AI生成的本质:以"理解"为核心的底层逻辑
AI生成文字、图片、视频的核心前提,本质是模型对内容的"理解"------生成文字需先读懂文字语义,生成图片需先看懂图像特征,文生图则需同时吃透提示词与图像逻辑,视频生成同样离不开对视频内容的深度解析。
但"理解"本身难以精准定义,正如人工智能的智能边界模糊,我们无法断言其具备人类式的推理能力。模型层面的"理解",更多停留在数学向量的维度:用向量重构文字、图片、视频的信息,以向量的相似度、关联度匹配作为判断理解的核心依据。当模型能基于提示词与学习内容输出对应成果时,我们便默认其具备了"理解"能力,这种理解虽与人类认知不同,却支撑起AI生成的全链路运转。
视频生成的突破:从规律捕捉到世界模拟的探索
在视觉生成领域,模型的可控性始终是关键挑战,而视频生成模型更被赋予"世界模拟器"的潜力。这种模拟能力并非源于模型参透物理原理,而是依托海量视频数据的训练------当模型接收大量附带文字描述的视频素材,便在数据中捕捉现实规律:比如人物的头与躯干必然相连,而非割裂分布,这并非模型理解物理规则,只是从数据中提炼出符合现实的关联模式。
随着文字条件扩散模型在视频、图片领域的应用,结合Transformer架构的空间处理能力,生成式模型在视频领域的表现持续突破。Diffusion Models、Autoregressive Transformers等模型已在细分场景崭露头角,但大多局限于窄类别或短时视频,而Sora的核心目标,正是打破这些限制,实现时长、分辨率、宽高比全维度自由的通用视频生成,为视频生成技术打开全新想象空间。
大家可以结合我之前写的文章 揭秘Transformer架构设计 1、揭秘Transformer架构设计 2(补全版) 进一步了解R=Transformer架构。
技术核心:Patch与Token,视觉信息的结构化革命
这一突破的关键在于对视觉信息的结构化处理,核心便是"patch"技术------将视觉内容拆解为可量化的块,这一思路与LLM的token机制异曲同工:LLM凭借文本token实现高效拓展,Sora则将视觉patch 作为核心载体,既延续了ViT模型中patch 在视觉领域的有效性,又解决了传统扩散模型在文生图时未采用patch的局限,让视觉信息能以高可扩展的向量形式被模型处理。
面对视频生成,模型需先理解视频的时间与空间关联,而ViViT(视频领域的Vision Transformer) 为此提供了技术支撑。2021年诞生的ViViT,在2020年ViT 处理单张图片的基础上,针对视频的时空特性设计了两种patch切割方式:
- 第一种是忽略时间序列,仅切割单帧图片的空间patch,适用于静态场景;
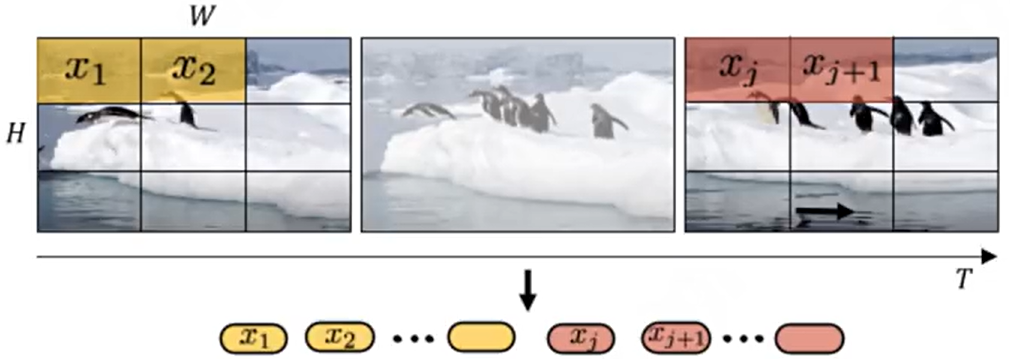
- 第二种是将多帧图片合并为立方体patch,兼顾空间位置与时间关联,即便面对高速运动的画面,也能通过立方体patch捕捉物体的运动轨。
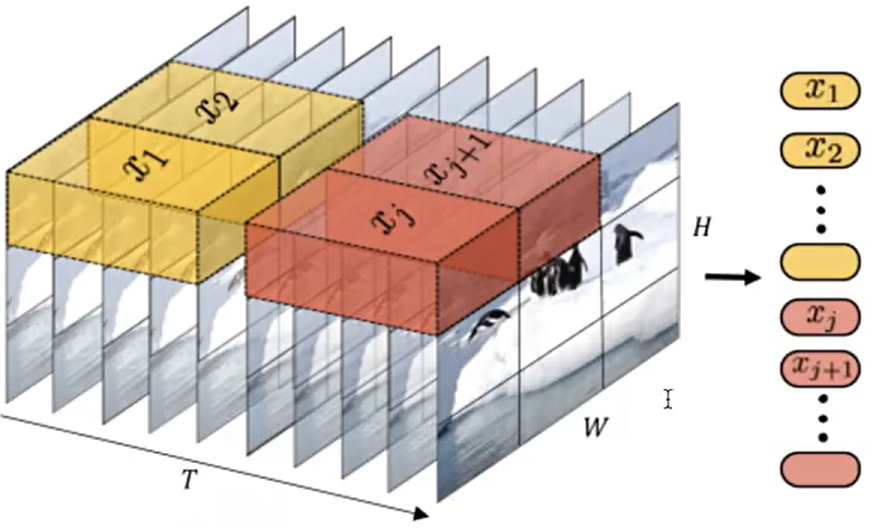
第二种也正是Sora选择此类切割方式的核心原因,为视频的精准理解与生成筑牢基础。
ViT的架构图:
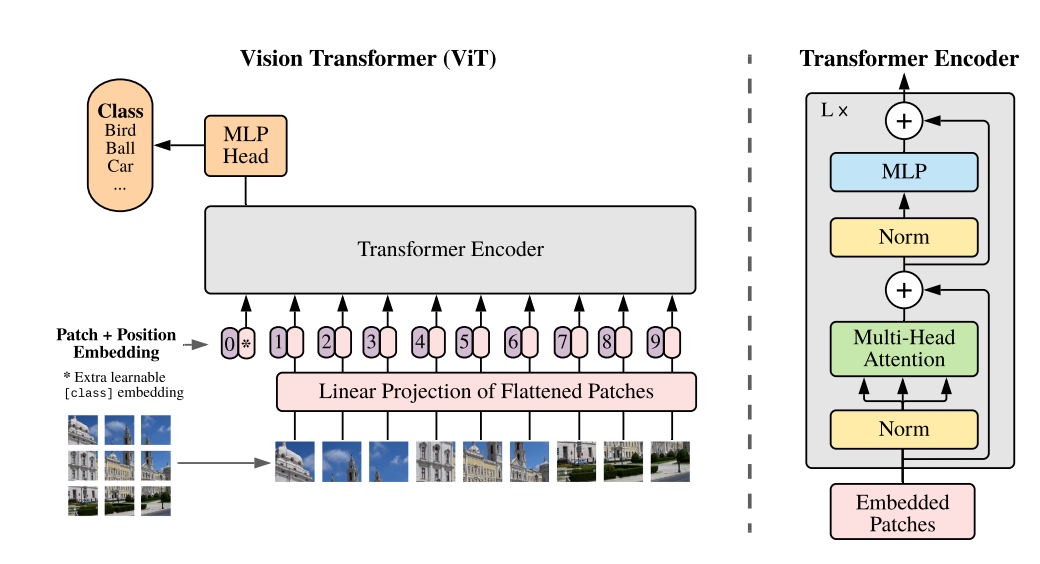
关于Patch概念、ViT模型详解,可以去看下我之前写的文章 浅谈多模态领域的Transformer。
生成逻辑:从向量压缩到像素还原的完整闭环
模型理解视频的核心逻辑,是将视频转化为patch向量,通过向量间的相似度计算、自注意力机制,识别视频中的物体、运动轨迹,再结合提示词完成训练与生成。这一过程本质是对视频的压缩:将冗余的像素信息转化为低维向量,同时保留时间与空间的关联性,再通过解码器将向量还原为像素空间的视频内容,形成从输入到输出的完整闭环。
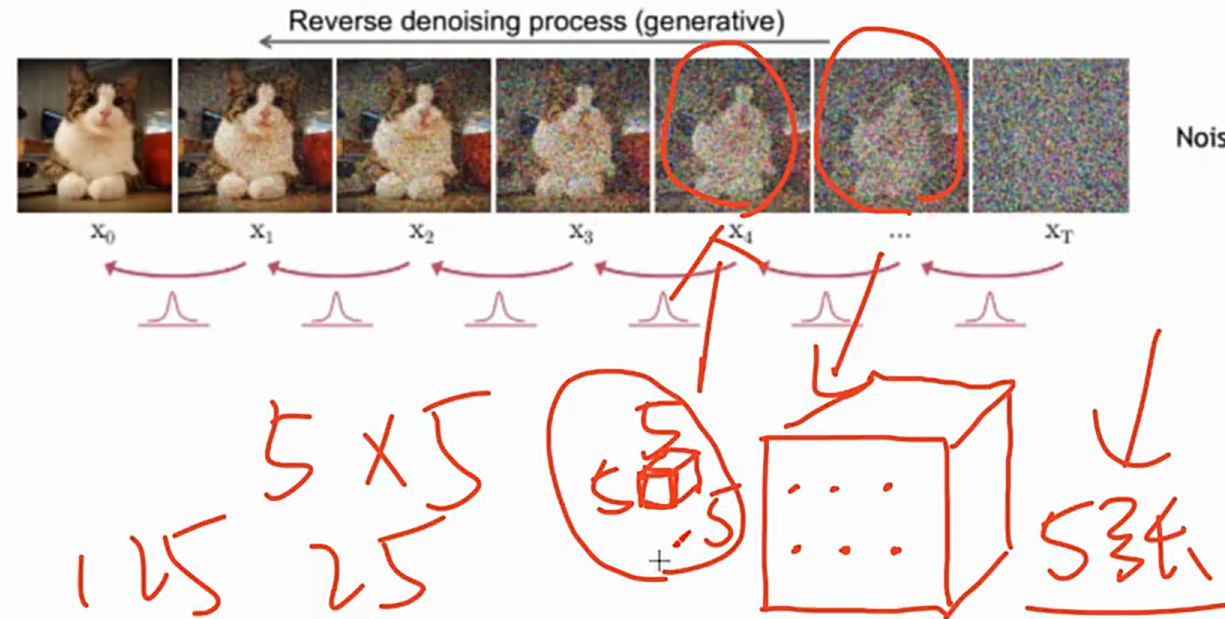
