小型语言模型(SLM)调研:从端侧部署到专业化 Agent
调研时间: 2026-06-12
适用读者: 关注本地 AI、端侧 Agent、低成本推理、私有化部署和模型选型的开发者
核心观点: 小模型不再只是"大模型的低配替代品"。在工具调用、代码补全、端侧助手、隐私敏感任务和固定流程自动化中,小模型正在成为更经济、更可控、更容易落地的默认选项。但在复杂推理、开放式长文档理解和高可靠多轮规划中,大模型仍然是必要兜底。
目录
- 为什么重新关注小模型
- 主流小模型版图
- 代表模型与适用场景
- 关键趋势:小模型正在变强的原因
- 行业观察与洞察结论
- 应用场景与边界
- 模型选型指南
- 生产落地架构
- 如何验证一个小模型是否可用
- 值得继续关注的项目
- 参考资料
1. 为什么重新关注小模型
过去两年,开发者谈 AI 应用时默认会从大模型开始:更强的推理、更好的泛化、更少的工程约束。但真实业务系统里,大量请求并不需要通用智能,而是更接近下面这些任务:
- 把自然语言路由到一个 API 或工具;
- 从固定格式中抽取参数;
- 在局部代码上下文中补全几行代码;
- 对本地文档做轻量问答或分类;
- 在手机、浏览器、边缘设备上执行低延迟推理;
- 在企业内网处理敏感数据,不上传到外部服务。
这些任务的共同点是:输入空间有限、输出格式可约束、业务目标明确、可收集领域数据。小模型在这些条件下通常更有优势:
| 维度 | 小模型优势 | 代价 |
|---|---|---|
| 成本 | 推理成本低,可本地部署 | 需要更精细的评估和路由 |
| 延迟 | CPU、NPU、浏览器 WASM 均可运行 | 首 token 质量和复杂推理弱于大模型 |
| 隐私 | 数据不必离开设备或内网 | 运维和模型更新由自己负责 |
| 可控性 | 容易微调、蒸馏和约束输出 | 泛化能力有限 |
| 工程集成 | 可作为系统中的专用组件 | 需要 fallback 和监控 |
因此,小模型更合理的定位不是"替代所有大模型",而是成为 AI 系统中的第一层执行器:高频、低风险、格式明确的任务交给小模型,低置信度或复杂任务再交给大模型。
2. 主流小模型版图
下面按照参数规模和模型定位梳理当前值得关注的小模型。表格中的性能数字来自模型卡、官方博客或公开 benchmark;不同评测集之间不可直接等价,应作为选型线索而不是最终结论。
2.1 极小模型:100M 以下
这类模型通常不适合开放式对话,更适合作为分类器、路由器、格式化抽取器、嵌入式 demo 或研究对象。
| 模型 | 参数量 | 典型定位 | License | 备注 |
|---|---|---|---|---|
| Needle | 26M | 单轮工具调用 | MIT | 极窄专家模型,专注 function/tool calling |
| Doge-60M | 55M | 超轻量语言模型 | Apache 2.0 | 适合研究和极低资源实验 |
| Lite-Oute-1-65M | 65M | 移动端轻量模型 | Apache 2.0 | 偏端侧部署 |
| llama-68m | 68M | 社区小模型 | Apache 2.0 | 生态活跃度较高 |
| Yuuki NxG Nano | 81M | 低成本训练实验 | Apache 2.0 | 适合观察小模型训练方法 |
| Pythia-70M | 约 96M | 可复现实验 | Apache 2.0 | EleutherAI,训练过程透明 |
这一区间的核心价值不是"聪明",而是"便宜、快、可控"。如果任务可以被定义为分类、路由、抽取或模板化生成,它们才有实际意义。
2.2 100M 到 1.5B:端侧和轻量服务的主力区间
| 模型 | 参数量 | 上下文 | License | 适合场景 |
|---|---|---|---|---|
| SmolLM2-135M | 135M | 8K | Apache 2.0 | 教学、研究、轻量文本任务 |
| SmolLM2-360M | 360M | 8K | Apache 2.0 | 轻量问答、分类、实验 |
