在介绍各种激活函数之前,先了解人工神经网络的提出背景和工作原理,从而更好地理解激活函数的作用,以及各个激活函数的特点分析。(想直接看激活函数的朋友可以跳过这部分直接到第3部分对常用激活函数的介绍。)
1 激活函数的生物背景
受生物神经系统处理信息的启发,人工神经网络(Artificial neural network1,简写ANN)的概念被提出。
1.1 生物神经网络
生物神经处理系统由数量庞大的神经元组成,这些神经元之间有复杂的连接关系,形成强大的生物神经网络(Biological Neural Networks2,简写BNN)。
生物神经网络中的每个神经元,只处理简单的任务。单个神经元由细胞体(Cell body)、轴突(axion)和树突(dendrite)构成,如图1所示。轴突负责向其它神经元发送信号,树突负责从其它神经元接收信号。图1中红色圈表示两个神经元的连接区域。当神经元通过树突接收到从另一个神经元的轴突传来的信号时,信号在细胞体内累计,当接收的信号超过一定强度时,神经元则通过轴突继续传递信号,若信号太弱,则无法通过该神经元继续传递。
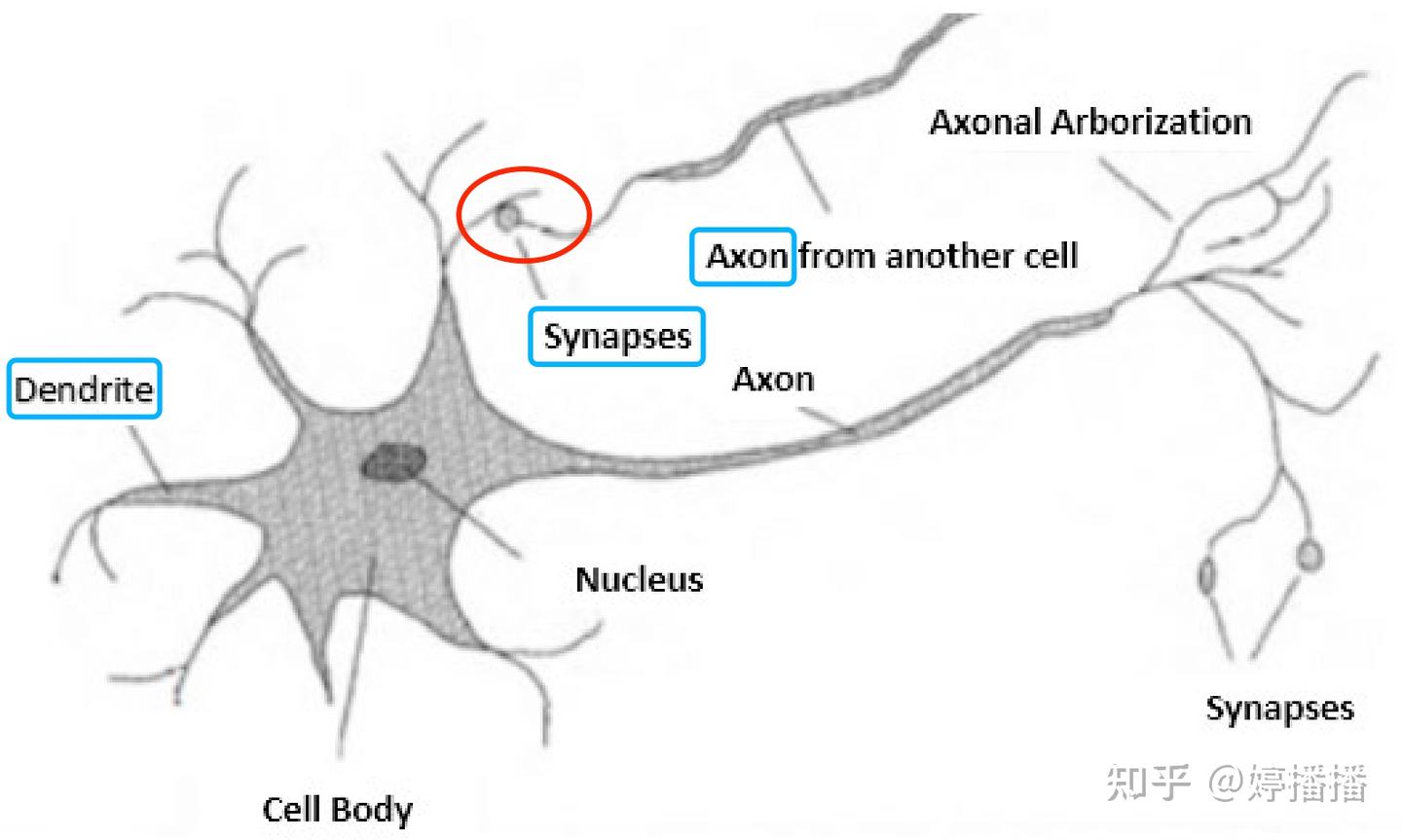
图1 神经元结构
1.2 人工神经网络
ANN类比BNN进行网络结构设计和神经元的计算设计。
1.2.1 网络结构和激活函数
ANN的结构如图2所示,可以包含一层或多层隐层。ANN的网络结构类似BNN,神经元之间相互连接,每个神经元进行简单的计算逻辑。和BNN神经元对信号的处理原理对应,ANN中每个神经元对输入进行加权、求和、激活计算后得到输出。激活计算对应于BNN中神经元对信号的继续传递或者阻断继续传递的处理。激活函数的产生由此而来,用于ANN中神经元的激活逻辑。
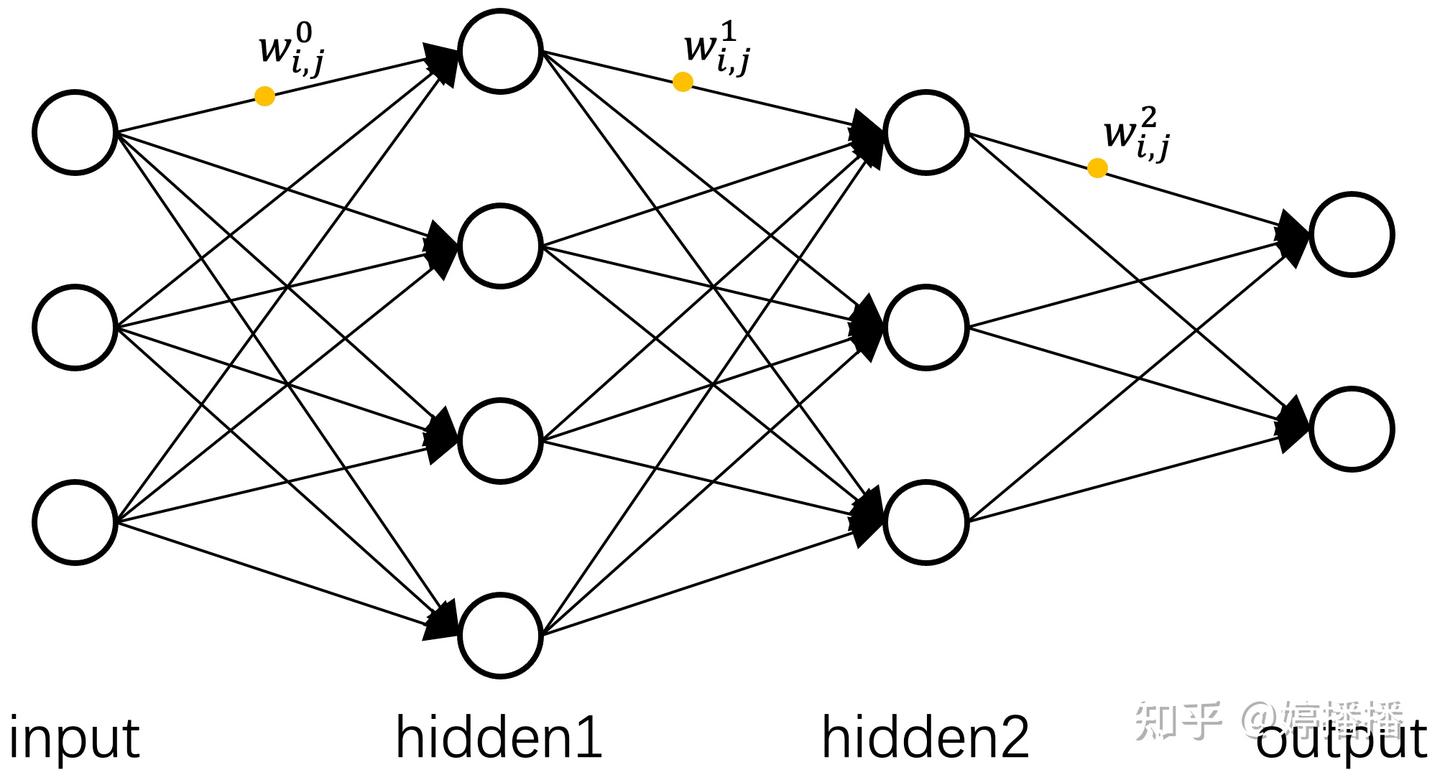
图2 人工神经网络(ANN)结构
1.2.2 网络学习过程
人工神经网络的学习分为两个过程:前向传播(forward propagation,简写为FP)和反向传播(back propagation,简写为BP)。两个过程交替进行,每次FP后进行BP,然后进行下一次FP和BP。
1.2.2.1 前向传播
FP的过程很简单,即输入经过若干隐层处理后得到输出,隐层中每个神经元的计算包括加权求和和激活。式子(1.1)和式子(1.2)分别表示了隐层神经元的加权求和和激活的计算过程。加权求和的输入为与当前神经元相连的上一层神经元的输出,即式子(1.1)中的 y ( i ) \mathbf y^{(i)} y(i) ,加权求和的结果也就是 z ( i + 1 ) \mathbf z^{(i+1)} z(i+1) 再经过激活函数,得到当前层神经元的输出 y ( i + 1 ) \mathbf y^{(i+1)} y(i+1) 。
z ( i + 1 ) = w ( i + 1 ) y ( i ) + b ( i ) y ( i + 1 ) = f ( z ( i + 1 ) ) \begin{align} &\mathbf z^{(i+1)} = \mathbf w^{(i+1)} \mathbf y^{(i)} + \mathbf b^{(i)} \tag{1.1} \\ & \mathbf y^{(i+1)} = f(\mathbf z^{(i+1)} ) \tag{1.2} \end{align} z(i+1)=w(i+1)y(i)+b(i)y(i+1)=f(z(i+1))(1.1)(1.2)
1.2.2.2 反向传播
FP过程中的计算,依赖很多参数,这些参数更新和计算,依赖于BP过程。BP采用梯度下降法对参数进行更新,也就是对FP过程计算出的损失(预测值和真实值的差异),对所有参数求导得到梯度,每个参数用自身的梯度进行更新。参数的梯度计算采用链式法则进行,如式子(2.1)所示,可见损失对w的求导依赖于损失对y的求导,损失对y的求导如式子(2.2)所示。每次BP后参数更新一次,那么下一次FP将采用更新后的参数进行计算。
∂ L ∂ w ( i ) = ∂ L ∂ y ( i ) ∂ y ( i ) ∂ z ( i ) ∂ z ( i ) ∂ w ( i ) = ∂ L ∂ y ( i ) f ′ ( z ( i ) ) y ( i − 1 ) ∂ L ∂ y ( i ) = ∂ L ∂ y ( i + 1 ) ∂ y ( i + 1 ) ∂ z ( i + 1 ) ∂ z ( i + 1 ) ∂ y ( i ) = ∂ L ∂ y ( i + 1 ) f ′ ( z ( i + 1 ) ) w ( i + 1 ) \begin{align} & \frac{\partial{L}}{\partial{\mathbf w^{(i)}}} = \frac{\partial{L}}{\partial{\mathbf y^{(i)}}} \frac{\partial{\mathbf y^{(i)}}}{\partial{\mathbf z^{(i)}}} \frac{\partial{\mathbf z^{(i)}}}{\partial{\mathbf w^{(i)}}} = \frac{\partial{L}}{\partial{\mathbf y^{(i)}}} f^{'}(\mathbf z^{(i)}) \mathbf y^{(i-1)} \tag{2.1} \\ & \frac{\partial{L}}{\partial{\mathbf y^{(i)}}} = \frac{\partial{L}}{\partial{\mathbf y^{(i+1)}}} \frac{\partial{\mathbf y^{(i+1)}}}{\partial{\mathbf z^{(i+1)}}} \frac{\partial{\mathbf z^{(i+1)}}}{\partial{\mathbf y^{(i)}}} = \frac{\partial{L}}{\partial{\mathbf y^{(i+1)}}} f^{'}(\mathbf z^{(i+1)}) \mathbf w^{(i+1)} \tag{2.2} \end{align} ∂w(i)∂L=∂y(i)∂L∂z(i)∂y(i)∂w(i)∂z(i)=∂y(i)∂Lf′(z(i))y(i−1)∂y(i)∂L=∂y(i+1)∂L∂z(i+1)∂y(i+1)∂y(i)∂z(i+1)=∂y(i+1)∂Lf′(z(i+1))w(i+1)(2.1)(2.2)
下面对这两个公式讲解下
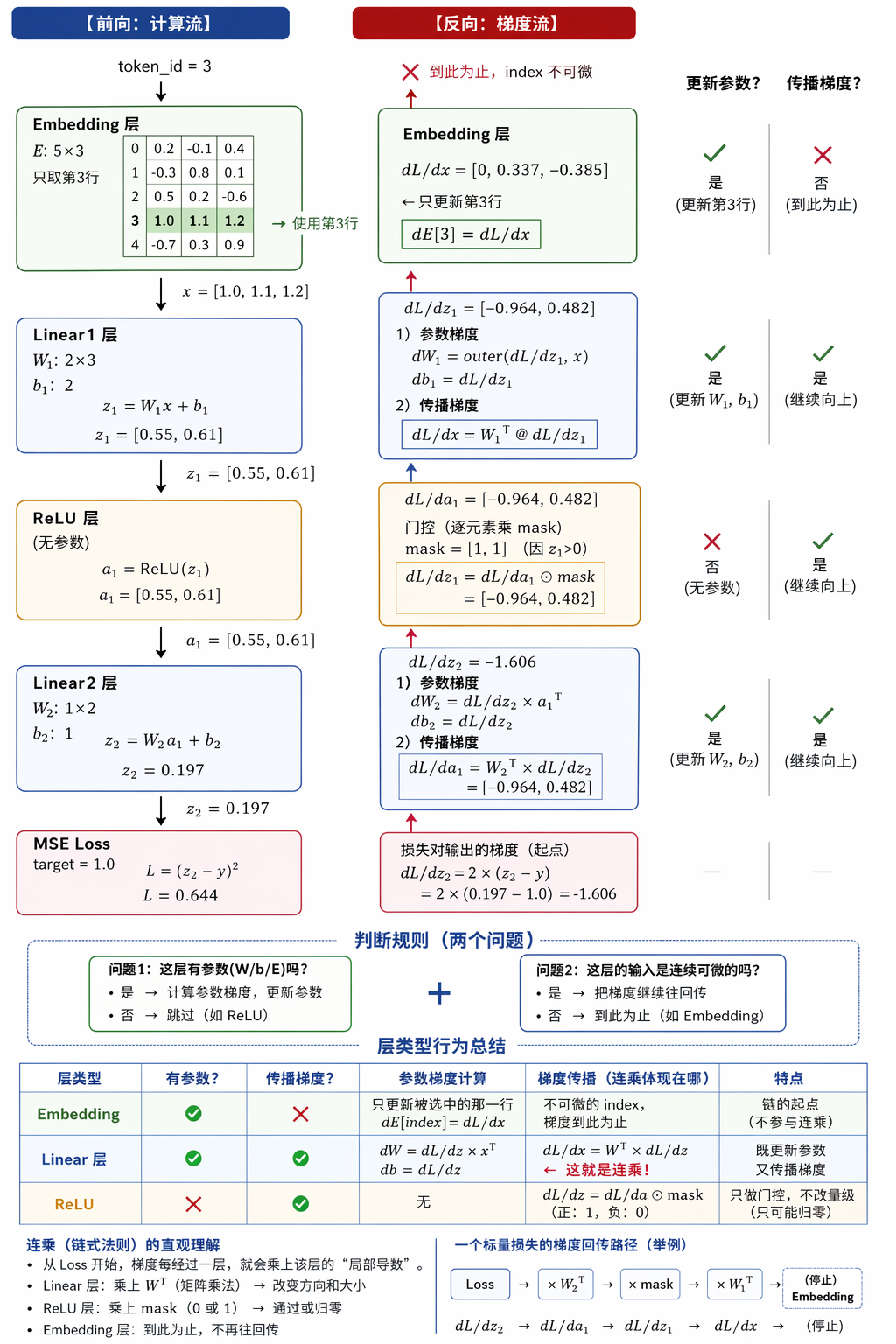
为什么必须对 a 1 a_1 a1(输入)求导?
