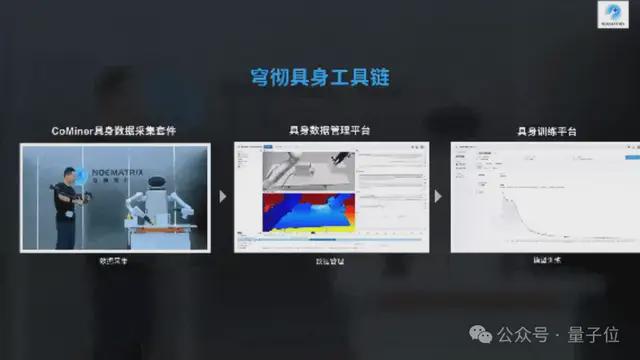
如果问2022年ChatGPT做对了什么,答案出奇一致:Transformer架构加上预训练-后训练的标准化流程。这套范式让语言模型从实验室迅速走向十亿用户,因为它给了所有人一张可复用的"施工图纸"。
但具身智能领域,连图纸长什么样都没达成共识。
在2026北京智源大会上,北京大学长聘副教授卢宗青的判断直击要害:当前具身基础模型的训练范式尚未形成共识。预训练阶段到底该喂给模型场景化数据还是通用化数据?后训练如何保证模型走出实验室后不"水土不服"?这些在大语言模型领域早已标准化的流程,在具身智能这里全是开放性问题。
范式缺失带来的直接后果是:每家公司都在用自己相信的方法"炼丹" 。有的团队押注仿真环境生成合成数据做预训练,再用少量真机数据微调;有的坚持真实世界采集才是唯一正道;还有的试图用世界模型凭空"想象"训练素材。上海创智学院副教授罗剑岚认为"各类数据都不可或缺",但关键问题在于------如何配比、如何衔接,全凭各家自己摸索,没有可复现的基准。
它石智航首席科学家丁文超指出了一个被行业严重低估的指标------数据效率,即单位数据对智能提升的实际贡献。"不能仅将数据输入模型,或在闭环实验中看到模糊的泛化能力,而应系统刻画数据对模型能力提升的贡献。"换言之,Demo里四倍速播放的任务执行只是表面繁荣,真正该追问的是:喂进去的数据,到底让模型变聪明了多少?
更深层的分歧在于架构选择。
端到端模型 试图用一个统一网络打通从感知到控制的全部环节,这更接近通用智能的终极形态,但对数据量和算力的需求堪称天文数字。分层架构则将系统拆分为负责高层决策的"大脑"和负责运动控制的"小脑",更贴近传统机器人技术栈,也更容易在现阶段落地。

但分层架构面临一个棘手难题:大脑和小脑之间的接口如何定义?耦合到什么程度? 如果分层不当,信息传递的损耗反而会造成算力浪费。乐聚机器人创始人冷晓琨点破了问题的本质:"怎么把好的大脑、好的小脑,这两个团队的成果快速融合在一起------这不是技术问题,而是一个行业或产业问题了。"
当连"成功"的标准都无法统一,"ChatGPT时刻"自然沦为模糊的修辞。
这种架构之争背后,折射出具身智能与语言模型的本质差异。语言模型只需处理文本这一个模态,而具身智能必须同时驾驭关节力矩、触觉反馈、空间感知、实时决策------每一个维度对模型架构都提出了不同要求,这才是统一范式迟迟无法诞生的根源。

二、数据之殇:低质数据如何成为模型泛化的致命瓶颈?
如果说统一范式的缺失是具身智能的"心脏病",那么数据质量的参差不齐,则是直接拖垮模型表现的"贫血症"。行业里常拿自动驾驶类比,后者迈向成熟需要百万小时级别的数据积累 ,而具身智能面对的是三维物理世界的复杂交互,数据需求可能达到千万小时级别。然而,现实是残酷的:目前全球真正运行在人类工作场景里的机器人,可能还不到1000台。
"脏数据"与模态缺失:数据金字塔的地基为何难以构建?
数据金字塔的地基,正被"脏数据"和模态缺失严重腐蚀。

