1. 目标
将 Claude Code 通过阿里云 AI 网关纳管,实现多模型统一接入、用量统计和按需路由。
2. 前提条件
- 已创建阿里云 AI 网关实例,并给网关所在VPC绑定公网NAT网关
- 已在阿里云百炼控制台开通目标模型(如通义千问、DeepSeek 等)并获取百炼的 API Key
- 安装Claude code客户端
3. 操作步骤
3.1. 创建 AI 服务
- 登录 AI 网关控制台
- 左侧导航栏选择服务 → 创建服务 ,来源选择 AI 服务
- 大模型供应商选择千问云/阿里云百炼,填写百炼 API Key,完成创建
- 如需接入多个供应商(如 DeepSeek),重复以上步骤再创建一个服务
建议 API Key 通过 KMS 凭据引用方式存储,避免明文泄露
3.2. 创建 Model API(Anthropic 兼容协议)
- 左侧导航栏选择 Model API → 创建 Model API → 选择文本生成
- 关键配置:
-
- 协议 :必须选择 Anthropic 兼容(,Claude Code 使用 Anthropic 格式请求)
- BasePath :
/
- 域名最好选择自定义域名,如果没有,可以选择网关提供的域名供测试使用
- 完成创建后发布
注意:协议必须选 Anthropic 兼容,若选 OpenAI 兼容会导致 405 错误
- 服务类型 选择多服务(按模型名称)
- 添加路由规则(使用 Glob 语法匹配模型名):
|-------------|-----------------------|
| Glob 匹配规则 | 路由到的服务 |
| qwen* | qwen(通义千问服务) |
| deepseek* | deepseek(DeepSeek 服务) |
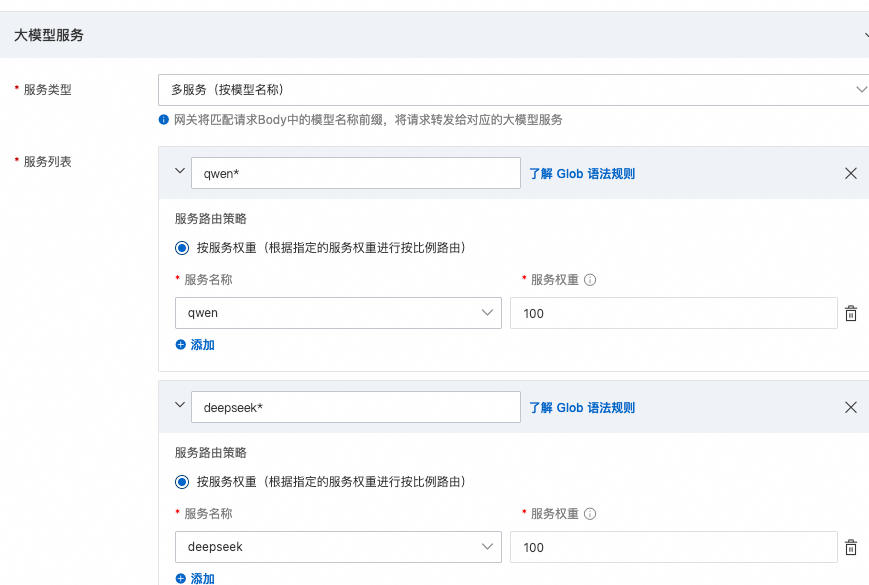
