目录
[门(相当于一个控制单元 值为0-1 注意力青春版)](#门(相当于一个控制单元 值为0-1 注意力青春版))
[为什么不能写成 self.linear(Y, in_features, out_features)?](#为什么不能写成 self.linear(Y, in_features, out_features)?)
1) begin_state不是 nn.Module的父类原函数 begin_state不是 nn.Module的父类原函数)
介绍
他在lstm之后才出现
这里就有点注意力的感觉了
门(相当于一个控制单元 值为0-1 注意力青春版)
也就是说,相当于2个RNN层 ,但是发挥的是不同的职责,因为是两套不同参数的作用!上节课的RNN code可以看出来,用的是当前时刻的x和上一个时刻的h
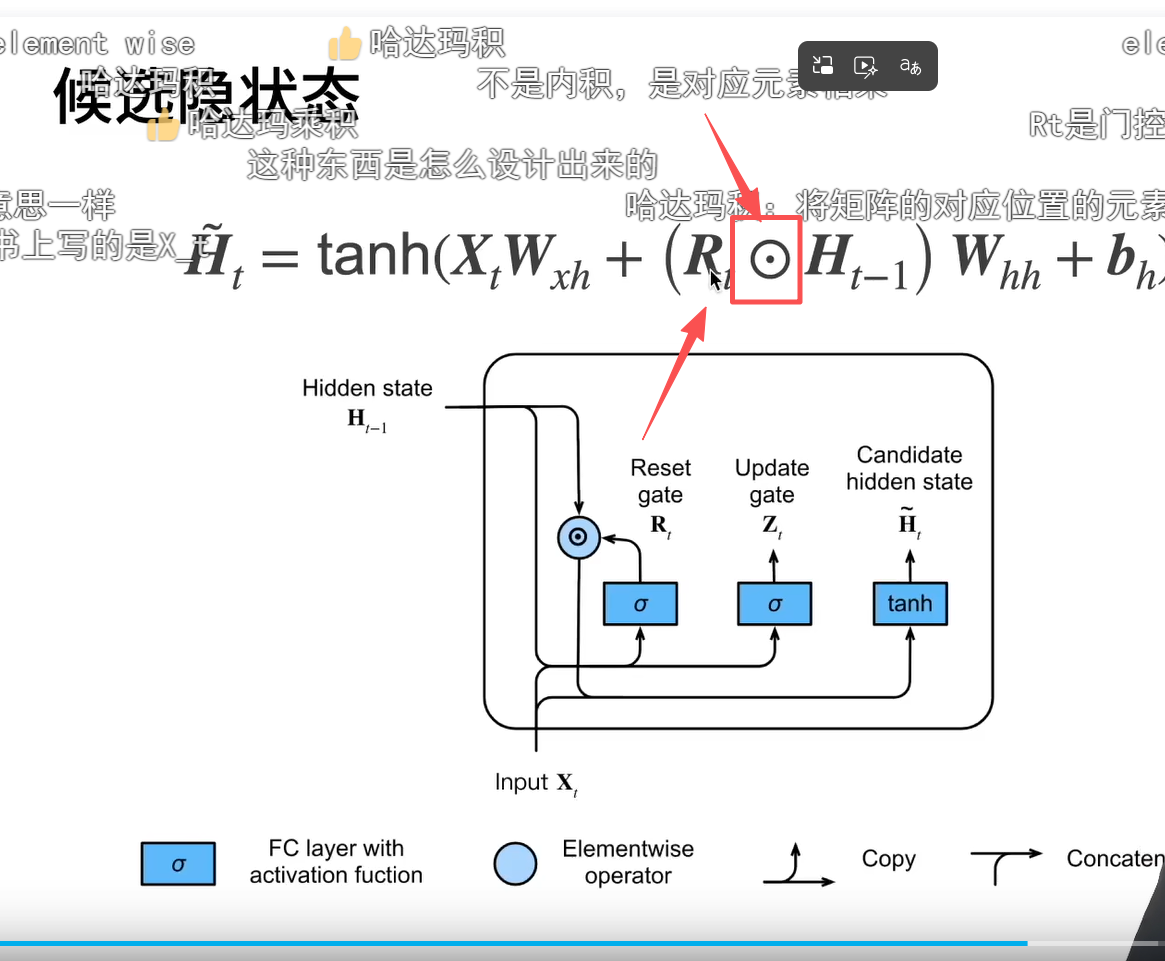