| Qwen3-0.6B | 0.6B | 32K | Apache 2.0 | 多语言、端侧、轻量 Agent |
| Qwen3.5-0.8B | 0.8B | 262K 级别 | Apache 2.0 | 较新小模型,规格以模型卡和平台支持为准 |
| LFM 2.5 1.2B | 1.2B | 依实现而定 | 待确认 | 非 Transformer/混合架构,速度表现突出 |
| MobileLLM-Flash 1.4B | 1.4B | 依实现而定 | Research | 面向移动端推理 |
| DeepSeek-R1-Distill-Qwen-1.5B | 1.5B | 依版本而定 | Apache 2.0 | 推理蒸馏、CoT 类任务 |
这个区间最值得关注的是 Qwen、SmolLM、LFM 等模型家族。它们已经能承担部分真实业务任务,但仍需要明确边界:不要把 1B 级模型当成通用助理,而应把它们放在"结构化、可验证、可兜底"的系统里。
2.3 1.5B 到 4B:当前性价比最高的通用小模型区间
| 模型 | 参数量 | 上下文 | License | 亮点 | 主要限制 |
|---|---|---|---|---|---|
| Qwen3-1.7B | 1.7B | 32K | Apache 2.0 | 多语言、推理、Agent 能力均衡 | 端侧部署需量化和性能测试 |
| SmolLM3-3B | 3B | 128K | Apache 2.0 | Hugging Face 出品,长上下文、双模式推理 | 代码和复杂 Agent 能力需单独评测 |
| Qwen2.5-Coder-3B | 3.1B | 32K | Apache 2.0 | 本地代码补全和代码生成强 | 非通用 Agent 模型 |
| Llama 3.2 3B | 3B | 128K | Meta Community | 生态成熟、工具链完善 | License 不是 Apache/MIT |
| Phi-4-mini | 3.8B | 128K | MIT | 推理能力强、体积小 | 仍建议以具体模型卡为准 |
| Gemma 3 4B | 4B | 128K | Gemma Terms | 多模态、数学和代码能力强 | 许可证和使用条款需评估 |
| Qwen3-4B | 4B | 32K 原生,可扩展 | Apache 2.0 | 综合能力强,开源友好 | 长上下文扩展需实测 |
| Qwen3.5-4B | 4B | 262K 级别 | Apache 2.0 | 新一代长上下文、工具和推理能力 | 较新模型,生态成熟度仍在变化 |
如果目标是"本地可用但能力不要太弱",3B 到 4B 是目前最值得测试的范围。它们在 4-bit 量化后可以进入普通消费级设备,但实际体验强依赖硬件、推理框架、上下文长度和任务类型。
2.4 多模态与专项小模型
| 模型 | 参数量 | 方向 | 适合场景 |
|---|---|---|---|
| SmolVLM | 256M-2B | 视觉-语言 | 图片理解、端侧 VLM |
| Gemma 3n E4B | 4B effective | 端侧多模态 | 移动端视觉、语音、文本任务 |
| Gemma 4 small/edge models | small/edge 系列 | 多模态、Agent、function calling | 端侧多模态和工具调用 |
| Qwen3-VL compact models | 4B/8B 等 | 视觉-语言 | 截图理解、视觉问答、GUI Agent |
| North Mini Code | 3B active / MoE | 代码生成 | 本地代码助手、低成本代码服务 |
多模态小模型是接下来一年最值得关注的方向之一。原因很简单:端侧 AI 真正有价值的场景往往不是纯文本,而是摄像头、屏幕、语音、传感器和本地应用状态共同参与。
3. 代表模型与适用场景
3.1 Qwen 系列:开源友好、能力均衡
Qwen3 公开了从 0.6B 到 32B 的 dense models,也包括 MoE 模型,官方说明为 Apache 2.0。对小模型开发者来说,Qwen 的优势主要有三点:
- 中文和多语言能力相对稳;
- 模型尺寸覆盖完整,从 0.6B 到 4B 都有可选项;
- 推理、工具调用、代码、长上下文能力比较均衡。
推荐用法:
| 任务 | 建议模型 |
|---|---|
| 轻量本地问答/分类 | Qwen3-0.6B、Qwen3.5-0.8B |
| 本地 Agent 原型 | Qwen3-1.7B |
| 稳定一点的本地通用助手 | Qwen3-4B、Qwen3.5-4B |
| 代码专项 | Qwen2.5-Coder-3B |
需要注意的是,Qwen3.5 属于较新的模型家族,Hugging Face collection、推理平台和第三方评测已经提供了不少规格和部署信息,但正式选型时仍建议以具体模型卡、运行框架支持和自己的 benchmark 为准。
3.2 SmolLM 系列:研究友好和训练透明
SmolLM 系列由 Hugging Face 推出,特点是模型规模清晰、训练资料相对完整、适合研究和教学。SmolLM3-3B 支持长上下文和 dual-mode reasoning,是 3B 区间值得对比的基线。
推荐用法:
- 教学和研究:SmolLM2-135M、SmolLM2-360M;
- 长上下文小模型实验:SmolLM3-3B;
- 构建可复现训练和评测流程:优先考虑 SmolLM 家族。
SmolLM 的价值不只是模型本身,还在于它提供了一个相对透明的小模型训练参考系。
3.3 Gemma 系列:强能力但需要关注条款
Gemma 3 4B 已经是 4B 档位中很强的候选,具备 128K 上下文、多语言和多模态能力。Google 近期也发布了 Gemma 4,官方文档强调 small/edge models 具备 128K 上下文、function calling、coding 和 agentic capabilities。
推荐用法:
- 多模态端侧应用;
- 数学、代码和通用推理;
- 需要 Google 生态兼容的应用。
需要注意的是,Gemma 使用 Google 的 Gemma Terms,不是 Apache 2.0 或 MIT。商业使用前应单独检查条款。
3.4 Phi 系列:小体积推理能力强
Phi-4-mini 这类模型的优势在于小体积下的推理和知识密度。它适合做本地推理助手、低资源问答、数学或逻辑类任务的候选模型。
Phi-4-mini 常见模型卡显示为 MIT License,但 Phi 系列存在不同版本和分发渠道,商用、再分发、微调发布等场景仍应以具体模型卡和许可证文件为准。
3.5 Needle:极窄专家模型的代表
Needle 是 Cactus Compute 在 2026 年 5 月发布的 26M function/tool calling 模型。它的特殊之处不是"通用能力强",而是把一个任务做到非常窄:单轮工具调用。
核心信息:
| 属性 | 说明 |
|---|---|
| 参数量 | 26M |
| 量化后体积 | 约 14MB |
| 架构 | Simple Attention Network,去掉 Transformer 中的 MLP/FFN |
| 任务 | 单轮 function/tool calling |
| License | MIT |
| 官方速度 | Cactus Runtime 上约 6000 tok/s prefill、1200 tok/s decode |
Needle 的启发在于:并不是所有 Agent 子任务都需要通用 LLM。工具选择、参数填充、JSON 生成等环节可以被拆成更小、更快、更可验证的组件。
但它的边界也非常清楚:
- 不适合开放式对话;
- 不负责复杂推理;
- 缺少天然拒绝机制,输入不匹配时仍可能生成工具调用;
- 生产中需要 guard、置信度阈值和 fallback。
因此,Needle 更适合作为"工具路由器"或"结构化调用层",不是通用小模型的替代品。
3.6 LFM、Mamba 和 MoE:架构路线正在分化
除了标准 Transformer,小模型领域还在探索混合架构:
- LFM 2.5 等非 Transformer/混合模型强调速度和长序列效率;
- Falcon-H1-Tiny 等模型使用 Mamba + Attention;
- North Mini Code 等 MoE 模型用较低激活参数获得更大容量;
- Qwen3.5 等新模型也出现了 hybrid architecture 的描述。
这类模型值得关注,但选型时要更谨慎:生态、推理框架、量化支持、部署文档往往比模型指标更重要。
4. 关键趋势:小模型正在变强的原因
4.1 专业化,而不是小号通用模型
小模型最容易成功的路线不是"什么都做一点",而是聚焦任务:
- 代码模型专注代码语料和代码评测;
- 工具调用模型专注 schema、参数和 JSON;
- 端侧多模态模型专注摄像头、屏幕和语音场景;
- 轻量问答模型专注 RAG 后的短答案生成。
专业化让模型不必把有限参数浪费在过宽的能力面上。
4.2 蒸馏和合成数据成为核心生产方式
小模型的能力很大程度来自大模型蒸馏:用强模型生成训练数据、推理轨迹、工具调用样本,再训练小模型执行固定任务。
这意味着未来的常见架构会是:
text
训练阶段:大模型生成数据 / 评审数据 / 修正样本
推理阶段:小模型本地执行 / 大模型低频兜底"训练靠大模型,推理用小模型"会成为很多垂直场景的默认实践。
4.3 长上下文下沉到小模型
过去长上下文主要属于大模型。现在部分 3B-4B 模型已经支持 128K 上下文,一些较新的小模型或平台版本也宣称支持 256K 级别上下文。长上下文并不自动等于强理解,但它让小模型能处理更多本地上下文,例如:
- 单个代码仓库片段;
- 长会议记录;
- 本地知识库检索结果;
- 多轮工具调用状态;
- GUI 或浏览器操作轨迹。
需要注意的是,长上下文会显著增加 KV cache 和延迟,端侧部署不能只看"最大上下文"。
4.4 约束解码和结构化输出降低了模型压力
很多业务场景并不需要模型自由发挥,而是需要输出合法 JSON、选中一个工具、填对几个参数。通过约束解码、schema validation、grammar decoding 和后处理校验,可以把生成空间缩小很多。
这对小模型尤其重要:让模型只在允许范围内生成,比期待它自然学会所有格式规范更可靠。
5. 行业观察与洞察结论
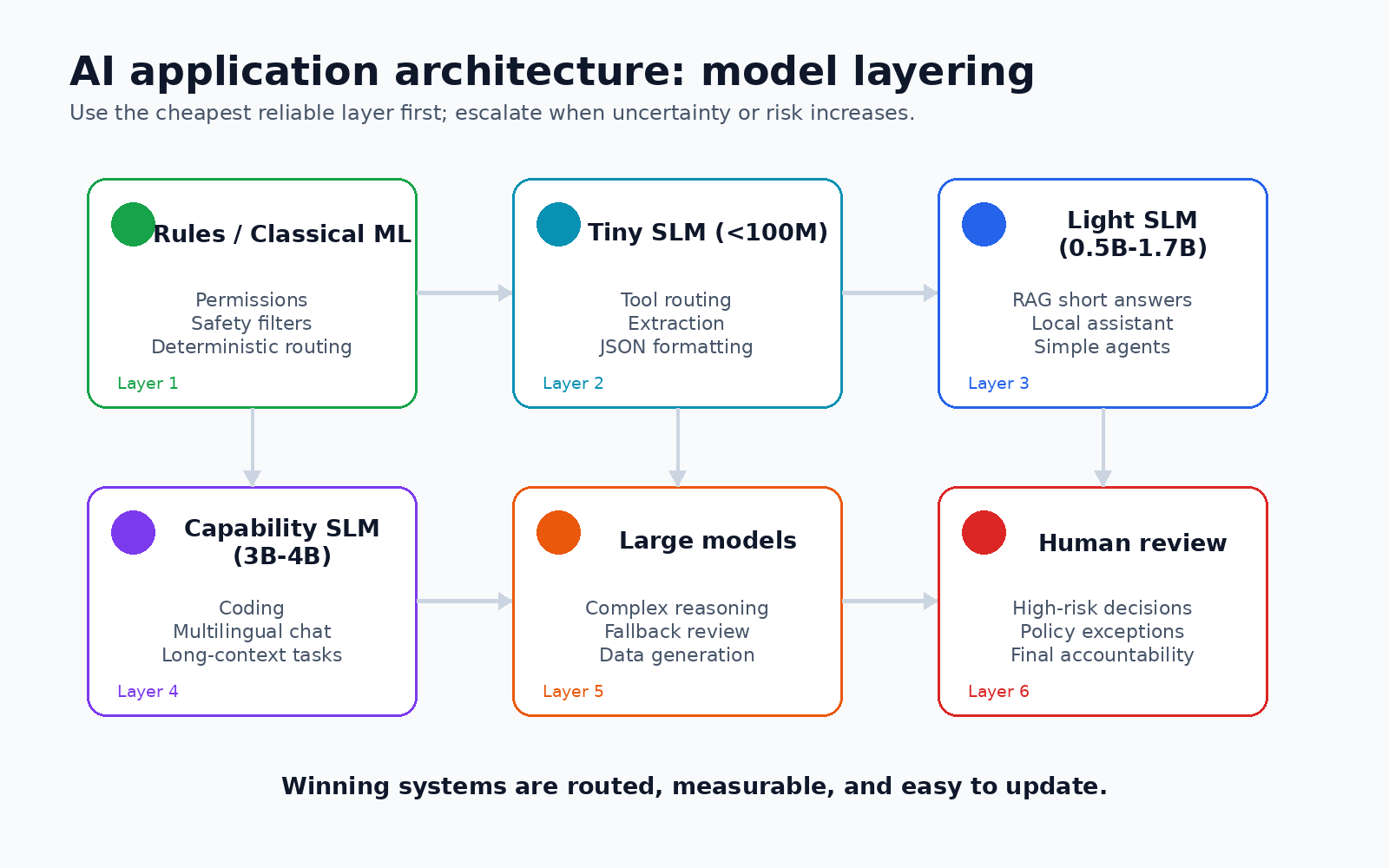
5.1 AI 应用架构正在从"单模型调用"变成"模型分层系统"
早期 AI 应用通常是一个前端加一个大模型 API:用户输入直接交给大模型,模型负责理解、推理、生成、调用工具和兜底。这个架构简单,但成本高、延迟不稳定,也很难解释每一次失败来自哪里。
小模型普及后,更合理的架构会变成分层系统:
text
规则和传统模型:处理确定性逻辑、权限、安全、简单分类
小模型:处理高频、低风险、结构化、可验证任务
大模型:处理复杂推理、开放式任务、异常兜底
人工流程:处理高风险、不可自动决策的场景未来的 AI 工程能力不只是"会调用哪个大模型",而是"会把任务拆到合适的智能层级"。模型路由、评测、监控、fallback、数据闭环,会比单次 prompt 设计更重要。
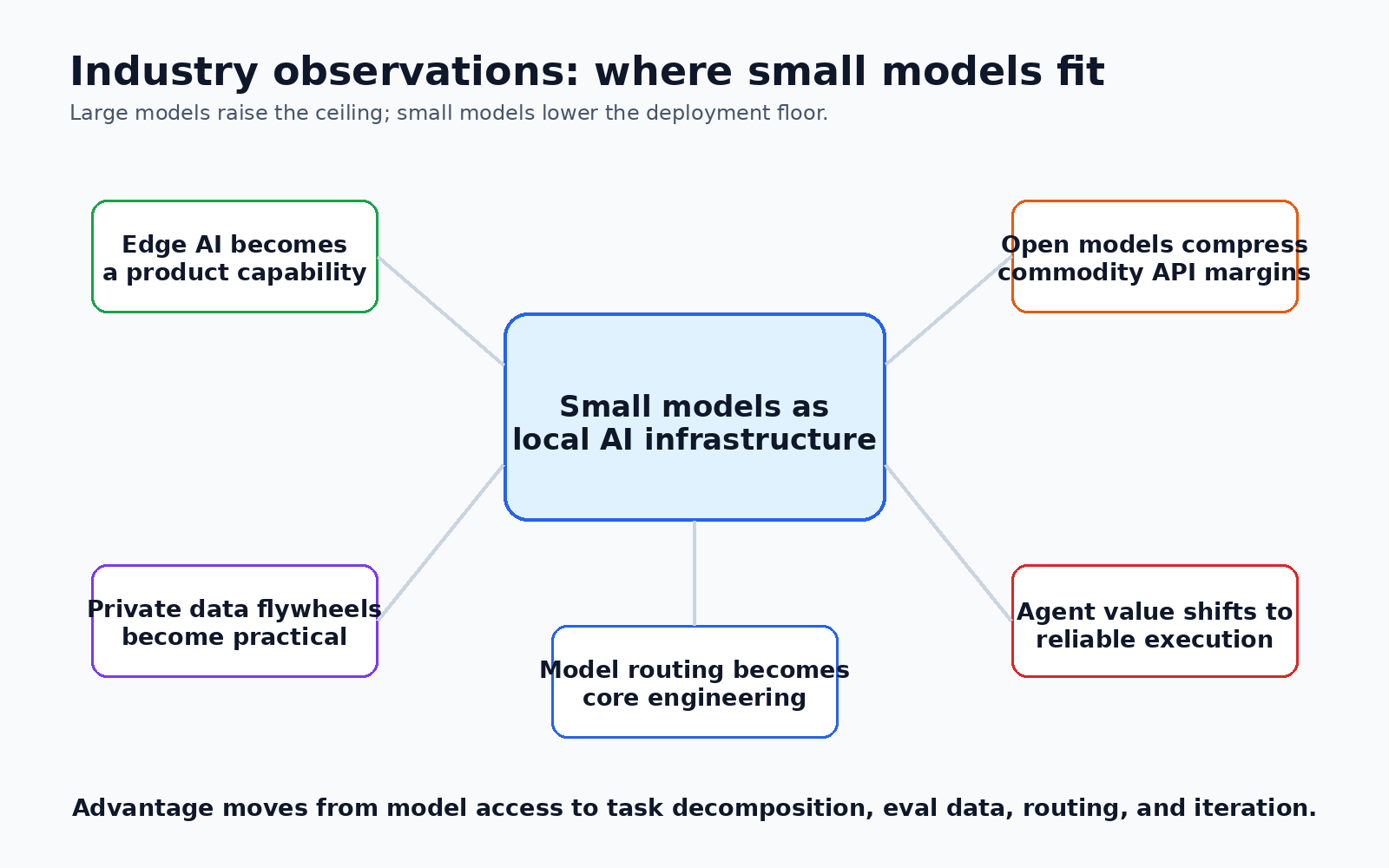
5.2 端侧 AI 会从体验优化变成产品能力
端侧小模型的价值不只是省钱。它会改变产品形态:
- 低延迟: 语音助手、车载座舱、AR 眼镜、输入法、代码补全等场景不能每一步都等云端返回。
- 隐私: 医疗、金融、办公文档、个人日程、企业代码等数据更适合在本地处理。
- 离线可用: 可穿戴设备、工业现场、车载系统和跨境应用都需要弱网甚至断网能力。
- 个性化: 本地模型更容易基于用户行为持续适配,而不必把所有数据上传。
因此,端侧 AI 不是云端 AI 的低配版,而是另一种产品能力:靠近用户、靠近数据、靠近设备传感器。
5.3 开源小模型会压缩中间层 API 的利润空间
大模型 API 仍然会有价值,尤其在复杂推理和高质量生成上。但对大量中低复杂度任务来说,开源小模型会不断压低成本基线。
这会带来三个变化:
- 只包装通用模型 API 的应用会越来越难形成壁垒;
- 真正的壁垒会转向业务数据、工作流集成、评测体系和交付能力;
- 企业会更倾向于混合架构:内部小模型处理常规任务,外部大模型处理疑难请求。
换句话说,模型能力本身会继续商品化,系统能力和行业数据会变得更值钱。
5.4 小模型让"私有数据飞轮"更容易建立
大模型 API 时代,很多团队没有持续训练和微调的习惯,因为成本、权限和工具链都比较重。小模型降低了这件事的门槛:
text
真实用户请求 -> 失败样本 -> 人工/大模型修正 -> 小模型微调 -> 回归评测 -> 灰度上线这套闭环一旦跑起来,小模型会越来越贴合某个企业、某个产品、某个流程。长期看,通用模型提供基础能力,垂直小模型承接业务经验,这会成为企业 AI 落地的重要路线。
5.5 Agent 的瓶颈不只是模型智商,而是可靠执行
Agent 热潮容易让人误以为核心问题是"找一个更聪明的模型"。但真实系统里的难点通常是:
- 工具描述是否清晰;
- 权限和状态是否可控;
- 每一步输出是否可验证;
- 失败后能否恢复;
- 是否知道什么时候不该行动;
- 是否能在成本和延迟预算内完成任务。
小模型在 Agent 系统里的角色,往往不是替代大模型思考,而是承担稳定的执行部件:路由、抽取、格式化、校验、短链路工具调用。Agent 要真正进入生产,靠的是"可控执行链",不是单纯更长的思维链。
5.6 行业会出现更多"模型组合"而不是单一赢家
未来不会只有一个最强小模型通吃所有场景。更可能出现的是模型组合:
| 层级 | 典型模型/方法 | 作用 |
|---|---|---|
| 规则层 | 规则、正则、传统分类器 | 处理确定性逻辑和低成本过滤 |
| 极小模型 | 100M 以下模型、专用 tool model | 路由、抽取、简单结构化输出 |
| 轻量模型 | 0.5B-1.7B | 端侧问答、RAG 短答、轻量 Agent |
| 能力模型 | 3B-4B | 本地助手、代码、多语言、长上下文 |
| 大模型 | GPT/Claude/Gemini/大参数开源模型 | 复杂推理、兜底、数据生成和评审 |
对企业和开发者来说,关键问题不是"哪个模型最强",而是"哪个组合在我的业务里最稳、最便宜、最好维护"。
5.7 洞察结论
综合来看,小模型的发展代表了 AI 行业从"能力崇拜"走向"工程效率"的阶段变化。大模型继续推动能力上限,小模型负责把这些能力拆解、压缩、部署到真实产品里。
可以把未来两三年的趋势概括为五句话:
- 大模型定义上限,小模型决定普及速度。
- 通用能力会商品化,行业数据和评测体系会成为壁垒。
- 端侧 AI 会从可选优化变成关键产品能力。
- Agent 的核心竞争力会从 prompt 转向可靠执行链。
- 最优解不是选一个模型,而是构建可评测、可路由、可迭代的模型系统。
6. 应用场景与边界
6.1 适合小模型优先的场景
| 场景 | 推荐模型类型 | 原因 |
|---|---|---|
| 单轮工具调用 | Needle、Qwen 小模型、专用微调模型 | 输出结构明确,可约束 |
| 本地代码补全 | Qwen2.5-Coder-3B、North Mini Code | 代码上下文局部性强 |
| 企业内网文档分类 | Qwen3-1.7B、SmolLM3-3B | 隐私和成本敏感 |
| RAG 后短答案生成 | Qwen3-1.7B、Qwen3.5-0.8B/4B | 上下文由检索控制 |
| 移动端助手 | Qwen3-0.6B/1.7B、Gemma 3n、Gemma 4 small | 低延迟、本地运行 |
| 浏览器/边缘 Worker | WASM/ONNX 小模型 | 部署轻、靠近用户 |
| 固定流程自动化 | 专用微调模型 | 任务边界清晰 |
6.2 不适合完全交给小模型的场景
| 场景 | 风险 |
|---|---|
| 高风险医疗、法律、金融建议 | 需要更强模型、审计和人工复核 |
| 复杂多步推理 | 小模型容易中途偏航 |
| 开放域深度问答 | 参数知识不足,幻觉风险高 |
