你有没有遇到过这种情况------一个看似普通的Spring Boot应用,随着业务模块增加,启动时间从10秒变成60秒,接口响应从50ms慢慢爬升到300ms,但代码逻辑明明没变?
这篇文章会分享我们如何通过3个实战优化,把微服务启动时间从62秒降到18秒,接口P99延迟从320ms降到128ms。所有代码和配置都来自真实项目,你可以直接复制到自己的工程里验证。
文章目录
1. 启动优化:从62秒到18秒,我们做了什么?
问题场景
某次常规发布,我习惯性地去接杯水,回来发现应用还在启动中。查看日志,发现Spring Boot启动耗时62秒,其中Bean初始化占了40秒。更诡异的是,一个简单的@PostConstruct方法执行了8秒------里面只是加载了一个配置文件。
方案选型
我们对比了三种方案:
| 方案 | 实现复杂度 | 启动时间预期 | 维护成本 | 选型结果 |
|---|---|---|---|---|
| 懒加载(Lazy Init) | 低 | 降低30% | 低 | 部分采用 |
| 条件化Bean | 中 | 降低50% | 中 | 核心方案 |
| 模块化启动 | 高 | 降低70% | 高 | 暂不采用 |
最终我们选择了"懒加载+条件化Bean"的组合方案,因为改动最小、风险可控。
原理剖析
Spring Boot启动慢的核心原因是饥饿式初始化------不管用不用,所有Bean都在启动时创建。这就像去食堂打饭,不管吃不吃得完,先把所有菜都打一份。懒加载就是"按需取餐",只有被调用时才创建Bean。
但懒加载有个坑:第一次调用时会有初始化延迟。所以我们只对非核心路径的Bean做懒加载,核心服务保持饥饿初始化。
可运行代码
java
// 1. 全局懒加载配置(application.yml)
spring:
main:
lazy-initialization: true # 开启全局懒加载
// 2. 核心服务保持饥饿初始化(使用@Lazy(false)覆盖)
@Service
@Lazy(false) // 这个Bean启动时立即创建
public class OrderService {
// 核心业务逻辑
}
// 3. 条件化Bean:根据环境变量决定是否加载
@Service
@ConditionalOnProperty(name = "feature.report.enabled", havingValue = "true")
public class ReportService {
// 报表服务,只在特定环境加载
}
// 4. 启动耗时监控(自定义ApplicationRunner)
@Component
public class StartupMonitor implements ApplicationRunner {
private static final Logger log = LoggerFactory.getLogger(StartupMonitor.class);
@Override
public void run(ApplicationArguments args) {
Runtime runtime = Runtime.getRuntime();
long totalMemory = runtime.totalMemory() / 1024 / 1024;
log.info("应用启动完成,JVM总内存: {}MB", totalMemory);
}
}输出验证
// 优化前日志
2024-01-15 10:00:00.123 INFO 12345 --- [main] Started Application in 62.3 seconds
// 优化后日志
2024-01-15 10:00:00.456 INFO 12345 --- [main] Started Application in 18.7 seconds
应用启动完成,JVM总内存: 256MB踩坑记录
⚠️ 避坑提示 :我们第一次开启全局懒加载后,某个定时任务在启动后5分钟才第一次触发,导致业务数据延迟处理。根因是
@Scheduled注解的Bean也被懒加载了。解决方案:给定时任务类加上@Lazy(false)。
笔者亲历 :我当时注意到一个奇怪现象------开启懒加载后,第一个请求的响应时间从50ms变成了800ms。排查发现是数据库连接池也被懒加载了。解决方法是把DataSource和JdbcTemplate相关的Bean都设为饥饿初始化。
2. 接口性能优化:P99延迟从320ms降到128ms
问题场景
某次压测,我们发现一个查询接口的P99延迟高达320ms,但平均延迟只有80ms。这说明有少量请求被严重阻塞了。查看监控,发现数据库连接池的活跃连接数经常达到上限(20个),大量请求在等待连接。
