CUDA Driver API 完全指南:从底层原理到与 Runtime API 的深度对比
在CUDA开发的入门阶段,我们接触的几乎都是Runtime API(运行时API) :cudaMalloc、cudaMemcpy、<<<>>>核函数启动......这些接口简单易用,几行代码就能跑起一个GPU程序。但很多人不知道,Runtime API 只是一层封装,它的底层是更基础、更灵活的 Driver API(驱动API)。
Driver API 是CUDA软件栈的最底层接口,直接和GPU驱动交互,掌握它能帮我们彻底理解CUDA的运行机制,也能应对Runtime API无法覆盖的复杂场景:比如动态加载核函数、多上下文隔离、跨语言/跨框架调用、底层性能调优等。
本文将从架构层级出发,系统对比Driver API与Runtime API的核心差异,讲解Driver API的核心概念与基础使用流程,并通过完整代码示例带你写出第一个基于Driver API的CUDA程序。
一、先理清定位:两层API的架构关系
CUDA的软件栈是分层设计的,从下到上依次是:
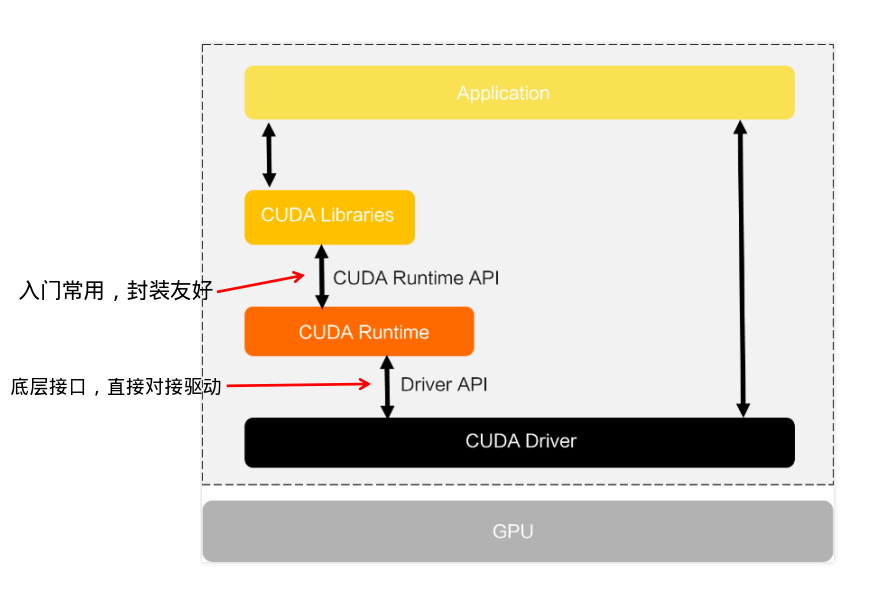
两者的关系:
Runtime API 是基于 Driver API 封装的高层接口,它隐藏了上下文管理、模块加载等底层细节,降低了开发门槛;而 Driver API 是更贴近硬件的底层接口,灵活性更高,但开发更繁琐。
打个通俗的比方:
- Runtime API 就像自动挡汽车,踩油门就走,不用管离合、换挡,适合日常使用
- Driver API 就像手动挡汽车,需要手动控制离合、挡位,操作复杂,但能精准控制动力输出,适合高性能、定制化场景
二、全方位对比:Driver API vs Runtime API
我们从开发体验、功能范围、适用场景等多个维度,系统对比两者的差异:
| 对比维度 | Runtime API | Driver API |
|---|---|---|
| 接口前缀 | cuda 开头,如 cudaMalloc |
cu 开头,如 cuMemAlloc |
| 抽象层级 | 高层封装,隐藏大量底层细节 | 底层接口,直接映射驱动能力 |
| 初始化方式 | 隐式初始化,首次调用API时自动完成 | 显式初始化,必须手动调用 cuInit |
| 上下文管理 | 隐式上下文,每个设备自动创建一个默认上下文,用户无感知 | 显式上下文,必须手动创建、绑定、销毁 CUcontext |
| 核函数管理 | 编译时静态编译进程序,运行时自动加载 | 运行时动态加载,支持加载PTX、Cubin等二进制 |
| 核函数启动 | <<<grid, block>>> 语法糖,编译器自动处理参数 |
cuLaunchKernel 手动调用,需手动配置网格、块、参数列表 |
| 代码复杂度 | 低,和普通C++代码差异小 | 高,需要手动管理所有资源生命周期 |
| 功能边界 | 覆盖绝大多数通用场景,高级功能受限 | 覆盖驱动全部能力,支持底层硬件控制 |
| 性能开销 | 极薄封装,和Driver API性能几乎无差异 | 无额外封装开销,理论性能上限一致 |
| 编译依赖 | 依赖nvcc编译器处理核函数语法 | 不依赖nvcc,纯C/C++即可调用,核函数可单独编译 |
| 典型使用场景 | 常规CUDA应用、算法开发、快速原型 | 框架开发、推理引擎、动态代码生成、多GPU隔离 |
几个核心差异的深入说明
1. 隐式上下文 vs 显式上下文
这是两者最本质的区别。
- Runtime API :你不需要知道"上下文"是什么,首次调用
cudaMalloc等接口时,CUDA会自动为当前线程绑定一个默认上下文,所有操作都在这个上下文里执行。 - Driver API :
CUcontext是GPU的"执行环境",类似CPU上的进程概念------包含内存地址空间、资源句柄、状态等。你必须手动创建上下文,并将其绑定到当前线程,后续的所有操作才会生效。
2. 静态编译 vs 动态加载
- Runtime API :核函数写在
.cu文件里,nvcc编译时直接把设备代码编译进最终的可执行文件,运行时自动加载,你感知不到加载过程。 - Driver API :设备代码和主机代码完全分离,你可以把核函数单独编译成PTX或Cubin文件,在程序运行时动态加载,甚至可以在运行时生成PTX代码再编译执行。
3. 语法糖 vs 纯函数调用
- Runtime API 的
<<<grid, block, smem, stream>>>是nvcc提供的语法糖,编译器会把它展开成底层的Driver API调用。 - Driver API 没有语法糖,启动核函数就是一个普通的C函数调用,所有参数都要手动传递。
三、Driver API 四大核心概念
在写代码之前,我们必须先搞懂Driver API里四个最核心的对象,它们是Runtime API里隐式处理的部分,也是理解底层运行机制的关键。
1. CUdevice:物理GPU设备
CUdevice 代表一个物理GPU显卡,是对硬件设备的抽象。
