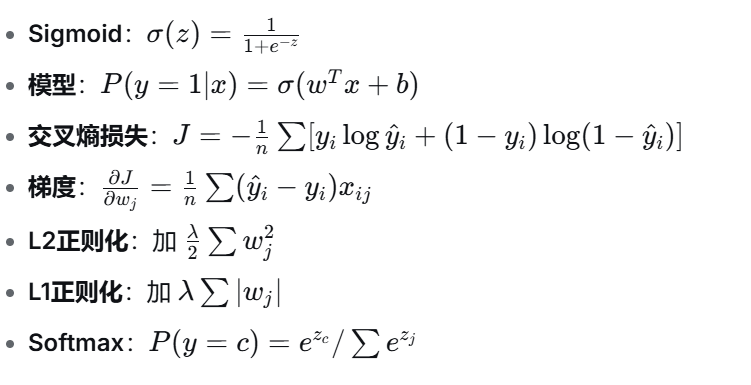核心问题:如何用回归的思路解决分类问题?
逻辑回归虽然名字里有"回归",但它是一种分类算法,尤其擅长二分类(如是否欺诈、是否患病)。
一、为什么不能用线性回归做分类?
1.1 线性回归的输出范围问题
-
线性回归:
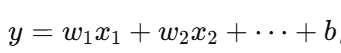 ,输出范围是 (−∞,+∞)。
,输出范围是 (−∞,+∞)。 -
分类问题需要输出概率,范围应该在 0,1 之间。
-
直接用线性回归,预测结果可能大于1或小于0,没有概率意义。
1.2 解决方案:套上一个"压缩函数"
我们需要一个函数,能把线性回归的输出(任意实数)映射到 (0,1)区间。
这个函数就是 Sigmoid 函数(也叫逻辑斯蒂函数)。
逻辑斯蒂回归 = 线性回归 + Sigmoid 函数
二、Sigmoid 函数(核心)
2.1 公式与图像
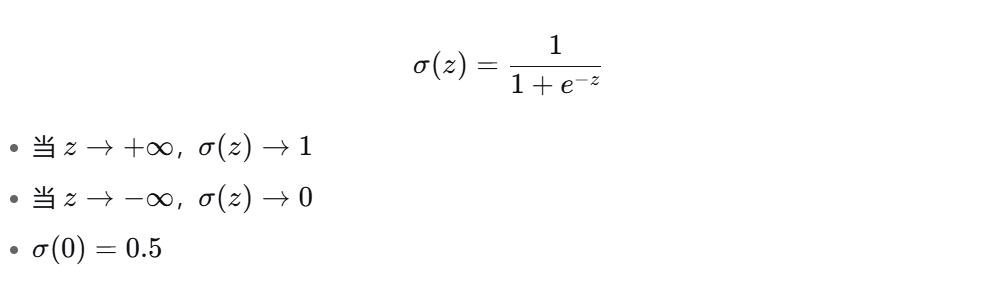
形状:S 形曲线,关于点 (0, 0.5) 中心对称。
2.2 导数性质(重要)
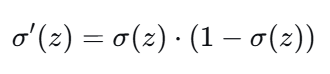
这个性质在梯度下降推导中非常有用。
2.3 为什么用它?
-
输出天然是概率值
-
光滑可导,适合梯度下降优化
-
在 z=0附近变化最敏感,远离0时趋于饱和
三、逻辑斯蒂回归模型定义(二分类)
3.1 模型表达式
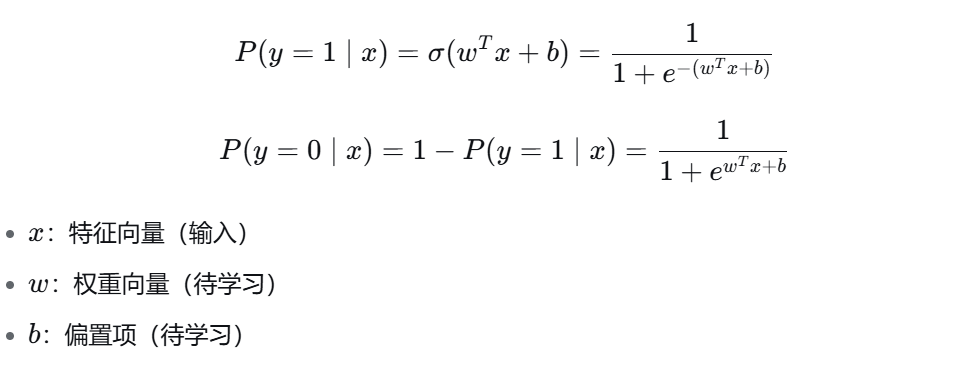
3.2 对数几率(Logit)
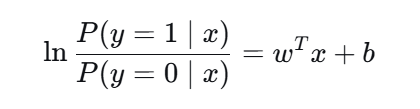
左边是"正类概率 / 负类概率"的对数,称为对数几率(log-odds) 。
这揭示了逻辑回归的本质:对数几率是输入特征的线性函数。
3.3 预测规则