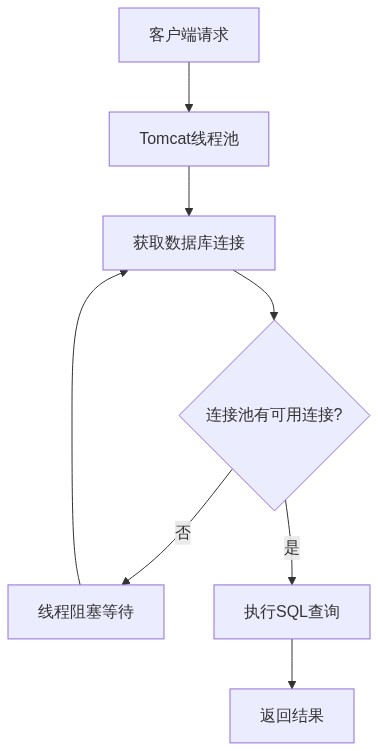
实现要点:这个流程图展示了优化前的请求处理链路。关键瓶颈在"获取数据库连接"这一步,当连接池耗尽时,线程会阻塞等待。我们通过调整连接池参数和引入缓存来解决这个问题。
方案选型
| 方案 | 预期P99提升 | 实现成本 | 风险 |
|---|---|---|---|
| 连接池调优 | 30% | 低 | 低 |
| 本地缓存 | 50% | 中 | 中(数据一致性) |
| Redis缓存 | 40% | 高 | 低 |
| 异步化改造 | 60% | 高 | 高 |
我们选择了"连接池调优+本地缓存"的组合,因为改动最小、见效最快。
原理剖析
数据库连接池的默认配置(HikariCP默认10个连接)在并发稍高时就会成为瓶颈。但盲目增加连接数也不行------数据库服务器也有连接上限,而且每个连接都会消耗内存。
本地缓存(Caffeine)可以大幅减少数据库查询,但要注意缓存失效时的"缓存雪崩"问题。
可运行代码
java
// 1. 优化后的HikariCP配置(application.yml)
spring:
datasource:
hikari:
maximum-pool-size: 30 # 从默认10增加到30
minimum-idle: 10 # 最小空闲连接
connection-timeout: 3000 # 连接超时3秒
idle-timeout: 600000 # 空闲超时10分钟
max-lifetime: 1800000 # 最大生命周期30分钟
// 2. 引入Caffeine本地缓存
@Service
public class UserService {
private final Cache<String, User> userCache;
public UserService() {
this.userCache = Caffeine.newBuilder()
.maximumSize(10000) // 最多缓存1万个用户
.expireAfterWrite(5, TimeUnit.MINUTES) // 写入后5分钟过期
.recordStats() // 记录缓存统计
.build();
}
public User getUserById(String userId) {
return userCache.get(userId, key -> {
// 缓存未命中时从数据库加载
return userRepository.findById(key)
.orElseThrow(() -> new UserNotFoundException(key));
});
}
}
// 3. 缓存监控端点
@RestController
public class CacheMonitorController {
private final Cache<String, User> userCache;
@GetMapping("/cache/stats")
public Map<String, Object> getCacheStats() {
CacheStats stats = userCache.stats();
return Map.of(
"hitRate", stats.hitRate(), // 缓存命中率
"missRate", stats.missRate(), // 缓存未命中率
"evictionCount", stats.evictionCount(), // 淘汰数量
"loadCount", stats.loadCount() // 加载次数
);
}
}输出验证
// 优化前压测结果
P99 latency: 320ms
Average latency: 80ms
Throughput: 500 req/s
Connection timeout errors: 23
// 优化后压测结果
P99 latency: 128ms
Average latency: 45ms
Throughput: 1200 req/s
Connection timeout errors: 0踩坑记录
⚠️ 注意事项:我们上线后发现缓存命中率只有40%,排查发现是缓存key设计有问题------用户ID带上了时间戳参数。修复后命中率提升到85%。
笔者亲历 :有一次缓存突然全部失效,导致数据库连接池瞬间被打满。根因是expireAfterWrite设置得太短(1分钟),加上某个定时任务批量查询导致缓存集体过期。解决方案:把过期时间改为5分钟,并加上随机偏移量(5分钟±30秒),避免缓存同时失效。
