很多人刚接触数据库迁移时,都会有个朴素的想法:只要 SQL 能跑通,迁移就算成功了。但在真实的工程落地中,这往往只是第一步。语法跑通只能证明骨架接上了,真正决定迁移成败的,其实是业务语义、底层约束以及那些隐藏在边缘场景里的行为表现。
最近我们在做 MySQL 向金仓数据库 KingbaseES(MySQL 模式)的迁移验证时,就刻意跳出了单纯的"功能清单对比",转而设计了一套针对真实业务交互的测试方案。这里我把完整的测试环境搭建过程、关键的 SQL 实战推演以及踩坑观察记录下来,供大家在做国产数据库迁移选型时参考。
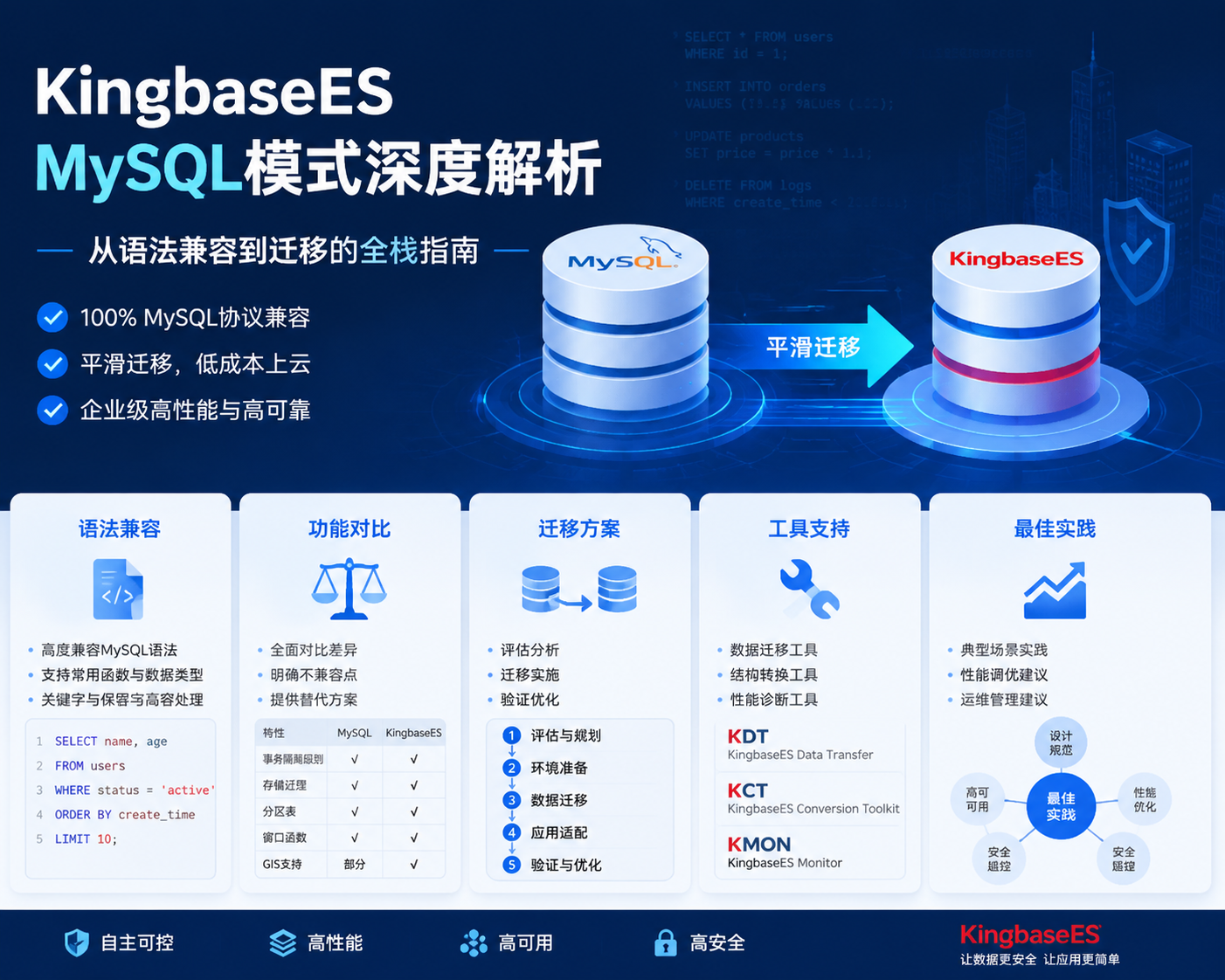
一、测试设计与环境底座搭建
为了最大程度模拟真实的业务压力,我们没有搞复杂的分库分表,而是直接圈定了一个典型的订单交易模型。具体的测试点位如下:
1.基础对象构建:涵盖表结构创建、字段约束、索引设计以及注释落地。
2.核心读写链路:完整覆盖单条与批量的增删改查逻辑。
3.MySQL 特色语法:重点验证 INSERT IGNORE、ON DUPLICATE KEY UPDATE、REPLACE INTO 等高阶语法。
4.复杂逻辑实体:测试触发器、存储过程等自带事务特性的对象。
5.边界场景把控:特意挑选了 BIT、ENUM、SET 这三种极易在迁移中翻车的特殊类型。
为了方便大家直接上手复刻,所有的测试案例都收敛在同一个目标库中。
sql
CREATE DATABASE IF NOT EXISTS kes_tests
CHARACTER SET utf8mb4
COLLATE utf8mb4_general_ci;
USE kes_tests;二、DDL 结构:业务模型的底层映射
在这个阶段,我们不仅要检验 KingbaseES 能否识别 MySQL 风格的关键字,更要看它在应对业务逻辑建模时的表现。以下是订单、用户、商品等核心业务表的落地脚本。
sql
-- 用户基础信息表
CREATE TABLE users (
user_id INT NOT NULL AUTO_INCREMENT COMMENT '用户自增ID',
username VARCHAR(50) NOT NULL COMMENT '业务用户名',
mobile VARCHAR(20) COMMENT '手机号码',
status ENUM('NORMAL', 'LOCKED', 'DISABLED') NOT NULL DEFAULT 'NORMAL' COMMENT '账户状态机',
tags SET('VIP', 'WHITE_LIST', 'RISK_CONTROL') COMMENT '用户多维标签',
created_at DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
updated_at DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
PRIMARY KEY (user_id),
UNIQUE KEY uk_username (username)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='用户基础信息表';
-- 商品信息表
CREATE TABLE products (
product_id INT NOT NULL AUTO_INCREMENT COMMENT '商品ID',
product_name VARCHAR(120) NOT NULL COMMENT '商品名称',
price DECIMAL(10, 2) NOT NULL DEFAULT 0.00 COMMENT '单价',
stock INT NOT NULL DEFAULT 0 COMMENT '库存水位',
is_online BIT(1) NOT NULL DEFAULT b'1' COMMENT '上下架标记',
created_at DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
PRIMARY KEY (product_id),
KEY idx_online_stock (is_online, stock)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='商品信息表';