候选隐状态(重置门Rt发挥作用)
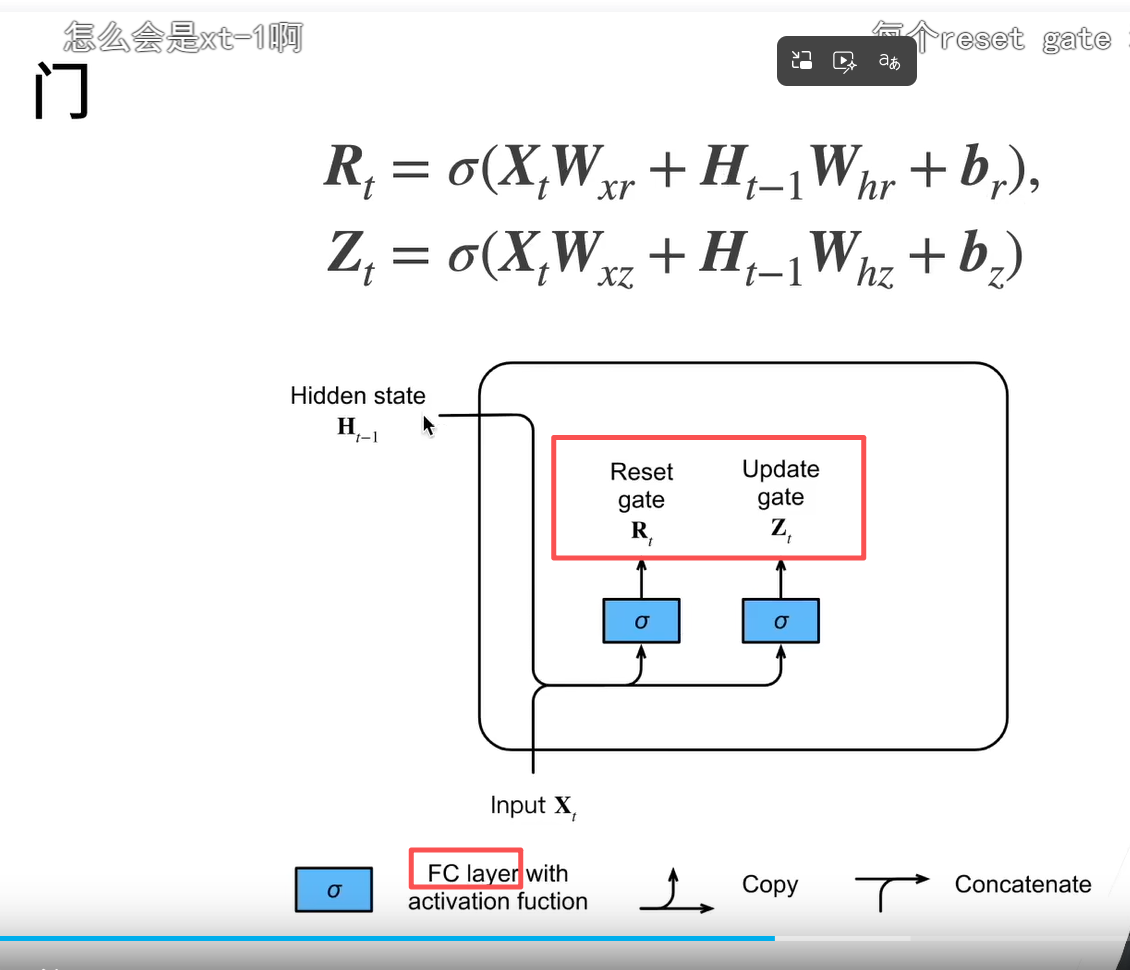
上节课哪个RNN的X_t-1应该是老师ppt写错了,书上写的是X_t 其实也不要纠结下标,下标不同解释不同,但本质都是一样的,重点是理解怎么工作的,结合例子去理解
哈达玛积:将矩阵的对应位置的元素相乘,并得到一个新的矩阵 公式里面也就这个地方和rnn不同
比如 Rt接近于0,乘出来后就清0了,相当于忘记上一个隐藏状态信息,这里直接清零状态太暴力了,对于长距离的重要信息Z并不能抓得很好,所以效果不如Transformer 可以理解为注意力(青春版)
全为0可以理解成前一个句子结束,和下一个句子没有上下文关联,但是现实中很少,因为可能出现隔一个句子又需要前面的信息,LSTM就会把前面所有的状态存起来,这一点就是有些时候LSTM更好的原因?
