目录
[1 · 引子](#1 · 引子)
[1 - 1 · 为什么需要高效稳定的排序算法](#1 - 1 · 为什么需要高效稳定的排序算法)
[1 - 2 · 归并排序概览](#1 - 2 · 归并排序概览)
[2 · 核心思想:分而治之](#2 · 核心思想:分而治之)
[2 - 1 · 分治法](#2 - 1 · 分治法)
[2 - 2 · 归并排序如何应用分治法](#2 - 2 · 归并排序如何应用分治法)
[3 · 代码实现(C)](#3 · 代码实现(C))
[4 · 性能分析](#4 · 性能分析)
[4 - 1 · 时间复杂度](#4 - 1 · 时间复杂度)
[4 - 2 · 空间复杂度](#4 - 2 · 空间复杂度)
[4 - 3 · 稳定性](#4 - 3 · 稳定性)
[5 · 非递归实现](#5 · 非递归实现)
[5 - 1 · 思想](#5 - 1 · 思想)
[5 - 2 · 代码实现](#5 - 2 · 代码实现)
1 · 引子
1 - 1 · 为什么需要高效稳定的排序算法
在处理大规模数据集时,排序算法的效率和稳定性至关重要。
-
效率考量 :
最明显的需求是时间复杂度。数据量增大时,时间成本指数级增长;例如,简单排序算法(如冒泡排序)在平均情况下的时间复杂度为
,这对于处理百万级数据非常低效。高效算法的时间复杂度应为
-
稳定性需求 :
某些应用(如排序复合数据表)要求稳定性:即相等元素的顺序在排序后保持不变。非稳定算法(如堆排序)、可能破坏原始顺序,导致数据失真。例如,在数据库中排序客户记录时,稳定性确保同一排序键的记录维持其录入序列。
这自然引出了归并排序------它兼具高效性和稳定性,成为选择排序算法的理想候选。
1 - 2 · 归并排序概览
- 稳定性:由于合并操作比较元素而不改变相等元素的相对位置,所以它是稳定算法。
- 时间复杂度 :在所有情况下(最好、最坏和平均情况)均实现
- 效率优势 :相比于其他
归并排序在处理外部数据(如硬盘数据)时特别有用,因为它通过分治策略管理内存使用。理解这些要素为深入学习排序算法奠定了基础。
2 · 核心思想:分而治之
2 - 1 · 分治法
分治是一种递归式的算法设计策略,核心包含:
-
分(Divide)
将原始规模为n 的问题分解 为 k 个(通常 k≥2)结构相似、规模更小的子问题 ,子问题间相互独立。
例如:在归并排序中,将长度为 n 的数组拆分为两个长度为 n/2 的子数组。
-
治(Conquer)
递归求解子问题 :若子问题规模足够小(如 n=1),则直接求解;否则继续分解。
例如:在归并排序中,当子数组长度为 1 时,默认有序;否则继续递归拆分。
-
合(Combine)
将子问题的解合并 为原问题的解。
例如:归并排序中,将两个已排序的子数组合并为一个有序数组。
2 - 2 · 归并排序如何应用分治法
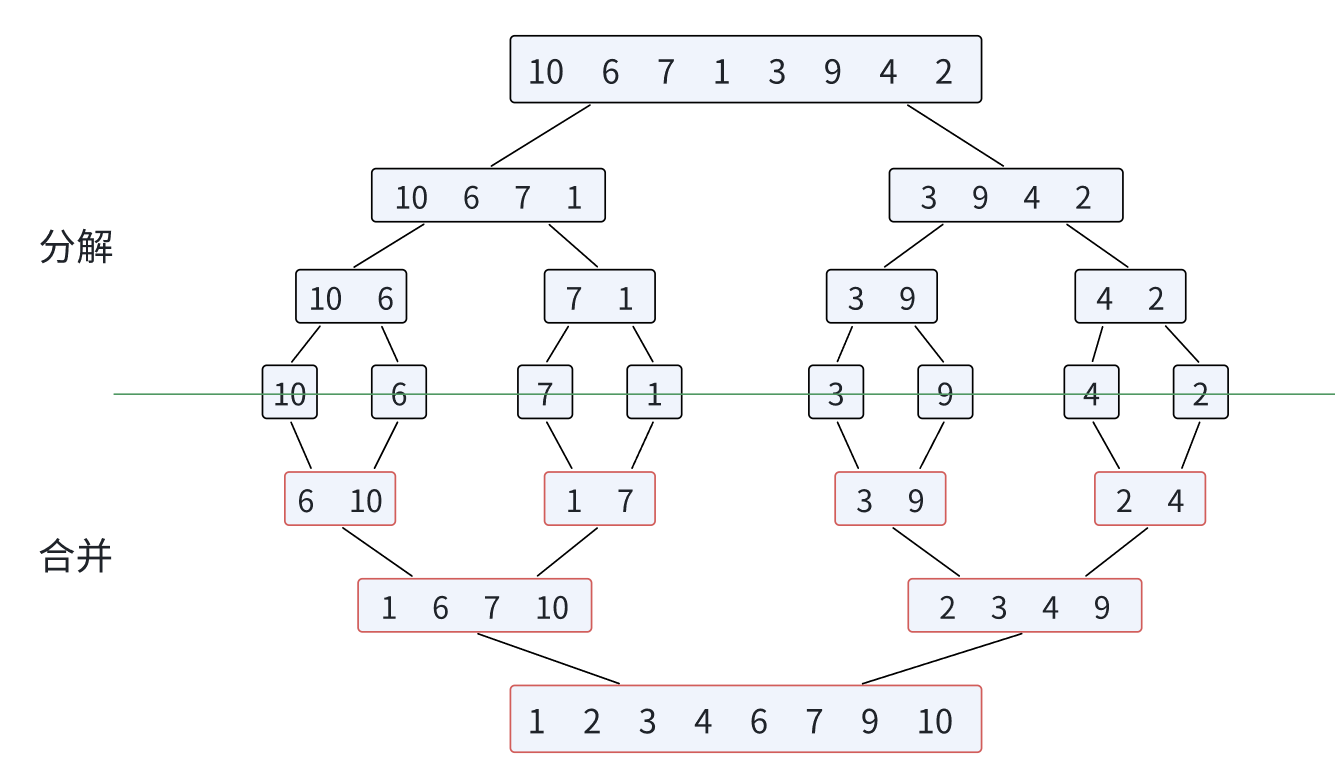
