Demo 能跑,不代表生产能扛。上线之后,真正考验的是成本控制、故障恢复和工程治理。

一、上线不是"模型更强",而是"系统更稳"
很多大模型项目,演示时很惊艳,上线后很狼狈。不是模型不行,而是工程没有兜住。用户一多,问题立刻暴露。
**•**并发上来,模型供应商开始 429。
**•**Agent 自己循环,模型调用次数飙升。
**•**RAG 每次都检索、重排、生成,成本越来越高。
**•**工具调用没有边界,搜索、爬虫、数据库被打爆。
**•**主模型一抖动,整个业务链路直接失败。
**•**日志没有打全,回答错了也不知道错在哪里。
这一章不讲炫技。讲上线。讲怎么让 LangChain 应用少花钱、少崩溃、可恢复、可追踪。
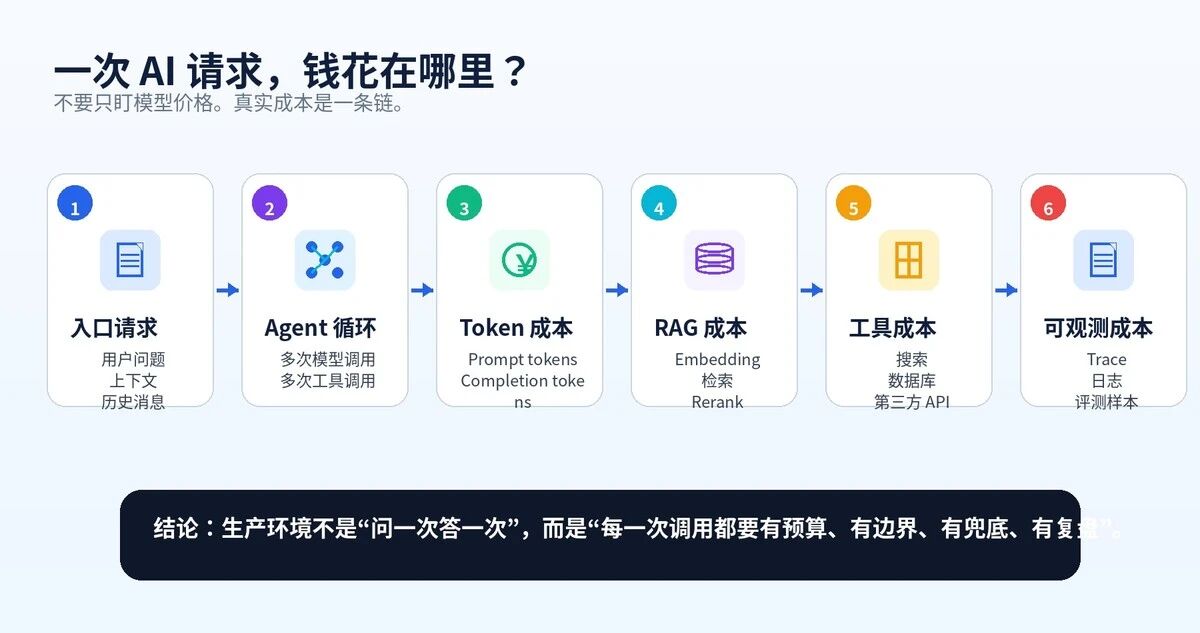
图 1:一次 AI 请求背后的真实成本链路
二、钱花在哪里:不要只盯模型单价
AI 应用的成本不是一个数字,而是一条链。一次用户请求,可能触发多次模型调用、多次工具调用、多次检索和多条日志写入。
真正的成本大头通常有七类:模型调用成本、Token 成本、Embedding 成本、Rerank 成本、工具成本、存储成本、评测与观测成本。
最容易被忽略的是 Agent 循环。普通问答可能只调一次模型,Agent 可能先调模型判断工具,再调工具,再调模型分析结果,再继续调工具。一次用户问题,可能被放大成 5 次、10 次甚至更多模型调用。