- 一台机器上有几张GPU,就有几个
CUdevice - 通过索引获取设备,从0开始编号,和Runtime API的设备编号一一对应
- 它只是一个设备标识,不包含运行状态
2. CUcontext:GPU执行上下文
CUcontext 是Driver API最核心的概念,相当于GPU上的"进程"。
- 一个上下文对应一个地址空间,内存、模块、流等资源都归属于某个上下文
- 同一个GPU可以创建多个上下文,它们之间相互隔离,内存不可直接互访
- 上下文和线程绑定:一个线程同一时间只能有一个"当前上下文",通过
cuCtxSetCurrent切换
补充:Runtime API的默认上下文,本质上就是驱动自动帮你创建的一个
CUcontext。
3. CUmodule:设备代码模块
CUmodule 是设备代码的容器,对应编译好的PTX或Cubin文件。
简单来说,CUmodule 代表一个动态加载到当前上下文中的 CUDA 模块。这个模块对应于一个已经编译好的、包含 GPU 代码的二进制文件(通常是 .cubin 文件或 .ptx 文件)。
- 一个模块可以包含多个核函数、设备函数、常量内存等
- 运行时加载到上下文中,类似CPU上的动态库(.so/.dll)
- 同一个模块可以加载到不同的上下文中,相互独立
CUmodule 是驱动 API 中管理 GPU 代码二进制文件的容器,通过它你可以获取并启动具体的内核函数 。 如果你只是普通的 CUDA 编程,使用运行时 API 会更方便;但需要底层精细控制时,就需要和 CUmodule 打交道了。
使用驱动API(显式加载CUmodule)更好的典型场景:
一、需要运行时动态性
- 运行时生成或修改GPU代码
- 场景:根据输入数据特征动态生成优化的PTX代码
- 例子 :
- 深度学习框架根据网络结构实时生成融合kernel
- 稀疏矩阵计算根据非零元分布生成专用kernel
- 根据问题规模动态展开循环、调整寄存器使用
- 为什么更好:运行时API无法在程序运行时创建新kernel
- 运行时选择不同版本的kernel
-
场景:根据GPU架构、输入大小、精度要求等条件选择最优kernel
-
例子:
c// 根据当前GPU动态选择最合适的cubin if (gpu_arch >= 80) cuModuleLoad(&mod, "sm80_optimized.cubin"); else if (gpu_arch >= 70) cuModuleLoad(&mod, "sm70_optimized.cubin"); -
为什么更好:运行时API只能编译时固定一个版本
- 插件化架构
- 场景:应用程序支持第三方或用户提供的kernel
- 例子 :
- 图像处理软件允许用户编写自定义滤镜kernel
- 科学计算平台支持用户提交自定义计算kernel
- 为什么更好:kernel作为独立文件分发,主程序无需重新编译
二、需要精细的资源控制
- 延迟加载和按需卸载
- 场景:程序有多个可选功能模块,但不一定全部使用
- 例子 :
- 大型软件有上百个kernel,但单次运行只用到少数几个
- 移动设备或嵌入式系统显存有限
- 为什么更好:运行时API会一次性加载所有嵌入的kernel,占用显存
- 显式管理GPU内存占用
-
场景:需要精确控制模块代码和常量内存的加载/释放时机
-
例子 :
ccuModuleLoad(&mod, "large_kernel.cubin"); // 执行一些操作 cuModuleUnload(mod); // 立即释放,不等程序结束 -
为什么更好:运行时API无法单独卸载某个kernel
三、需要命名空间隔离
- 同名kernel共存
- 场景:需要同时使用多个同名但实现不同的kernel
- 例子 :
- A/B测试两种算法实现(都叫
process) - 版本兼容:同时加载v1和v2接口
- 多个库可能导出相同名称的kernel
- A/B测试两种算法实现(都叫
- 为什么更好:运行时API的kernel在全局命名空间,会冲突
- 独立的编译单元
- 场景:大型项目需要模块化开发和测试
- 例子 :
- 不同团队开发的kernel独立编译、打包
- 可以热更新某个模块而不影响其他模块
- 为什么更好 :每个
CUmodule独立,互不干扰
四、需要特殊的部署/分发模式
- 减小主程序体积
- 场景:主程序需要保持小巧,GPU代码单独分发
- 例子 :
- 安装包可以只下载主程序,kernel按需下载
- 嵌入式系统:主程序在ROM,kernel在可更新的存储
- 为什么更好:运行时API会将GPU代码嵌入可执行文件
- 避开静态初始化开销
- 场景:需要快速启动或嵌入式实时系统
- 例子 :
- 程序启动时间要求严格(<100ms)
- 运行时API的静态注册在
main()之前执行,增加启动延迟
- 为什么更好:可以完全控制加载时机,甚至延迟到真正需要时
- 从内存或网络加载kernel
- 场景:GPU代码不是来自磁盘文件
- 例子 :
- 从加密的数据流中解密后得到PTX
- 从网络下载cubin到内存
