摘要
在掌纹验证任务中,现有方法通常直接从局部纹理提取全局特征;同时,掌纹序列特征仅被当作普通局部特征使用,其自身特性未能得到充分挖掘。针对该问题,本文提出一种序列特征融合网络(SF2Net) 用于掌纹验证。该网络构建了全新的特征学习范式:将具备稳定性与空间关联性的序列特征作为中间桥梁,生成鲁棒的全局特征表征。SF2Net 的核心流程为:首先提取细粒度局部特征,再通过序列特征提取器(SFE) 将局部特征转换为序列特征;最后以序列特征作为优质输入,学习高质量全局特征。该网络融合基于多阶纹理的局部特征与由序列特征推导得到的全局特征,具备优异的特征区分能力。为使模型在训练数据有限的条件下仍保持高识别精度,本文设计了融合交叉熵损失与三元组损失的混合损失函数。其中,三元组损失通过引入负样本,有效优化特征之间的区分度。本文在多个公开掌纹数据集上开展大量实验,结果表明 SF2Net 取得了当前最优性能。值得注意的是,即便训练集与测试集比例低至 1:9,该模型依旧能够达到 100% 识别准确率,在多个基准数据集上超越了现有最优算法。本研究代码已开源,地址:https://github.com/20201422/SF2Net。
1.概述
掌纹验证是一种生物识别技术,通过分析和比对掌纹独有的特征实现身份鉴别。该技术依托手掌上复杂的纹路、脊线以及细节特征开展识别。每个人的掌纹特征都是独一无二的,即便是同卵双胞胎,掌纹也存在明显差异。与此同时,相较于其他生物识别技术,掌纹验证具备用户接受度高、使用体验佳、隐私性强等突出优势。
特征提取是掌纹验证中至关重要的环节。伽柏(Gabor)滤波器是经典且高效的特征提取工具,被广泛应用于各类相关研究中。传统方法高度依赖领域先验知识,而深度学习方法可自适应学习特征,对先验知识的依赖更低。为结合两类方法的优势,不少研究将深度学习与传统技术相融合。例如,将伽柏滤波器设置为可学习参数的卷积核,实现自适应特征提取;采用多尺度伽柏滤波器还能够抑制噪声、提升识别精度。卷积神经网络(CNN)擅长捕捉局部特征,因此现有主流方案大多结合伽柏滤波器与卷积神经网络完成掌纹特征提取。
掌纹验证的一大难点在于同时提取精细的局部纹理特征与显著的全局结构特征。因此,融合局部特征与全局特征、发挥二者互补优势,成为一种行之有效的思路。目前多数基于卷积神经网络的方法,直接从局部细节特征推导全局特征,这种方式会削弱特征表达能力。其根本缺陷在于:细粒度的局部特征缺乏空间关联性,进而导致最终得到的全局表征效果不佳。
基于排序关系构建的序列特征具备极强的空间关联性与稳定性,是一类重要的特征形式。在传统算法中,竞争编码(CompCode)利用六个不同方向的伽柏滤波器提取纹理信息,将每个像素点响应值最小的滤波器索引编码为序列特征。在此基础上,诸多传统算法不断拓展序列特征的设计形式,以此提升识别性能。除传统方法外,序列特征也被逐步引入卷积神经网络。CCNet 通过 Softmax 函数在通道维度与空间维度挖掘判别性信息,融合三个方向的序列特征,优化深度学习掌纹验证模型的性能。杨等人将该思路拓展至三维掌纹分析,结合形状索引描述子、脆弱特征位,并基于形状索引构建伽柏小波特征。上述研究均证实,序列表征能够捕捉空间关联、具备良好鲁棒性,但序列特征的潜力仍未被充分挖掘:现有工作大多仅将其视作一种普通局部描述子,未能充分利用其内在的结构稳定性。如何借助序列特征完成全局表征学习,仍是亟待解决的问题。