隐状态(更新门Zt和候选隐状态H~t发挥作用)
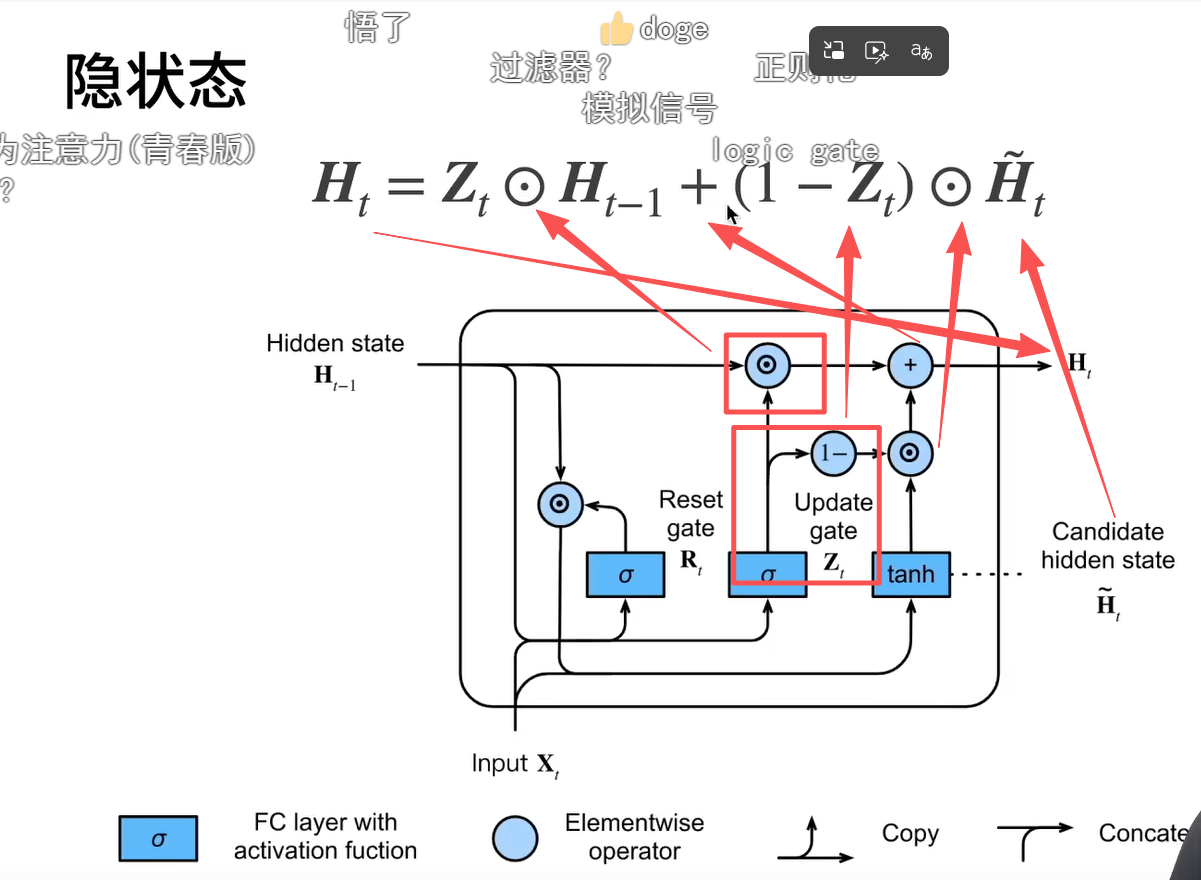
我们希望得到的隐状态是当前输入h~t 与历史输出h_t-1的按比例混合 (即适当遗忘后的结果).
如果你直接修改候选隐函数的权重r_t,那等于说直接改变了当前时刻的输出,而没有模拟出"遗忘"这一过程
本质就是上一个时间步的输出与当前时间步的输出比较,哪个合适选哪个,其中取决于 Zt
Zt为1,就是直接用上一个时间步,为0(R也全1)就类似rnn了
小结(重要)
公式说明
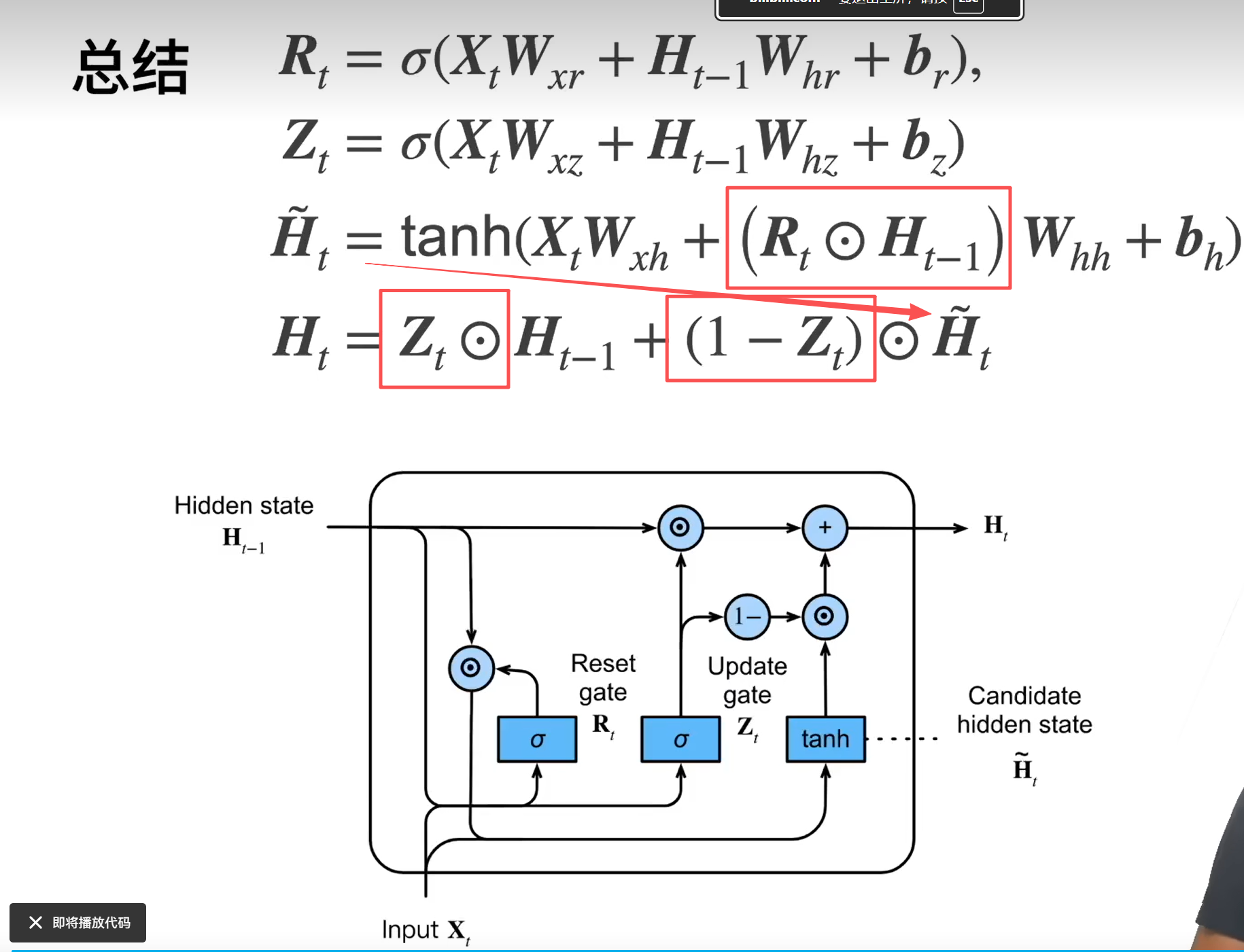
R是决定保留多少过去的内容,Z是是否保留当前X的内容(重置门决定了如何将新输入与过去的隐藏状态混合,而更新门决定了保留多少过去的隐藏状态。)
两种极端情况:第一种Rt全1,Zt全0,等价于RNN;第二种Zt全1 隐状态保持上次的不变
-
重置门有助于捕获序列中的短期依赖关系;它控制的是**「算当前步的新内容时,要不要接上一句的『紧邻上下文』」**,操作对象是「紧邻的上一个隐状态ht−1」,天然只影响近处的短期关系:
-
更新门有助于捕获序列中的长期依赖关系。
操作对象是整个旧隐状态ht−1本身,而且是「按比例的留存/覆盖」,天生适合跨多步存信息:
公式是ht=(1−zt)⊙h~t+zt⊙ht−1,翻译过来就是:
最终输出的新隐状态 = (当前步刚算出来的新信息 × 新信息占比) + (整个旧隐状态 × 旧记忆留存率)
sigmoid和Tanh函数
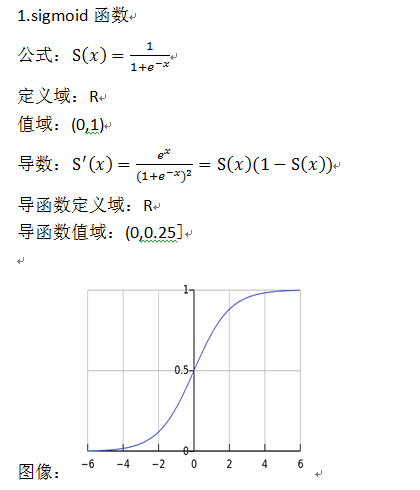

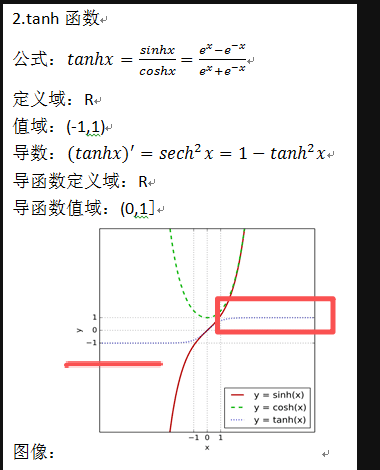

| Sigmoid | Tanh | |
|---|---|---|
| 范围 | (0, 1) | (-1, 1) |
| 适合做"门"(比例系数) | ✅ 天然比例 | ❌ 负值会让信息反转符号,门就失去"开/关"语义了 |
| 适合做"候选值/实际值" | ❌ 永远为正,表达能力受限 | ✅ 正负都有,能表示丰富的正负激活模式 |
-
门(gate)= Sigmoid → 控制"流多少"
-
候选状态 / 候选隐状态 = Tanh → 提供"流的是什么值"(可正可负)
代码:
初始化参数
python
import torch
from torch import nn
from d2l import torch as d2l
batch_size, num_steps = 32, 35
train_iter, vocab = d2l.load_data_time_machine(batch_size, num_steps)
#初始化模型参数