ReLU 层站在 Linear2 前面,它需要知道"损失对我的输出有多敏感"才能继续往回传。而 ReLU 的输出 = Linear2 的输入 = a 1 a_1 a1。
所以 Linear2 必须算 d L / d a 1 dL/da_1 dL/da1,才能把信号交接给 ReLU;ReLU 再算 d L / d z 1 dL/dz_1 dL/dz1,交接给 Linear1......一直传到头。
对参数求导是为了更新自己 ;对输入 a 求导 是为了传递给前一层------因为"我的输入"就是"前一层的输出",链式法则正是沿着这条路径拆解的。
符号与前向传播先明确每一层做了什么(以第 i i i 层为例):
z ( i ) = w ( i ) ⋅ y ( i − 1 ) (线性变换) \mathbf z^{(i)} = \mathbf w^{(i)} \cdot \mathbf y^{(i-1)} \tag{线性变换} z(i)=w(i)⋅y(i−1)(线性变换)
y ( i ) = f ( z ( i ) ) (激活) \mathbf y^{(i)} = f\!\left(\mathbf z^{(i)}\right) \tag{激活} y(i)=f(z(i))(激活)
| 符号 | 含义 |
|---|---|
| y ( i − 1 ) \mathbf y^{(i-1)} y(i−1) | 上一层的输出(也是本层的输入) |
| w ( i ) \mathbf w^{(i)} w(i) | 第 i i i 层的权重 |
| z ( i ) \mathbf z^{(i)} z(i) | 加权求和的结果(激活前) |
| f f f | 激活函数(如 ReLU、sigmoid) |
| y ( i ) \mathbf y^{(i)} y(i) | 激活后的输出 |
| L L L | 最终的损失 |
数据流方向:
y ( i − 1 ) → w ( i ) z ( i ) → f y ( i ) → w ( i + 1 ) z ( i + 1 ) → f y ( i + 1 ) ⟶ ⋯ ⟶ L \mathbf y^{(i-1)} \xrightarrow{\mathbf w^{(i)}} \mathbf z^{(i)} \xrightarrow{f} \mathbf y^{(i)} \xrightarrow{\mathbf w^{(i+1)}} \mathbf z^{(i+1)} \xrightarrow{f} \mathbf y^{(i+1)} \;\longrightarrow\; \cdots \;\longrightarrow\; L y(i−1)w(i) z(i)f y(i)w(i+1) z(i+1)f y(i+1)⟶⋯⟶L
公式 (2.1) 的推导: ∂ L ∂ w ( i ) \frac{\partial L}{\partial \mathbf w^{(i)}} ∂w(i)∂L
我们要求"损失 L L L 对第 i i i 层权重的梯度"。用链式法则 沿着前向传播的路径逆向 展开:
∂ L ∂ w ( i ) = ∂ L ∂ y ( i ) ⏟ 后面传回来的梯度 ⋅ ∂ y ( i ) ∂ z ( i ) ⏟ 激活函数那一步 ⋅ ∂ z ( i ) ∂ w ( i ) ⏟ 线性变换那一步 \frac{\partial L}{\partial \mathbf w^{(i)}} = \underbrace{\frac{\partial L}{\partial \mathbf y^{(i)}}}{\text{后面传回来的梯度}} \cdot \underbrace{\frac{\partial \mathbf y^{(i)}}{\partial \mathbf z^{(i)}}}{\text{激活函数那一步}} \cdot \underbrace{\frac{\partial \mathbf z^{(i)}}{\partial \mathbf w^{(i)}}}_{\text{线性变换那一步}} ∂w(i)∂L=后面传回来的梯度 ∂y(i)∂L⋅激活函数那一步 ∂z(i)∂y(i)⋅线性变换那一步 ∂w(i)∂z(i)
逐项计算:
- ∂ y ( i ) ∂ z ( i ) \frac{\partial \mathbf y^{(i)}}{\partial \mathbf z^{(i)}} ∂z(i)∂y(i):因为 y ( i ) = f ( z ( i ) ) \mathbf y^{(i)} = f(\mathbf z^{(i)}) y(i)=f(z(i)),直接对 z ( i ) \mathbf z^{(i)} z(i) 求导就是 f ′ ( z ( i ) ) f'(\mathbf z^{(i)}) f′(z(i))。
- ∂ z ( i ) ∂ w ( i ) \frac{\partial \mathbf z^{(i)}}{\partial \mathbf w^{(i)}} ∂w(i)∂z(i):因为 z ( i ) = w ( i ) ⋅ y ( i − 1 ) \mathbf z^{(i)} = \mathbf w^{(i)} \cdot \mathbf y^{(i-1)} z(i)=w(i)⋅y(i−1),对 w ( i ) \mathbf w^{(i)} w(i) 求导就剩下 y ( i − 1 ) \mathbf y^{(i-1)} y(i−1)(相当于 a x ax ax 对 a a a 求导得 x x x)。
代入得:
∂ L ∂ w ( i ) = ∂ L ∂ y ( i ) ⋅ f ′ ( z ( i ) ) ⋅ y ( i − 1 ) \boxed{\frac{\partial L}{\partial \mathbf w^{(i)}} = \frac{\partial L}{\partial \mathbf y^{(i)}} \cdot f'(\mathbf z^{(i)}) \cdot \mathbf y^{(i-1)}} ∂w(i)∂L=∂y(i)∂L⋅f′(z(i))⋅y(i−1)
公式 (2.2) 的推导: ∂ L ∂ y ( i ) \frac{\partial L}{\partial \mathbf y^{(i)}} ∂y(i)∂L现在问题变成:那个"后面传回来的梯度" ∂ L ∂ y ( i ) \frac{\partial L}{\partial \mathbf y^{(i)}} ∂y(i)∂L 本身怎么算?
y ( i ) \mathbf y^{(i)} y(i) 影响 L L L 的路径是:先经过第 i + 1 i{+}1 i+1 层的线性变换变成 z ( i + 1 ) \mathbf z^{(i+1)} z(i+1),再经过激活变成 y ( i + 1 ) \mathbf y^{(i+1)} y(i+1),然后继续往后传。所以再次用链式法则:
∂ L ∂ y ( i ) = ∂ L ∂ y ( i + 1 ) ⏟ 更后面传来的梯度 ⋅ ∂ y ( i + 1 ) ∂ z ( i + 1 ) ⏟ 第 i + 1 层激活 ⋅ ∂ z ( i + 1 ) ∂ y ( i ) ⏟ 第 i + 1 层线性 \frac{\partial L}{\partial \mathbf y^{(i)}} = \underbrace{\frac{\partial L}{\partial \mathbf y^{(i+1)}}}{\text{更后面传来的梯度}} \cdot \underbrace{\frac{\partial \mathbf y^{(i+1)}}{\partial \mathbf z^{(i+1)}}}{\text{第 }i{+}1\text{ 层激活}} \cdot \underbrace{\frac{\partial \mathbf z^{(i+1)}}{\partial \mathbf y^{(i)}}}_{\text{第 }i{+}1\text{ 层线性}} ∂y(i)∂L=更后面传来的梯度 ∂y(i+1)∂L⋅第 i+1 层激活 ∂z(i+1)∂y(i+1)⋅第 i+1 层线性 ∂y(i)∂z(i+1)
逐项计算:
- ∂ y ( i + 1 ) ∂ z ( i + 1 ) = f ′ ( z ( i + 1 ) ) \frac{\partial \mathbf y^{(i+1)}}{\partial \mathbf z^{(i+1)}} = f'(\mathbf z^{(i+1)}) ∂z(i+1)∂y(i+1)=f′(z(i+1)),道理同上。
- ∂ z ( i + 1 ) ∂ y ( i ) \frac{\partial \mathbf z^{(i+1)}}{\partial \mathbf y^{(i)}} ∂y(i)∂z(i+1):因为 z ( i + 1 ) = w ( i + 1 ) ⋅ y ( i ) \mathbf z^{(i+1)} = \mathbf w^{(i+1)} \cdot \mathbf y^{(i)} z(i+1)=w(i+1)⋅y(i),对 y ( i ) \mathbf y^{(i)} y(i) 求导得 w ( i + 1 ) \mathbf w^{(i+1)} w(i+1)(相当于 a x ax ax 对 x x x 求导得 a a a)。
代入得:
∂ L ∂ y ( i ) = ∂ L ∂ y ( i + 1 ) ⋅ f ′ ( z ( i + 1 ) ) ⋅ w ( i + 1 ) \boxed{\frac{\partial L}{\partial \mathbf y^{(i)}} = \frac{\partial L}{\partial \mathbf y^{(i+1)}} \cdot f'(\mathbf z^{(i+1)}) \cdot \mathbf w^{(i+1)}} ∂y(i)∂L=∂y(i+1)∂L⋅f′(z(i+1))⋅w(i+1)
| 公式 | 一句话理解 |
|---|---|
| (2.1) | 要更新第 i i i 层的权重,需要三样东西:后面传来的梯度 × 本层激活函数的导数 × 本层的输入 |
| (2.2) | 后面传来的梯度本身是递推的:更后面传来的梯度 × 下一层激活函数的导数 × 下一层的权重 |
这就是"反向传播"名字的由来------梯度从输出层一层一层向后递推 回去,每经过一层就乘上该层的 f ′ f' f′ 和 w \mathbf w w。
在梯度计算过程中,若网络参数初始化不当或者网络超参设置不合理等,容易出现梯度消失和梯度爆炸问题。梯度消失 是指训练过程中梯度趋近于0,造成参数无法更新,损失函数不再继续收敛,从而导致网络得不到充分训练。梯度爆炸是指训练过程中,梯度过大甚至是NAN(not a number),造成损失大幅震荡或者无法收敛,导致网络无法收敛。
2 为什么需要激活函数
对于没有系统学过神经网络基础知识而是在业务中直接运用神经网络的人来说,激活函数好像很天然地跟神经网络绑定在一起,有神经网络的地方就自然会有激活函数。另一方面,激活函数的生物学背景,也使得它似乎天然就应该设计在神经网络的计算逻辑中。激活函数确实是神经网络的一部分,那为什么神经网络需要激活函数,是否可以不需要它,没有激活函数的神经网络还能不能称为神经网络,理解了这些问题,就理解了激活函数的作用和神经网络的大致工作原理。
神经网络必须包含激活函数,激活函数的作用是给神经元引入非线性。
如果没有激活函数,神经网络的本质将发生变化,此时不管神经网络有多少层,最终的输出将成为输入的线性组合,如式子(3)所示,这将导致神经网络退化成感知机,也就是由一个线性加权组合表达的分类器。神经网络之所以被公认的强大,可以拟合任何函数,正是因为它的非线性,当从神经网络中去掉激活函数后,相当于把神经网络从王者直接变成青铜。 z ( i + 1 ) = w ( i + 1 ) y ( i ) + b ( i ) = w ( i + 1 ) ( w ( i ) y ( i − 1 ) + b ( i − 1 ) ) + b ( i ) = w ( i + 1 ) ( w ( i ) . . . ( w ( 0 ) x + b ( 0 ) ) . . . + b ( i − 1 ) ) + b ( i ) (3) \mathbf z^{(i+1)} = \mathbf w^{(i+1)} \mathbf y^{(i)} + \mathbf b^{(i)} = \mathbf w^{(i+1)} ( \mathbf w^{(i)} \mathbf y^{(i-1)} + \mathbf b^{(i-1)} )+ \mathbf b^{(i)} = \mathbf w^{(i+1)} ( \mathbf w^{(i)}... (\mathbf w^{(0)}\mathbf x+ \mathbf b^{(0)})...+ \mathbf b^{(i-1)} )+ \mathbf b^{(i)} \tag {3} z(i+1)=w(i+1)y(i)+b(i)=w(i+1)(w(i)y(i−1)+b(i−1))+b(i)=w(i+1)(w(i)...(w(0)x+b(0))...+b(i−1))+b(i)(3)
3 常用的激活函数
常用的激活函数包括sigmoid、tanh、ReLU、Leaky ReLU、ELU、SELU、PReLU、Dice、maxout、softmax等,其中Leaky ReLU、ELU、SELU、PReLU、Dice的原理都是ReLU为基础进行一些改进,softmax是sigmoid的拓展,主要用于多分类网络的最后一层。激活函数的原理决定了其特点和适用场景,通过了解原理,可以在具体业务场景中更好地运用这些激活函数。
3.1 sigmoid
sigmoid激活函数被广泛使用,和生物神经元的激活逻辑最接近,其定义如式子(4)所示,函数图像如图3所示。
f ( x ) = 1 1 + e − x (4) f(x) = \frac{1}{1+e^{-x}} \tag{4} f(x)=1+e−x1(4)
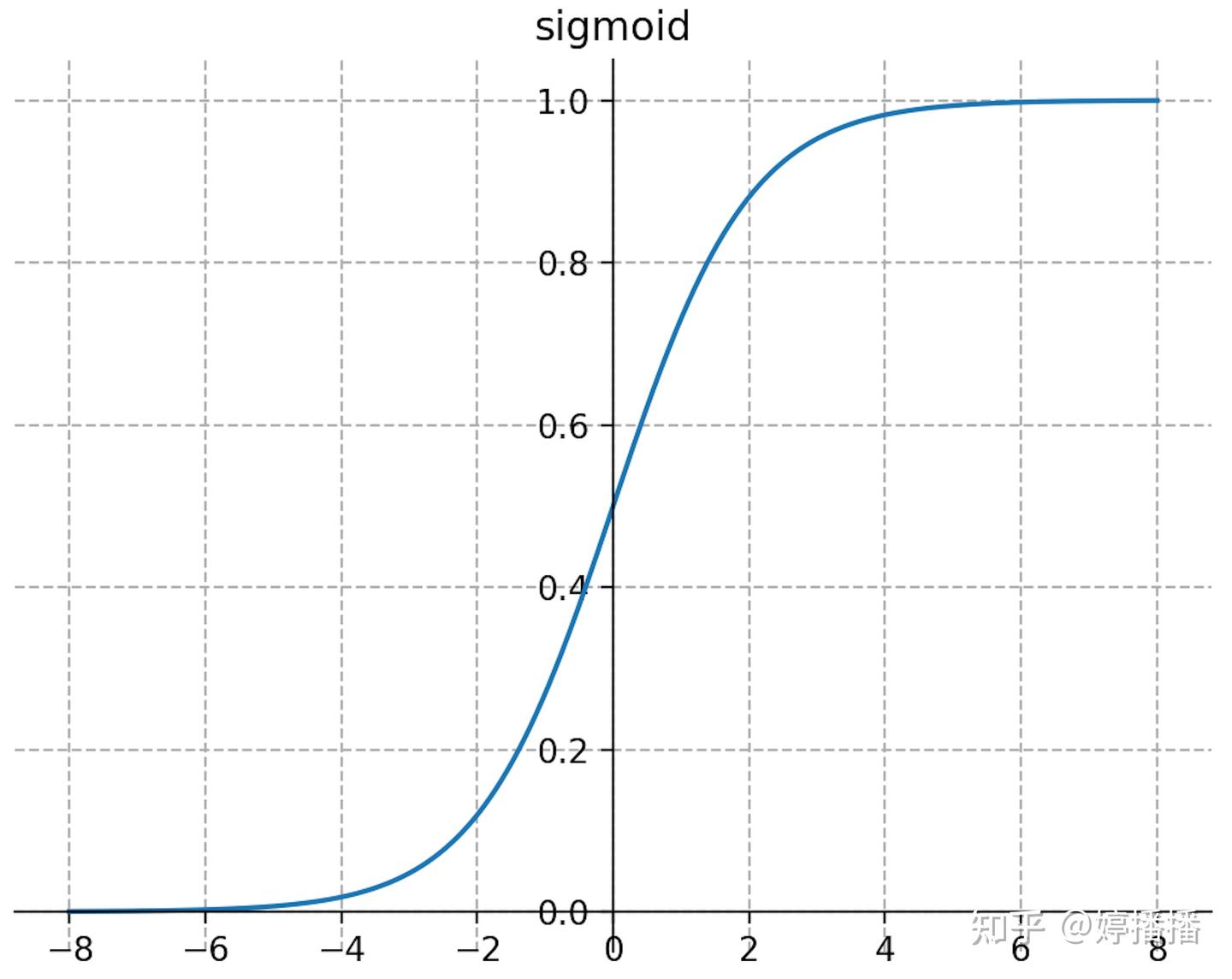
图3 sigmoid函数
sigmoid函数的特点明显:(1) 连续光滑、严格单调;(2) 输出范围为(0,1),以(0, 0.5)为对称中心;(3) 当输入趋于负无穷时,输出趋近于0,当输入趋于正无穷时,输出趋近于1;(4) 输入在0附近时,输出变化趋势明显,输入离0越远,变化趋势越平缓且逐渐趋于不变。
根据sigmoid激活函数的特点,可以得到对应的优缺点。其优点包括:(1) 输出范围为(0,1),适合作为概率的使用;(2) 求导方便,如式子(5)所示,不需要额外的计算量。
f ′ ( x ) = f ( x ) ( 1 − f ( x ) ) = − ( f ( x ) − 1 2 ) 2 + 1 4 ∈ ( 0 , 1 4 ] (5) f^{'}(x)=f(x)(1-f(x)) = -(f(x)-\frac{1}{2})^2+ \frac{1}{4} \in (0, \frac{1}{4}] \tag{5} f′(x)=f(x)(1−f(x))=−(f(x)−21)2+41∈(0,41](5)