银河通用王鹤在圆桌上直言,市面上大量第一人称视角数据依赖开源算法做基础标注后直接售卖,"高质量数据非常少"。卢宗青更是指出,部分供应商连文本标注、动作标注的标准都未统一,甚至反过来向模型公司询问标注方法。这种本末倒置的供给,生产出大量无法复现、传感器不同步的"废数据"。
更深层的问题在于模态的缺失。智源研究院副院长王仲远强调,当前具身智能主要依赖视觉和文本,但触觉、力反馈、温度感知等关键模态尚未被有效利用。这就好比让一个人蒙着眼睛、戴着厚手套去拧螺丝------视觉再清晰,没有触觉反馈,永远掌握不了精密的力度控制。
丁文超由此提出了数据的金字塔结构:底层是价值持续降低的互联网视频和低成本第一视角数据;中间层是包含精确末端动作和触觉信息的数据;塔尖则是高质量遥操作数据。地基若由劣质建材堆砌,塔尖的突破便无从谈起。

数据飞轮悖论:让机器人自主生产高质量数据的理想与现实
面对数据荒,最诱人的设想莫过于构建"数据飞轮":将规模化机器人投放到真实环境,让它们自主交互、采集数据,再反哺模型训练。
智元机器人首席科学家罗剑岚正是这一路径的支持者。但现实是,这陷入了一个经典的**"鸡生蛋"悖论**:要让机器人自主生产高质量数据,需要它先具备足够的泛化能力;而要让它具备泛化能力,又需要海量高质量数据。
它石智航丁文超指出了一个被行业严重低估的关键指标------数据效率 。判断数据是否有效,不能只看数据量,而要系统刻画每类数据对模型能力的具体提升效果。他甚至提出一个尖锐标准:"要看泛化能力是否超过人类,而非关注Demo中四倍速、五倍速执行任务等表面现象。"
这才是飞轮转不动的根本原因。在飞轮启动前,行业必须先回答:什么才是真正有效的数据?答案或许不在于盲目堆量,而在于先建立一套工业级的数据质量评估体系,从源头过滤掉视觉与位姿未对齐、轨迹不可复现的"废数据",让每一份采集成本都转化为实实在在的智能提升。

三、破局之道:在混沌期寻找商业闭环的生存策略
前两部分的剖析,揭示了一个略显残酷的现实:范式未统一,数据质量堪忧。但行业不会因此停摆,在混沌中寻找确定性的生存法则,成为当下最务实的命题。
重新定义成功:从惊艳Demo到70%成功率,真实场景部署有多远?
银河通用创始人王鹤给出了一个具象化到近乎苛刻的定义:具身智能的"ChatGPT时刻",意味着机器人在真实场景中,能以70%到80%的成功率完成人类无需专门学习的技能,并具备良好的可部署性。
这一定义直接刺破了行业泡沫。互联网上充斥着机器人跑酷、空翻的惊艳视频,但这些Demo往往是在受控环境中反复拍摄的"最优解"。它石智航首席科学家丁文超的批判更为尖锐:判断数据是否有效,关键看模型吸收后的泛化效果能否超越人类,而非关注Demo中四倍速、五倍速执行任务的表面现象。
真正的成功不是一次性的表演,而是7×24小时的稳定运行。
智源研究院院长王仲远曾透露,他们采购的某款机器人10台,仅一两个月就坏了5台,硬件稳定性仍停留在科研阶段 。这意味着,从实验室到真实场景的差距是数量级的。王鹤判断,若未来两三年内能力与可部署性取得突破,行业出货量有望在2028年底前后迎来增长,但率先爆发的将是B端场景,而非直接进入C端家庭。

软硬协同深水区:初创企业如何在18个月内跑通首个应用闭环?
范式未收敛的混沌期,比拼的不再是单项技术的炫酷程度,而是软硬协同的系统工程能力。
王鹤提出了一个关键策略:构建技术闭环至关重要 。对于硬件中其他企业难以做好的部分,必须纳入自身技术闭环自主掌控。依赖外部供给,只会拖慢发展节奏。智元机器人首席科学家罗剑岚则给出了更紧迫的时间表:未来半年至18个月内,谁能在有限但非完全封闭的半开放场景中率先跑通首个闭环,将成为决定竞争格局的关键。
这个闭环无需覆盖所有场景,但必须能在真实环境中持续运行、采集数据并优化模型。
丁文超揭示了更深层的系统性问题:许多真正影响机器人执行效果的关键因素,往往隐藏在VLA、世界模型等高端概念背后------末端传感器配置、硬件形态设计、数据采集方式、模型推理效率与吞吐能力等细节,才是决定成败的"魔鬼"。硬件、本体与人类数据需要实现系统化对齐,而非各自为战。当行业从"卖跑跳功能"转向"让数万台机器人自主作业",那些埋头解决底层工程问题的团队,或许比追逐概念的公司走得更远。