- 从数据库读取编译好的kernel
- 为什么更好 :
cuModuleLoadData()支持从内存指针加载
五、需要底层调试/诊断
- 详细的错误诊断
- 场景:开发CUDA框架或调试复杂问题
- 例子 :
- 诊断kernel加载失败的详细原因
- 检查PTX编译到cubin的具体错误
- 为什么更好:驱动API返回更细粒度的错误码和详细信息
- 运行时查询kernel属性
-
场景:需要获取kernel的静态信息
-
例子 :
cint maxThreads; cuFuncGetAttribute(&maxThreads, CU_FUNC_ATTRIBUTE_MAX_THREADS_PER_BLOCK, function); -
为什么更好:可以查询共享内存大小、寄存器数、参数大小等元数据
六、编写系统级或跨平台框架
- 实现CUDA运行时库的替代品
- 场景:编写自己的CUDA抽象层或语言绑定
- 例子 :
- PyTorch/TensorFlow的CUDA后端
- Julia的CUDA.jl
- Rust的rustacuda
- 为什么更好:驱动API是更底层的接口,不受运行时库特定行为限制
- 统一处理多种GPU计算后端
- 场景:框架同时支持CUDA、HIP、OpenCL等
- 例子 :
- 设计统一的kernel加载和执行接口
- 驱动API的模式更容易抽象(load→get→launch)
- 为什么更好 :运行时API的
<<<>>>语法难以统一抽象
重要提醒
- 90%以上的CUDA开发者永远不需要驱动API,运行时API已经足够
- 驱动API代码更复杂、更容易出错(需要手动管理更多资源)
- 性能没有区别,最终都调用相同的底层驱动
- 即使是上述场景,也可以考虑混合使用:主体用运行时API,特殊部分用驱动API
4. CUfunction:核函数句柄
CUfunction 是单个核函数的句柄,对应模块里的一个__global__函数。
简单来说,CUfunction 就是驱动 API 中对你编写的 __global__ 函数的直接句柄。它类似于运行时 API 中你直接调用的内核函数名(比如 myKernel<<<...>>>),但驱动 API 要求你显式地获取它,然后通过专门的启动函数来调用。
- 从
CUmodule中通过函数名获取 - 启动核函数时,传入的是这个句柄,而不是函数指针
四、Driver API 完整工作流与基础接口
Driver API的使用流程非常清晰,就是"初始化→创建设备上下文→加载代码→分配资源→执行→释放资源"的显式管理流程。下面我们按执行顺序,讲解最核心的基础API。
以下函数需要引用CUDA Driver API 头文件
cpp
#include <cuda.h>1. 驱动初始化
cpp
CUresult cuInit(unsigned int Flags);- 功能:初始化CUDA驱动,必须是第一个调用的Driver API
Flags:保留参数,必须传0- 注意:整个进程只需要初始化一次,重复调用无害
2. 获取GPU设备
cpp
// 获取设备数量
CUresult cuDeviceGetCount(int* count);
// 根据索引(序号)获取对应 GPU 的设备句柄(handle),后续操作(如创建上下文、加载模块等)需要用到这个句柄。
CUresult cuDeviceGet(CUdevice* device, int ordinal);- 功能:枚举系统中的GPU设备,获取设备句柄
count:输出参数,指向一个 int 类型的变量,函数返回后该变量会被设置为设备数量。device:输出参数,CUdevice 类型(实际是 int 的别名),用于返回设备句柄。ordinal:设备索引,从0开始
返回值:
- CUDA_SUCCESS:成功。
- CUDA_ERROR_INVALID_DEVICE:ordinal 超出有效范围。
示例:
cpp
#include <cuda.h>
#include <stdio.h>
int main() {
// 必须先初始化 CUDA Driver API
cuInit(0);
int deviceCount;
CUresult res = cuDeviceGetCount(&deviceCount);
if (res == CUDA_SUCCESS) {
printf("找到 %d 个 CUDA 设备\n", deviceCount);
for (int i = 0; i < deviceCount; i++) {
CUdevice dev;
cuDeviceGet(&dev, i);
char name[256];
cuDeviceGetName(name, sizeof(name), dev);
printf("设备 %d: %s\n", i, name);
}
}
return 0;
}
/*
ubuntu@ubuntu:~/MyProject/MyCuda$ nvcc -o deviceGetCount deviceGetCount.cpp -lcuda
