
一、Prompt 只是入口,上下文才是现场
很多人做 AI 应用,第一反应是改 Prompt。
但线上 Agent 出错,往往不是 Prompt 写得不够玄,而是模型看到的上下文不对。
|-----------------------------------------------------------------------------|
| 一句话讲透 Context Engineering,就是把正确的信息、正确的工具、正确的记忆、正确的规则,在正确的时间,放进模型的上下文窗口。 |
Prompt Engineering 解决"怎么说"。
Context Engineering 解决"给模型看什么"。
模型不会看见你的数据库。不会看见你的用户画像。不会自动知道权限。不会自动理解刚刚哪个工具失败了。
这些东西,都要被工程系统组织成上下文。
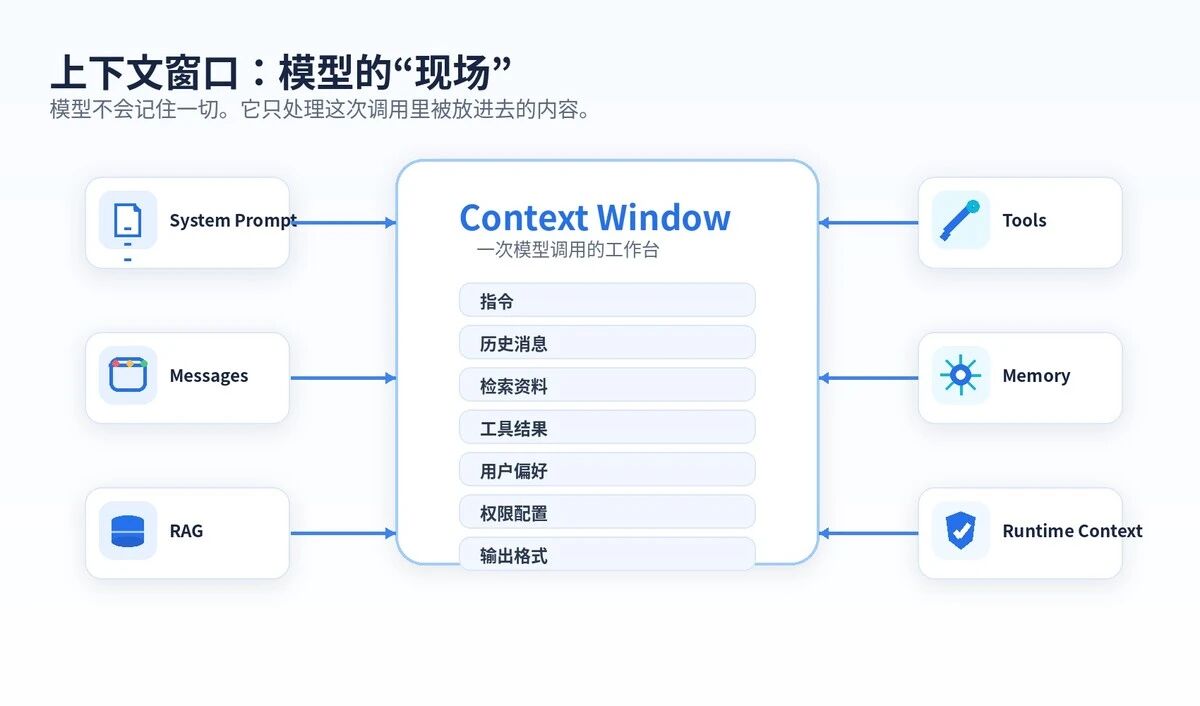
二、为什么它比 Prompt 更重要?