卷积神经网络擅长提取复杂的局部细节,但难以保留全局上下文信息。与之相对,视觉 Transformer(ViT)能够有效建模长距离依赖,非常适合提取大范围的结构特征;而序列特征自带的空间关联性,可进一步辅助视觉 Transformer 学习更优质的全局特征。
针对上述问题,本文提出一种全新的掌纹验证网络架构 ------序列特征融合网络(SF2Net)。该网络的核心设计思路为:不再单纯依赖局部细节,而是以序列特征作为中间载体,生成鲁棒性更强的全局特征表征。
由于序列特征保留了强全局空间关联特性,十分适用于构建全局表征。SF2Net 首先提取多阶局部纹理特征,再通过自研的序列特征提取器(SFE) ,将局部细节转化为稳定性更强的序列特征。随后,序列特征被输入全局特征提取模块(GFE-Block),该模块依靠长距离依赖建模能力生成高质量全局特征。最终,网络融合基于多阶纹理的原始局部特征与基于序列的全局特征,得到判别能力更强的掌纹特征表达。本文所提技术框架如图 1 所示。
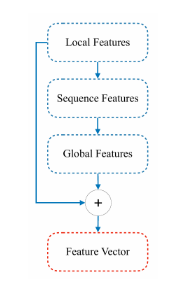
此外,为保证模型在训练数据有限的场景下仍具备高识别精度,本文设计了一种包含三元组损失的混合损失函数。该损失函数在计算过程中引入负样本,既能增大类间特征间距,又能缩小类内特征差异,实现对特征区分度的针对性优化。
本文主要创新点总结如下:
- 提出面向掌纹验证的序列特征融合网络 SF2Net,构建全新的特征融合范式。该网络创新性地以序列特征为中间桥梁生成鲁棒全局特征,并将全局特征与局部特征完成融合。
- 设计序列特征提取器(SFE),用以挖掘具备强全局空间关联性的序列特征,支撑全局表征的学习,充分发挥序列特征的固有优势。
- 在四种公开掌纹数据集上,分别基于闭集、跨光谱、开集协议开展实验。结果表明,SF2Net 不仅取得当前最优性能,即便在训练样本较少的情况下,依旧表现出色。
本文其余章节安排如下:第二章梳理相关研究工作;第三章详细介绍本文所提方法;第四章展示实验结果并展开分析讨论;第五章总结全文工作,并展望未来研究方向。
第三章 研究方法
3.1 整体框架
如图 2 所示,本文提出的序列特征融合网络(SF2Net)主要由局部特征提取、全局特征提取、特征融合三大模块构成。
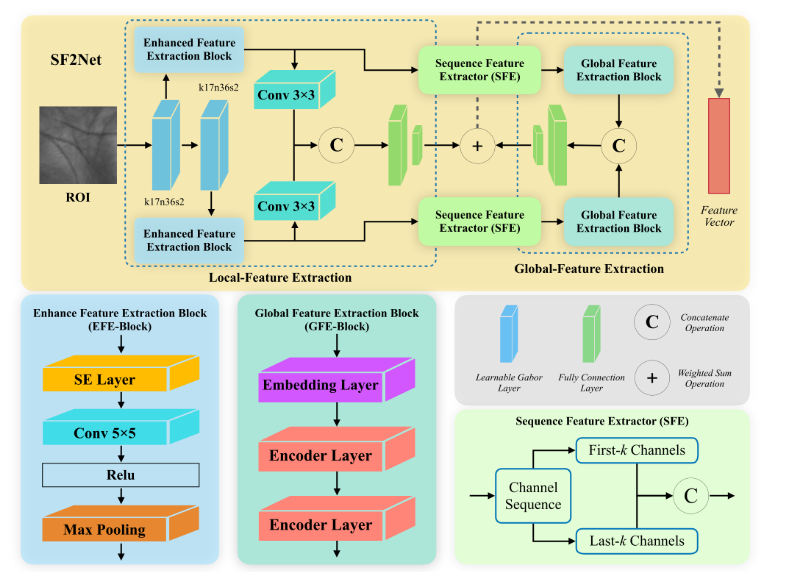
不同阶数的纹理特征具备不同特性:一阶纹理擅长表征细微褶皱,二阶纹理则更适用于描述掌纹主线等主体结构。为此,SF2Net 采用分层滤波策略:通过单层局部伽柏滤波器提取一阶纹理特征,借助双层局部伽柏滤波器得到二阶纹理特征。提取后的两类特征再经由增强特征提取模块做进一步优化。处理完成的一、二阶特征经过卷积层融合,得到多阶纹理特征,完整保留图像细粒度细节与主体结构信息。
SF2Net 的核心创新体现在第二阶段。首先利用序列特征提取器 ,从一、二阶纹理特征中挖掘序列特征。原始纹理特征主要保留像素灰度信息,而序列特征更侧重表达空间位置关系,因此能更好地捕捉全局关联。提取得到的序列特征输入全局特征提取模块进行处理,最终拼接为完整的全局特征表征,充分发挥序列特征的自身优势。