ubuntu@ubuntu:~/MyProject/MyCuda$ ./deviceGetCount
找到 1 个 CUDA 设备
设备 0: NVIDIA GeForce RTX 4070 Ti SUPER
*/3. 创建与管理上下文
cpp
// 创建上下文并设为当前上下文
CUresult cuCtxCreate(CUcontext* pctx, unsigned int flags, CUdevice dev);
// 设置当前线程的上下文
CUresult cuCtxSetCurrent(CUcontext ctx);
// 获取当前线程的上下文
CUresult cuCtxGetCurrent(CUcontext* pctx);
// 销毁上下文
CUresult cuCtxDestroy(CUcontext ctx);cuCtxCreate
- 作用:为指定的 GPU 设备创建一个 CUDA 上下文,并自动将其设为当前线程的活跃上下文。
- 参数:
pctx:输出参数,返回创建的上下文句柄flags:输入参数,创建标志(通常为 0)dev:输入参数,目标 GPU 设备句柄(由 cuDeviceGet 获得)
- flags 可选值:
| 标志 | 含义 |
|---|---|
| CU_CTX_SCHED_AUTO | 自动调度模式(默认) |
| CU_CTX_SCHED_SPIN | 自旋等待,低延迟 |
| CU_CTX_SCHED_YIELD | 让出 CPU,降低功耗 |
| CU_CTX_SCHED_BLOCKING_SYNC | 阻塞同步 |
| CU_CTX_MAP_HOST | 映射主机内存 |
| CU_CTX_LMEM_RESIZE_TO_MAX | 最大局部内存 |
cuCtxSetCurrent
- 作用:将指定的上下文设置为当前线程的活跃上下文。
- 参数:
ctx:输入参数,要激活的上下文句柄
- 典型场景:
- 多 GPU 编程中切换设备
- 保存和恢复上下文状态
- 线程间协作(共享上下文)
cuCtxGetCurrent
- 作用:获取当前线程活跃的 CUDA 上下文句柄。
- 参数:
pctx:输出参数,返回当前上下文句柄
- 用途:
- 检查是否有活跃上下文
- 保存当前状态以便后续恢复
- 调试和错误处理
cuCtxDestroy
- 作用:销毁指定的上下文,释放所有相关资源。
- 参数:
- ctx:输入参数,要销毁的上下文句柄
- 重要注意事项:
- 如果销毁的是当前上下文,系统会自动将当前上下文设为 NULL
- 销毁后,该上下文关联的所有资源(内存、流、事件等)也会被释放
- 必须在程序结束前调用,避免资源泄漏
示例
cpp
#include <cuda.h>
#include <stdio.h>
int main() {
// 1. 初始化 Driver API
cuInit(0);
// 2. 获取设备
CUdevice device;
cuDeviceGet(&device, 0);
// 3. 打印设备信息
char name[256];
cuDeviceGetName(name, sizeof(name), device);
printf("使用设备: %s\n", name);
// 4. 创建上下文
CUcontext context;
CUresult res = cuCtxCreate(&context, 0, device);
if (res != CUDA_SUCCESS) {
printf("创建上下文失败\n");
return -1;
}
printf("上下文创建成功\n");
// 5. 验证当前上下文
CUcontext current;
cuCtxGetCurrent(¤t);
printf("当前上下文: %p\n", current);
// 6. 执行 GPU 操作(例如加载模块、启动内核)
// cuModuleLoad(...);
// cuLaunchKernel(...);
// 7. 同步等待完成
cuCtxSynchronize();
// 8. 清理上下文
cuCtxDestroy(context);
printf("上下文已销毁\n");
return 0;
}多上下文管理示例:
cpp
// 管理两个 GPU 上的上下文
CUdevice devices[2];
CUcontext contexts[2];
// 获取两个设备
cuDeviceGet(&devices[0], 0);
cuDeviceGet(&devices[1], 1);
// 为每个设备创建上下文
for (int i = 0; i < 2; i++) {
cuCtxCreate(&contexts[i], 0, devices[i]);
}
// 在 GPU 0 上执行操作
cuCtxSetCurrent(contexts[0]);
// ... GPU 0 操作 ...
// 切换到 GPU 1
cuCtxSetCurrent(contexts[1]);
// ... GPU 1 操作 ...
