
在大数据时代,Hadoop 早已成为处理海量数据的 "标配工具",但手动搭集群的各种依赖冲突、环境配置问题,却常常让新手望而却步。而 Docker 容器的出现,完美解决了这一痛点:通过容器化部署,我们可以快速拉起一套标准、可复现的 Hadoop 集群,告别 "环境不一致" 的烦恼。本项目正是基于 Docker 搭建的 Hadoop 集群,完成交通流量数据的分布式统计,既体验了 Hadoop 分式计算的核心流程,也感受了容器技术给大数据开发带来的便捷与高效。
目录
[一. 项目准备->环境配置及安装](#一. 项目准备->环境配置及安装)
[1. 克隆Hadoop集群官方稳定项目](#1. 克隆Hadoop集群官方稳定项目)
[1.1 docker-compose.yml 修改(直接粘贴即可,新增管理Mapreduce可视化端口开放)](#1.1 docker-compose.yml 修改(直接粘贴即可,新增管理Mapreduce可视化端口开放))
[1.2 一键启动](#1.2 一键启动)
[2. Eclipse 安装及 winutils.exe配置](#2. Eclipse 安装及 winutils.exe配置)
[2.1 Eclipse安装流程](#2.1 Eclipse安装流程)
[2.2 什么是 winutils.exe?及配置步骤(生产环境及客户端所需/docker部署集群需打包jar文件到容器中运行)](#2.2 什么是 winutils.exe?及配置步骤(生产环境及客户端所需/docker部署集群需打包jar文件到容器中运行))
[2.2.1 连接地址下载Winutils对应版本](#2.2.1 连接地址下载Winutils对应版本)
[2.2.2 下载好配置环境变量重启电脑(环境变量配置位置为如下)](#2.2.2 下载好配置环境变量重启电脑(环境变量配置位置为如下))
[2.2.3 环境变量配置成果截图](#2.2.3 环境变量配置成果截图)
[二. HDFS文件操作(容器执行/也可用Hadoop Java API实现)](#二. HDFS文件操作(容器执行/也可用Hadoop Java API实现))
[1. HDFS存放交通数据目录创建](#1. HDFS存放交通数据目录创建)
[2. 交通数据文件上传到HDFS](#2. 交通数据文件上传到HDFS)
[3. 查看HDFS文件内容](#3. 查看HDFS文件内容)
[4. 删除HDFS文件](#4. 删除HDFS文件)
[二. Eclipse Hadoop集群连接](#二. Eclipse Hadoop集群连接)
[1. eclipse项目新建](#1. eclipse项目新建)
[2. 创建完成](#2. 创建完成)
[3. 查看自己hadoop 集群版本](#3. 查看自己hadoop 集群版本)
[4. 下载对应版本的 Hadoop 到本地](#4. 下载对应版本的 Hadoop 到本地)
