Loop Engineering:AI 编程从提示词走向循环系统
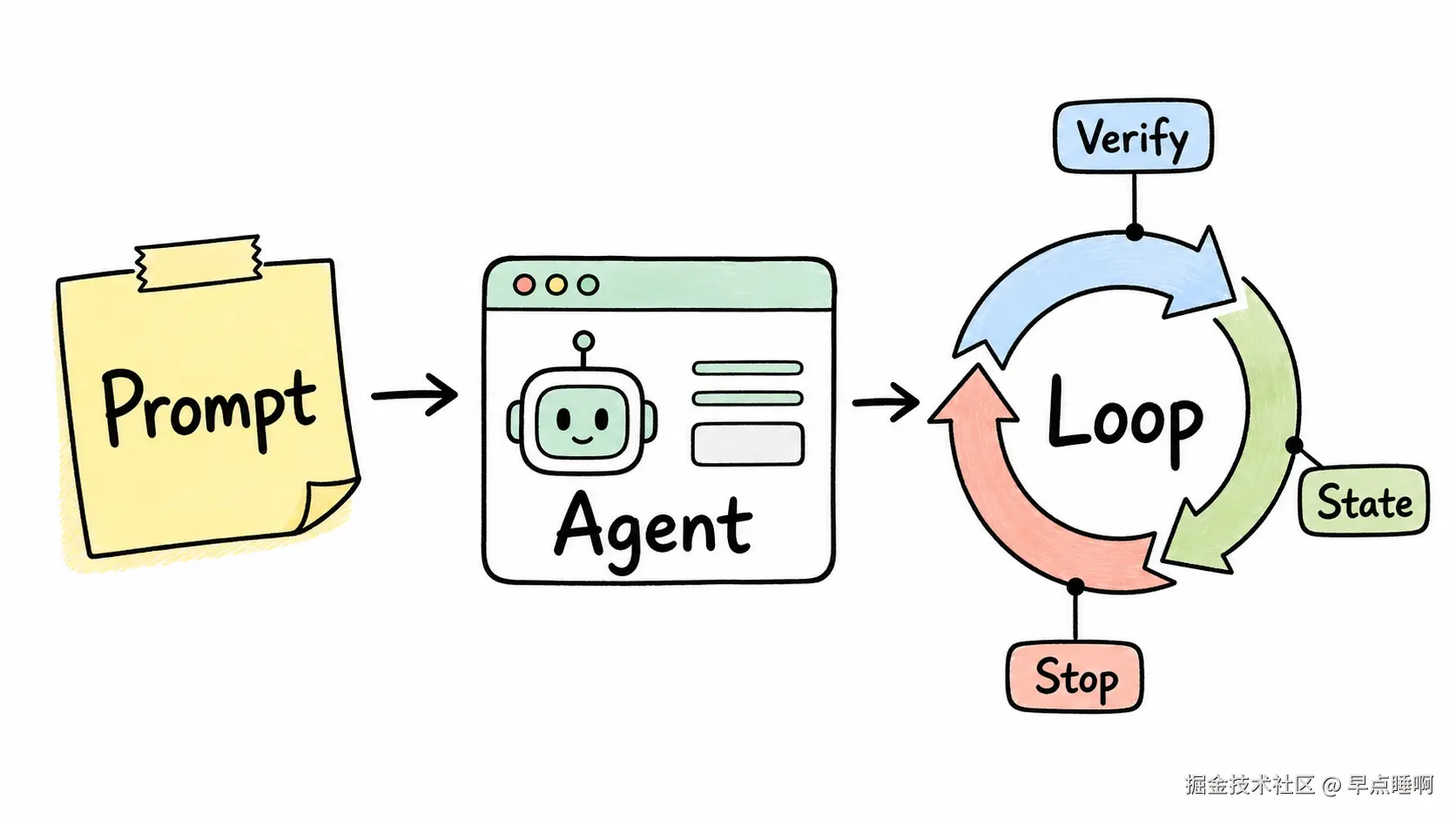
最近 AI 编程,一个新词火爆出圈:Loop Engineering。
以前我们更关心的是:怎么写出更好的 Prompt?怎么让模型一次就能生成更准的代码?怎么把需求描述得更完整?
但现在,经过一段时间AI编程,开发小伙伴们开始遇到另一个问题:即使 Prompt 写得不错,AI 也只能帮你完成一次局部操作。下一步做什么、怎么检查结果、失败后怎么恢复、什么时候应该停止,仍然要靠人盯着。
这就是 Loop Engineering 要解决的问题,它不是一个新的模型,也不是一个新的框架名字。它更像是一种工程组织方式:把 AI Agent 放进一个可以持续运行、可以验证、可以恢复、可以中断的循环系统里。
下面结合 Addy Osmani等大佬的 相关 Loop 文章,我们一起看看Loop Engineering:
未来的 AI 编程能力,不只取决于你会不会写 Prompt,而取决于你会不会设计 Loop。
0. 概述
本文核心主线是:
text
Prompt -> Agent -> Loop -> Engineering System其中:
Prompt:提示词,表示人给模型的一次性或多轮自然语言指令。Agent:智能体,表示可以基于目标、上下文和工具自主完成任务的模型执行单元。Loop:循环,表示每一轮都能读取上下文、执行任务、接受反馈、决定下一步。Engineering System:工程系统,表示带有验证、状态、恢复、安全门和停止条件的可维护系统。
所以,Loop Engineering 不是在讲"让 AI 一直自动跑",而是在讲:
怎么把 AI 的不确定执行能力,放进一个确定性更强、风险可控、结果可验证的工程闭环里。
下面这张图可以先帮我们把主线串起来:
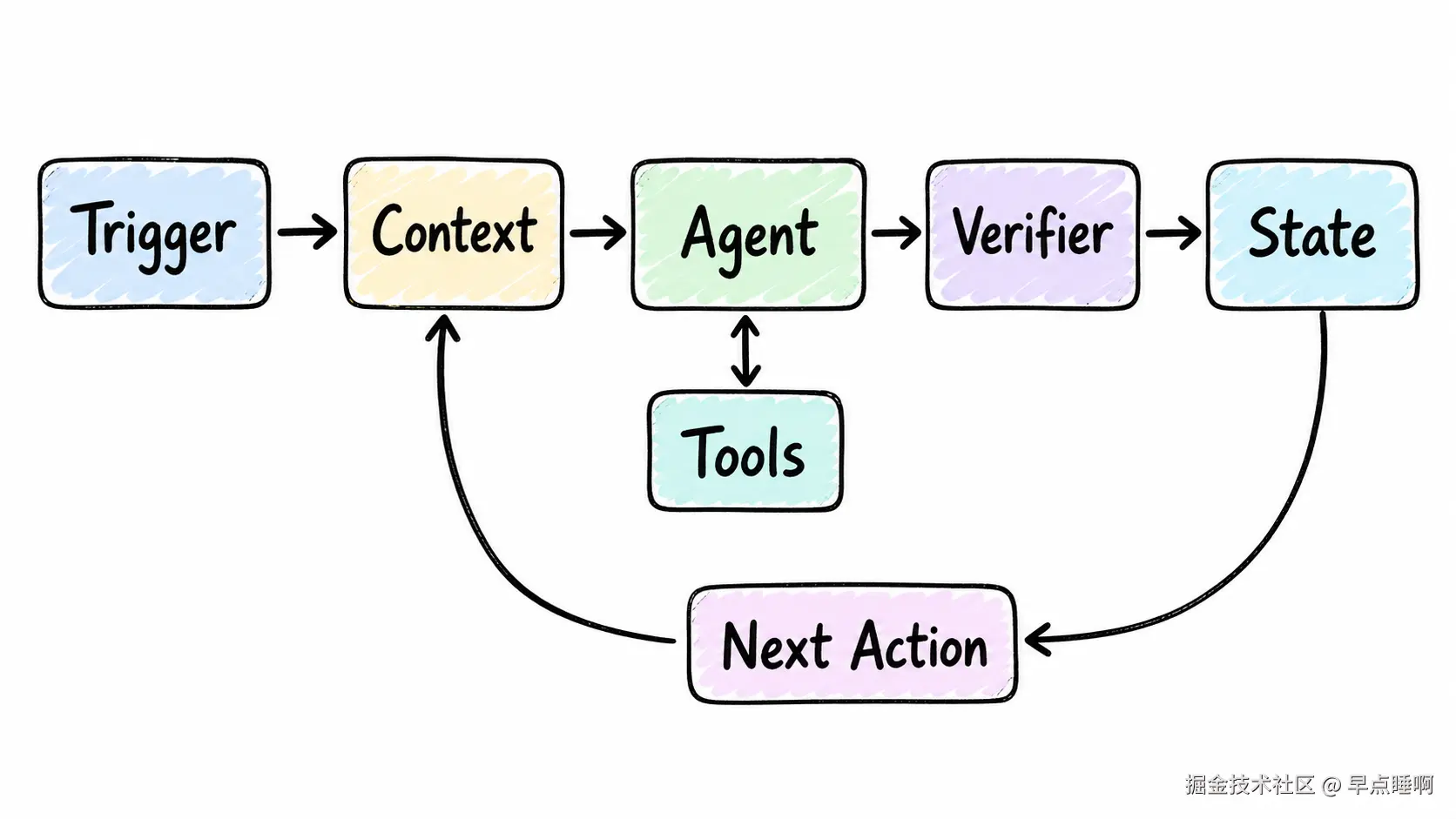
图里可以重点看这条链路:
text
触发任务 -> 加载上下文 -> Agent 执行 -> 验证结果 -> 记录状态 -> 决定下一步这条链路,就是后面所有模块要展开的主线。
1. Prompt Engineering(提示词工程)为什么开始不够用了
它解决的问题:
先理解 Loop Engineering,必须先理解 Prompt Engineering 的边界。Prompt Engineering 解决的是"怎么把一句话说清楚",但它不负责"这件事做完以后系统该怎么继续运转"。
示例:
text
请帮我修复这个单元测试失败的问题,并解释你修改了哪些文件。这是一条不错的 Prompt。它有目标,也有输出要求。
但它没有回答这些问题:
- 测试失败日志从哪里来?
- 模型应该读取哪些代码文件?
- 修改前要不要创建隔离工作区?
- 修改后运行哪些验证命令?
- 如果验证失败,最多重试几次?
- 如果涉及删除文件或数据库迁移,要不要停下来让人确认?
- 这次任务的状态记录在哪里?
这里:
Prompt Engineering:提示词工程,重点是优化人和模型之间的一次性交互质量。Prompt:提示词,通常包含任务目标、上下文、约束和输出格式。output format:输出格式,例如要求模型返回 Markdown、JSON、代码 diff 或执行计划。context:上下文,表示模型完成任务时需要读取的需求、代码、日志、文档和历史记录。
业务场景:
一个开发者让 AI 修一个 bug,第一次 AI 可能给出可用修改;第二次测试失败,开发者再把日志贴给 AI;第三次又要提醒它不要改别的模块。这个过程中,人类其实在手动扮演"循环控制器"。
最简记法:
text
Prompt 解决"这一轮怎么说",Loop 解决"下一轮怎么走"。2. Loop Engineering(循环工程)到底是什么
它解决的问题:
Loop Engineering 解决的是:当 AI Agent 不再只是聊天,而是要参与真实工程任务时,怎样设计一条可持续、可验证、可恢复的执行闭环。
可以先把它理解成一个公式:
text
Loop Engineering = Trigger + Context + Agent + Tools + Verifier + State + Human Gate + Stop Condition示例:
text
每天 9 点:
1. 扫描昨天失败的 CI 任务
2. 选择一个低风险测试失败
3. 创建独立工作区
4. 调用 Agent 分析和修改
5. 运行测试和静态检查
6. 成功则生成 PR 草稿
7. 失败两次则记录原因并停止这里:
Trigger:触发器,决定循环什么时候开始,例如定时任务、Issue、PR 评论、告警或人工按钮。Context:上下文,表示每一轮 Agent 执行前必须读取的信息。Tools:工具,例如文件读写、命令行、浏览器、数据库、GitHub、Figma、日志系统。Verifier:验证器,用测试、类型检查、静态扫描、人工审查等方式检查结果。State:状态,记录当前执行到哪里、产物在哪里、失败原因是什么。Human Gate:人工安全门,遇到高风险动作时停止并等待确认。Stop Condition:停止条件,定义什么时候成功、失败、暂停或转人工。
业务场景:
在一个真实团队里,AI 不应该直接"随便改代码"。更合理的做法是:它只处理一个明确的小任务,在隔离目录里修改,通过测试后留下变更摘要,最后让人 review。
最简记法:
text
Loop Engineering 不是让 AI 更自由,而是让 AI 的行动被系统接住。3. Open Loop 与 Closed Loop(开放循环与闭合循环)
它解决的问题:
很多人听到 Loop,会误以为是"让模型一直重复执行"。真正有工程价值的是闭合循环,也就是每一轮都要根据反馈决定下一步,而不是无条件继续。
示例:
开放循环:
text
while true:
让 Agent 继续修复问题闭合循环:
text
while not stop:
让 Agent 执行一个小任务
运行验证命令
根据验证结果决定继续、重试、升级给人工或停止这里:
open loop:开放循环,指没有明确反馈判断和停止条件的循环。closed loop:闭合循环,指执行结果会被验证,验证结果会影响下一步动作。feedback:反馈,表示测试结果、错误日志、代码审查意见、用户确认或业务指标。retry limit:重试上限,表示同一任务最多允许自动尝试几次。budget:预算,可以是 token 成本、运行时间、API 调用次数或人工等待成本。
