Cloud_Shy 陪你解读《Effective Python 3rd Edition》:从练气到老魔

第七章 Classes and Interfaces(类与接口)
作为一种面向对象编程语言,Python 支持各种特性,如继承、多态和封装。在 Python 中完成任务通常需要编写新的类,并定义它们如何通过接口和关系进行交互。
类与继承机制使得用对象来表述 Python 程序的预期行为变得十分简便。它们使您能够随着时间的推移不断完善和扩展功能。在需求不断变化的环境中,这些机制提供了灵活性。熟练掌握类与继承的使用方法,有助于您编写易于维护的代码。
Python 也是一种多范式语言 ,它鼓励采用函数式编程 风格。函数对象属于第一类,这意味着它们可以像普通变量一样被传递。Python 还允许你在同一程序中使用混合的面向对象风格与函数式风格特性,这种方式可能比各自独立使用任何一种风格都更为强大。
Item 51:首选数据类来定义轻量级类
通过使用内置数据类型(如字符串和字典)并定义与之交互的函数,开始编写 Python 程序可谓轻而易举。到了一定阶段,你的代码会变得足够复杂,以至于有必要创建自己的对象类型来容纳数据并封装行为(请参阅 Item 29 内容:"构建类而非深度嵌套字典、列表和元组"以获取示例)。
然而,Python 庞大的面向对象功能集可能会让人感到无从下手,尤其是对于初学者而言。为了便于理解这些特性,Python 提供了多种内置模块(参见 Item 57:"通过继承 collections.abc 类实现自定义容器类型"), 并且还有许多由社区开发的包(例如 attrs 和 pydantic------参见 Item 116:"了解何处可找到社区开发的模块")。
其中一个尤为有价值的内置模块是数据类(dataclasses),它能够帮助极大程度地减少类定义中重复代码的数量。使用该模块的代价在于导入时会产生轻微的性能开销,这是由于其实现方式依赖于 exec(详见 Item 91:"避免使用 exec 和 eval,除非你正在构建一款面向开发者的工具")。但总体而言,这一投入是非常值得的,尤其是对于那些主要仅包含少量或根本没有方法的类而言,这些方法的主要作用就是以属性形式存储数据。
当考虑到自行构建每个数据类特性所需耗费的大量精力时,其潜在优势便会变得尤为明显(更多示例请参见 Item 56:"偏好使用数据类来创建不可变对象")。了解这些常见的面向对象惯用手法在底层的工作原理同样重要,这样在你不可避免地需要更多灵活性或定制化时,便能够逐步将代码从数据类中迁移出来。
避免使用 __init__ 样板
处理对象的首要步骤便是创建它们。当以类似函数调用的方式调用类名时,会调用 __init__ 专用方法来构建一个对象。例如,这里我定义了一个简单的类,用于存储 RGB(红、绿、蓝)颜色值:
class RGB:
def __init__(self, red, green, blue):
self.red = red
self.green = green
self.blue = blue这段代码较为冗长,重复了每个属性的名称三次。此外,它还容易出错,因为存在许多可能插入拼写错误或意外将属性赋值给 __init__ 函数中错误参数的机会:
class BadRGB:
def __init__(self, green, red, blue): # Bad: Order swapped
self.red = red
self.green = green
self.bloe = blue # Bad: Typo数据类模块包含一个类装饰器(参见 Item 66:"在构建可组合类扩展时,应优先使用类装饰器而非元类")。该装饰器可为此类简单类提供更为理想的默认行为。在此处,我定义了一个与上述示例类似的新类,但将其包裹在了数据类装饰器中:
from dataclasses import dataclass
@dataclass
class DataclassRGB:
red: int
green: int
blue: int为了使用 dataclass 装饰器,我在类主体中列出了对象的每个属性及其相应的类型提示(请参阅 Item 124:"通过 typing 考虑静态分析以消除错误")。我只需识别每个属性一次,因此避免了拼写错误的风险。如果我对属性重新排序,我只需要更新调用者,而不是确保类本身是一致的。
有了这些类型注释,我还可以使用静态类型检查工具在程序执行之前检测错误。例如,这里我在构造对象并修改它时提供了错误的类型:
from dataclasses import dataclass
@dataclass
class DataclassRGB:
red: int
green: int
blue: int
obj = DataclassRGB(1, "bad", 3)
obj.red = "also bad"类型检查器能够报告这些问题,而无需在类定义中添加更多代码:
>>>
$ python3 -m mypy --strict example.py
.../example.py:9: error: Argument 2 to "DataclassRGB" has
➥incompatible type "str"; expected "int" [arg-type]
.../example.py:10: error: Incompatible types in assignment
➥(expression has type "str", variable has type "int")
➥[assignment]
Found 2 errors in 1 file (checked 1 source file)通过向标准类中的 __init__ 方法中添加类型信息,同样可以实现类型检查功能。不过,相较于类主体部分,这一位置显得较为局促且视觉上较为杂乱:
class RGB:
def __init__(
self, red: int, green: int, blue: int
) -> None: # Changed
self.red = red
self.green = green
self.blue = blue如果您不希望项目中出现类型注解(请参阅 Item 3:"切勿期望 Python 能在编译时检测错误"),或者如果您需要使类属性具备完全的灵活性,您仍可使用 dataclass 装饰器。只需为字段提供来自内置 typing 模块的 Any 类型即可:
from typing import Any
@dataclass
class DataclassRGB:
red: Any
green: Any
blue: Any要求初始化参数需以关键字形式传递
向 __init__ 函数传递的参数与对其他任何函数调用的处理方式并无二致,这意味着既允许使用位置参数,也允许使用关键字参数(有关信息,请参阅 Item 35:"通过关键字参数提供可选行为")。例如,以下代码以三种不同的方式对 RGB 类进行了初始化:
color1 = RGB(red=1, green=2, blue=3)
color2 = RGB(1, 2, 3)
color3 = RGB(1, 2, blue=3)然而,这种灵活性容易导致错误,因为我很容易混淆不同颜色组件的值。为解决这一问题,我可以在参数列表中使用星号符号(*)来要求 __init__ 方法的参数必须始终以关键字形式提供(详情请见 Item 37:"通过仅使用关键字和仅使用位置参数来增强清晰度"):
class RGB:
def __init__(self, *, red, green, blue): # Changed
self.red = red
self.green = green
self.blue = blue现在使用关键字参数是创建这些对象的唯一方法:
color4 = RGB(red=1, green=2, blue=3)使用位置参数初始化该类将会失败:
RGB(1, 2, 3)
>>>
Traceback ...
TypeError: RGB.__init__() takes 1 positional argument but 4 were given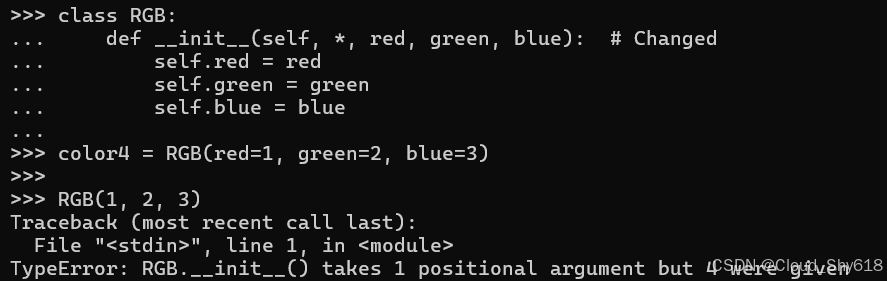
默认情况下,被 dataclass 装饰器包裹的类也支持同时接受位置参数和关键字参数。我只需将 kw_only 标志传递给装饰器,便可以实现与上述相同的仅接受关键字参数的行为:
@dataclass(kw_only=True)
class DataclassRGB:
red: int
green: int
blue: int现在,这个类必须通过关键字参数进行初始化:
color5 = DataclassRGB(red=1, green=2, blue=3)传递任何位置参数都会导致失败,这与标准类实现的情况相同:
DataclassRGB(1, 2, 3)
>>>
Traceback ...