[5. 导入 Eclipse hadoop相对应依赖包](#5. 导入 Eclipse hadoop相对应依赖包)
[6. 点击Eclipse新建项目主目录](#6. 点击Eclipse新建项目主目录)
[7. 选取claasspath->点击Add External JARs 在弹出的窗口里,找到本地的 Hadoop 安装目录并依次导入这些关键路径下的所有 JAR 包](#7. 选取claasspath->点击Add External JARs 在弹出的窗口里,找到本地的 Hadoop 安装目录并依次导入这些关键路径下的所有 JAR 包)
[8. 导入完成后,点击 Apply and Close,回到代码界面](#8. 导入完成后,点击 Apply and Close,回到代码界面)
[9. 创建 HDFS 连接测试程序](#9. 创建 HDFS 连接测试程序)
[编辑10. Eclipse 项目连接 Docker 里的 Hadoop 集群](#编辑10. Eclipse 项目连接 Docker 里的 Hadoop 集群)
[11. 连接结果测试](#11. 连接结果测试)
[三. 配置Hadoop Java API](#三. 配置Hadoop Java API)
[1. java api 文件创建](#1. java api 文件创建)
[2. 编写代码](#2. 编写代码)
[四. Eclipse导出jar包(因为容器部署所以需在容器内执行,如果为生产环境机器直接在Eclipse运行文件就可)](#四. Eclipse导出jar包(因为容器部署所以需在容器内执行,如果为生产环境机器直接在Eclipse运行文件就可))
[1. Eclipse 导出 Jar 包 Java 项目 → Export → JAR file 选择导出路径,生成 traffic.jar](#1. Eclipse 导出 Jar 包 Java 项目 → Export → JAR file 选择导出路径,生成 traffic.jar)
[2. 把 Jar 传到容器里 打开 Windows CMD 执行:](#2. 把 Jar 传到容器里 打开 Windows CMD 执行:)
[3. 上传成功结果](#3. 上传成功结果)
[4. 容器内运行 MapReduce 任务](#4. 容器内运行 MapReduce 任务)
[5. 查看最终结果 在当前容器内执行:](#5. 查看最终结果 在当前容器内执行:)
[6. 查询与管理MapReduce任务](#6. 查询与管理MapReduce任务)
[五. 生产环境及Docker hadoop集群的区别](#五. 生产环境及Docker hadoop集群的区别)
[1.导出 Jar 放入容器运行的原因](#1.导出 Jar 放入容器运行的原因)
[2. Windows 本地无法完整连接容器集群](#2. Windows 本地无法完整连接容器集群)