业务场景:
如果一个 Agent 连续 10 次修同一个测试都失败,它不应该第 11 次继续瞎试。更好的处理是:记录失败日志、总结已经尝试过的方案、把任务升级给人类工程师。
最简记法:
text
开放循环会放大错误,闭合循环才会吸收反馈。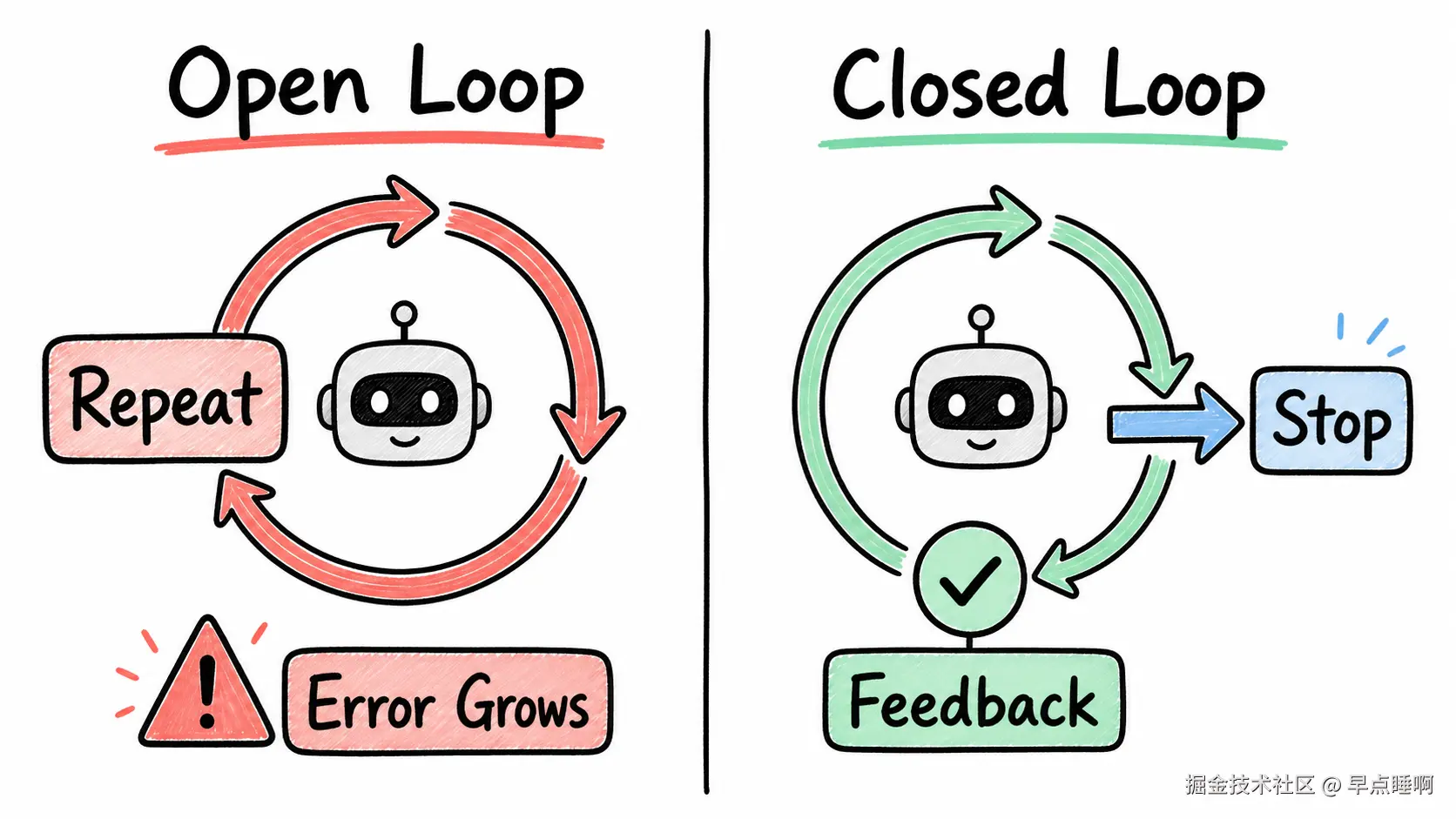
4. Agent Runner(智能体执行器)
它解决的问题:
Agent Runner 负责把一个明确的小任务交给模型执行。它不是整个系统的全部,只是 Loop 里的执行节点。
示例:
python
import os
from openai import OpenAI
client = OpenAI(
api_key=os.environ["QWEN_API_KEY"],
base_url=os.environ["QWEN_BASE_URL"],
)
# 这个函数负责把一次明确的小任务交给模型执行,并返回模型生成的文本结果。
def run_agent_task(task_description: str, context_text: str) -> str:
response = client.chat.completions.create(
model="qwen3.7-max",
messages=[
{
"role": "system",
"content": "你是一个谨慎的软件工程助手。每次只处理一个小任务,避免无关重构。",
},
{
"role": "user",
"content": f"任务:{task_description}\n\n上下文:\n{context_text}",
},
],
)
return response.choices[0].message.content这里:
OpenAI:OpenAI-compatible SDK 客户端,这里通过兼容格式调用qwen3.7-max。QWEN_API_KEY:环境变量,保存模型服务密钥,不应写入代码仓库。QWEN_BASE_URL:环境变量,保存 OpenAI-compatible 服务地址。run_agent_task:函数名,表示"运行一次 Agent 小任务"。task_description:参数名,表示这轮要完成的具体任务描述。context_text:参数名,表示传给模型的上下文文本。messages:模型消息列表,通常包含system和user两类消息。role:消息角色,system表示系统约束,user表示用户任务。content:消息内容,保存自然语言指令或上下文。
业务场景:
在一个代码修复 Loop 里,Agent Runner 每次只处理一个小范围问题,例如"修复 tests/test_user_api.py 中的失败用例"。它不负责决定是否继续,也不负责最终验收。
最简记法:
text
Agent Runner 是执行手,不是裁判,也不是总指挥。5. Context Loader(上下文加载器)
它解决的问题:
上下文加载器负责决定每一轮 Agent 应该看什么。上下文太少,模型会猜;上下文太多,模型会迷路;上下文不稳定,循环会逐轮变形。
示例:
python
from pathlib import Path
# 这个函数负责读取循环任务所需的稳定上下文文件。
def load_context(workspace_dir: Path) -> str:
context_files = [
"AGENTS.md",
"IMPLEMENTATION_PLAN.md",
"loop-state.json",
]
parts = []
for file_name in context_files:
file_path = workspace_dir / file_name
if file_path.exists():
parts.append(f"## {file_name}\n{file_path.read_text(encoding='utf-8')}")
return "\n\n".join(parts)这里:
Path:Python 标准库中的路径对象,用来跨平台处理文件路径。load_context:函数名,表示"加载本轮循环需要的上下文"。workspace_dir:参数名,表示当前项目工作目录。context_files:变量名,表示固定要读取的上下文文件列表。AGENTS.md:给 Agent 阅读的项目约束文件,通常包含代码规范、禁止行为和验证命令。IMPLEMENTATION_PLAN.md:实现计划文件,用来把长任务拆成可执行步骤。loop-state.json:循环状态文件,用来保存当前阶段、失败原因和下一步动作。
业务场景:
Ralph Loop 这类实践强调把计划、约束和状态外化到文件里。这样即使模型上下文被重置,下一轮也能从同一份文件恢复,而不是靠聊天记录残留记忆。
最简记法:
text
上下文不要只放在聊天窗口里,要放到循环每轮都能读到的地方。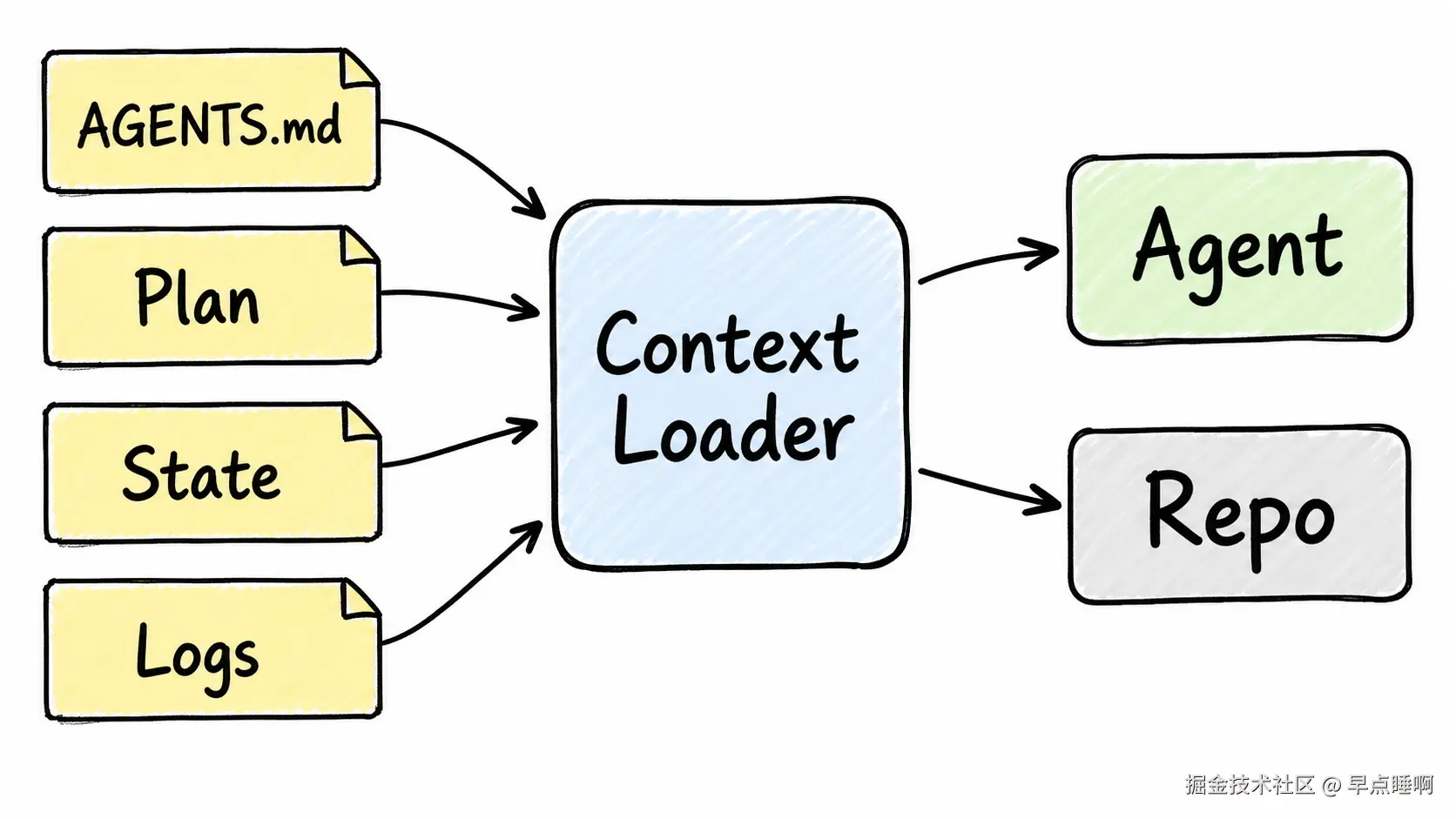
6. Workspace Isolation(工作区隔离)
它解决的问题:
当多个 Agent、多个任务或多次重试同时发生时,最怕的是互相污染代码。工作区隔离就是把每个任务放到可控边界里执行。
示例:
text
main repository
|
+-- worktree/fix-login-test
|
+-- worktree/update-readme
|
+-- worktree/refactor-parser这里:
workspace isolation:工作区隔离,表示不同任务使用不同目录、分支、容器或沙箱执行。worktree:Git 提供的工作树机制,允许同一个仓库在不同目录检出不同分支或提交状态。branch:分支,用来保存某个任务的独立修改线。sandbox:沙箱,表示限制文件、网络或命令权限的隔离环境。diff:代码差异,表示本次任务相对于基线代码的修改内容。
业务场景:
如果一个 Agent 正在修登录测试,另一个 Agent 正在改 README,第三个 Agent 正在重构解析器,最好让它们在不同 worktree 里执行。最后再由人或 CI 检查每个变更是否值得合并。
