Learning Dual-Arm Push and Grasp Synergy in Dense Clutter
- 文章概括
- ABSTRACT
- [I. 引言](#I. 引言)
- [II. 相关工作](#II. 相关工作)
-
- [A. 目标驱动的物体抓取](#A. 目标驱动的物体抓取)
- [B. 推抓策略](#B. 推抓策略)
- [C. 用于操作任务的强化学习](#C. 用于操作任务的强化学习)
- [III. 方法](#III. 方法)
-
- [A. 系统概述](#A. 系统概述)
- [B. Model Architecture](#B. Model Architecture)
-
- 1)角度-视角网络:
- [2)基于 CNN 的强化学习模型:](#2)基于 CNN 的强化学习模型:)
- [C. Learning Strategy](#C. Learning Strategy)
- [IV. EXPERIMENTS](#IV. EXPERIMENTS)
- [V. 结论](#V. 结论)
文章概括
引用:
bash
@article{wang2025learning,
title={Learning dual-arm push and grasp synergy in dense clutter},
author={Wang, Yongliang and Kasaei, Hamidreza},
journal={IEEE Robotics and Automation Letters},
year={2025},
publisher={IEEE}
}
markup
Wang, Y. and Kasaei, H., 2025. Learning dual-arm push and grasp synergy in dense clutter. IEEE Robotics and Automation Letters.主页: https://sites.google.com/view/pg4da/home
原文: https://arxiv.org/pdf/2412.04052
代码、数据和视频: https://github.com/wyl1253/Learning-Dual-Arm-Push-and-Grasp-Synergy-in-Dense-Clutter
系列文章:
请在 《 《 《文章 》 》 》 专栏中查找
宇宙声明!
引用解析部分属于自我理解补充,如有错误可以评论讨论然后改正!
ABSTRACT
在高度杂乱的环境中进行机器人抓取是很有挑战性的,因为可用的无碰撞抓取机会很少。 非抓取动作可以增加杂乱环境中可行抓取的数量,但大多数研究关注的是单臂操作,而不是双臂操作。 来自单臂系统的策略无法充分利用双臂协同的优势。 我们提出了一种面向目标的分层深度强化学习,Deep Reinforcement Learning,DRL 框架,用于学习双臂推抓协同,以便在高度杂乱环境中抓取物体,并增强机器人的灵巧操作能力。 我们的框架通过一个预训练的深度学习骨干网络和一个新的基于 CNN 的 DRL 模型,将视觉观测映射为动作;该模型使用近端策略优化,Proximal Policy Optimization,PPO 进行训练,从而学习双臂推抓策略。 该骨干网络增强了在高度杂乱环境中的特征映射能力。 本文引入了一种新的基于模糊逻辑的奖励函数,用来加速高效策略的学习。 我们的系统在 Isaac Gym 中开发和训练,然后在仿真环境和真实机器人上进行测试。 实验结果表明,我们的框架能够有效地将视觉数据映射为双臂推抓动作,使双臂系统能够在复杂环境中抓取目标物体。 与其他方法相比,我们的方法能够生成 6 自由度,6-DoF,抓取候选,并支持双臂推动动作,从而模仿人类行为。 结果表明,我们的方法能够在高度杂乱的环境中高效完成任务。 论文主页:https://sites.google.com/view/pg4da/home
索引词------ 强化学习,机器人抓取,双臂操作,灵巧操作。
I. 引言
物体抓取在机器人操作中非常关键,因为它是许多复杂任务的基础。 在许多应用中,机器人需要在杂乱环境中工作;由于空间受限,在这类环境中识别可行且无碰撞的抓取机会是很有挑战性的。 受人类行为的启发,将推动和抓取结合起来,为杂乱环境中的操作提供了一种有效解决方案。 通过将周围物体推开,可以在目标物体周围创造空间,从而使机器人能够成功抓取目标物体。 大多数研究集中于使用单臂机器人来开发操作策略,以复现这种推抓能力。 然而,在高度杂乱的环境中,与双臂机器人相比,单臂机器人通常需要明显更多的动作,才能高效地清理场景中的杂乱物体。
机器人抓取任务通常可以分为两大类:目标无关型任务和面向目标型任务。 对于目标无关型任务,1 使用两个并行的深度强化学习,DRL,网络来均衡地学习策略。 基于 Transformer 和 CNN,2 提出了一种新的推抓检测网络,该网络将抓取网络、基于视觉 Transformer,ViT,的物体位置预测网络,以及推动 Transformer 网络结合在一起。 对于面向目标型任务,3 提出了一种具有高样本效率的面向目标的分层强化学习方法,用于学习在杂乱环境中取出特定物体的推抓策略。 此外,4 使用强化学习,RL,研究了杂乱环境中的面向目标推抓协同问题,并且不依赖物体检测和分割。 5 提出了一种双功能推抓策略,可同时用于目标无关型任务和面向目标型任务。 他们的方法根据任务需求,将推动和抓取结合起来,从而高效地拾取所有物体或特定目标物体。 然而,大多数方法主要关注自上而下的抓取,并且推动动作通常被限制为预先定义好的直线距离。 虽然这些方法在一般杂乱环境中表现良好,但在高度密集杂乱的环境中效果较差。
已有若干研究使用双臂机器人来开发超出推抓范围的操作策略。 例如,6 提出了一种深度卷积循环神经网络,用于从初始场景图像中预测任务与运动规划,TAMP,所需的动作序列。 7 提出了一种由粗到细的框架,将全局规划和局部控制相结合,用于双臂操作可变形线状物体,DLOs,从而实现精确定位和避碰。 8 提出了一种以目标为条件的双动作深度模仿学习,DIL,方法,用于从人类示范中学习灵巧操作技能。 类似地,9 开发了一种用于双臂系统闭链操作的深度强化学习,DRL,框架。 10 提出了一套用于双臂任务与运动规划,TAMP,的流程。 虽然这些研究关注双臂运动规划和操作,但它们没有解决面向灵巧操作的自监督学习问题。