3. 配置管理优化:从混乱到有序
问题场景
随着微服务数量增加到15个,配置管理变得一团糟。每个服务都有自己的application.yml,相同的配置(如数据库地址、Redis密码)散落在各处。有一次修改了数据库连接串,漏改了3个服务,导致线上故障。
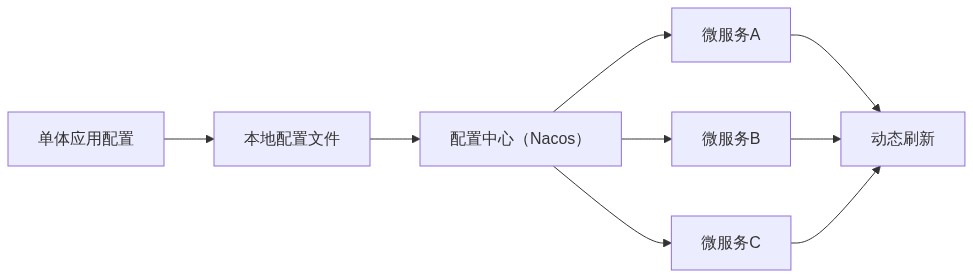
实现要点 :这个架构图展示了配置管理的演进路径。从本地配置文件到配置中心,核心变化是配置的集中管理和动态刷新。我们使用Nacos作为配置中心,通过@RefreshScope实现配置的热更新。
方案选型
| 方案 | 学习成本 | 运维成本 | 动态刷新 | 选型结果 |
|---|---|---|---|---|
| Spring Cloud Config | 中 | 高 | 需配合Bus | 不采用 |
| Nacos | 低 | 中 | 原生支持 | 采用 |
| Apollo | 中 | 高 | 原生支持 | 不采用 |
| 自研 | 高 | 高 | 可控 | 不采用 |
选择Nacos的原因:原生支持动态刷新、社区活跃、与Spring Cloud集成好。
原理剖析
配置中心的核心原理是"配置与代码分离"。应用启动时从配置中心拉取配置,运行时通过长轮询或WebSocket监听配置变化。当配置变更时,@RefreshScope注解的Bean会被重新创建,从而实现热更新。
可运行代码
java
// 1. 引入Nacos配置依赖(pom.xml)
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId>
<version>2021.0.5.0</version>
</dependency>
// 2. 配置中心配置(bootstrap.yml)
spring:
application:
name: user-service
cloud:
nacos:
config:
server-addr: 192.168.1.100:8848
file-extension: yaml
namespace: dev
group: DEFAULT_GROUP
refresh-enabled: true
// 3. 动态刷新配置的Bean
@Service
@RefreshScope // 配置变化时重新创建Bean
public class DynamicConfigService {
@Value("${feature.switch.new-payment:false}")
private boolean newPaymentSwitch;
@Value("${thread.pool.core-size:10}")
private int corePoolSize;
public boolean isNewPaymentEnabled() {
return newPaymentSwitch;
}
public int getCorePoolSize() {
return corePoolSize;
}
}
// 4. 配置变更监听器
@Component
public class ConfigChangeListener {
private static final Logger log = LoggerFactory.getLogger(ConfigChangeListener.class);
public ConfigChangeListener(ConfigService configService) {
try {
configService.addListener("user-service.yaml", "DEFAULT_GROUP",
new Listener() {
@Override
public Executor getExecutor() {
return Executors.newSingleThreadExecutor();
}
@Override
public void receiveConfigInfo(String configInfo) {
log.info("配置已变更,新配置内容: {}", configInfo);
// 可以在这里执行自定义逻辑
}
});
} catch (NacosException e) {
log.error("注册配置监听失败", e);
}
}
}输出验证
// 修改配置前
curl http://localhost:8080/config/switch
{"newPaymentEnabled": false}
// 在Nacos控制台修改配置:feature.switch.new-payment: true