最简记法:
text
让 Agent 并行前,先给每个任务一张自己的工作台。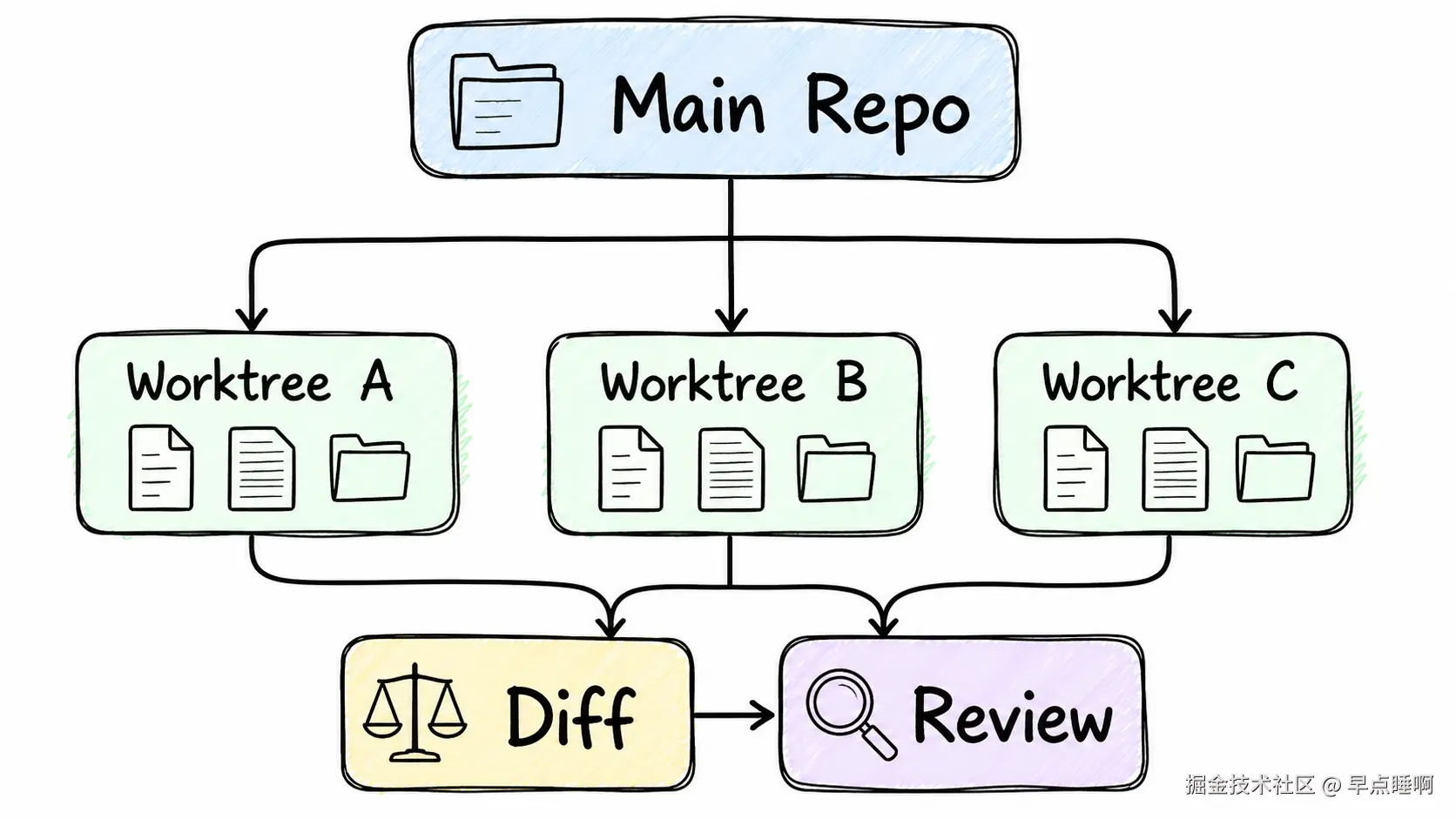
7. Verifier(验证器)才是 Loop 的刹车系统
它解决的问题:
如果没有验证器,Loop Engineering 就只是更快地自动化错误。SonarSource 那篇文章的核心提醒正是:没有 verification 的 loop,只是 automation。
示例:
python
import subprocess
# 这个函数负责运行确定性的验证命令,并返回是否通过。
def run_verification(commands: list[list[str]]) -> bool:
for command in commands:
result = subprocess.run(command, text=True, capture_output=True)
if result.returncode != 0:
print(result.stdout)
print(result.stderr)
return False
return True
verification_passed = run_verification([
["python", "-m", "pytest"],
["python", "-m", "ruff", "check", "."],
])这里:
subprocess.run:Python 标准库函数,用来运行命令行命令。commands:参数名,表示需要依次运行的验证命令列表。returncode:返回码,0通常表示命令成功,非0表示失败。stdout:标准输出,保存命令正常输出内容。stderr:标准错误,保存命令错误输出内容。verification_passed:变量名,表示验证是否通过。pytest:Python 测试框架,用来运行单元测试或集成测试。ruff:Python 代码检查工具,用来做静态检查和格式相关检查。
业务场景:
代码修复类 Loop 中,模型说"我修好了"没有意义。真正有意义的是:测试是否通过、类型检查是否通过、静态扫描是否通过、关键业务用例是否通过。
最简记法:
text
Agent 可以生成答案,Verifier 才决定答案能不能进下一步。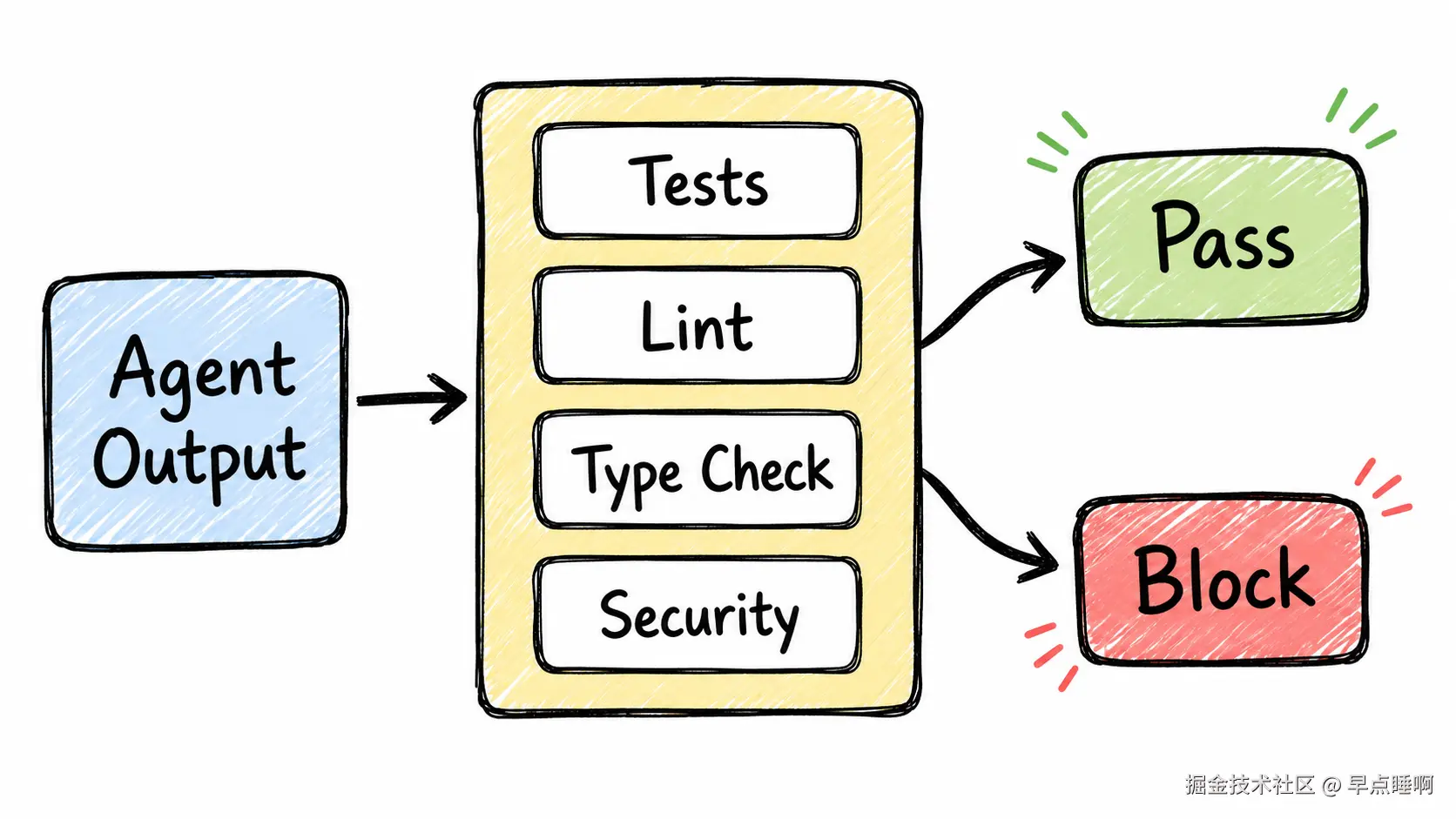
8. State Store(状态存储)决定循环能不能恢复
它解决的问题:
Loop 不是一次聊天。如果任务会持续 10 分钟、1 小时甚至几天,就必须把状态写下来。否则一旦上下文丢失、进程中断或工具失败,就只能从头再来。
示例:
json
{
"task_id": "fix-login-test-20260616",
"current_phase": "verification",
"attempt_count": 2,
"last_error": "tests/test_login.py::test_token_expired failed",
"next_action": "summarize_failure_and_request_human_review",