为结合局部特征与全局特征的互补优势,网络将多阶纹理特征与全局特征进行融合。融合后的特征向量既包含具备判别力的细粒度细节,又能体现长距离结构依赖,最终形成鲁棒且信息丰富的掌纹特征表达,用于后续验证任务。
3.2 序列特征提取器
伽柏滤波器的方向参数会直接决定所提取纹理特征的方向性,也是影响特征效果的关键。为获取更丰富的纹理信息,现有方法普遍采用多个不同方向的滤波器,将单通道纹理特征转换为多通道形式,以此提取判别性更强的序列特征。
图像经过增强特征提取模块后,会得到丰富的掌纹纹理特征。对特征沿通道维度执行柔性最大值运算(Softmax),特征表达的重心会从像素绝对响应强度,转向不同方向模式的相对优势,这一过程也等效于鲁棒归一化操作。该方式能让序列特征更好地保留主线、褶皱等核心结构信息,同时抑制噪声干扰,相比原始纹理具备更强的判别能力。
考虑到多阶纹理特征各自的优势,SF2Net 分别从一阶、二阶纹理特征中提取序列信息,同步保留图像细节与整体结构。序列特征的提取公式如下:
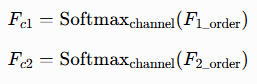
式中,F1_order∈Rb×c×w×h、F2_order∈Rb×c×w×h 分别为序列特征提取器的输入,b、c、w、h 依次代表批次大小、通道数、特征图宽度与高度;Softmaxchannel(⋅) 表示沿通道维度提取序列特征;Fc1、Fc2 分别为一阶、二阶特征对应的通道维度序列特征。
为降低特征维度、减少计算量,序列特征提取器仅选取前k个通道 与后k个通道的序列信息作为最终输出,本文结合实验设定参数 k=10。

图 3 展示了特征抗噪效果对比:图 (a)(b) 分别为添加椒盐噪声前后的滤波纹理特征;图 (c)(d) 分别为六个方向伽柏滤波得到的最大响应序列特征在加噪前后的效果。可以看出,原始纹理特征易受噪声干扰发生畸变,而序列特征始终保持稳定。
3.3 全局特征提取模块
受限于自身结构,伽柏滤波器与卷积核的感受野范围有限,仅能捕捉局部空间信息,因此提取的纹理特征本质上属于局部特征。而序列特征会兼顾整体空间结构,建立不同区域之间的关联,是学习全局特征的优质基础。
需要说明的是,序列特征并不等同于全局特征,其依旧依赖相邻元素的局部关系。但序列特征具备结构稳定、抗干扰能力强的特点,即便引入噪声也不会出现明显失真,同时能更直观地呈现掌纹验证所需的主体纹理。
凭借强全局空间关联性与高稳定性,序列特征可以有效支撑全局特征的学习。全局特征提取模块擅长建模长距离依赖关系,相较于直接输入像素级局部细节,将稳定且具备完整结构的序列特征作为该模块的输入,能够更高效地挖掘图像全局模式,生成鲁棒的全局特征表达。
3.4 局部与全局特征融合
融合阶段会整合两类特征的互补特性:局部特征来自网络前端提取的多尺度纹理信息,提供区分不同掌纹所需的细粒度细节;全局特征则依托 "序列特征过渡" 这一创新思路生成,完整表征掌纹整体结构。
网络对两类特征向量做加权求和,最终得到的特征表达,既保证细粒度区分能力,又具备全局层面的稳定性,局部与全局特征的自适应融合是模型取得优异性能的关键。
最终输出特征向量 Fout 的计算公式为:
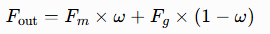