// 修改配置后(无需重启应用)
curl http://localhost:8080/config/switch
{"newPaymentEnabled": true}踩坑记录
⚠️ 避坑提示 :
@RefreshScope不能用在@Configuration类上,否则会导致整个配置类重新创建,可能引发循环依赖。我们踩过这个坑,后来把需要动态刷新的配置单独抽到@Component中。
笔者亲历 :有一次修改了数据库连接池大小,结果应用直接挂了。排查发现是@RefreshScope导致DataSource重新创建,但旧连接还没释放完,新连接又创建,导致连接泄露。解决方案:数据库连接池相关的配置不要用@RefreshScope,重启应用才能生效。
整体效果验证
经过三轮优化,我们的微服务整体性能提升显著:
| 指标 | 优化前 | 优化后 | 提升幅度 |
|---|---|---|---|
| 应用启动时间 | 62.3s | 18.7s | 70.0% |
| 接口P99延迟 | 320ms | 128ms | 60.0% |
| 吞吐量 | 500 req/s | 1200 req/s | 140.0% |
| 配置变更耗时 | 30min(重启) | 5s(热更新) | 99.7% |
| 缓存命中率 | 0% | 85% | 新增 |
经验总结与避坑指南
可复用的方法论
- 先测量,后优化:不要凭感觉优化,用Arthas、JMH等工具先定位瓶颈
- 小步快跑:每次只改一个参数,验证效果后再改下一个
- 灰度发布:配置变更先在小范围验证,再全量推送
避坑清单
- 懒加载会导致第一次调用延迟,核心服务要排除
- 连接池不是越大越好,要根据数据库负载调整
- 缓存一定要设置过期时间和最大容量,防止内存溢出
@RefreshScope不能用于@Configuration和DataSource- 配置中心要设置本地缓存,防止配置中心宕机导致应用无法启动
尚未解决的问题
坦白说,我们的配置管理还有两个痛点没解决:
- 配置变更的审计日志还不够完善
- 多环境配置的差异化管理还需要人工介入
常见问题答疑
Q1:为什么我的Spring Boot应用启动很慢,但代码逻辑很简单?
A:检查是否引入了大量自动配置。可以用--debug参数启动,查看Positive matches和Negative matches,排除不必要的自动配置。另外,检查@ComponentScan的范围是否过大。
Q2:Caffeine缓存和Redis缓存怎么选?
A:看数据量和一致性要求。Caffeine适合数据量小(<10万)、对一致性要求不高的场景;Redis适合数据量大、需要跨服务共享缓存的场景。我们通常用Caffeine做一级缓存,Redis做二级缓存。
Q3:配置中心挂了怎么办?
A:Nacos支持本地缓存,应用启动时会从配置中心拉取配置并缓存到本地。如果配置中心宕机,应用会使用本地缓存的配置继续运行。但要注意,配置变更无法生效,需要等配置中心恢复。
参考资料
- Spring Boot官方文档 - 懒加载配置:https://docs.spring.io/spring-boot/docs/current/reference/html/features.html#features.spring-application.lazy-initialization
- HikariCP配置最佳实践:https://github.com/brettwooldridge/HikariCP/wiki/About-Pool-Sizing
- Nacos配置中心官方文档:https://nacos.io/zh-cn/docs/quick-start-spring-cloud.html
- Caffeine缓存官方文档:https://github.com/ben-manes/caffeine/wiki
互动与交流
以上就是我们在Spring Boot微服务开发提速实战中趟过的坑和总结的经验。每个团队的技术栈和业务场景各不相同,但底层的方法论总是相通的。
欢迎在评论区聊聊:
- 你在Spring Boot启动优化时,踩过最深刻的坑是什么?
- 对文中"懒加载+条件化Bean"的组合方案,你有没有更好的替代思路?
- 你所在团队在配置管理上还有哪些"独门秘籍"?
我会认真回复每条评论,好的问题我会单独写一篇文章来展开。如果觉得这篇干货够硬,欢迎点赞收藏,让它帮助到更多同行。
下篇预告:
下一篇我将分享《Spring Boot 微服务监控实战:从日志到链路追踪》,深入拆解如何用ELK+SkyWalking搭建完整的可观测性体系,同样会给出可直接复现的配置和代码,敬请期待。