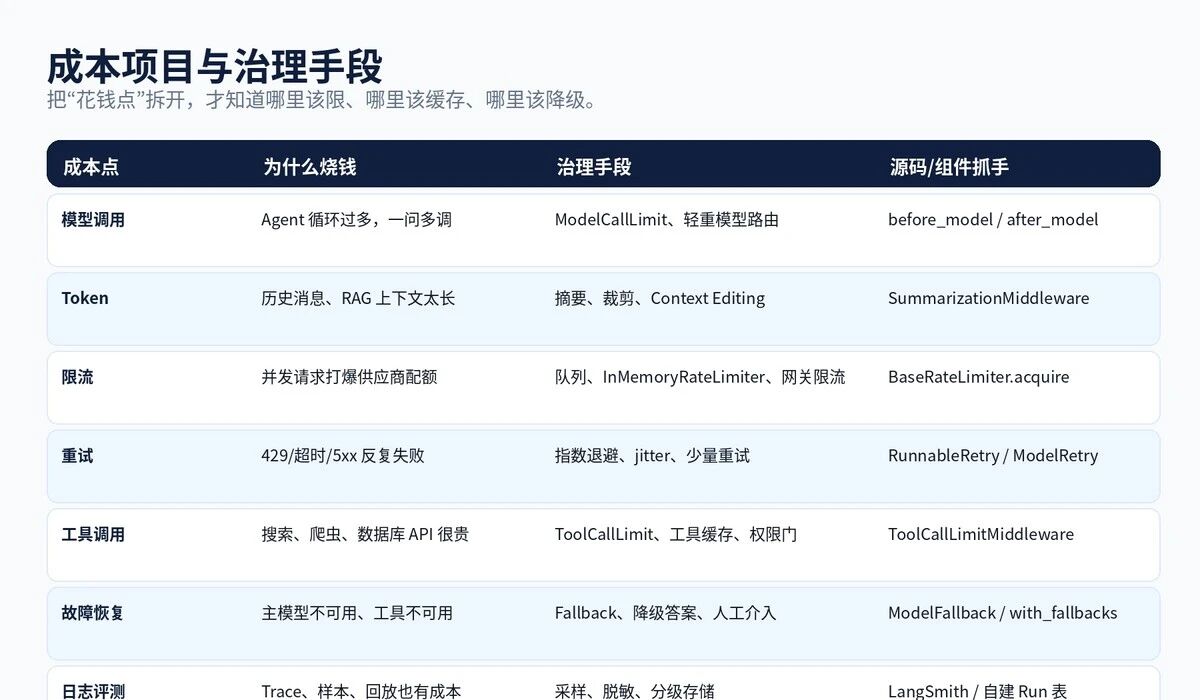
图 2:成本项目与治理手段
所以第一条铁律是:任何 Agent 上线前,都要先定义调用预算。没有预算,就没有生产。
三、限流:不要等供应商帮你限
供应商的限流,是最后一道墙。撞上去的时候,用户已经在等待,业务已经在报错。生产系统应该自己先限。
限流要分层做。入口限流拦用户。队列限流削峰。模型限流保护供应商接口。Agent 内部还要限制模型调用次数和工具调用次数。
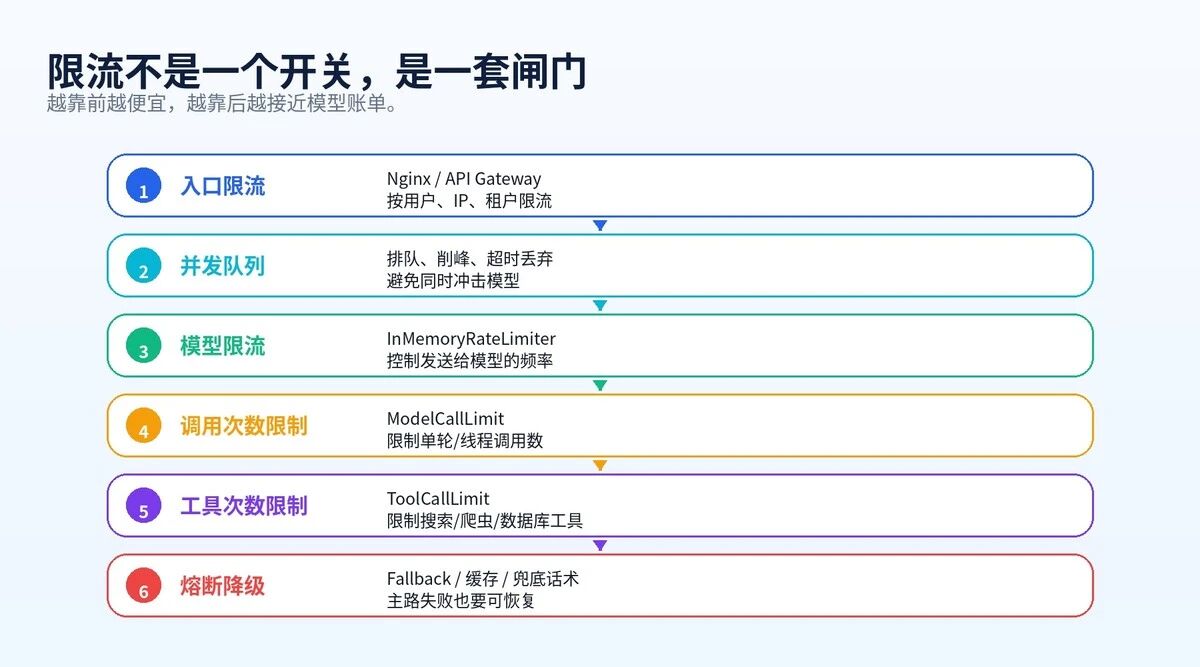
图 3:生产级限流不是一个开关,而是一套闸门
四、源码级看限流:InMemoryRateLimiter 到底做了什么?
LangChain 的 `InMemoryRateLimiter` 是一个基于 token bucket 的内存限流器。注意,这里的 token 不是 LLM token,而是"请求令牌"。
它的源码逻辑很直接:调用模型前先执行 `acquire()`;`acquire()` 内部调用 `_consume()`;`_consume()` 根据时间差补充令牌;如果令牌足够,就消费一个令牌并放行;如果不够,就 sleep 一小段时间后继续尝试。
它适合单进程、线程内保护模型调用频率。但它不是分布式限流。多实例部署时,要在网关、Redis、消息队列或统一模型网关层再做一层。