而Sora作为扩散型Transformer,其生成逻辑更具创新性:以随机雪花图(对应视频帧)为初始状态,根据文字提示词,通过扩散过程逐步消除噪点,让每一帧画面变清晰,同时保证多帧画面的连续性,而非独立生成每一帧。这种处理方式,既依托Transformer"模型越大效果越好"的特性,又破解了传统生成方式中画面割裂的难题,让长视频的连贯生成成为可能。

技术迭代:从3D-UNet到Transformer,破解视频生成瓶颈
回溯视频生成技术的发展,2022年的视频扩散模型(Video Diffusion Models)是重要起点,它仅将文生图的2D-UNet升级为3D-UNet,把2D卷积核拓展为3D卷积核,但受限于卷积核的局部处理特性,仅能捕捉小范围的时空信息,难以应对长视频的复杂关联,因此只能生成短时视频,无法满足更复杂的生成需求。
Video Diffusion Models架构图:
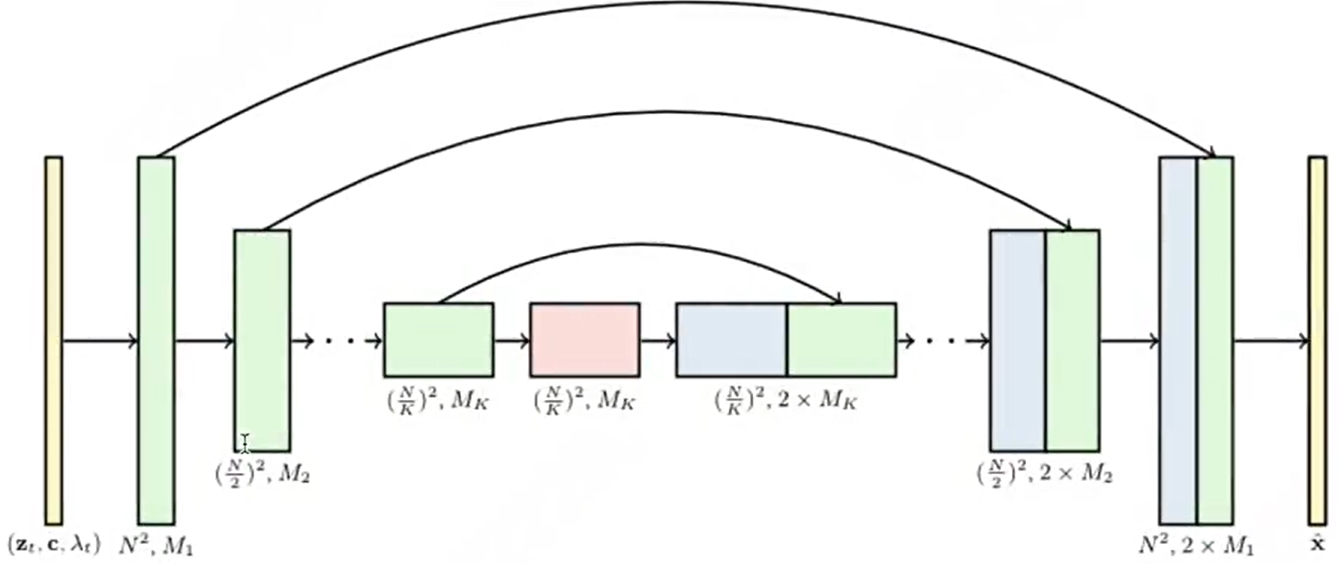
2D-UNet升级为3D-UNet:
而Transformer架构在视频领域的应用,通过四种核心方法破解了这一难题:
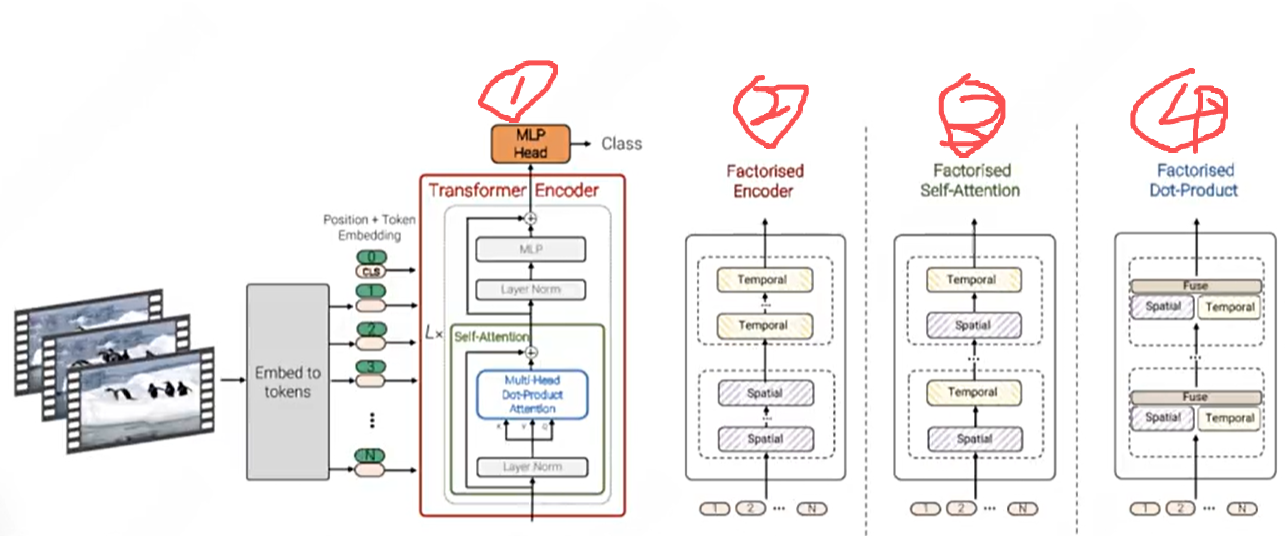
一是空间与时间联合注意力机制,计算量最大但效果最佳,与Transformer处理文字的逻辑一致,实现patch向量的两两关联计算;
