处理数字
1、计算平均值
问题:你想计算某一列的平均值,这可能是整张表中所有行的平均值,也可能是部分行的平均值。例如,你可能想计算全部员工的平均薪水以及每个部门的平均薪水。
解决方案:要计算全部员工的平均薪水,只需将 AVG 函数应用于包含薪水的列。
在没有指定 WHERE 子句的情况下,计算平均值时将只考虑非 NULL 值。
sql
select avg(sal) as avg_sal
from emp;
avg_sal
-----------------------
2640.0000000000000000
(1 row)要计算每个部门的平均薪水,可以使用 GROUP BY 子句创建对应于每个部门的分组。
sql
select deptno, avg(sal) as avg_sal
from emp
group by deptno;要将整张表作为一个分组或窗口,并计算平均值,只需将函数 AVG 应用于目标列,无须使用 GROUP BY 子句。函数 AVG 会忽略 NULL 值,明白这一点很重要。下面的示例说明了忽略 NULL 值的效果。
sql
create table t2(sal integer)
insert into t2 values (10)
insert into t2 values (20)
insert into t2 values (null)
select avg(sal) select distinct 30/2
from t2 from t2
AVG(SAL) 30/2
---------- ----------
15 15
select avg(coalesce(sal,0)) select distinct 30/3
from t2 from t2
AVG(COALESCE(SAL,0)) 30/3
-------------------- ----------
10 10函数 COALESCE 会返回你传入的参数列表中的第一个非NULL 值。将 SAL 值 NULL 转换为 0 后,平均值发生了变化。调用聚合函数时,务必考虑要如何处理 NULL 值。
SELECT 列表无须包含在 GROUP BY 子句中指定的列。
sql
select avg(sal)
from emp
group by deptno;
AVG(SAL)
----------
2916.66667
2175
1566.66667虽然 SELECT 子句中没有包含 DEPTNO,但还是会按DEPTNO 分组。在 SELECT 子句中包含作为分组依据的列通常可以提高可读性,但并非必须这样做。然而,没有出现在 GROUP BY 子句中的列不能包含在 SELECT 列表中。
2、找出最大列值和最小列值
问题:你想找出给定列中的最大值和最小值。例如,你想找出所有员工的最高薪水和最低薪水,以及每个部门的最高薪水和最低薪水。
解决方案:要找出所有员工的最高薪水和最低薪水,只需分别使用函数 MAX 和 MIN。
sql
select min(sal) as min_sal, max(sal) as max_sal
from emp;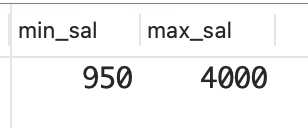
要找出每个部门的最高薪水和最低薪水,可以将函数 MAX和 MIX 同子句 GROUP BY 结合起来使用。
sql
select min(sal) as min_sal, max(sal) as max_sal
from emp
group by deptno;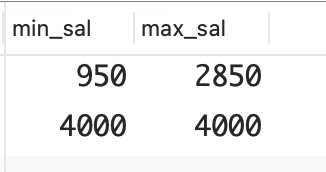
函数 MAX 和 MIN 会忽略 NULL 值,在有些分组中,可能所有行的列值都为 NULL,也可能只是部分行的列值为 NULL。在下面的示例中,使用 GROUP BY 的查询返回的两个分组(它们的 DEPTNO 分别为 10 和 30)的值都为 NULL。
sql
select deptno, comm
from emp
where deptno in (10,30)
order by 1
DEPTNO COMM
---------- ----------
10
10
10
30 300
30 500
30
30 0
30 1300
30
select min(comm), max(comm)
from emp
MIN(COMM) MAX(COMM)
---------- ----------
0 1300
select deptno, min(comm), max(comm)
from emp
group by deptno
DEPTNO MIN(COMM) MAX(COMM)
---------- ---------- ----------
10
20
30 0 13003、计算列值总和
问题:你想计算列值的总和,比如计算所有员工的薪水总额。
解决方案:在整张表为分组或窗口时,要计算总和,只需将函数 SUM应用于目标列,无须使用 GROUP BY 子句。
sql
select sum(sal)
from emp;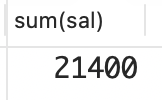
