【LLM】第二章:HuggingFace入门学习
HuggingFace是一个提供开源预训练模型 和相关工具链的平台,目前已经是一个完整的AI开发生态系统,支持NLP、计算机视觉、语音处理、多模态任务等多个领域。我们使用HF可以简化预训练模型的使用,加速项目的开发和落地。
说明:学习大模型,会使用HuggingFace是必备的,因为HuggingFace是大模型的框架。大模型之于HuggingFace就像神经网络之于pytorch一样。所以本章我们先入门一下HuggingFace的基本操作。
一、HuggingFace概述
HF生态系统主要由两个核心部分组成:
1、HuggingFace Hub,是一个提供托管和分享模型、数据集、各种AI应用的开源平台。
(1)HuggingFace官网地址:https://huggingface.co/ 官网我们国内一般访问不了。
(2)国内镜像地址:HF-Mirror 我们一般用这个镜像地址。
(3)国内类似的网站还有比如:ModelScope 魔搭社区
2、工具链(Libraries)
HF提供了一套围绕预训练模型构建的工具库,覆盖从数据处理到模型训练与推理的完整流程。
(1)Datasets:用于加载和处理数据集的工具库。支持在线仓库、本地文件加载数据、数据清洗、编码、切分等预处理操作。处理后的数据可直接用于模型训练。