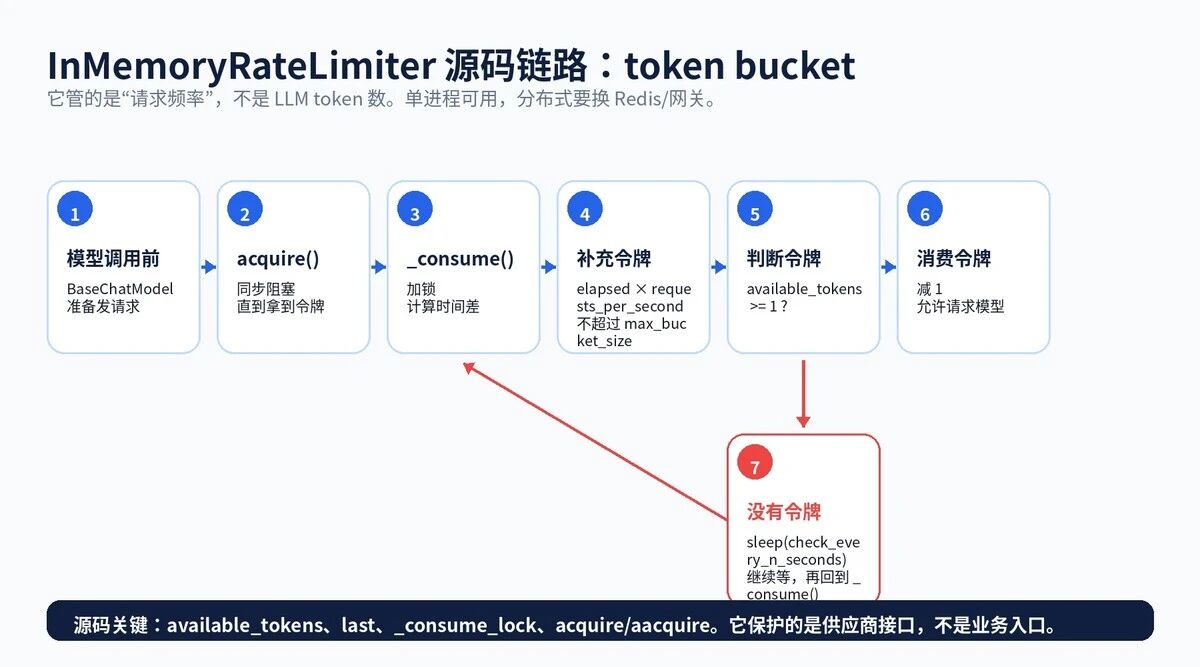
图 4:InMemoryRateLimiter 的 token bucket 源码链路
源码要点很清楚:
•`BaseRateLimiter` 定义 `acquire()` 和 `aacquire()` 两个入口。
•`InMemoryRateLimiter` 用 `requests_per_second` 控制令牌补充速度。
•`max_bucket_size` 控制最大突发量。
•`check_every_n_seconds` 控制阻塞等待时的检查间隔。
**•**它只做时间维度限流,不按 prompt 大小、completion 大小或价格限流。
五、调用次数限制:防止 Agent 自己把自己跑疯
限流解决"单位时间请求太多"。调用次数限制解决"单个 Agent 任务内部调用太多"。两者不是一回事。
LangChain 的预置 Middleware 里有 `ModelCallLimitMiddleware` 和 `ToolCallLimitMiddleware`。一个管模型调用次数,一个管工具调用次数。
`ModelCallLimitMiddleware` 的源码核心是两个 hook:`before_model` 和 `after_model`。
•`before_model`:模型调用前检查 thread_count 和 run_count 是否超限。
