目录
1、免费资源
无偿分享每日免费10+次画图网页分享,该网页非本人开发
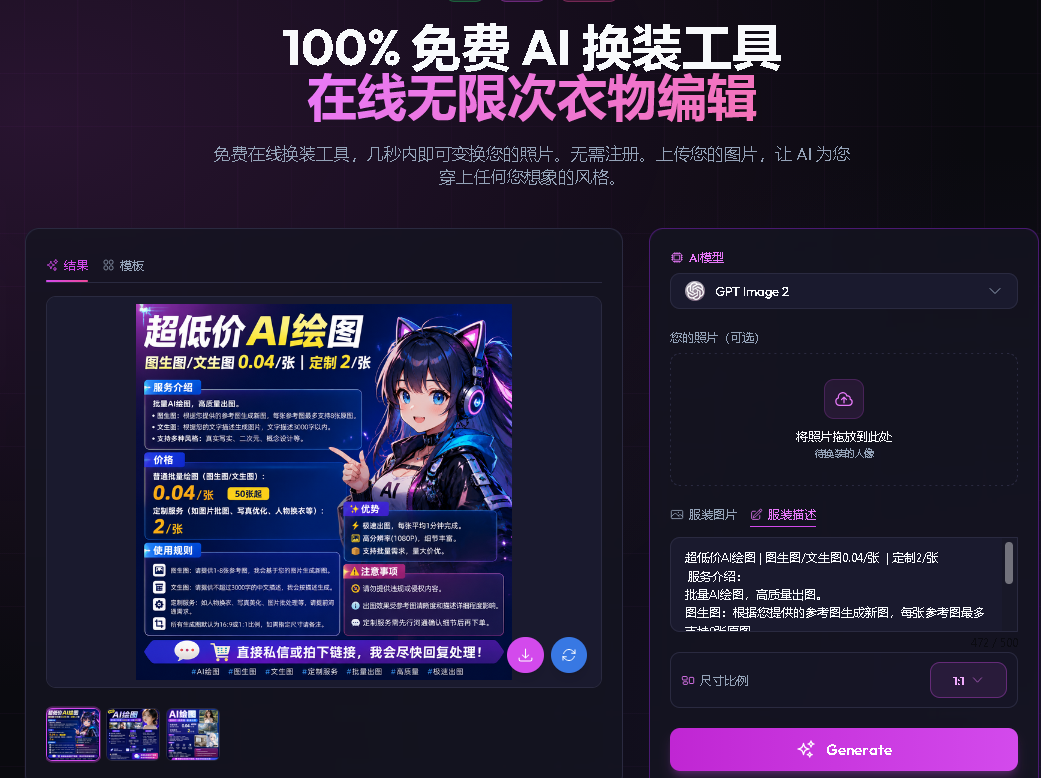 ChatGPT Image 2 可用于营销广告素材的快速生成(海报、电商主图)、出版与内容创作支持(漫画分镜、书籍插图、人物设计),以及教育与科研中的可视化(课件、信息图表、实验示意图)。此外,也能应用于课堂上的学习材料制作(如学习指南)、帮助激发创意灵感和原型设计。
ChatGPT Image 2 可用于营销广告素材的快速生成(海报、电商主图)、出版与内容创作支持(漫画分镜、书籍插图、人物设计),以及教育与科研中的可视化(课件、信息图表、实验示意图)。此外,也能应用于课堂上的学习材料制作(如学习指南)、帮助激发创意灵感和原型设计。
|----------------------------------------------------------------------------|----------------------------------------------------------------------------|
|  |
|  |
|
| |  |
|
|  |
|  |
|
请严格遵守法律法规。
2、0.04超低价付费资源
代码无偿分析,搭配专有画图网页与API使用。
ChatGPT Image 2---0.04/张 附带画图网页与并发绘图python程序【Ai绘图】
画图网页:https://api.zmoapi.cn/image/
 资源稳定不涨价
资源稳定不涨价
python
# -*- coding: utf-8 -*-
import os
import time
import random
import requests
import base64
import tempfile
from concurrent.futures import ThreadPoolExecutor, as_completed
import threading
from PIL import Image
# ================= 配置区域 =================
API_BASE_URL = "https://api.zmi"
API_KEY = "sk-hK8_KMnpJ-vaEHfgkCfWjr5"
KEY_ID = "367c2ba9914c"
KEY_NAME = "BetaCat."