- (选)Fallback 根据需求配置
- 保存并发布
3.3. 配置消费者认证(可选,建议配置)
可给不同使用者分配一个消费者APIKEY,使用者用APIKEY调用后端大模型提供服务,观测方面也可基于消费者纬度进行统计。配置方式如下:
- 创建消费者,进入AI网关控制台,消费者 -创建消费者 -自定义消费者名称,认证方式选择APIKEY,系统自动生成凭证,凭证来源为
Authorization: Bearer <token>。
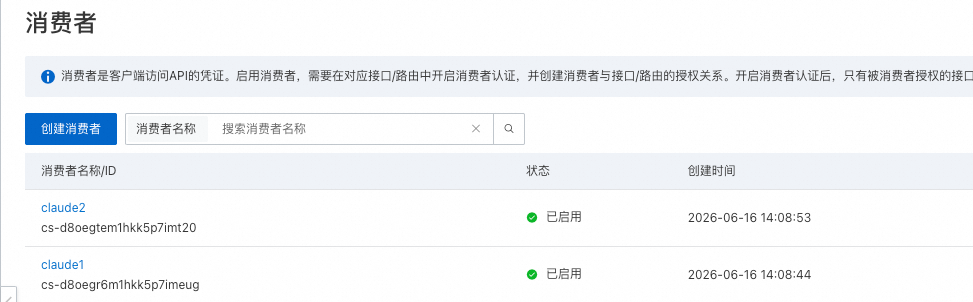
- 配置消费者认证鉴权,进入网关实例, 点击左侧Model API→进入上面创建的modeapi → 消费者认证 → 编辑 → 启用认证
- 点击授权 → 将创建的2个消费者添加进来
3.4. 控制台调试
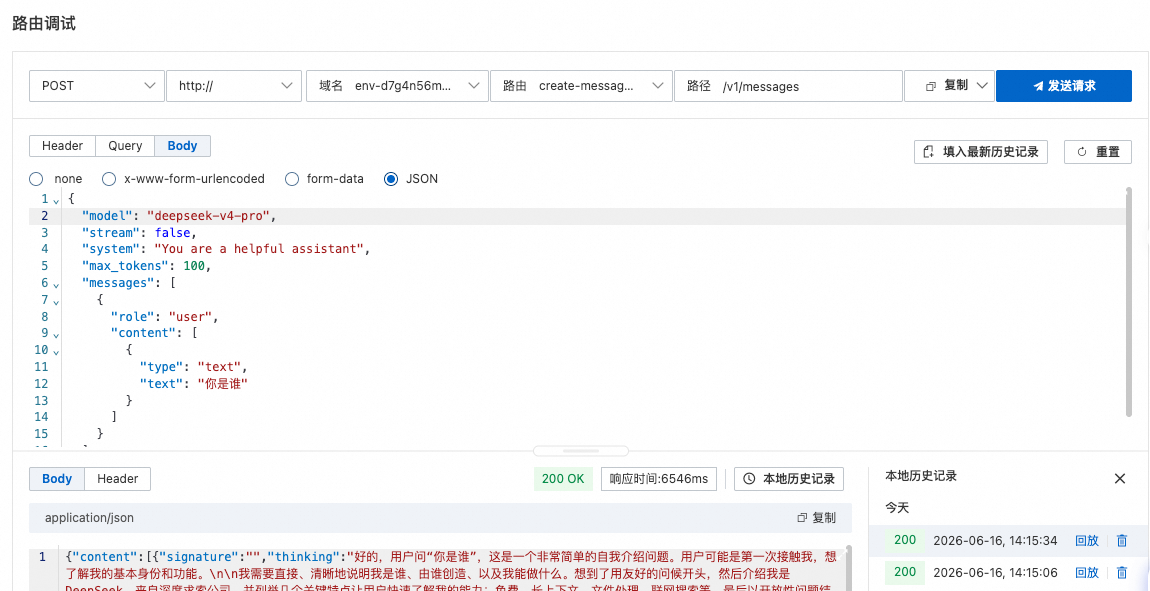
- 进入Medel API,点击右上角调试,发送请求看是否能调用成功,返回200即为成功。
4. 配置 Claude Code
Claude Code 的全局配置文件位于 ~/.claude/settings.json,其中 env 字段下的环境变量会在启动时自动注入,优先级高于终端中手动 export的同名环境变量。
编辑配置文件:
# 用编辑器打开(macOS)
open ~/.claude/settings.json
# 或直接用 vi
vi ~/.claude/settings.json配置文件中环境变量包含以下内容:
{
"env": {
"ANTHROPIC_BASE_URL": "http://env-xxxxxx-cn-hangzhou.alicloudapi.com(网关的公网访问域名,如果网关绑定了自定义域名,使用自定义域名,测试域名每天1000次访问限制)",