Prompt 再好,也只是上下文的一部分。
真实应用里,模型看到的是一整包东西:
系统指令
用户问题
历史消息
RAG 检索结果
工具返回结果
短期状态
长期记忆
权限配置
输出格式
这包东西只要乱,模型就会乱。
|----------------------------------------|
| 关键判断 如果回答错了,先不要怪模型。先问:这次模型到底看到了什么? |

三、上下文工程管的不是一件事,而是三类上下文
LangChain 官方把 Agent 上下文分成三个层次。
第一层:Model Context。模型调用时临时看到的东西。
第二层:Tool Context。工具执行时可以读取和写入的东西。
第三层:Life-cycle Context。模型和工具之间发生的治理动作。
这三个层次,决定了 Agent 是不是能上线。
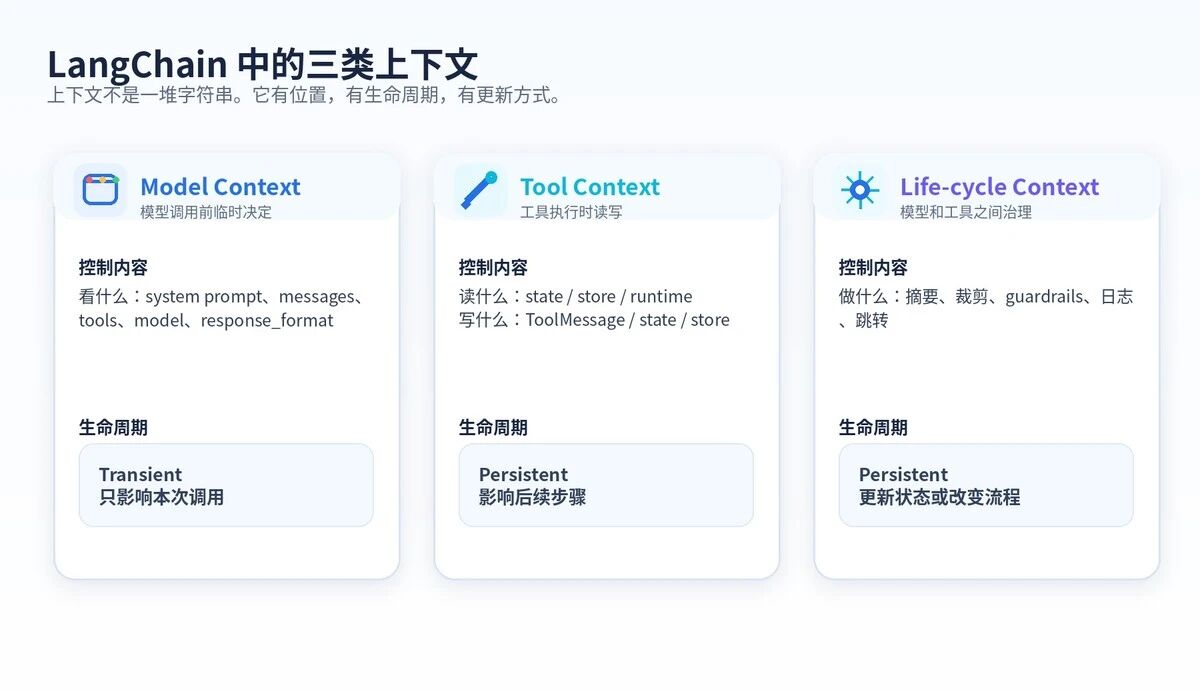
三类上下文:模型看到什么,工具能读写什么,生命周期如何治理。
四、上下文从哪里来?三个数据源
上下文不是凭空出现的。
在 LangChain 里,常见来源是三个:
Runtime Context:本次运行配置,比如 user_id、role、env、api_key。
State:当前线程状态,比如 messages、认证状态、上传文件、工具结果。
Store:长期记忆,比如用户偏好、历史洞察、跨会话资料。
这三个来源组合起来,才是完整的上下文工程。
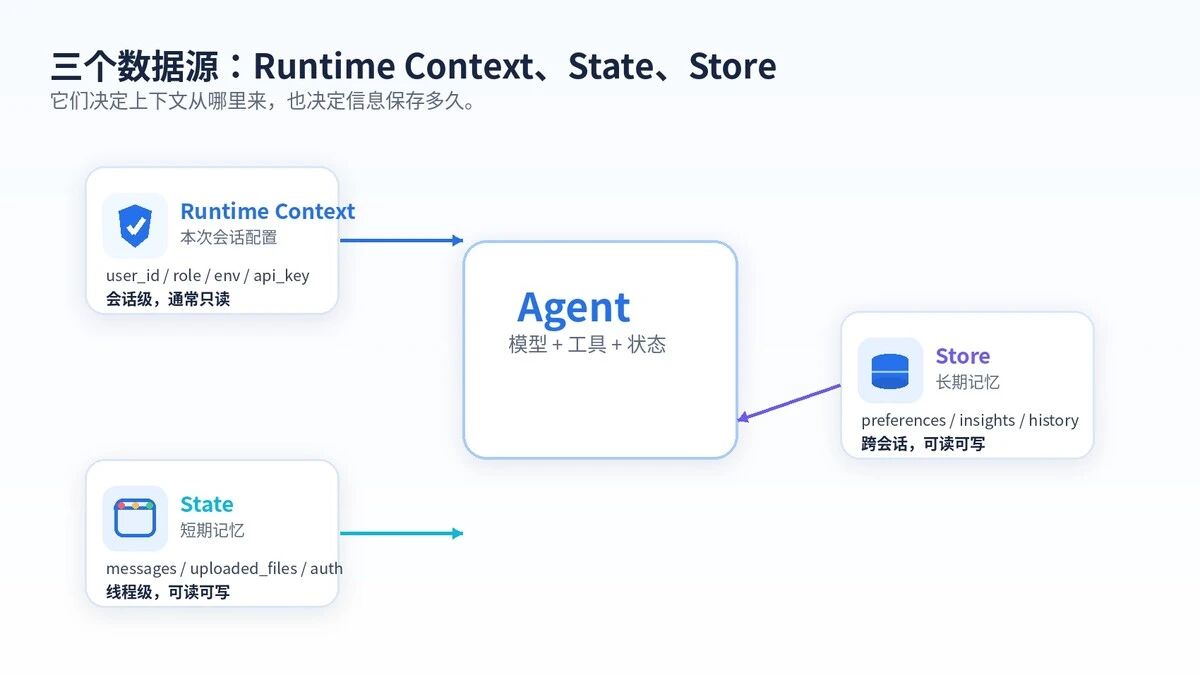
Runtime Context、State、Store 分别解决不同生命周期的数据问题。
五、上下文最终都会落到这条链路上
从源码看,上下文工程不是一个抽象概念。
它最后会落到 AgentState、ModelRequest、Middleware、ToolRuntime、Store 这些对象上。