要创建多个数据分组或窗口,并分别计算它们的总和,可以结合使用函数 SUM 和 GROUP BY 子句。下面的示例会计算各部门员工的薪水总额。
sql
select sum(sal)
from emp
group by deptno;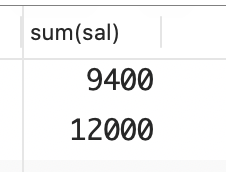
计算每个部门的薪水总额时,需要创建数据分组或窗口。对于每个部门,将该部门所有员工的薪水相加,得到部门薪水总额。这是一个 SQL 聚合示例,因为它关注的不是详情(比如每位员工的薪水),而是每个部门的最终结果。需要指出的是,函数 SUM 会忽略 NULL 值,但你可以有最终结果为 NULL 的分组,如下面的示例所示。在这个示例中,10 号部门的员工都没有业务提成,因此按DEPTNO 分组,并计算 COMM 列值总和时,SUM 将返回一个值为 NULL 的分组。
sql
select deptno, comm
from emp
where deptno in (10,30)
order by 1
DEPTNO COMM
---------- ----------
10
10
10
30 300
30 500
30
30 0
30 1300
30
select sum(comm)
from emp
SUM(COMM)
----------
2100
select deptno, sum(comm)
from emp
where deptno in (10,30)
group by deptno
DEPTNO SUM(COMM)
---------- ----------
10
30 21004、计算表中的行数
问题:你想计算特定表包含多少行或特定列包含多少个值。例如,你想确定员工总数以及每个部门的员工数。
解决方案:在整张表为分组或窗口时,要计算行数,只需使用函数COUNT 和字符 *。
sql
select count(*)
from emp;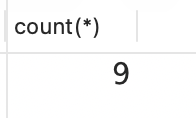
要创建多个数据分组或窗口,并分别计算它们包含的行数,可以结合使用函数 COUNT 和 GROUP BY 子句。
sql
select count(*)
from emp
group by deptno;
为了计算各部门的员工数量,可以创建数据分组或窗口。在各个部门中,每找到一位员工,就将计数加 1,最终得到该部门的员工总数。这是一个 SQL 聚合示例,因为它关注的不是详情(比如每位员工的薪水或职位),而是每个部门的最终结果。需要指出的是,如果将列名作为参数传递给函数 COUNT,那么它将忽略该列为 NULL 值的行,但将字符 * 或其他任何常量作为参数时,不会忽略NULL 值。
sql
select deptno, comm
from emp
DEPTNO COMM
---------- ----------
20
30 300
30 500
20
30 1300
30
10
20
10
30 0
20
30
20
10
select count(*), count(deptno), count(comm), count('hello')
from emp
COUNT(*) COUNT(DEPTNO) COUNT(COMM) COUNT('HELLO')
---------- ------------- ----------- --------------
14 14 4 14
select deptno, count(*), count(comm), count('hello')
from emp
group by deptno
DEPTNO COUNT(*) COUNT(COMM) COUNT('HELLO')
---------- ---------- ----------- --------------
10 3 0 3
20 5 0 5
30 6 4 6如果在所有行中作为参数传递给 COUNT 的列值都为NULL,那么 COUNT 将返回 0。如果表是空的,则COUNT 也将返回 0。还需指出的是,即便 SELECT 子句只包含聚合函数,也可以按表中的其他列分组。
sql
select count(*)
from emp
group by deptno
COUNT(*)
----------
3
5
6注意,虽然 DEPTNO 没有包含在 SELECT 子句中,但依然可以按 DEPTNO 分组。在 SELECT 子句中包含作为分组依据的列通常可以提高可读性,但并非必须这样做。然而,包含在 SELECT 列表中的列也必须包含在 GROUP BY 子句中。
5、计算非Null列值数
问题:你想计算特定列中的非 NULL 值个数。例如,你想确定有多少位员工有业务提成。
解决方案:计算 EMP 表的 COMM 列中非 NULL 值的个数。
sql
select count(comm)
from emp
COUNT(COMM)
-----------