def get_params(vocab_size, num_hiddens, device):
num_inputs = num_outputs = vocab_size
def normal(shape):
return torch.randn(size=shape, device=device)*0.01
def three():
return (normal((num_inputs, num_hiddens)),
normal((num_hiddens, num_hiddens)),
torch.zeros(num_hiddens, device=device))
W_xz, W_hz, b_z = three() # 更新门参数
W_xr, W_hr, b_r = three() # 重置门参数 就这两行和rnn不同
W_xh, W_hh, b_h = three() # 候选隐状态参数
# 输出层参数
W_hq = normal((num_hiddens, num_outputs))
b_q = torch.zeros(num_outputs, device=device)
# 附加梯度
params = [W_xz, W_hz, b_z, W_xr, W_hr, b_r, W_xh, W_hh, b_h, W_hq, b_q]
for param in params:
param.requires_grad_(True)
return params在语言模型中,GRU 的工作流程分两步:
-
GRU 循环体 :根据输入序列,逐步计算出每个时间步的隐状态 ht(维度
num_hiddens)。 -
输出层 :把每个时间步的隐状态 ht映射到词汇表大小的向量上,得到下一个词的预测概率分布。
因此,你需要两个额外的参数来完成第二步:
-
W_hq:形状(num_hiddens, num_outputs),其中num_outputs = vocab_size,负责把隐状态线性投影到词汇空间。 -
b_q:形状(vocab_size,),偏置项。
如果没有这两个参数,GRU 只能产出隐状态,却无法给出最终的预测结果(即无法计算损失和反向传播)。
python
def init_gru_state(batch_size, num_hiddens, device):
return (torch.zeros((batch_size, num_hiddens), device=device), )
"""
功能:初始化 GRU 的初始隐状态(不是模型参数)*********。
返回一个元组,里面只有一个元素:全零张量 (batch_size, num_hiddens)。
元组形式是为了兼容未来可能出现的多状态模型(比如 LSTM 会返回 (H, C)两个状态),这里用一个逗号把单个张量包装成元组。
"""