(2)Tokenizers:用于将文本转化为模型输入的工具。比如文本分词、编码(token ID)、处理特殊符号、填充(padding)、attention mask、句子对标记(token type ID)等。
由于每个模型,它的特殊符号、输入格式都不一样,所以每个模型都有其对应的Tokenizer,我们一般加载model的时候,也加载其tokenizer。
(3)Transformers:用于加载、使用各种微调方法训练模型、保存预训练模型。支持数百种预训练模型,用于只需要from_pretrained()直接加载公开模型,就可以进行训练和推理。
二、预训练模型的加载
1、下载预训练模型
如果你是window系统,你需要在你的环境变量中添加HF_ENDPOINT="https://hf-mirror.com" ,如下图所示: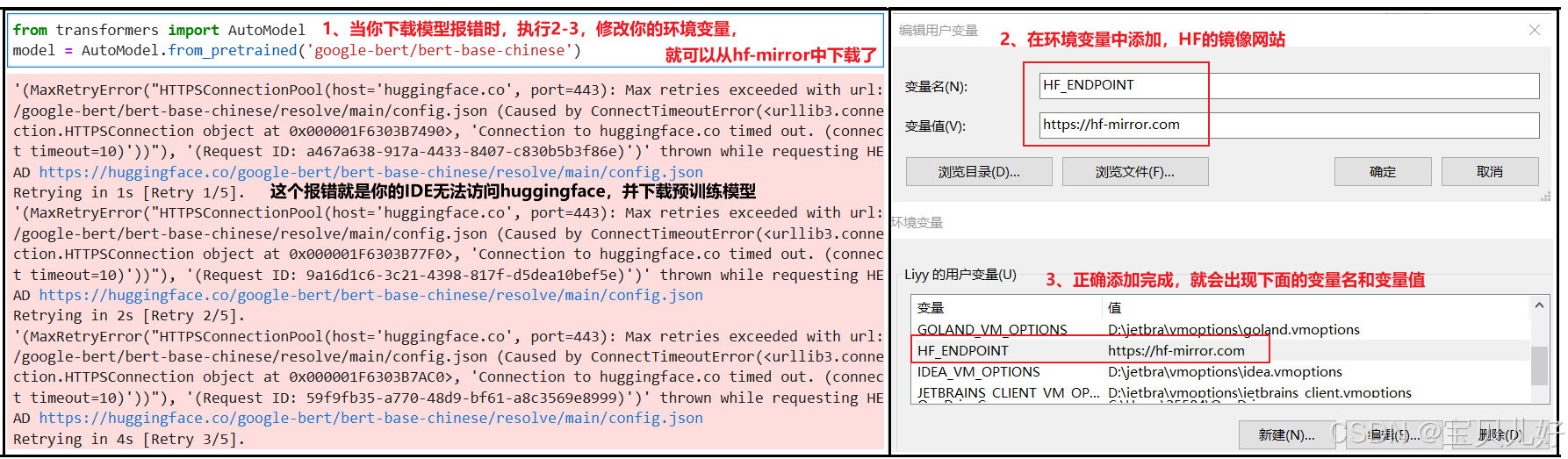 这样AutoModel会根据模型名称,从hf-mirror上下载所需的模型权重和模型的配置文件,这些文件默认下载到~/.cache/huggingface/hub/下面。下次你再加载的时候,就会直接先从缓存中读取,不再联网下载了。