4将函数 COUNT 的参数指定为星号(COUNT(*))时,实际上计算的是行数(而不管实际值如何,即把包含 NULL值和非 NULL 值的行都计算在内)。然而,将列名作为函数 COUNT 的参数时,计算的是该列值非 NULL 值的个数。上一节的"讨论"部分说明了这种差别。在上述解决方案中,COUNT(COMM) 返回了 COMM 列不为 NULL 值的行数。由于仅当员工有业务提成时,其 COMM 列的值才不为NULL,因此 COUNT(COMM) 返回的是有业务提成的员工数量。
6、生成移动总计
问题:你想计算列值的移动总计。
解决方案:例如,下面的解决方案演示了如何计算所有员工薪水的移动总计。为了提高可读性,对结果按 SAL 进行了排序,让你能够轻松地查看移动总计的变化过程。
sql
select ename, sal,
sum(sal) over (order by sal,empno) as running_total
from emp
order by 2; 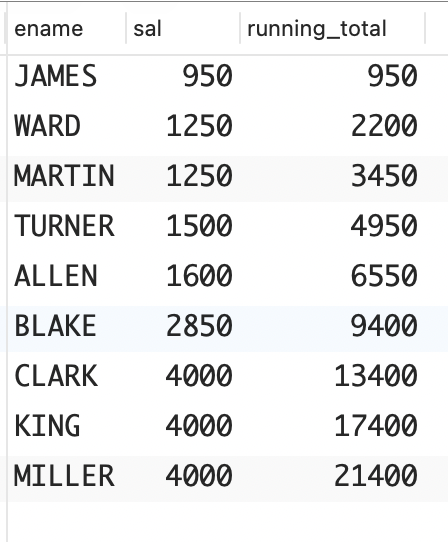
7、生成移动总积
问题:你想计算数字列的移动总积。此操作与上一节的实例类似,但使用的是乘法运算,而不是加法运算。
解决方案:本解决方案以计算员工薪水的移动总积为例。虽然薪水的移动总积没什么用,但使用这里介绍的方法,可以轻松地计算其他更有用的移动总积。
可以将对数相加来模拟乘法运算,然后结合使用窗口函数SUM OVER,就可以计算移动总积了。
sql
select empno,ename,sal,
exp(sum(ln(sal))over(order by sal,empno)) as running_prod
from emp
where deptno = 10;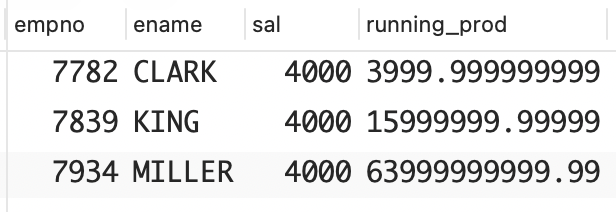
在 SQL 中(准确地说是在数学中),计算小于或等于 0的值的对数是非法的。如果表中有这样的值,则需要避免将这些非法值传递给 SQL 的函数 LN。出于可读性考虑,本解决方案没有采取防止传入值为 NULL 或非法的措施,但编写生产代码时,必须考虑是否要采取这样的防范措施。如果肯定会涉及负数或 0,则本解决方案可能不管用。另外,如果涉及 0(但不涉及负数),那么一种常规的规避办法是给所有的值都加 1,因为不管底数是多少,1的对数都是 0。
如果你使用的是 SQL Server,请将 LN 替换为 LOG。
8、平滑值序列
问题:你有一系列随时间变化的值,比如月度销量。通常,相邻数据点之间的波动很大,但你想知道的是总体趋势。为了更好地找出总体趋势,你要实现一个简单的平滑器,比如加权移动平均。
假设有一个报摊,其日销售额(单位为美元)如下。
sql
DATE1 SALES
2020-01-01 647
2020-01-02 561
2020-01-03 741
2020-01-04 978
2020-01-05 1062
2020-01-06 1072
... ...但你知道,销售数据的波动性导致难以发现总体趋势。例如,一周或一个月的某些天的销量特别高或特别低。或者,由于数据收集方式的影响,有些天的销量并入了下一天,导致波谷后面紧跟着一个波峰,可是你又无法在这两天之间正确地分配销售总量。因此,要弄明白发生的情况,需要平滑一段时间内的数据。
为此,可以计算移动平均,方法是将当前值与前 n -- 1 个值相加,再除以 n。如果同时显示以前的值作为参考,结果将如下所示。
sql
DATE1 sales salesLagOne SalesLagTwo MovingAverage
----- ------ ----------- ------------ --------------
2020-01-01 647 NULL NULl NULL
2020-01-02 561 647 NULL NULL
2020-01-03 741 561 647 649.667
2020-01-04 978 741 561 760
2020-01-05 1062 978 741 927
2020-01-06 1072 1062 978 1037.333
2020-01-07 805 1072 1062 979.667
2020-01-08 662 805 1072 846.333
2020-01-09 1083 662 805 850
2020-01-10 970 1083 662 905解决方案:计算平均值的公式众所周知。为了更好地解决上述问题,可以使用加权移动平均,对于越接近预测期的值,指定越大的权重。要计算移动平均,可以使用窗口函数 LAG。
sql
select date1, sales,lag(sales,1) over(order by date1) as salesLagOne,
lag(sales,2) over(order by date1) as salesLagTwo,
(sales
+ (lag(sales,1) over(order by date1))
+ lag(sales,2) over(order by date1))/3 as MovingAverage