"artifacts": {
"worktree_path": "./worktrees/fix-login-test",
"diff_path": "./outputs/fix-login-test.diff"
}
}这里:
task_id:任务编号,用来唯一标识一次循环任务。current_phase:当前阶段,例如planning、implementation、verification、review。attempt_count:尝试次数,用来限制自动重试上限。last_error:最近一次失败原因。next_action:下一步动作,用来在中断后恢复任务。artifacts:产物集合,记录工作区路径、diff 文件、日志文件、报告文件等。worktree_path:隔离工作区路径。diff_path:代码差异文件路径。
业务场景:
一个文档生成任务如果中途断了,状态文件应该告诉系统:来源摘要已经完成、文章草稿已经完成、图片生成到第几张、草稿 URL 是什么、下一张图片该上传哪一个。
最简记法:
text
没有 State,Loop 就没有记忆;没有恢复点,自动化越长越脆。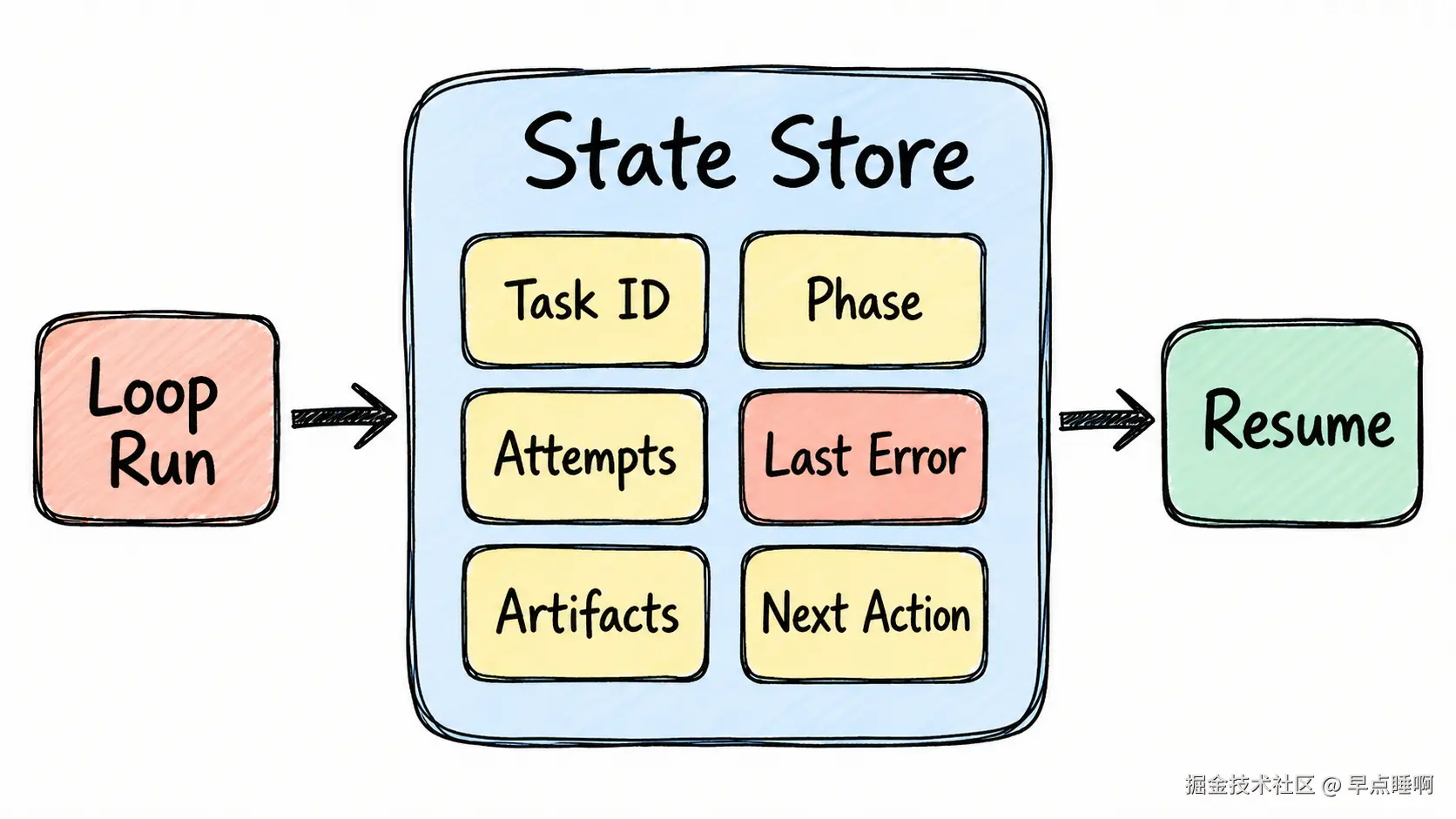
9. Human Gate(人工安全门)
它解决的问题:
AI Agent 越能干,越不能让它无限制行动。Human Gate 负责定义哪些动作必须停下来,让人类明确确认。
示例:
python
# 这个函数负责判断某个动作是否需要人工确认。
def requires_human_gate(action_name: str) -> bool:
risky_actions = {
"delete_files",
"publish_article",
"deploy_production",
"run_database_migration",
"send_customer_email",
"change_permissions",
}
return action_name in risky_actions这里:
requires_human_gate:函数名,表示"判断是否需要人工安全门"。action_name:参数名,表示当前准备执行的动作名称。risky_actions:变量名,表示高风险动作集合。delete_files:删除文件。publish_article:发布文章。deploy_production:部署生产环境。run_database_migration:运行数据库迁移。send_customer_email:给客户发送邮件。change_permissions:修改权限配置。
业务场景:
让 Agent 自动生成掘金草稿可以接受,但让它直接点击"发布"就不应该默认发生。让 Agent 修改代码可以接受,但让它删除项目外文件、操作远程仓库或改生产数据库,就必须有人工确认。
最简记法:
text
Human Gate 不是降低效率,而是给不可逆动作加保险。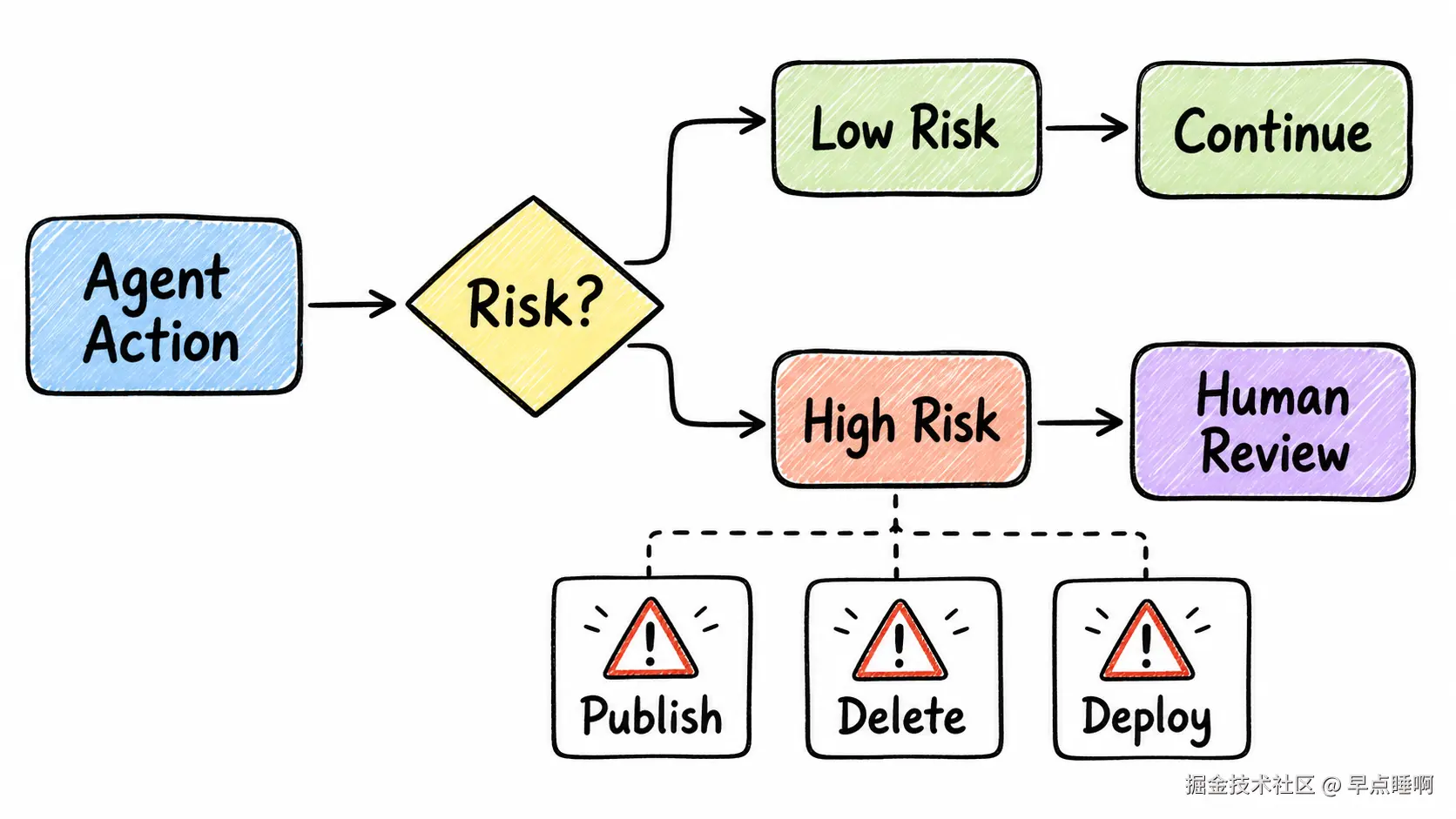
10. Stop Condition(停止条件)比启动条件更重要
它解决的问题:
很多自动化系统只设计"怎么开始",没有认真设计"什么时候停"。Loop Engineering 必须把停止条件写清楚,否则就会出现无限重试、成本失控和错误放大。
示例:
python
# 这个函数负责根据验证结果、尝试次数和预算判断循环是否应该停止。
def should_stop(verification_passed: bool, attempt_count: int, token_budget_left: int) -> bool:
if verification_passed:
return True
if attempt_count >= 2:
return True
if token_budget_left < 5000:
return True
return False这里:
should_stop:函数名,表示"判断循环是否应该停止"。verification_passed:参数名,表示验证是否通过。attempt_count:参数名,表示已经自动尝试的次数。token_budget_left:参数名,表示剩余 token 预算。True:布尔值,表示应该停止。False:布尔值,表示可以继续。
业务场景:
如果测试已经通过,循环应该停止并生成总结;如果失败超过 2 次,也应该停止并请求人工审查;如果预算不足,还继续让模型尝试,通常只是制造更贵的混乱。
最简记法:
text
Loop 的成熟度,不看它能跑多久,而看它知不知道什么时候该停。11. 最小可行 Loop:从一个代码仓库维护任务开始
它解决的问题:
理解概念之后,最容易犯的错是立刻想做一个"全自动研发系统"。更稳妥的方式是先做一条很窄的小闭环。
示例:
text
目标:每天检查一个低风险失败测试,并尝试自动修复。
输入:
- 昨天失败的 CI 日志
- 相关测试文件
- 相关业务代码
- AGENTS.md 项目约束
循环:
1. 选择一个失败测试
2. 创建隔离 worktree
3. 加载上下文
4. 调用 Agent 修改
5. 运行 pytest 和 lint
6. 成功则输出 diff 和总结
7. 失败两次则停止并记录原因这里:
CI:持续集成,用来自动运行测试、构建和检查。lint:代码风格和静态规则检查。diff:本次修改前后的差异。AGENTS.md:项目内的 Agent 约束说明,告诉 Agent 什么可以做、什么不能做。pytest:Python 测试命令,示例中代表确定性验证命令。
业务场景:
在一个中小团队里,这条 Loop 的价值很直接:它不会替你合并代码,也不会自动上线,但它能每天把一部分低风险维护工作处理成"可 review 的草稿"。
最简记法:
text
第一条 Loop 不要追求全自动,要追求小、稳、可验证。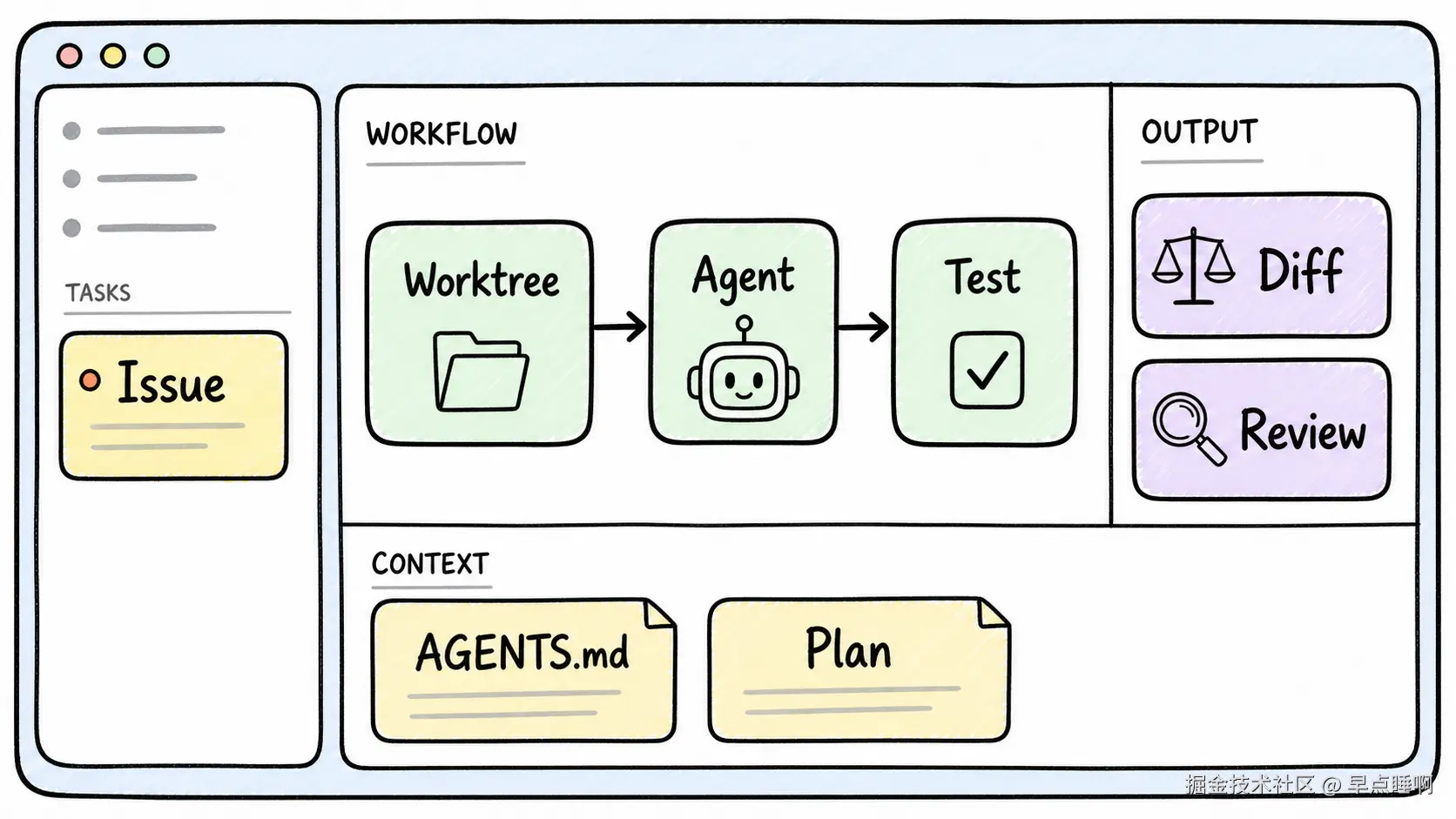
12. Loop Engineering 对工程师意味着什么
它解决的问题:
最后要回答一个更现实的问题:Loop Engineering 火起来之后,工程师是不是就不需要写代码了?
答案不是。
工程师的工作会从"只写某一段代码",逐渐扩展成"设计一套能让 AI 安全做事的系统"。
示例:
text
过去:
我写代码 -> 我运行测试 -> 我修 bug -> 我提交 PR
现在:
我定义目标 -> 我设计上下文 -> 我配置 Agent -> 我设置验证器 -> 我审查结果 -> 我改进循环这里:
goal:目标,表示这条循环最终要达成什么结果。context design:上下文设计,决定 Agent 每轮能看到什么。verification design:验证设计,决定用什么确定性证据判断结果。loop improvement:循环改进,表示根据失败记录、人工审查和成本数据持续优化闭环。
业务场景:
一个技术负责人不应该只问"我们买哪个 AI 编程工具",还应该问"我们有哪些重复任务适合做成 Loop,哪些验证命令足够稳定,哪些动作必须人工确认,失败记录沉淀在哪里"。
最简记法:
text
未来工程师不是少设计系统,而是要把 AI 也设计进系统。总结
Loop Engineering 可以压缩成下面这张心智表:
| 模块 | 作用 |
|---|---|
Prompt |
说明这一轮要模型做什么 |
Agent |
根据目标、上下文和工具执行任务 |
Trigger |
决定循环什么时候启动 |
Context Loader |
决定每轮读取哪些上下文 |
Workspace Isolation |
避免多个任务互相污染 |
Verifier |
用确定性证据检查结果 |
State Store |
记录阶段、产物、失败原因和下一步 |
Human Gate |
遇到高风险动作时交给人确认 |
Stop Condition |
决定循环什么时候成功、失败或暂停 |
一句话总结:
Loop Engineering 的核心不是"让 AI 一直干活",而是"让 AI 在可验证、可恢复、可停止的工程闭环里干活"。
学习时可以分三层理解:
text
第一层:Prompt 到 Agent,解决单次任务执行。
第二层:Agent 到 Loop,解决连续任务推进。
第三层:Loop 到 Engineering System,解决验证、状态、权限、成本和恢复。如果你现在已经在使用 AI 编程工具,下一步不用急着追最新模型。更值得做的是挑一个真实但低风险的重复任务,设计一条小 Loop:
text
明确目标 -> 固定上下文 -> 限定工作区 -> 运行 Agent -> 执行验证 -> 记录状态 -> 设置停止条件这才是从"会用 AI"走向"会工程化使用 AI"的关键一步。
参考来源
(文章参考多篇文章,并结合了一些自己的理解,欢迎大家指正、互相学习)
- Addy Osmani:Loop Engineering
- Firecrawl:Loop Engineering: Should You Stop Prompting Agents and Start Designing Loops
- SOTA Sync:WTF Is a Loop
- SonarSource:Loop engineering without verification is just automation
- Geoffrey Huntley:everything is a ralph loop
- GitHub:ghuntley/how-to-ralph-wiggum