-- 订单主表
CREATE TABLE orders (
order_id BIGINT NOT NULL AUTO_INCREMENT COMMENT '订单ID',
order_no VARCHAR(32) NOT NULL COMMENT '外部订单号',
user_id INT NOT NULL COMMENT '关联用户ID',
total_amount DECIMAL(12, 2) NOT NULL DEFAULT 0.00 COMMENT '订单总额',
order_status ENUM('CREATED', 'PAID', 'SHIPPED', 'FINISHED', 'CLOSED') NOT NULL DEFAULT 'CREATED' COMMENT '订单流转状态',
created_at DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
updated_at DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
PRIMARY KEY (order_id),
UNIQUE KEY uk_order_no (order_no),
KEY idx_user_status (user_id, order_status)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='订单主表';
-- 订单明细表
CREATE TABLE order_items (
item_id BIGINT NOT NULL AUTO_INCREMENT COMMENT '明细ID',
order_id BIGINT NOT NULL COMMENT '关联订单ID',
product_id INT NOT NULL COMMENT '关联商品ID',
quantity INT NOT NULL COMMENT '下单数量',
item_price DECIMAL(10, 2) NOT NULL COMMENT '快照价格',
subtotal DECIMAL(12, 2) NOT NULL COMMENT '明细小计',
PRIMARY KEY (item_id),
KEY idx_order_id (order_id),
KEY idx_product_id (product_id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='订单明细表';这里有一个容易被忽略的点,KingbaseES 对 ENUM和 SET类型的支持并不是简单的状态代号映射,而是完整保留了字段枚举逻辑。这对存量业务的平滑过渡非常友好,因为这意味着应用层的校验规则基本不需要动。
三、DML 实战:从基础写入到冲突仲裁
我们的测试思路是"先注水,再施压"。先通过一批基础数据初始化业务底座,然后再去验证各种并发写入和冲突场景下的数据库表现。

数据初始化
sql
INSERT INTO users (username, mobile, status, tags) VALUES
('user_zhangsan', '13800010001', 'NORMAL', 'VIP'),
('user_lisi', '13800010002', 'NORMAL', 'VIP,WHITE_LIST'),
('user_wangwu', '13800010003', 'LOCKED', NULL);
INSERT INTO products (product_name, price, stock, is_online) VALUES
('Wireless Bluetooth Headset', 199.00, 150, b'1'),
('USB-C Charging Cable', 39.90, 500, b'1'),
('Laptop Cooling Pad', 129.00, 80, b'0'),
('Mechanical Keyboard', 299.00, 120, b'1');
INSERT INTO orders (order_no, user_id, total_amount, order_status) VALUES
('ORD202605080001', 1, 199.00, 'PAID'),
