
大家好,我是张大鹏,欢迎来到大鹏AI教育。 在 AI 时代,我们一起学编程、做项目,把技术真正用起来。 这一节课,我们来学习 Pandas 为什么会这么流行。
Pandas 之所以流行,一个很重要的原因,就是它用起来比较直观。 对于很多刚开始学习 Python 数据分析的同学来说,最害怕的不是数据本身,而是不知道怎么操作这些数据。 Pandas 提供了一套比较友好的接口,让我们可以用比较简单的代码,完成数据读取、查看、筛选、统计和分析这些操作。 也就是说,它把很多复杂的数据处理过程,变得更接近我们的日常理解。 比如我们平时看到的数据,很多都是表格形式的。 Excel 是表格。 数据库查询结果也是表格。 CSV 文件打开之后,看起来也像表格。 而 Pandas 里面最常用的数据结构,也很像这种表格。 所以很多同学第一次接触 Pandas 的时候,会觉得它并不是特别陌生。 因为它处理数据的方式,和我们平时看 Excel 表格、看数据库表的感觉很像。
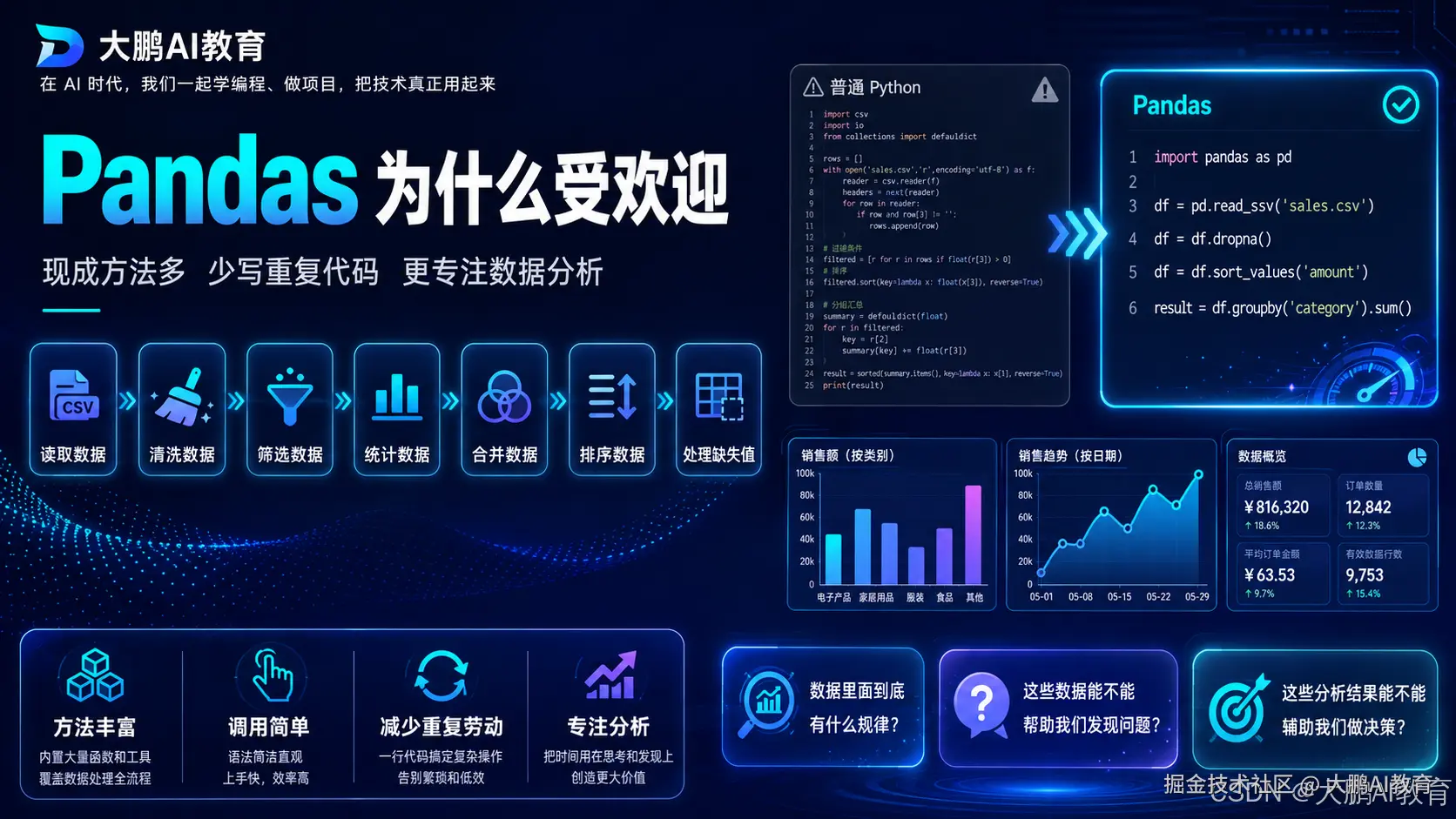
Pandas 受欢迎的另一个原因,是它提供了很多现成的方法。 在真实工作中,我们处理数据时,经常要做这些事情: 读取数据、清洗数据、筛选数据、统计数据、合并数据、排序数据、处理缺失值。 如果这些操作都用普通 Python 代码从头写,会比较麻烦。 但是 Pandas 已经帮我们封装好了很多常用功能。 我们只需要调用对应的方法,就可以完成很多数据处理工作。 这样做的好处是,使用 Pandas 的时候,我们不用把太多精力浪费在重复、繁琐的数据处理细节上。
我们可以把更多注意力放在真正重要的事情上: 数据里面到底有什么规律? 这些数据能不能帮助我们发现问题? 这些分析结果能不能辅助我们做决策? 这也是 Pandas 对数据分析非常有价值的地方。