| 超长文档综合分析 | 长上下文不等于稳定综合能力 |
| 无明确评测集的 Agent | 无法判断真实可靠性 |
| 需要强拒绝能力的安全场景 | 很多小模型不会稳定 abstain |
一句话:小模型适合"把确定的事做得便宜又快",不适合"在不确定中独立负责最终判断"。
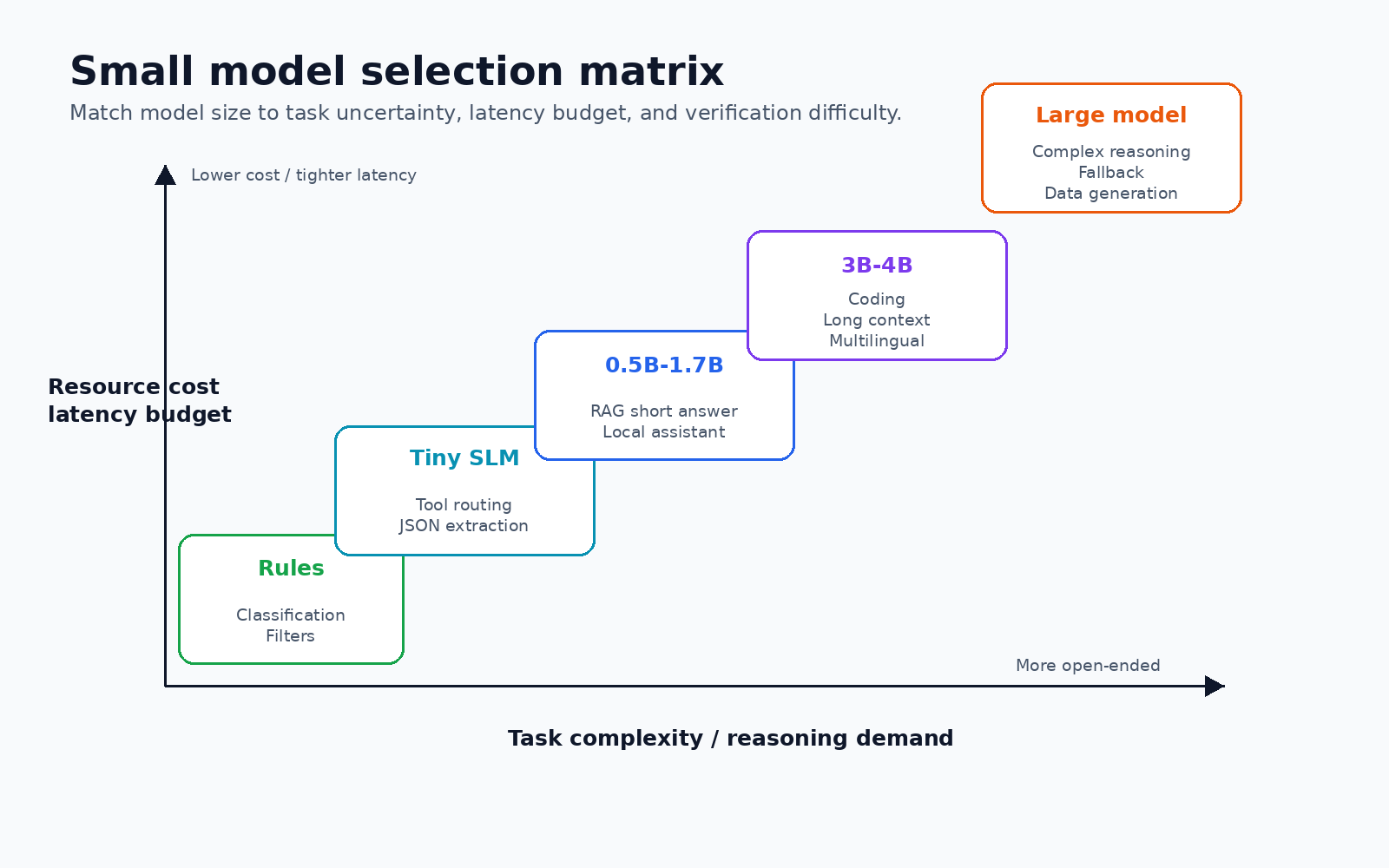
7. 模型选型指南
7.1 按任务选
| 任务 | 首选候选 | 备选 | 重点验证 |
|---|---|---|---|
| 单轮 Tool Calling | Needle、Qwen3-0.6B/1.7B 微调 | Qwen3.5-0.8B | 工具选择、参数 exact match、拒绝能力 |
| 多步 Agent | Qwen3-1.7B/4B | Gemma 4 small、Phi-4-mini | 多轮状态、错误恢复、是否乱调用工具 |
| 代码补全 | Qwen2.5-Coder-3B | North Mini Code | 本仓库代码风格、延迟、隐私 |
| 通用本地助手 | Qwen3-4B、Gemma 3/4 small | SmolLM3-3B、Phi-4-mini | 中文、推理、长上下文 |
| 教学/研究 | SmolLM2、Pythia | TinyLlama 类模型 | 可复现性、训练资料 |
| 端侧多模态 | Gemma 3n、Gemma 4 small、SmolVLM | Qwen3-VL compact | 设备兼容、功耗、模型格式 |
| 超低资源路由 | Needle、100M 以下模型 | 传统分类器 | 误路由成本、fallback |
7.2 按资源选
| 资源限制 | 可考虑模型 |
|---|---|
| <20MB | Needle INT4、传统 ML 分类器 |
| <100MB | 100M 以下量化模型 |
| <1GB RAM | Qwen3-0.6B、SmolLM2-360M、专用小模型 |
| <3GB RAM | Qwen3-1.7B、Qwen3.5-0.8B、部分 3B Q4 |
| 4-8GB RAM/VRAM | Qwen3-4B、SmolLM3-3B、Gemma 3/4 small |
| 浏览器 | WASM/ONNX/WebGPU 优先,模型越小越稳 |
| 手机 NPU | 优先选择已有端侧 runtime 支持的模型 |
7.3 按 License 选
| License 类型 | 模型/家族 | 备注 |
|---|---|---|
| MIT | Needle | 商用友好,仍需确认依赖许可 |
| Apache 2.0 | Qwen、SmolLM、Pythia、部分代码模型 | 企业落地通常更容易 |
| Meta Community License | Llama 3.2 | 需遵守 Meta 条款 |
| Gemma Terms | Gemma 3/4 | 不是 Apache/MIT,商用前需审条款 |
| MIT | Phi-4-mini 常见模型卡 | 不同 Phi 版本和渠道仍需逐项确认 |
选型时不要只看模型能力。License、推理框架、量化格式、部署工具链、社区活跃度,经常比 benchmark 更决定能不能上线。
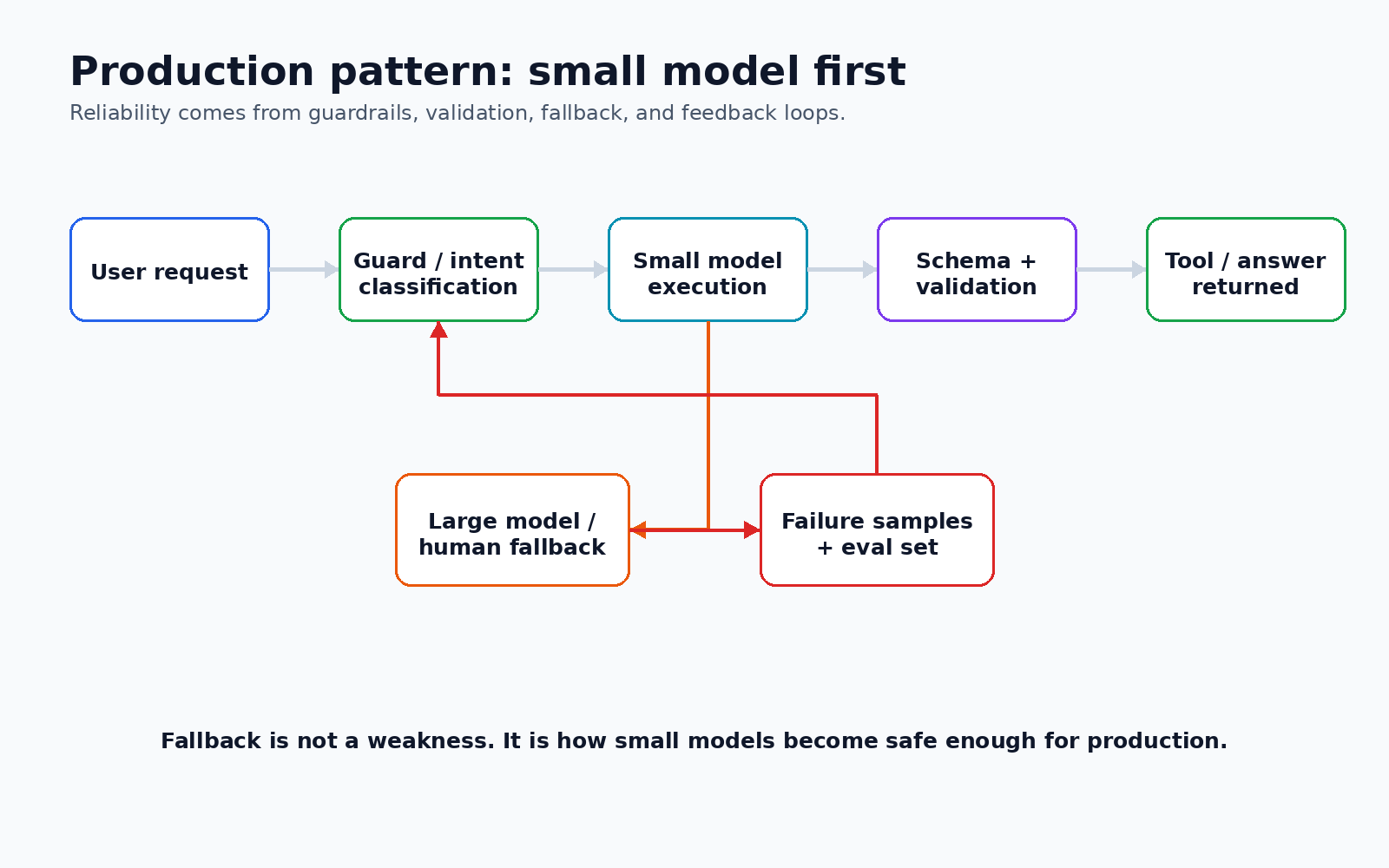
8. 生产落地架构
8.1 小模型优先,大模型兜底
text
用户请求
|
v
轻量 Guard / 意图识别 / 安全检查
|
+-- 高置信度、低风险、结构化任务 --> 小模型处理
| |
| +-- 工具调用:专用 tool model / Qwen 小模型
| +-- 代码补全:Coder 小模型
| +-- RAG 短答:1B-4B 通用小模型
|
+-- 低置信度、复杂推理、高风险任务 --> 大模型或人工复核这个架构的关键不是"永远用小模型",而是明确路由条件:
- 小模型能否给出置信度;
- 输出能否被校验;
- 错误成本是否可接受;
- 是否有 fallback;
- 是否能记录失败样本并持续微调。
8.2 工具调用系统建议
