模型不是看一眼就会:一文搞懂监督学习、标签、Loss 与训练循环
第 03 讲《监督学习:数据、标签、Loss与训练循环》
整理说明:本文基于 B 站视频《第03讲〈监督学习:数据、标签、Loss与训练循环〉》的公开信息、课程课件主线,并结合 PyTorch 训练循环常见写法进行原创化整理。本文不是逐字稿,重点是把"模型如何通过做题、对答案、改参数来学习"整理成科研小白能照着学、照着跑、照着排错的教程。

上一讲我们讲清楚了一件事:模型看到的不是照片,而是一组排列好的数字,也就是张量。
那今天继续往前走。
有了输入张量以后,模型到底是怎么学会的?
很多新手第一次训练模型时,会有一个很朴素的想法:我把图片丢进去,模型看一遍,不就应该会了吗?
但真实情况不是这样。
模型一开始就像刚进考场的新手。你给它看猫,它可能说是狗;你给它看缺陷图,它可能说正常;你让它框目标,它可能框到背景上。
它不是看一眼就懂,而是反复经历一个过程:
做题 → 对答案 → 算错多少 → 改参数 → 再做题
这就是监督学习的训练循环。
01 本讲只解决一个问题
神经网络怎样通过"做题---对答案---改参数"来学习?
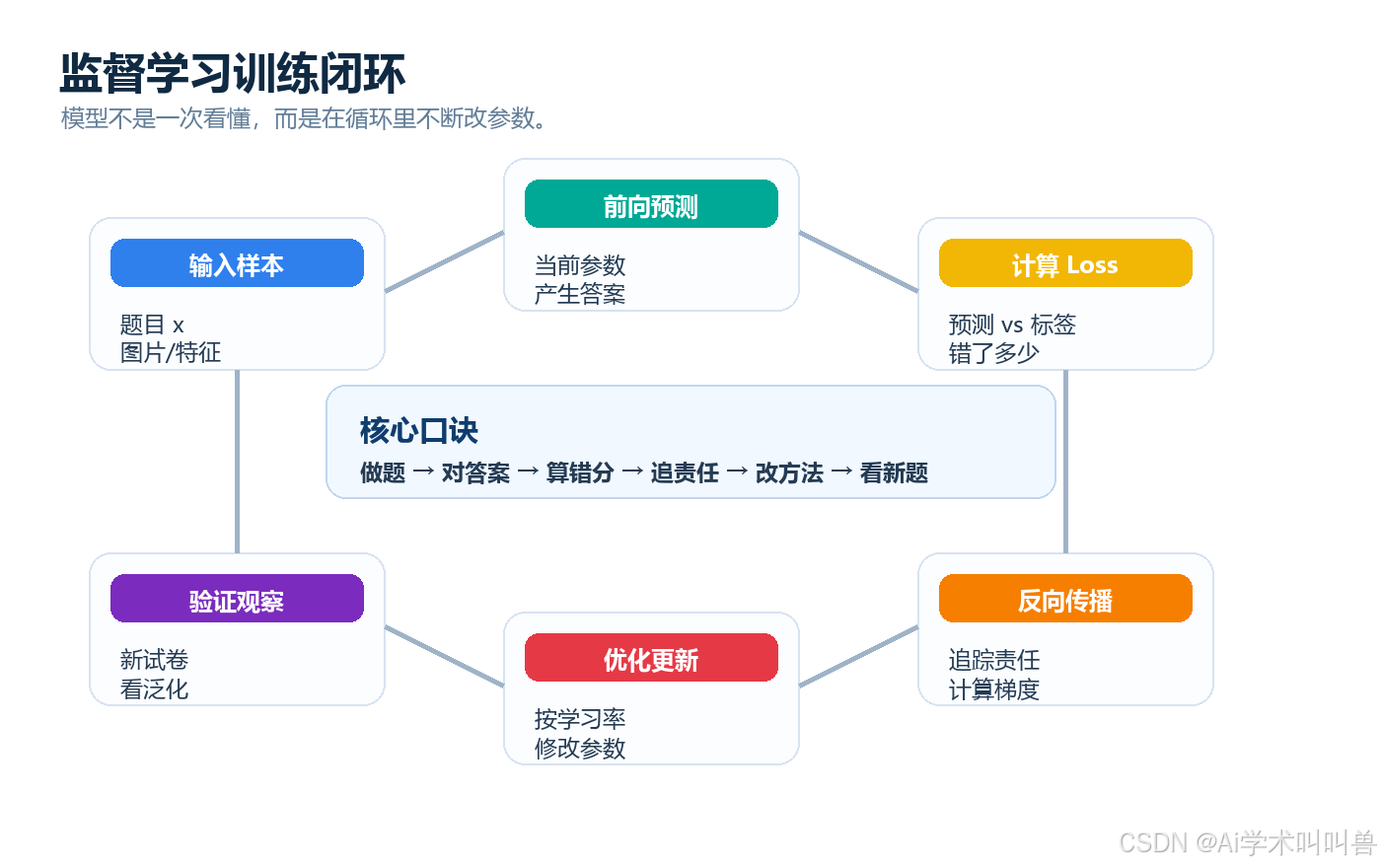
把训练看成学生做题,就很清楚:
| 训练环节 | 学生做题类比 | 深度学习术语 |
|---|---|---|
| 输入样本 | 题目 | x、图片张量、特征 |
| 标签 | 标准答案 | y、类别、边界框 |
| 预测 | 学生写的答案 | y_pred |
| Loss | 错了多少分 | 损失函数 |
| 梯度 | 往哪改更接近答案 | grad |
| 参数更新 | 修改做题方法 | optimizer step |
| 验证观察 | 换一张新试卷检查 | validation |
所以别再把训练想成"模型自己神秘变聪明"。
训练就是一次又一次地让模型做题,然后用标签告诉它错在哪里,再用 Loss 和梯度推动参数往更好的方向改。
02 先把 6 个词说清楚