MODEL = "gpt-image-2"
GENERATION_ENDPOINT = "/v1/images/generations"
folders = [
(r"E:\AiPhoto\photo\1", 9),
(r"E:\AiPhoto\photo\4", 9),
(r"E:\AiPhoto\photo\11", 9),
(r"E:\AiPhoto\photo\12", 9),
(r"E:\AiPhoto\photo\13", 9),
]
loop_count = 0
round_interval = 90
output_dir = r"E:\AiPhoto\output8"
temp_dir = r"E:\AiPhoto\Atemp"
os.makedirs(output_dir, exist_ok=True)
os.makedirs(temp_dir, exist_ok=True)
max_workers = 2
rate_per_minute = 2
CONSOLE_CLEAR_INTERVAL = 180 # 每3分钟清空控制台
# ========== 子图布局描述 ==========
LAYOUTS = {
"collage": "子图排列为错落叠压/杂志拼贴风格:子图大小不一,部分重叠(半透明或边缘交错),不严格对齐。时尚、前卫、层次丰富,类似平面设计排版。不同子图的人可以跨越边界互动"
}
# ========== 简化后的提示词模板 ==========
PROMPT_TEMPLATE = (
"""
)
# ========== 控制台清屏功能 ==========
def clear_console():
"""清空控制台内容(兼容 Windows / Linux / macOS)"""
command = 'cls' if os.name == 'nt' else 'clear'
os.system(command)
def clear_loop():
"""后台线程:每隔 CONSOLE_CLEAR_INTERVAL 秒清屏一次"""
while True:
time.sleep(CONSOLE_CLEAR_INTERVAL)
clear_console()
# ========== 限流器(滑动窗口) ==========
class RateLimiter:
def __init__(self, max_per_minute):
self.max_per_minute = max_per_minute
self.timestamps = []
self.lock = threading.Lock()
def acquire(self):
with self.lock:
now = time.time()
self.timestamps = [t for t in self.timestamps if now - t < 60]
if len(self.timestamps) >= self.max_per_minute:
wait_time = 60 - (now - self.timestamps[0]) + 0.1
print(f"⏳ 达到速率限制 ({self.max_per_minute}次/分钟),等待 {wait_time:.1f} 秒...")
time.sleep(wait_time)
now = time.time()
self.timestamps = [t for t in self.timestamps if now - t < 60]
self.timestamps.append(now)
limiter = RateLimiter(rate_per_minute)
# ========== 延迟删除辅助函数 ==========
def delete_later(file_path, delay=180):
"""在 delay 秒后删除文件(默认3分钟)"""
def remove_file():
try:
if os.path.exists(file_path):
os.remove(file_path)
print(f"🗑️ 已删除临时文件: {file_path}")
except Exception as e:
print(f"⚠️ 删除临时文件失败 {file_path}: {e}")
timer = threading.Timer(delay, remove_file)
timer.daemon = True
timer.start()
# ========== 图片尺寸规范化(保持宽高比) ==========
def resize_image_to_bounds(img, min_size=1024, max_size=2048):
"""将图片缩放,使其满足:
- 若最大边长 > max_size,则缩小至最大边长为 max_size
- 否则若最小边长 < min_size,则放大至最小边长为 min_size
保持宽高比不变。
"""
width, height = img.width, img.height
max_dim = max(width, height)
min_dim = min(width, height)
if max_dim > max_size:
scale = max_size / max_dim
new_w = int(width * scale)
new_h = int(height * scale)
img = img.resize((new_w, new_h), Image.Resampling.LANCZOS)
return img
if min_dim < min_size:
scale = min_size / min_dim
new_w = int(width * scale)
new_h = int(height * scale)
img = img.resize((new_w, new_h), Image.Resampling.LANCZOS)
return img
return img
# ========== 图片拼接函数(保持每个子图宽高比) ==========
def merge_images(image_paths, output_path=None, max_size=2048):
"""
将多张图片拼合成网格。
每张子图先进行边界缩放(保持比例),然后统一放入相同大小的格子中(居中放置,留白填充)。
若合并后的画布最大边长超过 max_size,则整体等比例缩小。
"""
if not image_paths:
return None
images = []
for path in image_paths:
img = Image.open(path).convert("RGB")
img = resize_image_to_bounds(img)
images.append(img)
n = len(images)
cols = int(n ** 0.5)
rows = (n + cols - 1) // cols
if cols * rows < n:
cols += 1
cell_w = max(img.width for img in images)
cell_h = max(img.height for img in images)
merged_width = cell_w * cols
merged_height = cell_h * rows