工具调用是小模型最容易落地的场景,但也最容易被低估。建议把系统拆成几层:
text
用户输入
-> 安全检查 / 意图分类
-> 工具候选召回 Top-K
-> 小模型生成调用 JSON
-> JSON schema validation
-> 参数业务校验
-> 执行工具
-> 失败时 fallback 或追问特别注意 abstention 问题:模型不仅要知道"调用哪个工具",还要知道"什么时候不该调用工具"。如果模型本身不会拒绝,必须用外层 guard 或分类器补上。
8.3 持续微调闭环
小模型上线后的价值来自持续迭代:
text
1. 为每个任务构造初始评测集
2. 上线灰度,记录失败样本
3. 人工或大模型修正失败样本
4. 加入训练集或偏好数据
5. 定期微调并回归测试
6. 只在指标提升且无关键回退时发布小模型微调成本低,这是它相对大模型 API 的重要优势。但低成本不等于可以随意更新。每次更新都需要固定评测集和线上监控。
9. 如何验证一个小模型是否可用
不要只看公开 benchmark。真正的判断标准应该来自你的任务、数据和约束。
9.1 最小评测集
建议至少准备:
- 200-500 条真实或近似真实用户输入;
- 覆盖高频路径、低频路径、异常输入、恶意输入;
- 每条样本包含期望输出、可接受输出范围和错误等级;
- 工具调用任务要包含"不应调用任何工具"的负样本。
9.2 核心指标
| 指标 | 说明 |
|---|---|
| Task success rate | 最终任务是否完成 |
| Exact match | 工具名、参数名、参数值是否完全匹配 |
| JSON validity | 输出是否是合法结构 |
| Schema pass rate | 是否通过 schema 校验 |
| Abstention accuracy | 不该调用时是否能拒绝 |
| P50/P95 latency | 平均延迟和尾延迟 |
| Memory peak | 峰值内存/显存 |
| Cost per 1K requests | 每千次请求成本 |
| Fallback rate | 有多少请求需要大模型兜底 |
9.3 对比基线
至少对比三类方案:
| 方案 | 目的 |
|---|---|
| 规则/传统分类器 | 判断是否真的需要 LLM |
| 小模型 | 判断本地部署收益 |
| 大模型 API | 作为质量上限和 fallback 参考 |
如果小模型只比规则系统好一点,但复杂度高很多,可能不值得引入。反过来,如果小模型能覆盖相当一部分高频请求,即使剩余请求交给大模型,系统成本和延迟也会明显下降。
10. 值得继续关注的项目
| 项目 | 关注理由 |
|---|---|
| Qwen 系列 | Apache 2.0,中文、多语言、Agent 和代码能力均衡 |
| SmolLM 系列 | 训练透明,适合研究和复现 |
| Gemma 3/4 | 多模态和端侧能力强,Google 生态推进快 |
| Phi 系列 | 小体积推理能力强 |
| Needle | 极窄专家模型和工具调用组件化的代表 |
| LFM 系列 | 非 Transformer/混合架构方向 |
| SmolVLM | 端侧视觉语言模型 |
| Qwen3-VL compact models | GUI Agent、截图理解、端侧视觉任务 |
| llama.cpp / GGUF 生态 | 本地部署事实标准之一 |
| ONNX Runtime / WebGPU / WASM runtime | 浏览器和跨平台部署关键工具链 |
| awesome-mobile-llm | 端侧模型索引 |
11. 参考资料
以下资料用于核对模型信息、发布时间、上下文长度、许可和代表性指标。社区 benchmark 和博客应作为参考,不应替代自己的业务评测。
- Cactus Compute Needle 官方博客:https://cactuscompute.com/blog/needle
- Needle GitHub:https://github.com/cactus-compute/needle