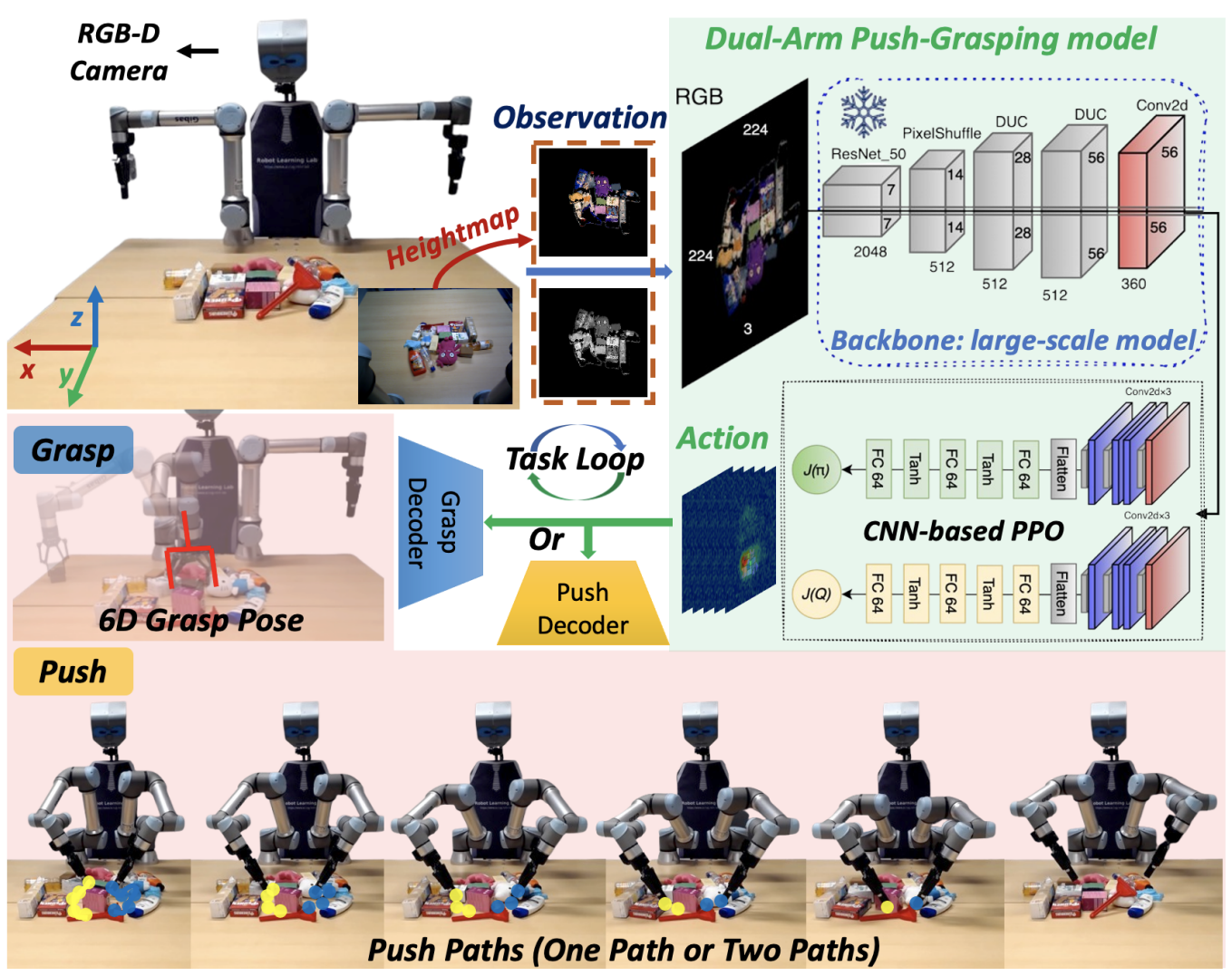 图 1: 一个面向目标的抓取任务示例,其中机器人旨在从高度杂乱的环境中抓取一个绿色物体。 目标物体周围的紧密堆叠要求推动动作和抓取动作之间进行协同配合。 我们的系统将 RGBD 图像映射为动作,根据当前状态决定执行推动还是抓取,并规划合适的推动动作,双路径或单路径,以便在执行稳定的 6 自由度,6-DoF,抓取之前,将目标物体从周围杂乱物体中分离出来,从而完成任务。
图 1: 一个面向目标的抓取任务示例,其中机器人旨在从高度杂乱的环境中抓取一个绿色物体。 目标物体周围的紧密堆叠要求推动动作和抓取动作之间进行协同配合。 我们的系统将 RGBD 图像映射为动作,根据当前状态决定执行推动还是抓取,并规划合适的推动动作,双路径或单路径,以便在执行稳定的 6 自由度,6-DoF,抓取之前,将目标物体从周围杂乱物体中分离出来,从而完成任务。
在本文中,我们提出了一种用于双臂机器人的自监督深度强化学习,DRL,框架,使其能够在高度杂乱环境中的面向目标任务里,学习协调的推抓动作。 如图 1 所示,我们的模型处理 RGB-D 图像,以生成自适应的双臂推动动作,从而使机器人能够抓取那些原本难以直接抓取的目标物体。 与现有研究不同,我们将双臂系统视为一个学习智能体,并将该任务构建为一个以目标为条件的分层强化学习问题,从零开始训练模型。 我们的框架使用一个大规模深度学习,DL,模型作为多自由度,multi-DoF,抓取的骨干网络,并集成了一个自定义的基于 CNN 的强化学习,RL,模型;该模型使用 PPO 进行训练,用于学习推抓策略。 我们引入了一种新的基于模糊逻辑的奖励函数,以加速高效策略的学习。 我们的系统在 Isaac Gym 中开发和训练,并在仿真环境和真实机器人上进行测试。 在仿真环境和真实环境中的实验表明,我们的系统在面向目标的任务中优于其他方法,能够以更少的步骤实现更高的任务完成率和抓取成功率。 该系统可以从仿真环境无缝迁移到真实世界应用中,而不需要额外的数据采集或微调。 总而言之,本文的贡献如下:
-
我们提出了一种自适应推动动作生成方法,该方法从学习到的特征图中采样,将连通的像素点投影到三维空间中,并使用 Savitzky-Golay 滤波器对三维轨迹进行平滑处理。 与以往较为简单的推动方法不同,我们的方法能够实现灵活的双臂推动动作,包括单路径推动或协同路径推动。
-
我们的模型通过输出 6 自由度,6-DoF,抓取位姿,解决了传统自上而下抓取位姿在推抓任务中的局限性,从而能够在高度杂乱环境中实现更具适应性和更精确的抓取。
-
为了高效学习双臂推抓协同,我们设计了一种模糊奖励函数,通过评估动作有效性以及推动或抓取的适宜性来引导模型学习。
-
为了加速学习,我们在 Isaac Gym 中开发了两个版本的机器人系统:一个是用于训练的版本,该版本使用简化夹爪并且没有运动学约束;另一个是用于测试的完整系统版本,该版本包含机械臂操作器。 我们在仿真的密集杂乱场景和真实世界场景中评估了该框架,并且没有进行微调,验证了其有效性。
II. 相关工作
A. 目标驱动的物体抓取
在过去几十年中,机器人抓取方法已经得到了广泛研究,大体上可以分为基于模型的方法和基于学习的方法 11--14。 根据任务目标,这些方法也可以分为目标无关型方法 15--17 和目标驱动型方法 18, 19。
目标无关型抓取方法使用深度神经网络来学习自上而下的抓取位姿,或者 6 自由度,6-DoF,抓取位姿。 对于自上而下的抓取,20 提出了抓取质量卷积神经网络,Grasp Quality Convolutional Neural Network,GQ-CNN,用于从深度图像中预测抓取成功率;而 14, 21 提出了生成式抓取卷积神经网络,Generative Grasping Convolutional Neural Network,GG-CNN,用于预测每个像素位置上的抓取质量和抓取位姿。 然而,自上而下的抓取位姿会限制复杂任务的执行,因此近期研究开始推动 6-DoF 抓取方法的发展 15, 16。 22 通过 RGB Matters 改进了 7 自由度,7-DoF,检测,并提出了 AnyGrasp,这是一种鲁棒的抓取感知系统 17。 23 通过从完整点云检测器中进行知识蒸馏,增强了单视角 6-DoF 抓取检测能力;而 24 提出了一种 6-DoF 局部抓取生成器,该方法结合了基于网格的策略、高斯编码,以及新的非均匀锚点采样方法。
目标驱动型抓取得到的关注较少,并且需要一个感知模块来识别特定物体。 18 将视觉、语言和动作与以物体为中心的表示相结合,以支持灵活的指令,从而提高样本效率和 sim2real 迁移能力。 19 提出了 Visual-Lingual-Grasp,VL-Grasp,这是一种交互式策略,它整合了语言提示、视觉定位数据集,以及 6-DoF 抓取策略。 一些方法使用抓取式运动辅助的抓取方式,不过大多数方法都假设物体是分散场景中的孤立物体。 在密集杂乱环境中,仅仅依靠抓取动作是不够的。
B. 推抓策略
推动和抓取之间的协同已经被研究用于重新整理杂乱物体,从而实现更有效的抓取 25。 1 提出了 Visual Pushing for Grasping,VPG,这是一种无模型深度强化学习,DRL,框架,通过并行架构学习联合的推抓策略,从而开启了推抓协同研究。 2 提出了一种基于视觉 Transformer 的推动网络,PTNet,并结合交叉密集融合网络,CDFNet,用于精确抓取检测;而 26 提出了一种端到端的推抓方法,该方法使用 EfficientNet-B0 和交叉融合模块。 这些方法都是目标无关型方法。 对于面向目标的推抓任务,27 提出了 GE-Grasp,这是一个具有多样化动作基元和生成器-评估器深度学习,DL,架构的框架,用于在密集杂乱环境中进行抓取,即使存在遮挡也能工作。 类似地,28 提出了 PLOT,该方法使用目标 RGB-D 图像、物体分割、特征匹配以及自监督 Q-learning 来实现高效的目标抓取。 5 使用了一种带有分层强化学习,RL,的双功能网络,同时支持目标无关型任务和面向目标型任务。 29 研究了大规模杂乱环境中的推抓问题,而 30 将推抓方法应用于水下环境。 31 使用变分自编码器,Variational Autoencoder,和 PPO,高效学习针对书本等大型扁平物体的推抓策略。 32 在杂乱环境中联合学习推动和 6 自由度,6-DoF,抓取;而 33 将神经网络预测与树搜索相结合,以高效优化推动动作。 34 开发了一种由强化学习,RL,引导的混合规划器,用于取出被遮挡的物体;而 35 和 36 探索了在杂乱环境中用于稳定多指操作的推抓方法。 然而,这些方法依赖单个机械臂操作器,这限制了它们在密集杂乱环境中的效率,也突出了双臂推抓的价值。
C. 用于操作任务的强化学习