把源码链路压缩后,就是下面这条线。
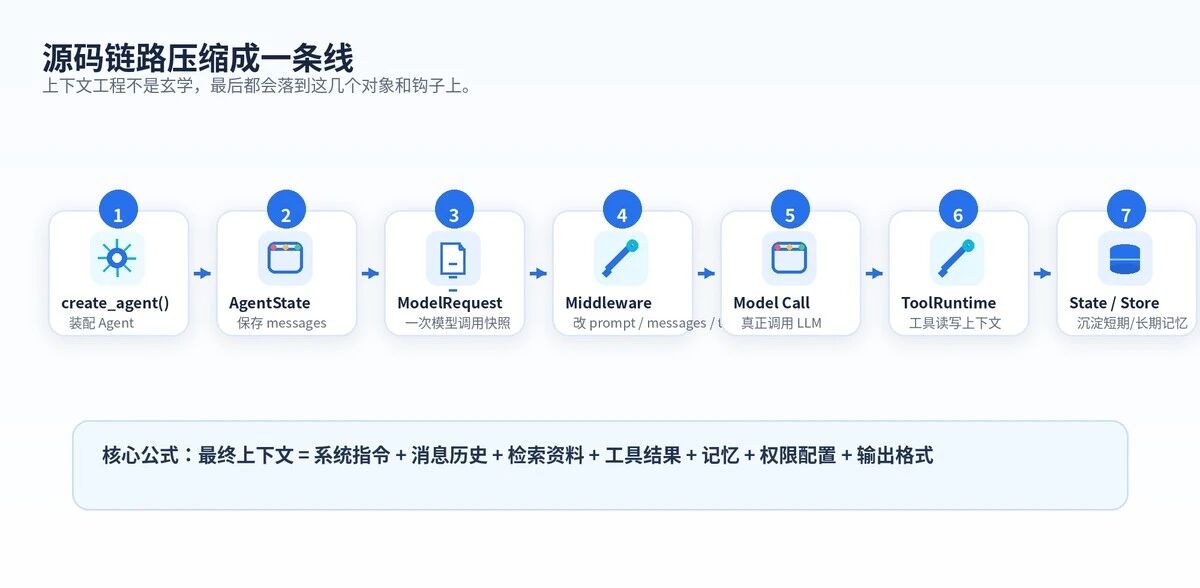
上下文工程的核心源码链路。
六、ModelRequest 是一次模型调用的上下文快照
ModelRequest 很关键。
它不是普通参数对象。
它是一次模型调用前的"上下文快照"。
里面装着:模型、消息、系统指令、工具、输出格式、状态、运行时上下文。

ModelRequest 的精简源码结构。
源码里最值得注意的是 override。
它不是直接修改原请求,而是返回一个新请求。
这意味着:中间件可以临时换模型、换工具、换消息、换输出格式,而不污染原始状态。
|-----------------------------------------------------------------------|
| 源码理解 ModelRequest.override(...) 是上下文工程最常见的动刀口。它让"本次模型调用看到什么"变得可控。 |
七、AgentState 是短期上下文的仓库
AgentState 里最核心的字段是 messages。
它不是普通 list。它带有 add_messages reducer。
这意味着:每次模型返回、工具返回,都会被追加进状态。
|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 精简源码 class AgentState(TypedDict): messages: RequiredAnnotated\[list\[AnyMessage, add_messages]] jump_to: NotRequired... structured_response: NotRequired... |
所以,聊天历史为什么能一轮轮延续?