from sales分析时序数据(出现在特定时段内的数据)时,最简单的一个方法是使用加权移动平均。这里演示的是计算简单移动平均的一个方法,你也可以结合使用分区和移动平均。我们选择的是简单的三点移动平均,但根据要分析的数据的特征,也可以使用不同的公式和不同的数据点数,以充分发挥这种方法的作用。
例如,下面的解决方案演化版本会计算三点加权移动平均,通过修改系数和分母,它会对越接近预测期的数据,指定越大的权重。
sql
select date1, sales,lag(sales,1) over(order by date1),
lag(sales,2) over(order by date1),
((3*sales)
+ (2*(lag(sales,1) over(order by date1)))
+ (lag(sales,2) over(order by date1)))/6 as SalesMA
from sales9、计算众数
问题:你想找出列值的众数(众数的数学定义是,在给定数据集中,出现频率最高的元素)。例如,你想找出 20 号部门的员工薪水众数。
在下面的薪水中,众数为 3000。
sql
select sal
from emp
where deptno = 20
order by sal
SAL
----------
800
1100
2975
3000
3000解决方案:
DB2、MySQL、PostgreSQL 和 SQL Server:为了获取众数,可以使用窗口函数 DENSE_RANK 按出现次数对薪水值排名。
sql
select sal
from (
select sal,
dense_rank()over( order by cnt desc) as rnk
from (
select sal, count(*) as cnt
from emp
where deptno = 20
group by sal
) x
) y
where rnk = 1;Oracle:可以使用聚合函数 MAX 的 KEEP 扩展来找出薪水众数。需要指出的是,如果出现分不出胜负的情况,即多个薪水值出现的次数都是最多的,那么使用 KEEP 的解决方案将只返回最高的薪水。如果要返回所有的众数,则必须修改该解决方案,或使用前面的 DB2 解决方案。在本例中,20 号部门的薪水众数为 3000,也是最高的薪水,因此以下解决方案足够用了。
sql
select max(sal)
keep(dense_rank first order by cnt desc) sal
from (
select sal, count(*) cnt
from emp
where deptno=20
group by sal
)10、计算中值
问题:你想计算数字列的中值(中值指的是在一组有序元素中,位于正中央的那个元素的值)。例如,你想找出 20 号部门的薪水中值。在下面的薪水中,中值为 2975。
sql
select sal
from emp
where deptno = 20
order by sal
SAL
----------
800
1100
2975
3000
3000解决方案:在 Oracle 中,可以使用内置函数来计算中值。在其他DBMS 中,传统的解决方案是使用自连接,但引入窗口函数后,可以使用效率更高的解决方案。
DB2 和 PostgreSQL:使用窗口函数 PERCENTILE_CONT 来查找中值。
sql
select percentile_cont(0.5)
within group(order by sal)
from emp
where deptno=20;SQL Server:使用窗口函数 PERCENTILE_CONT 来查找中值。
sql
select percentile_cont(0.5)
within group(order by sal)
over()
from emp
where deptno=20SQL Server 解决方案与 DB2 解决方案相同,但需要包含OVER 子句。
MySQL:MySQL 中没有函数 PERCENTILE_CONT,因此需要采取权变措施。可以结合使用函数 CUME_DIST 和 CTE 来模拟函数 PERCENTILE_CONT。
sql
with rank_tab (sal, rank_sal) as (
select sal, cume_dist() over (order by sal)
from emp
where deptno=20
),
inter as (
select sal, rank_sal from rank_tab
where rank_sal>=0.5
union
select sal, rank_sal from rank_tab
rank_sal<=0.5
)
select avg(sal) as MedianSal
from inter;Oracle:使用函数 MEDIAN 或 PERCENTILE_CONT。
sql
select median(sal)
from emp
where deptno=20
select percentile_cont(0.5)
within group(order by sal)
from emp