"ANTHROPIC_AUTH_TOKEN": "你的消费者凭证APIKEY(未开启认证填任意非空字符串)",
"ANTHROPIC_MODEL": "qwen3.7-max",
"ANTHROPIC_DEFAULT_HAIKU_MODEL": "qwen3.6-flash",
"ANTHROPIC_DEFAULT_SONNET_MODEL": "qwen3.7-max",
"ANTHROPIC_DEFAULT_OPUS_MODEL": "qwen3.7-max",
"CLAUDE_CODE_SUBAGENT_MODEL": "qwen3.7-max"
}
}4.1. 参数说明
|----------------------------------|---------------------------------------------------------------------------------------------------------|
| 参数 | 说明 |
| ANTHROPIC_BASE_URL | AI 网关的访问入口地址,从 Model API 列表页实例访问入口 复制,也可以使用自定义域名,格式:http://env-xxxxxx-cn-hangzhou.alicloudapi.com |
| ANTHROPIC_AUTH_TOKEN | 网关消费者认证凭证。开启认证时填写网关生成的凭证(即API KEY);未开启认证时填任意非空字符串(如 test) |
| ANTHROPIC_MODEL | 默认使用的模型,直接执行 claude 命令时生效 |
| ANTHROPIC_DEFAULT_HAIKU_MODEL | Claude Haiku 角色对应的模型,用于轻量级背景任务(如代码补全、简短问答) |