TypeError: DataclassRGB.__init__() takes 1 positional argument but 4 were given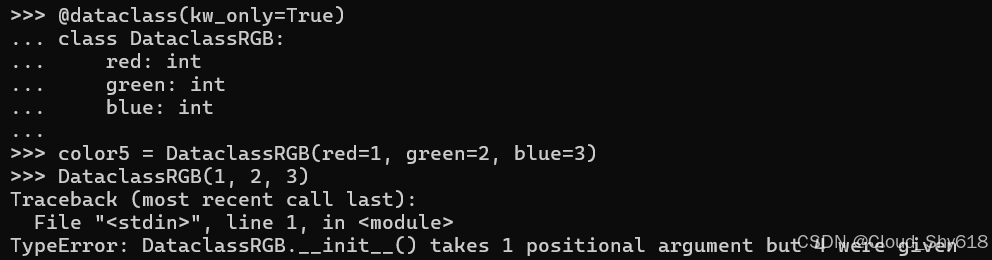
提供默认属性值
对于那些专注于数据存储的类而言,为某些属性设置默认值可能会非常有用,这样便无需在每次对象被创建时都需对其进行指定。例如,假设我想要扩展 RGB 类,使其能够包含一个 alphafield 属性,用以表示颜色在 0 到 1 范围内的透明度级别。默认情况下,我希望颜色保持不透明状态,alpha 值为 1。为此,我通过在 __init__ 构造函数中对相应参数提供默认值来实现这一目标:
class RGBA:
def __init__(self, *, red, green, blue, alpha=1.0):
self.red = red
self.green = green
self.blue = blue
self.alpha = alpha现在我可以省略 alpha 参数了,系统仍会自动为其指定默认值:
color1 = RGBA(red=1, green=2, blue=3)
print(
color1.red,
color1.green,
color1.blue,
color1.alpha,
)
>>>
1 2 3 1.0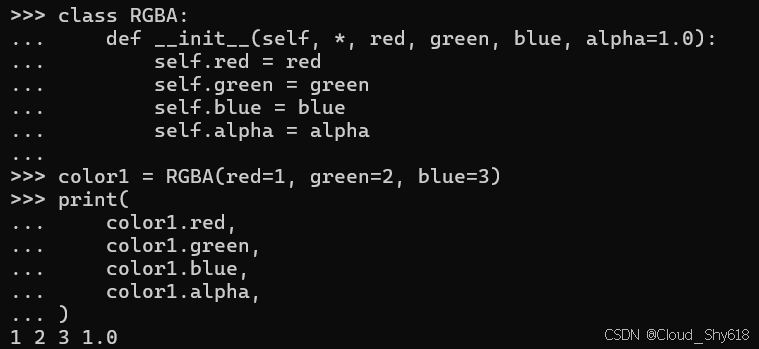
为了使用 dataclass 装饰器实现相同的行为,我只需为类主体中的属性分配一个默认值:
@dataclass(kw_only=True)
class DataclassRGBA:
red: int
green: int
blue: int
alpha: int=1.0使用此新构造函数创建对象将为 alpha 属性分配正确的默认值:
color2 = DataclassRGBA(red=1, green=2, blue=3)
print(color2)
>>>
DataclassRGBA(red=1, green=2, blue=3, alpha=1.0)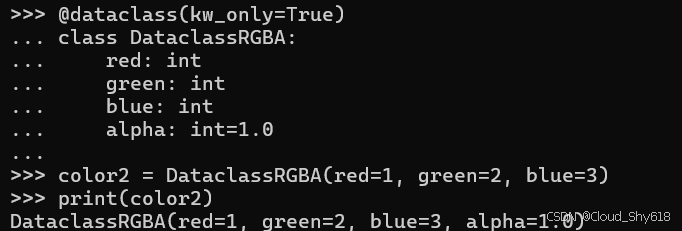
然而,当默认值可变时,这些方法都无法正常工作(有关类似问题,请参阅 Item 26:"首选 get 而不是 in 和 Key Error 来处理丢失的字典键",以及 Item 30:"了解函数参数可以改变"以了解背景)。例如,如果提供的默认值是一个列表,则单个对象引用将在类的所有实例之间共享,从而导致如下奇怪的行为:
class BadContainer:
def __init__(self, *, value=[]):
self.value = value
obj1 = BadContainer()
obj2 = BadContainer()
obj1.value.append(1)
print(obj2.value) # Should be empty, but isn't
>>>
[1]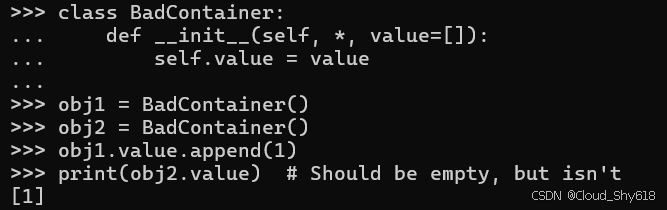
对于标准类,可以通过在 __init__ 方法中提供 None 的默认值,然后动态分配真正的默认值来解决这个问题(请参见 Item 36:"使用 None 和 Docstrings 指定动态默认参数"):
class MyContainer:
def __init__(self, *, value=None):
if value is None:
value = [] # Create when not supplied
self.value = value现在每个对象都会默认分配一个不同的列表:
obj1 = MyContainer()
obj2 = MyContainer()
obj1.value.append(1)
assert obj1.value == [1]
assert obj2.value == []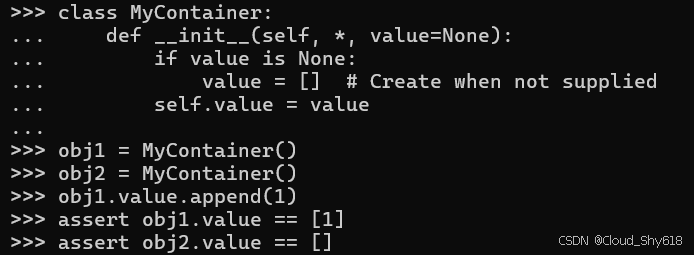