其中,Fm 为由一阶、二阶纹理特征拼接得到的多阶纹理特征(局部特征);Fg 为由 Fc1、Fc2 经过全局特征提取模块后拼接得到的全局特征;结合实验结果,权重参数设定为 ω=0.7。
3.5 混合损失函数
对于高精度掌纹验证任务,理想的特征空间需要同时满足两大条件:特征可分性强、类内样本距离紧凑、类间样本距离足够大。
交叉熵损失是分类任务的常用损失函数,核心作用是缩小模型预测结果与真实标签之间的偏差。在本任务中,该损失函数主要服务于有监督分类学习,最大化掌纹样本被正确分类的概率,将同一身份的样本特征向类别中心聚拢,有效提升类内紧凑性。其计算公式如下:
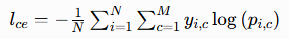
式中,N 为单类样本数量,M 为总类别数;yi,c 代表第 c 类中第 i 个样本的真实标签,pi,c 为对应样本的预测概率。
分类任务的目标是将样本划分至指定类别,而掌纹验证本质是基于特征差异的一对一匹配任务,二者存在明显区别。仅使用交叉熵损失,虽然可以优化类内相似度,但无法显式约束类间区分度。
多数公开掌纹数据集每类样本数量充足,可支撑模型依靠丰富的类内数据完成训练。但在实际应用场景中,用户通常仅录入少量掌纹样本作为注册数据,此时负样本数量会远多于正样本。在损失计算中引入负样本,能够显著提升模型的验证性能,尤其适用于训练数据不足的场景。
三元组损失直接对特征距离进行优化,同时兼顾类内紧凑性与类间分离度。其优化目标为:锚点样本与异类负样本的特征距离,大于锚点样本与同类正样本的特征距离,且二者差值不小于预设间隔。该机制主动拉大不同类别样本的间距,强化类间区分效果。三元组损失公式如下:
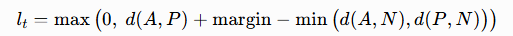
式中,A 为锚点样本,P 为同类正样本,N 为异类负样本;margin 为预设距离间隔,本文取值为 2;d(⋅,⋅) 代表欧氏距离。
本文将两种损失函数结合,构建混合损失函数,让模型学习到表征能力更强、鲁棒性更高的特征。交叉熵损失把控整体分类方向,三元组损失优化特征空间的类间结构。组合公式为:
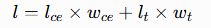
式中,wce、wt 分别为交叉熵损失与三元组损失的权重,根据实验结果,二者依次设定为 0.7 和 0.3。
这种双重优化目标十分适配掌纹验证这类开集任务,既能提升闭集测试的准确率,又能增强模型对未知类别的泛化能力,同时让模型在小样本训练条件下依旧维持良好性能。
第四章 实验与分析
4.1 数据集与实验设置
本文选取PolyU、同济(Tongji)、IITD 以及多光谱数据集这四个主流公开掌纹数据集开展实验,各数据集的采集方式存在差异:同济数据集与 IITD 数据集采用非接触式采集,PolyU 数据集为接触式采集,多光谱数据集则通过多光谱专用设备完成采集。四份数据集均包含完整掌纹图像及对应的感兴趣区域(ROI)图像。
- PolyU 数据集:包含 193 位受试者(共 386 只手掌)的 7752 张图像,每位受试者分两次采集样本。该数据集感兴趣区域图像尺寸为 128×128 像素,分辨率 72 每英寸点数。实验选取每位受试者前 5 张图像作为训练集,其余作为测试集。