| ANTHROPIC_DEFAULT_SONNET_MODEL | Claude Sonnet 角色对应的模型,用于常规编程任务(主力模型) |
| ANTHROPIC_DEFAULT_OPUS_MODEL | Claude Opus 角色对应的模型,用于复杂推理任务 |
| CLAUDE_CODE_SUBAGENT_MODEL | Claude Code 内部子 Agent 执行任务时使用的模型 |
排查问题时,务必先检查此文件,因为它会覆盖终端中手动 export 的同名环境变量
4.2. 启动与模型切换
# 使用默认模型(settings.json 中配置的 ANTHROPIC_MODEL)
claude
# 切换到指定模型
claude --model qwen3.6-plus
claude --model deepseek-v4-pro
# 启动后在 Claude Code 内部切换
/model deepseek-v4-pro使用qwen3.6-plus模型:
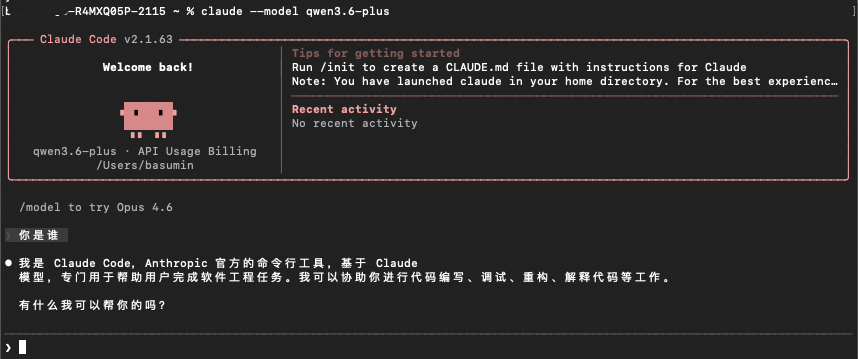
切换成deepseek-v4-pro:

4.3. 添加新模型
以后续添加新模型为例:
- 确认模型名称 :如果添加百炼提供的模型,建议去百炼模型广场找到模型的模型 Code
- 添加路由规则 :AI 网关 → 找到对应Model API → 编辑路由 → 新增 Glob 规则,如
gemini*→ gemini 服务 - 使用 :
claude --model 模型Code
4.4. 验证与排查
验证网关是否可达:
curl -X POST http://env-xxxxxx-cn-hangzhou.alicloudapi.com/v1/messages \