为了使用 dataclass 装饰器实现相同的行为,我可以使用 dataclasses 模块中的 field 辅助函数。 它接受 default_factory 参数,该参数是要调用的函数,以便为该属性分配默认值:
from dataclasses import field
@dataclass
class DataclassContainer:
value: list = field(default_factory=list)这同样修复了实现,以确保每个新对象都有自己单独的列表实例:
obj1 = DataclassContainer()
obj2 = DataclassContainer()
obj1.value.append(1)
assert obj1.value == [1]
assert obj2.value == []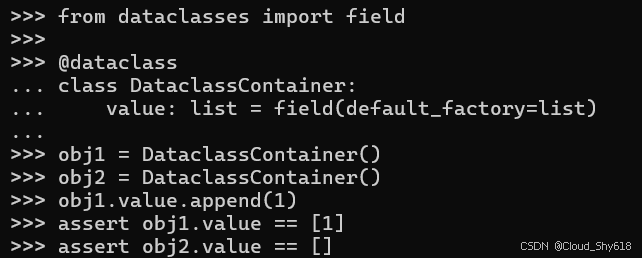
dataclasses 模块提供了许多其他类似的有用功能,官方文档(https://docs.python.org/3/library/dataclasses.html)详细介绍了这些功能。
将对象表示为字符串
当您使用标准方法在 Python 中定义一个新类时,即使像 print 这样的基本功能似乎也无法正常工作。您不会看到属性及其值的列表,而是获得对象的内存地址,这实际上是无用的:
color1 = RGB(red=1, green=2, blue=3)
print(color1)
>>>
<__main__.RGB object at 0x1029a0b90>
为了解决这个问题,我可以实现 __repr__ 特殊方法(请参阅 Item 12:"了解打印对象时 repr 和 str 之间的差异"了解背景)。在这里,我使用一个大格式字符串将这样的方法添加到标准 Python 类中(有关信息,请参阅 Item 11:"优先使用插值 F 字符串而不是 C 样式格式字符串和 str.format"):
class RGB:
def __init__(self, *, red, green, blue):
self.red = red
self.green = green
self.blue = blue
def __repr__(self):
return (
f"{type(self).__module__}"
f".{type(self).__name__}("
f"red={self.red!r}, "
f"green={self.green!r}, "
f"blue={self.blue!r})"
)现在这些对象在打印时看起来会很好:
color1 = RGB(red=1, green=2, blue=3)
print(color1)
>>>
__main__.RGB(red=1, green=2, blue=3)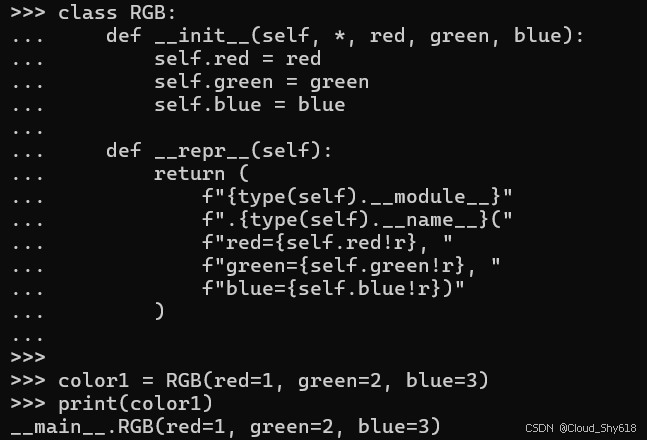
然而,自己实现 __repr__ 存在两个问题。首先,它是重复且冗长的样板,需要添加到每个类中。其次,它很容易出错,因为我很容易忘记添加新属性、拼错属性名称、以错误的位置构造顺序放置属性名称,或者错误地插入分隔逗号和空格。
dataclass 装饰器默认提供 __repr__ 特殊方法的实现,提高生产力并避免这些潜在的错误:
color2 = DataclassRGB(red=1, green=2, blue=3)
print(color2)
>>>
DataclassRGB(red=1, green=2, blue=3)
将对象转换为元组
为了帮助进行相等性测试、索引和排序,将对象转换为元组可能很有用。为了使用标准 Python 类来完成此操作,我在这里定义了一个新方法,将对象的属性打包在一起:
class RGB:
def __init__(self, red, green, blue):
self.red = red
self.green = green
self.blue = blue
def _astuple(self):
return (self.red, self.green, self.blue)使用这个方法很简单:
color1 = RGB(1, 2, 3)
print(color1._astuple())