[3. 生产 Linux 服务器可以正常访问](#3. 生产 Linux 服务器可以正常访问)
一. 项目准备->环境配置及安装
1. 克隆Hadoop集群官方稳定项目
python
git clone https://github.com/big-data-europe/docker-hadoop.git
cd docker-hadoop1.1 docker-compose.yml 修改(直接粘贴即可,新增管理Mapreduce可视化端口开放)
python
version: "3"
services:
namenode:
image: bde2020/hadoop-namenode:2.0.0-hadoop3.2.1-java8
container_name: namenode
restart: always
ports:
- 9870:9870
- 9000:9000
volumes:
- hadoop_namenode:/hadoop/dfs/name
environment:
- CLUSTER_NAME=test
env_file:
- ./hadoop.env
datanode:
image: bde2020/hadoop-datanode:2.0.0-hadoop3.2.1-java8
container_name: datanode
restart: always
ports: # 新增 DataNode 端口映射
- 9864:9864
- 9866:9866
volumes:
- hadoop_datanode:/hadoop/dfs/data
environment:
SERVICE_PRECONDITION: "namenode:9870"
env_file:
- ./hadoop.env
resourcemanager:
image: bde2020/hadoop-resourcemanager:2.0.0-hadoop3.2.1-java8
container_name: resourcemanager
restart: always
ports:
- 8032:8032
- 8088:8088
environment:
SERVICE_PRECONDITION: "namenode:9000 namenode:9870 datanode:9864"
env_file:
- ./hadoop.env
nodemanager1:
image: bde2020/hadoop-nodemanager:2.0.0-hadoop3.2.1-java8
container_name: nodemanager
restart: always
ports:
- 8042:8042
environment:
SERVICE_PRECONDITION: "namenode:9000 namenode:9870 datanode:9864 resourcemanager:8088"