def gru(inputs, state, params):
W_xz, W_hz, b_z, W_xr, W_hr, b_r, W_xh, W_hh, b_h, W_hq, b_q = params
H, = state
#←逗号之前讲过是为后面的模型预留的,后面的LSTM模型会返回不止一个状态
#H, = state等价于 H = state[0],把元组里的唯一元素赋值给变量 H。
outputs = [] # 收集每个时间步的输出
for X in inputs: # X 的形状: (batch_size, vocab_size) ------ 一个时间步的独热编码输入
# 更新门 Z
Z = torch.sigmoid((X @ W_xz) + (H @ W_hz) + b_z)
# 重置门 R
R = torch.sigmoid((X @ W_xr) + (H @ W_hr) + b_r)
# 候选隐状态 H_tilda
H_tilda = torch.tanh((X @ W_xh) + ((R * H) @ W_hh) + b_h)
# 最终隐状态 H(更新门混合)
H = Z * H + (1 - Z) * H_tilda
# 输出层:隐状态 -> 词汇表 logits
Y = H @ W_hq + b_q
outputs.append(Y)
return torch.cat(outputs, dim=0), (H,)
#torch.cat(outputs, dim=0):将所有时间步的输出沿 batch 维度拼接,形成形状 (num_steps * batch_size, vocab_size),方便一次性计算交叉熵损失。| 初始化函数 | 初始化什么 | 何时调用 | 是否可学习 |
|---|---|---|---|
get_params(...) |
模型参数(权重矩阵和偏置) | 模型构建时,只调用一次 | ✅ 是,梯度会更新它们 |
init_gru_state(...) |
隐状态 H(循环的起点) | 每个 mini-batch 开始时调用 | ❌ 否,固定为零 |
| 运算符 | 名称 | 数学符号 | 形状要求 | 典型用途 |
|---|---|---|---|---|
@ |
矩阵乘法 | AB | (m,n) @ (n,p) → (m,p) |
线性层、全连接变换 |
* |
逐元素乘 | A⊙B | 形状完全相同 | 门控缩放、注意力权重、残差掩码 |
rnn.concise章节的:
python
#@save
class RNNModel(nn.Module):
"""循环神经网络模型"""
def __init__(self, rnn_layer, vocab_size, **kwargs):
super(RNNModel, self).__init__(**kwargs)