-H "Content-Type: application/json" \
-H "Authorization: Bearer 你的Token" \
-d '{"model":"qwen3.7-max","max_tokens":10,"messages":[{"role":"user","content":"hi"}]}'常见问题:
|-----------------------|---------------------------------------------------|---------------------------------|
| 错误 | 原因 | 解决方案 |
| 403 invalid api-key | Model API 协议选了 OpenAI 兼容 | 重新创建,协议选 Anthropic 兼容 |
| 403 invalid api-key | settings.json 中有旧的 ANTHROPIC_BASE_URL 覆盖了环境变量 | 检查并修改 ~/.claude/settings.json |
| 405 Not Allowed | ANTHROPIC_BASE_URL 缺少路径或路径不对 | 确认完整访问入口地址 |
| model not found | 模型名称与百炼平台不一致 | 去百炼控制台确认模型 Code |
5. 用量观测
所有请求经过 AI 网关后,可在控制台多维度查看用量数据。
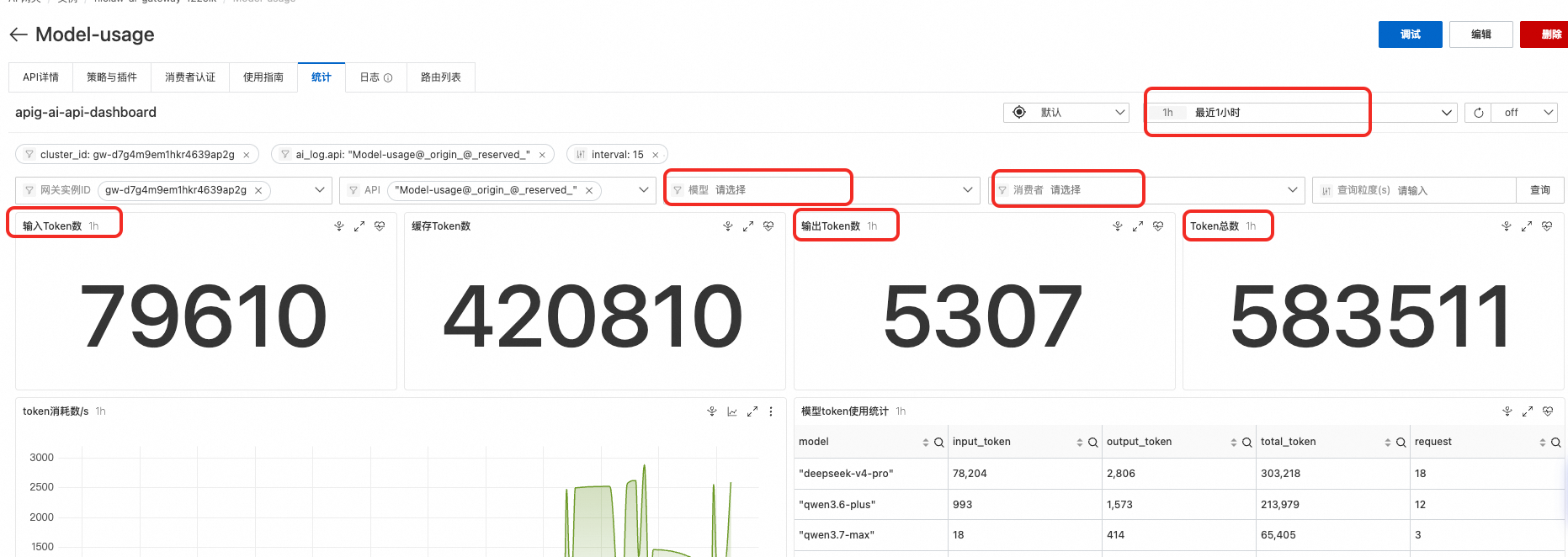
5.1. 查看整体用量
- 登录 AI 网关控制台
- 进入目标 Model API
- 点击统计标签页
可基于模型、消费者 纬度筛选查询某段时间 内的token输入输出量 以及总量。
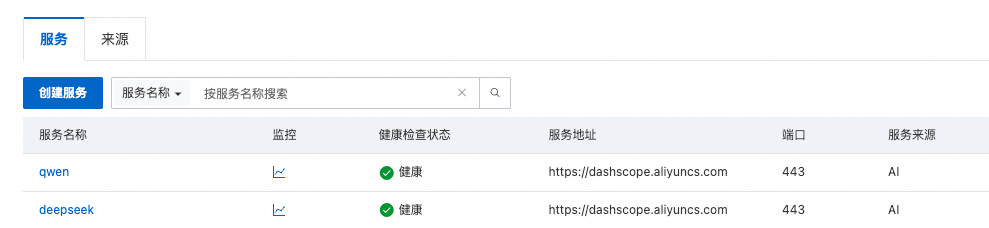