// 清理
for (int i = 0; i < 2; i++) {
cuCtxDestroy(contexts[i]);
}4. 加载模块与获取核函数
cpp
// 从文件加载模块(支持PTX、Cubin)
CUresult cuModuleLoad(CUmodule* module, const char* fname);
// 从内存中的PTX/Cubin数据加载模块
CUresult cuModuleLoadData(CUmodule* module, const void* image);
// 从模块中获取核函数句柄
CUresult cuModuleGetFunction(CUfunction* hfunc, CUmodule hmod, const char* name);
// 卸载模块
CUresult cuModuleUnload(CUmodule hmod);这是Driver API最核心的能力之一:运行时动态加载设备代码,不需要把核函数编译进主机程序
cuModuleLoad
-
作用:从磁盘文件加载 CUDA 模块(包含 GPU 代码)。
-
参数:
- module:输出参数,返回模块句柄
- fname:输入参数,模块文件路径(支持 .ptx、.cubin、.fatbin 格式)
-
返回值:
- CUDA_SUCCESS:成功
- CUDA_ERROR_FILE_NOT_FOUND:文件不存在
- CUDA_ERROR_INVALID_PTX:PTX 文件无效
cuModuleLoadData
- 作用:从内存中的数据加载 CUDA 模块(避免磁盘 I/O,更灵活)。
- 参数:
- module:输出参数,返回模块句柄
- image:输入参数,指向内存中 PTX/Cubin 数据的指针
- 优点:
- 可以将 PTX 嵌入可执行文件
- 运行时动态生成代码
- 避免文件系统依赖
cuModuleGetFunction
- 作用:从已加载的模块中获取指定名称的核函数句柄,后续用于启动内核。
- 参数:
- hfunc:输出参数,返回核函数句柄
- hmod:输入参数,模块句柄(由 cuModuleLoad 或 cuModuleLoadData 获得)
- name:输入参数,核函数名称(与设备代码中定义的名称匹配)
cuModuleUnload
- 作用:卸载模块,释放 GPU 上的相关资源(代码、常量内存、纹理引用等)。
- 参数:
- hmod:输入参数,要卸载的模块句柄
- 重要:
- 卸载后,从该模块获取的 CUfunction 句柄将失效
- 程序结束前应卸载所有模块,避免资源泄漏
示例:
cpp
#include <cuda.h>
#include <stdio.h>
int main() {
// 1. 初始化
cuInit(0);
// 2. 获取设备
CUdevice device;
cuDeviceGet(&device, 0);
// 3. 创建上下文
CUcontext context;
cuCtxCreate(&context, 0, device);
// 4. 加载模块
CUmodule module;
CUresult res = cuModuleLoad(&module, "mykernel.ptx");
if (res != CUDA_SUCCESS) {
printf("模块加载失败\n");
return -1;
}
// 5. 获取核函数
CUfunction kernel;
res = cuModuleGetFunction(&kernel, module, "VecAdd");
if (res != CUDA_SUCCESS) {
printf("获取核函数失败\n");
return -1;
}
// 6. 准备参数并启动内核(这里省略参数设置)
// cuLaunchKernel(kernel, gridX, gridY, gridZ, blockX, blockY, blockZ,
// sharedMemBytes, stream, kernelParams, extraParams);
// 7. 同步
cuCtxSynchronize();
// 8. 清理
cuModuleUnload(module);
cuCtxDestroy(context);
return 0;
}5. 设备内存管理
和Runtime API一一对应,只是前缀不同:
cpp
// 分配设备内存
CUresult cuMemAlloc(CUdeviceptr* dptr, size_t bytesize);
// 释放设备内存
CUresult cuMemFree(CUdeviceptr dptr);
// 内存拷贝(同步)
CUresult cuMemcpyHtoD(CUdeviceptr dstDevice, const void* srcHost, size_t ByteCount);
CUresult cuMemcpyDtoH(void* dstHost, CUdeviceptr srcDevice, size_t ByteCount);
CUresult cuMemcpyDtoD(CUdeviceptr dstDevice, CUdeviceptr srcDevice, size_t ByteCount);
// 内存初始化
CUresult cuMemsetD32(CUdeviceptr dstDevice, unsigned int ui, size_t N);- 注意:设备内存指针类型是
CUdeviceptr,本质是无符号整数,而不是void*
cuMemAlloc
-
作用:在 GPU 设备上分配线性内存。
-
参数:
- dptr:输出参数,返回分配的设备内存指针(类型 CUdeviceptr,本质是 unsigned long long)
- bytesize:输入参数,要分配的字节数
-
注意事项:
- 分配的内存默认是未初始化的
- 内存大小最好为 256 字节的倍数(性能优化)
- 分配失败时 dptr 指向无效值
cuMemFree
-
作用:释放之前通过 cuMemAlloc 分配的设备内存。
-
参数:
- dptr:输入参数,要释放的设备内存指针
-
重要:
- 释放后指针失效,再次使用会导致未定义行为
- 必须在上下文销毁前释放所有分配的内存
- 重复释放同一个指针会导致错误
cuMemcpyHtoD
- 作用:将数据从主机内存拷贝到设备内存(同步操作)。
- 参数:
- dstDevice:目标设备内存地址
- srcHost:源主机内存地址
- ByteCount:拷贝字节数
cuMemcpyDtoH
- 作用:将数据从设备内存拷贝到主机内存(同步操作)。
- 参数:
- dstHost:目标主机内存地址
- srcDevice:源设备内存地址
- ByteCount:拷贝字节数
cuMemcpyDtoD
- 作用:在设备内存之间拷贝数据(同步操作)。
- 参数:
- dstDevice:目标设备内存地址
- srcDevice:源设备内存地址
- ByteCount:拷贝字节数
cuMemsetD32
- 作用:将设备内存初始化为指定的 32 位无符号整数值。
- 参数:
- dstDevice:目标设备内存地址
- ui:要设置的 32 位值(填充模式)
- N:要设置的 32 位字的数量(不是字节数!)