**•**超限时,如果配置为 `end`,直接跳到结束节点,并注入一条 AIMessage。
**•**如果配置为 `error`,抛出 `ModelCallLimitExceededError`。
•`after_model`:模型调用成功后,把 thread_model_call_count 和 run_model_call_count 加一。
这就是生产里非常重要的"预算闸门":不是靠 Prompt 告诉模型"少调用点",而是代码层面直接卡住。
六、缓存:能不调模型,就别调模型
缓存是省钱最快的手段。尤其是 FAQ、固定制度问答、标准产品说明、低温度模型输出,这些场景非常适合缓存。
LangChain 的 `BaseCache` 很简单:`lookup()`、`update()`、`clear()`。命中就直接返回,未命中才继续调模型。缓存键通常来自两部分:prompt 的序列化文本,以及 `llm_string`,也就是模型名称、温度、stop、max tokens 等调用参数。
这点很关键。相同问题但模型参数不同,不应该误命中。温度不同、模型不同、系统提示词不同,都可能让输出变化。
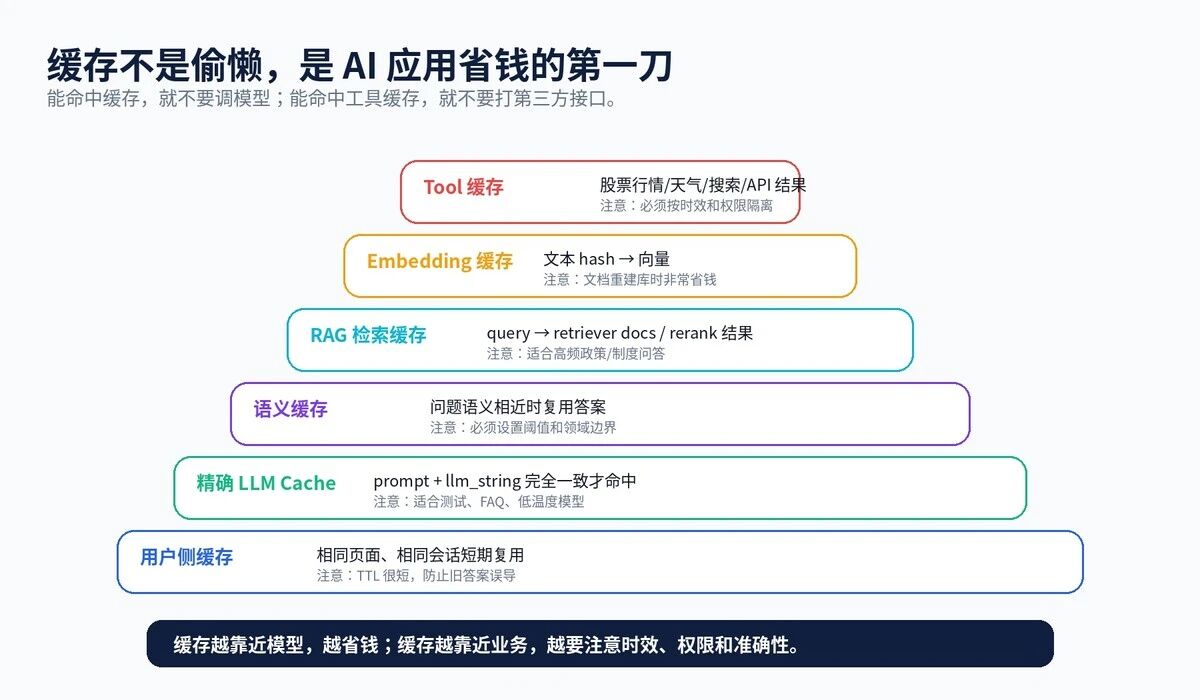
图 5:AI 应用常见缓存层级
缓存不能乱用。实时股票行情、订单状态、库存、价格、政策变更,都要严格设置 TTL。对有权限的数据,还要按用户、租户、角色隔离。
七、重试:只救临时错误,不救逻辑错误