随着强化学习,RL,在机器人操作领域的发展,研究者已经为这些任务开发了多种深度强化学习,DRL,模型 37。 强化学习中的关键挑战包括:如何设计有效的状态-动作表示,以及如何设计奖励机制。 在机器人操作中,深度 Q 学习,Deep Q-learning,DQN,通常用于直接从视觉信息中学习,但在需要复杂动作的任务中,它通常表现不足。 例如,基于 DQN 的推抓方法通常生成简单的推动方向,并且推动长度是固定的,因此在高度杂乱环境中效率较低 1, 3, 38。 大多数研究会提取视觉特征,并将这些特征转换成向量,作为 DRL 模型的状态表示 39, 40。 然而,一种常见做法是为不同的动作基元设计并行网络,这种方法资源消耗较大,并且需要大量参数调节。 因此,开发一种轻量化模型,使其能够直接从视觉线索学习到动作,仍然是一个活跃的研究方向。
总而言之,现有 DRL 模型采用了多种方式从视觉输入中进行学习。 一些方法仅依赖 DQN 来处理视觉信息,而另一些方法则会先预处理视觉数据,提取位姿向量,再将这些向量输入到 RL 模型中来学习动作。 此外,一些方法需要多个模型,或者需要多阶段处理流程。 相比之下,我们的方法简化了这一流程,可以直接从 RGB 图像中学习,而不需要使用并行网络来管理不同的动作基元。
III. 方法
A. 系统概述
目标导向的双臂推抓任务。
也就是桌面上有一堆物体,机器人有两个机械臂,它的目标是把指定目标物体拿起来。 但是目标物体可能被其他物体挡住,所以机器人不能只会抓,还要会:
- 推开障碍物
- 调整目标物体的位置或姿态
- 最后抓取目标物体
所以它叫 push-grasping,推抓协同。
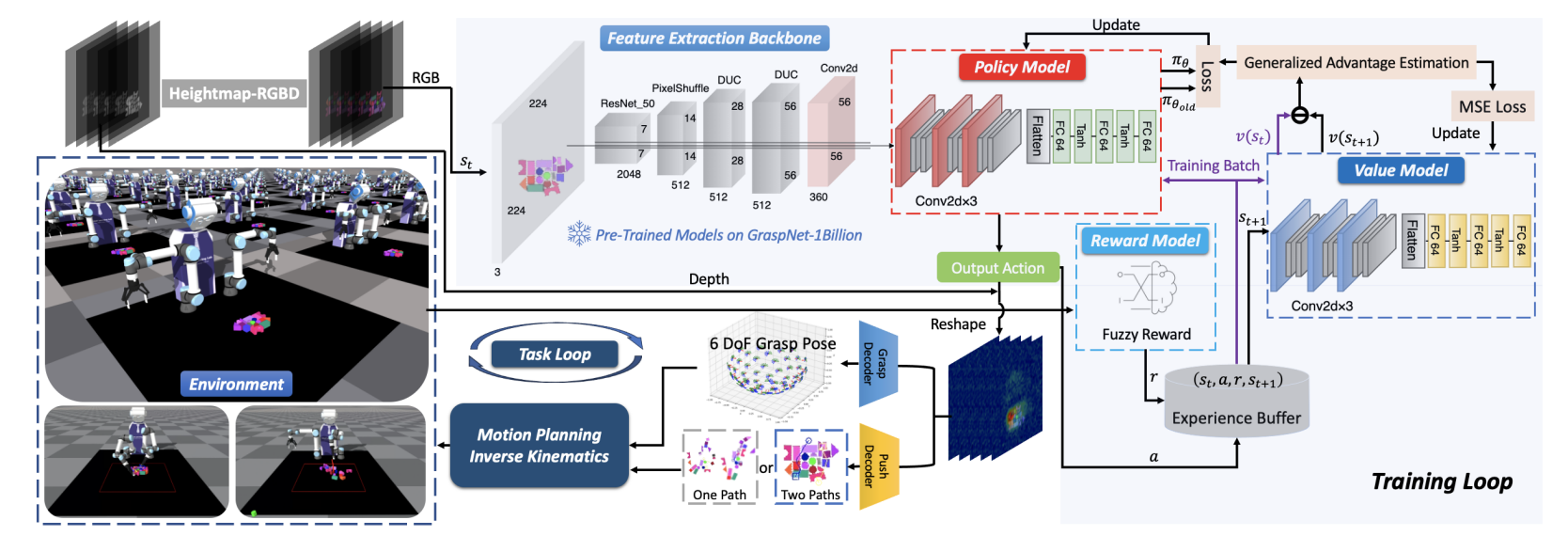 图 2:双臂推抓学习框架概览: 在 Isaac Gym 环境中,目标物体被标记为绿色;与双臂 UR5e 机器人集成的 RGB-D 相机会采集图像,并将其转换为自上而下的高度图。 RGB 图像被输入到一个在 GraspNet-1 Billion 上预训练的抓取网络中,该网络提取特征,并将这些特征输入到一个基于 CNN 的 RL 模型中;该 RL 模型使用 PPO 进行训练。 该模型会生成一个特征图,并由两个运动解码器对其进行解码,从而在环境中生成动作。 一个模糊奖励模块在浅蓝色区域中提供反馈,并引导训练过程。
图 2:双臂推抓学习框架概览: 在 Isaac Gym 环境中,目标物体被标记为绿色;与双臂 UR5e 机器人集成的 RGB-D 相机会采集图像,并将其转换为自上而下的高度图。 RGB 图像被输入到一个在 GraspNet-1 Billion 上预训练的抓取网络中,该网络提取特征,并将这些特征输入到一个基于 CNN 的 RL 模型中;该 RL 模型使用 PPO 进行训练。 该模型会生成一个特征图,并由两个运动解码器对其进行解码,从而在环境中生成动作。 一个模糊奖励模块在浅蓝色区域中提供反馈,并引导训练过程。
我们将面向目标的双臂推抓任务建模为一个目标条件马尔可夫决策过程,Markov Decision Process,MDP,并将其放在分层强化学习框架中,这与先前工作 1, 3, 38 保持一致。 不同于以往主要依赖深度 Q 网络,Deep Q-Networks,DQN 的方法,我们的框架能够直接从视觉输入学习到动作。
"分层强化学习":整个任务被拆成两个层次/两个子任务。
第一层:看图像,理解哪里能抓、夹爪应该朝哪个方向。
第二层:强化学习策略决定具体执行什么动作。
可以理解成:
视觉理解层:看懂场景,提取特征
策略决策层:根据特征决定推还是抓,以及怎么推/抓
所以它不是一个网络从头到尾乱学,而是先让一个视觉骨干网络提取有用信息,再让 RL 模型学习动作策略。
如图 2 所示,双臂机器人上的俯视相机会采集工作空间的 RGB-D 图像。 每个状态 s t s_t st 由彩色高度图 c t c_t ct 和深度高度图 d t d_t dt 表示,这些高度图是通过沿重力轴投影 RGB-D 图像生成的。
彩色高度图 c t c_t ct: 从上往下看的 RGB 图
深度高度图 d t d_t dt: 从上往下看的高度/深度信息
这种设置使智能体能够直接从原始视觉数据中学习面向目标的行为。 双臂推抓任务被表述为一个分层强化学习问题,并被分解为两个子任务。 首先,角度-视角网络,Angle-View Network,AVN,骨干网络处理 RGB 图像,用于预测图像中不同位置处的夹爪方向。 其次,我们引入了一个专门的基于 CNN 的强化学习(RL)模型,并使用 PPO 进行训练,用于生成双臂推抓动作。
为什么说它不是 DQN,而是 PPO?
DQN 的特点是: 把动作离散化,然后给每个动作打分。
比如:
位置 1,角度 1:Q = 0.3
位置 2,角度 3:Q = 0.7
位置 5,角度 2:Q = 0.9
然后选 Q 值最高的动作。 但是这篇文章说它使用 PPO。 PPO 是一种策略梯度方法,它不是简单给所有离散动作打 Q 分数,而是直接学习策略:
π θ ( a t ∣ s t ) π_θ(a_t ∣ s_t) πθ(at∣st)
意思是 : 在状态 s t s_t st 下,策略网络输出动作 a t a_t at 的概率或参数。 PPO 的好处是训练比较稳定,适合连续动作或者更复杂的动作空间。
我们的框架使用骨干网络中的 RGB 通道来生成特征图,同时利用深度图像对 RL 模型生成的动作进行细化和筛选,从而增强智能体的决策能力。 不同于当前方法,我们的框架生成的是 6 自由度,6-DoF,抓取候选,而不是自上而下的抓取。 我们学习得到的推动动作也更加自适应,具有灵活的方向和推动长度,从而形成更加多样且高效的策略,并提升双臂操作性能。
整套系统可以这样理解:
- 机器人在 Isaac Gym 里看到当前场景
- 相机获得 RGB-D 图像
- RGB-D 转成高度图
- Backbone 提取视觉特征
- Policy Model 生成动作特征图
- Grasp Decoder / Push Decoder 解码动作
- Motion Planning + IK 执行动作
- 环境发生变化
- Reward Model 给奖励
- 保存经验到 Experience Buffer
- PPO 用这些经验更新 Policy Model 和 Value Model
- 重复训练很多次
B. Model Architecture
1)角度-视角网络:
AVN 网络输入一张 RGB 图像,输出每个位置最适合的夹爪方向。
也就是它要回答:
夹爪应该在哪个位置抓?
夹爪应该从哪个方向靠近?
夹爪自身还要转多少角度?