where deptno=2011、计算总计占比
问题:你想计算特定列的各个列值占总计的百分比。例如,你想确定 10 号部门的薪水占薪水总额的百分比。
解决方案:一般而言,在 SQL 中,计算总计占比与在纸上完成这种计算的方法相同,只需先做除法,再做乘法。在本例中,要计算 10 号部门的薪水占 EMP 表中薪水总额的百分比,只需先找出 10 号部门的薪水总额,将其除以整张表的薪水总额,再乘以 100 得到百分比值。
MySQL 和 PostgreSQL:将 10 号部门的薪水总额除以整张表的薪水总额。
sql
select (sum(
case when deptno = 10 then sal end)/sum(sal))*100 as pct
from emp;DB2、Oracle 和 SQL Server:在一个内嵌视图中,使用窗口函数 SUM OVER 计算整张表的薪水总额和 10 号部门的薪水总额,然后在外部查询中执行除法运算和乘法运算。
sql
select distinct (d10/total)*100 as pct
from (
select deptno,
sum(sal)over() total,
sum(sal)over(partition by deptno) d10
from emp
) x
where deptno=1012、聚合值可为NULL的列
问题:你想对特定列执行聚合运算,但该列的值可为 NULL。你希望聚合结果是精确的,但问题是聚合函数会忽略NULL。例如,你要计算 30 号部门员工的平均业务提成,但有些员工没有业务提成,因此这些员工的 COMM 列为 NULL。聚合函数会忽略 NULL,这将导致结果的准确度大打折扣。你希望执行聚合运算时,将目标列值为NULL 的行也考虑进来。
解决方案:使用函数 COALESCE 将 NULL 转换为 0,让聚合运算将它们也考虑进来。
sql
select avg(coalesce(comm,0)) as avg_comm
from emp
where deptno=30;
avg_comm
----------------------
366.6666666666666667
(1 row)13、计算剔除最高值和最低值后的平均值
问题:你要计算平均值,但想将最高值和最低值排除在外,以降低扭曲效果。在统计学中,剔除最大值和最小值后的平均值被称为截尾均值(trimmed mean)。例如,你想计算剔除最高薪水和最低新水后全部员工的平均薪水。
解决方案:
MySQL 和 PostgreSQL:使用子查询将最高值和最低值排除在外。
sql
select avg(sal)
from emp
where sal not in (
(select min(sal) from emp),
(select max(sal) from emp)
);
avg
-----------------------
2556.2500000000000000
(1 row)DB2、Oracle 和 SQL Server:在内嵌视图中使用窗口函数 MAX OVER 和 MIN OVER 来生成一个结果集,并使用这个结果集将最高值和最低值排除在外。
sql
select avg(sal)
from (
select sal, min(sal)over() min_sal, max(sal)over() max_sal
from emp
) x
where sal not in (min_sal,max_sal)14、将由字母和数字组成的字符串转换为数字
问题:你有一些由字母和数字组成的数据,但只想返回其中的数字。例如,你想返回字符串 paul123f321 中的数字123321。
解决方案:
DB2:使用函数 TRANSLATE 和 REPLACE 提取字母数字字符串中的数字。
sql
select cast(
replace(
translate( 'paul123f321',
repeat('#',26),
'abcdefghijklmnopqrstuvwxyz'),'#','')
as integer ) as num
from t1Oracle、SQL Server 和 PostgreSQL:使用函数 TRANSLATE 和 REPLACE 提取字母数字字符串中的数字。
sql
select cast(
replace(
translate( 'paul123f321',
'abcdefghijklmnopqrstuvwxyz',
rpad('#',26,'#')),'#','')
as integer ) as num
from t1;
num
--------
123321
(1 row)MySQL:使用REGEXP_REPLACE函数
sql
SELECT REGEXP_REPLACE('paul123f321', '[^0-9]', '') AS result;15、修改移动总计中的值
问题:你想根据另一列的值修改移动总计中的值。请看下面的场景:你要显示一个信用卡账户的交易记录以及每次交易后的余额。本实例会将下面的视图 V 作为数据源。
sql