- 重要说明:
- 总共会设置 N * 4 字节的内存
- 内存地址必须按 32 位对齐
- 相关函数:cuMemsetD16(16位)、cuMemsetD8(8位)、cuMemsetD2D32(2D)
示例
cpp
#include <cuda.h>
#include <stdio.h>
#include <stdlib.h>
int main() {
// 初始化
cuInit(0);
// 创建设备上下文
CUdevice device;
CUcontext context;
cuDeviceGet(&device, 0);
cuCtxCreate(&context, 0, device);
// 1. 分配设备内存
const int N = 1000;
size_t size = N * sizeof(float);
CUdeviceptr d_a, d_b, d_c;
cuMemAlloc(&d_a, size);
cuMemAlloc(&d_b, size);
cuMemAlloc(&d_c, size);
// 2. 初始化主机数据
float* h_a = (float*)malloc(size);
float* h_b = (float*)malloc(size);
float* h_c = (float*)malloc(size);
for (int i = 0; i < N; i++) {
h_a[i] = (float)i;
h_b[i] = (float)(i * 2);
}
// 3. 拷贝数据到设备
cuMemcpyHtoD(d_a, h_a, size);
cuMemcpyHtoD(d_b, h_b, size);
// 4. 初始化设备内存(清零)
cuMemsetD32(d_c, 0, size / 4);
// 5. 这里可以启动内核进行向量加法
// cuLaunchKernel(...);
// 6. 模拟:手动在设备间拷贝(假设 d_a + d_b -> d_c)
// 实际应该用内核,这里仅演示设备间拷贝
cuMemcpyDtoD(d_c, d_a, size / 2); // 示例:拷贝前一半
// 7. 拷贝结果回主机
cuMemcpyDtoH(h_c, d_c, size);
// 8. 验证部分结果
for (int i = 0; i < 10; i++) {
printf("h_c[%d] = %f\n", i, h_c[i]);
}
// 9. 清理资源
cuMemFree(d_a);
cuMemFree(d_b);
cuMemFree(d_c);
free(h_a);
free(h_b);
free(h_c);
cuCtxDestroy(context);
return 0;
}6. 启动核函数
这是Driver API最繁琐也最灵活的部分,替代了Runtime的<<<>>>语法:
cpp
CUresult cuLaunchKernel(
CUfunction f, // 核函数句柄
unsigned int gridDimX, // 网格X维度
unsigned int gridDimY, // 网格Y维度
unsigned int gridDimZ, // 网格Z维度
unsigned int blockDimX, // 线程块X维度
unsigned int blockDimY, // 线程块Y维度
unsigned int blockDimZ, // 线程块Z维度
unsigned int sharedMemBytes, // 动态共享内存大小
CUstream hStream, // 执行流
void** kernelParams, // 核函数参数数组
void** extra // 额外参数,一般传NULL
);kernelParams是一个指针数组,每个元素指向一个参数的地址,顺序和核函数参数顺序一致- 没有语法糖,所有维度都要手动指定,灵活性拉满
cuLaunchKernel 是 CUDA Driver API 中启动核函数 的核心函数,相当于 Runtime API 中的 <<<grid, block, sharedMem, stream>>> 语法。下面详细解释每个参数和使用方法:
函数原型
c
CUresult cuLaunchKernel(
CUfunction f, // 核函数句柄
unsigned int gridDimX, // 网格X维度
unsigned int gridDimY, // 网格Y维度
unsigned int gridDimZ, // 网格Z维度
unsigned int blockDimX, // 线程块X维度
unsigned int blockDimY, // 线程块Y维度
unsigned int blockDimZ, // 线程块Z维度
unsigned int sharedMemBytes, // 动态共享内存大小
CUstream hStream, // 执行流
void** kernelParams, // 核函数参数数组
void** extra // 额外参数(通常为 NULL)
);参数详解
CUfunction f - 核函数句柄
通过 cuModuleGetFunction 从模块中获取的核函数句柄。
c
CUfunction kernel;
cuModuleGetFunction(&kernel, module, "MyKernel");网格维度参数
c
unsigned int gridDimX, gridDimY, gridDimZ定义整个网格(Grid)的尺寸,即启动的线程块数量:
- gridDimX:X 维度的线程块数量
- gridDimY:Y 维度的线程块数量
- gridDimZ:Z 维度的线程块数量
总线程块数 = gridDimX × gridDimY × gridDimZ
线程块维度参数
c
unsigned int blockDimX, blockDimY, blockDimZ定义每个线程块(Block)的尺寸,即每个块内的线程数量:
- blockDimX:X 维度的线程数
- blockDimY:Y 维度的线程数
- blockDimZ:Z 维度的线程数