merged_img = Image.new("RGB", (merged_width, merged_height), (255, 255, 255))
for idx, img in enumerate(images):
row = idx // cols
col = idx % cols
x0 = col * cell_w
y0 = row * cell_h
scale = min(cell_w / img.width, cell_h / img.height)
new_w = int(img.width * scale)
new_h = int(img.height * scale)
if new_w <= 0 or new_h <= 0:
continue
img_resized = img.resize((new_w, new_h), Image.Resampling.LANCZOS)
x_offset = (cell_w - new_w) // 2
y_offset = (cell_h - new_h) // 2
merged_img.paste(img_resized, (x0 + x_offset, y0 + y_offset))
max_dim = max(merged_width, merged_height)
if max_dim > max_size:
scale = max_size / max_dim
new_w = int(merged_width * scale)
new_h = int(merged_height * scale)
merged_img = merged_img.resize((new_w, new_h), Image.Resampling.LANCZOS)
if output_path is None:
os.makedirs(temp_dir, exist_ok=True)
timestamp = int(time.time() * 1000)
rand = random.randint(1000, 9999)
output_path = os.path.join(temp_dir, f"merged_{timestamp}_{rand}.jpg")
merged_img.save(output_path, quality=95)
return output_path
# ========== 按文件夹选取图片 ==========
def pick_images_by_folder(folder_configs):
result = []
for folder, num in folder_configs:
if num <= 0:
continue
if not os.path.exists(folder):
print(f"⚠️ 文件夹不存在: {folder}")
return []
images = [f for f in os.listdir(folder) if f.lower().endswith((".png", ".jpg", ".jpeg"))]
if len(images) < num:
print(f"⚠️ 文件夹 {folder} 中图片不足 {num} 张(实际 {len(images)} 张),跳过本轮")
return []
chosen = random.sample(images, num)
chosen_paths = [os.path.join(folder, img) for img in chosen]
result.append((folder, chosen_paths))
return result
# ========== API调用 ==========
def call_generation_api(prompt, reference_image_paths, max_retries=3):
print(f"📤 准备上传参考图 {len(reference_image_paths)} 张:")
for idx, path in enumerate(reference_image_paths, 1):
print(f" {idx}. {path}")
print("🔄 正在编码参考图为 Base64...")
image_data_list = []
for img_path in reference_image_paths:
try:
with open(img_path, "rb") as f:
b64 = base64.b64encode(f.read()).decode("utf-8")
image_data_list.append(b64)
except Exception as e:
print(f"❌ 编码失败 {os.path.basename(img_path)}: {e}")
return []
if len(image_data_list) != len(reference_image_paths):
print(f"❌ 实际编码图片数量({len(image_data_list)})与输入数量({len(reference_image_paths)})不一致")
return []
print("✅ 编码完成")
headers = {
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json"
}
payload = {
"key_id": KEY_ID,
"key_name": KEY_NAME,
"model": MODEL,
"prompt": prompt,
"reference_images": image_data_list,
"num_images": 1,
"safety_filter": False
}
for attempt in range(max_retries):
try:
print(f"📡 第 {attempt + 1} 次尝试请求 API...")
response = requests.post(
API_BASE_URL + GENERATION_ENDPOINT,
headers=headers,
json=payload,
timeout=(10, 300)
)
print(f"📨 响应状态码: {response.status_code}")
if response.status_code == 400:
try:
error_json = response.json()
error_code = error_json.get("error", {}).get("code")
error_msg = error_json.get("error", {}).get("message", "无详细消息")
print(f"❌ API 拒绝请求 (400)")
print(f" 错误代码: {error_code}")
print(f" 错误信息: {error_msg}")
if error_code == "content_policy_violation":
print("⚠️ 内容策略违规!可能由于参考图中包含敏感内容或提示词触发策略。")
print("📋 本次上传的所有参考图如下(请检查是否可能包含不当内容):")
for path in reference_image_paths:
print(f" - {path}")
print("📝 提示词前5000字符:")
print(prompt[:5000] + "......")