答案就在这里:messages 被状态图持续合并。
但这也带来问题:messages 会越来越长。
所以后面必须有裁剪、摘要、过滤。
八、Middleware 是上下文手术刀
Middleware 让你在 Agent Loop 的关键点动手。
常见钩子有四类:
before_model:模型调用前,适合裁剪消息、注入规则、提前结束。
wrap_model_call:包住模型调用,适合换模型、换工具、换 response_format。
after_model:模型返回后,适合校验输出、拦截敏感内容、决定跳转。
wrap_tool_call:包住工具调用,适合鉴权、重试、脱敏、审计。
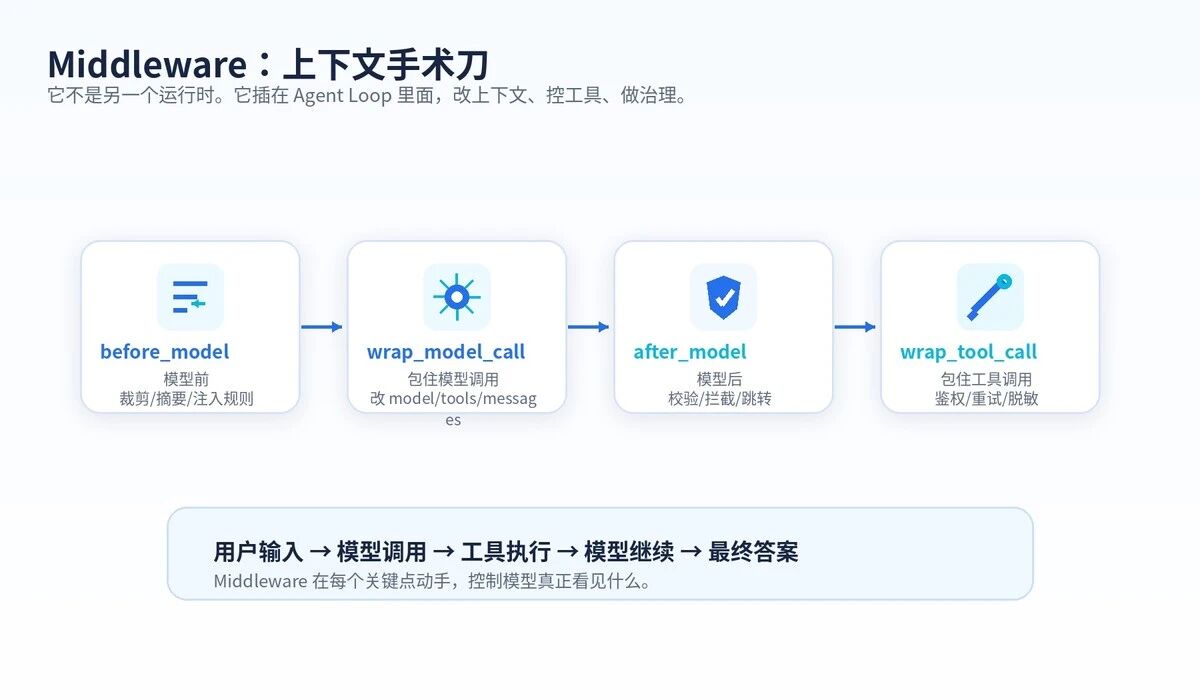
Middleware 插在 Agent Loop 内部,控制上下文流动。
|----------------------------------------------------------------|
| 工程价值 Middleware 的本质,是把"拼上下文"从散乱业务代码里抽出来,变成可复用、可测试、可审计的工程层。 |
九、动态上下文:不是所有用户都该看到同一套 Prompt 和工具
同一个 Agent,不同用户看到的上下文应该不同。
管理员、普通用户、游客,权限不同。
新用户、老用户、高风险用户,策略不同。
短对话、长对话、复杂任务,模型也可以不同。
这就是动态上下文。
|----------------------------------------------------------------------------------------------------------------------------------------------|