归并排序(MERGE-SORT)是建立在归并操作上的⼀种有效的排序算法,该算法是采用分治法(Divide and Conquer)的⼀个非常典型的应用。将已有序的子序列合并,得到完全有序的序列。
即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成⼀个有序表,称为二路归并。过程如下图:
3 · 代码实现(C)
归并排序必须借助一个第三方数组,如果直接在原数组上操作,会覆盖有效数据。下面实现递归版本的归并排序:
void _MergeSort(int* a, int left, int right, int* tmp)
{
if (left >= right)
{
return;
}
int mid = left + (right - left) / 2;
_MergeSort(a, left, mid, tmp);
_MergeSort(a, mid + 1, right, tmp);
int begin1 = left;
int end1 = mid;
int begin2 = mid + 1;
int end2 = right;
int count = 0;
while (begin1 <= end1 && begin2 <= end2)
{
if (a[begin1] < a[begin2])
{
tmp[count++] = a[begin1];
++begin1;
}
else
{
tmp[count++] = a[begin2];
++begin2;
}
}
//将另一组未完全入进tmp的数据放入tmp中
while (begin1 <= end1)
{
tmp[count++] = a[begin1];
++begin1;
}
while (begin2 <= end2)
{
tmp[count++] = a[begin2];
++begin2;
}
//拷贝回去
for (int i = 0; i < count; i++)
{
a[i + left] = tmp[i];
}
}
void MergeSort(int* a, int n)
{
int* tmp = (int*)malloc(sizeof(int) * n);
if (tmp == NULL)
{
perror("malloc");
exit(1);
}
_MergeSort(a, 0, n-1, tmp);
free(tmp);
}由于递归需要传数组与区间,所以我们递归放在子函数中。
4 · 性能分析
4 - 1 · 时间复杂度
可以想象成一棵二叉树,分割的高度是 logN 层,每层的操作需要处理所有N个元素,因此时间复杂度为
4 - 2 · 空间复杂度
归并排序在合并两个有序数组为一个有序数组时,需要借助额外的存储空间。这是因为合并操作本身需要在其他地方存储数据,然后再将其复制回原数组。这一点很容易理解,而进行递归的深度为 logN,那么归并排序的空间复杂度到底是多少呢?是 O(N) 还是 O(NlogN)?