- Needle Hugging Face:https://huggingface.co/Cactus-Compute/needle
- Needle SAN 文档:https://github.com/cactus-compute/needle/blob/main/docs/simple_attention_networks.md
- Qwen3 官方博客:https://qwenlm.github.io/blog/qwen3/
- Qwen3 GitHub:https://github.com/qwenLM/qwen3
- Qwen3-1.7B Hugging Face:https://huggingface.co/Qwen/Qwen3-1.7B
- Qwen3.5 Hugging Face Collection:https://huggingface.co/collections/Qwen/qwen35
- Qwen3.5 small models 规格参考:https://artificialanalysis.ai/articles/qwen3-5-small-models
- SmolLM3 Hugging Face:https://huggingface.co/HuggingFaceTB/SmolLM3-3B
- SmolLM3 官方博客:https://huggingface.co/blog/smollm3
- Llama 3.2 官方博客:https://ai.meta.com/blog/llama-3-2-connect-2024-vision-edge-mobile-devices/
- Llama 3.2 3B Hugging Face:https://huggingface.co/meta-llama/Llama-3.2-3B-Instruct
- Phi-4-mini Hugging Face:https://huggingface.co/microsoft/Phi-4-mini-instruct
- Phi-4-mini Microsoft Foundry:https://ai.azure.com/catalog/models/Phi-4-mini-instruct
- Gemma 3 4B Hugging Face:https://huggingface.co/google/gemma-3-4b-it
- Gemma 3 Technical Report:https://arxiv.org/html/2503.19786v1
- Gemma 4 Google AI Docs:https://ai.google.dev/gemma/docs/core
- Gemma 4 Google Blog:https://blog.google/innovation-and-ai/technology/developers-tools/gemma-4/
- Tool calling benchmark 示例:https://github.com/MikeVeerman/tool-calling-benchmark
- ONNX Runtime Web:https://onnxruntime.ai/docs/tutorials/web/
- llama.cpp:https://github.com/ggml-org/llama.cpp
结语
小模型的机会不在于证明"参数越少越好",而在于重新拆分 AI 应用架构:把高频、结构化、可验证的任务交给便宜快速的小模型,把复杂判断交给大模型或人工流程。
从行业角度看,小模型会让 AI 从"云端能力调用"进一步走向"本地智能基础设施"。未来真正有竞争力的 AI 产品,不会只依赖某一个最强模型,而会拥有自己的任务分层、模型路由、评测数据、失败样本闭环和持续优化机制。
对开发者来说,最务实的路线是:先用业务数据做一个小评测集,再同时测试规则系统、小模型和大模型。只有当小模型在真实任务上同时满足质量、延迟、成本和可维护性,它才是一个真正值得上线的选择。
如果您觉得有用,欢迎 点赞、转发、评论、关注。