env_file:
- ./hadoop.env
historyserver:
image: bde2020/hadoop-historyserver:2.0.0-hadoop3.2.1-java8
container_name: historyserver
restart: always
ports:
- 8188:8188
environment:
SERVICE_PRECONDITION: "namenode:9000 namenode:9870 datanode:9864 resourcemanager:8088"
volumes:
- hadoop_historyserver:/hadoop/yarn/timeline
env_file:
- ./hadoop.env
volumes:
hadoop_namenode:
hadoop_datanode:
hadoop_historyserver:1.2 一键启动
python
docker-compose up -d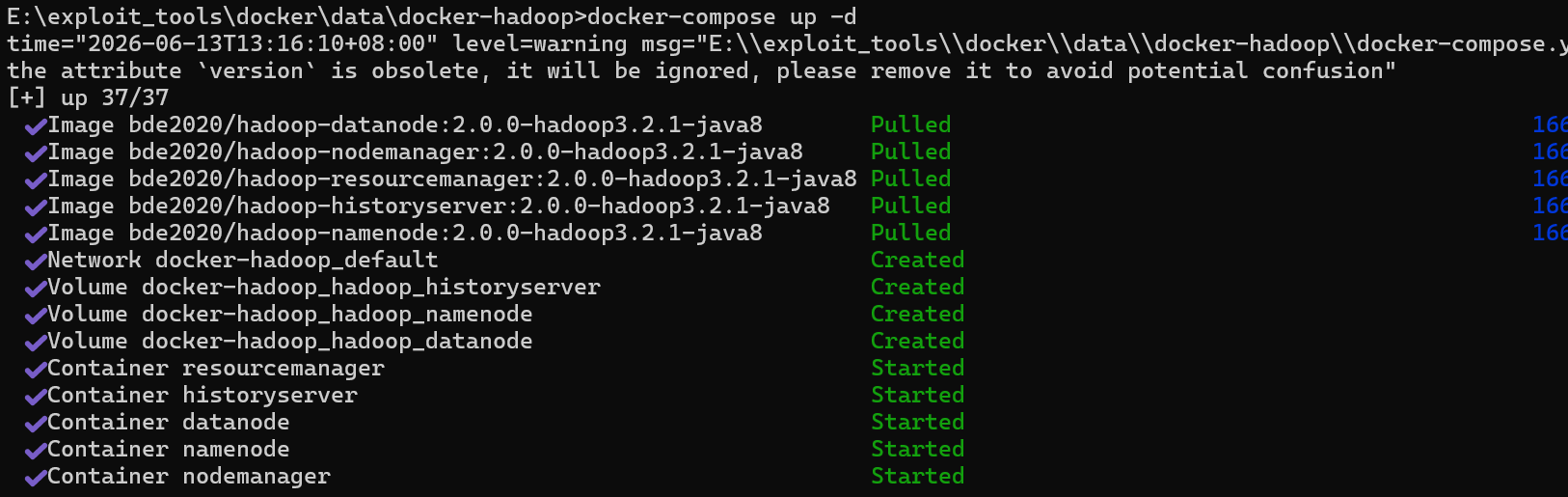
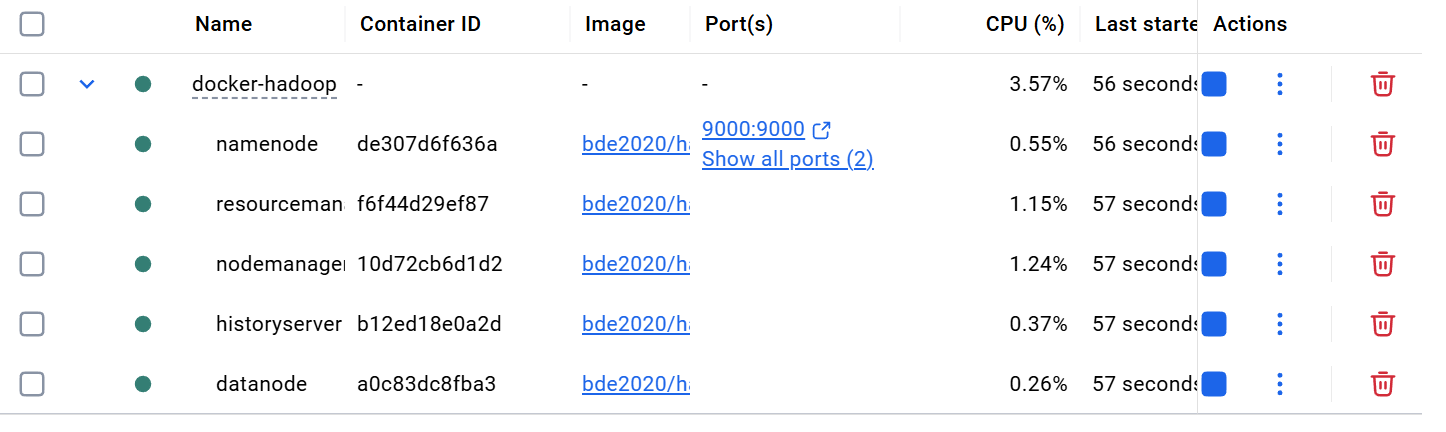
2. Eclipse 安装及 winutils.exe配置
2.1 Eclipse安装流程
python
安装地址
https://www.eclipse.org/downloads/packages/
2.2 什么是 winutils.exe?及配置步骤(生产环境及客户端所需/docker部署集群需打包jar文件到容器中运行)
Hadoop 原生基于 Linux 系统开发,大量底层操作(文件权限、目录创建、用户组、系统命令调用)都依赖 Linux 内核接口。
而 Windows 系统没有对应的系统 API,winutils.exe 就是 Hadoop 官方提供的 Windows 兼容工具集,专门用来模拟 Linux 系统调用,让 Windows 上的 Hadoop 客户端、Eclipse 插件正常工作。
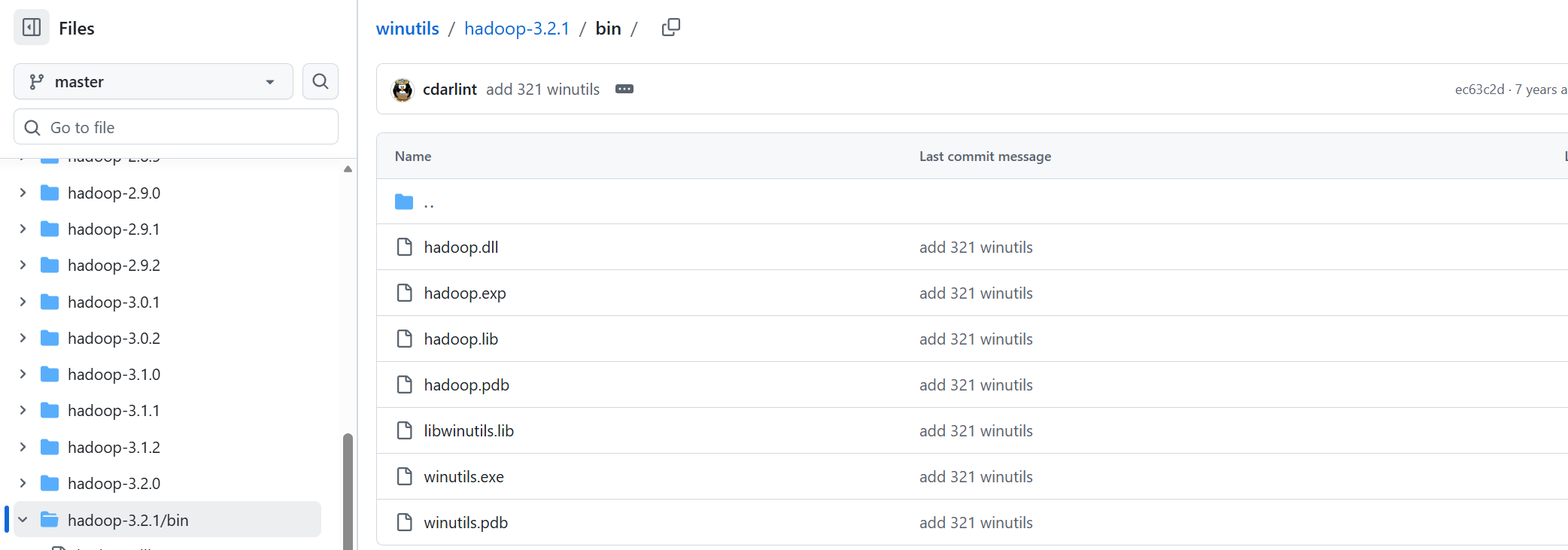
2.2.1 连接地址下载Winutils对应版本
winutils/hadoop-3.2.1/bin at master · cdarlint/winutils · GitHub
2.2.2 下载好配置环境变量重启电脑(环境变量配置位置为如下)
hadoop.dll 再复制一份到:C:\Windows\System32
2.2.3 环境变量配置成果截图
二. HDFS文件操作(容器执行/也可用Hadoop Java API实现)
1. HDFS 存放交通数据目录创建

2. 交通数据文件上传到HDFS

3. 查看HDFS文件内容
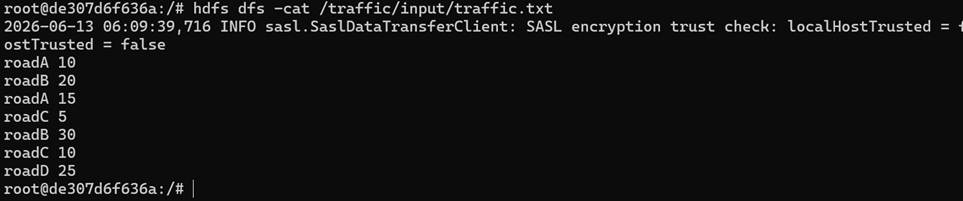
4. 删除HDFS文件

