
文章目录
- [一、为什么最早 Transformer 有 Encoder 和 Decoder?](#一、为什么最早 Transformer 有 Encoder 和 Decoder?)
- [二、GPT 为什么把 Encoder 删了?](#二、GPT 为什么把 Encoder 删了?)
- [三、那 GPT 怎么"理解"用户输入?](#三、那 GPT 怎么“理解”用户输入?)
- [四、GPT 的 Decoder 到底在干什么?](#四、GPT 的 Decoder 到底在干什么?)
- [五、那为什么还叫 Decoder?](#五、那为什么还叫 Decoder?)
- [六、Encoder 和 Decoder 最大区别](#六、Encoder 和 Decoder 最大区别)
- [七、BERT 为什么是 Encoder-only?](#七、BERT 为什么是 Encoder-only?)
- [八、为什么 GPT 成功了?](#八、为什么 GPT 成功了?)
- [九、为什么 Decoder-only 反而统一了 AI](#九、为什么 Decoder-only 反而统一了 AI)
- 十、形象理解(小学生版)
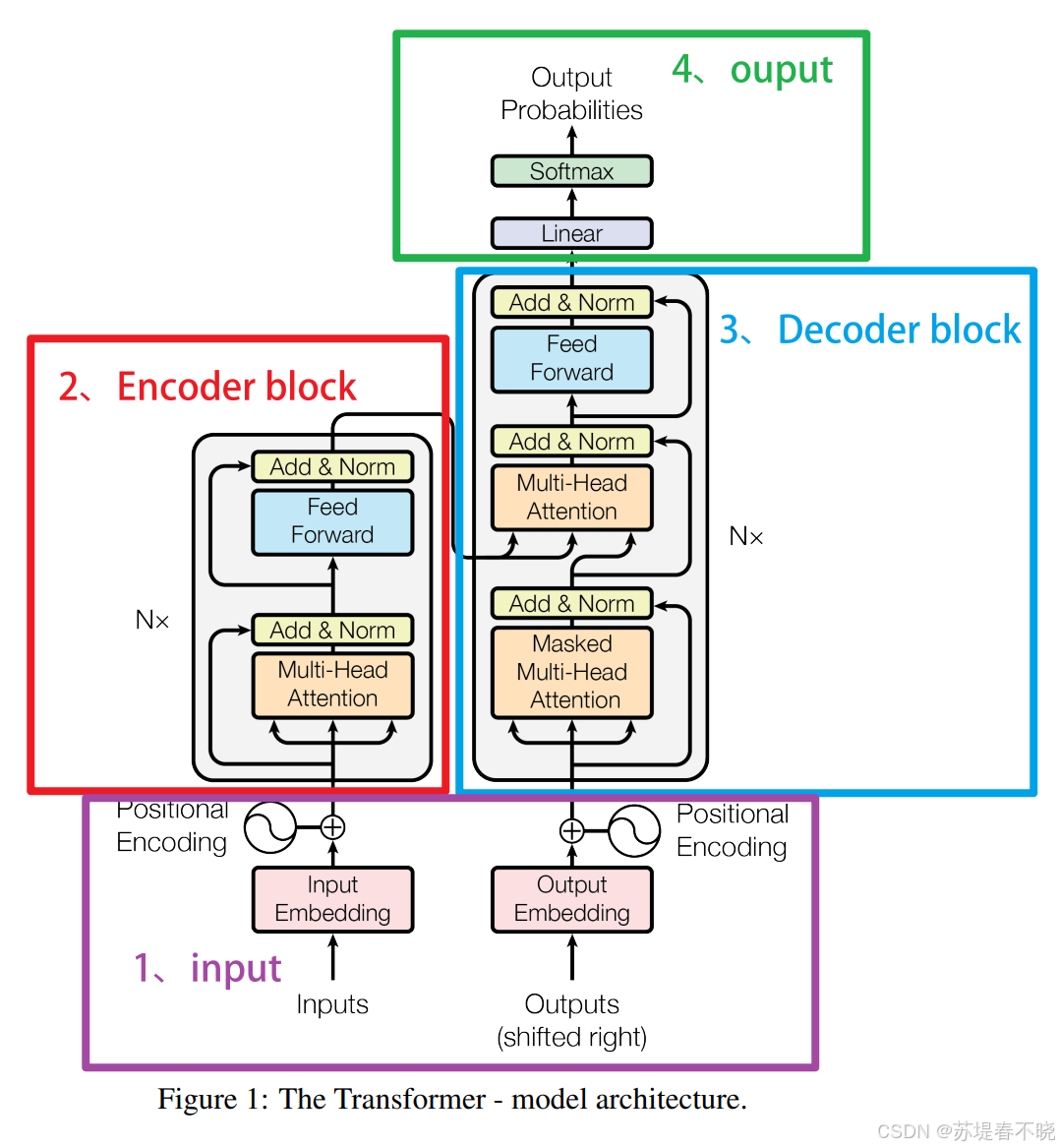
严格来说:
ChatGPT(GPT 系列)是"只有 Decoder"的 Transformer。
没有 Encoder。
这是它和传统 Transformer 最大区别之一。
先给一句最核心的话:
Transformer 原版:Encoder + Decoder
最早是做:
"机器翻译"
比如:
- 输入英文(Encoder 理解)
- 输出中文(Decoder 生成)
论文:Attention Is All You Need
但 GPT 把 Encoder 整个删掉了
只保留:Decoder Stack
所以:GPT = Decoder-Only Transformer
一、为什么最早 Transformer 有 Encoder 和 Decoder?