self.rnn = rnn_layer
self.vocab_size = vocab_size
self.num_hiddens = self.rnn.hidden_size
# 如果RNN是双向的(之后将介绍),num_directions应该是2,否则应该是1
if not self.rnn.bidirectional:
self.num_directions = 1
self.linear = nn.Linear(self.num_hiddens, self.vocab_size)
else:
self.num_directions = 2
self.linear = nn.Linear(self.num_hiddens * 2, self.vocab_size)
def forward(self, inputs, state):
X = F.one_hot(inputs.T.long(), self.vocab_size)
X = X.to(torch.float32)
Y, state = self.rnn(X, state)
# 全连接层首先将Y的形状改为(时间步数*批量大小,隐藏单元数)
# 它的输出形状是(时间步数*批量大小,词表大小)。
output = self.linear(Y.reshape((-1, Y.shape[-1])))
return output, state
def begin_state(self, device, batch_size=1):
if not isinstance(self.rnn, nn.LSTM):
# nn.GRU以张量作为隐状态
return torch.zeros((self.num_directions * self.rnn.num_layers,
batch_size, self.num_hiddens),
device=device)
else:
# nn.LSTM以元组作为隐状态
return (torch.zeros((
self.num_directions * self.rnn.num_layers,
batch_size, self.num_hiddens), device=device),
torch.zeros((
self.num_directions * self.rnn.num_layers,
batch_size, self.num_hiddens), device=device))为啥nn.linear需要两个参数,但是self.linear时候只是传入y:
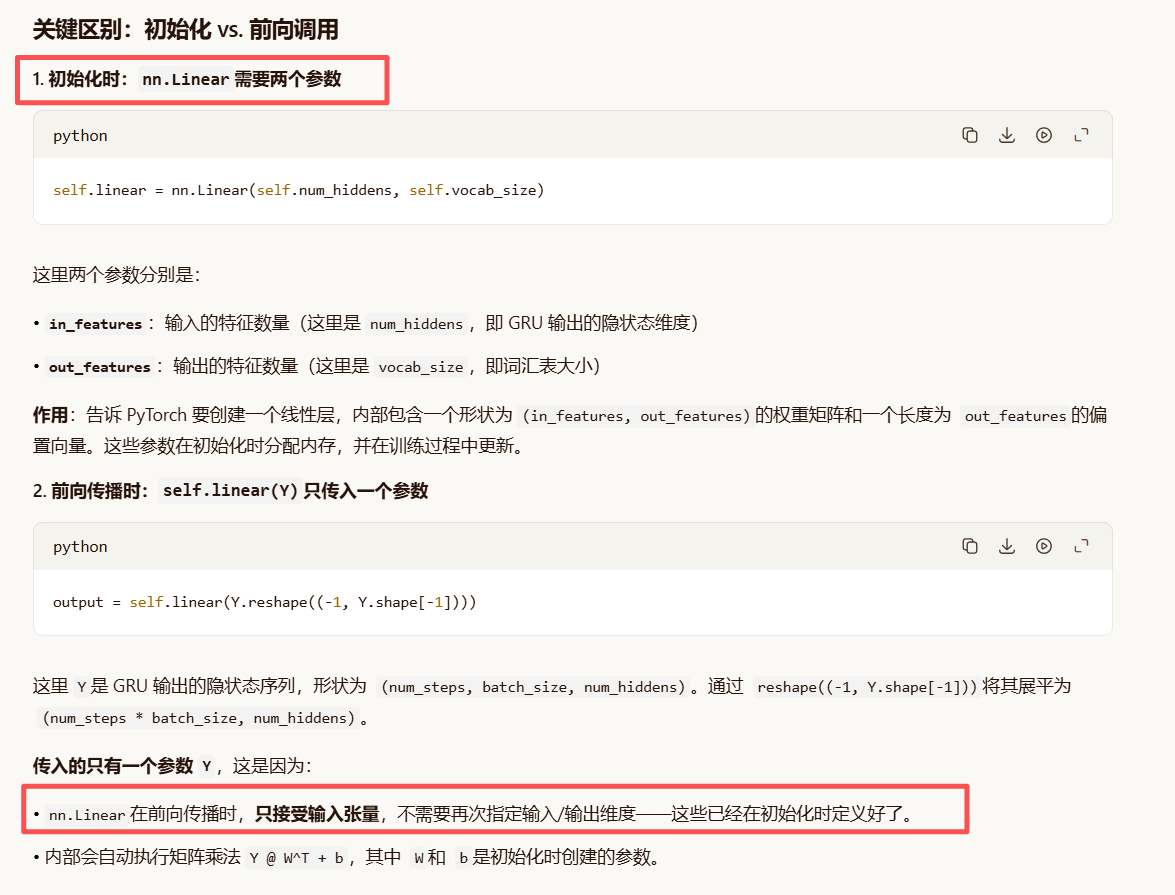
为什么不能写成 self.linear(Y, in_features, out_features)?