二. Eclipse Hadoop集群连接
1. eclipse项目新建
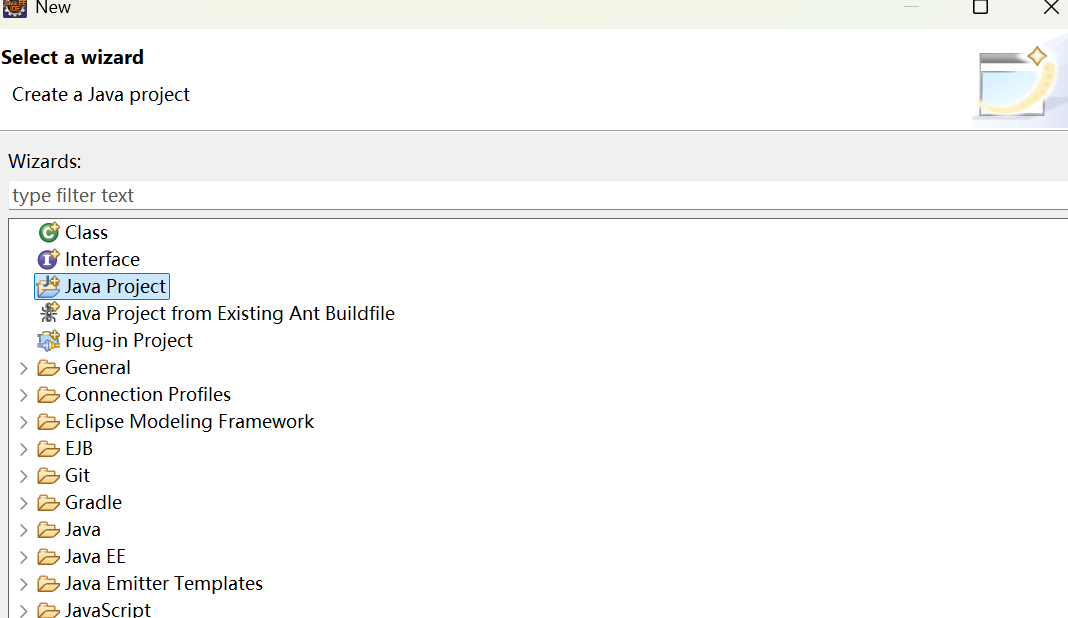
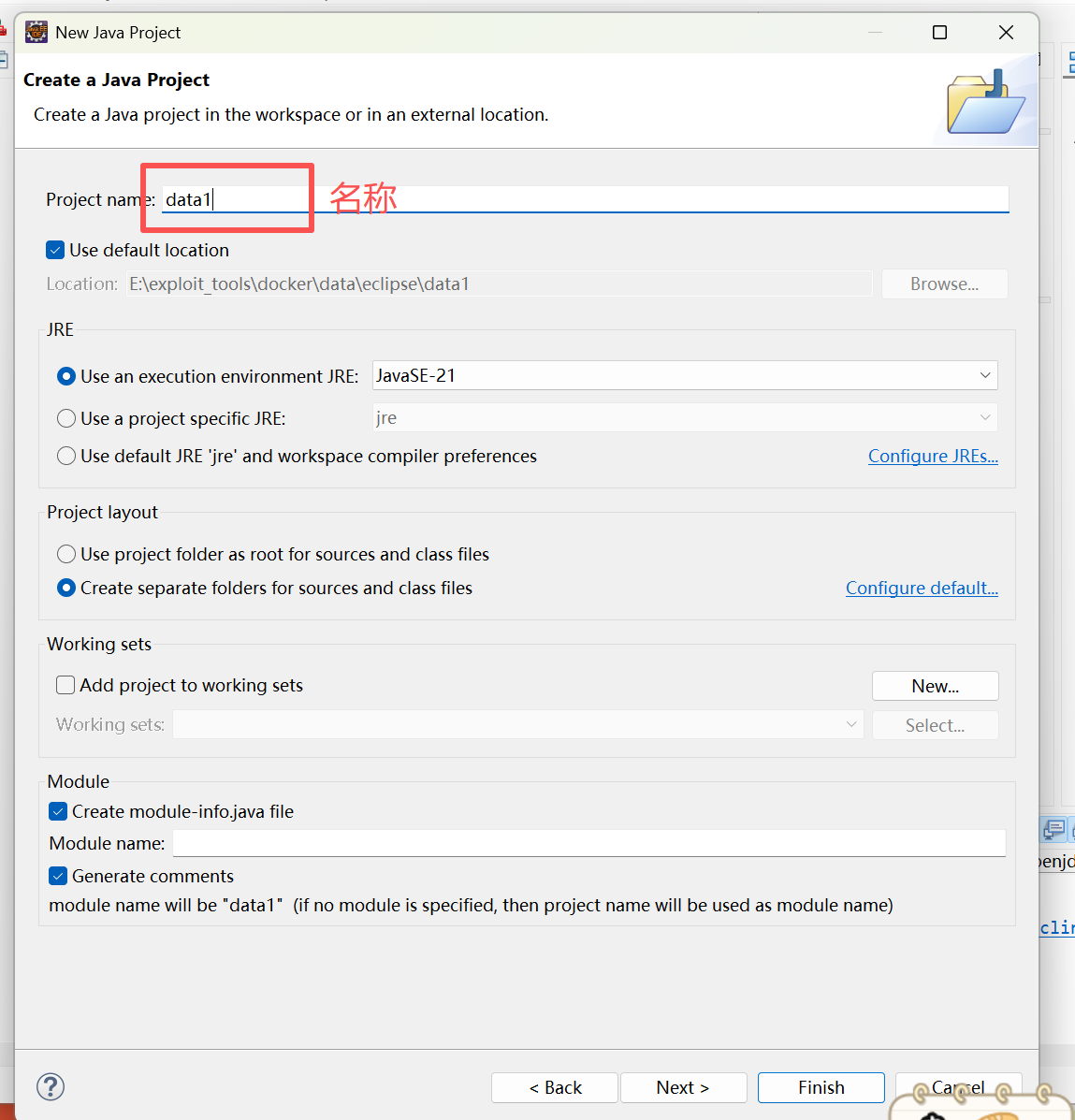
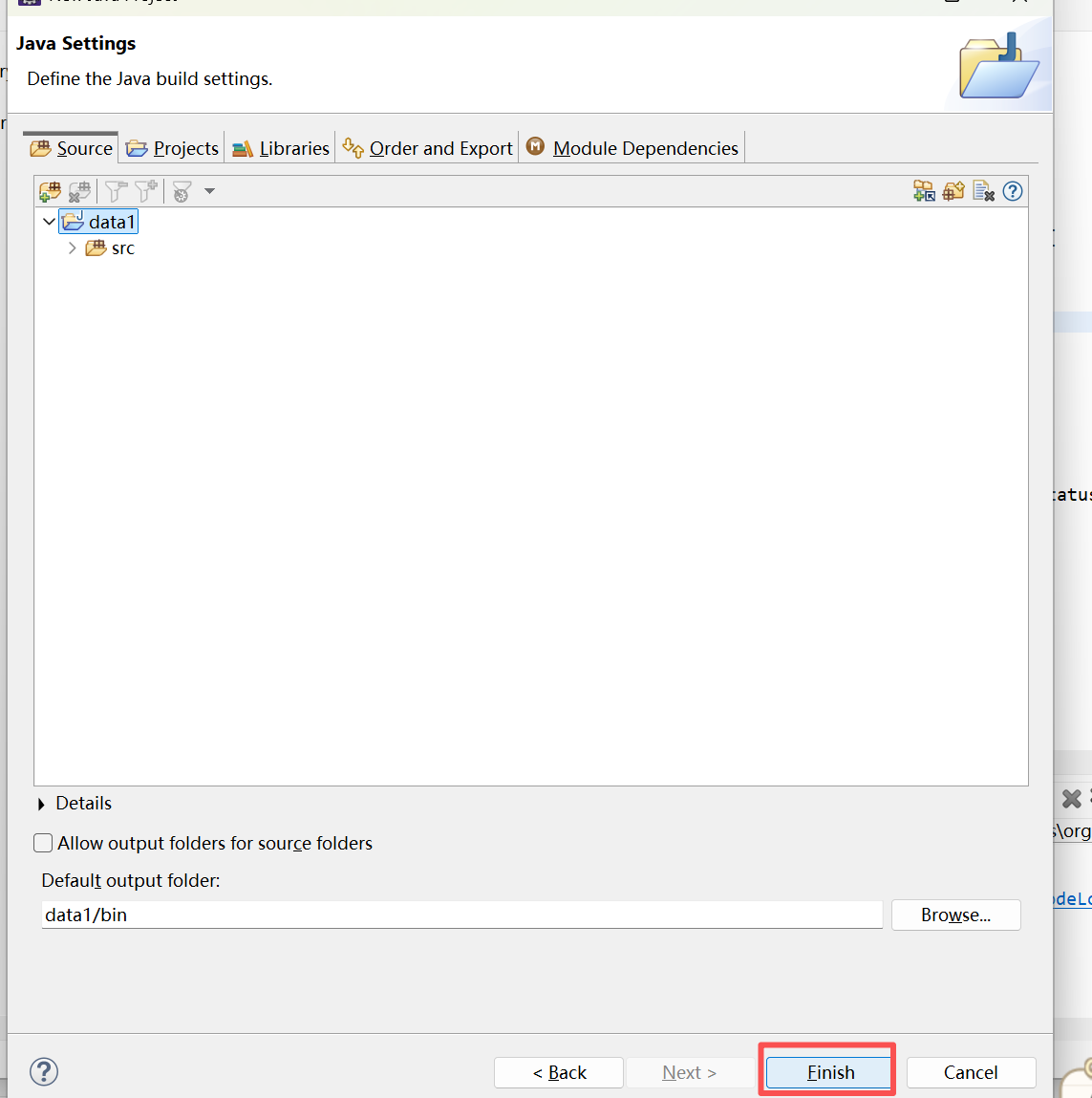
2. 创建完成
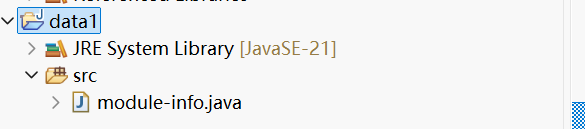
3. 查看自己hadoop 集群版本
python
hadoop version
4. 下载对应版本的 Hadoop 到本地
python
去 Apache 官网下载:
https://archive.apache.org/dist/hadoop/common/5. 导入 Eclipse hadoop相对应依赖包
6. 点击Eclipse新建项目主目录
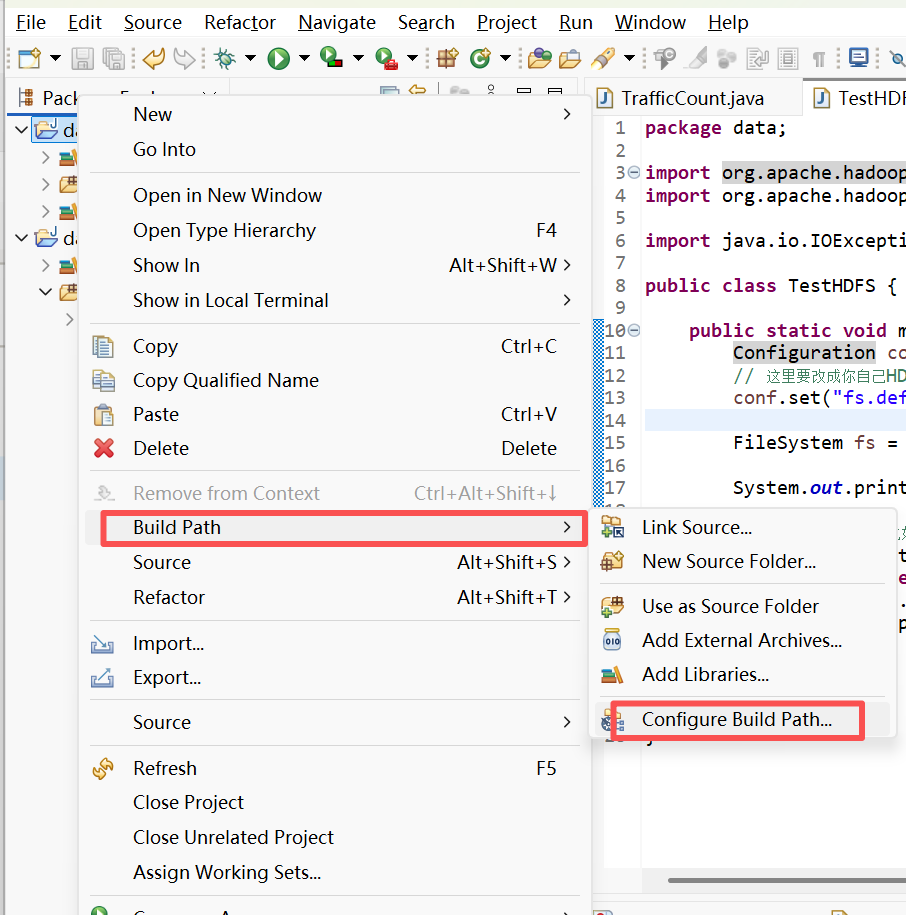
7. 选取claasspath->点击Add External JARs 在弹出的窗口里,找到本地的 Hadoop 安装目录并依次导入这些关键路径下的所有 JAR 包
python
hadoop-3.2.1/share/hadoop/common/*.jar
hadoop-3.2.1/share/hadoop/common/lib/*.jar
hadoop-3.2.1/share/hadoop/hdfs/*.jar
hadoop-3.2.1/share/hadoop/mapreduce/*.jar
hadoop-3.2.1/share/hadoop/yarn/*.jar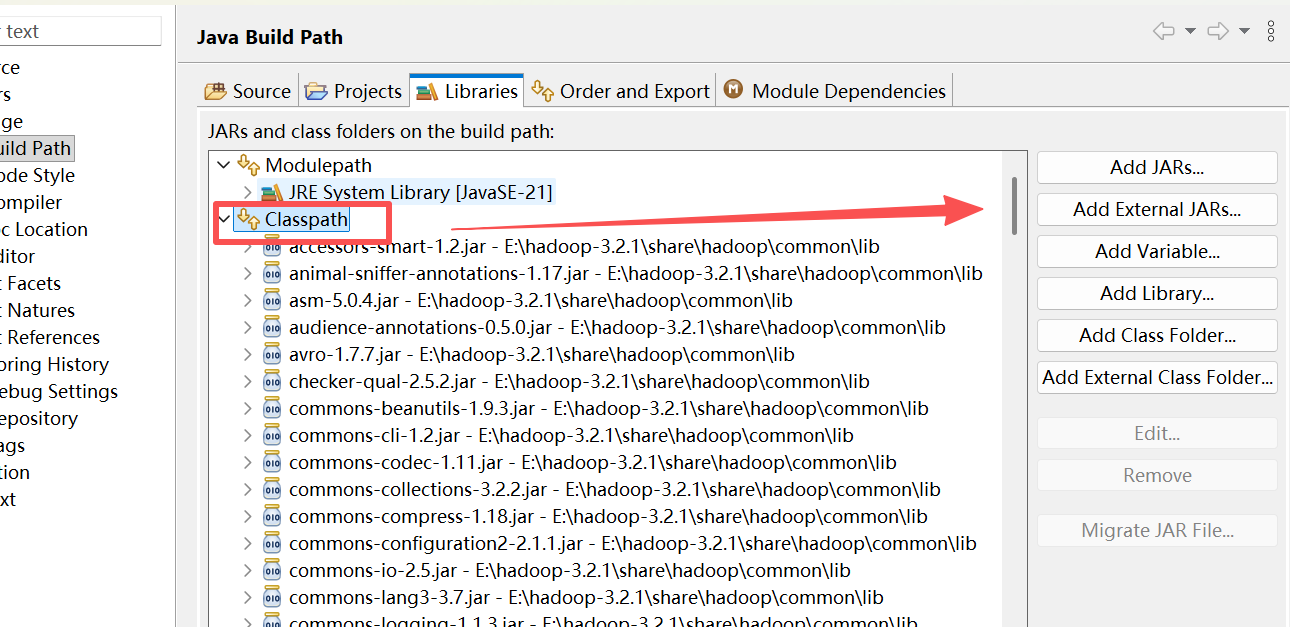
8. 导入完成后,点击 Apply and Close,回到代码界面
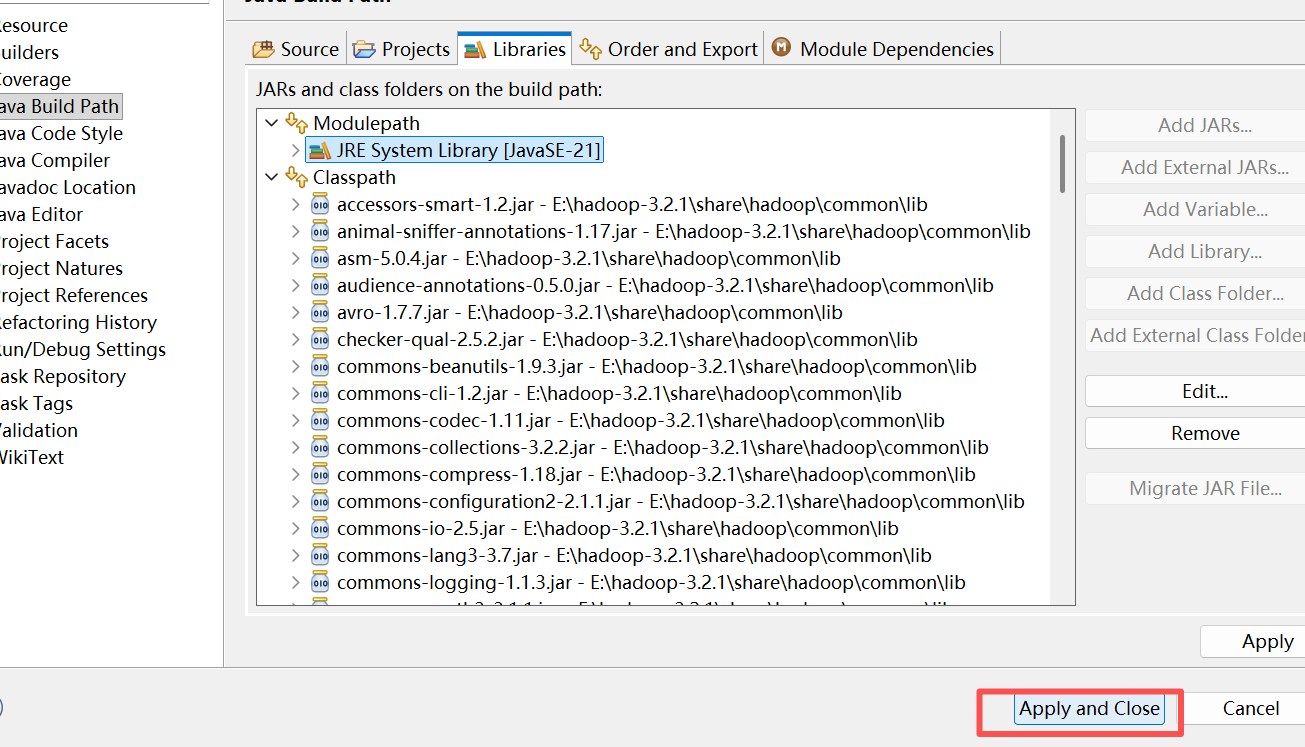
9. 创建 HDFS 连接测试程序
 10. Eclipse 项目连接 Docker 里的 Hadoop 集群
10. Eclipse 项目连接 Docker 里的 Hadoop 集群
python
package data;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import java.io.IOException;
public class TestHDFS {
public static void main(String[] args) throws IOException {
Configuration conf = new Configuration();
// 这里要改成你自己HDFS的地址,比如hdfs://你的服务器IP:9000
conf.set("fs.defaultFS", "hdfs://localhost:9000");