else:
print(f" 完整响应: {error_json}")
return []
except:
print(f"❌ API 返回400但无法解析JSON: {response.text[:300]}")
return []
elif response.status_code == 200:
data = response.json()
if "urls" in data and data["urls"]:
print(f"✅ API 接受所有参考图,成功生成 {len(data['urls'])} 张图片")
return data["urls"]
elif "url" in data and data["url"]:
print("✅ API 接受所有参考图,成功生成1张图片")
return [data["url"]]
elif "data" in data and isinstance(data["data"], list):
urls = [item.get("url") for item in data["data"] if item.get("url")]
if urls:
print(f"✅ API 接受所有参考图,成功生成 {len(urls)} 张图片")
return urls
print(f"❌ API 返回200但格式异常,未找到图片URL: {data}")
return []
else:
print(f"❌ API 请求失败,状态码: {response.status_code}")
print(f" 响应内容: {response.text[:500]}")
return []
except requests.exceptions.Timeout:
print(f"⏱️ 请求超时 (尝试 {attempt + 1}/{max_retries}),等待后重试...")
time.sleep(10 * (attempt + 1))
except Exception as e:
print(f"❌ 请求异常 (尝试 {attempt + 1}/{max_retries}): {e}")
time.sleep(5)
return []
def download_image(url, save_path):
try:
resp = requests.get(url, timeout=60)
resp.raise_for_status()
with open(save_path, "wb") as f:
f.write(resp.content)
print(f"✅ 图片已下载: {save_path}")
except Exception as e:
print(f"❌ 保存图片失败: {e}")
def process_one_round(round_id):
print(f"\n[任务 {round_id}] 开始")
folder_images = pick_images_by_folder(folders)
if not folder_images:
print(f"[任务 {round_id}] 素材不足,跳过")
return
merged_paths = []
temp_files = []
for folder_name, img_paths in folder_images:
print(f"[任务 {round_id}] 拼接文件夹 {folder_name} 中的 {len(img_paths)} 张图片...")
merged = merge_images(img_paths)
if merged:
merged_paths.append(merged)
temp_files.append(merged)
else:
print(f"[任务 {round_id}] 文件夹 {folder_name} 拼接失败,跳过本轮")
for f in temp_files:
delete_later(f)
return
print(f"[任务 {round_id}] 共生成 {len(merged_paths)} 张拼接图")
limiter.acquire()
layout_key = random.choice(list(LAYOUTS.keys()))
layout_desc = LAYOUTS[layout_key]
print(f"[任务 {round_id}] 选择布局: {layout_key}")
num_refs = len(merged_paths)
placeholders = ", ".join([f"image{i + 1}" for i in range(num_refs)])
prompt = PROMPT_TEMPLATE.format(
placeholders=placeholders,
layout_description=layout_desc
)
print(f"[任务 {round_id}] 调用 API...")
generated_urls = call_generation_api(prompt, merged_paths)
for f in temp_files:
delete_later(f, delay=180)
if not generated_urls:
print(f"[任务 {round_id}] 生成失败")
return
timestamp = time.strftime("%Y%m%d_%H%M%S")
for idx, url in enumerate(generated_urls):
filename = f"gen_{timestamp}_{round_id}_{idx + 1}.png"
save_path = os.path.join(output_dir, filename)
download_image(url, save_path)
print(f"[任务 {round_id}] 完成")
# ========== 主流程 ==========
def main():
# 启动后台清屏线程
threading.Thread(target=clear_loop, daemon=True).start()
round_number = 0
with ThreadPoolExecutor(max_workers=max_workers) as executor:
futures = []
try:
while True:
round_number += 1
if loop_count > 0 and round_number > loop_count:
for f in as_completed(futures):
f.result()
break
future = executor.submit(process_one_round, round_number)
futures.append(future)
futures = [f for f in futures if not f.done()]
time.sleep(1)
except KeyboardInterrupt:
print("\n用户中断,等待剩余任务完成...")
for f in as_completed(futures):
f.result()
print("所有任务已终止")
if __name__ == "__main__":
main()