create view V (id,amt,trx)
as
select 1, 100, 'PR' from t1 union all
select 2, 100, 'PR' from t1 union all
select 3, 50, 'PY' from t1 union all
select 4, 100, 'PR' from t1 union all
select 5, 200, 'PY' from t1 union all
select 6, 50, 'PY' from t1
select * from V
ID AMT TR
-- ---------- --
1 100 PR
2 100 PR
3 50 PY
4 100 PR
5 200 PY
6 50 PYID 列可以唯一地标识每次交易。AMT 列表示交易涉及的金额(要么为收入,要么为支出)。TR 列为交易类型:支出用 PY 表示,收入用 PR 表示。如果 TR 列的值为PY,就从移动总计中减去当前 AMT 值;如果 TR 列的值为 PR,就将移动总计加上当前 AMT 值。你希望返回的最终结果集如下所示。
sql
TRX_TYPE AMT BALANCE
-------- ---------- ----------
PURCHASE 100 100
PURCHASE 100 200
PAYMENT 50 150
PURCHASE 100 250
PAYMENT 200 50
PAYMENT 50 0解决方案:使用窗口函数 SUM OVER 生成移动总计,并使用 CASE表达式来确定交易类型。
sql
select case when trx = 'PY'
then 'PAYMENT'
else 'PURCHASE'
end trx_type,
amt,
sum(
case when trx = 'PY'
then -amt else amt
end
) over (order by id,amt) as balance
from V;16、使用绝对中位差找出异常值
问题:你想找出数据集中可能存在疑问的值。值存在疑问有多种原因:可能是数据收集方式有问题,比如记录值的仪表存在误差;可能是数据输入错误导致的;还可能是因为数据生成时环境出现异常,这意味着数据点是正确的,但应谨慎根据数据得出任何结论。有鉴于此,你想检测出异常数据。
一种检测异常数据的常用方法是,计算数据的标准偏差,并将超过 3 倍标准偏差(或其他类似距离)的数据点视为异常数据。很多针对非统计学家的统计学课程会教授这种方法。然而,如果数据不符合正态分布,则这种方法可能错误地识别异常数据,而当数据分布不对称,或者如果你远离平均值,数据就不像正态分布那样变得稀疏时更是如此。
解决方案:先使用 10 节的解决方案找出中值。你需要将这个查询放在 CTE 中,以便对其结果做进一步查询。偏差是中值与各个值的绝对差,而绝对中位差是偏差的中值,因此需要再次计算中值。
SQL Server:SQL Server 中提供了函数 PERCENTILE_CONT,其可以简化查找中值的任务。由于要找出并操作两个不同的中值,因此需要一系列 CTE。
sql
with median (median)
as
(select distinct percentile_cont(0.5) within group(order by sal)
over()
from emp),
Deviation (Deviation)
as
(Select abs(sal-median)
from emp join median on 1=1),
MAD (MAD) as
(select DISTINCT PERCENTILE_CONT(0.5) within group(order by deviation) over()
from Deviation )
select abs(sal-median)/MAD, sal, ename, job
from MAD join emp on 1=1PostgreSQL 和 DB2:总体结构与 SQL Server 解决方案相同,但函数PERCENTILE_CONT 的语法不同,因为在 PostgreSQL和 DB2 中,PERCENTILE_CONT 被视为聚合函数,而不是窗口函数。
sql
with median (median)
as
(select percentile_cont(0.5) within group(order by sal)
from emp),
devtab (deviation)
as
(select abs(sal-median)
from emp join median),
MedAbsDeviation (MAD) as
(select percentile_cont (0.5) within group(order by deviation)
from devtab)
select abs(sal-median)/MAD, sal, ename, job
FROM MedAbsDeviation join emp; Oracle:Oracle 中提供了计算中值的函数 MEDIAN,因此解决方案更简单,但为了处理标量值偏差,依然需要使用CTE。