重试不是万能药。它只能处理临时失败,比如 429、网络超时、供应商 5xx。不要对参数错误、鉴权错误、业务校验失败做无限重试。
LangChain 的 `RunnableRetry` 基于 tenacity 做 retry。源码说明里也强调,最好把 retry 范围放小,只包住最可能失败的 Runnable。不要把整条链都包起来,否则一次失败会导致整套 Prompt、检索、工具逻辑重复执行,成本会放大。
Agent 场景下,`ModelRetryMiddleware` 用 `wrap_model_call` 包住模型调用。失败后先判断异常是否可重试,再计算延迟时间,执行指数退避;耗尽次数后,根据 `on_failure` 决定返回错误消息还是直接抛异常。
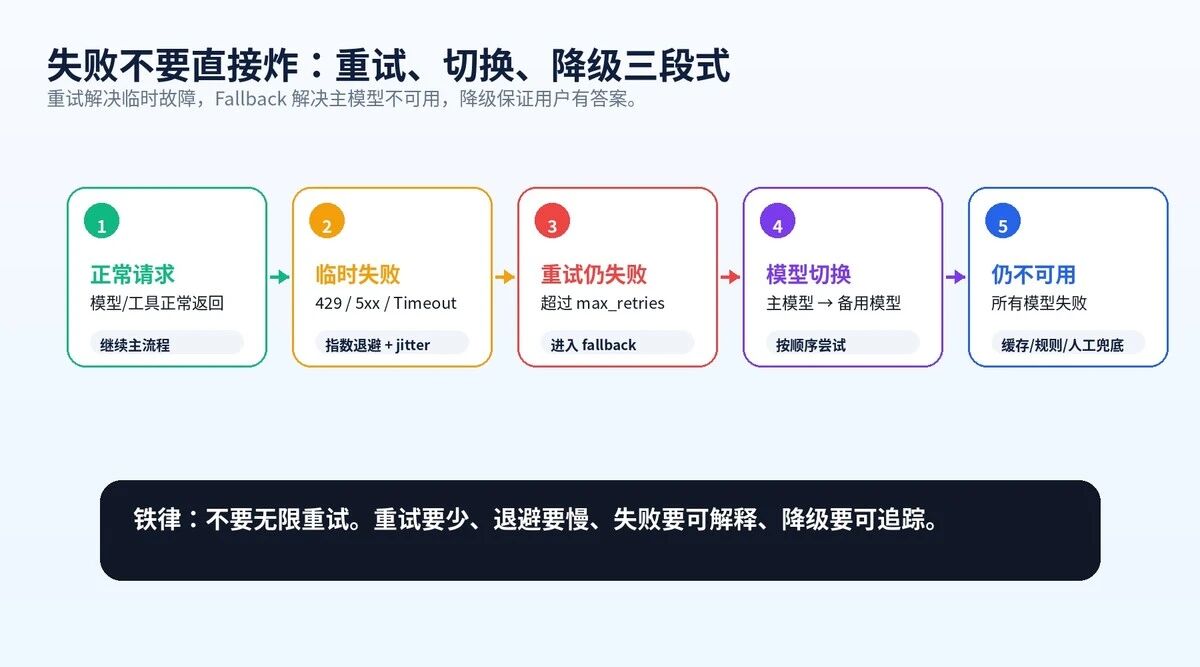
图 6:重试、Fallback、降级三段式
生产建议很简单:
**•**429、Timeout、5xx 可以重试。
**•**401、403、参数校验失败不要重试。
**•**重试次数通常 2 到 3 次足够。
**•**必须加指数退避和 jitter,避免雪崩。
**•**重试失败后要进入 Fallback 或降级,而不是继续死等。
八、Fallback:主模型失败,换路继续走
Fallback 解决的是"主路不可用"。主模型超时、限流、供应商故障时,系统不能直接崩。