AVN 用于预测逐像素的夹爪旋转配置。 由于在每个位置上都可能存在多个可用于稳定抓取的有效旋转,因此直接回归旋转矩阵或四元数是不现实的。 受 GraspNet-1Billion 的启发,AVN 将夹爪方向分解为两个部分:接近方向和平面内旋转,并将该任务表述为一个多类别分类问题,以便更好地处理旋转的多样性。 如图 3 所示,从上半球均匀采样 V V V 个接近方向,并采样 A A A 个平面内旋转角,从而形成 V × A V\times A V×A 个不同的方向类别,用于覆盖大量可能的夹爪配置。
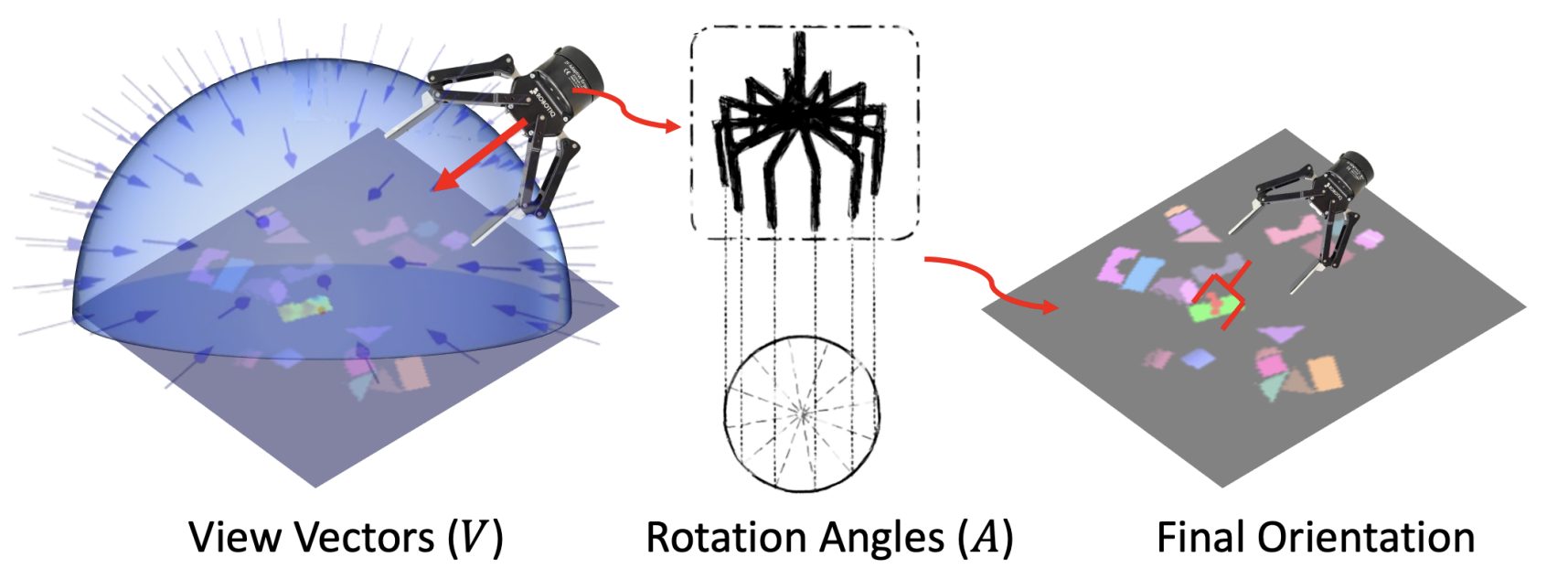 图 3:从角度视角到最终方向: 用于抓取的夹爪方向由一个视角向量和一个平面内旋转角共同决定。 在图的左侧, V V V 个视角向量在上半球上被均匀采样;而在图的中间部分, A A A 个平面内旋转角被采样。 这里, V V V 和 A A A 分别被设置为 60 和 6。 模型输出一个数值,范围为 0 到 359,随后该数值会被解码,用来确定最终的夹爪方向。
图 3:从角度视角到最终方向: 用于抓取的夹爪方向由一个视角向量和一个平面内旋转角共同决定。 在图的左侧, V V V 个视角向量在上半球上被均匀采样;而在图的中间部分, A A A 个平面内旋转角被采样。 这里, V V V 和 A A A 分别被设置为 60 和 6。 模型输出一个数值,范围为 0 到 359,随后该数值会被解码,用来确定最终的夹爪方向。
为了确定整张图像中各个位置的夹爪方向,AVN 将图像划分为大小为 G H × G W G_H\times G_W GH×GW 的网格,其中 G H G_H GH 和 G W G_W GW 分别表示垂直方向和水平方向上的网格单元数量。 对于每个网格单元,AVN 输出一个包含 V × A V\times A V×A 个元素的一维向量,用来表示该网格单元内每个方向类别的置信度分数。 最终输出被称为角度-视角热力图,Angle-View Heatmap,AVH,可以表示为一个三维张量:
A V H ∈ R ( V × A ) × G H × G W (1) \mathbf{AVH}\in\mathbb{R}^{(V\times A)\times G_H\times G_W}\tag{1} AVH∈R(V×A)×GH×GW(1)
AVH 的意思是: 对于图像中每个位置,网络预测 360 种夹爪方向分别有多靠谱。
AVH 的一个示例如图 4 所示。 为了将 RGB 图像映射到 AVH,AVN 使用了编码器-解码器结构。 首先,ResNet50 编码器将输入图像转换为高维特征。 随后,这些高维特征通过一个 pixel-shuffle 层和两个密集上采样卷积,Dense Upsampling Convolution,DUC,层被解码为 AVH,从而重建空间方向信息。 当视角数量和角度数量分别设置为 60 和 6 时,最终的 AVH 张量包含 360 张特征图。
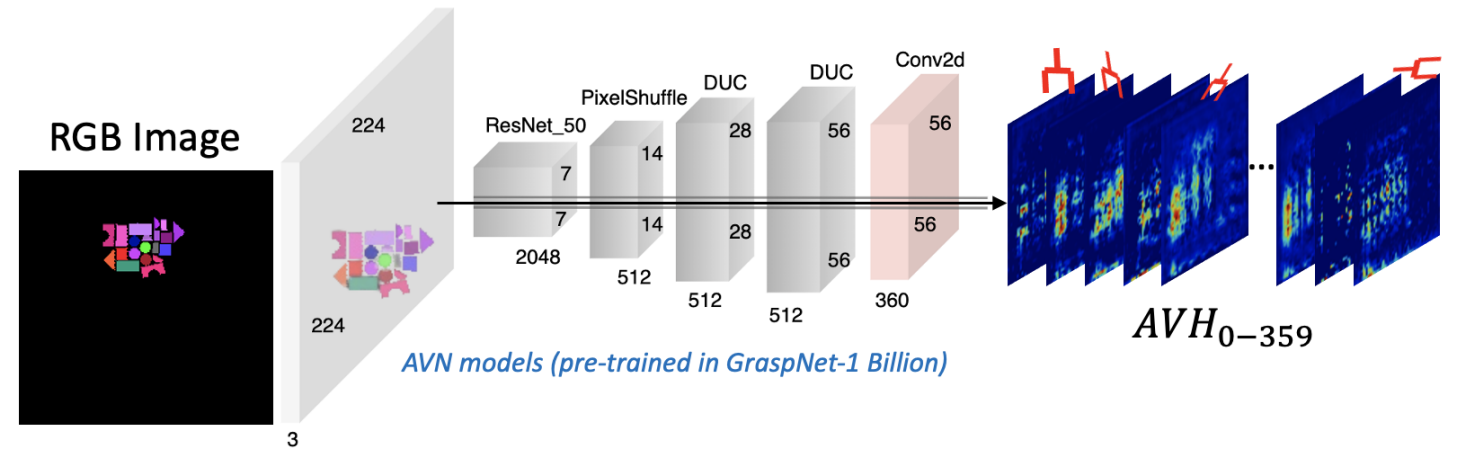 图 4:AVN 的结构: 该网络以 RGB 图像作为输入,先通过 ResNet 提取密集特征,然后使用 pixel shuffle 和 DUC 层进行上采样,最终生成 AVH。
图 4:AVN 的结构: 该网络以 RGB 图像作为输入,先通过 ResNet 提取密集特征,然后使用 pixel shuffle 和 DUC 层进行上采样,最终生成 AVH。
2)基于 CNN 的强化学习模型:
图 2:双臂推抓学习框架概览: 在 Isaac Gym 环境中,目标物体被标记为绿色;与双臂 UR5e 机器人集成的 RGB-D 相机会采集图像,并将其转换为自上而下的高度图。 RGB 图像被输入到一个在 GraspNet-1 Billion 上预训练的抓取网络中,该网络提取特征,并将这些特征输入到一个基于 CNN 的 RL 模型中;该 RL 模型使用 PPO 进行训练。 该模型会生成一个特征图,并由两个运动解码器对其进行解码,从而在环境中生成动作。 一个模糊奖励模块在浅蓝色区域中提供反馈,并引导训练过程。
AVN 将 RGB 图像映射为 AVH;然而,对于我们的双臂推抓任务来说,仅有 AVH 是不够的,因为双臂运动的协调非常复杂。 由于 AVH 是一种视觉表示,因此强化学习部分必须专门设计,以处理灵巧的双臂操作。 不同于以往依赖 DQN、并且需要对 RGB-D 图像进行多次旋转以确定动作方向的方法,这些方法会导致模型复杂且笨重;我们的方法使用一个简化的基于 CNN 的强化学习模型,直接处理 AVN 的输出。 如图 2 所示,在 AVN 完成特征提取之后,这些特征会被输入到我们高效的基于 CNN 的强化学习模型中。
AVN 输出的是 : A V H ∈ R ( V × A ) × G H × G W \mathbf{AVH}\in\mathbb{R}^{(V\times A)\times G_H\times G_W} AVH∈R(V×A)×GH×GW
意思是:
56 × 56 个位置
每个位置有 360 种夹爪方向的置信度
但是 AVH 只是一个视觉特征图,它还不是最终动作。 它只告诉机器人:
这个位置可能适合抓
那个方向可能适合夹爪
但是双臂推抓任务还要决定很多更复杂的东西:
现在应该推还是抓?
用左臂还是右臂?
两个机械臂要不要一起动?
推的起点在哪里?
推的方向是什么?
推多远?
抓取姿态是什么?
动作会不会碰撞?
所以论文说: 仅有 AVH 不够。 因为 AVH 更像是"视觉理解结果",不是完整的"双臂动作决策"。
为什么不用传统 DQN 方法?
论文说以前很多方法依赖 DQN,而且要对 RGB-D 图像进行多次旋转。 这句话的意思是: 以前的方法为了判断不同方向的动作,经常这样做:
把图像旋转 0°
输入网络,预测动作价值
把图像旋转 10°
输入网络,预测动作价值
把图像旋转 20°
输入网络,预测动作价值
......
重复很多次
为什么要旋转图像? 因为机器人动作有方向。 比如推一个物体,可以向左推、向右推、斜着推。 抓一个物体,也有不同夹爪角度。 传统 DQN 不一定直接处理这些方向,所以它通过"旋转图像"来间接枚举动作方向。 问题是:
旋转很多次图像
每次都跑一遍网络
计算量大
模型笨重
训练和推理都慢
而这篇文章的想法是: AVN 已经把方向信息编码进了 AVH 的 360 个通道里,所以不用再反复旋转 RGB-D 图像。 也就是说:
传统方法 :靠旋转图像枚举方向
本文方法:直接在 AVH 的 360 个通道里表示方向
这是一个重要改进。
基于 CNN 的强化学习模型是干什么的?