每块线程数 = blockDimX × blockDimY × blockDimZ
总线程数 = 总线程块数 × 每块线程数
unsigned int sharedMemBytes - 动态共享内存
为每个线程块分配的动态共享内存大小(字节数):
- 仅分配动态 声明的共享内存(
extern __shared__) - 静态 声明的共享内存(
__shared__)不占用此参数 - 通常为 0,如果不需要动态共享内存
c
// 核函数中声明动态共享内存
extern __shared__ float dynamic_data[];CUstream hStream - 执行流
- 传入
0或NULL:使用默认流(阻塞流) - 传入有效的流句柄:使用非阻塞流,可实现异步执行
c
CUstream stream;
cuStreamCreate(&stream, 0);
cuLaunchKernel(..., stream, ...); // 使用自定义流void** kernelParams - 核函数参数
指向参数指针数组的指针,每个元素是核函数参数的指针。
void** extra - 额外参数
- 通常传
NULL - 用于传递额外的参数(如 CUDA 的特殊属性)
7. 同步与错误处理
cpp
// 等待上下文所有操作完成
CUresult cuCtxSynchronize(void);
// 获取错误码的字符串描述
const char* cuGetErrorString(CUresult error);- Driver API的错误码类型是
CUresult,成功为CUDA_SUCCESS - 和Runtime一样,异步操作的错误需要在同步后才能获取
五、完整实战:Driver API 实现向量加法
下面我们用一个完整的向量加法示例,直观感受Driver API的开发流程。我们将核函数单独编译成PTX,然后在主机代码中动态加载执行。
步骤1:编写核函数文件
新建kernel.cu,只写核函数:
cpp
extern "C" // 添加这个,禁用 C++ name mangling
__global__ void vectorAdd(const float* a, const float* b, float* c, int n) {
int i = blockIdx.x * blockDim.x + threadIdx.x;
if (i < n) {
c[i] = a[i] + b[i];
}
}编译生成PTX文件:
bash
nvcc -ptx kernel.cu -o kernel.ptx步骤2:编写Driver API主机代码
新建main.cpp,纯C++代码,不需要nvcc编译,用g++/msvc即可:
cpp
#include <iostream>
#include <vector>
#include <cuda.h> // Driver API 头文件
#define CHECK_CUDA(err) \
if (err != CUDA_SUCCESS) { \
const char* msg; \
cuGetErrorString(err, &msg); \
std::cerr << "CUDA Error: " << msg << " at line " << __LINE__ << std::endl; \
exit(1); \
}
int main() {
const int n = 1 << 20; // 1M元素
const size_t size = n * sizeof(float);
// ========== 1. 初始化驱动 ==========
CHECK_CUDA(cuInit(0));
// ========== 2. 获取GPU设备 ==========
int deviceCount = 0;
CHECK_CUDA(cuDeviceGetCount(&deviceCount));
if (deviceCount == 0) {
std::cerr << "No CUDA device found!" << std::endl;
return 1;
}
CUdevice device;
CHECK_CUDA(cuDeviceGet(&device, 0)); // 使用0号设备
// ========== 3. 创建上下文 ==========
CUcontext ctx;
CHECK_CUDA(cuCtxCreate(&ctx, 0, device));
// ========== 4. 加载PTX模块,获取核函数 ==========
CUmodule module;
CHECK_CUDA(cuModuleLoad(&module, "kernel.ptx"));
CUfunction kernel;
CHECK_CUDA(cuModuleGetFunction(&kernel, module, "vectorAdd"));
// ========== 5. 分配并初始化主机内存 ==========
std::vector<float> h_a(n);
std::vector<float> h_b(n);
std::vector<float> h_c(n);
for (int i = 0; i < n; i++) {
h_a[i] = static_cast<float>(i);
h_b[i] = static_cast<float>(i * 2);
}
// ========== 6. 分配设备内存 ==========
CUdeviceptr d_a, d_b, d_c;
CHECK_CUDA(cuMemAlloc(&d_a, size));
CHECK_CUDA(cuMemAlloc(&d_b, size));
CHECK_CUDA(cuMemAlloc(&d_c, size));
// ========== 7. 数据拷贝:主机→设备 ==========
CHECK_CUDA(cuMemcpyHtoD(d_a, h_a.data(), size));
CHECK_CUDA(cuMemcpyHtoD(d_b, h_b.data(), size));
// ========== 8. 启动核函数 ==========