直接按求导法则推导,把它看成:
f ( x ) = ( 1 + e − x ) − 1 f(x)=(1+e^{-x})^{-1} f(x)=(1+e−x)−1
对它求导,用链式法则:
f ′ ( x ) = − 1 ⋅ ( 1 + e − x ) − 2 ⋅ d d x ( 1 + e − x ) f'(x)=-1\cdot (1+e^{-x})^{-2}\cdot \frac{d}{dx}(1+e^{-x}) f′(x)=−1⋅(1+e−x)−2⋅dxd(1+e−x)
而
d d x ( 1 + e − x ) = − e − x \frac{d}{dx}(1+e^{-x})=-e^{-x} dxd(1+e−x)=−e−x
所以:
f ′ ( x ) = − ( 1 + e − x ) − 2 ( − e − x ) f'(x)=-(1+e^{-x})^{-2}(-e^{-x}) f′(x)=−(1+e−x)−2(−e−x)
化简得:
f ′ ( x ) = e − x ( 1 + e − x ) 2 f'(x)=\frac{e^{-x}}{(1+e^{-x})^2} f′(x)=(1+e−x)2e−x
这已经是正确导数了。
现在把原函数代回去:
f ( x ) = 1 1 + e − x f(x)=\frac{1}{1+e^{-x}} f(x)=1+e−x1
那么
1 − f ( x ) = 1 − 1 1 + e − x 1-f(x)=1-\frac{1}{1+e^{-x}} 1−f(x)=1−1+e−x1
通分:
1 − f ( x ) = 1 + e − x − 1 1 + e − x = e − x 1 + e − x 1-f(x)=\frac{1+e^{-x}-1}{1+e^{-x}}=\frac{e^{-x}}{1+e^{-x}} 1−f(x)=1+e−x1+e−x−1=1+e−xe−x
于是:
f ( x ) ( 1 − f ( x ) ) f(x)(1-f(x)) f(x)(1−f(x))
= 1 1 + e − x ⋅ e − x 1 + e − x =\frac{1}{1+e^{-x}}\cdot \frac{e^{-x}}{1+e^{-x}} =1+e−x1⋅1+e−xe−x
= e − x ( 1 + e − x ) 2 =\frac{e^{-x}}{(1+e^{-x})^2} =(1+e−x)2e−x
这正好就是刚才求出的导数,所以:
f ′ ( x ) = f ( x ) ( 1 − f ( x ) ) f'(x)=f(x)(1-f(x)) f′(x)=f(x)(1−f(x))
"求导方便"到底方便在哪导数形式非常简单;并且前向算过一次,反向几乎直接复用;计算图也简单。
很多函数求导后会得到一个新的复杂表达式,但 sigmoid 的导数仍然只依赖于 sigmoid 自己:
f ′ ( x ) = f ( x ) ( 1 − f ( x ) ) f'(x)=f(x)(1-f(x)) f′(x)=f(x)(1−f(x))
a = σ ( z ) a=\sigma(z) a=σ(z)
∂ a ∂ z = a ( 1 − a ) \frac{\partial a}{\partial z}=a(1-a) ∂z∂a=a(1−a)
也就是说,只要你已经算出了前向传播的输出 (f(x)),反向传播时就能立刻得到导数,不必再重新算一大堆东西。
其缺点包括:(1) 当输入离0较远时,输出变化非常平缓,容易陷入梯度饱和状态,导致梯度消失问题;(2) 以(0, 0.5)为对称中心,原点不对称,容易改变输出的数据分布;(3) 导数取值范围为(0, 0.25](推导过程见式子(5)),连乘后梯度呈指数级减小,所以当网络加深时,浅层网络梯度容易出现梯度消失,详细原因见推导1;(4) 输出总是正数,使反向传播时参数w的梯度全正或全负,梯度下降出现zigzag形状,导致网络收速度慢,详细原因见分析1;(5) 计算包括指数项,耗时多。
sigmoid 导数是
σ ′ ( x ) = σ ( x ) ( 1 − σ ( x ) ) \sigma'(x)=\sigma(x)(1-\sigma(x)) σ′(x)=σ(x)(1−σ(x))
设
u = σ ( x ) ∈ ( 0 , 1 ) u=\sigma(x)\in(0,1) u=σ(x)∈(0,1)
则
σ ′ ( x ) = u ( 1 − u ) \sigma'(x)=u(1-u) σ′(x)=u(1−u)
把它整理成配方形式:
u ( 1 − u ) = u − u 2 = − ( u − 1 2 ) 2 + 1 4 u(1-u)=u-u^2= -\left(u-\frac12\right)^2+\frac14 u(1−u)=u−u2=−(u−21)2+41
因此:
σ ′ ( x ) = − ( σ ( x ) − 1 2 ) 2 + 1 4 ≤ 1 4 \sigma'(x)= -\left(\sigma(x)-\frac12\right)^2+\frac14 \le \frac14 σ′(x)=−(σ(x)−21)2+41≤41
并且只有在 σ ( x ) = 1 2 \sigma(x)=\frac12 σ(x)=21,也就是 (x=0) 时取到最大值 1 4 \frac14 41。
所以:
σ ′ ( x ) ∈ ( 0 , 1 4 ] \sigma'(x)\in (0,\tfrac14] σ′(x)∈(0,41]
这说明 sigmoid 的局部梯度天生就偏小。
推导1 sigmoid激活函数梯度消失问题
根据梯度反向传播式子(2.2)有 ∂ L ∂ y ( i ) = ∂ L ∂ y ( i + 1 ) f ′ ( z ( i + 1 ) ) w ( i + 1 ) \frac{\partial{L}}{\partial{\mathbf y^{(i)}}} = \frac{\partial{L}}{\partial{\mathbf y^{(i+1)}}} f^{'}(\mathbf z^{(i+1)}) \mathbf w^{(i+1)} ∂y(i)∂L=∂y(i+1)∂Lf′(z(i+1))w(i+1) ,而根据sigmoid的求导式子(5)有 f ′ ( x ) ≤ 1 4 f^{'}(x) \leq \frac{1}{4} f′(x)≤41 ,w一般会进行标准化,因此w通常小于1,所以得到 ∣ ∂ L ∂ y ( i ) ∣ ≤ 1 4 ∣ ∂ L ∂ y ( i + 1 ) ∣ |\frac{\partial{L}}{\partial{\mathbf y^{(i)}}}| \leq \frac{1}{4} |\frac{\partial{L}}{\partial{\mathbf y^{(i+1)}}}| ∣∂y(i)∂L∣≤41∣∂y(i+1)∂L∣ ,可以看出,损失对y的梯度随着层数的增加按照每层1/4的大小缩小,当深度较深时,损失对y的梯度容易变得很小甚至消失。
根据式子(2.1)有 ∂ L ∂ w ( i ) = ∂ L ∂ y ( i ) f ′ ( z ( i ) ) y ( i − 1 ) \frac{\partial{L}}{\partial{\mathbf w^{(i)}}} = \frac{\partial{L}}{\partial{\mathbf y^{(i)}}} f^{'}(\mathbf z^{(i)}) \mathbf y^{(i-1)} ∂w(i)∂L=∂y(i)∂Lf′(z(i))y(i−1) ,参数w的梯度依赖于y的梯度,当损失对y的梯度消失时,参数w的梯度也随之消失,从而造成梯度消失问题。
分析1 sigmoid激活函数zigzag现象
1 参数w的梯度方向特点
参数w的梯度为 ∂ L ∂ w ( i ) = ∂ L ∂ y ( i ) f ′ ( z ( i ) ) y ( i − 1 ) \frac{\partial{L}}{\partial{\mathbf w^{(i)}}} = \frac{\partial{L}}{\partial{\mathbf y^{(i)}}} f^{'}(\mathbf z^{(i)}) \mathbf y^{(i-1)} ∂w(i)∂L=∂y(i)∂Lf′(z(i))y(i−1) ,由于sigmoid的导数 f\^{'} 恒为正,y为上一层隐层经过sigmoid的输出,同样恒为正,因此参数w的梯度方向取决于 ∂ L ∂ y ( i ) \frac{\partial{L}}{\partial{\mathbf y^{(i)}}} ∂y(i)∂L 的梯度方向,而对同一层的所有参数w而言, ∂ L ∂ y ( i ) \frac{\partial{L}}{\partial{\mathbf y^{(i)}}} ∂y(i)∂L 是相同的,所以同一层的参数w在更新时要么同时增大,要么同时减小,没有自己独立的正负方向。
2 为什么参数的梯度方向一致容易造成zigzag现象
当所有梯度同为正或者负时,参数在梯度更新时容易出现zigzag现象。zigzag现象如图4所示,不妨假设一共两个参数, w 0 w_0 w0 和 w 1 w_1 w1 ,紫色点为参数的最优解,蓝色箭头表示梯度最优方向,红色箭头表示实际梯度更新方向。由于参数的梯度方向一致,要么同正,要么同负,因此更新方向只能为第三象限角度或第一象限角度,而梯度的最优方向为第四象限角度,也就是参数 w 0 w_0 w0 要向着变小的方向, w 1 w_1 w1 要向着变大的方向,在这种情况下,每更新一次梯度,不管是同时变小(第三象限角度)还是同时变大(第四象限角度),总是一个参数更接近最优状态,另一个参数远离最优状态,因此为了使参数尽快收敛到最优状态,出现交替向最优状态更新的现象,也就是zigzag现象。
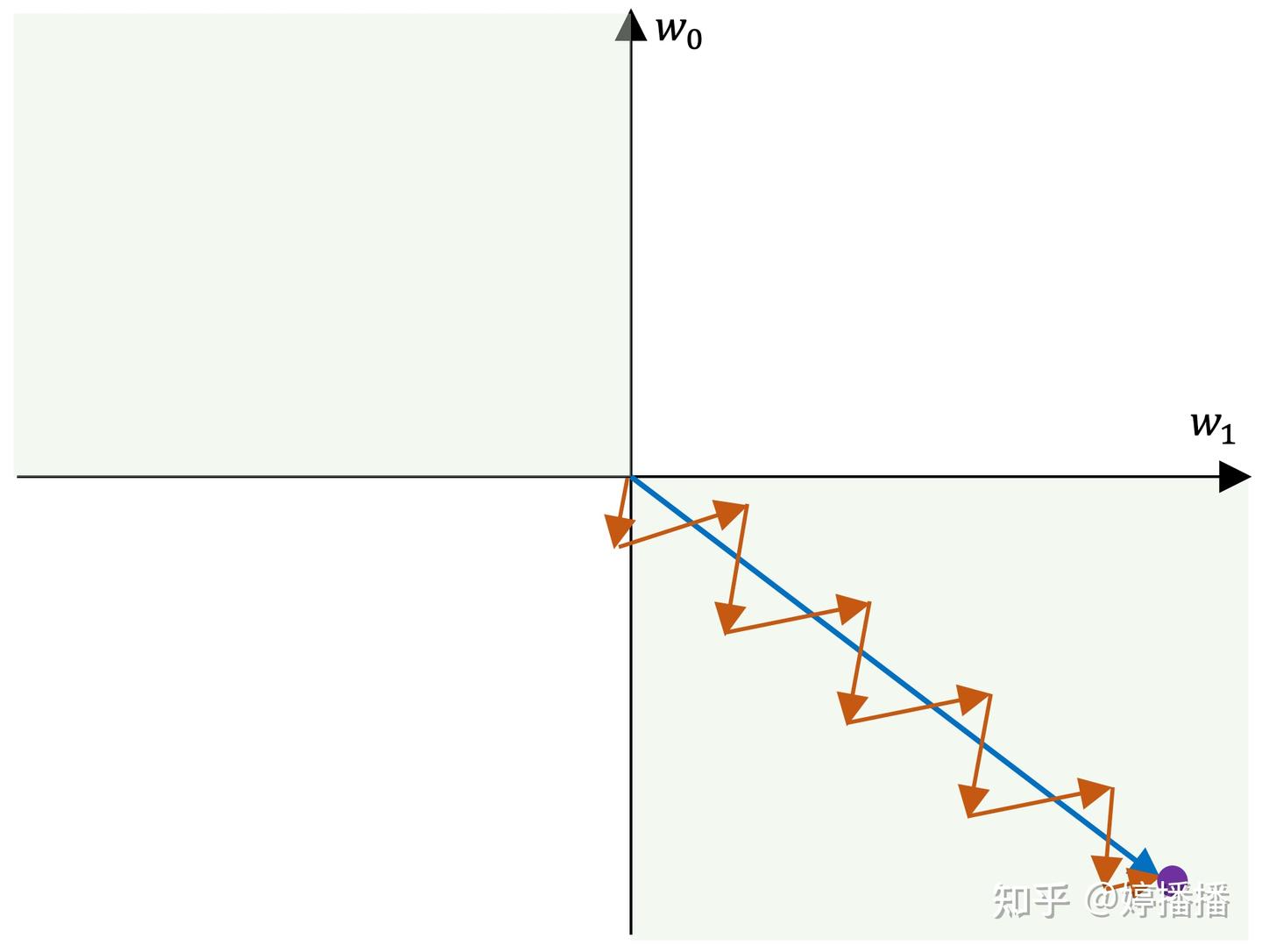
图4 sigmoid激活函数zigzag现象
sigmoid函数在什么情况下会出现zigzag现象呢(有兴趣的朋友可以先思考一下再看后面的内容)。从上面的分析可以看出,当梯度更新的最优方向不满足所有参数梯度正负向一致时,也就是有的参数梯度正向,有的参数梯度负向,容易出现zigzag现象。
两个参数时,出现zigzag现象的梯度更新最优方向为图4中的绿色背景部分,即第二象限和第四象限。在深度学习中,网络参数非常巨大,形成高维的空间,梯度更新的最优方向非常容易出现不同参数的梯度正负向不一致的情况,也就更容易造成zigzag现象。
抛开激活函数,当参数量纲差异大时,也容易造成zigzag现象,其中的原因和sigmoid函数造成的zigzag现象,是相通的。
原文中提到:sigmoid激活函数zigzag现象
第〇部分:先把场景和符号全部交代清楚
一个最简单的单层网络,用来做回归 或二分类:
输入 x = [x_0, x_1] → 神经元 → 输出 a神经元内部做两件事:
- 加权求和: z = w 0 x 0 + w 1 x 1 z = w_0 x_0 + w_1 x_1 z=w0x0+w1x1
- 过激活函数: a = σ ( z ) a = \sigma(z) a=σ(z),其中 σ \sigma σ 是 sigmoid 函数
损失函数(用最简单的均方误差来讲)
L = 1 2 ( a − t ) 2 L = \frac{1}{2}(a - t)^2 L=21(a−t)2
- a a a(actual/activation)= 网络的实际输出,是 sigmoid 算出来的值,范围 (0, 1)
- t t t(target)= 目标值,就是训练数据告诉你"正确答案应该是多少"
所以 ( a − t ) (a - t) (a−t)** 就是"网络输出 - 正确答案"= 误差**。
- 如果 a > t a > t a>t(输出太大了), ( a − t ) > 0 (a-t) > 0 (a−t)>0
- 如果 a < t a < t a<t(输出太小了), ( a − t ) < 0 (a-t) < 0 (a−t)<0
梯度公式怎么来的?对 w j w_j wj 求偏导,链式法则一步步展开:
∂ L ∂ w j = ∂ L ∂ a ⋅ ∂ a ∂ z ⋅ ∂ z ∂ w j \frac{\partial L}{\partial w_j} = \frac{\partial L}{\partial a} \cdot \frac{\partial a}{\partial z} \cdot \frac{\partial z}{\partial w_j} ∂wj∂L=∂a∂L⋅∂z∂a⋅∂wj∂z
逐项算:
- ∂ L ∂ a = ( a − t ) \frac{\partial L}{\partial a} = (a - t) ∂a∂L=(a−t) ← 误差方向,可正可负
- ∂ a ∂ z = σ ′ ( z ) = σ ( z ) ( 1 − σ ( z ) ) \frac{\partial a}{\partial z} = \sigma'(z) = \sigma(z)(1-\sigma(z)) ∂z∂a=σ′(z)=σ(z)(1−σ(z)) ← sigmoid 导数,永远 > 0
- ∂ z ∂ w j = x j \frac{\partial z}{\partial w_j} = x_j ∂wj∂z=xj ← 输入值
合起来:
∂ L ∂ w j = ( a − t ) ⋅ σ ′ ( z ) ⋅ x j \boxed{\frac{\partial L}{\partial w_j} = (a - t) \cdot \sigma'(z) \cdot x_j} ∂wj∂L=(a−t)⋅σ′(z)⋅xj
第一部分:为什么 sigmoid 导致所有梯度同号?看这三项的正负号:
| 项 | 正负 | 原因 |
|---|---|---|
| ( a − t ) (a-t) (a−t) | 可正可负 | 取决于当前预测是偏大还是偏小 |
| σ ′ ( z ) \sigma'(z) σ′(z) | 恒正 | sigmoid 导数 = σ ( 1 − σ ) \sigma(1-\sigma) σ(1−σ),两个 (0,1) 数相乘 |
| x j x_j xj | 恒正 | 因为 x j x_j xj 是上一层 sigmoid 的输出,范围 (0,1) |
所以:
sign ( ∂ L ∂ w j ) = sign ( a − t ) ⋅ ( + ) ⋅ ( + ) = sign ( a − t ) \text{sign}\left(\frac{\partial L}{\partial w_j}\right) = \text{sign}(a-t) \cdot (+) \cdot (+) = \text{sign}(a-t) sign(∂wj∂L)=sign(a−t)⋅(+)⋅(+)=sign(a−t)
不管 j j j 是 0 还是 1,梯度的正负号都只由 ( a − t ) (a-t) (a−t) 决定,而 ( a − t ) (a-t) (a−t) 对所有权重是同一个数!