- 同济数据集:涵盖 300 位受试者(共 600 只手掌)的 12000 张图像,每位受试者同样分两次采集,图像分辨率为 1280×960 像素。实验选取每组采集样本中的前 5 张用于训练,剩余图像用于测试。
- IITD 数据集:包含 230 位受试者的 2601 张图像,每位受试者有 5 至 6 张样本图像,分辨率为 256 每英寸点数。实验选取每位受试者前 3 张图像作为训练集,其余作为测试集。
- 多光谱数据集:包含 250 位受试者(共 500 只手掌),分为红光、绿光、蓝光、近红外四个子数据集,每个子数据集各含 6000 张图像,分辨率达 2500~3000 每英寸点数。实验选取每位受试者前 6 张图像作为训练集,其余作为测试集。
为验证本文算法性能,实验对比了多种当下主流方法,涵盖传统编码类算法与深度学习算法,包括:PalmCode、CompCode、OrdinalCode、FusionCode、RLOC、BOCV、E-BOCV、HOC、DOC、DRCC、2TCC、MTCC、DHPN、PalmNet、DHN、CompNet、CO3Net、CCNet、SACNet 以及 MSPHNet。
为模拟真实场景、提升模型鲁棒性并缓解过拟合问题,本文对训练集图像执行随机变换操作,包括随机裁剪、尺寸缩放与透视变换,以此丰富数据多样性;测试集图像仅做尺寸归一化处理,统一将感兴趣区域缩放至 128×128 像素。其中 CO3Net、CCNet、SACNet、MSPHNet 采用与本文算法完全一致的实验方案,其余对比算法则参照对应文献中的实验设置。
本次实验硬件环境为英伟达 RTX 3090 Ti(24GB)显卡、英特尔 i9-8222CL 处理器与 64GB 内存。模型采用 Adam 优化器训练,初始学习率设为 0.001,步长为 500,批次大小设置为 500,匹配策略参照现有研究方案执行。
实验采用 ** 等错误率(EER)与受试者工作特征曲线(ROC)** 作为核心评价指标。等错误率是验证任务的关键指标,代表错误接受率(FAR)与错误拒绝率(FRR)数值相等时的取值,该指标越低,代表验证精度越高。受试者工作特征曲线以错误接受率为横轴、真实接受率(GAR)为纵轴绘制,其中错误拒绝率 = 1 - 真实接受率。真实接受率代表正确通过合法匹配的样本占比,错误接受率代表错误通过非法匹配的样本占比,曲线越靠近坐标系左上角,算法性能越优异。
4.2 闭集实验
闭集实验的规则为:训练集与测试集样本无重叠,但全部样本均来自同一批受试者。
表 1 为三份数据集上不同算法的等错误率对比结果。可以看到,本文 SF2Net 算法在 PolyU 数据集与同济数据集上的等错误率达到 0%,在 IITD 数据集上的表现也全面优于其他对比算法,充分体现了算法的有效性与鲁棒性。
表 2 为多光谱数据集上的闭集实验结果。SF2Net 与 CCNet 在该数据集上均取得顶尖效果,证明两种算法对不同光谱输入均具备良好的适应性。
图 4 为各算法在不同数据集上的受试者工作特征曲线,可见 SF2Net 的性能与近三年的 CO3Net、CCNet、SACNet、MSPHNet 等前沿算法处于同一水准。
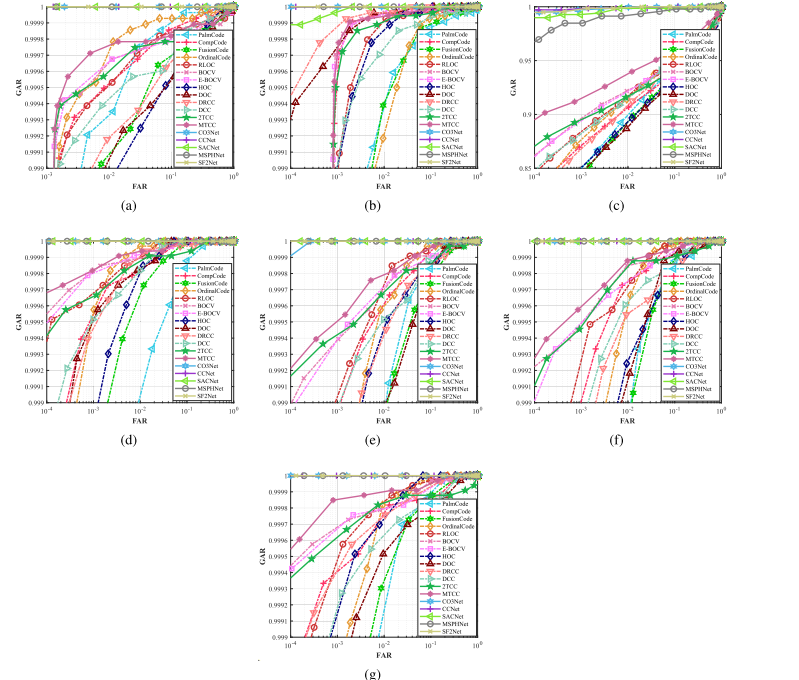