FileSystem fs = FileSystem.get(conf);
System.out.println("✅ HDFS连接成功:" + fs.getUri());
// 可以再加个测试,比如查看根目录
System.out.println("根目录下的文件列表:");
fs.listStatus(new org.apache.hadoop.fs.Path("/"));
for (org.apache.hadoop.fs.FileStatus status : fs.listStatus(new org.apache.hadoop.fs.Path("/"))) {
System.out.println(status.getPath());
}
fs.close();
}
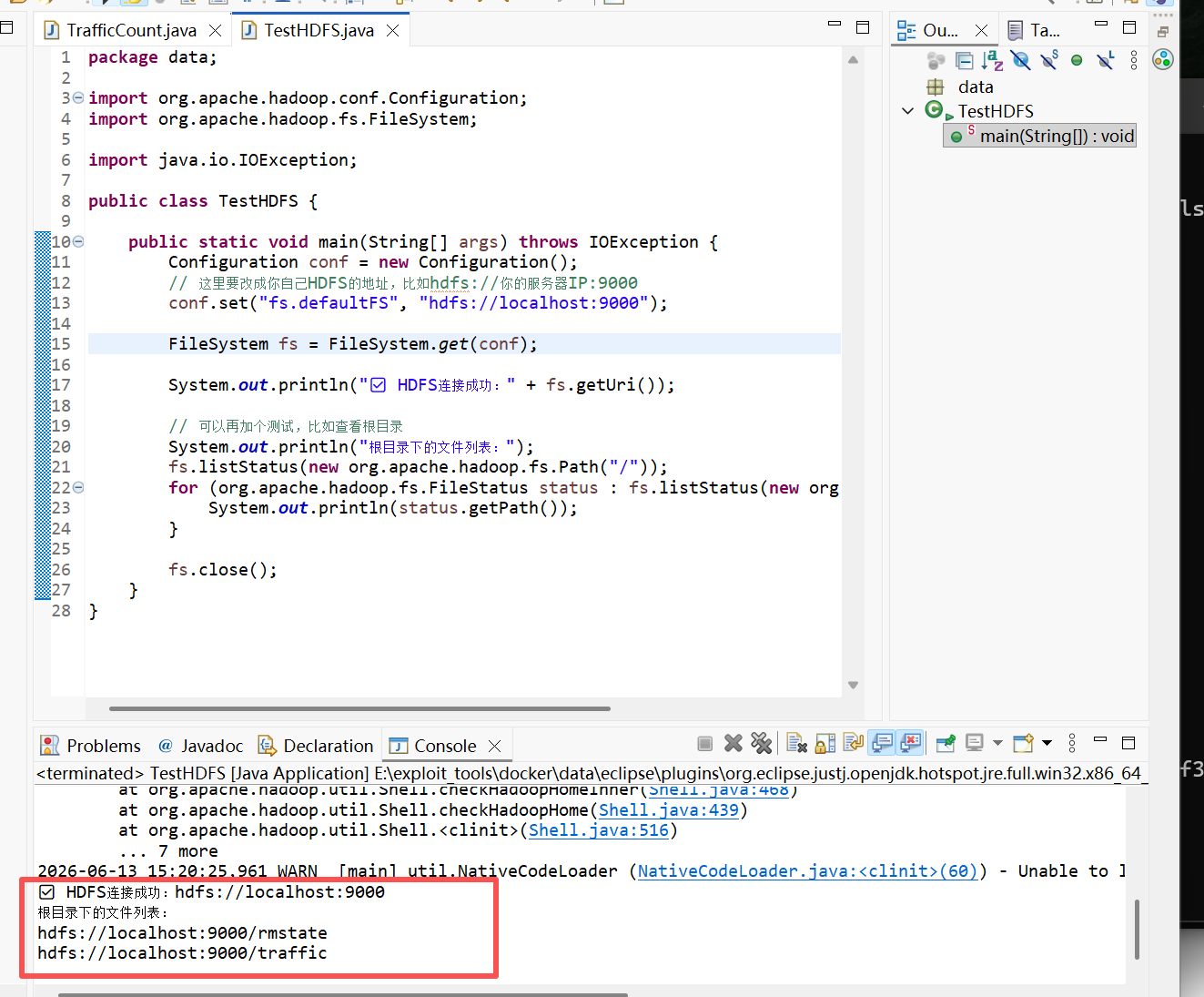
}11. 连接结果测试
三. 配置Hadoop Java API
1. java api 文件创建
2. 编写代码
Hadoop Java API ,借助 Mapper 提取标签、Combiner 本地优化、Reducer 全局汇总,实现对 HDFS 交通数据的分布式统计,最终结果落回 HDFS
python
//读取你上传到 HDFS /traffic/input 里的 traffic.txt 交通数据
//按「路口 ID」统计每个路口的总车流量
//把统计结果输出到 HDFS /traffic/output 目录里
package data;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class TrafficCount {
// ---------------------- Mapper 组件 ----------------------
// 功能:读取每一行 traffic.txt,输出 <路口ID, 1>
public static class TrafficMapper extends Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text crossId = new Text();
@Override
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
// 假设你的 traffic.txt 每行格式:路口ID,时间,车辆数(例:C001,2026-06-13,5)
String[] parts = value.toString().split(",");
if (parts.length >= 1) {
crossId.set(parts[0]); // 取路口ID作为key
context.write(crossId, one); // 输出 <路口ID, 1>
}
}
}
// ---------------------- Reducer 组件 ----------------------