结论: w 0 w_0 w0** 和 w 1 w_1 w1 的梯度永远同号------要么一起为正,要么一起为负。**
第二部分:Zigzag 是什么?
- 设两个权重 w0,w1,最优解需要 w0 减小、w1 增大(第二象限方向)
- 但梯度同号只允许:↗(同增,第一象限)或 ↙(同减,第三象限)
- 每一步总有一个权重方向正确、另一个方向错误,下一步再反过来纠正 → 交替折返,形成锯齿路径
第三部分:为什么换 Tanh 就好了?Tanh 输出范围是 ( − 1 , + 1 ) (-1, +1) (−1,+1),所以上一层传过来的 x j x_j xj 可以是负数 。
∂ L ∂ w j = ( a − t ) ⋅ f ′ ( z ) ⋅ x j \frac{\partial L}{\partial w_j} = (a-t) \cdot f'(z) \cdot x_j ∂wj∂L=(a−t)⋅f′(z)⋅xj
- f ′ ( z ) > 0 f'(z) > 0 f′(z)>0(tanh 导数也恒正)
- 但 x j x_j xj 可正可负!
所以:
- 如果 x 0 = + 0.7 x_0 = +0.7 x0=+0.7, x 1 = − 0.4 x_1 = -0.4 x1=−0.4
- 那么 ∂ L ∂ w 0 \frac{\partial L}{\partial w_0} ∂w0∂L 和 ∂ L ∂ w 1 \frac{\partial L}{\partial w_1} ∂w1∂L 符号相反
这意味着 w 0 w_0 w0 可以增大的同时 w 1 w_1 w1 减小 → 更新方向可以指向任意象限 → 可以直奔最优解 → 不再 zigzag。
| Sigmoid | Tanh | |
|---|---|---|
| 上一层输出 x j x_j xj 的范围 | (0, 1) 恒正 | (-1, 1) 可正可负 |
| 同一层各 w j w_j wj 梯度符号 | 全部相同 (被 ( a − t ) (a-t) (a−t) 绑死) | 可以不同 ( x j x_j xj 的正负打破绑定) |
| 可选的更新方向 | 只有 ↗ 或 ↙(第一/三象限) | 任意方向(所有象限) |
| 结果 | 必须锯齿逼近 → zigzag | 可以直线逼近 → 高效收敛 |
原文中说到:抛开激活函数,当参数量纲差异大时,也容易造成zigzag现象,其中的原因和sigmoid函数造成的zigzag现象,是相通的。在此讲解
Zigzag 与特征归一化
预测房价: y ^ = w 0 ⋅ x 0 + w 1 ⋅ x 1 \hat{y} = w_0 \cdot x_0 + w_1 \cdot x_1 y^=w0⋅x0+w1⋅x1
- x 0 x_0 x0:面积,典型值 100
- x 1 x_1 x1:房间数,典型值 3
归一化前:Zigzag
梯度 ∂ L ∂ w j = ( y ^ − y ) ⋅ x j \frac{\partial L}{\partial w_j} = (\hat y - y) \cdot x_j ∂wj∂L=(y^−y)⋅xj
- w 0 w_0 w0 梯度 ∝ 100 → 步子巨大,来回冲过头
- w 1 w_1 w1 梯度 ∝ 3 → 步子极小,挪动缓慢
损失等高线是极度扁长的椭圆 ( w 0 w_0 w0 方向窄、 w 1 w_1 w1 方向宽),梯度方向几乎垂直于长轴 → 在窄方向震荡、宽方向蠕动 → zigzag。
归一化后:直线收敛
把特征缩放到同一量级(如均值0、方差1):
x 0 ′ = x 0 − μ 0 σ 0 , x 1 ′ = x 1 − μ 1 σ 1 x_0' = \frac{x_0 - \mu_0}{\sigma_0}, \quad x_1' = \frac{x_1 - \mu_1}{\sigma_1} x0′=σ0x0−μ0,x1′=σ1x1−μ1
现在两个特征量级相当 → 两个方向梯度幅度接近 → 等高线变成正圆,梯度直指圆心 → 一步一步直奔最优解,无 zigzag。
对比总结
归一化消除量纲差异 → 各方向梯度均衡 → 等高线变圆 → 梯度方向就是最优方向 → zigzag 消失。这和 tanh 缓解 sigmoid zigzag 的本质一样------消除导致更新方向被扭偏的不对称性。
w1 ↑ ★ 最优解
| ←→←→←→↗ ← w0震荡,w1缓慢爬升
●─────────→ w0w1 ↑
| ↘
| ↘
| ★ 最优解
●─────────→ w0| 归一化前 | 归一化后 | |
|---|---|---|
| 各维度梯度幅度 | 差距悬殊(100 vs 3) | 相近 |
| 损失等高线形状 | 扁长椭圆 | 接近正圆 |
| 更新方向 | 偏离最优方向 → zigzag | 直指最优解 |
| 收敛速度 | 慢,需大量折返 | 快,步步有效 |
3.2 tanh
tanh激活函数如式子(6)所示,函数图像如图5所示。
f ( x ) = e x − e − x e x + e − x (6) f(x) = \frac{e^{x}-e^{-x}}{e^{x}+e^{-x}} \tag{6} f(x)=ex+e−xex−e−x(6)
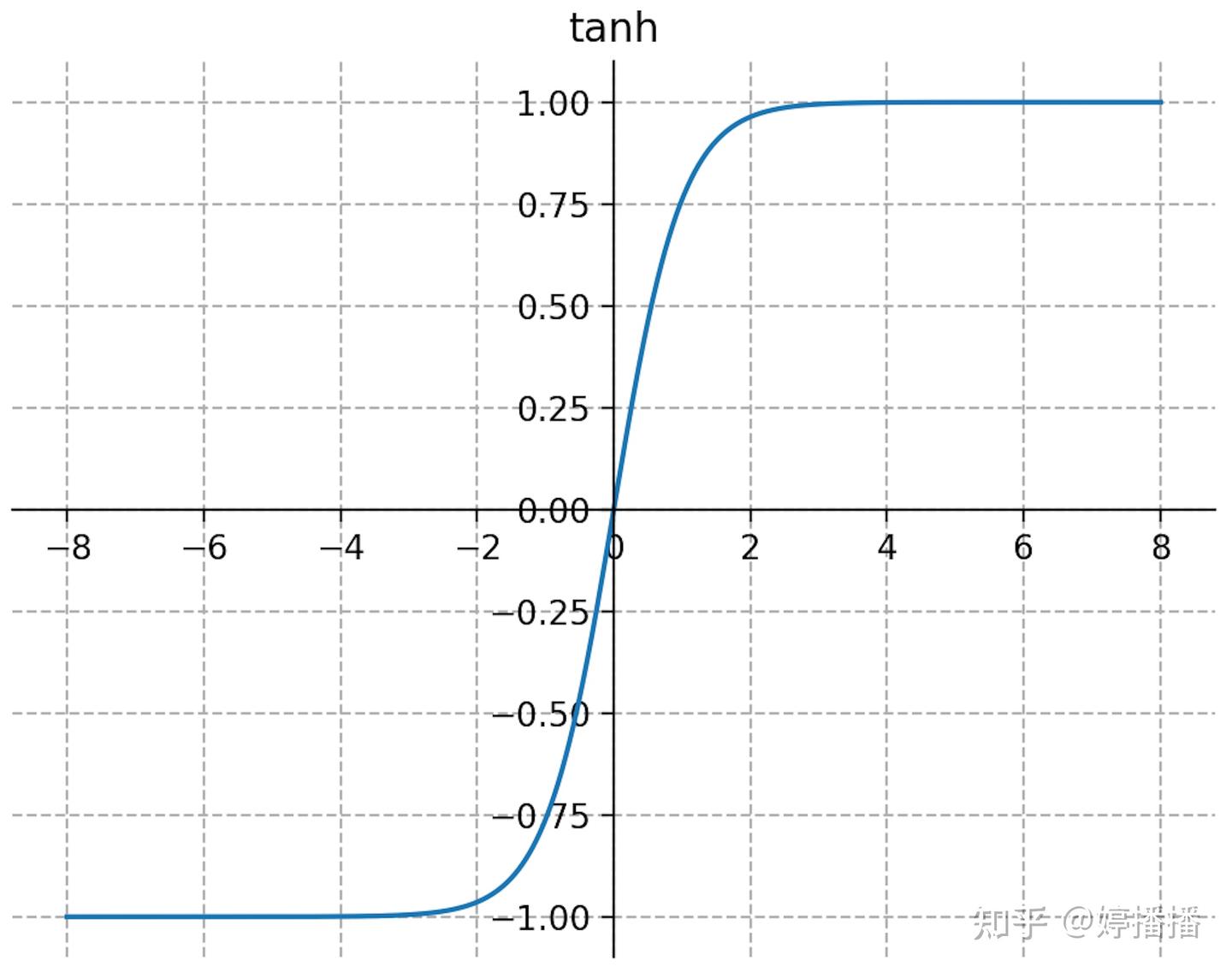
图5 tanh函数
tanh函数形状和sigmoid函数很相似,由tanh和sigmoid函数的定义有 t a n h ( x ) = 2 s i g m o i d ( 2 x ) − 1 tanh(x) = 2sigmoid(2x)-1 tanh(x)=2sigmoid(2x)−1 ,因此tanh函数可以由sigmoid函数伸缩平移得到,所以tanh函数一些特点和sigmoid函数相同。
tanh函数特点:(1) 连续光滑、严格单调;(2) 输出范围为(-1,1),以(0, 0)为对称中心,均值为0;(3) 输入在0附近时,输出变化明显;输入离0越远,输出变化越小最后输出趋近于1不变。
根据tanh函数的特点可以得到其优缺点。
优点:输出关于原点对称,0均值,因此输出有正有负,可以规避zigzag现象,另外原点对称本身是一个很好的优点,有益于网络的学习。
缺点:存在梯度消失问题,tanh的导数计算为 f ′ = 4 e 2 x ( e 2 x + 1 ) 2 f^{'} = \frac{4e^{2x}}{(e^{2x}+1)^2} f′=(e2x+1)24e2x ,取值范围为(0,1],虽然取值范围比sigmoid导数更广一些,可以缓解梯度消失,但仍然无法避免随着网络层数增多梯度连乘导致的梯度消失问题。
t a n h ( x ) = 2 s i g m o i d ( 2 x ) − 1 tanh(x) = 2sigmoid(2x)-1 tanh(x)=2sigmoid(2x)−1 推倒
已知
σ ( x ) = 1 1 + e − x , tanh ( x ) = e x − e − x e x + e − x \sigma(x) = \frac{1}{1+e^{-x}}, \quad \tanh(x) = \frac{e^x - e^{-x}}{e^x + e^{-x}} σ(x)=1+e−x1,tanh(x)=ex+e−xex−e−x
推导
从右边 2 σ ( 2 x ) − 1 2\sigma(2x) - 1 2σ(2x)−1 出发:
2 σ ( 2 x ) − 1 = 2 1 + e − 2 x − 1 = 2 − ( 1 + e − 2 x ) 1 + e − 2 x = 1 − e − 2 x 1 + e − 2 x 2\sigma(2x) - 1 = \frac{2}{1+e^{-2x}} - 1 = \frac{2 - (1+e^{-2x})}{1+e^{-2x}} = \frac{1 - e^{-2x}}{1 + e^{-2x}} 2σ(2x)−1=1+e−2x2−1=1+e−2x2−(1+e−2x)=1+e−2x1−e−2x
再看 tanh ( x ) \tanh(x) tanh(x),分子分母同乘 e − x e^{-x} e−x:
tanh ( x ) = e x − e − x e x + e − x = e x ⋅ e − x − e − x ⋅ e − x e x ⋅ e − x + e − x ⋅ e − x = 1 − e − 2 x 1 + e − 2 x \tanh(x) = \frac{e^x - e^{-x}}{e^x + e^{-x}} = \frac{e^x \cdot e^{-x} - e^{-x} \cdot e^{-x}}{e^x \cdot e^{-x} + e^{-x} \cdot e^{-x}} = \frac{1 - e^{-2x}}{1 + e^{-2x}} tanh(x)=ex+e−xex−e−x=ex⋅e−x+e−x⋅e−xex⋅e−x−e−x⋅e−x=1+e−2x1−e−2x
两者相等,得证:
tanh ( x ) = 2 σ ( 2 x ) − 1 \boxed{\tanh(x) = 2\sigma(2x) - 1} tanh(x)=2σ(2x)−1
直观理解
这个式子说明 tanh 就是 sigmoid 经过两步变换得到的:
- 横向压缩 2 倍( x → 2 x x → 2x x→2x)
- 纵向拉伸 2 倍再下移 1( 2 ⋅ ( ⋅ ) − 1 2 \cdot (\cdot) - 1 2⋅(⋅)−1,把值域从 ( 0 , 1 ) (0,1) (0,1) 映射到 ( − 1 , 1 ) (-1,1) (−1,1))
所以两者形状相似,只是 tanh 关于原点对称、sigmoid 关于 ( 0 , 0.5 ) (0, 0.5) (0,0.5) 对称。
原点对称本身是一个很好的优点,有益于网络的学习。讲解这个其实就是前面 zigzag 问题的另一面。
关于原点对称 = 输出均值为 0,正负各半。
为什么说"零中心化有益于学习"------它直接避免了 sigmoid 那种"梯度方向被锁死"的问题。同样的道理,也是为什么实践中常对输入数据做 zero-mean 归一化。
| 激活函数 | 输出范围 | x j x_j xj 的特点 | 对梯度的影响 |
|---|---|---|---|
| Sigmoid | (0, 1) | 恒正,均值≈0.5 | 所有 w j w_j wj 梯度同号 → zigzag |
| Tanh | (-1, 1) | 有正有负,均值≈0 | 各 w j w_j wj 梯度可独立正负 → 可直奔最优解 |
输出有正有负 → 下一层各权重的梯度符号不再被绑定 → 更新方向不受限 → 收敛更快、不 zigzag。
原文提及到:Tanh 的梯度消失问题0、Tanh 导数推导
第一步:用商法则求原始导数
已知 tanh ( x ) = e x − e − x e x + e − x \tanh(x) = \frac{e^x - e^{-x}}{e^x + e^{-x}} tanh(x)=ex+e−xex−e−x
设分子 u = e x − e − x u = e^x - e^{-x} u=ex−e−x,分母 v = e x + e − x v = e^x + e^{-x} v=ex+e−x
则 u ′ = e x + e − x u' = e^x + e^{-x} u′=ex+e−x, v ′ = e x − e − x v' = e^x - e^{-x} v′=ex−e−x
商法则 f ′ = u ′ v − u v ′ v 2 f' = \frac{u'v - uv'}{v^2} f′=v2u′v−uv′:
f ′ ( x ) = ( e x + e − x ) ( e x + e − x ) − ( e x − e − x ) ( e x − e − x ) ( e x + e − x ) 2 f'(x) = \frac{(e^x+e^{-x})(e^x+e^{-x}) - (e^x-e^{-x})(e^x-e^{-x})}{(e^x+e^{-x})^2} f′(x)=(ex+e−x)2(ex+e−x)(ex+e−x)−(ex−e−x)(ex−e−x)
= ( e x + e − x ) 2 − ( e x − e − x ) 2 ( e x + e − x ) 2 = \frac{(e^x+e^{-x})^2 - (e^x-e^{-x})^2}{(e^x+e^{-x})^2} =(ex+e−x)2(ex+e−x)2−(ex−e−x)2
展开:
( e x + e − x ) 2 = e 2 x + 2 + e − 2 x (e^x+e^{-x})^2 = e^{2x} + 2 + e^{-2x} (ex+e−x)2=e2x+2+e−2x
( e x − e − x ) 2 = e 2 x − 2 + e − 2 x (e^x-e^{-x})^2 = e^{2x} - 2 + e^{-2x} (ex−e−x)2=e2x−2+e−2x