>>>
(1, 2, 3)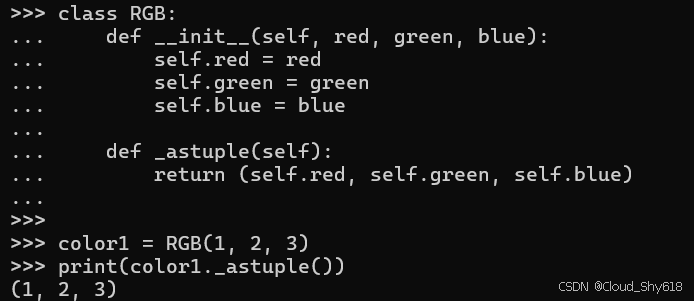
_astuple 方法还允许我通过使用 * 运算符将返回值用作构造函数的位置参数来复制对象(请参阅 Item 34:"使用可变位置参数减少视觉噪音"和 Item 16:"优先使用 Catch-All 解包而不是切片"了解背景):
color2 = RGB(*color1._astuple())
print(color2.red, color2.green, color2.blue)
>>>
1 2 3
然而,与标准 Python 类的 __repr__ 实现一样,_astuple 方法需要容易出错的样板文件,并且存在所有相同的缺陷。相反,我可以使用 dataclasses 模块中的 astuple 函数为任何数据类修饰的类实现相同的行为:
from dataclasses import dataclass
@dataclass
class DataclassRGB:
red: int
green: int
blue: int
from dataclasses import astuple
color3 = DataclassRGB(1, 2, 3)
print(astuple(color3))
>>>
(1, 2, 3)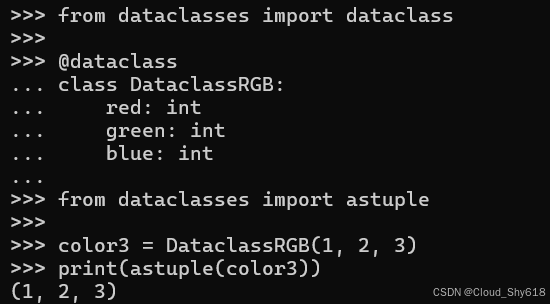
将对象转换为字典
为了帮助数据序列化,将对象转换为包含其属性的字典可能很有用。我可以通过定义一个新方法,使用标准 Python 类来实现此目的:
class RGB:
def __init__(self, red, green, blue):
self.red = red
self.green = green
self.blue = blue
def __repr__(self):
return (
f"{type(self).__module__}"
f".{type(self).__name__}("
f"red={self.red!r}, "
f"green={self.green!r}, "
f"blue={self.blue!r})"
)
def _asdict(self):
return dict(
red=self.red,
green=self.green,
blue=self.blue,
)该方法的返回值可以从 json 内置模块传递给 dumps 函数以生成序列化表示:
import json
color1 = RGB(red=1, green=2, blue=3)
data = json.dumps(color1._asdict())
print(data)
>>>
{"red": 1, "green": 2, "blue": 3}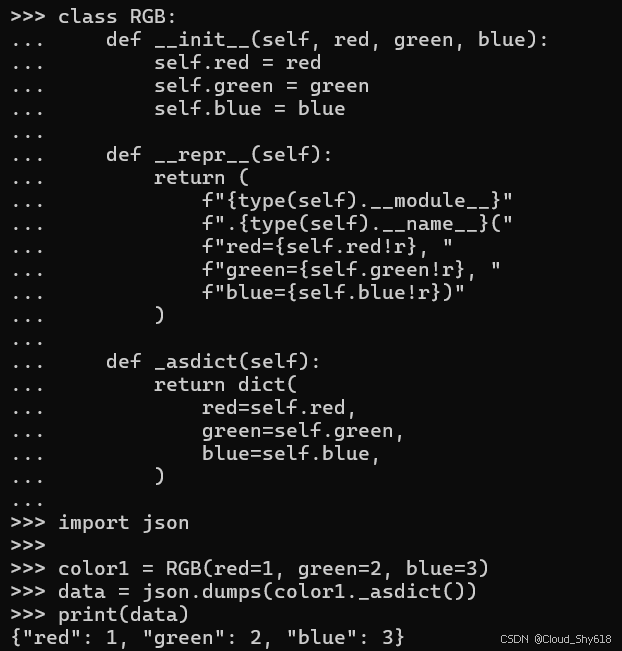
_asdict 方法还允许您使用关键字参数字典和 ** 运算符来创建对象的副本,类似于 _astuple 对于位置参数的工作方式:
color2 = RGB(**color1._asdict())
print(color2)
>>>
__main__.RGB(red=1, green=2, blue=3)
为了使用 dataclasses 模块获得相同的行为,我可以使用 asdict 函数,它避免了所有的样板:
from dataclasses import asdict
color3 = DataclassRGB(red=1, green=2, blue=3)
print(asdict(color3))
>>>
{'red': 1, 'green': 2, 'blue': 3}
dataclasses 中的 asdict 函数也优于我手工构建的 _asdict 方法;它将自动转换属性中嵌套的数据,包括基本容器类型和其他数据类对象。要使用标准类达到相同的效果需要做更多的工作(有关信息,请参阅 Item 54:"考虑使用混合类来组合功能")。
检查对象是否相等
对于标准 Python 类,两个看起来相同的对象实际上并不相同:
color1 = RGB(1, 2, 3)
color2 = RGB(1, 2, 3)