四、如何学习参数 w 和 b?------ 最大似然估计


五、梯度下降求解
5.1 梯度公式

5.2 参数更新(梯度下降)
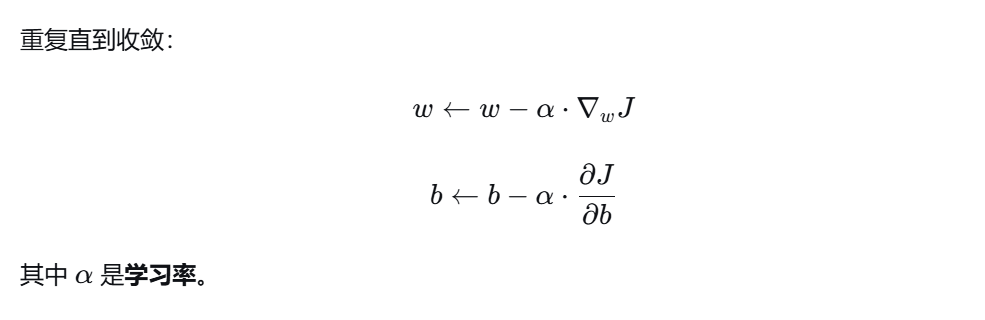

5.3 学习率的选择
| 学习率 | 表现 | 问题 |
|---|---|---|
| 过小 | 收敛极慢 | 训练时间长 |
| 适中 | 稳定收敛 | --- |
| 过大 | 震荡甚至发散 | 无法收敛 |
常用策略:学习率衰减、自适应优化器(Adam、RMSprop)。
六、决策边界
6.1 线性决策边界
由预测规则 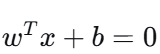 决定。
决定。
在二维空间中是一条直线,在高维空间中是一个超平面。
例子:0.5x1+0.8x2−1=0 是一条直线,一侧预测为 1,另一侧为 0。
6.2 局限性
逻辑回归的决策边界始终是线性的。如果数据本身是非线性可分的(如圆形、螺旋形),原始逻辑回归无法正确分类。
6.3 如何实现非线性决策边界?

七、模型评估(分类标准指标)
7.1 混淆矩阵
| 真实\预测 | 正类 (1) | 负类 (0) |
|---|---|---|
| 正类 (1) | TP | FN |
| 负类 (0) | FP | TN |