图 5 展示了 SF2Net 在各数据集上合法样本与非法样本的匹配得分分布,分别对应类内匹配与类间匹配结果。在所有测试数据集上,该算法都能清晰区分两类样本,具备出色的特征判别能力。
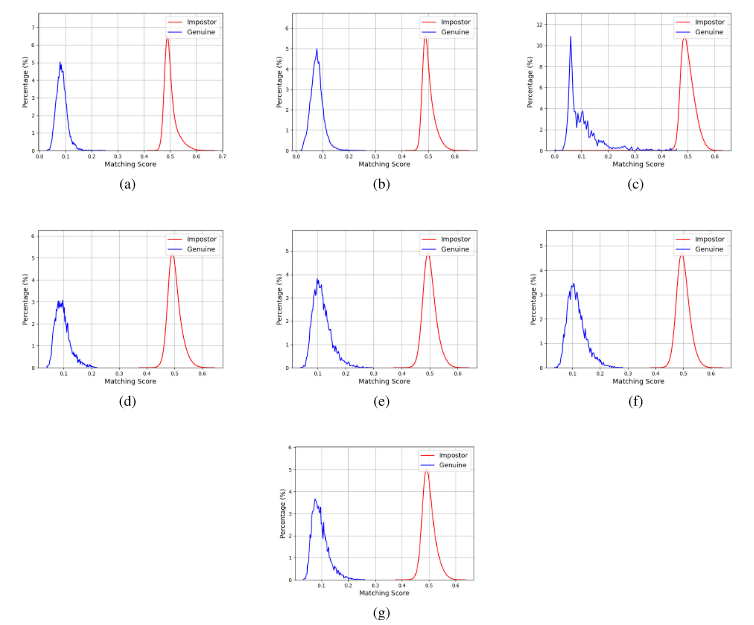
部分前沿算法与本文算法的等错误率已降至 0%,仅依靠该指标难以进一步区分性能优劣,因此本文引入 ** 判别指数d′** 作为补充评价指标。判别指数数值越大,代表合法样本与非法样本的匹配得分分布重叠区域越小、两类样本间隔越明显,说明识别系统可靠性与鲁棒性更强,在实际应用中能有效降低误判概率。判别指数计算公式如下: d′=2σ12+σ22∣μ1−μ2∣ 式中,μ1、μ2分别为合法匹配距离与非法匹配距离的均值;σ1、σ2分别为两类匹配距离的标准差。
表 3、表 4 为不同算法的判别指数对比。即便部分算法与 SF2Net 的等错误率同为 0%,本文算法的判别指数依然显著更高,这一优势在多光谱数据集上表现得尤为突出。
为模拟真实生物识别系统的应用场景(每位用户仅采集少量样本完成注册),本文调整数据集划分方式,设置训练集与测试集的样本比例,每位受试者仅选取 2 张图像用于训练,其余作为测试样本,并将 SF2Net 与 CO3Net、CCNet、SACNet、MSPHNet 等主流算法进行对比(批次大小 500,迭代轮数 1000)。实验结果如表 5 所示,在训练样本数量极少的情况下,SF2Net 依旧取得最优效果。尤其在同济数据集(训练、测试样本比例 2:18)中,该算法实现 100% 识别准确率,泛化能力十分突出。
表 6 为多光谱数据集在小样本划分规则下的等错误率与准确率。在绿光、蓝光光谱下,SF2Net 的等错误率与 CCNet 接近;在其余场景中,本文算法性能均为最优。其中近红外光谱下的提升效果尤为明显:近红外图像中掌纹纹理特征弱化、静脉特征更为突出,传统纹理提取算法难以捕捉静脉走向,而本文的序列特征提取模块能够有效强化静脉主特征的表达,提升近红外场景下的识别可靠性。
本文基于难度更高的 IITD 数据集完成超参数寻优:该数据集上多数先进算法性能都会出现明显下降,在此数据集上确定的超参数具备更强的鲁棒性,同时数据集规模较小,便于开展多组对比实验。
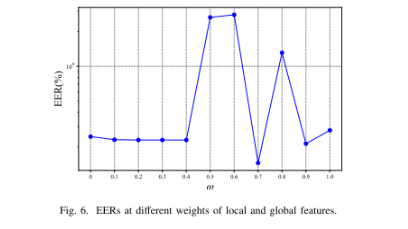
- 局部特征与全局特征融合权重:由图 6 可知,当权重ω取 0.7 时,等错误率最低,为最优取值。
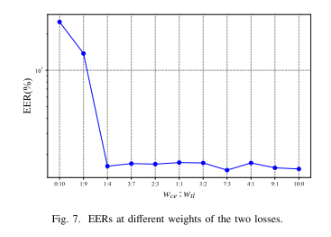
- 混合损失权重:由图 7 可得,交叉熵损失与三元组损失的权重比例设为 7:3 时效果最佳。
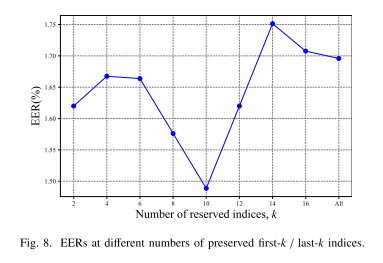
- 序列特征通道参数k:由图 8 可知,保留前k、后k个通道时,k取 10 为最优值。实验证明,保留全部序列特征并不能取得最优效果,剔除部分无效信息后,算法在小样本场景下仍能保持高性能,同时降低存储开销。
4.3 跨光谱实验
跨光谱实验的设置为:使用某一种光谱数据训练模型,再在其余光谱数据上完成测试。实验结果如表 7 所示,相较于 CO3Net、CCNet、SACNet、MSPHNet 等主流算法,SF2Net 在所有跨光谱测试场景中均取得最低等错误率,跨光谱泛化能力更强。