('ORD202605080002', 1, 39.90, 'CREATED'),
('ORD202605080003', 2, 299.00, 'SHIPPED'),
('ORD202605080004', 3, 328.00, 'FINISHED');
INSERT INTO order_items (order_id, product_id, quantity, item_price, subtotal) VALUES
(1, 1, 1, 199.00, 199.00),
(2, 2, 1, 39.90, 39.90),
(3, 4, 1, 299.00, 299.00),
(4, 1, 1, 199.00, 199.00),
(4, 4, 1, 129.00, 129.00);冲突处理机制的细节验证
这里是一个非常有意思的观察切面。很多时候我们会默认数据库"兼容"某个语法就万事大吉,但实际上不同数据库在处理冲突时的底层策略是有微差的。
1.INSERT IGNORE 的静默拦截 :当我们尝试写入一个已存在的唯一键(如已有的 order_no)时,数据库选择了直接跳过。这就像是给写操作加了一道单向防火墙,保证了当前批次数据的安全,又不阻断整体任务的执行。
sql
INSERT IGNORE INTO orders (order_no, user_id, total_amount)
VALUES ('ORD202605080001', 2, 99.00);
-- 预期行为:由于唯一键冲突,该行被静默忽略,影响行数为 0
SELECT order_id, order_no, total_amount FROM orders WHERE order_no = 'ORD202605080001';2.ON DUPLICATE KEY UPDATE 的状态同步 :这是业务中最常用的"存在即更新"逻辑。在更新订单状态时,它不仅改了目标字段,还顺手更新了 updated_at。这里有一个容易被忽略的硬约束:冲突仲裁的触发基准必须是 PRIMARY KEY 或 UNIQUE INDEX。如果是普通索引冲突,数据库是绝对不会触发后续更新动作的。
sql
INSERT INTO orders (order_no, user_id, total_amount, order_status)
VALUES ('ORD202605080002', 1, 59.90, 'PAID')
ON DUPLICATE KEY UPDATE
total_amount = VALUES(total_amount),
order_status = VALUES(order_status),
updated_at = CURRENT_TIMESTAMP;3.REPLACE INTO 的隐性成本:它看似方便,实则是一招"破坏性重建"。当遇到主键冲突时,它会先物理删除旧记录,再插入新值。
sql
REPLACE INTO orders (order_no, user_id, total_amount)
VALUES ('ORD202605080005', 2, 159.00);如果你有自增组件依赖这条记录的历史 ID,或者外键关联了这张表,用这招就很危险。所以在实际业务中,除非明确不需要保留历史痕迹,否则我更推荐用 ON DUPLICATE KEY UPDATE。
复杂查询与限定更新
在跑批任务或清理历史数据时,我极度依赖 LIMIT子句。它能防止一条糟糕的 SQL 锁死全表。
- 动态维度的组合查询:通过关联用户、商品、订单明细,我们可以轻松拼出业务的全貌画像。
sql
SELECT
o.order_id,
o.order_no,
u.username,
o.total_amount,
o.order_status,
o.created_at
FROM orders o
JOIN users u ON o.user_id = u.user_id
WHERE o.created_at >= '2026-05-01'
ORDER BY o.created_at DESC
LIMIT 10;- 安全可控的局部更新:比如只给前 1 条未支付订单推进状态,或者分批清理 30 天前的脏数据。
sql
UPDATE orders
SET order_status = 'PAID', updated_at = CURRENT_TIMESTAMP
WHERE order_status = 'CREATED'