sql
with
Deviation (Deviation)
as
(select abs(sal-median(sal))
from emp),
MAD (MAD) as
(select median(Deviation)
from Deviation )
select abs(sal-median)/MAD, sal, ename, job
FROM MAD join empMySQL:10 节说过,MySQL 中没有提供函数 MEDIAN 或PERCENTILE_CONT,这意味着为计算绝对中位差而找出每个中值时,需要在 CTE 中使用两个子查询。这导致MySQL 解决方案的代码要长些。
sql
with rank_tab (sal, rank_sal) as (
select sal, cume_dist() over (order by sal)
from emp),
inter as
(
select sal, rank_sal from rank_tab
where rank_sal>=0.5
union
select sal, rank_sal from rank_tab
where rank_sal<=0.5
)
,
medianSal (medianSal) as
(
select (max(sal)+min(sal))/2
from inter),
deviationSal (Sal,deviationSal) as
(select Sal,abs(sal-medianSal)
from emp join medianSal
on 1=1
)
,
distDevSal (sal,deviationSal,distDeviationSal) as
(
select sal,deviationSal,cume_dist() over (order by deviationSal)
from deviationSal
),
DevInter (DevInter, sal) as
(
select min(deviationSal), sal
from distDevSal
where distDeviationSal >= 0.5
union
select max(DeviationSal), sal
from distDevSal
where distDeviationSal <= 0.5
),
MAD (MedianAbsoluteDeviance) as
(
select abs(emp.sal-(min(devInter)+max(devInter))/2)
from emp join DevInter on 1=1
)
select emp.sal,MedianAbsoluteDeviance,
(emp.sal-deviationSal)/MedianAbsoluteDeviance
from (emp join MAD on 1=1)
join deviationSal on emp.sal=deviationSal.sal;17、使用本福特法则查找反常数据
问题:上一节实例介绍的异常值是一种易于识别的反常数据,但有些存在疑问的数据并不那么容易识别。检测不像异常值那样显而易见的反常数据的一种方式是查看数字位的出现频率,这种频率通常符合本福特法则。本福特法则最常用于检测数据造假------在数据集中人为地添加伪造的数字,也可用于检测不符合预期规律的数据。例如,可以使用它来检测诸如重复数据点等错误,这种错误不一定像异常值那样明显。
解决方案:要使用本福特法则,需要先计算数字位的期望分布,然后将其与实际分布进行比较。在最复杂的本福特法则用法中,会考虑第一位、第二位以及数字位组合,但本例中只考虑前几位。
将本福特法则预测的频率与数据的实际频率进行比较。最终的结果集包含 4 列数据,分别是第一位的预测频率、第一位的实际频率、本福特法则预测的前几位的频率,以及前几位的实际频率。
sql
with
FirstDigits (FirstDigit)
as
(select left(cast(SAL as CHAR),1) as FirstDigit
from emp),
TotalCount (Total)
as
(select count(*)
from emp),
ExpectedBenford (Digit,Expected)
as
(select ID,(log10(ID + 1) - log10(ID)) as expected
from t10
where ID < 10)
select count(FirstDigit),Digit,
coalesce(count(*)/Total,0) as ActualProportion,Expected
From FirstDigits
Join TotalCount
Right Join ExpectedBenford
on FirstDigits.FirstDigit=ExpectedBenford.Digit
group by Digit
order by Digit