LangChain 的 `RunnableWithFallbacks` 逻辑是:先跑主 Runnable,失败后按顺序尝试 fallback;直到某一个成功,或者全部失败。`ModelFallbackMiddleware` 的源码也是这个思路:先调用主模型,捕获异常后,用 `request.override(model=fallback_model)` 切换模型,再重新调用 handler。
Fallback 可以有两种方向:
**•**可靠性 fallback:OpenAI 失败切 Anthropic,或者云服务 A 失败切云服务 B。
**•**成本 fallback:复杂问题用强模型,简单问题用便宜模型,预算不足时切轻模型。
但是要注意:不同模型的工具调用、结构化输出、上下文长度能力不完全一致。Fallback 不是简单换名字,要提前评测。
九、降级:最后一道防线,不是胡说八道
降级不是"随便回一句"。降级是有边界的替代方案。
**•**模型不可用:返回缓存答案或规则答案。
**•**RAG 不可用:提示知识库暂时不可用,不编造来源。
**•**工具不可用:说明实时数据暂时无法获取。
**•**预算耗尽:转轻模型、缩短上下文、只给摘要。
**•**高风险操作失败:暂停执行,转人工。
生产级降级一定要诚实。宁可告诉用户"实时数据暂时不可用",也不要让模型补一个看似合理的假答案。
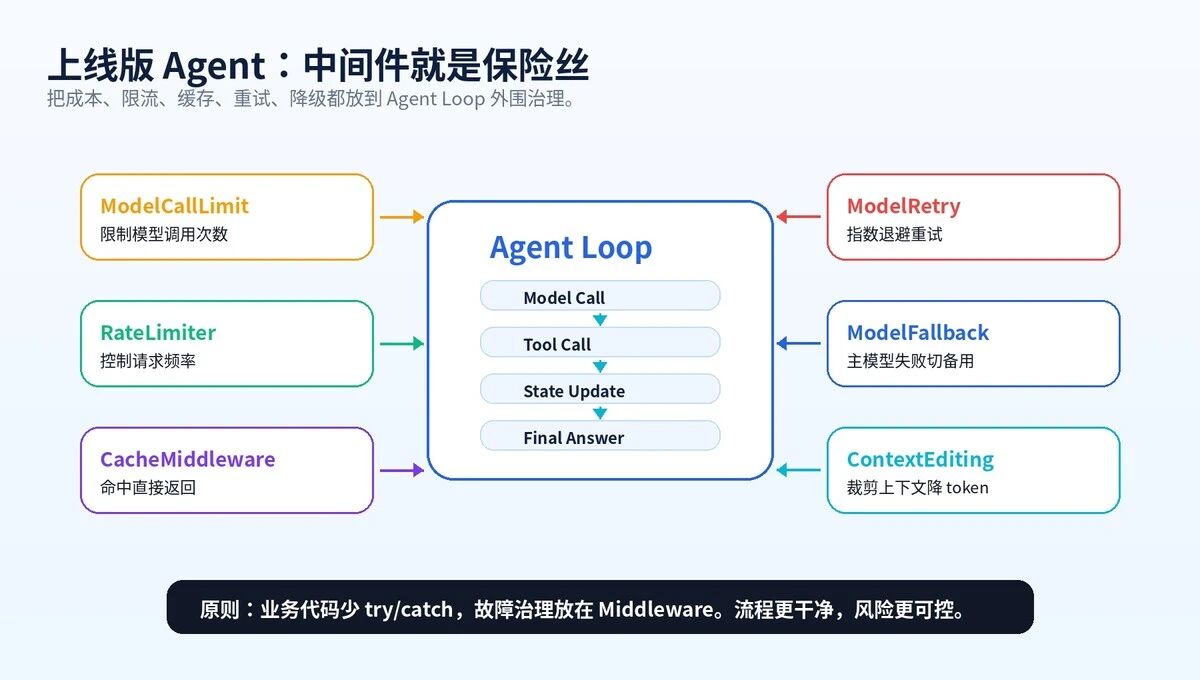