int blockSize = 256;
int gridSize = (n + blockSize - 1) / blockSize;
// 准备核函数参数:注意每个参数都要传地址
void* args[] = { &d_a, &d_b, &d_c, &n };
CHECK_CUDA(cuLaunchKernel(
kernel,
gridSize, 1, 1, // grid 维度
blockSize, 1, 1, // block 维度
0, nullptr, // 共享内存、流
args, nullptr // 参数列表、额外参数
));
// ========== 9. 同步等待执行完成 ==========
CHECK_CUDA(cuCtxSynchronize());
// ========== 10. 数据拷贝:设备→主机 ==========
CHECK_CUDA(cuMemcpyDtoH(h_c.data(), d_c, size));
// ========== 11. 验证结果 ==========
bool success = true;
for (int i = 0; i < n; i++) {
if (h_c[i] != h_a[i] + h_b[i]) {
std::cerr << "Verification failed at index " << i << std::endl;
success = false;
break;
}
}
if (success) {
std::cout << "Vector addition succeeded with Driver API!" << std::endl;
}
// ========== 12. 释放所有资源 ==========
CHECK_CUDA(cuMemFree(d_a));
CHECK_CUDA(cuMemFree(d_b));
CHECK_CUDA(cuMemFree(d_c));
CHECK_CUDA(cuModuleUnload(module));
CHECK_CUDA(cuCtxDestroy(ctx));
return 0;
}编译运行
主机代码可以直接用g++编译,只需要链接CUDA驱动库:
bash
nvcc main.cpp -o driver_demo -I/usr/local/cuda/include -lcuda
./driver_demo六、Driver API 的独特能力:什么时候必须用它?
绝大多数常规CUDA开发,Runtime API都能胜任。但在以下场景中,Driver API是唯一选择:
1. 动态加载与JIT编译
Runtime API的核函数必须编译时静态确定,而Driver API可以在运行时:
- 加载预编译的Cubin/PTX文件
- 动态生成PTX代码,实时编译执行
- 根据运行时的GPU架构,选择最优的二进制版本
这是深度学习框架、推理引擎(TensorRT、ONNX Runtime)的核心能力------它们不需要针对每个架构编译程序,运行时加载对应架构的算子即可。
2. 多上下文资源隔离
当你需要在同一个进程中运行多个独立的GPU任务,希望它们的内存、资源完全隔离时,就需要用Driver API创建多个独立的CUcontext。每个上下文有自己的地址空间,互不干扰,类似CPU上的多进程。
3. 跨语言/跨环境调用
Runtime API强依赖nvcc编译器和C/C++环境,而Driver API是纯C接口,可以被任何语言调用(Python、Java、Go等)。Python的cuda-python、Numba的CUDA后端,底层都是调用Driver API。
4. 底层硬件控制
很多底层特性只有Driver API能访问,比如:
- 精细的上下文调度控制
- 模块级的JIT编译选项配置
- 底层内存物理属性查询
- CUDA Graph的底层操作
- 与OpenGL、DirectX等图形API的深度互操作
5. 极致轻量化部署
Runtime API会引入额外的运行时库依赖,而Driver API只依赖系统自带的GPU驱动。对于轻量化部署场景,用Driver API可以减小程序体积,减少依赖。
七、常见误区与选型建议
误区1:Driver API 比 Runtime API 性能高很多
错误。 Runtime API 只是Driver API的一层极薄封装,几乎没有额外开销。两者的核函数执行性能完全一致,差异只在主机端的调用开销,而这个开销相对于GPU执行时间可以忽略不计。
不要为了"追求性能"强行改用Driver API,只会增加开发成本,不会带来实际收益。
误区2:Runtime API 和 Driver API 不能混用
可以混用,但不推荐。 Runtime API的默认上下文本质上就是一个Driver API的CUcontext,你可以在Runtime代码中调用Driver API,通过cuCtxGetCurrent获取当前上下文。但混用会增加代码复杂度,容易出现资源管理混乱,除非必要否则不建议。
选型建议
| 场景 | 推荐选择 | 理由 |
|---|---|---|
| 常规算法开发、应用开发 | Runtime API | 开发效率高,生态完善,性能足够 |
| 深度学习框架、推理引擎开发 | Driver API | 需要动态加载算子、资源隔离 |
| 跨语言CUDA绑定 | Driver API | 纯C接口,易于封装 |
| 动态代码生成、JIT编译 | Driver API | 运行时加载编译设备代码 |
| 底层硬件特性定制 | Driver API | 访问驱动层全部能力 |
八、总结
Driver API 是CUDA软件栈的基石,Runtime API 是建立在它之上的易用封装。两者不是优劣之分,而是定位不同:一个面向灵活与底层控制,一个面向易用与快速开发。
对于大多数开发者,熟练掌握Runtime API就足以应对绝大多数场景;但了解Driver API,能帮我们拨开封装的迷雾,真正理解CUDA程序的运行本质,在遇到复杂场景时能有更多的技术选择。
从学习路径来说,建议先吃透Runtime API,建立完整的CUDA编程体系,再按需深入Driver API的底层能力。