// 功能:汇总每个路口的总车流量
public static class TrafficReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
@Override
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
context.write(key, new IntWritable(sum));
}
}
// ---------------------- Combiner 组件(重点) ----------------------
// 功能:Map 阶段本地预聚合,减少 Shuffle 数据传输量
// 逻辑和 Reducer 完全一致(满足交换律/结合律,适合计数/求和场景)
public static class TrafficCombiner extends Reducer<Text, IntWritable, Text, IntWritable> {
@Override
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
context.write(key, new IntWritable(sum));
}
}
// ---------------------- 主方法:配置并提交任务 ----------------------
public static void main(String[] args) throws Exception {
// 1. 配置 Hadoop 连接信息
Configuration conf = new Configuration();
// conf.set("fs.defaultFS", "hdfs://localhost:9000"); // 外部localhost 内部容器名称或者ip
conf.set("fs.defaultFS", "hdfs://namenode:9000"); // 和你 TestHDFS 里的地址一致
conf.set("mapreduce.framework.name", "yarn"); // 使用 YARN 调度
// 2. 创建 Job 实例
Job job = Job.getInstance(conf, "traffic_count_job");
job.setJarByClass(TrafficCount.class); // 设置主类
// 3. 配置 Mapper/Reducer/Combiner
job.setMapperClass(TrafficMapper.class);
job.setCombinerClass(TrafficCombiner.class); // 启用 Combiner
job.setReducerClass(TrafficReducer.class);