图 7:上线版 Agent 的中间件保险丝
十、源码链路:把治理点挂到 Agent 执行线上
这一章的源码可以压缩成一条线。
请求先进缓存。缓存没命中,再进入限流。拿到令牌,进入模型调用前检查。调用失败,进入重试。重试失败,进入模型 fallback。工具调用前再检查工具预算。最终结果写缓存,写日志,返回用户。
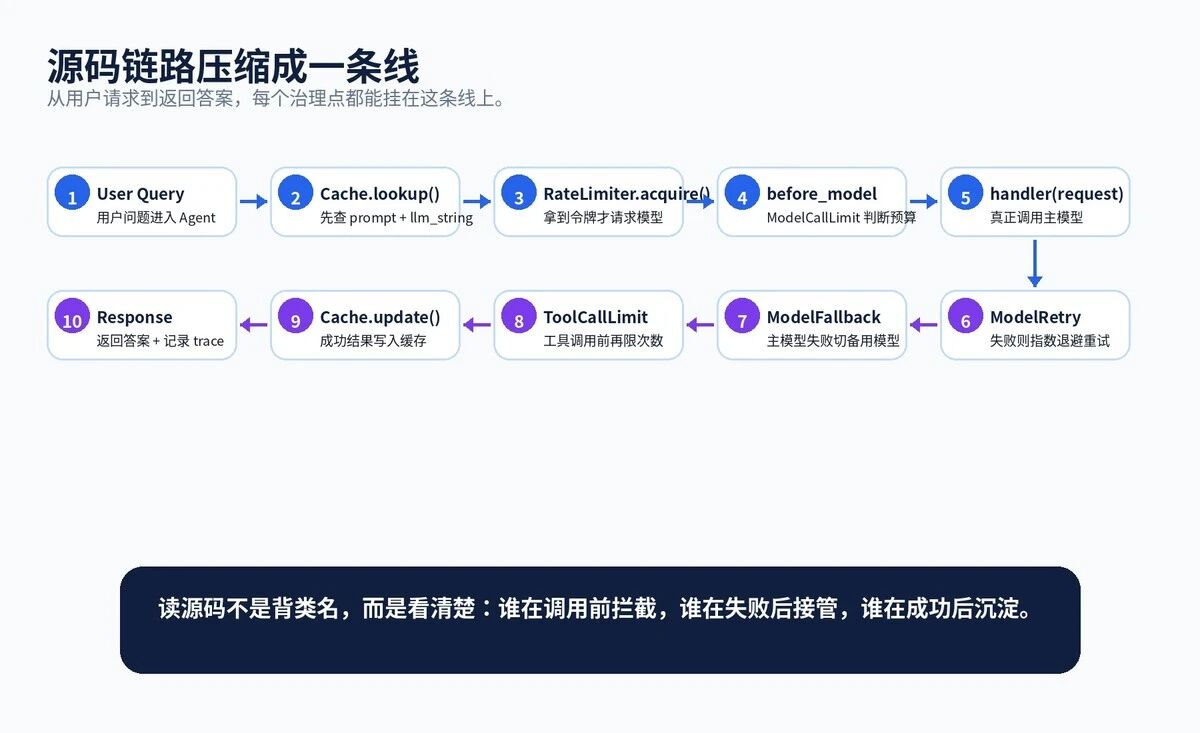
图 8:成本、限流、缓存、重试、Fallback 的源码链路
读源码时别只看类名,要看调用时机:
•`Cache.lookup()` 在模型调用前发挥作用。
•`RateLimiter.acquire()` 在真正请求供应商前发挥作用。
•`ModelCallLimitMiddleware.before_model()` 在模型节点前发挥作用。
•`ModelRetryMiddleware.wrap_model_call()` 包住模型调用过程。
•`ModelFallbackMiddleware.wrap_model_call()` 在主模型失败后切换模型。
•`ToolCallLimitMiddleware` 在工具执行前控制调用次数。
•`Cache.update()` 在成功返回后沉淀结果。
十一、企业级落地:Java 主服务 + Python AI 服务怎么设计?