ORDER BY created_at ASC
LIMIT 1;
DELETE FROM orders
WHERE order_status = 'CLOSED'
ORDER BY created_at ASC
LIMIT 100;虽然官方文档指出多表 DELETE 场景下 ORDER BY 和 LIMIT 的表现会有差异 ,但在单表维护场景中,用 LIMIT 守好最后一道防线是非常实用的工程习惯。
四、复杂逻辑对象:触发器与存储过程
在早些年的架构设计中,我们喜欢把逻辑往数据库里放。现在虽然流行逻辑下沉,但在处理"审计日志"、"积分流水"这类强一致性场景时,触发器依然是最高效的方案。
触发器驱动的行为审计
下面这个触发器的作用,是在订单状态发生翻转的那一瞬间,自动把变更轨迹记录下来。
sql
DROP TRIGGER IF EXISTS trg_orders_status_log;
DELIMITER $$
CREATE TRIGGER trg_orders_status_log
AFTER UPDATE ON orders
FOR EACH ROW
BEGIN
IF OLD.order_status <> NEW.order_status THEN
INSERT INTO order_status_log (
order_id,
old_status,
new_status,
change_time
) VALUES (
OLD.order_id,
OLD.order_status,
NEW.order_status,
NOW()
);
END IF;
END
$$
DELIMITER ;配合之前建的日志表,只要执行一次状态推进,审计数据就会自动落库:
sql
UPDATE orders
SET order_status = 'SHIPPED'
WHERE order_no = 'ORD202605080001'
LIMIT 1;
SELECT log_id, order_id, old_status, new_status, change_time
FROM order_status_log
ORDER BY log_id DESC
LIMIT 5;存储过程的事务编排
对于像"下单扣库存"这种既要写订单又要减库存的操作,必须把逻辑包在一个强事务里。这里我们调用了 DECLARE ... HANDLER来做异常兜底,一旦出错立马回滚,保证数据不会被"悬空"。
sql
DROP PROCEDURE IF EXISTS sp_create_order;
DELIMITER $$
CREATE PROCEDURE sp_create_order(
IN p_order_no VARCHAR(32),
IN p_user_id INT,
IN p_product_id INT,
IN p_quantity INT,
OUT p_order_id BIGINT,
OUT p_result_code INT,
OUT p_result_msg VARCHAR(255)
)
BEGIN
DECLARE v_price DECIMAL(10, 2);
DECLARE v_stock INT;
DECLARE EXIT HANDLER FOR SQLEXCEPTION
BEGIN
ROLLBACK;
SET p_result_code = -1;
SET p_result_msg = 'SQL exception occurred and transaction rolled back';
SET p_order_id = NULL;
END;
SET p_result_code = 0;
SET p_result_msg = 'SUCCESS';
SET p_order_id = NULL;
START TRANSACTION;
SELECT price, stock INTO v_price, v_stock
FROM products
WHERE product_id = p_product_id AND is_online = b'1'
FOR UPDATE;
IF v_price IS NULL THEN
SET p_result_code = 1001;
SET p_result_msg = 'Product does not exist or has been taken offline';
ROLLBACK;