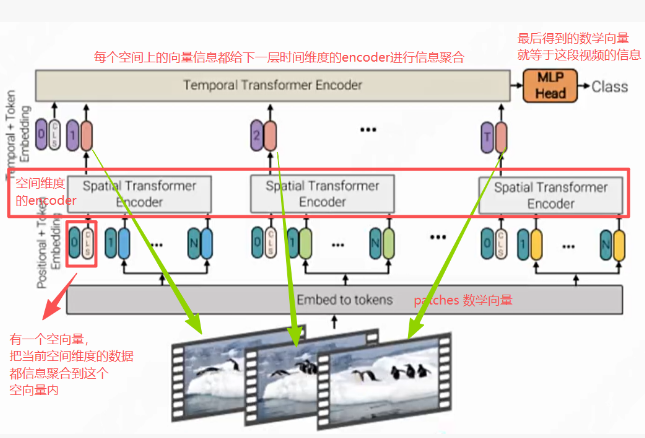
二是分解编码器(Factorised encoder),将编码器拆分为空间与时间两个模块,先聚合空间信息再处理时间关联,平衡计算量与效果;
三是分解自注意力机制(Factorised self-attention),在单层编码器中先后处理空间与时间信息,进一步提升信息整合的全面性;
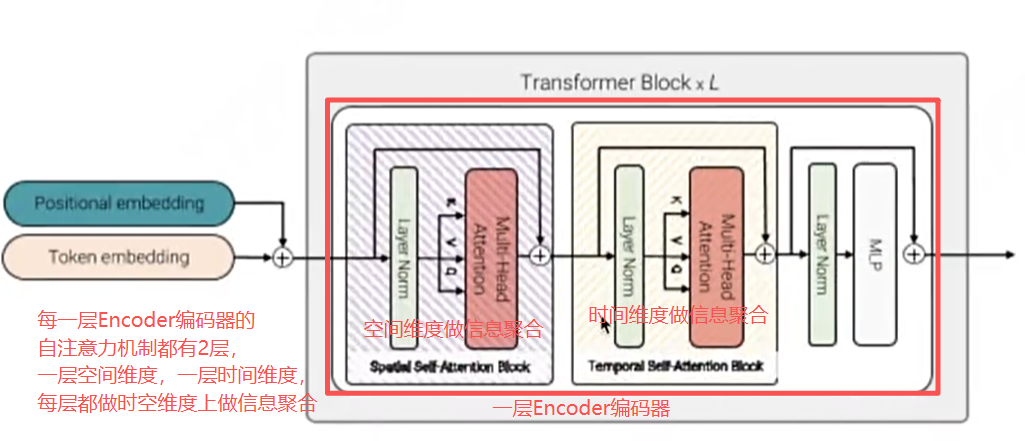
四是分解点积注意力机制,虽极致压缩计算量,但效果难以保障。事实证明,扩散Transformer在视频生成中,计算量与效果呈正相关,这也为技术优化指明了方向,推动视频生成技术持续进阶。举例:输入1000个向量,同时给2个自注意力机制,一个自注意力机制只做空间上的信息处理,一个自注意力机制只做时间上的信息处理,2个自注意力机制输出的向量直接进行首位拼接成一个长向量,给linear层做信息融合,这个计算力是最小的,但是他的效果难以保证。
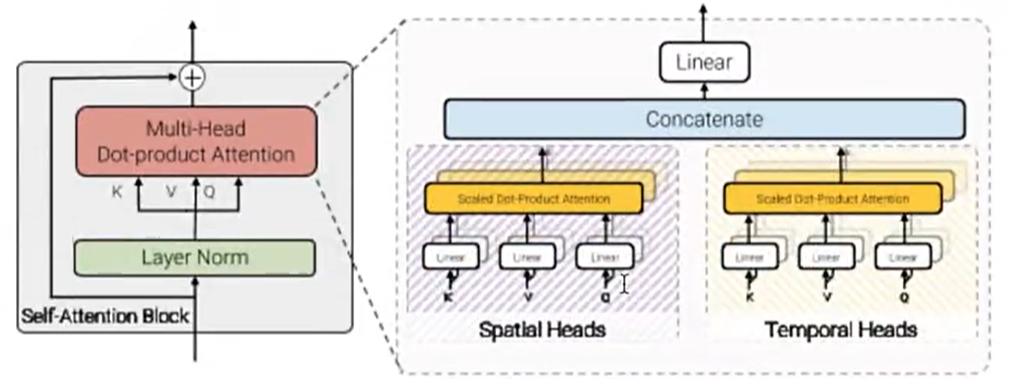
我们能发现diffusion transformer在扩散模型内使用transformer,做视频模型的效果越来越好,计算量越大,效果越好.