因为线性变换的权重和偏置是固定尺寸的参数 ,一旦初始化就不能动态改变。如果每次调用都传入维度信息,不仅冗余,还会破坏参数的可学习性------因为维度信息已经在 __init__中决定了网络结构。
nn.Linear(a, b)在__init__中定义"输入 a 维、输出 b 维"的结构;在forward中只需传入形状为(*, a)的张量,它就会自动输出形状为(*, b)的结果。
nn.Module介绍:(重要)
在 PyTorch 中,nn.Module是所有神经网络模块的基类。当你定义一个自己的模型类(如 RNNModel)并继承 nn.Module时,你需要重写 forward方法来描述前向传播的逻辑。但这个 forward方法并不会被用户直接调用 ,而是由 PyTorch 框架自动调用的。
具体来说,当你执行 output, state = model(inputs, state)时,实际上发生了以下步骤:
-
Python 调用
model.__call__(inputs, state)(这是nn.Module定义的魔法方法)。 -
__call__内部会做一些预处理(如钩子注册、设备检查等),然后调用你重写的forward方法。 -
forward执行完毕后,__call__再做一些后处理(如梯度钩子),最后返回结果。
1) begin_state不是 nn.Module的父类原函数
nn.Module的公开"父类原函数"主要是这些(你用到最多的):
-
__call__(就是你写model(x)时会触发的那个) → 它内部会调 你的forward() -
参数/状态管理:
parameters(),state_dict(),load_state_dict() -
设备/类型:
to(device),cpu(),cuda() -
模式切换:
train(),eval() -
梯度:
zero_grad() -
钩子:
register_forward_hook之类(高阶)
👉 nn.Module里并不存在 begin_state这个函数。
所以 begin_state不是"框架自动回调",而是 d2l 自己在 RNNModel里定义的一个普通方法,用来"给调用方一个统一方式去拿初始隐状态"。
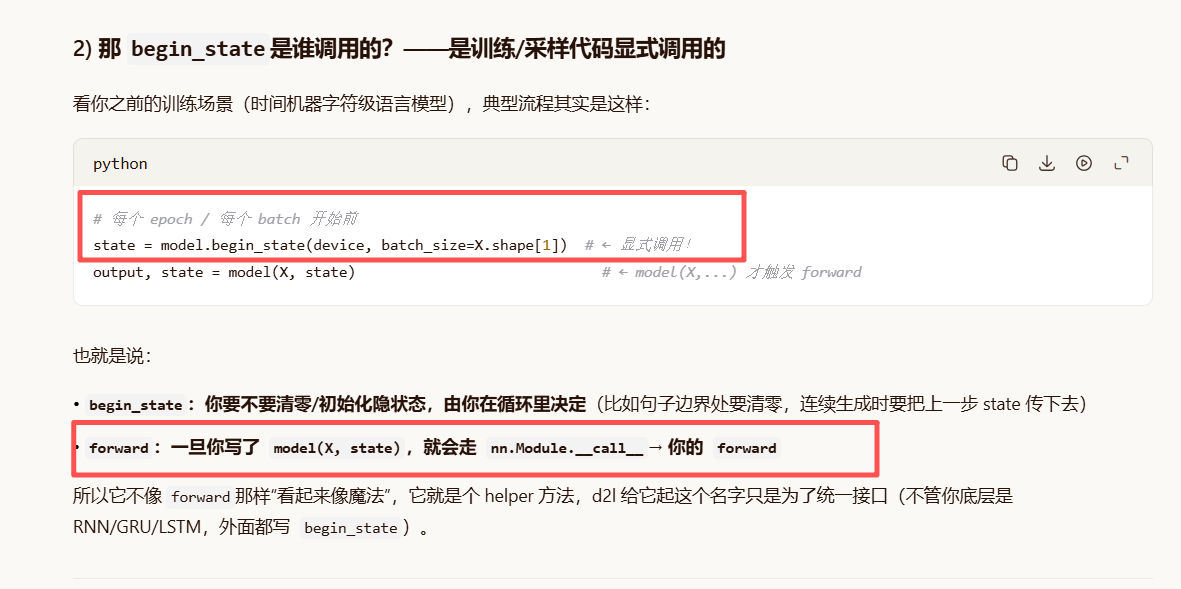
train_ch8的内部:在真正开始循环训练之前,它会根据传入的设备信息,自己去调用模型的 begin_state方法来获取初始状态
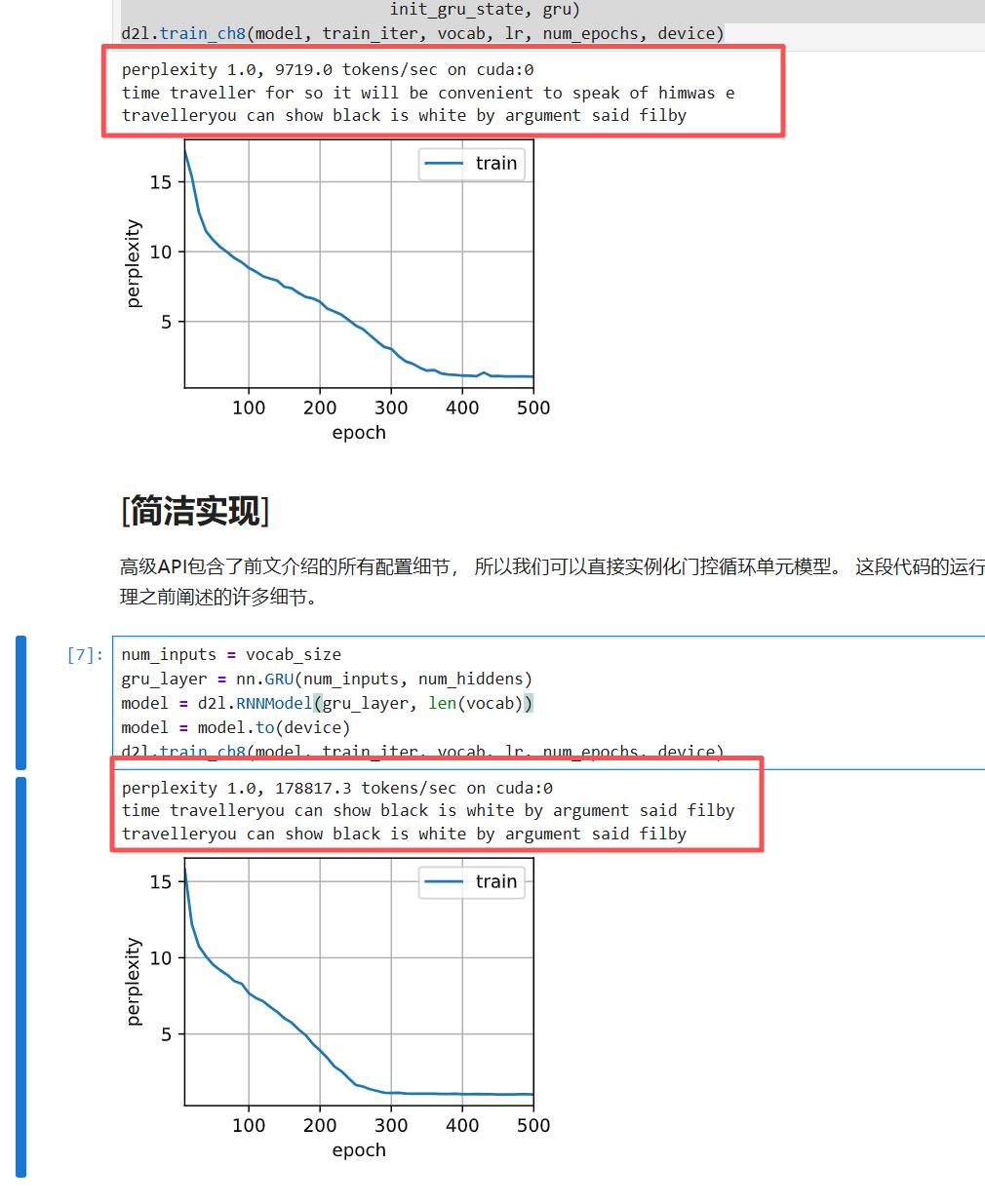
实现
python
# 从0实现的方法:使用手动实现的 GRU(从零实现)训练语言模型
vocab_size, num_hiddens, device = len(vocab), 256, d2l.try_gpu()
# 获取词汇表大小(即输出类别数)、隐藏单元数(256)、设备(优先 GPU)
# vocab 是从 load_data_time_machine 返回的 Vocabulary 对象
num_epochs, lr = 500, 1