推荐架构还是:Java 管业务,Python 管 AI。Java 负责用户、权限、额度、计费、接口鉴权、审计日志。Python 负责 LangChain、Agent、RAG、模型调用、工具编排。
最稳的落地方式是四层:
**•**第一层:Java API Gateway。做用户限流、租户额度、请求幂等、鉴权。
**•**第二层:AI Gateway。做模型路由、供应商 fallback、统一 token 计费。
**•**第三层:Python Agent Service。做 LangChain Agent、Middleware、RAG、工具调用。
**•**第四层:Observability。记录 trace、run、token、cache_hit、retry_count、fallback_model、tool_call_count。
不要把所有治理都塞进一个 Python 函数。生产系统要分层。入口层保业务,模型层保供应商,Agent 层保流程,日志层保复盘。

图 9:上线前检查清单
十二、最后总结:Demo 追求聪明,生产追求可控
LangChain 应用上线后,最怕的不是模型答错一次,而是系统失控。调用失控,成本爆炸。重试失控,服务雪崩。工具失控,外部 API 被打爆。日志缺失,问题无法复盘。
核心就一句话:
AI 应用上线,不是让模型自由发挥,而是给模型装上刹车、保险丝和备用路。
把成本、限流、缓存、重试、Fallback、降级、观测做好,LangChain 才能从 Demo 框架变成真正的企业级 AI 工程底座。