7.2 核心指标
-
准确率 (Accuracy) = (TP+TN) / 总样本 ------ 整体正确率,但易受不平衡数据影响。
-
精确率 (Precision) = TP / (TP+FP) ------ 预测为正的样本中实际为正的比例。
-
召回率 (Recall) = TP / (TP+FN) ------ 实际为正的样本中被找出的比例。
-
F1 分数 = 2 × (精确率×召回率) / (精确率+召回率) ------ 两者的调和平均。
-
ROC 曲线与 AUC:
-
ROC 横轴 FPR = FP/(FP+TN),纵轴 TPR = TP/(TP+FN)
-
AUC 是 ROC 曲线下面积,值越大模型排序能力越强,且对不平衡数据鲁棒。
-
详情可参考前一章《ROC曲线与AUC手动计算》。
八、正则化(防止过拟合)
8.1 为什么需要正则化?
逻辑回归中,如果特征很多或数据线性可分,权重会变得非常大,导致模型对输入微小变化极其敏感(过拟合)。正则化通过对权重施加惩罚,控制模型复杂度。
8.2 L1 与 L2 正则化

带有正则化的损失函数:
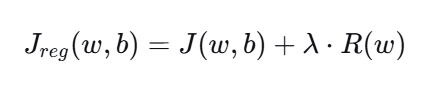
8.3 参数 C(scikit-learn 中的用法)
sklearn 中使用 C 而不是 λ,关系为 C=1/λ:
-
C 很大 → 正则化弱 → 模型复杂 → 可能过拟合
-
C 很小 → 正则化强 → 模型简单 → 可能欠拟合
实践中通过交叉验证(LogisticRegressionCV)选择最优 C。
九、多分类扩展
9.1 一对其他(One-vs-Rest, OvR)
-
对 k 个类别训练 k 个二分类器。第 i 个分类器将类别 i 作为正类,其余所有类别作为负类。
-
预测时,选择概率最高的分类器对应的类别。
-
优点:只需 k 个分类器。
-
缺点:训练集不平衡(负类样本远多于正类)。
9.2 一对一(One-vs-One, OvO)
-
对每对类别训练一个二分类器,共 k(k−1)/2 个。
-
预测时,所有分类器投票,得票最多的类别获胜。
-
优点:每个分类器训练数据少,边界更精细。
-
缺点:分类器数量随 k 平方增长,存储和预测开销大。
9.3 Softmax 回归(多类别逻辑回归)

sklearn 逻辑回归默认使用 OvR,可通过
multi_class='multinomial'切换为 Softmax。
十、Python 实战(鸢尾花分类)
10.1 基本代码
python
from sklearn.datasets import load_iris
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report, confusion_matrix
# 加载数据
iris = load_iris()
X, y = iris.data, iris.target # 三分类
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=42, stratify=y
)
# 创建模型(Softmax 多分类)
model = LogisticRegression(multi_class='multinomial', solver='lbfgs', max_iter=200)
model.fit(X_train, y_train)
# 预测与评估
y_pred = model.predict(X_test)
print("准确率:", model.score(X_test, y_test))
print(confusion_matrix(y_test, y_pred))
print(classification_report(y_test, y_pred))10.2 重要参数说明
| 参数 | 说明 | 常用值 |
|---|---|---|
penalty |
正则化类型 | 'l2'(默认)、'l1'、'elasticnet' |
C |
正则化强度的倒数 | 正浮点数,默认 1.0,越小正则化越强 |
solver |
优化算法 | 'lbfgs'(小数据)、'liblinear'(大数据)、'saga'(支持 L1) |
multi_class |
多分类策略 | 'ovr'(默认)、'multinomial'(Softmax) |
max_iter |
最大迭代次数 | 默认 100,复杂问题需增大 |
class_weight |
类别权重 | 'balanced' 自动平衡,或手动指定 |
十一、逻辑回归的优缺点总结
优点
-
简单、高效、训练速度快
-
输出具有概率意义,可解释性强(权重直接反映特征影响方向和大小)
-
配合正则化不容易过拟合
-
支持在线学习(增量更新)
缺点
-
决策边界是线性的,对非线性数据需要手动做特征工程
-
对异常值敏感
-
特征之间存在多重共线性时,系数估计不稳定
-
对类别不平衡数据敏感(需用
class_weight或采样方法)
十二、核心公式速记卡