分子相减: ( e 2 x + 2 + e − 2 x ) − ( e 2 x − 2 + e − 2 x ) = 4 (e^{2x}+2+e^{-2x}) - (e^{2x}-2+e^{-2x}) = 4 (e2x+2+e−2x)−(e2x−2+e−2x)=4
所以:
f ′ ( x ) = 4 ( e x + e − x ) 2 f'(x) = \frac{4}{(e^x+e^{-x})^2} f′(x)=(ex+e−x)24
第二步:化成 4 e 2 x ( e 2 x + 1 ) 2 \frac{4e^{2x}}{(e^{2x}+1)^2} (e2x+1)24e2x 的形式
分母 ( e x + e − x ) 2 (e^x + e^{-x})^2 (ex+e−x)2 中提取 e − x e^{-x} e−x:
e x + e − x = e − x ( e 2 x + 1 ) e^x + e^{-x} = e^{-x}(e^{2x} + 1) ex+e−x=e−x(e2x+1)
所以:
( e x + e − x ) 2 = e − 2 x ( e 2 x + 1 ) 2 (e^x + e^{-x})^2 = e^{-2x}(e^{2x}+1)^2 (ex+e−x)2=e−2x(e2x+1)2
代回:
f ′ ( x ) = 4 e − 2 x ( e 2 x + 1 ) 2 = 4 e 2 x ( e 2 x + 1 ) 2 f'(x) = \frac{4}{e^{-2x}(e^{2x}+1)^2} = \boxed{\frac{4e^{2x}}{(e^{2x}+1)^2}} f′(x)=e−2x(e2x+1)24=(e2x+1)24e2x
第三步:化成简洁形式 1 − tanh 2 ( x ) 1 - \tanh^2(x) 1−tanh2(x)
回到 f ′ ( x ) = ( e x + e − x ) 2 − ( e x − e − x ) 2 ( e x + e − x ) 2 f'(x) = \frac{(e^x+e^{-x})^2 - (e^x-e^{-x})^2}{(e^x+e^{-x})^2} f′(x)=(ex+e−x)2(ex+e−x)2−(ex−e−x)2
拆开:
f ′ ( x ) = 1 − ( e x − e − x ) 2 ( e x + e − x ) 2 f'(x) = 1 - \frac{(e^x-e^{-x})^2}{(e^x+e^{-x})^2} f′(x)=1−(ex+e−x)2(ex−e−x)2
而 tanh ( x ) = e x − e − x e x + e − x \tanh(x) = \frac{e^x - e^{-x}}{e^x + e^{-x}} tanh(x)=ex+e−xex−e−x,所以 tanh 2 ( x ) = ( e x − e − x ) 2 ( e x + e − x ) 2 \tanh^2(x) = \frac{(e^x-e^{-x})^2}{(e^x+e^{-x})^2} tanh2(x)=(ex+e−x)2(ex−e−x)2
代入得:
f ′ ( x ) = 1 − tanh 2 ( x ) \boxed{f'(x) = 1 - \tanh^2(x)} f′(x)=1−tanh2(x)
1、导数范围
Tanh 导数: f ′ ( x ) = 1 − tanh 2 ( x ) f'(x) = 1 - \tanh^2(x) f′(x)=1−tanh2(x),最大值在 x = 0 x=0 x=0 处取到 1 ,其余位置都 < 1 。
对比:
Tanh 比 sigmoid 好一些(最大值是 1 而非 0.25),但大部分情况下导数仍然远小于 1。
2、为什么会梯度消失
反向传播时,梯度逐层回传,每过一层要乘以那一层的激活函数导数:
∂ L ∂ w ( 1 ) ∝ f ′ ( z ( n ) ) ⋅ f ′ ( z ( n − 1 ) ) ⋯ f ′ ( z ( 1 ) ) \frac{\partial L}{\partial w^{(1)}} \propto f'(z^{(n)}) \cdot f'(z^{(n-1)}) \cdots f'(z^{(1)}) ∂w(1)∂L∝f′(z(n))⋅f′(z(n−1))⋯f′(z(1))
一堆小于 1 的数连乘 → 结果指数级趋近于 0 → 前面层的梯度几乎为零 → 权重更新不动 → 梯度消失。
3、数值感受
假设每层 f ′ ( z ) ≈ 0.7 f'(z) \approx 0.7 f′(z)≈0.7(已经算比较大了):
20 层后梯度只剩千分之一,前面的层几乎学不到东西。
如果是 sigmoid, f ′ ( z ) f'(z) f′(z) 最大才 0.25,衰减更惨: 0.25 10 ≈ 10 − 6 0.25^{10} \approx 10^{-6} 0.2510≈10−6。
4. 总结
- Tanh 导数最大值为 1(sigmoid 为 0.25),所以缓解了梯度消失
- 但只要导数普遍 < 1,连乘后仍然会消失,只是比 sigmoid 慢一些,并没有根本解决
- 真正解决梯度消失的方案:ReLU(正区间导数恒为 1,不衰减)、残差连接(跳过层,梯度直通)
| 导数范围 | 最大值 | |
|---|---|---|
| Sigmoid | (0, 0.25] | 0.25 |
| Tanh | (0, 1] | 1 |
| 经过层数 | 梯度衰减为 |
|---|---|
| 5 层 | 0.7 5 = 0.168 0.7^5 = 0.168 0.75=0.168 |
| 10 层 | 0.7 10 = 0.028 0.7^{10} = 0.028 0.710=0.028 |
| 20 层 | 0.7 20 = 0.0008 0.7^{20} = 0.0008 0.720=0.0008 |
3.3 ReLU系列
ReLU系列的激活函数包括ReLU、Leaky ReLU、PReLU、ELU,在PReLU的基础上,又发展出Dice激活函数。这个系列的激活函数采用分段的思路,其中一段为线性,从而解决部分梯度消失的问题。
3.3.1 ReLU
ReLU(rectified linear unit)激活函定义为式子(7),函数图像如图6所示。
f ′ ( x ) = { 1 , x > 0 , 0 , x ≤ 0. \begin{equation} f'(x)=\begin{cases} 1, & x>0,\\ 0, & x\le 0. \end{cases} \tag{7} \end{equation} f′(x)={1,0,x>0,x≤0.(7)
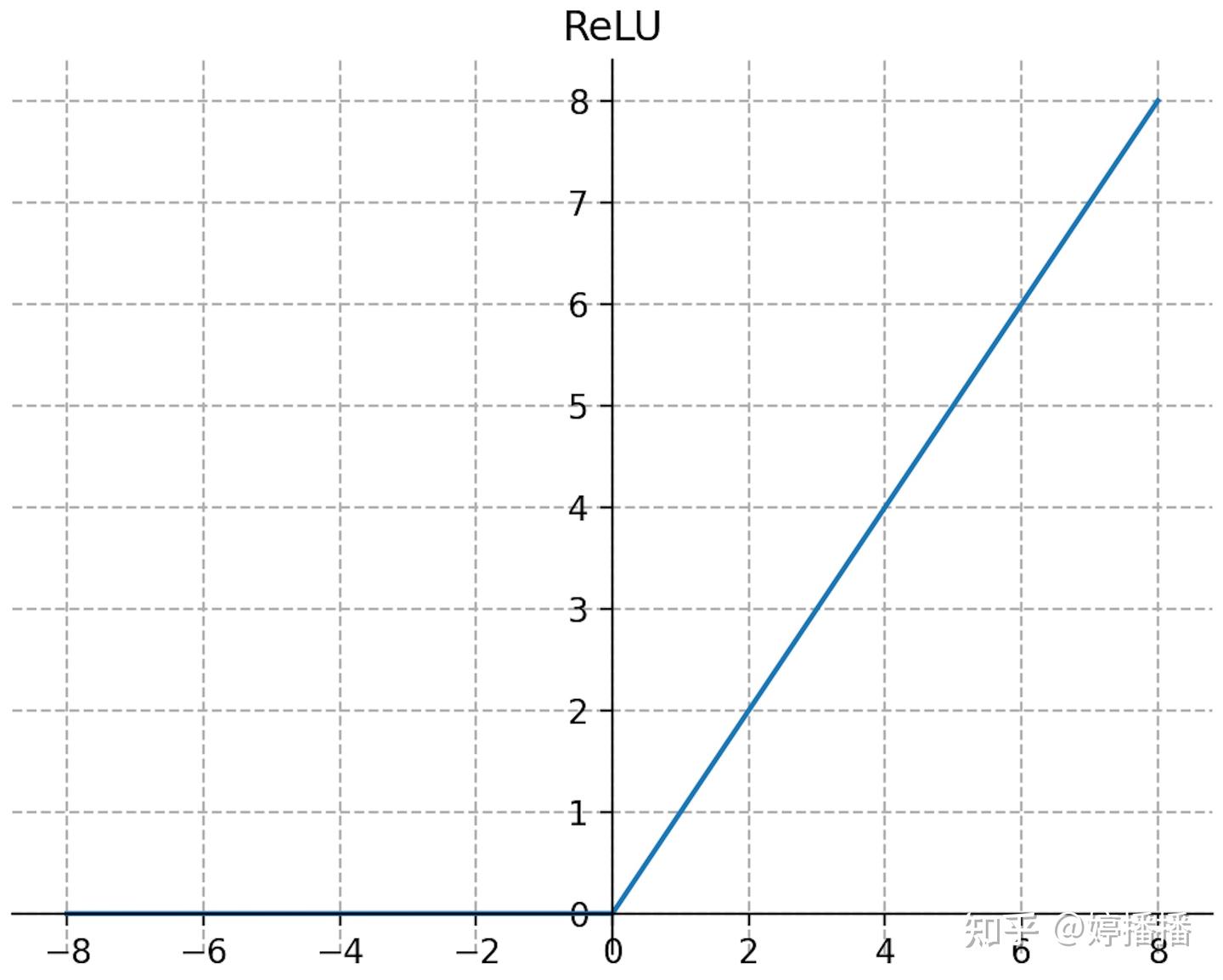
图6 ReLU函数
ReLU函数的分段性使其具有如下优点:(1) 输入>0时保持梯度为恒定值不衰减,从而缓解梯度消失问题;(2) 输入<0时导数为0,当神经元激活值为负值时,梯度不再更新,增加了网络的稀疏性,从而使模型更具鲁棒性,这点类似dropout但不完全等同dropout;(3) 计算速度快,ReLU函数的导数是if-else的实现逻辑,计算非常方便快速。
ReLU 三个优点的详细讲解
1. 为什么 x > 0 x > 0 x>0 时缓解梯度消失?
一、反向传播的本质:链式法则 = 沿路径逐步相乘
以 2 层网络为例,前向传播:
x ──×w1──→ z1 ──f──→ a1 ──×w2──→ z2 ──f──→ a2 ──→ L
各步含义:
- z 1 = w 1 ⋅ x z_1 = w_1 \cdot x z1=w1⋅x(线性变换)
- a 1 = f ( z 1 ) a_1 = f(z_1) a1=f(z1)(激活函数)
- z 2 = w 2 ⋅ a 1 z_2 = w_2 \cdot a_1 z2=w2⋅a1(线性变换)
- a 2 = f ( z 2 ) a_2 = f(z_2) a2=f(z2)(激活函数)
- L L L:损失函数
二、对 w 1 w_1 w1 求梯度的链路
从 L L L 出发,沿计算图一路走到 w 1 w_1 w1,每一步求"输出对输入的局部导数":
链路:L → a2 → z2 → a1 → z1 → w1
∂L ∂a2 ∂z2 ∂a1 ∂z1 ── × ─── × ─── × ─── × ─── ∂a2 ∂z2 ∂a1 ∂z1 ∂w1逐步解释每个局部导数从哪来:
|这一步|前向公式|局部导数|为什么|
|-|-|-|-|
| ∂ a 2 ∂ z 2 \frac{\partial a_2}{\partial z_2} ∂z2∂a2| a 2 = f ( z 2 ) a_2 = f(z_2) a2=f(z2)| f ′ ( z 2 ) f'(z_2) f′(z2)|激活函数对其输入求导|
| ∂ z 2 ∂ a 1 \frac{\partial z_2}{\partial a_1} ∂a1∂z2| z 2 = w 2 ⋅ a 1 z_2 = w_2 \cdot a_1 z2=w2⋅a1| w 2 w_2 w2|乘法里对 a 1 a_1 a1 求导,剩下 w 2 w_2 w2|
| ∂ a 1 ∂ z 1 \frac{\partial a_1}{\partial z_1} ∂z1∂a1| a 1 = f ( z 1 ) a_1 = f(z_1) a1=f(z1)| f ′ ( z 1 ) f'(z_1) f′(z1)|激活函数对其输入求导|
| ∂ z 1 ∂ w 1 \frac{\partial z_1}{\partial w_1} ∂w1∂z1| z 1 = w 1 ⋅ x z_1 = w_1 \cdot x z1=w1⋅x| x x x|乘法里对 w 1 w_1 w1 求导,剩下 x x x|
所以完整梯度为:∂ L ∂ w 1 = ∂ L ∂ a 2 ⋅ f ′ ( z 2 ) ⋅ w 2 ⋅ f ′ ( z 1 ) ⋅ x \frac{\partial L}{\partial w_1} = \frac{\partial L}{\partial a_2} \cdot f'(z_2) \cdot w_2 \cdot f'(z_1) \cdot x ∂w1∂L=∂a2∂L⋅f′(z2)⋅w2⋅f′(z1)⋅x
注意 : w 2 w_2 w2 出现在式子里,不是在对 w 2 w_2 w2 求导,而是梯度从 z 2 z_2 z2 传回 a 1 a_1 a1 时必须"穿过" w 2 w_2 w2(因为前向时 z 2 = w 2 ⋅ a 1 z_2 = w_2 \cdot a_1 z2=w2⋅a1,对 a 1 a_1 a1 的导数就是 w 2 w_2 w2)。
三、推广到 n n n 层
如果有 n n n 层,梯度传到第 1 层要穿过中间所有层,每层贡献一个 f ′ ( z i ) ⋅ w i f'(z_i) \cdot w_i f′(zi)⋅wi:
∂ L ∂ w 1 = ∂ L ∂ a n ⋅ f ′ ( z n ) ⋅ w n ⋅ f ′ ( z n − 1 ) ⋅ w n − 1 ⋯ f ′ ( z 2 ) ⋅ w 2 ⏟ 梯度穿过第 2~n 层时被连乘的系数 ⋅ f ′ ( z 1 ) ⋅ x \frac{\partial L}{\partial w_1} = \frac{\partial L}{\partial a_n} \cdot \underbrace{f'(z_n) \cdot w_n \cdot f'(z_{n-1}) \cdot w_{n-1} \cdots f'(z_2) \cdot w_2}_{\text{梯度穿过第 2\textasciitilde n 层时被连乘的系数}} \cdot f'(z_1) \cdot x ∂w1∂L=∂an∂L⋅梯度穿过第 2~n 层时被连乘的系数 f′(zn)⋅wn⋅f′(zn−1)⋅wn−1⋯f′(z2)⋅w2⋅f′(z1)⋅x
层数越多,连乘次数越多 → 系数大小决定了梯度的命运。
四、连乘系数 > 1 还是 < 1?
w i w_i wi 通过合理初始化控制在 ≈1,所以关键看 f ′ ( z i ) f'(z_i) f′(zi):
| 激活函数 | f ′ ( z ) f'(z) f′(z) 典型值 | 每层系数 ≈ | 10 层连乘 | 结果 |
|---|---|---|---|---|
| Sigmoid | ≤ 0.25 | 0.25 | 0.25 9 ≈ 0.000004 0.25^9 ≈ 0.000004 0.259≈0.000004 | 梯度消失 |
| Tanh | 通常 ≈ 0.7 | 0.7 | 0.7 9 ≈ 0.04 0.7^9 ≈ 0.04 0.79≈0.04 | 仍在衰减 |
| ReLU( x > 0 x>0 x>0) | = 1 | 1 | 1 9 = 1 1^9 = 1 19=1 | 稳定传递 |
五、围绕结论的三个自然追问
Q1:导数 = 1,不会梯度爆炸吗?