在可见光光谱的跨场景测试中,SF2Net 的等错误率趋近于 0;在近红外光谱场景下,算法性能相比其他竞品也有大幅提升,证明该算法能够适应光照变化复杂的真实应用环境。同时实验也发现,可见光光谱与近红外光谱之间的跨域测试效果,要弱于不同可见光光谱之间的测试效果。
原因在于两类图像所捕捉的生物特征存在本质差异:近红外成像可穿透皮肤,重点呈现皮下静脉结构,而可见光图像主要采集手掌表层纹理,二者特征域差异较大;红、绿、蓝三类可见光图像的表层纹理高度相似,特征关联性强,域间差距更小。尽管 SF2Net 具备优秀的跨光谱泛化能力,但可见光与近红外图像之间巨大的特征差异,仍是跨域识别的主要难点。
4.4 跨数据集实验
跨数据集实验同时也属于开集实验,实验设置为:分别使用 PolyU、同济、IITD 其中一个数据集训练模型,再在另外两个数据集上测试,以此验证算法的跨数据集泛化能力。实验结果如表 8 所示,在绝大多数跨数据集组合中,SF2Net 的等错误率均低于对比算法,整体泛化性能优异。
当目标测试集为同济数据集时,SF2Net 的优势最为明显;使用同济数据集训练、分别在 PolyU 与 IITD 数据集测试时,算法也取得最低等错误率。仅有一组实验例外:使用 PolyU 数据集训练、IITD 数据集测试时,CCNet 性能略优于 SF2Net,说明本文算法在部分跨数据集场景中仍有优化空间。整体而言,SF2Net 能够适配不同采集设备、不同采集方式的掌纹数据,具备落地到实际生物识别系统的潜力,后续可通过优化特征对齐策略,进一步缩小跨数据集场景下的性能损失。
4.5 消融实验
本文在 IITD 数据集上开展消融实验,验证多阶纹理、序列特征提取器、三元组损失三大核心组件的作用,实验结果如表 9 所示。
实验证明,每一个组件都对模型性能起到关键作用:引入多阶纹理特征,能够有效提升特征判别能力;序列特征提取器可以挖掘完整的序列特征,优化全局表征学习;将交叉熵损失与三元组损失结合后,模型等错误率显著下降,同时维持高准确率,证明联合约束特征空间的有效性。当三大组件全部启用时,模型取得最低等错误率(0.1449%)。消融实验充分证实,三者协同作用是算法实现顶尖性能的核心保障。
第五章 结论与展望
本文提出了一种序列特征融合网络 SF2Net,并将其应用于掌纹验证任务。该算法充分挖掘序列特征的固有优势,将纹理细节信息与全局特征表征高效融合,有效提升掌纹验证效果。
本文的核心设计思路为:把稳定性强、具备空间关联特性的序列特征作为中间过渡载体,以此构建鲁棒的全局特征表达。同时,针对训练样本不足的场景,设计融合交叉熵损失与三元组损失的混合损失函数,通过约束锚点样本、正样本与负样本之间的特征距离,进一步优化特征学习效果。
实验结果表明,依托序列特征完成全局表征学习的方案效果显著,即便在每位受试者仅提供少量训练样本的小样本场景下,SF2Net 依旧能保持优异性能。
在未来的研究工作中,我们计划引入风格迁移、联邦学习等前沿技术,进一步提升模型在跨光谱、跨数据集场景下的泛化能力。同时,将持续优化序列特征提取策略,让算法在复杂多变的真实环境与高难度实测场景中,始终保持稳定可靠的表现。