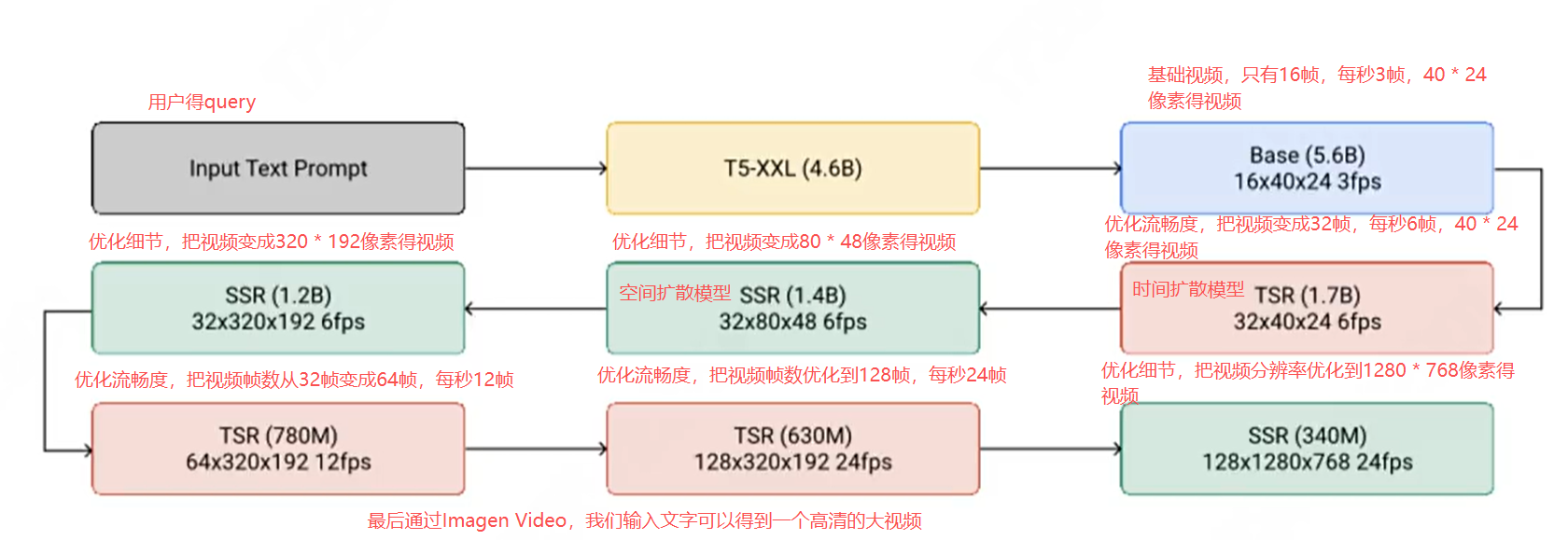
标杆实践:Imagen Video,级联式生成的体系化突破
2022年10月推出的Imagen Video,则构建了级联式的生成体系,以7个视频扩散模型(总计116亿参数)形成完整流水线:基础视频扩散模型先搭建视频的骨架与轮廓,生成低分辨率、低帧率的核心内容;后续的3个空间超分辨率(SSR)模型负责提升画面细节,3个时间超分辨率(TSR)模型优化帧间流畅度,各模块各司其职,既保证了生成效率,又能输出高质量、高帧率且连贯的视频。
这种分工明确的级联模式,让Imagen Video展现出强大的文本控制与风格表达能力,不仅实现了从低分辨率到高分辨率的平稳过渡,更在生成质量与效率之间找到平衡,成为视频生成领域的标志性成果,为后续技术迭代提供了极具价值的实践参考。