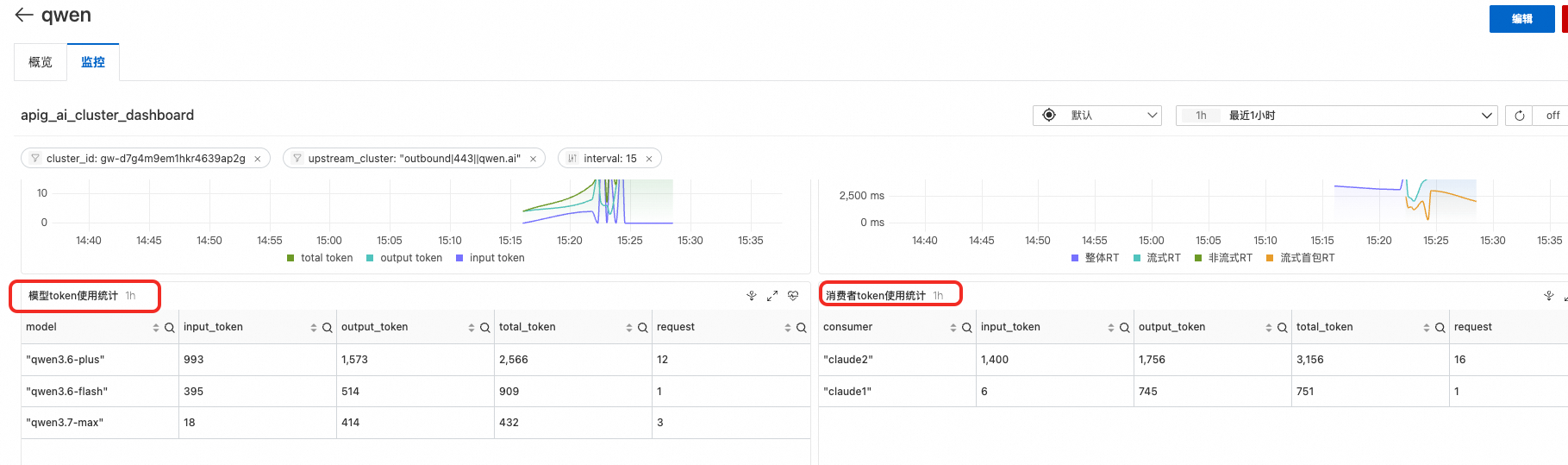
5.2. 按服务区分用量
由于路由配置了按模型名称分发,不同模型的请求会路由到不同的后端服务,可以在各个 AI 服务维度分别查看:
- 进入 AI 网关控制台 → 服务
- 分别点击
qwen(通义千问)和deepseek(DeepSeek)服务 - 点击监控页签,查看各服务的统计数据,即可区分不同模型的用量,也支持查看不同消费者使用此服务的token情况
5.3. 查看请求日志
如需查看每一条请求的详细信息(模型名、耗时、Token 数等):
- 进入 Model API → 日志标签页
- 可筛选时间范围,查看每条请求的模型名称、响应状态、Token 消耗等详情
开启 AI 请求日志后日志功能才可用,在 Model API 详情页 → API 详情 → 找到「AI 请求日志」开关确认已开启
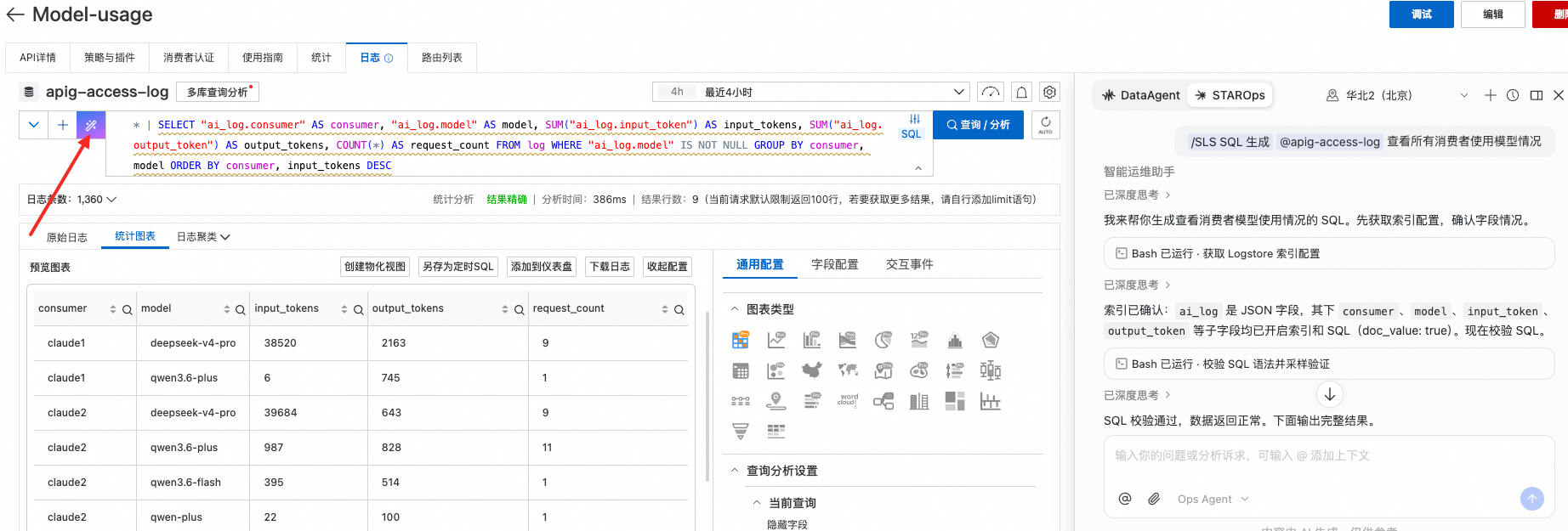
6. 日志聚合查询(按消费者 + 模型统计 Token)
将日志投递到**阿里云日志服务(SLS)**后,可通过 SQL 对日志进行聚合分析,实现按消费者、按模型的 Token 用量统计并导出。
6.1. 查询单个消费者的模型用量
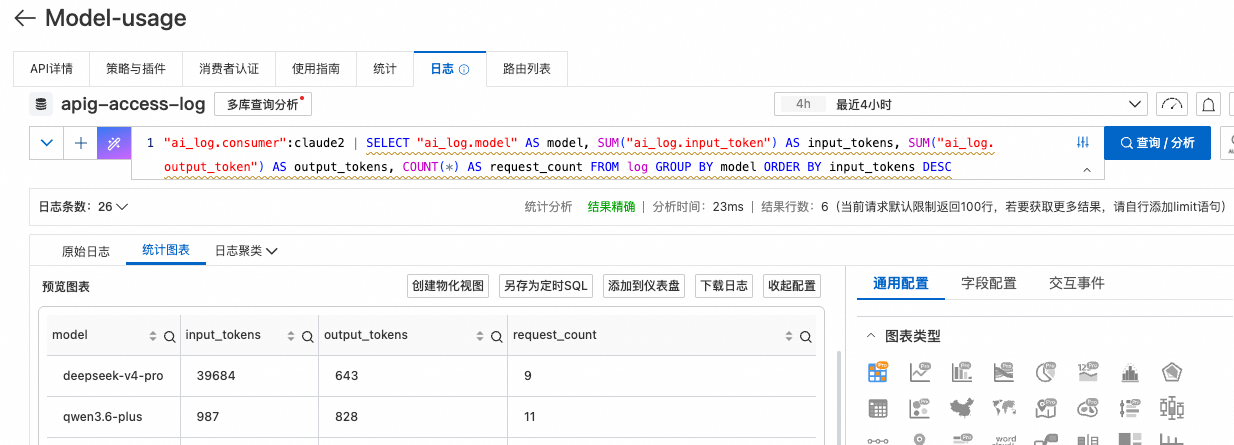
在 SLS 日志查询框中输入以下语句(将 claude1 替换为实际消费者名称):
"ai_log.consumer":claude1 | SELECT
"ai_log.model" AS model,
SUM("ai_log.input_token") AS input_tokens,
SUM("ai_log.output_token") AS output_tokens,