不会。 f ′ = 1 f'=1 f′=1 是中性的,不缩小也不放大。梯度爆炸是 w i w_i wi 过大导致的(初始化问题),和 ReLU 无关。
Q2: y = x y = x y=x** 导数也是 1,为什么不直接用?**
y = x y=x y=x 是纯线性,多层叠加 W n ⋅ W n − 1 ⋯ W 1 ⋅ x = W 总 ⋅ x W_n \cdot W_{n-1} \cdots W_1 \cdot x = W_{总} \cdot x Wn⋅Wn−1⋯W1⋅x=W总⋅x,等价于单层,没有表达能力。ReLU 负半轴截断为 0,这个"折线"引入了非线性,多层叠加才有意义。
Q3:负半轴用 y = − x y = -x y=−x (即 ∣ x ∣ |x| ∣x∣)不行吗?
∣ x ∣ |x| ∣x∣ 把 +3 和 -3 都映射到 3 → 丢失正负信息。且完全对称,优化困难。改进方案是 Leaky ReLU(负半轴 0.01 x 0.01x 0.01x),保留区分性,避免神经元死亡。
一句话总结
反向传播 = 链式法则 = 沿路径连乘局部导数。ReLU 在 x > 0 x>0 x>0 时局部导数恒为 1,梯度穿过时不衰减,从根源上消除了激活函数导致的梯度消失。
2. 为什么 x < 0 x < 0 x<0 导数为 0 反而是好事?
为什么稀疏性带来鲁棒性?(具体例子 + 论据)
一、具体数值例子
假设一个分类任务:识别输入是"猫"还是"狗"。某层有 6 个神经元。
密集网络(Sigmoid,所有神经元都输出非零值)
干净的猫图输入后,6个神经元的输出:
0.72, 0.45, 0.61, 0.38, 0.55, 0.49
下一层计算:z = w1×0.72 + w2×0.45 + w3×0.61 + w4×0.38 + w5×0.55 + w6×0.49
= 所有6个神经元都在贡献
现在输入有噪声(比如图片模糊了),每个神经元输出都被扰动:
带噪声的猫图,6个神经元输出:
0.68, 0.52, 0.57, 0.44, 0.60, 0.43
偏移: -0.04, +0.07, -0.04, +0.06, +0.05, -0.06
6 个神经元都偏移了 → 6 个误差项全部累加到下一层 → 总误差被放大。
稀疏网络(ReLU,大部分输出为 0)
干净的猫图输入后,6个神经元的输出:
2.3, 0, 0.7, 0, 0, 1.1
只有3个在工作,其余3个 = 0
下一层计算:z = w1×2.3 + w2×0 + w3×0.7 + w4×0 + w5×0 + w6×1.1
= 只有3个神经元在贡献
带噪声时:
带噪声的猫图,6个神经元的输出:
2.1, 0, 0.8, 0, 0, 0.9
偏移: -0.2, 0, +0.1, 0, 0, -0.2
只有 3 个激活的神经元会传递误差,另外 3 个输出始终是 0(噪声把它们的 z z z 从 -1.5 变成 -1.2,ReLU 之后还是 0)→ 误差传播通道更少 → 下一层受到的干扰更小。
二、更深的原因:减少参数间的相互依赖
这不是我编的,有论文支持:
"Sparse representations are more efficient and less prone to overfitting. By reducing the number of active neurons at any time, ReLU decreases the chances of interdependencies between parameters ."
(来源:Medium, Meet Patel, "Understanding the Rectified Linear Unit")
什么意思?用例子说明:
密集网络中:
下一层的输出 = w1×0.72 + w2×0.45 + w3×0.61 + w4×0.38 + w5×0.55 + w6×0.49
训练时要同时调 w1~w6 来达到目标值
→ w1调大一点,可能要靠w3调小来补偿
→ 6个参数互相牵制、互相依赖(co-adaptation)
→ 学到的是"6个参数的特定配合",而不是每个参数独立有意义的特征
稀疏网络中:
下一层的输出 = w1×2.3 + w3×0.7 + w6×1.1 (只有3项)
训练时只需调 w1, w3, w6
→ 参数之间的依赖关系更少
→ 每个权重更倾向于学到独立有意义的特征
→ 换一个输入,激活的神经元变了,那些权重照样能独立工作
三、学术论据
- Layton et al. (2024),"ReLU, Sparseness, and the Encoding of Optic Flow in Neural Networks":
实验证明 ReLU/Leaky ReLU 网络比 GELU/Mish 网络对噪声输入 (noisy optic flow) 和新环境有更好的鲁棒性和泛化能力,并将此归因于 ReLU 产生的稀疏编码。
- Sahoo et al. (2020),"Selectivity and robustness of sparse coding networks":
稀疏编码网络中的群体非线性(thresholding,类似 ReLU 截断)提高了对首选刺激的选择性,并能保护网络不受对抗性扰动影响。
四、一句话总结
稀疏性 → 每个输入只激活少量神经元 → 噪声传播通道更少,参数间依赖更弱 → 网络对扰动更不敏感 → 鲁棒性更强。
这不是"直觉上好像对",而是有实验验证的结论。
3. 计算速度:ReLU 真的比 Sigmoid/Tanh 快吗?
Sigmoid/Tanh 反向传播时可以复用前向结果,不算慢。但还是有差别:
前向传播的差异
指数运算
exp()在硬件层面比一次比较操作慢得多(通常慢 5-10 倍)。反向传播的差异
ReLU 连乘法都省了,只需判断正负。
总结
Sigmoid/Tanh 虽然能复用前向结果简化反向计算,但前向本身就需要算指数,这是真正的性能瓶颈。ReLU 前向反向都只需要一次比较操作,在大规模网络中这个差距会被放大。
ReLU函数的缺点也很明显:(1) 输入>0时梯度为1,可能导致爆炸问题;(2) 输入<0时导数为0,一旦神经元激活值为负,则神经元进入永久性dead状态,梯度不再更新,导致梯度消失问题,学习率过大容易导致所有神经元都进入dead状态,所以需设置较小的学习率;(3) ReLU的输出均值大于0,容易改变输出的分布,可以通过batch normalization缓解这个问题。
ReLU 的三个缺点详解
缺点一:输入 > 0 时梯度恒为 1,可能导致梯度爆炸
先回顾之前的讨论
之前我说过: f ′ = 1 f'=1 f′=1 是中性的,不放大也不缩小。这没错------ReLU 本身不制造爆炸。但问题在于:ReLU 不再帮你"刹车"。
具体解释
回忆梯度连乘中每层的系数 = f ′ ( z i ) ⋅ w i f'(z_i) \cdot w_i f′(zi)⋅wi:
w ** 多大就传多大,没有衰减,因为导数是1。**
10 层连乘: 1.5 10 = 57.7 1.5^{10} = 57.7 1.510=57.7 → 梯度爆炸。
Sigmoid/Tanh 的 f ′ < 1 f' < 1 f′<1 虽然导致梯度消失,但同时也"天然刹车"防止爆炸。ReLU 去掉了这个刹车------消失问题解决了,但爆炸问题暴露出来了。
解决方案
- 合理的权重初始化(He 初始化: w ∼ N ( 0 , 2 / n ) w \sim N(0, \sqrt{2/n}) w∼N(0,2/n ))
- 梯度裁剪(Gradient Clipping)
- Batch Normalization
缺点二:Dead ReLU(神经元永久死亡)
什么是 Dead ReLU?
如果某个神经元的输入 z z z 变成了永久的负值 → ReLU 输出永远为 0 → 导数永远为 0 → 收不到梯度 → 权重永远不更新 → 这个神经元永远活不过来。
用具体例子说明是怎么"死"的
初始状态:
z = w1×x1 + w2×x2 + b = 0.3(正值,正常工作)
一次学习率过大的更新后:
b 从 0.5 被更新为 -5.0(跳太远了)
之后不管什么输入:
z = w1×x1 + w2×x2 + (-5.0)
即使 w1×x1 + w2×x2 = 3,z = 3 - 5 = -2 < 0 → 输出0
输出0 → 梯度为0 → w1、w2、b都收不到梯度 → 无法更新
→ b永远是-5.0 → z永远为负 → 永久死亡
恶性循环:一旦掉进去就出不来了。
为什么学习率大更容易导致死亡?
学习率小(lr = 0.001):
b: 0.5 → 0.5 - 0.001×梯度 → 0.497 (小幅调整,不会跳太远)
学习率大(lr = 0.1):
b: 0.5 → 0.5 - 0.1×梯度 → -4.5 (一步跳到负值区域 → 死了)
学习率越大 → 参数更新幅度越大 → 越容易一步把神经元推入永久负值区 → dead 神经元越多。极端情况下,所有神经元都死了,网络完全停止学习。
解决方案
- 使用较小的学习率
- Leaky ReLU:负半轴给一个小斜率 0.01 x 0.01x 0.01x → 导数 = 0.01 而不是 0 → 还能收到微弱梯度 → 有机会"活过来"
- PReLU:负半轴斜率可学习
- 合理的偏置初始化( b b b 初始为小正值,如 0.01)
缺点三:输出均值 > 0,非零中心化
回忆之前讲过的零中心化问题
ReLU 输出范围是 [ 0 , + ∞ ) [0, +\infty) [0,+∞)------全是非负数 ,均值必然 > 0。
这和 Sigmoid 输出 ( 0 , 1 ) (0, 1) (0,1) 是同样的问题:
下一层某神经元的梯度:
∂L/∂w_j = δ × a_j
如果 a_j 全部 ≥ 0(ReLU的输出):
→ 所有 w_j 的梯度符号和 δ 一致
→ 全正或全负
→ 权重更新方向被绑定
→ zigzag 震荡下降
和之前讲 Sigmoid 的问题完全一样:非零中心化 → 梯度方向被锁 → 收敛效率低。
对比
ReLU 解决了梯度消失,但把"非零中心化"这个老问题又带回来了。
解决方案
Batch Normalization:在每层激活后,对输出做归一化(减均值、除方差),强制把分布拉回均值 ≈ 0。
ReLU输出:2.3, 0, 0.7, 0, 0, 1.1 均值 > 0
BN之后: 1.2, -1.1, -0.5, -1.1, -1.1, 0.0 均值 ≈ 0 ✓
相比sigmoid和tanh,ReLU可明显改善梯度消失的问题,且计算高效,因此在业界被广泛使用。
ReLU的非线性
ReLU的非线性来源于不同隐层对不同神经元的激活,如图7所示,当神经元的输出为正时,神经元才被激活,即图7中蓝色神经元所示。虽然每个被激活的神经元的输入输出是线性关系,但通过每层选择部分神经元激活实现了输入输出的非线性。
图7 ReLU激活函数对神经元的选择