这样AutoModel会根据模型名称,从hf-mirror上下载所需的模型权重和模型的配置文件,这些文件默认下载到~/.cache/huggingface/hub/下面。下次你再加载的时候,就会直接先从缓存中读取,不再联网下载了。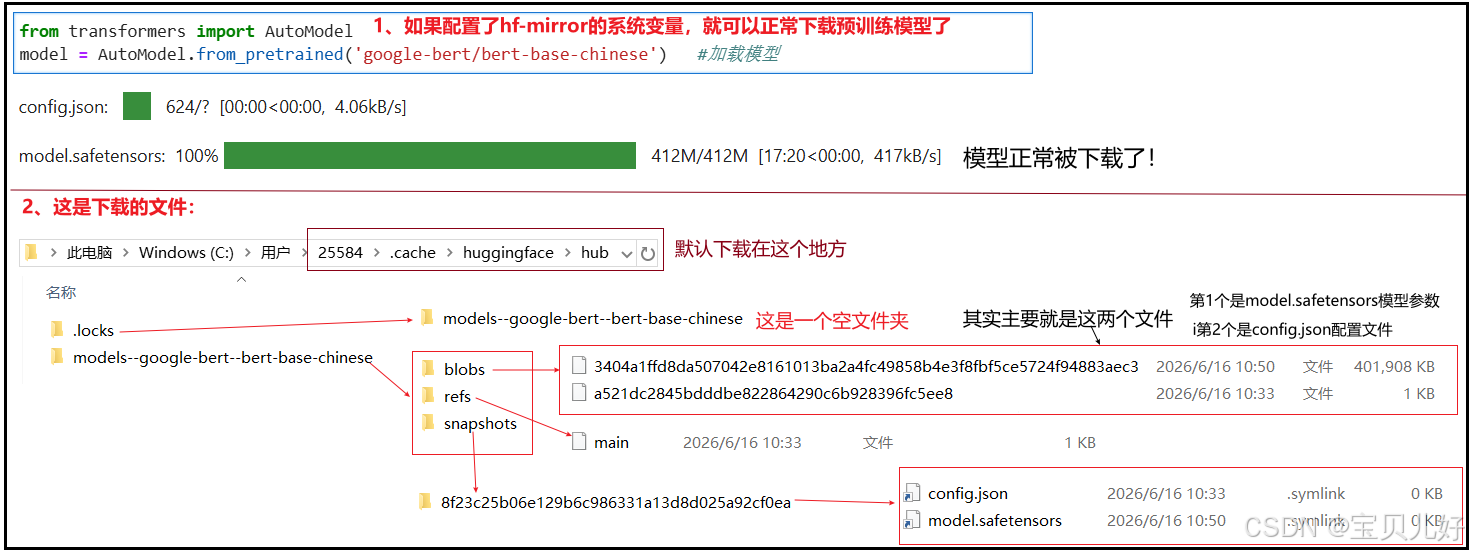
这是我们下载完毕的bert-base预训练模型: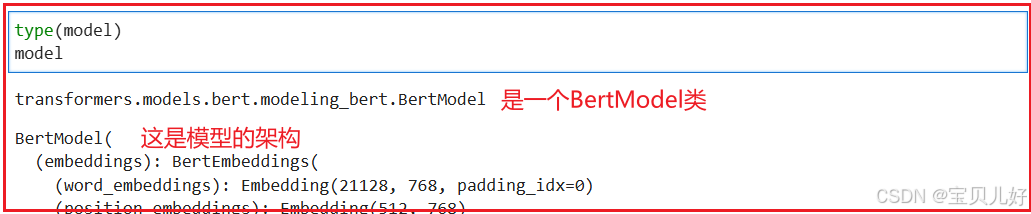
2、加载本地已有的预训练模型
假如我们本地就已经有bert-base和其对应的配置文件了,我们只需要加载一下即可: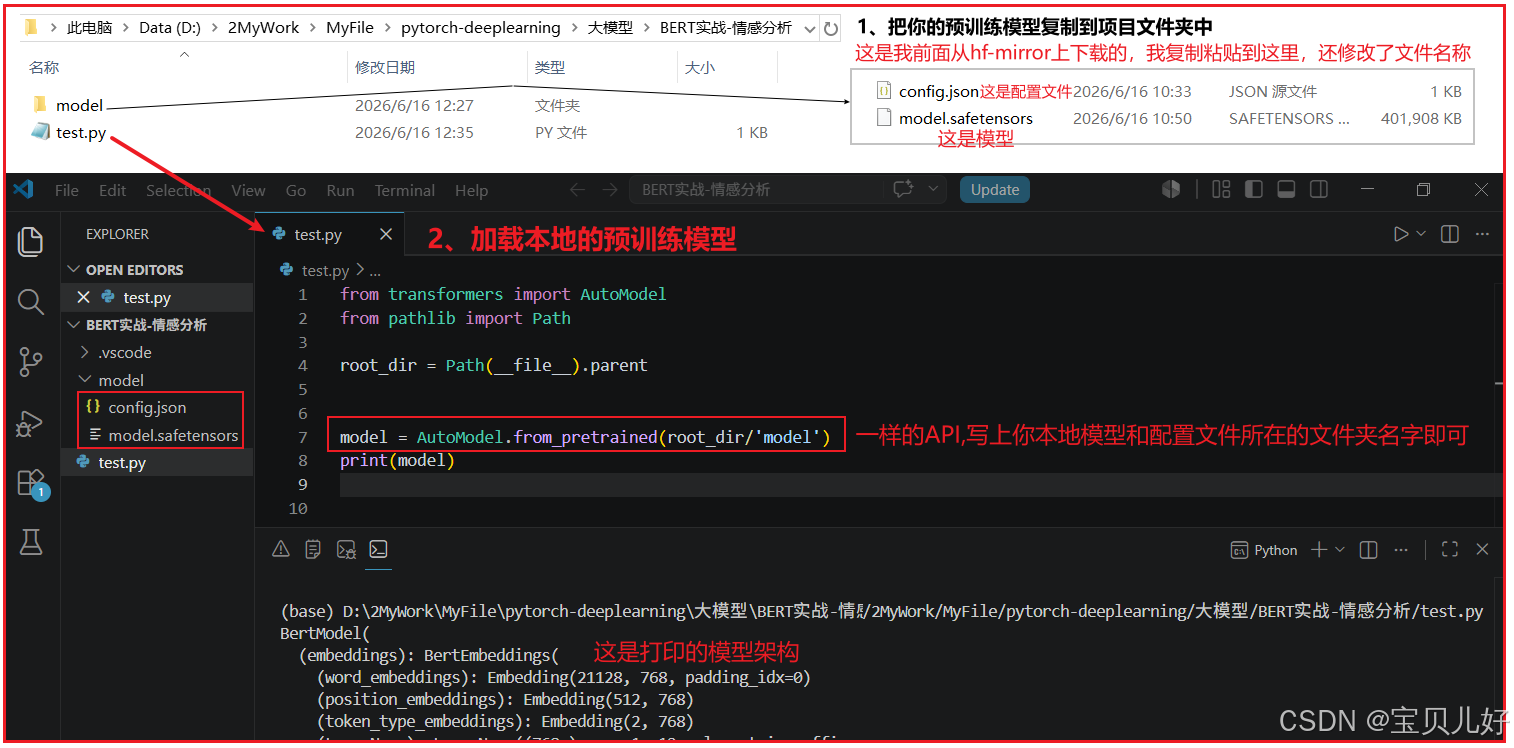
三、添加任务头(Task Head)
上面的AutoModel只是 加载预训练的主干结构,我们想把模型迁移到具体的下游任务上,我们还得添加适配具体任务 的输出层,也就是我们通常说的任务头(Task Head) 。
1、Transforms也提供了添加具体任务头的类
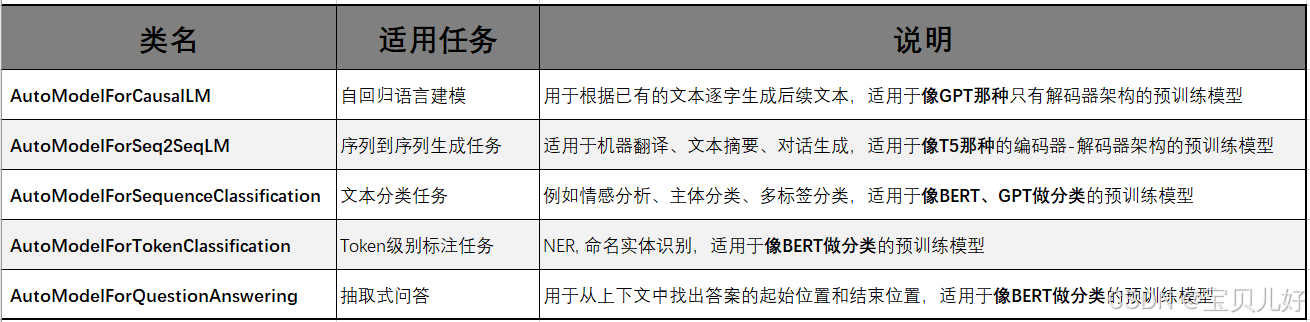
这样模型就可以直接用于分类、命名实体识别、问答等任务的训练和推理了。
2、示例:给bert-base预训练模型添加句子分类头
也就是要用bert-base来对句子文本进行情感判断。
待续。。。。