# 训练轮数设为 500,学习率设为 1(较大的学习率,因为手动实现没有自适应优化器)
model = d2l.RNNModelScratch(len(vocab), num_hiddens, device, get_params,
init_gru_state, gru)
# 创建一个从零实现的 RNN 模型(此处实际是 GRU):
# - 参数:词汇表大小、隐藏单元数、设备
# - get_params: 之前定义的初始化模型参数的函数
# - init_gru_state: 初始化隐状态的函数(返回全零元组)
# - gru: 前向传播函数(定义 GRU 计算逻辑)
# 该模型封装了参数管理、状态初始化、前向传播等功能
d2l.train_ch8(model, train_iter, vocab, lr, num_epochs, device)
# 调用 d2l 的训练函数(适用于 RNN 语言模型):
# - model: 待训练的模型
# - train_iter: 数据迭代器(来自 load_data_time_machine)
# - vocab: 词汇表(用于解码预测结果和计算困惑度)
# - lr, num_epochs, device: 学习率、轮数、设备
# 该函数会执行训练循环,打印困惑度和时间,并绘制损失曲线
--------------------------------------------------------------------------
# 第二种实现:使用 PyTorch 内置的 nn.GRU 层训练语言模型*****简洁实现
num_inputs = vocab_size
# 输入维度 = 词汇表大小(因为输入是 one-hot 编码或嵌入索引)
gru_layer = nn.GRU(num_inputs, num_hiddens)
# 创建一个单层 GRU 实例:
# - input_size = vocab_size
# - hidden_size = num_hiddens (256)
# - 默认 num_layers=1,batch_first=False(输入形状为 (seq_len, batch, input_size))
model = d2l.RNNModel(gru_layer, len(vocab))
# 使用 d2l 提供的 RNNModel 封装类,将 GRU 层包装成一个完整的语言模型:
# - gru_layer: 刚刚创建的 nn.GRU 层
# - vocab_size: 输出层的输入维度(同时也是输出维度,因为输出层是线性层)
# 该封装会自动添加输出层(全连接)将隐藏状态映射到词汇表大小
model = model.to(device)
# 将模型参数移动到指定设备(GPU 或 CPU)
d2l.train_ch8(model, train_iter, vocab, lr, num_epochs, device)
# 再次调用训练函数,训练使用内置 GRU 的模型