print(color1 == color2)
>>>
False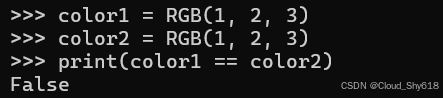
出现此行为的原因是 __eq__ 特殊方法的默认实现使用 is 操作符,它测试两个操作数是否具有相同的标识(即,它们是否占用内存中的相同位置):
assert color1 == color1
assert color1 is color1
assert color1 != color2
assert color1 is not color2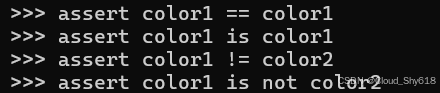
对于简单的类,当具有相同属性值的相同类型的两个对象被认为是等效的时,它会更有用。在这里,我使用 _astuple 方法为标准 Python 类实现此行为:
class RGB:
def __init__(self, red, green, blue):
self.red = red
self.green = green
self.blue = blue
def __repr__(self):
return (
f"{type(self).__module__}"
f".{type(self).__name__}("
f"red={self.red!r}, "
f"green={self.green!r}, "
f"blue={self.blue!r})"
)
def _astuple(self):
return (self.red, self.green, self.blue)
def __eq__(self, other):
return (
type(self) == type(other)
and self._astuple() == other._astuple()
)现在 == 和 != 运算符按预期工作:
color1 = RGB(1, 2, 3)
color2 = RGB(1, 2, 3)
color3 = RGB(5, 6, 7)
assert color1 == color1
assert color1 == color2
assert color1 is not color2
assert color1 != color3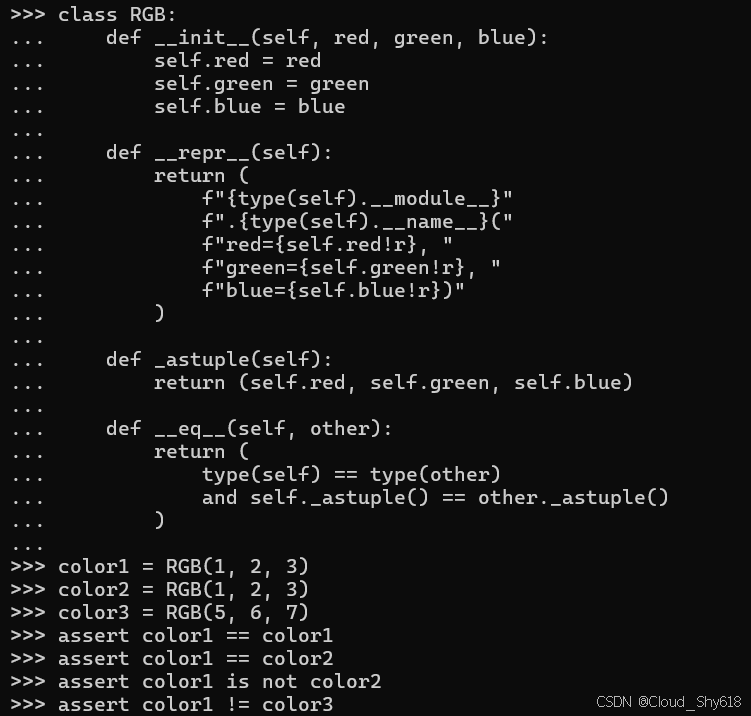
当使用 dataclass 装饰器创建类时,您会自动获得此功能,而无需自己实现 __eq__ :
color4 = DataclassRGB(1, 2, 3)
color5 = DataclassRGB(1, 2, 3)
color6 = DataclassRGB(5, 6, 7)
assert color4 == color4
assert color4 == color5
assert color4 is not color5
assert color4 != color6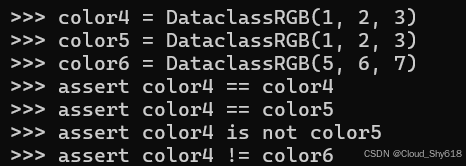
启用对象比较
除了等价之外,比较两个对象以确定哪个更大或更小也很有用。 例如,这里我定义一个标准类来表示宇宙中行星的大小及其与地球的距离:
class Planet:
def __init__(self, distance, size):
self.distance = distance
self.size = size
def __repr__(self):
return (
f"{type(self).__module__}"
f"{type(self).__name__}("
f"distance={self.distance}, "
f"size={self.size})"
)如果我尝试对这些行星进行排序,则会引发异常,因为 Python 不知道如何对对象进行排序:
import logging
try:
far = Planet(10, 5)
near = Planet(1, 2)
data = [far, near]
data.sort()
except:
logging.exception('Expected')
else:
assert False
>>>
Traceback ...