先形象理解。
(1)Encoder 干什么?
负责: "读懂输入"
比如:
输入:
"I love cats"
Encoder 会:
- 理解语义
- 建立上下文关系
- 输出一堆 hidden states
相当于:"阅读理解老师"
(2)Decoder 干什么?
负责:"一个字一个字往后写"
比如:
输出:
"我喜欢猫"
它会:
- 看 Encoder 理解结果
- 再一步步生成
相当于:"写作文老师"
原始 Transformer 结构
大概:
text
输入句子
↓
Encoder
↓
语义表示
↓
Decoder
↓
生成输出二、GPT 为什么把 Encoder 删了?

因为 GPT 的目标不是:"翻译"
而是:"续写"
核心任务:
text
给前文 → 预测下一个 token例如:
text
今天天气很 →预测:
text
好然后继续:
text
适合 →继续预测。
于是发现:根本不需要 Encoder。
因为:输入本身就是"已经生成过的文本"。
GPT 实际干的事情
text
已有文本
↓
Decoder
↓
预测下一个 token没了。
三、那 GPT 怎么"理解"用户输入?

很多人会疑惑:
"没有 Encoder,GPT 怎么理解问题?"
关键点来了:
Decoder 本身也能理解。
因为:
Transformer Decoder 不是"纯生成器"
它里面也有:Self-Attention
四、GPT 的 Decoder 到底在干什么?

实际上:
GPT 的 Decoder:
既负责:
- 理解上下文
- 又负责生成
是一体化的。
它会:对之前所有 token 做 attention
例如:
text
小明打了小红,因为他很生气模型会分析:
- "他"是谁
- "生气"对应谁
这本身就是"理解"。
五、那为什么还叫 Decoder?

因为它有一个关键特征:Masked Self-Attention(因果 Mask)
只能看:前面的 token
不能偷看未来。
例如:
生成:
text
我爱北京天安门预测"京"时:
只能看:
text
我爱北不能看:
text
天安门这就是: Decoder 的核心特征。
六、Encoder 和 Decoder 最大区别

核心:
| 模块 | 能不能看未来 |
|---|---|
| Encoder | 可以 |
| Decoder | 不可以 |
Encoder 是"双向理解"
比如:
text
苹果很好吃"苹果"可以同时看:
- 前面
- 后面
所以理解能力强。
Decoder 是"单向预测"
只能:
text
左 → 右一步步生成。
七、BERT 为什么是 Encoder-only?

因为:BERT 不负责生成。
它主要做:
- 分类
- 理解
- 检索
- NLP 理解任务
所以:只保留 Encoder。
于是:三大流派
(1)Encoder-only
代表:
- BERT
特点:
- 擅长理解
- 不擅长生成
(2)Decoder-only
代表:
- GPT
特点:
- 擅长生成
- 也能理解
(3)Encoder-Decoder
代表:
- T5
- BART
特点:
- 输入输出分离
- 翻译/摘要强
八、为什么 GPT 成功了?

因为发现:"只靠预测下一个 token"
规模够大以后:理解能力会自动涌现。
这就是 GPT 最震撼的地方。
九、为什么 Decoder-only 反而统一了 AI

因为它天然适合:"自回归生成"
而很多东西本质都能变成生成:
文本:生成 token
图像:生成 patch/token
音频:生成 waveform token
视频:生成 frame token
所以:Decoder-only 很容易统一多模态。
确实,原来的比喻容易让人误解成:
GPT 只是机械地猜字接龙。
实际上 GPT 在"猜下一句"的过程中学到了语言规律、逻辑关系和世界知识。
可以这样润色:
十、形象理解(小学生版)

Encoder 像什么?
Encoder 像一个认真读书的小朋友:
先把整篇文章从头到尾读完,
理解每一句话的意思,
再回答老师的问题。
例如:
text
今天天气很好,
小明去公园放风筝。Encoder 会先看完整段话,再理解:
text
谁去放风筝?
→ 小明Decoder 像什么?
Decoder 像一个讲故事的小朋友:
每说一句话,
只能看到自己前面已经说过的内容,
然后猜下一句最合理是什么。
例如:
text
从前有一只小猫,
它每天都会......Decoder 会继续往下编:
text
去森林里玩耍。然后再根据前面所有内容继续往下讲。
GPT 为什么厉害?
GPT 在训练时做的事情看起来很简单:
根据前面的内容,预测下一个词。
例如:
text
太阳从东方____预测:
text
升起
text
鱼儿生活在____预测:
text
水里但它读过海量的书籍、网页和代码。
在无数次预测中,它逐渐学会了:
- 语言规律
- 常识知识
- 逻辑推理
- 编程技巧
- 问题解决方法
最终可以这样理解
Encoder:
先读完整本书,再回答问题。
Decoder:
根据已经看到的内容,继续把故事讲下去。
GPT:
通过海量"续写练习",不仅学会了写句子,还学会了理解和运用人类积累的大量知识。