Pandas 能够流行起来,还和它的开源社区有关。 Pandas 是一个开源项目。 这意味着,世界各地的开发者都可以参与它的改进。 有人会贡献新功能。 有人会修复问题。 有人会完善文档。 有人会帮助它适配更多真实的数据分析场景。 正是因为有大量开发者和用户持续参与,Pandas 才能不断更新和完善。

另外,Pandas 不是孤立存在的。 它和 Python 数据分析生态中的很多工具都能很好地配合使用。 比如,Pandas 可以和 NumPy 一起做数值计算。 可以和 Matplotlib 一起做数据可视化。 也可以和 scikit-learn 一起做机器学习前的数据准备。 这让 Pandas 不只是一个单独的工具,而是整个 Python 数据分析工作流中的重要一环。

所以我们可以这样理解:
Pandas 之所以流行,不只是因为它功能强大。
更重要的是,它把 Python 处理表格数据这件事,变得更加简单、直观和高效。
它的语法比较友好,处理数据的方式很接近 Excel 表格和数据库表,所以初学者更容易理解。
它提供了很多现成的方法,让我们可以快速完成数据读取、清洗、筛选、统计、合并、排序和缺失值处理。
它背后还有活跃的开源社区,不断贡献新功能、修复问题、完善文档,让 Pandas 持续更新和进化。
同时,它还能和 NumPy、Matplotlib、scikit-learn 这些工具配合使用,成为 Python 数据分析工作流中的重要一环。

这一节我们只需要记住一句话: Pandas 之所以流行,是因为它让 Python 处理表格数据变得简单、直观、高效,并且能够很好地融入整个 Python 数据分析生态。 后面我们学习 Pandas,其实就是学习如何用这些简单直观的方法,完成真实的数据处理和数据分析工作。 好了,这节课我们就先讲到这里。 我是张大鹏,关注大鹏AI教育,我们一起在 AI 时代学编程、做项目。