TypeError: '<' not supported between instances of 'Planet' and 'Planet'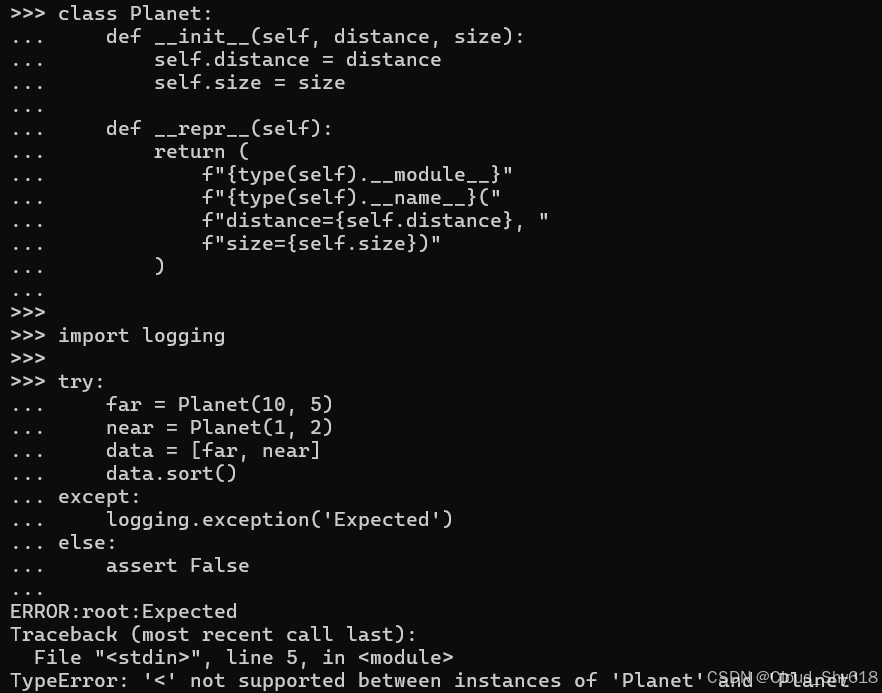
在许多情况下,有足够的解决此限制的解决方法(请参阅 Item 100:"使用关键参数按复杂标准排序")。然而,在其他情况下,您需要一个对象拥有自己的自然顺序(请参阅 Item 104:"了解如何使用 heapq 作为优先级队列")。为了在标准类中支持这种行为,我使用 _astuple 辅助方法(如上所述)来填充 Python 比较对象所需的所有特殊方法:
class Planet:
def __init__(self, distance, size):
self.distance = distance
self.size = size
def __repr__(self):
return (
f"{type(self).__module__}"
f"{type(self).__name__}("
f"distance={self.distance}, "
f"size={self.size})"
)
def _astuple(self):
return (self.distance, self.size)
def __eq__(self, other):
return (
type(self) == type(other)
and self._astuple() == other._astuple()
)
def __lt__(self, other):
if type(self) != type(other):
return NotImplemented
return self._astuple() < other._astuple()
def __le__(self, other):
if type(self) != type(other):
return NotImplemented
return self._astuple() <= other._astuple()
def __gt__(self, other):
if type(self) != type(other):
return NotImplemented
return self._astuple() > other._astuple()
def __ge__(self, other):