// 4. 设置输出键值类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 5. 设置输入输出路径(和你之前的 HDFS 路径对应)
FileInputFormat.addInputPath(job, new Path("/traffic/input"));
FileOutputFormat.setOutputPath(job, new Path("/traffic/output")); // 注意:这个目录必须不存在!
// 6. 提交任务并等待完成
boolean success = job.waitForCompletion(true);
System.exit(success ? 0 : 1);
}
}四. Eclipse导出jar包(因为容器部署所以需在容器内执行,如果为生产环境机器直接在Eclipse运行文件就可)
在容器删除旧输出目录
# 进入 namenode 容器
docker exec -it namenode bash
# 删除输出文件夹
hdfs dfs -rm -r /traffic/output1. Eclipse 导出 Jar 包 Java 项目 → Export → JAR file 选择导出路径,生成 traffic.jar

2. 把 Jar 传到容器里 打开 Windows CMD 执行:
python
docker cp 你的Jar文件路径/traffic.jar namenode:/3. 上传成功结果

4. 容器内运行 MapReduce 任务
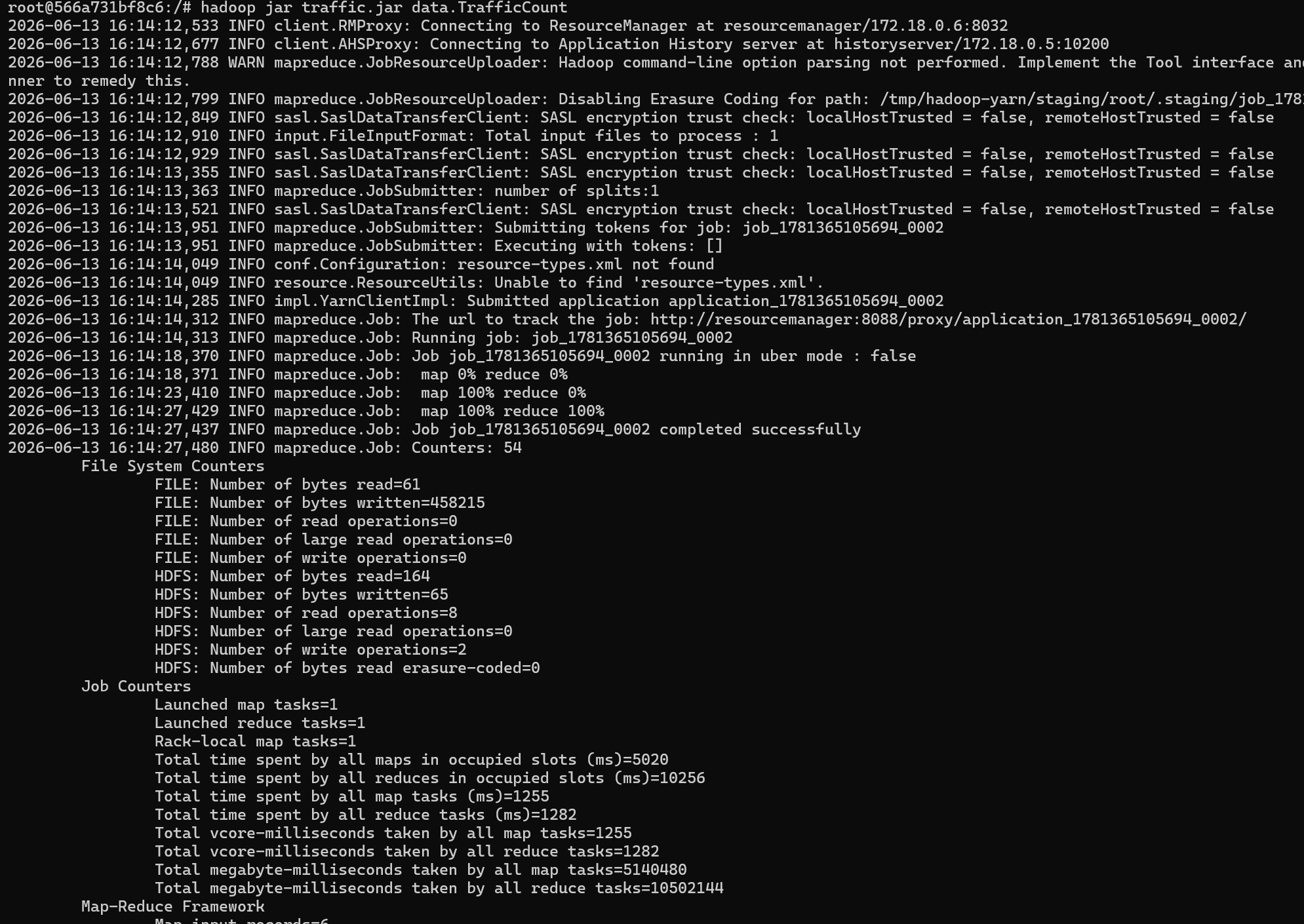
5. 查看最终结果 在当前容器内执行:
python
hdfs dfs -cat /traffic/output/part-r-00000
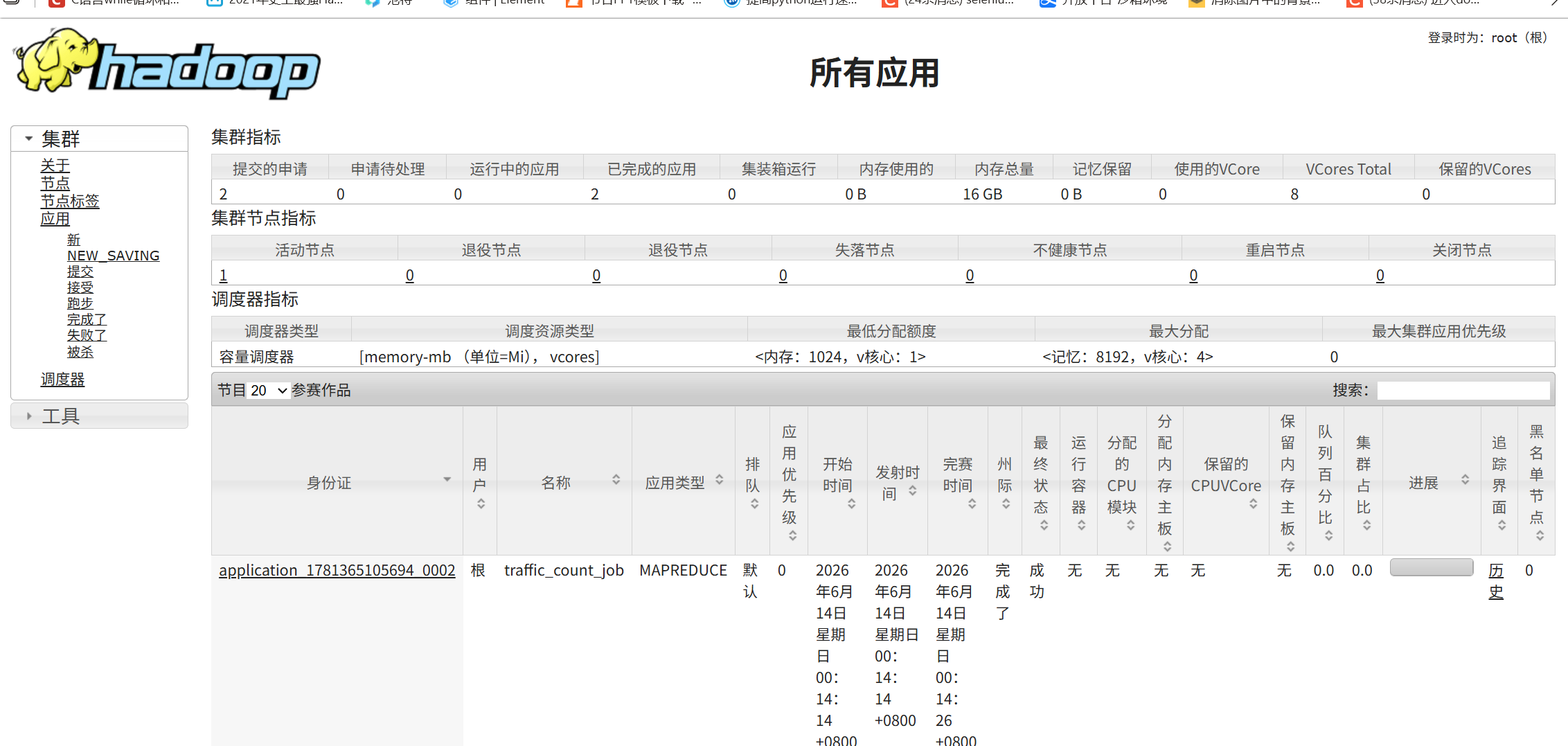
6. 查询与管理MapReduce任务
五. 生产环境及Docker hadoop集群的区别
1.导出 Jar 放入容器运行的原因
Eclipse 仅作为代码编写工具,Hadoop 集群标准运行方式是提交 Jar 包。Docker 容器是模拟的 Linux Hadoop 环境,Jar 包可以直接被集群命令执行,同时避开 Windows 下 winutils、系统调用等兼容问题。
2. Windows 本地无法完整连接容器集群
Docker 采用私有内网隔离容器,仅部分端口对外映射。Windows 只能连通做了端口映射的 NameNode,无法访问 DataNode 等数据节点的私有地址,最终读写数据失败。
3. 生产 Linux 服务器可以正常访问
生产环境所有 Hadoop 服务、客户端都处在同一个物理局域网,节点 IP 可互相路由、所有服务端口全互通,没有 Docker 网络隔离限制,因此客户端可以直接完整访问整个集群。