ReLU对神经元的选择,类似dropout,但两者原理不同。深度学习场景数据量复杂高维,ReLU根据神经元的输出进行选择,多层神经元的选择相当于在原始输入数据层增加稀疏度,这也是ReLU增加模型鲁棒性的原因,增加数据稀疏度可以起到去除噪音的效果。Dropout是动态去除一些神经元到下一层的连接,相当于是动态L2正则化,通过打压隐层连接参数W实现稀疏性。
3.3.2 基于ReLU的改进
ReLU激活函数使得输出为负值的神经元永久性dead,这个问题可以通过对ReLU函数负半轴的输出进行调整,使其不为0,从而得到解决。Leaky Relu、elu、selu等函数则是采用这种思路解决神经元永久性dead问题。
3.3.2.1 Leaky ReLU
Leaky ReLU激活函数如式子(8)所示,函数图像如图8所示。
f ( x ) = max ( α x , x ) = { x , x > 0 , α x , x ≤ 0. \begin{equation} f(x)=\max(\alpha x,x)=\begin{cases} x, & x>0,\\ \alpha x, & x\le 0. \end{cases} \tag{8} \end{equation} f(x)=max(αx,x)={x,αx,x>0,x≤0.(8)
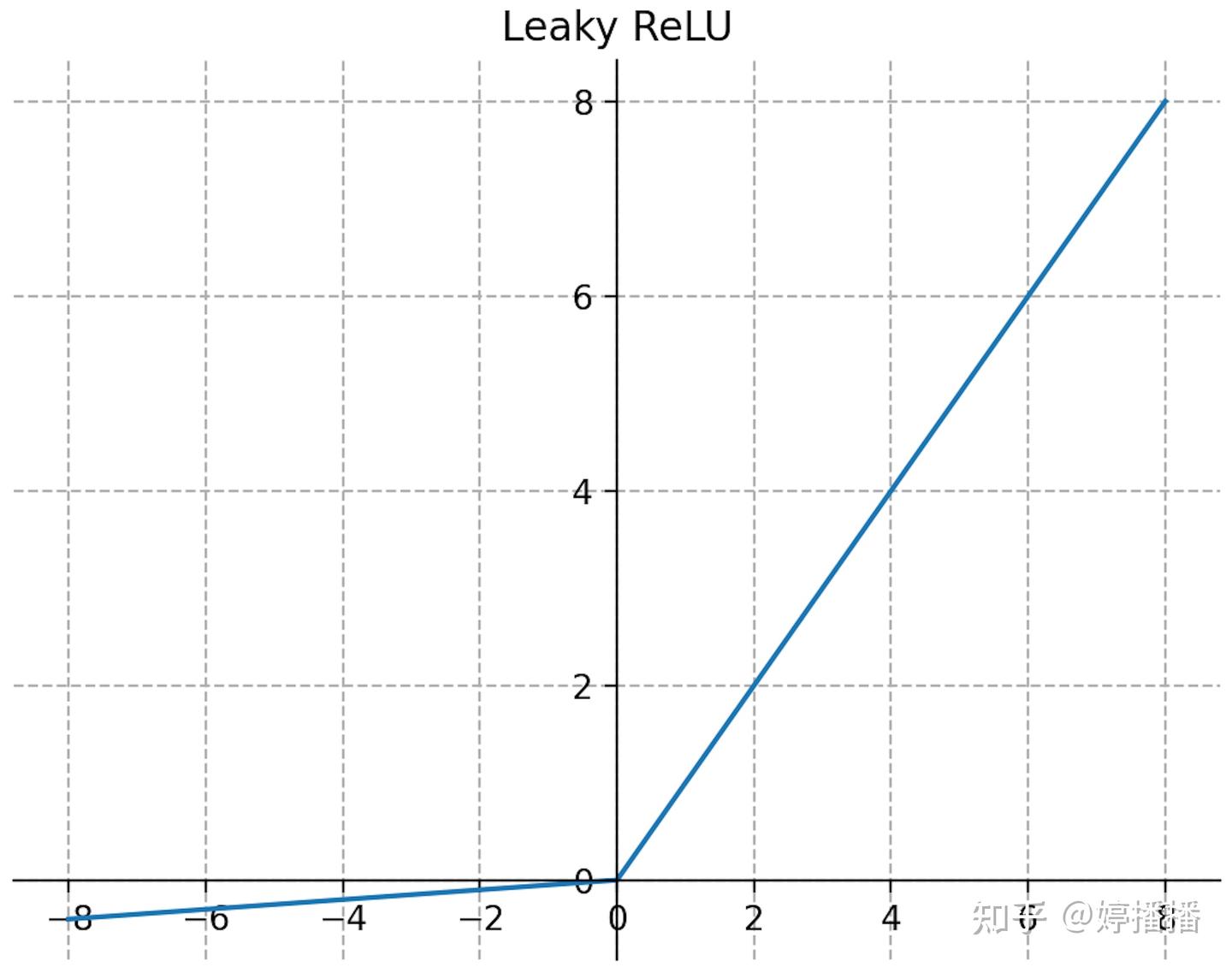
图8 Leaky ReLU函数
Leaky ReLU函数中的参数 α \alpha α 非常小,即负半轴的输入输出的线性斜率小。其优点是通过在负半轴引入非0线性输出,解决了ReLU的神经元dead问题;同时也带来了参数 α \alpha α 需要手工调整的缺点。理论上Leaky ReLU激活函数效果好,但其优势在实际场景中并未得到证明,因此在具体业务中使用不多。
3.3.2.2 ELU和SELU
类似Leaky ReLU思路解决神经元dead问题的还有ELU和SELU,式子(9)为ELU函数,图9为其函数图像,式子(10)为SELU函数。从定义可以看出,SELU在ELU的基础上引入了一个缩放系数,其形状和ELU相似。
ELU ( x ) = { x , x > 0 , α ( e x − 1 ) , x ≤ 0. \begin{equation} \operatorname{ELU}(x)=\begin{cases} x, & x>0,\\ \alpha\left(e^x-1\right), & x\le0. \end{cases} \tag{9} \end{equation} ELU(x)={x,α(ex−1),x>0,x≤0.(9)
SELU ( x ) = λ { x , x > 0 , α ( e x − 1 ) , x ≤ 0. \begin{equation} \operatorname{SELU}(x)=\lambda\begin{cases} x, & x>0,\\ \alpha\left(e^x-1\right), & x\le 0. \end{cases} \tag{10} \end{equation} SELU(x)=λ{x,α(ex−1),x>0,x≤0.(10)
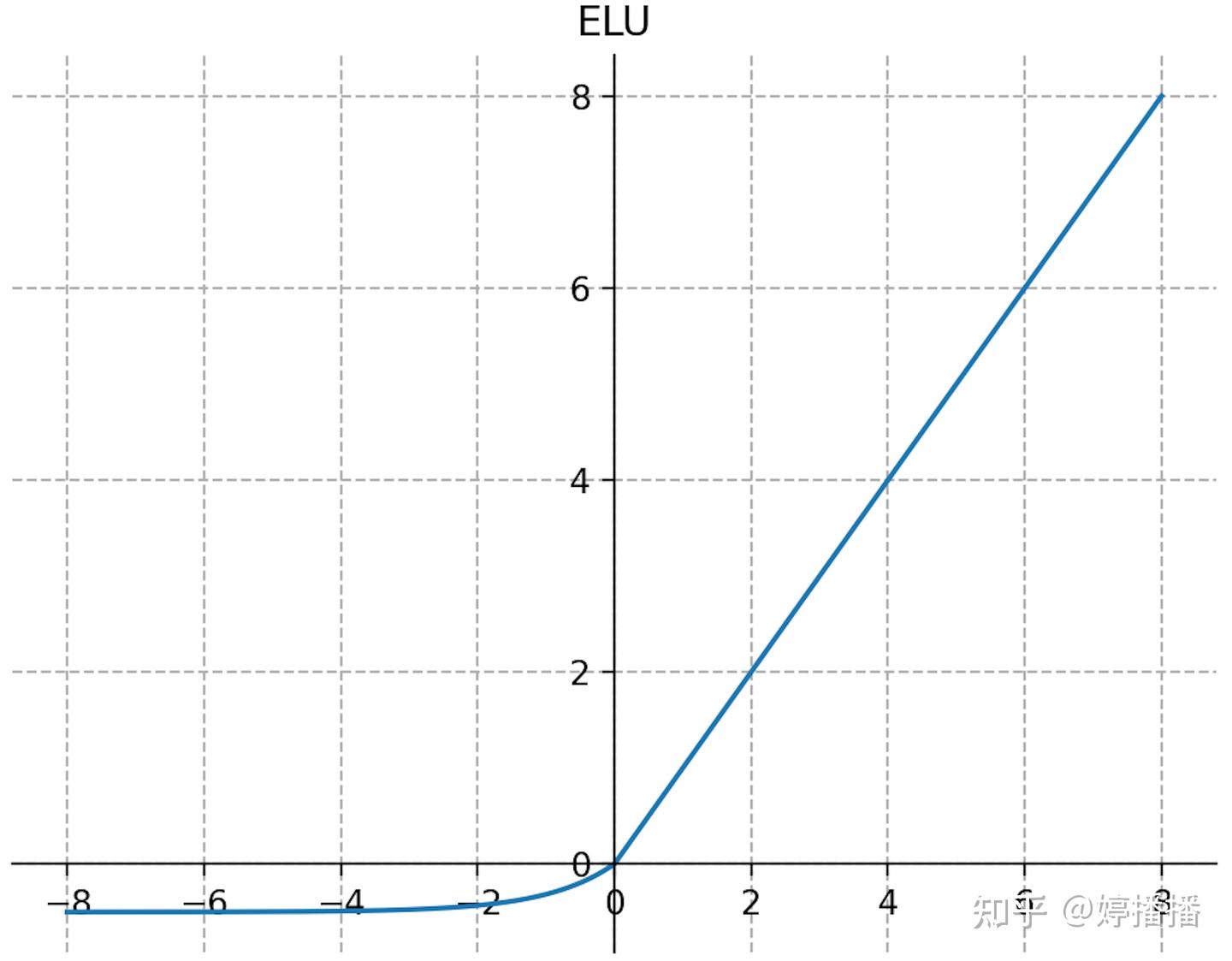
图9 ELU函数
ELU的导数为 f ′ ( x ) = { 1 , x > 0 , α e x , x ≤ 0. \begin{equation} f'(x)=\begin{cases} 1, & x>0,\\ \alpha e^x, & x\le0. \end{cases} \tag{导数} \end{equation} f′(x)={1,αex,x>0,x≤0.(导数) 。
ELU结合了ReLU和sigmoid,具备两者的优点:(1) 在输入正半轴为线性,无饱和性,使其可以缓解梯度消失问题;(2) 在输入负半轴具有软饱和性,其下边界为 − α -\alpha −α ,软饱和性一方面可以解决ReLU中神经元永久性dead问题,另一方面可以使ELU对输入噪声具有更强的鲁棒性;(3) 输出的均值接近0,可以缓解均值不为0带来的输出分布变化问题,加快模型收敛。
ELU在输入负半轴采用指数的形式,这导致ELU相比ReLU存在计算复杂度较高的缺点。
SELU和ELU具有同样的特点。理论上ELU优于ReLU,但在推荐实际应用场景没有得到充分证明,可能和推荐领域网络深度不深有关系,在视觉领域网络层数深,相比ReLU、Leaky ReLU,ELU可以在网络收敛性上有优势。
3.3.2.3 PReLU
Leaky ReLU函数中引入了参数 α \alpha α ,存在依赖人工调整的缺陷,针对此,PReLU(Parametric ReLU)采用把 α \alpha α 当成神经元的一个参数的思路,通过网络学习得到,从而使其不依赖于人工。
PReLU的定义和函数图像跟Leaky ReLU相同,如式子(8)和图8所示,其特点也和Leaky ReLU相同。不同的是,PReLU通过网络自身学习参数\alpha,使其和当前场景的数据更适配。
3.3.2.4 Dice
Dice(Data Adaptive Activation Function)激活函数出自论文DIN3,发表于KDD2018,是针对PReLU的改进。ReLU系列的激活函数,不管数据分布如何,其阶跃点均在 x = 0 x=0 x=0 处,论文根据对不同数据分布的输入其激活函数的阶跃点应进行对应调整的思路,提出Dice。
Dice的定义如式子(11)所示,其中p(s)为阶跃点的指示函数,如图10所示,Es和Vars为每个输入batch的均值和方差。图10对比了PReLU和Dice的阶跃点指示函数,可以看出,Dice激活函数的阶跃点随着输入数据的分布动态变化。
f ( s ) = { s , s > 0 , α s , s ≤ 0 , = p ( s ) ⋅ s + ( 1 − p ( s ) ) ⋅ α s , p ( s ) = 1 1 + e − s − E s Var s + ε \begin{equation} f(s)=\begin{cases} s, & s>0,\\ \alpha s, & s\le0, \end{cases} = p(s)\cdot s + \bigl(1-p(s)\bigr)\cdot \alpha s,\quad p(s)=\frac{1}{1+e^{-\frac{s-Es}{\sqrt{\operatorname{Var}s+\varepsilon}}}} \tag{11} \end{equation} f(s)={s,αs,s>0,s≤0,=p(s)⋅s+(1−p(s))⋅αs,p(s)=1+e−Vars+ε s−Es1(11)
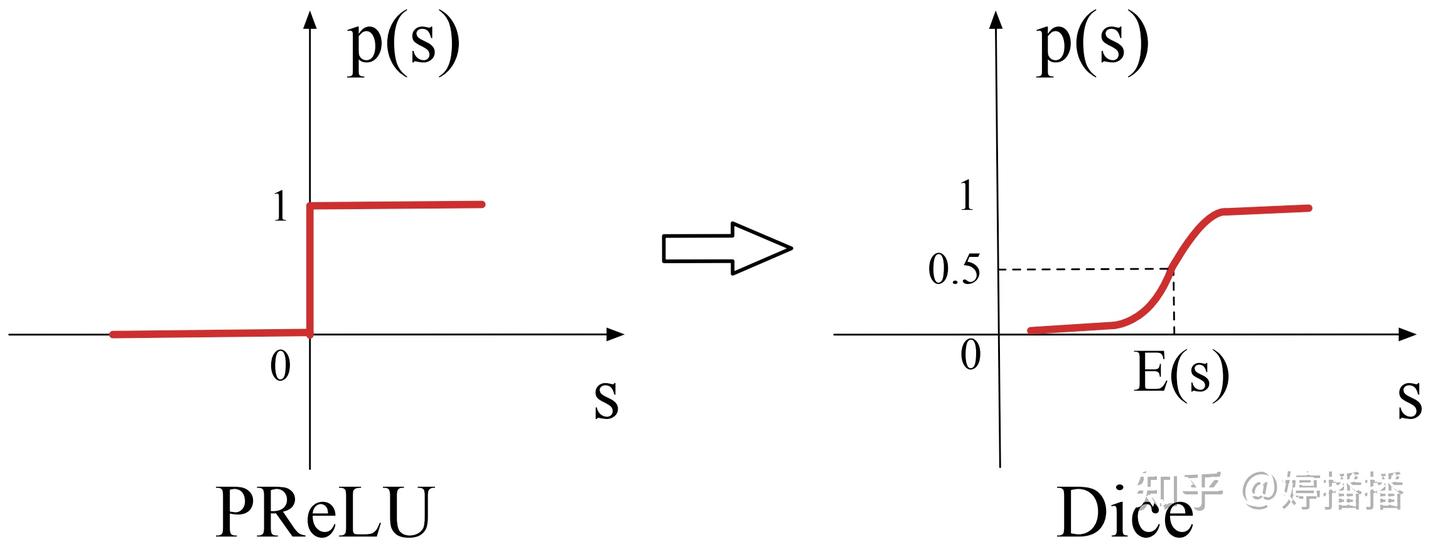
图10 PReLU和Dice阶跃点指示函数p(s)
Dice激活函数的优点在于可以根据输入数据的分布灵活调整阶跃点,使其和输入数据有更好的适配性。Dice的改进出发点和Batch nornalization的出发点相同,都是为了解决数据分布偏移问题。由于Dice的阶跃点需根据输入进行计算,带来了计算复杂度高的缺点。
3.4 Maxout
Maxout激活函数是对ReLU和Leaky ReLU的一般化归纳,其定义如式子(12)所示。当 w 1 = 0 , b 1 = 0 , w 2 = 1 , b 2 = 0 w_1 = 0,\quad b_1 = 0,\quad w_2 = 1,\quad b_2 = 0 w1=0,b1=0,w2=1,b2=0 时,为ReLU激活函数。当 w 1 = α , b 1 = 0 , w 2 = 1 , b 2 = 0 w_1=\alpha,\quad b_1=0,\quad w_2=1,\quad b_2=0 w1=α,b1=0,w2=1,b2=0 时,为Leaky ReLU激活函数。
f ( x ) = max ( w 1 x + b 1 , w 2 x + b 2 ) f(x)=\max(w_1x+b_1,w_2x+b_2) f(x)=max(w1x+b1,w2x+b2)
图11 Maxout函数
Maxout激活函数具有ReLU的优点:(1) 输出的不饱和性使其不存在梯度消失问题;(2) 计算简单高效。其缺点在于每个神经元的参数增加了一倍导致整个网络的参数量增加。
3.5 softplus
softplus激活函数的定义如式子(13)所示,图像如图12所示,从函数定义和图像可以看出,softplus是ReLU的平滑版本。
f ( x ) = log ( 1 + e x ) f(x)=\log(1+e^x) f(x)=log(1+ex)
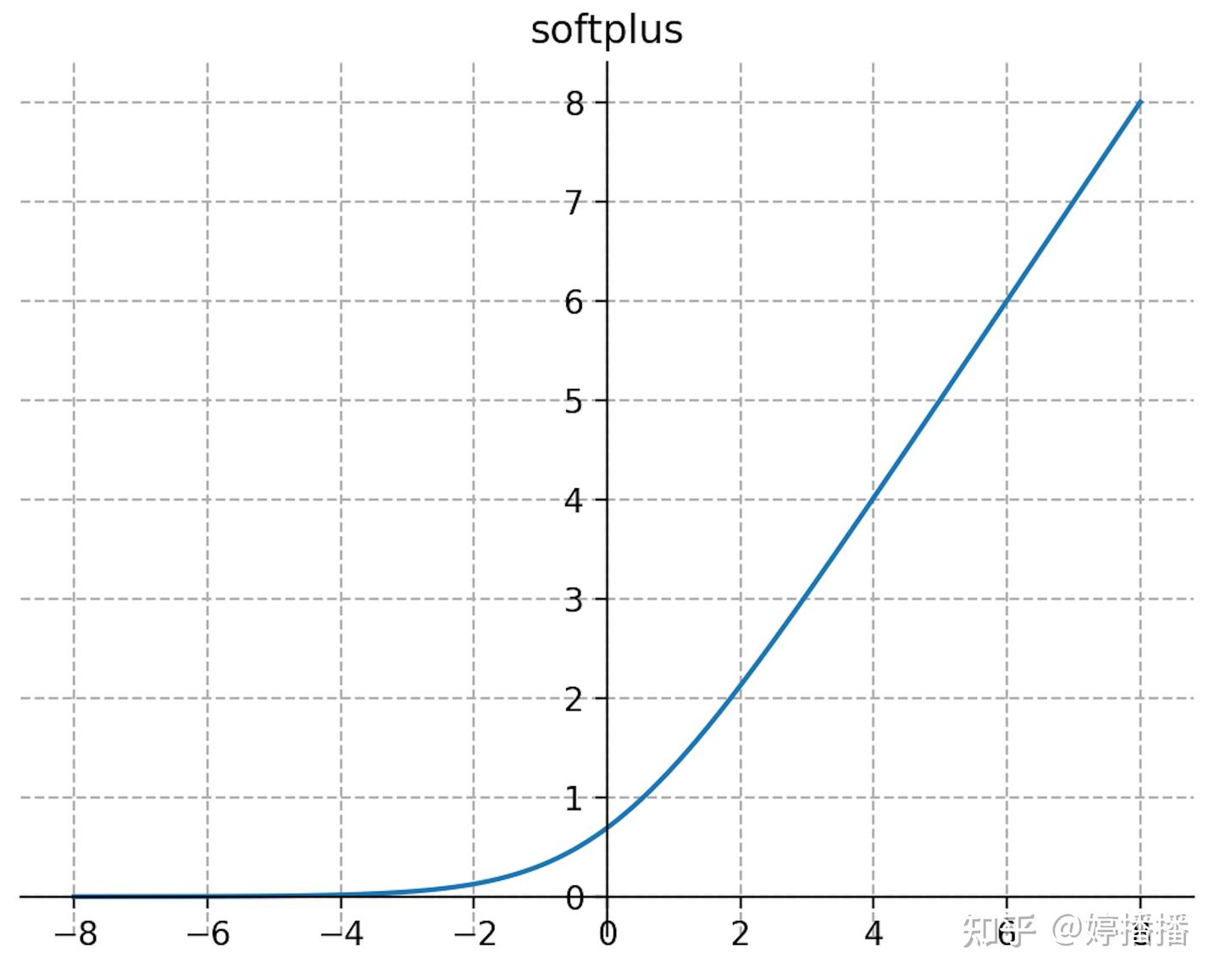
图12 softplus函数
softplus用的比较少,但在我所在的业务中被使用时,取得了比较好的效果,这个会在后面第4部分分享激活函数的业务应用中详细展开。
3.6 softmax
softmax激活函数是sigmoid激活函数的扩展,如式子(14)所示,通常用于多分类网络最后的输出层。softmax通过指数归一化方式,可以强化各项之间的区分度。
f ( x ) i = e x i ∑ k = 1 N e x k f(x)i=\dfrac{e^{x_i}}{\sum{k=1}^N e^{x_k}} f(x)i=∑k=1Nexkexi
4 激活函数的业务应用
激活函数的特点决定了其适用场景,在实际使用过程中,需根据具体的业务特点采用不同的激活函数。在多种激活函数中,目前使用最广泛的是ReLU,主要因为其对梯度消失问题的缓解和计算简单高效性。
4.1 如何选择激活函数
在网络的不同隐层,一般会选择相同的激活函数,不会在不同隐层使用不同的激活函数,这样会增加网络的学习难度。
好问题!这个说法背后有几个核心原因:
1. 梯度流不一致 → 训练不稳定
不同激活函数的梯度范围差异很大:
- Sigmoid 梯度最大只有 0.25
- ReLU 梯度为 0 或 1
- Tanh 梯度最大为 1
混用时,反向传播经过不同层,梯度尺度忽大忽小,容易加剧梯度消失或爆炸,优化器很难找到一个统一的学习率来适配所有层。
2. 权重初始化方案被破坏
现代初始化方法是针对特定激活函数推导的:
- He 初始化 → 假设用 ReLU
- Xavier 初始化 → 假设用 tanh/sigmoid
它们的数学前提是"每层激活函数相同",以此保证信号方差逐层稳定。混用激活函数会打破这个假设,导致前向传播中信号逐层放大或衰减。
3. 超参数调优复杂度暴增
统一激活函数时,学习率、初始化方式、BatchNorm 配置可以全局共享。混用则意味着:
- 每层可能需要不同的初始化策略
- 不同层对学习率的敏感度不同
- 调参空间从 O(n) 变成 O(n^k)
实际收益却很小,性价比极低。
一句话总结
统一激活函数的本质是让网络各层的数值动态特性一致 ,使得初始化、学习率、归一化等全局设定能同时适配所有层,降低优化难度。
💡 追问引导:你是否好奇------那为什么输出层可以用不同的激活函数(如 softmax),这和隐层的情况有什么本质区别?或者你想进一步理解 He/Xavier 初始化是怎么推导出来的?