if type(self) != type(other):
return NotImplemented
return self._astuple() >= other._astuple()Python 允许在不同类型之间进行比较,因此我需要返回 NotImplemented 单例(与 NotImplemented Error 异常类不同)以指示对象何时不可比较。现在,这些对象具有由 _astuple 返回的值给出的自然排序,并且可以对它们进行排序(首先按距地球的距离,然后按大小),而无需任何额外的样板:
far = Planet(10, 2)
near = Planet(1, 5)
data = [far, near]
data.sort()
print(data)
>>>
[__main__Planet(distance=1, size=5), __main__Planet(distance=10, size=2)]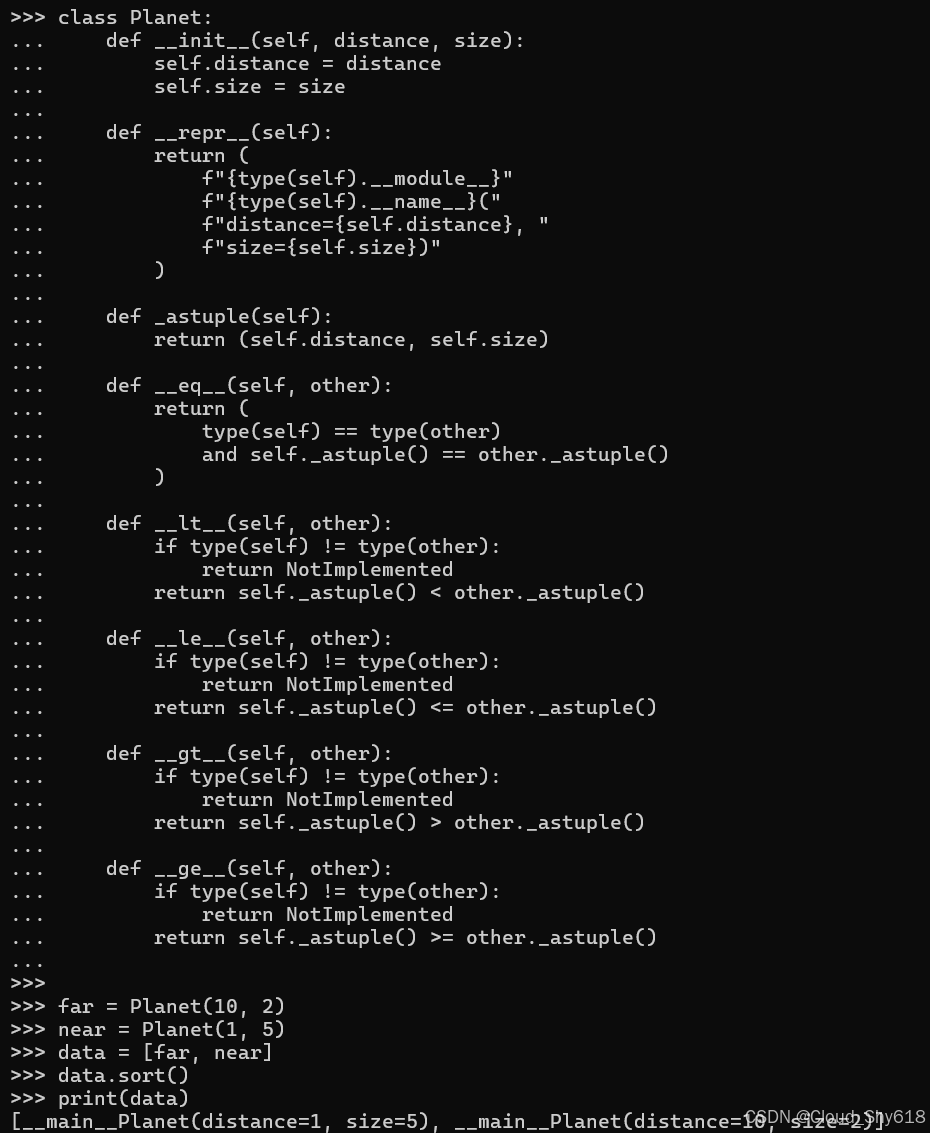
减少所需特殊方法实现数量的一种替代方法是 functools 内置模块中的 total_ordering 类装饰器。但使用数据类实现相同的行为甚至更容易。只需传递 order flag:
@dataclass(order=True)
class DataclassPlanet:
distance: float
size: float这些对象将按照它们在类主体中声明的顺序使用它们的属性进行比较:
far2 = DataclassPlanet(10, 2)
near2 = DataclassPlanet(1, 5)
assert far2 > near2
assert near2 < far2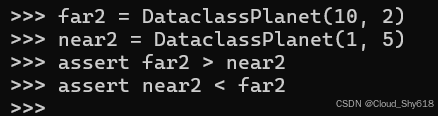
注意:
- dataclasses 内置模块中的 dataclass 装饰器可用于定义通用的轻量级类,而无需标准 Python 语法通常所需的样板文件。
- 使用 dataclasses 模块可以帮助您避免由于 Python 标准面向对象功能的冗长和容易出错的特性而导致的陷阱。
- dataclasses 模块为转换(例如,asdict、astuple)和高级属性行为(例如,field)提供了额外的辅助函数。
- 了解如何自己实现面向对象的习惯用法非常重要,这样一旦您需要的自定义超出了 dataclasses 模块的允许范围,您就可以从该模块中迁移出来。