这个 CNN-based RL Model 就是策略决策模块。 它接收 AVN 输出的 AVH:
输入 :360 × 56 × 56 的 AVH
输出:动作向量 action vector
你可以理解为:
AVN :告诉机器人哪里、哪个方向可能适合抓
CNN-RL 模型:根据这些信息决定最终该做什么动作
所以它的作用是: 把视觉方向热力图转换成机器人可以执行的推抓动作。
策略模型由连续的 3 个主要层组成,首先是一个卷积层,该层将输入大小从 360 × 56 × 56 360\times56\times56 360×56×56 减少到 180 个通道,在保留空间信息的同时降低计算需求。 随后是深度卷积层和逐点卷积层,使模型能够对各个通道进行独立处理,并用更少的参数增强特征提取能力。 最后一个卷积层将输出重新调整回 360 个通道,为动作预测做准备。 随后,一系列 3 个全连接层将这些特征映射为一个动作向量。 在价值模型中,也类似地应用这一卷积序列,以保持一致的特征提取过程。 不过,它的输出会经过全连接层处理,将特征压缩成一个标量,用来表示该状态-动作对的期望奖励。 价值模型为优化策略网络提供了重要反馈。 这些模型共同引导决策过程,从而提升系统在复杂操作任务中的表现。
所以策略网络可以总结成:
AVH: 360 × 56 × 56
↓
Conv2d:降到 180 通道
↓
Depthwise Conv:各通道独立提取空间特征
↓
Pointwise Conv:融合通道信息
↓
Conv2d:恢复到 360 通道
↓
Flatten
↓
3 个 FC 层
↓
Action Vector
它的目标是: 根据 AVH 输出当前最合适的推抓动作。
这段论文其实是在说:
AVN 输出 AVH
但是 AVH 只是视觉方向特征
双臂推抓还需要复杂决策
所以作者设计 CNN-based RL Model
这个模型直接处理 AVH,不再反复旋转 RGB-D 图像
Policy Model 用卷积结构提取 AVH 特征
然后通过 FC 层输出动作向量
Value Model 用类似结构输出一个价值标量
Policy 和 Value 一起用于 PPO 训练
最终让机器人学会复杂双臂推抓
你可以把整个结构想象成:
AVN :生成一张"哪里能抓、哪个方向能抓"的地图
Policy Model :看这张地图后决定下一步怎么做
Value Model :判断当前局面和动作选择值不值
PPO:根据奖励不断更新 Policy Model 和 Value Model
C. Learning Strategy
1)状态
当前状态 s t s_t st
\quad ↓
策略网络选择动作 a t a_t at
\quad ↓
机器人执行推或抓
\quad ↓
环境变化
\quad ↓
得到下一个状态 s t + 1 s_{t+1} st+1
学习智能体的状态由杂乱环境中的视觉信息定义,并表示为一张 3 通道 RGB 图像。 在我们的框架中,这张图像作为 MDP(马尔可夫决策过程) 的观测,其尺寸为 224 × 224 224\times224 224×224 像素。 因此,时间步 t t t 时的状态 s t s_t st 可以表示为:
s t = RGB ∈ R 3 × 224 × 224 (2) s_t=\text{RGB}\in\mathbb{R}^{3\times224\times224}\tag{2} st=RGB∈R3×224×224(2)
2)动作
网络输出的"动作"不是机器人马上能执行的真实动作,而是一个中间表示。 它先输出两个东西: a t = f map , v AVH a_t=f_\\text{map},v_\\text{AVH} at=fmap,vAVH
然后再通过两个解码器变成真实动作:
网络输出的中间动作表示
\quad ↓
Grasp Decoder 抓取解码器 或 Push Decoder 推动解码器
\quad ↓
真实机器人动作
\quad ↓
运动规划 + 逆运动学
\quad ↓
机械臂执行
所以重点是: Policy Model 输出的不是直接的机械臂轨迹,而是给解码器使用的动作特征。
模型的动作向量被描述为特征图与排序后的 AVH 索引的组合,其中 AVH 索引根据预测分数进行排序。 动作输出 a t a_t at 的表示可以定义为:
a t = f map , v AVH ∈ R 56 × 56 + 360 (3) a_t=f_\\text{map},v_\\text{AVH}\in\mathbb{R}^{56\times56+360}\tag{3} at=fmap,vAVH∈R56×56+360(3)
其中, f map f_\text{map} fmap 表示由网络处理 RGB 输入后得到的大小为 56 × 56 56\times56 56×56 的特征图,而 v AVH v_\text{AVH} vAVH 表示根据预测分数排序后的 360 个 AVH 索引序列。 然而,这里的动作设计只是为了学习更好的特征图表示,不能直接用于生成机器人运动。 因此,我们实现了两个解码器,用于将输出转换为动作基元。
动作输出由两部分组成:
符号 含义 f map f_\text{map} fmap 一个 56 × 56 56\times56 56×56 的特征图 v AVH v_\text{AVH} vAVH 排序后的 360 个 AVH 方向索引 所以: a t a_t at = 特征图 + 方向排序信息
这里的 a t a_t at 叫动作向量,但它不是最终机器人动作。 它更像是: 网络告诉后续解码器:哪里重要、哪个方向更可能好。
f map f_\text{map} fmap 是一个大小为: 56 × 56 56\times56 56×56 的特征图。 可以把它理解成一张"动作热力图"。 它告诉系统 : 图像中哪些位置更值得关注? 哪里可能适合抓? 哪里可能适合推? 哪里和目标物体有关? 比如特征图上某个位置分数很高,可能表示 : 这个地方可能适合抓取或者这个地方附近需要推动。 所以 f map f_\text{map} fmap 主要负责表达空间位置上的重要性。
上一节讲过 AVH 是: 360 × 56 × 56 360\times56\times56 360×56×56,其中 360 表示 360 种夹爪方向类别。 v AVH v_\text{AVH} vAVH 是把这 360 个方向类别按照预测分数排序后的索引序列。简单说:
网络认为哪个夹爪方向最好?
哪个第二好?
哪个第三好?
......
比如排序后可能是: 127 , 35 , 208 , 14 , . . . , 6 127, 35, 208, 14, ..., 6 127,35,208,14,...,6。意思是:
方向 127 最可能好
方向 35 第二可能好
方向 208 第三可能好
......
所以 v AVH v_\text{AVH} vAVH 主要负责表达方向选择信息。
Policy Model 的输出还要经过解码器,才能变成真实动作。
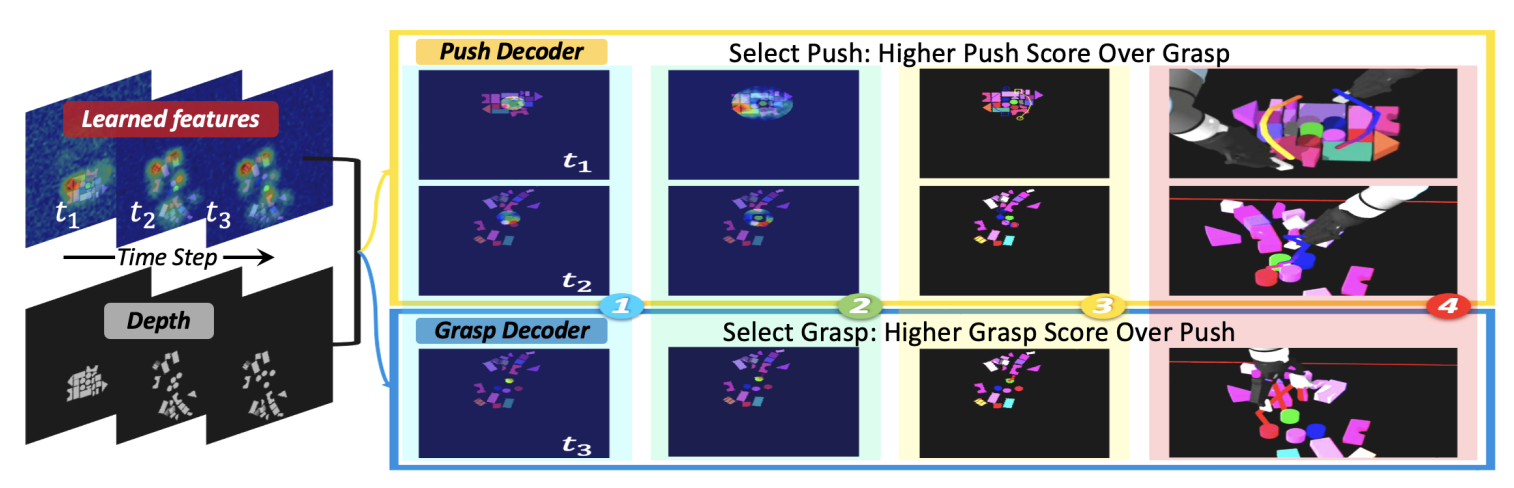 图 5:用于双臂执行的解码器: 解码器将特征图转换为动作,图中展示的是一次试验中的时间步序列。 目标掩码用于生成抓取预测,而扩展后的目标掩码,放大 1.5 倍,用于生成推动分数 ①。 系统会选择分数更高的动作,即抓取或推动。 对于抓取动作,系统使用目标掩码处理后的特征图;对于推动动作,系统会根据最大轮廓半径调整掩码 ②。 抓取过程会提取平移和方向;推动过程则会将关键点连接成路径 ③。 机器人会在完成运动规划和逆运动学求解后执行动作 ④。
图 5:用于双臂执行的解码器: 解码器将特征图转换为动作,图中展示的是一次试验中的时间步序列。 目标掩码用于生成抓取预测,而扩展后的目标掩码,放大 1.5 倍,用于生成推动分数 ①。 系统会选择分数更高的动作,即抓取或推动。 对于抓取动作,系统使用目标掩码处理后的特征图;对于推动动作,系统会根据最大轮廓半径调整掩码 ②。 抓取过程会提取平移和方向;推动过程则会将关键点连接成路径 ③。 机器人会在完成运动规划和逆运动学求解后执行动作 ④。
图 5 左边是网络在不同时间步学到的特征图和深度图。 比如:
t1:当前局面可能需要推
t2:推了一步之后,局面变化
t3:目标更容易抓,于是选择抓
右边分成上下两条路线:
上面黄色框:Push Decoder,推动解码器
下面蓝色框:Grasp Decoder,抓取解码器
图里有两种情况:
如果 push score > grasp score
\quad 系统选择推动
如果 grasp score > push score
\quad 系统选择抓取
所以系统每一步都会比较:
现在推更好?
还是抓更好?
然后选择分数更高的动作。
如图 5 所示,解码器将学习到的特征图转换为可执行的运动。 目标物体掩码用于生成抓取预测图;而扩展后的目标掩码会被放大 1.5 倍,以覆盖目标附近区域,并用于过滤特征图,从而产生推动预测分数。 随后,系统会选择分数最高的动作,也就是抓取或推动。 抓取解码器会计算精确的抓取配置,包括平移和方向。 平移由经过掩码处理的特征图和深度图像得到,而方向则基于第一个 angle-view 值确定,如图 3 所示。 随后,得到的视角值和角度值会被用于计算最终的欧拉角方向。 推动解码器会生成路径,用于在密集杂乱环境中重新排列物体。 当选择推动动作时,系统会计算最大轮廓半径来创建推动掩码,并将该掩码内的关键点连接成一条或两条路径。 这些路径会经过带有平滑处理和深度验证的迭代优化,以确保其空间可行性,随后再使用 Savitzky-Golay 滤波器进行三维平滑。 为了提高可靠性和精确性,方向检查和安全检查会考虑工作空间约束,并且路径规划会确保推动起点避开物体表面,从而实现安全推动。 这种自适应方法优化了推动轨迹,为复杂环境中的双臂操作提供了一个鲁棒框架。 在完成最终运动规划、安全检查和逆运动学求解之后,机器人会执行该动作。
为什么推动要用扩展后的 target mask?
推动不一定直接推目标物体。 很多时候目标物体被障碍物挡住,机器人需要推开目标周围的障碍物。 如果只看目标物体本身,范围太小。 所以作者把目标 mask 放大 1.5 倍。 意思是:
原来的目标区域
\quad ↓ 放大 1.5 倍
覆盖目标附近区域
这样推动解码器不仅能看到目标,还能看到目标周围的障碍物。 所以:
动作 使用的区域 抓取 目标物体本身 推动 目标及其附近区域 这很合理,因为:
抓取关注目标本体
推动关注目标周围障碍物
抓取解码器怎么工作?
抓取解码器要输出一个完整抓取配置。 论文说它包括:
平移 translation
方向 orientation
也就是抓取位姿:
位置:x, y, z
姿态:roll, pitch, yaw
抓取位置怎么来?
论文说:
平移由经过掩码处理的特征图和深度图像得到。
意思是:
先用 target mask 过滤特征图,只保留目标物体区域。 然后在这个区域里找高分位置。
这个位置对应图像中的二维坐标:
x_image, y_image
但是机器人需要三维位置:
x, y, z
所以还要用深度图 Depth 得到高度/深度信息。> 简单理解:
特征图 :告诉你在图像哪里抓
深度图:告诉你这个地方有多高/多深
两者结合,才能得到抓取的三维位置。
抓取方向怎么来?