实际上,归并排序的空间复杂度并不是通过累加递归过程中的空间来计算的。重要的一点是,尽管每次合并操作都需要申请额外的内存空间,但在合并完成之后,这些临时开辟的内存空间就被释放掉了。在任意时刻,CPU 只会有一个函数在执行,也就只会有一个临时的内存空间在使用。临时内存空间最大也不会超过 n 个数据的大小,因此归并排序的空间复杂度是 O(n)。
4 - 3 · 稳定性
是稳定的排序算法。原因:在合并过程中,当相等时,优先复制左区间元素(或右区间元素,但保证一致的策略),就能保留相等元素的原始相对顺序。
5 · 非递归实现
5 - 1 · 思想
实现非递归,一般会想到借助一个数据结构来模拟递归的过程,但是对于归并排序,仅仅借助一个容器来存储,只可以实现分割的过程,不能实现合并的过程,那么就需要两个容器来实现非递归写法。
这时可以想想另一条路,迭代(循环),记录每一次有序表的长度,从1开始,不断更新,进行归并。
5 - 2 · 代码实现
void MergeSortNonR(int* a, int n)
{
int* tmp = (int*)malloc(sizeof(int) * n);
if (tmp == NULL)
{
perror("malloc");
exit(1);
}
//记录有序表长度
int count = 1;
while (count < n)
{
for (int i = 0; i < n; i += 2 * count)
{
int begin1 = i;
int end1 = i + count - 1;
int begin2 = i + count;
int end2 = i + 2 * count - 1;
int k = i;//开始放入tmp的位置
//判断越界
//begin2越界说明后一个有序表越界,此时不动即可
//end1越界同理
if (begin2 >= n)
{
break;
}
//只有end2越界说明后一个有序表部分越界,此时更新end2
if (end2 >= n)
{
end2 = n - 1;
}
while (begin1 <= end1 && begin2 <= end2)
{
if (a[begin1] < a[begin2])
{
tmp[k++] = a[begin1];
++begin1;
}
else
{
tmp[k++] = a[begin2];
++begin2;
}
}
//将另一组未完全入进tmp的数据放入tmp中
while (begin1 <= end1)
{
tmp[k++] = a[begin1];
++begin1;
}
while (begin2 <= end2)
{
tmp[k++] = a[begin2];
++begin2;
}
//拷贝回去
for (int j = i; j < k; j++)
{
a[j] = tmp[j];
}
}
count *= 2;
}
free(tmp);
}**注意:**有些越界的情况是需要分情况讨论的,begin1 永远不会越界,其余的 end1 , begin2 , end2 均可能超出n,对于end1和begin2 超出n的情况,解法相同,此时后一个有序表整体越界,无需归并,直接不动。对于end2 超出n的情况,此时后一个有序表部分越界,仍需归并,这时便需要对end2进行更新。
总结
优点: 归并排序在各种情况下的时间复杂度都保持一致,这使得归并排序在处理大规模数据时效率稳定且高效,尤其在最坏情况下也不会退化为像某些排序算法那样的级别,同时归并排序也是一种稳定的排序算法。归并排序在处理链表结构的数据时特别有效。由于其有序合并的特性,在需要处理无法全部装入内存的庞大数据集时是一种很自然的选择(例如外部排序)。
但缺点也同样致命:虽然归并排序在时间上非常有效,但它相对消耗更多的空间,通常在内部排序中不会使用这种方法,而是选择快速排序。
总结: 归并排序是一种高效、稳定、时间复杂度优秀的算法,非常适合大规模数据处理,尤其是链表数据排序和外部排序。
以上内容如有错误或不准确之处,欢迎指出,或者你有更好的想法,也欢迎交流。