| 典型做法 用 runtime.context 读取用户角色;用 state 读取会话状态;用 store 读取长期偏好;再通过 ModelRequest.override(...) 改 system_message、tools、model、response_format。 |
工具也一样。
不要把所有工具一次性暴露给模型。
工具越多,模型越容易选错。
正确做法是:按权限、意图、阶段动态筛工具。
十、上下文太长:不是扩上下文窗口,而是管上下文质量
长上下文不等于好上下文。
长上下文会带来四个问题:
成本上升:token 越多,越贵。
延迟上升:输入越长,越慢。
注意力分散:无关信息越多,模型越容易跑偏。
冲突增加:旧信息、新信息、工具信息互相打架。
解决思路不是无限塞,而是选、裁、压、隔离。

上下文压缩的四种常见手段。
十一、SummarizationMiddleware 做的是持久压缩
临时裁剪,只影响这一次模型调用。
摘要中间件不一样。
它会把旧消息压成摘要,并写回 State。
以后每一轮都会看到摘要,而不是原始长历史。
|---------------------------------------------------------------------------------------------------------------------------------------------|
| 精简源码链路 SummarizationMiddleware → 统计 messages token → 达到 trigger 阈值 → 保留最近 keep 条消息 → 用模型总结旧消息 → 用 summary message 替换旧消息 → 更新 AgentState |
这就是生命周期上下文。
它不是临时改 ModelRequest。
它会真正改变未来会话的状态。
十二、企业级做法:做一个 Context Builder
生产系统不要到处拼 Prompt。
更好的做法是加一层 Context Builder。
它负责统一收集、筛选、压缩、注入上下文。
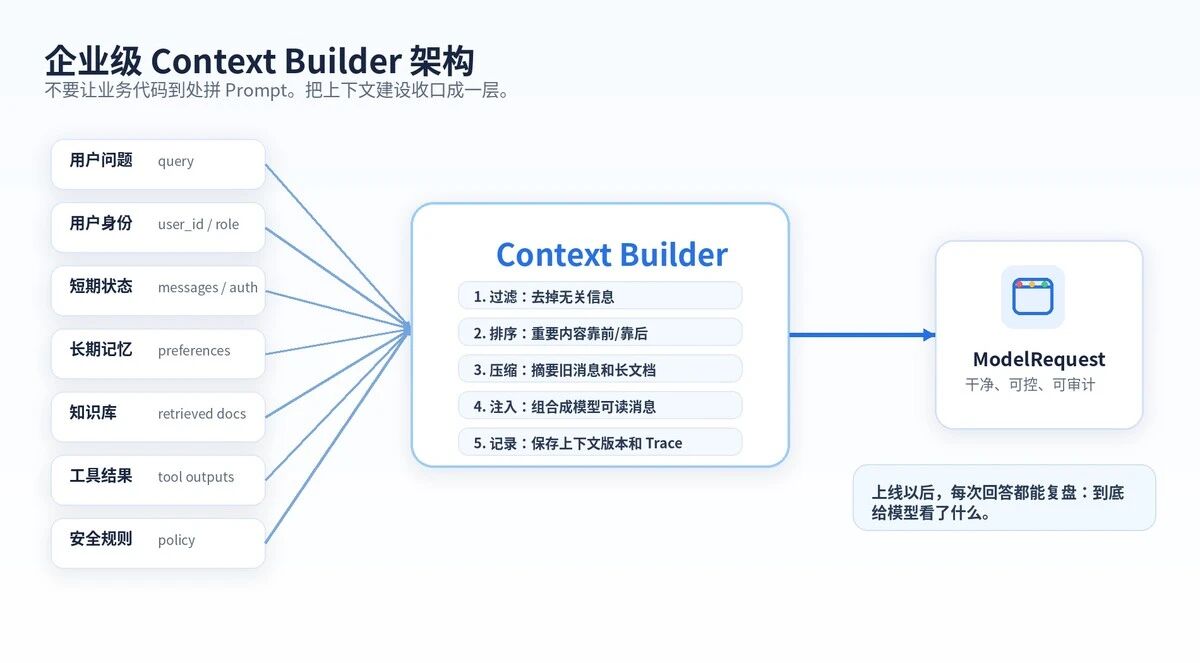
这一层应该输出一份干净的 ModelRequest。
里面包括:
任务上下文:当前用户到底要做什么。
身份上下文:用户是谁、权限是什么。
记忆上下文:用户偏好、历史偏好。
知识上下文:RAG 检索到的资料。
工具上下文:工具结果、错误状态。
安全上下文:合规规则、敏感词、风险控制。
输出上下文:结构化输出 Schema。
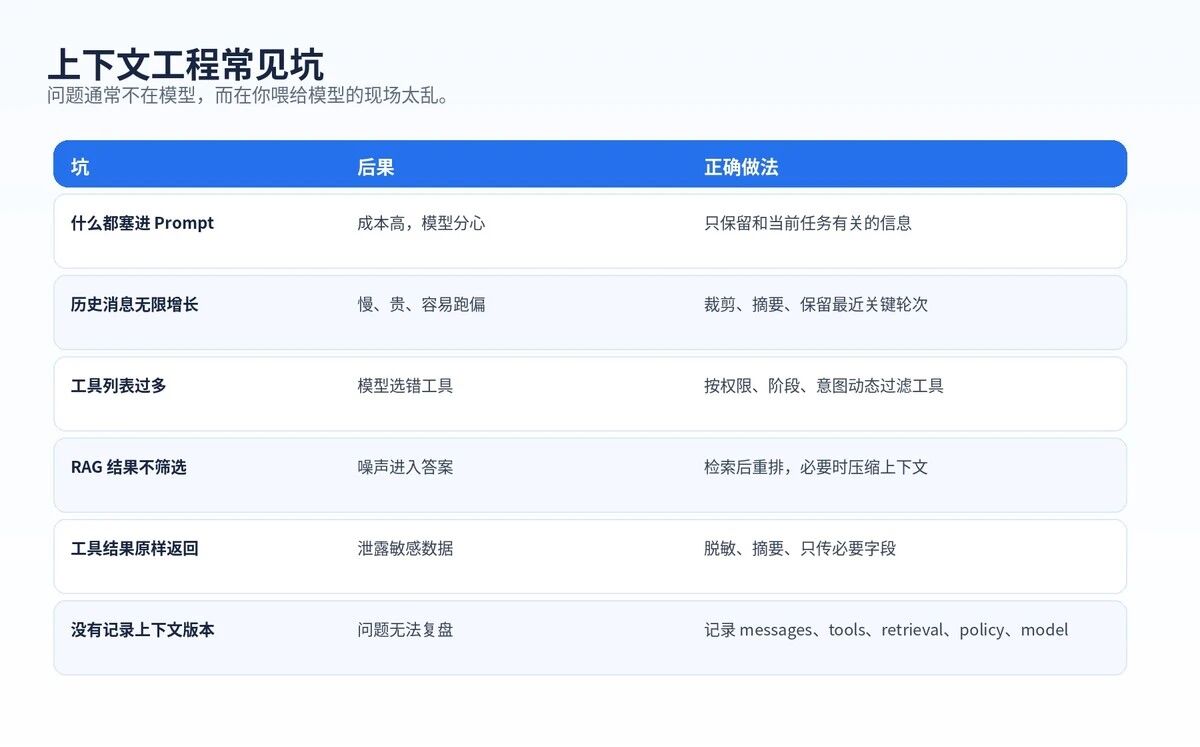
十三、上下文工程常见坑
上下文工程做不好,Agent 就会看起来"不聪明"。
本质上,是你给它的现场太乱。
十四、总结
|--------------------------------------------------------------|
| 最终结论 Prompt 只是上下文的一部分。真正决定 Agent 质量的,是你能否控制模型每一步看到的全部信息。 |
内容来源:Context Engineering:比 Prompt Engineering 更重要的上下文工程:功能变化与行业影响解析_热闻岛