论文说:
方向则基于第一个 angle-view 值确定。
这里的第一个 angle-view 值,就是排序后的 v AVH v_\text{AVH} vAVH 里面分数最高的方向索引。 比如:
v AVH v_\text{AVH} vAVH 的第一个值 = 127
说明网络认为:
方向类别 127 最适合当前抓取
然后系统把 127 解码成:
一个 view vector + + + 一个 in-plane rotation angle
再把它们组合成最终夹爪姿态。 最后可能转成欧拉角:
roll, pitch, yaw
所以抓取方向的流程是:
AVH 方向索引
\quad ↓
解码成 view vector 和 angle
\quad ↓
组合成夹爪方向
\quad ↓
转换成欧拉角
推动解码器怎么工作?
推动解码器和抓取解码器不一样。
抓取是找一个抓取位姿。
推动是生成一条路径。
也就是:
Grasp Decoder:输出一个抓取点 + 抓取方向
Push Decoder:输出一条推动轨迹
推动动作需要知道:
从哪里开始推?
经过哪些点?
往哪个方向推?
到哪里结束?
什么是最大轮廓半径?
论文说:
当选择推动动作时,系统会计算最大轮廓半径来创建推动掩码。
可以理解为:
系统先找到目标区域或相关物体区域的轮廓,然后估计这个区域大概有多大。 最大轮廓半径就是描述这个轮廓范围大小的量。 它用来决定推动 mask 应该覆盖多大区域。
为什么要这么做?
因为不同物体大小不同,杂乱程度不同。
如果推动 mask 太小:
可能找不到合适推动路径
如果推动 mask 太大:
可能包含太多无关物体,动作不安全
所以用最大轮廓半径来自适应调整推动区域。
什么是关键点连接成路径?
推动路径不是随便画一条线。 系统会先在推动 mask 里面找一些关键点。 这些关键点可能表示:
推动起点
中间经过点
推动终点
然后把这些点连接起来,形成一条轨迹。 简单说:
关键点 → 路径
机器人末端夹爪会沿着这条路径运动,从而推动物体。
整体流程可以写成:
Policy Model 输出 f map f_\text{map} fmap 和 v AVH v_\text{AVH} vAVH
用 target mask 处理 f map f_\text{map} fmap 得到抓取预测分数
用扩大 1.5 倍的 target mask 处理 f map f_\text{map} fmap 得到推动预测分数
比较 grasp score 和 push score
如果 grasp score 更高: Grasp Decoder 生成抓取位置和方向
如果 push score 更高: Push Decoder 生成一条或两条推动路径
使用深度图检查三维可行性
做路径平滑和安全检查
运动规划 + 逆运动学
机器人执行动作
3)奖励
这一节讲的是强化学习里的 reward,奖励函数。
强化学习靠奖励学习。机器人做一个动作以后,环境要告诉它:
这个动作做得好不好?
以后应该多做还是少做?
所以奖励函数就是老师给机器人的打分规则。 在这篇文章里,机器人每一步要决定:
现在应该推?
还是应该抓?
奖励函数就是用来评价这个选择对不对。
我们使用一种基于模糊机制的奖励函数,来引导双臂推动和抓取动作的策略学习。 由于我们的强化学习模型关注的是优化特征表示,因此一致的评估尺度对于公平且有效的学习非常重要。 为此,模糊奖励函数会在每个时间步提供自适应反馈,从而能够对动作进行更细致的评估。 这种方法有助于在统一框架中学习推动动作和抓取动作之间的复杂相互作用,从而增强模型鲁棒性,并加速模型向最优操作策略收敛。
该奖励函数会自适应地评估双臂推抓动作,并根据决策的正确性、动作是否成功,以及目标隔离率等级来分配 0 0 0 到 1 1 1 范围内的奖励;目标隔离率等级包括很高、中等或很低。 对于最优动作,例如在高隔离率下成功抓取,或者在低隔离率下成功推动,系统会分配 1.0 1.0 1.0 的非常好奖励。 正确但未成功的动作会获得 0.5 0.5 0.5 的较好奖励,以鼓励系统即使没有完全成功也继续朝正确方向改进。 在中等隔离率条件下,奖励函数会进行更加细致的评估。 成功动作仍然会获得最高奖励 1.0 1.0 1.0,而未成功动作会获得 0.25 0.25 0.25 的中性奖励,并根据目标隔离率进行调整。 例如,随着目标隔离率升高,未成功的推动动作会受到更重的惩罚,其奖励会接近 0.25 0.25 0.25。 相反,随着目标隔离率升高,未成功的抓取动作会获得更高奖励,因为这反映出其对目标而言是较为正确的选择,不过其奖励仍然低于成功动作。 错误引导的动作,例如在高隔离率下仍然推动,或者在低隔离率下尝试抓取,会被分配 0.0 0.0 0.0 的非常差奖励,以抑制那些不符合预期目标的决策。 这种自适应设计保证了连续评估,并强调决策正确性和动作成功性。 通过将输出保持在 0 0 0 到 1 1 1 的范围内,它可以提供策略性反馈,用于指导决策并提升性能,如图 6 所示。
目标隔离率可以理解为: 目标物体有没有从杂乱物体中暴露出来。 也就是目标是否容易被直接抓取。
这段其实是在说:
双臂推抓任务中,动作好坏不能只用成功/失败判断。
因为推动经常是为了给后续抓取创造条件。
所以作者设计了模糊奖励。
它根据目标隔离率、动作选择是否正确、动作是否成功,给 0 到 1 之间的奖励。
目标暴露时鼓励抓取,目标被遮挡时鼓励推动。
中等情况则根据动作效果进行细致评分。
这样可以让机器人更稳定地学会推抓之间的配合。
举一个完整例子假设桌面上目标物体被一堆东西挡住。 此时目标隔离率低。 机器人有两个选择:
选择 A:直接抓
选择 B:先推开旁边障碍物
奖励函数会认为:
直接抓是不合理的
推动是合理的
所以:
如果机器人推动成功:reward = 1.0
如果机器人推动没成功但方向合理:reward = 0.5
如果机器人硬抓失败:reward = 0.0
再过几步,目标被推出来了。 此时目标隔离率高。 现在奖励逻辑变成:
如果机器人成功抓取:reward = 1.0
如果机器人尝试抓取但失败:仍然给一定奖励
如果机器人继续推动:reward = 0.0 或很低
机器人就会逐渐学到:
目标被挡住时先推
目标暴露出来后再抓
这就是推抓协同。
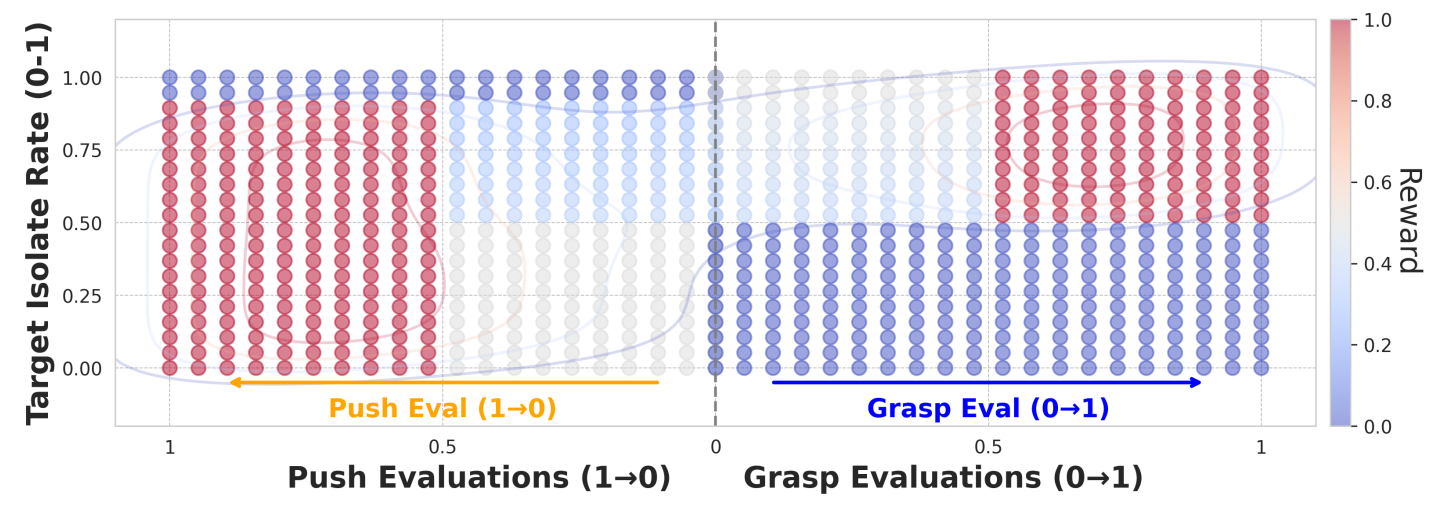 图 6:模糊奖励: 最优动作,例如在高隔离率下成功抓取,以及在低隔离率下成功推动,会获得 1.0 1.0 1.0 的奖励,图中以红色表示。 低奖励动作的奖励接近 0.0 0.0 0.0,图中以蓝色表示,体现了奖励与目标隔离率之间的对应关系。
图 6:模糊奖励: 最优动作,例如在高隔离率下成功抓取,以及在低隔离率下成功推动,会获得 1.0 1.0 1.0 的奖励,图中以红色表示。 低奖励动作的奖励接近 0.0 0.0 0.0,图中以蓝色表示,体现了奖励与目标隔离率之间的对应关系。
4)策略优化
这一节讲的是: 作者怎样训练机器人学会"什么时候推、什么时候抓"。
他们用的是:
一个 PPO 强化学习策略
一个模糊奖励函数
一个 CNN Actor-Critic 网络
最核心一句话是:
作者没有把推动和抓取当成两个完全独立任务来训练,而是用一个统一的 PPO 策略,让机器人把"推"和"抓"学成一个连续协作过程。
我们使用单一 PPO 策略来高效学习双臂推动和抓取动作,并利用模糊奖励函数,见第 III-C3 节,以及基于 CNN 的 Actor-Critic 架构,见图 2。 不同于使用独立奖励函数的现有方法,我们的方法将推动和抓取视为相互关联的任务,因为二者都需要与物体形成稳定接触,并且共享结构性组成部分。 这种统一奖励框架使 RL 模型能够专注于优化用于动作解码的特征图输出,而不是将每一种动作都独立处理。 通过将推动和抓取视为共同影响工作空间的动作,奖励函数会评估动作对整体环境的收益,并为有益动作分配更高奖励。 这种整体式方法使智能体能够将两类动作作为一个组合过程来学习,从而通过单一 PPO 模型实现高效学习,并增强复杂操作任务中推动和抓取之间的协同能力。
什么叫"单一 PPO 策略"?
