没有能快速渲染视频的软件!下次用这些工具时,不妨想想:背后全是线程在 "默默分身干活" 呢~
五、总结:线程与分页的 "底层协同" 支撑现代操作系统
线程和分页存储管理是 Linux 系统的两大核心机制,它们一上一下、协同工作,支撑了现代操作系统的 "多任务、高并发、高效能":
- 分页存储管理是 "底层基石":它解决了物理内存的碎片化和地址隔离问题,让进程可以安全、高效地使用内存,还通过虚拟内存实现了 "按需分配" 和 "内存扩展"(Swap 分区);
- 线程是 "上层执行单元":它让进程内部的任务可以并行执行,充分利用 CPU 资源,降低了并发编程的开销,成为构建高性能程序的核心工具。
结语:于底层肌理处,看见技术世界的心跳
当我们终于把 "线程" 的轻捷与 "分页" 的精妙铺陈开来,回头望时,你会发现自己已经走过了一段从 "知其然" 到 "知其所以然" 的旅程 ------ 从最初对 "线程是什么" 的懵懂,到能拆解task_struct的共享与私有;从对 "虚拟内存" 的模糊认知,到能一步步推演虚拟地址到物理地址的转换流程。这一路,我们啃下的不只是 "知识点",更是操作系统世界的 "底层逻辑",是那些支撑着我们每天打开的软件、刷过的网页、运行的程序的 "隐形骨架"。
你有没有想过?当你打开浏览器同时浏览十个标签页,背后是线程在 CPU 里交替奔跑,分页机制在默默调配内存,让每个标签页既不互相干扰,又能高效共享资源;当你用微信发送一张图片,主线程负责界面响应,后台线程处理图片压缩与传输,分页让内存按需分配,哪怕图片再大,也不会让系统卡顿 ------ 我们习以为常的 "流畅" 与 "高效",从来都不是凭空而来,而是这些被我们反复咀嚼的mm_struct、页表、task_struct,在底层精密协作的结果。
我知道,学习这些内容的过程里,你一定有过困惑:比如第一次理解 "线程是共享资源的进程" 时的恍惚,拆解二级页表地址转换时对着二进制位的头疼,琢磨缺页异常 "软" 与 "硬" 的区别时的迷茫...... 但请你相信,这些 "磕磕绊绊" 恰恰是成长的证明。因为操作系统的魅力,从来不在 "一眼看懂" 的浅薄里,而在 "层层剥开" 后的通透中。当你终于明白 "为什么线程切换比进程快" 时,当你能说出 "malloc 只是预留虚拟地址而非分配物理内存" 时,你已经拥有了超越 "表层使用" 的能力 ------ 你开始能 "看见" 程序运行的底层图景,能在遇到 bug 时穿透现象看本质,能在设计系统时考虑到资源与效率的平衡。
这些看似 "枯燥" 的底层知识,其实是技术人最坚实的 "底气"。如今的行业里,太多人追逐着框架的更迭、语言的新潮,却忘了 "万丈高楼平地起" 的道理。可你要知道,无论前端框架如何迭代,后端架构怎样升级,支撑它们运行的,永远是我们今天聊的线程调度、内存管理。就像建筑师不懂力学原理,永远建不出稳固的大厦;技术人不懂操作系统底层,也终究只能停留在 "调用 API" 的层面,难以触及真正的核心与创新。
我还记得自己第一次啃透分页机制时的心情 ------ 突然就懂了,为什么小时候用电脑时 "内存不足" 的提示会频繁出现,而现在的系统却能同时跑几十个程序;为什么有些软件关闭后再打开会更快,有些却总是 "重新加载"。那种 "打通任督二脉" 的通透感,是任何表层技巧的学习都无法比拟的。而我希望,你也能在这次学习中,收获这样的 "通透"------ 不是记住几个结构体的名字,而是理解它们为什么被设计出来,理解每一个字段、每一个标志位背后的 "权衡与智慧"。
比如struct page里的_mapcount,藏着 "共享" 的巧思;页表项里的A位(访问位),支撑着 LRU 算法的运转;线程的私有栈与共享地址空间,平衡着 "独立" 与 "协作" 的需求 ------ 这些设计里,没有一处是 "随便" 的,全是前辈工程师们在性能与资源、复杂与简洁之间反复推敲的结果。而我们学习这些,不只是为了 "掌握知识",更是为了传承这种 "权衡的智慧",为了在未来自己写代码、做设计时,也能多一份底层的考量,多一份对 "为什么这么做" 的追问。
当然,这绝不是你学习的终点。操作系统的世界远比我们今天聊的更广阔:比如多级页表之外的 "巨型页",线程之上的 "协程",还有内存屏障、缓存一致性这些更深邃的话题...... 但请你不要害怕 "未知",因为你已经迈出了最关键的一步 ------ 你已经愿意沉下心来,去触碰那些 "看不见却至关重要" 的底层逻辑。这就像登山,当你站在 "线程与分页" 的山腰回望,会发现自己已经越过了最陡峭的坡,前路的风景只会更壮阔。
最后,想对你说:技术的学习从来不是一场 "速通游戏",而是一场 "慢慢走,深深爱" 的旅程。当你下次打开电脑,不妨多一份 "好奇"------ 好奇你敲下的一行代码如何被线程执行,好奇你分配的一块内存如何被分页映射。正是这些藏在细节里的 "底层之美",构成了技术世界最动人的心跳。愿你永远保持这份对底层的追问与热爱,在技术的道路上,一步一步,走得扎实,走得坦荡,终能看见别人看不见的风景,做出别人做不出的深度。毕竟,那些能真正改变世界的技术,从来都诞生于对 "底层" 最执着的探索里。