如果没有特殊的要求,尽量不使用sigmoid,推荐采用性价比高的激活函数为ReLU。使用ReLU激活函数时,需注意学习率的设置,学习率过大,容易导致网络中很多神经元进入dead状态,影响网络的收敛效果。如果使用ReLU导致的神经元dead状态影响网络效果,可以使用Leaky Relu、PReLU解决此问题。
网络隐层一般使用相同的激活函数,但对于有针对性作用的层,比如gate层,可以使用和隐层不一样的激活函数,这时候需根据具体层的目的来决定使用哪种激活函数。举个例子,mmoe网络中生成expert权重的gate层,其目的是得到各个expert的权重,且希望这些权重有区分度,则在这个层往往使用softmax激活函数。
一个统一的底层逻辑
激活函数的选择,本质上只由一件事决定:这一层的输出在数学和语义上需要满足什么约束。
隐层之间统一激活函数、输出层和 gate 层可以用不同的激活函数,这两件事看似矛盾,实际上都在遵循同一个原则。下面我从三个层面展开。
第一部分:为什么隐层要统一激活函数
隐层在网络中的角色是"通用特征变换器"。第一层隐层接收原始输入、提取低阶特征,第二层在此基础上提取更高阶的特征,依此类推。每一层做的事情性质完全相同------把上一层的特征做非线性变换后传给下一层。
因为每一层的角色一样,所以它们对输出值的约束也一样:不需要和为 1,不需要限制在 0 到 1 之间,不需要表达概率,只需要两个条件------引入非线性(否则多层线性变换等价于一层),以及让梯度能够稳定地向后传播。
既然约束一样,自然用同一种激活函数就够了。而统一之后会带来三个重要好处:
第一,梯度尺度逐层一致。每一层的激活函数梯度范围相同,反向传播时梯度不会因为某一层突然变大或变小而震荡,训练过程更稳定。
第二,初始化方案可以全局适用。现代权重初始化方法(比如 He 初始化、Xavier 初始化)都是在"每层激活函数相同"这个假设下推导出来的。它们的数学目标是让信号的方差在前向传播中保持不变、梯度方差在反向传播中保持不变。如果你第三层用 ReLU、第五层换成 Sigmoid,这些初始化公式的推导前提就被打破了,信号方差会逐层漂移,最终导致训练困难。
第三,超参数调优简单。学习率、BatchNorm 的动量参数、权重衰减系数,都可以全局统一设置。混用激活函数意味着不同层对这些超参数的敏感度不同,你可能需要为每一层单独调参,调参空间急剧膨胀,但实际收益几乎为零------因为隐层之间没有语义差异,用不同激活函数不会让网络学到更多东西。
所以结论是:隐层统一激活函数不是教条,而是因为它们的功能相同、约束相同,统一是最优策略。
第二部分:为什么输出层和 Gate 层可以用不同的激活函数
输出层和 gate 层和隐层有本质区别------它们不是"通用特征变换器",而是"有特定语义的功能模块",它们的输出有明确的数学约束。
先说输出层。如果你在做多分类任务,输出层需要给出各个类别的概率,这些概率必须非负且和为 1。满足这个约束的激活函数是 softmax。如果你在做多标签分类,每个标签独立判断是否存在,每个输出需要是一个独立的 0 到 1 之间的概率值,这时用 sigmoid。如果你在做回归任务,输出是任意实数,不需要任何限制,那就不加激活函数。你看,每种情况选什么激活函数,完全由"输出需要满足什么约束"决定。
再说 gate 层。以 MMoE 为例,gate 层的目的是为多个 expert 分配权重。这些权重需要非负、和为 1(因为最终输出是各 expert 的加权平均),而且希望有区分度(让网络能清楚地表达"更偏好哪个 expert")。Softmax 恰好同时满足这三点:输出非负、和为 1、指数运算会放大 logit 差距从而产生区分度。所以 gate 层用 softmax 是"约束驱动"的必然选择,不是随意为之。
第三部分:LSTM 内部的选择逻辑
LSTM 是理解这个原则的最好案例,因为一个 cell 里同时存在用 sigmoid 和用 tanh 的组件,而且每个选择都有清晰的道理。
先说 forget gate。它的语义是"上一时刻的记忆保留多少比例"。比例这个概念天然在 0 到 1 之间:0 表示完全遗忘,1 表示完全保留。Sigmoid 的输出恰好在 0 到 1 之间,完美匹配这个约束。然后这个比例值会逐元素乘以旧的 cell state,相当于对每一维记忆做"按比例衰减"。
Input gate 同理。它决定新信息写入多少比例,也是一个 0 到 1 之间的比例值,所以也用 sigmoid。
Output gate 也同理。它决定当前 cell state 中有多少暴露给外部作为隐状态输出,还是比例,还是 sigmoid。
但候选状态(就是那个准备写入 cell state 的新信息本身)用的是 tanh。为什么?因为它的语义不是"比例",而是"信息内容"。信息内容可以是正的(增强某维度),也可以是负的(抑制某维度),所以必须允许负值------这就排除了 sigmoid(sigmoid 输出全为正)。同时又需要有界,因为 cell state 是逐步累加的,如果每步写入的值没有上界,cell state 会随时间爆炸。Tanh 输出在 -1 到 1 之间,既允许正负又有界,完美匹配。
你看,LSTM 内部的选择逻辑没有任何神秘之处:forget gate 是比例所以用 sigmoid,候选状态是有界双向信号所以用 tanh。每个选择都是"约束决定激活函数"这同一个原则的具体实例。
第四部分:为什么功能层用不同激活不会增加学习难度
回到最初的问题------隐层混用会增加学习难度,但 gate 层和输出层用不同激活不会,为什么?
原因一:深度不同。隐层是堆叠的,可能有几十层,梯度要穿过所有这些层。如果每层梯度尺度不一致,误差会在穿越过程中累积放大。而 gate 层和输出层通常只有一层线性变换加一个激活,梯度只穿过一次,不存在累积效应。
原因二:目的不同。隐层混用是在"功能相同的层之间无理由地引入差异"------增加了复杂度却没有对应收益,纯粹是负担。而 gate 层和输出层用不同激活是"为了让输出满足正确的语义约束"------如果不用,网络的输出从数学意义上就是错的。比如你让 gate 层用 ReLU,输出可能是 5、10 这样的值,既不归一化也没有概率含义,根本无法作为"权重分配"来使用。所以这不是"额外负担",而是"必须这样做才能让网络正确运作"。
总结
整个问题归结为一个统一原则:约束决定激活函数。
隐层的约束都一样(非线性 + 梯度可传),所以统一用同一种激活函数是最优解。功能层(输出层、gate 层)的约束各不相同,所以必须按各自的约束选择对应的激活函数。前者是"相同需求导致相同选择",后者是"不同需求导致不同选择",两者不矛盾,是同一个原则在不同场景下的自然表现。
1.2 具体业务应用例子
在我工作相关的业务中,和激活函数相关的工作主要有两个:(1) 在网络attention结构中使用softplus激活函数优化已有的softmax激活函数;(2) 在POSO结构中使用sigmoid激活函数。
1.2.1 attention中的softplus
网络中attention结构的目的是提取用户历史序列的兴趣表征,用户历史包含众多item,而不同item对兴趣表征的贡献程度不同,因此需要用attention机制对用户历史进行处理。
attention处理用户历史的核心是得到历史序列中不同item的权重,因此很自然地会采用softmax激活函数,softmax函数本身具有归一化性质,和想要计算不同item对最终兴趣表征贡献非常吻合。
虽然softmax和attention的目的非常吻合,但也存在几个问题。
- (1) softmax具有强化区分度的性质,这对于用户兴趣广泛的场景,会带来损伤,它会加强用户头部兴趣,打压非头部兴趣,从而导致用户原有的广泛兴趣在提取过程中被削窄,影响最终推荐效果。
- (2) softmax强制归一化,导致和target不相似的item也会分配到一定权重贡献于兴趣表征,从而对最终的兴趣表征造成损伤。
针对softmax在用户兴趣提取中的问题,采用softplus激活函数进行改进。softplus的优势包括:
- (1) 不存在强制归一化操作,因此对和target不相关的item,不会强制分配权重从而干扰最终兴趣表征;
- (2) 经过softplus的输出接近于输入,不会进一步强化区分度,从而保留了用户的头部和非头部兴趣,有利于推荐结果的多样性,更适用于用户兴趣广泛的场景。
1.2.2 POSO中的sigmoid
POSO1是快手提出的对用户生成个性化网络结构的方法。在实现过程中,使用了近似等价的方式,通过对神经元输出的个性化加权,达到对网络参数实现个性化的目的。
对神经元输出的个性化加权是通过gate层生成权重,这个场景和softmax也非常吻合,但在实际业务中并没有使用softmax,原因是softmax的强制归一化会导致权重差异性增大,从而使最终权重坍缩在几个神经元上,导致其余神经元对后续计算几乎失去作用。因此这里采用sigmoid激活函数,由于sigmoid激活函数的输出范围是(0, 1),且所有输出均在同一标准下,适合POSO中神经元输出的加权场景。
2 相关面试题目
网络的非线性是通过什么实现的
通过激活函数实现。如果没有激活函数,无论网络有多少层,整体都只是输入的线性变换(多个线性变换的复合仍是线性),激活函数在每层输出后引入非线性,使网络能够拟合复杂的非线性关系。
有什么操作可以缓解梯度饱和问题
一是使用非饱和激活函数,比如 ReLU,正区间梯度恒为 1,不存在饱和。二是使用 Batch Normalization,把层输入拉回均值为 0、方差为 1 的区间,避免激活函数输入落入饱和区。三是残差连接,梯度可以通过 shortcut 直接回传,不受饱和层的限制。四是合理的权重初始化,防止前向传播时信号过大落入饱和区。
各种激活函数的非饱和区梯度都较大,容易造成什么问题,有没有什么函数可以解决,会不会有其它问题
非饱和区梯度大容易造成梯度爆炸,深层网络中梯度逐层累乘后变得极大,导致权重更新过猛、训练不稳定。ReLU6、Clipped ReLU 等函数通过对输出设置上界来限制梯度(超过阈值后梯度为 0),能缓解爆炸。但这又引入了新的问题:上界区域梯度为 0,本质上又出现了饱和区,大输入信号的梯度会消失,信息被截断。
对 sigmoid 做什么改进可以解决 zigzag 问题
Zigzag 问题的根源是 sigmoid 输出恒正(值域 0 到 1),导致梯度方向在各维度上总是同号,参数更新只能沿对角方向走锯齿形路线。改进方式是将输出平移为零中心:用 tanh 代替 sigmoid。Tanh 的输出在 -1 到 1 之间,均值为 0,梯度方向可正可负,消除了 zigzag 现象。
在 POSO 结构中使用 sigmoid 激活函数,为什么对输出乘以 2
Sigmoid 输出范围是 (0, 1),如果直接作为特征的缩放系数(gate),只能缩小特征、不能放大。乘以 2 后输出范围变为 (0, 2),中心点在 1 附近,这样 gate 值大于 1 时可以放大特征,小于 1 时可以缩小特征,让网络同时具备增强和抑制的能力,表达力更强。
如何缓解 ReLU 输入为负时的梯度消失问题
给负区间一个非零梯度。Leaky ReLU 在负区间设置一个小斜率(如 0.01),PReLU 让这个斜率作为可学习参数,ELU 在负区间用指数曲线(输出趋近一个负常数但梯度不为零)。这些变体都保证负区间仍有梯度回传,神经元不会因为输入为负就彻底"死掉"。
ReLU 学习率大,为什么会导致神经元永久性 dead
学习率大时,一次权重更新的幅度很大。如果某次更新后权重变化过猛,使得该神经元对所有训练样本的加权输入都变成负值,那么 ReLU 输出全为 0,梯度也全为 0。梯度为 0 意味着这个神经元的权重永远不会再被更新,无论之后来什么样本都无法恢复------这就是永久性死亡。本质上是 ReLU 负区间梯度严格为 0 造成的不可逆性。
对 ReLU 做什么改进可以解决其梯度爆炸问题
ReLU 正区间无上界,深层累积后输出和梯度都可能很大。改进方式是给正区间加一个上限:ReLU6 将输出截断在 6(min(max(0, x), 6)),超过 6 的部分梯度为 0,防止信号和梯度无限增长。Hard-swish 等变体也有类似的有界性质。代价是大输入区间梯度为 0,会丢失部分信息。
激活函数从sigmoid到tanh再到ReLU系列,其改进主要针对梯度消失和爆炸、和数据分布的适配性等问题,这些改进可以较好解决深度网络加深后的梯度消失和爆炸问题,同时也加快了模型的收敛速度,提高了模型的拟合能力。在业务的应用过程中,也通过实验效果证明了激活函数的重要性。所以不可小看激活函数,它对于网络的效果有重要作用。
后续将分享多目标、attention等