"单一 PPO 策略"的意思是:
不是一个网络专门学推动,另一个网络专门学抓取,而是一个 PPO 模型同时学习推和抓。
也就是说,机器人每一步都由同一个策略网络决定:
当前应该推?
还是应该抓?
如果推,怎么推?
如果抓,怎么抓?
传统方法可能是:
推动策略网络:专门负责 push
抓取策略网络:专门负责 grasp
而这篇文章是:
一个 PPO 策略:同时负责 push 和 grasp
这就是"单一策略"。
PPO 是一种强化学习优化算法。
它的作用是:
根据奖励不断调整策略网络,让机器人越来越倾向于选择好动作。
流程大概是:
- Actor 根据当前图像特征输出动作
- 机器人执行推动或抓取
- 环境发生变化
- 模糊奖励函数给分
- Critic 估计动作价值
- PPO 根据奖励和价值更新 Actor 和 Critic
所以 PPO 就是训练方法。 它不是机器人结构,也不是相机,也不是解码器。 它负责:
让策略网络通过不断试错变得更聪明
IV. EXPERIMENTS
在本节中,我们描述了在仿真环境和真实世界环境中进行的操作任务的实验设置、评估指标和实验结果。 通过这些实验,我们旨在研究以下问题:
-
与两个并行网络相比,单一策略网络是否能够以更高的数据效率,更好地整合推动动作和抓取动作?
-
由我们策略生成的双臂动作基元是否更加高效,从而能够比单臂机器人更快、更有效地完成任务?
-
该策略是否具有足够的鲁棒性,能够处理各种具有挑战性的场景,包括紧密堆叠、部分遮挡、完全遮挡,以及随机密集杂乱环境?
-
该策略是否能够在不进行微调的情况下迁移到真实机器人上,并且优于现有的推抓基线方法?
A. 实验设置
我们使用 Isaac Gym 物理仿真器训练所提出的系统,并在双臂机器人平台上,在多种杂乱条件下,于仿真环境和真实世界环境中评估其性能。 仿真任务设置和真实世界任务设置如图 7 所示。 所有实验均在一台台式计算机上完成,该计算机配备两块 Nvidia RTX 2080Ti GPU、一颗 Intel i7-9800X CPU,并且每块 GPU 分配 12GB 显存。
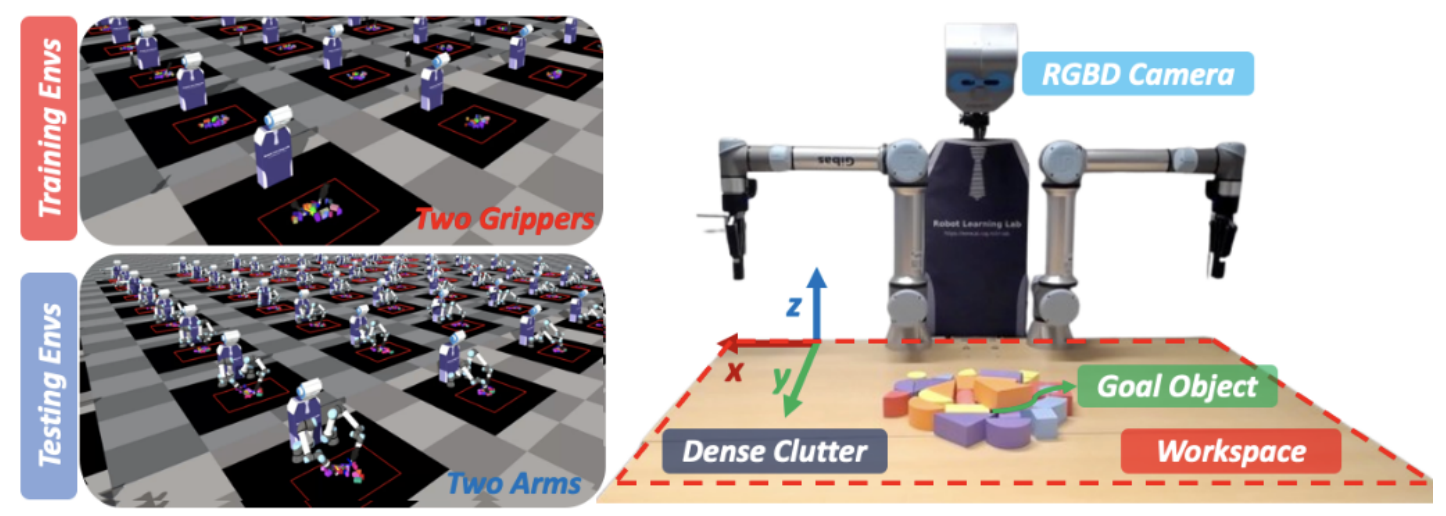 图 7:仿真与真实世界场景: 该策略在 Isaac Gym 的并行环境中进行训练;为了加速训练,训练时使用了一个简化设置,即用两个夹爪代替完整机械臂。 在真实世界测试中,该策略在两台 UR5e 机器人上进行验证,这两台机器人配备 Robotiq 2F-140 夹爪。
图 7:仿真与真实世界场景: 该策略在 Isaac Gym 的并行环境中进行训练;为了加速训练,训练时使用了一个简化设置,即用两个夹爪代替完整机械臂。 在真实世界测试中,该策略在两台 UR5e 机器人上进行验证,这两台机器人配备 Robotiq 2F-140 夹爪。
B. 评估指标
我们通过测试案例来评估这些方法,在这些测试中,机器人需要重新整理密集杂乱的物体,以抓取目标物体。 每个测试在仿真中包含 100 次运行,或在真实机器人上包含 10 次运行;性能通过三个指标进行衡量,这些指标与当前先进方法,state-of-the-art,SOTA,VPG 1、EPG 3 和 SPG 41 中使用的指标相似。 所有方法都使用面向目标的标准进行评估。
-
完成率,Completion Rate,C: 所有测试运行中的平均任务完成百分比。 如果策略成功抓起目标物体,并且没有出现连续 5 次抓取失败的情况,则认为该任务完成。
-
抓取成功率,Grasp Success Rate,GS: 每次完成任务中成功抓取目标物体的平均百分比,用于反映抓取动作的有效性。
-
动作次数,Motion Number,MN: 每次完成任务所需的平均动作次数,用于表示动作效率,尤其反映推动动作的有效性。
C. 仿真实验
Isaac Gym 中的仿真环境,见图 7,通过默认相机设置采集 RGB-D 图像。 机器人以位置控制模式运行,并使用逆运动学将末端执行器的位置转换为关节空间命令。 大小为 1.0 × 1.0 m 1.0\times1.0\text{m} 1.0×1.0m 的工作空间被划分为 224 × 224 224\times224 224×224 的网格,其中每个网格单元对应相机正交图像中的一个像素。
1)训练阶段
训练所用物体如图 8 所示。 对于推抓任务,现有方法通常会将训练阶段分开:先从抓取训练开始,直到达到某个成功率阈值,然后再进入推抓训练阶段。 这些模型通常使用彼此独立的推动模块和抓取模块,因此直接进行推抓联合训练的情况较少。 在这里,我们探究两个问题:我们的模型是否可以直接进行推抓训练,以及分阶段训练是否能够提升性能。 在抓取训练阶段,不需要目标掩码;物体会被随机放置在工作空间中。 对于推抓训练,我们使用简单的杂乱场景,以确保模型能够泛化到更复杂的环境设置中。 我们将本文方法与消融变体进行比较,以研究以下两个问题:1)微调预训练骨干网络是否能够提升性能?2)对推动和抓取进行分阶段训练是否有益?