COUNT(*) AS request_count
FROM log
GROUP BY model
ORDER BY input_tokens DESC返回结果示例:
|-----------------|--------------|---------------|---------------|
| model | input_tokens | output_tokens | request_count |
| qwen3.6-plus | 987 | 828 | 11 |
| deepseek-v4-pro | 39684 | 643 | 9 |
6.2. 查询所有消费者的汇总用量
按消费者 + 模型两个维度分组,一次看全局用量分布:
* | SELECT
"ai_log.consumer" AS consumer,
"ai_log.model" AS model,
SUM("ai_log.input_token") AS input_tokens,
SUM("ai_log.output_token") AS output_tokens,
COUNT(*) AS request_count
FROM log
WHERE "ai_log.model" IS NOT NULL
GROUP BY consumer, model
ORDER BY consumer, input_tokens DESC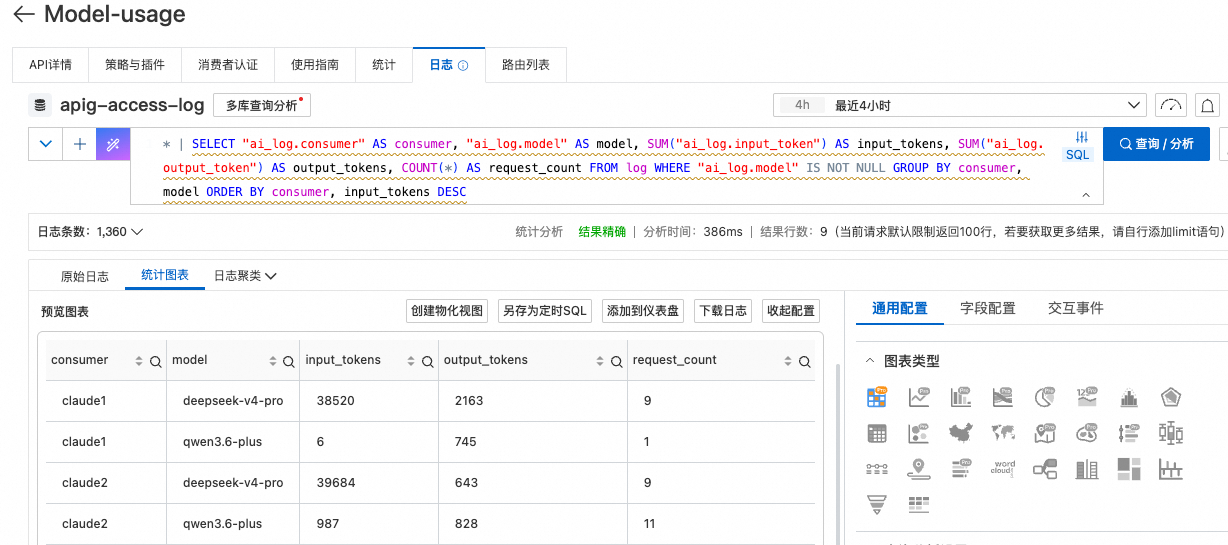
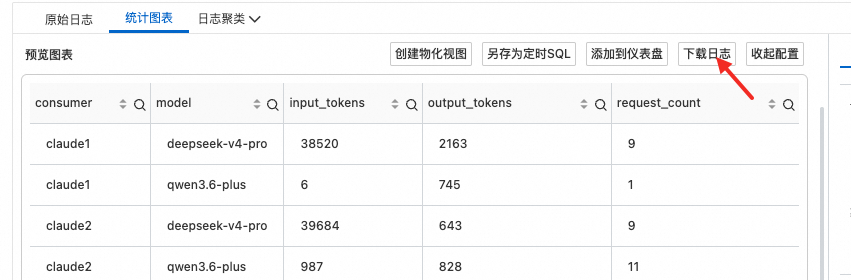
6.3. 导出数据
查询结果出来后,点击 下载日志 按钮,可导出为 CSV 文件,适合进一步用 Excel 分析或汇总费用报表。
6.4. 结合 STAROps
可以通过控制台提供的STAROps入口,通过自然语言查询。