ELSEIF v_stock < p_quantity THEN
SET p_result_code = 1002;
SET p_result_msg = 'Insufficient product inventory';
ROLLBACK;
ELSE
INSERT INTO orders (order_no, user_id, total_amount, order_status)
VALUES (p_order_no, p_user_id, v_price * p_quantity, 'CREATED');
SET p_order_id = LAST_INSERT_ID();
INSERT INTO order_items (
order_id, product_id, quantity, item_price, subtotal
) VALUES (
p_order_id, p_product_id, p_quantity, v_price, v_price * p_quantity
);
UPDATE products
SET stock = stock - p_quantity
WHERE product_id = p_product_id;
COMMIT;
END IF;
END
$$
DELIMITER ;调用一下看看效果:
sql
CALL sp_create_order(
'ORD202606130001',
1,
1,
2,
@out_order_id,
@out_code,
@out_msg
);
SELECT @out_order_id, @out_code, @out_msg;五、特殊类型的真实表现
很多迁移项目在评估阶段顺风顺水,一到灰度测试就掉进数据类型的坑里。我们专门挑了三个高危类型做了压力测试。
- BIT 类型的二元决策 :非常适合存状态、开关。插入时用
b'1'这种位字面量,查询时用BIN()函数解析,整个流程非常顺畅。
sql
INSERT INTO products (product_name, price, stock, is_online) VALUES ('Test Product Alpha', 59.00, 50, b'1');
SELECT product_id, product_name, BIN(is_online) AS bin_flag, is_online FROM products WHERE is_online = b'1' LIMIT 5;- ENUM 类型的状态约束 :没开启严格模式时,写入非法值是会被截断的。但这里有一个致命隐患------不同数据库对这种"非法输入的默认处理机制"可能完全不同。所以千万别凭经验假设它一定会报错,老老实实去跑回归测试才是正解。
sql
INSERT INTO users (username, mobile, status) VALUES ('user_test_enum', '13800019999', 'NORMAL');
SELECT user_id, username, status FROM users WHERE username = 'user_test_enum';- SET 类型的多标签归档 :这种类型在用户分层打标时极其好用。通过
FIND_IN_SET函数,可以精准捞出带有特定标签的人群包。
sql
SELECT user_id, username, tags FROM users WHERE FIND_IN_SET('VIP', tags) > 0;六、写在最后:迁移视角的几点建议
做完这一整套测试,我的体感很明确:KingbaseES 在 MySQL 模式下的兼容,绝不是停留在"能解析 SQL"的浅层模仿。从 DDL 语义到底层的事务反馈,它都在尽力抹平迁移过程中的感知差异。官方资料显示,其在常量、运算符、SELECT/LIMIT、UPDATE/LIMIT 乃至 trigger/procedure 等层面都已具备成熟度 。
如果你的团队正在规划去 MySQL 化,不妨按这个思路走:
-
面向业务建模:直接拿真实的表结构和存储过程去跑,不要只看厂商给的兼容性矩阵。
-
守住边界测试:对于 ENUM 越界、触发器联动、AUTO_INCREMENT 行为,一定要单独拎出来做破坏性验证。
-
盯紧性能波动:当历史数据量突破千万级,或者在复杂 JOIN 场景下,原先在 MySQL 上跑得很好的索引策略,可能需要重新过一遍执行计划。