 图 8:训练场景: 这些场景被分为两类------左侧,绿色,用于抓取训练;右侧,蓝色,用于推抓训练。
图 8:训练场景: 这些场景被分为两类------左侧,绿色,用于抓取训练;右侧,蓝色,用于推抓训练。
a)消融实验
我们的方法采用一个大规模预训练模型作为图像特征提取的骨干网络,为强化学习,RL,模型提供了坚实的基础。 一个主要问题是:对于我们的任务,应该冻结这些预训练权重,还是对它们进行微调。 此外,我们的分层框架的训练策略,尤其是多阶段训练,也需要仔细考虑。 图 9 中的结果表明,在训练过程中冻结骨干网络权重,比更新这些权重表现更好。 此外,两阶段方法,也就是先进行抓取训练,再进行推抓训练,相比单阶段推抓训练能够获得略高的奖励;这表明多阶段训练的收益有限,除非物体差异非常明显,在这种情况下,单独的抓取训练阶段是有优势的。
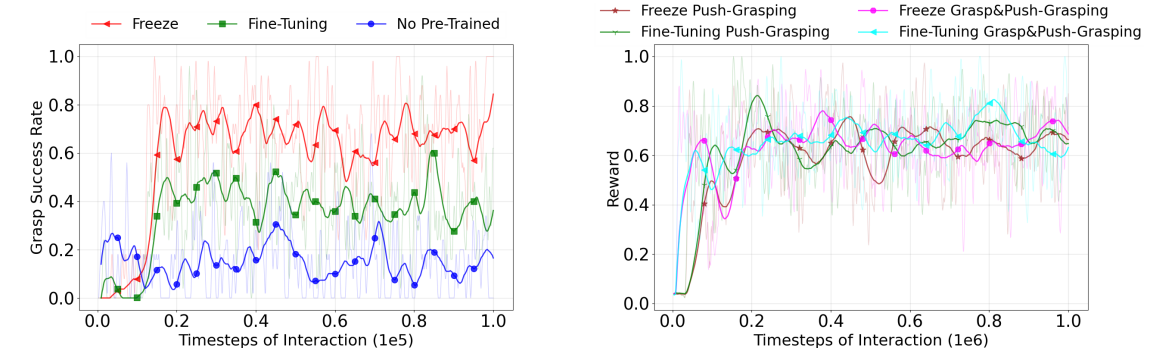 图 9: 用于评估本文方法训练性能的消融实验,旨在分析不同训练配置对学习效果的影响。
图 9: 用于评估本文方法训练性能的消融实验,旨在分析不同训练配置对学习效果的影响。
2)测试阶段
训练完成后,我们部署该模型,用于在杂乱环境中抓取目标物体,其中包括目标被部分遮挡或完全遮挡的挑战性情况。 我们创建了多样化的测试场景,包括积木结构和家用物体,用于评估模型在熟悉物体和新物体上的表现。
a)对比实验
我们将我们的系统与现有基线方法进行了比较。 据我们所知,我们的方法是第一个引入双臂推抓策略的方法;因此,我们将其与当前先进的单臂方法进行基准比较。 我们进行了 5 轮实验,每一轮包含 4 个不同场景。 所有表格数据都表示不同场景上的平均结果;详细指标见补充材料。 虽然我们的方法的单臂版本在一些杂乱场景中表现相当,但在大多数密集杂乱场景中表现不足。 单臂设置和双臂设置的选择会影响场景的变化过程,从而影响任务成功率。
杂乱场景: 在第一轮实验中,使用了 4 个形状不同的物体,构成复杂度逐渐增加的紧密杂乱场景,如图 10 的 Case 1 所示。 如 Table I 的 Case 1 所示,与其他基线方法相比,我们的方法能够以更少的动作次数完成任务,并取得更高的成功率。
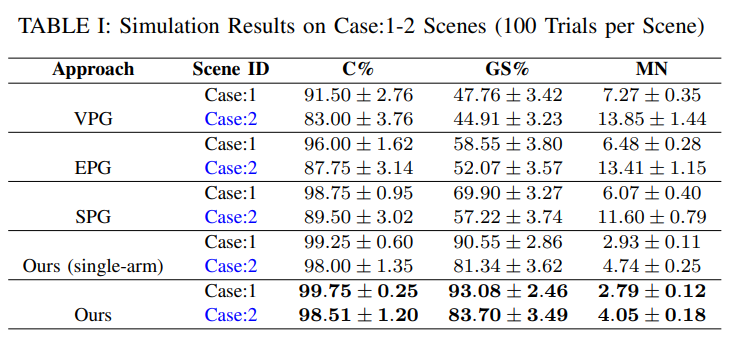
 图 10:仿真对比实验场景: 具有挑战性的仿真实验场景共包含 5 个案例,每个案例由 4 个场景组成,并且每个案例都有一种独特形状的目标物体。 Case 1: 紧密杂乱场景,最多包含 10 个物体;Case 2: 密集杂乱场景,包含 20 个物体;Case 3: 目标物体在密集杂乱环境中被部分遮挡,包含 25 个物体;Case 4: 目标物体在密集杂乱环境中被完全遮挡,包含 30 个物体;Case 5: 目标物体位于随机密集杂乱环境中,包含 35 个物体。 目标物体用绿色标出。
图 10:仿真对比实验场景: 具有挑战性的仿真实验场景共包含 5 个案例,每个案例由 4 个场景组成,并且每个案例都有一种独特形状的目标物体。 Case 1: 紧密杂乱场景,最多包含 10 个物体;Case 2: 密集杂乱场景,包含 20 个物体;Case 3: 目标物体在密集杂乱环境中被部分遮挡,包含 25 个物体;Case 4: 目标物体在密集杂乱环境中被完全遮挡,包含 30 个物体;Case 5: 目标物体位于随机密集杂乱环境中,包含 35 个物体。 目标物体用绿色标出。
密集杂乱场景: 在第二轮实验中,目标物体被 20 个物体包围,形成密集杂乱环境,如图 10 的 Case 2 所示。 Table I 的 Case 2 表明,与其他基线方法相比,我们的方法实现了明显更少的动作次数和更高的成功率。 这种提升并不仅仅来自双臂设置;更重要的是,模型能够有效地从图像中学习关键点,并结合设计良好的动作策略,从而获得最高的抓取成功率。
部分遮挡杂乱场景: 在第三轮实验中,目标物体在一个包含 25 个物体的密集场景中被部分遮挡,如图 10 的 Case 3 所示。 Table II 的 Case 3 表明,尽管物体数量很多,我们的方法仍然保持了较高效率。
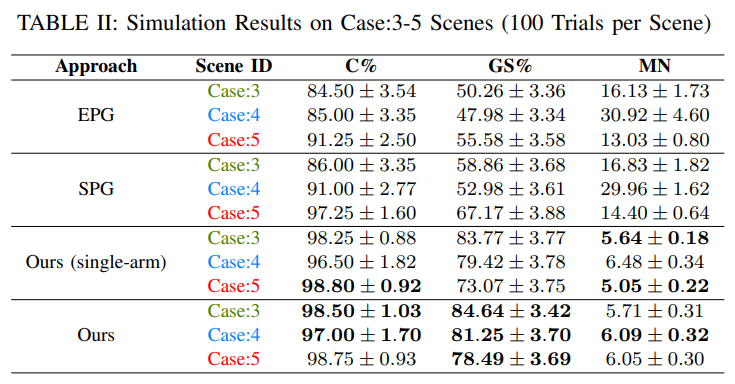
完全遮挡杂乱场景: 在第四轮实验中,目标物体在 30 个物体中被完全遮挡,如图 10 的 Case 4 所示。 Table II 的 Case 4 表明,我们的方法能够以更少的动作次数获得更高的抓取成功率。 不同于那些依赖抓取适宜性阈值的方法,它们通常会在抓取质量较低或边界占用率较高时默认执行推动动作;我们的方法直接从图像中学习决策。 我们的抓取并不局限于自上而下的位姿,这提升了方法在密集杂乱环境中的有效性;同时,我们的推动动作更长且更具适应性,有助于将目标物体分离出来。
随机排列杂乱场景: 在第五轮实验中,35 个物体被随机放置在工作空间中,如图 10 的 Case 5 所示。 Table II 的 Case 5 表明,我们的方法优于其他方法,不过由于物体摆放具有随机性,其性能差距比前几个场景更小。 目标物体可能是可直接接近的,也可能被完全遮挡,但我们的方法仍然保持了较高效率。
D. 真实世界实验
我们在真实世界实验中评估了我们的系统。 实验设置如图 7 所示,系统使用 Asus Xtion 相机采集 RGB-D 图像。 如图 11 所示,我们的测试案例包括 12 个积木场景和 4 个家用物体场景。 对于积木场景,测试包括 4 个密集杂乱场景、4 个目标被部分遮挡的场景,以及 4 个目标被完全遮挡的场景。 对于家用物体,所有 4 个场景都属于密集杂乱场景。 值得注意的是,我们的模型是直接从仿真环境迁移到真实世界中的,并没有重新训练。 Table III 中的结果表明,我们的策略能够有效泛化到真实世界环境,并且能够适应一些未见过的物体。
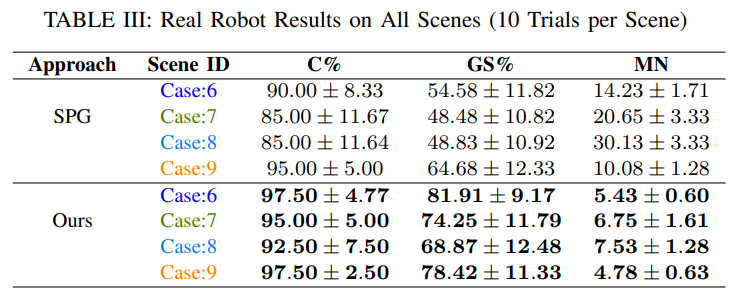
 图 11:真实世界对比实验场景: 具有挑战性的真实世界场景共包含 4 个案例,每个案例包含 4 个场景,并且每个案例都有一种不同形状的目标物体。 Case 6: 密集杂乱场景,包含 20 个物体;Case 7: 目标物体在密集杂乱环境中被部分遮挡,包含 25 个物体;Case 8: 目标物体在密集杂乱环境中被完全遮挡,包含 30 个物体;Case 9: 目标物体在密集杂乱环境中被各种家用物品包围,包含 15 个物体。 目标物体用绿色高亮显示。
图 11:真实世界对比实验场景: 具有挑战性的真实世界场景共包含 4 个案例,每个案例包含 4 个场景,并且每个案例都有一种不同形状的目标物体。 Case 6: 密集杂乱场景,包含 20 个物体;Case 7: 目标物体在密集杂乱环境中被部分遮挡,包含 25 个物体;Case 8: 目标物体在密集杂乱环境中被完全遮挡,包含 30 个物体;Case 9: 目标物体在密集杂乱环境中被各种家用物品包围,包含 15 个物体。 目标物体用绿色高亮显示。
E. 失败案例
物体移出工作空间: 当某个物体离开工作空间时,实验会被判定为失败。 推动路径点不可达: 尽管进行了安全检查,推动路径有时仍然会包含机器人无法到达的点。 抓取不精确: 由抓取位姿误差导致的失败,会造成抓空,或者意外同时抓住多个物体。
V. 结论
在本文中,我们提出了一种基于视觉的双臂推抓方法,用于密集杂乱环境;在这类环境中,抓取目标物体需要先将障碍物推开。 为了高效解决这一任务,我们使用一个大规模抓取模型作为从图像中提取特征的骨干网络,并开发了一个基于 CNN 的 PPO 模型,用于学习最优的双臂推抓策略。 我们在仿真环境和真实世界环境中的多种具有挑战性的场景里,对我们的方法进行了严格评估。 仿真结果表明,我们的方法能够有效训练出一种适应复杂场景的策略,并在随机杂乱和密集杂乱场景中取得较高性能。 训练得到的策略可以在不进行微调的情况下无缝迁移到真实世界应用中,这突出了该策略的鲁棒性和泛化能力。 我们的模型使双臂机器人能够执行协调的推抓动作,从而利用双臂高效处理密集杂乱环境。 在未来工作中,我们计划将该框架扩展到更复杂的场景,并将开放世界抓取与大型视觉语言模型结合起来 42,以推动真实世界自主操作的发展。