| 概念 | 一句话解释 | 小白理解 |
|---|---|---|
| 训练集 | 用于计算 Loss 并更新模型参数的数据 | 平时刷的练习册 |
| 验证集 | 训练过程中观察泛化能力的数据 | 模拟考试 |
| 测试集 | 最终评估真实性能的数据 | 期末验收 |
| 标签 Label | 监督学习中的参考答案 | 标准答案 |
| Loss | 把预测错误转成可优化的数值 | 错题分 |
| 学习率 | 每次参数更新走多大一步 | 改错时下笔力度 |
这里最重要的是前三个集合不要混:

一句话记住:
训练集用来学,验证集用来挑,测试集用来验。
如果你把验证集也拿去训练,验证结果就会失真;如果你反复用测试集调参,测试集也不再是公正的最终考试。
03 一次训练循环到底发生了什么?
一次完整训练循环可以拆成 6 步:
- 输入样本:取一批图片或特征作为模型输入。
- 前向预测:模型用当前参数产生预测结果。
- 计算 Loss:比较预测和标签的差异。
- 反向传播:计算每个参数对 Loss 的影响方向。
- 优化更新:按梯度和学习率修改参数。
- 验证观察:用未参与更新的数据判断是否泛化。
这 6 步就是你以后看训练代码的主线。
python
for epoch in range(num_epochs):
model.train()
for x, y in train_loader:
pred = model(x)
loss = loss_fn(pred, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
model.eval()
# 在验证集上观察效果科研小白第一次看训练代码,不要一行一行死背。你要问:
- 哪一行做预测?
- 哪一行算 Loss?
- 哪一行清空梯度?
- 哪一行反向传播?
- 哪一行更新参数?
- 哪一段是在验证集上观察?
能回答这 6 个问题,你就已经抓住了训练循环的骨架。
04 epoch、batch、learning rate 怎么记?
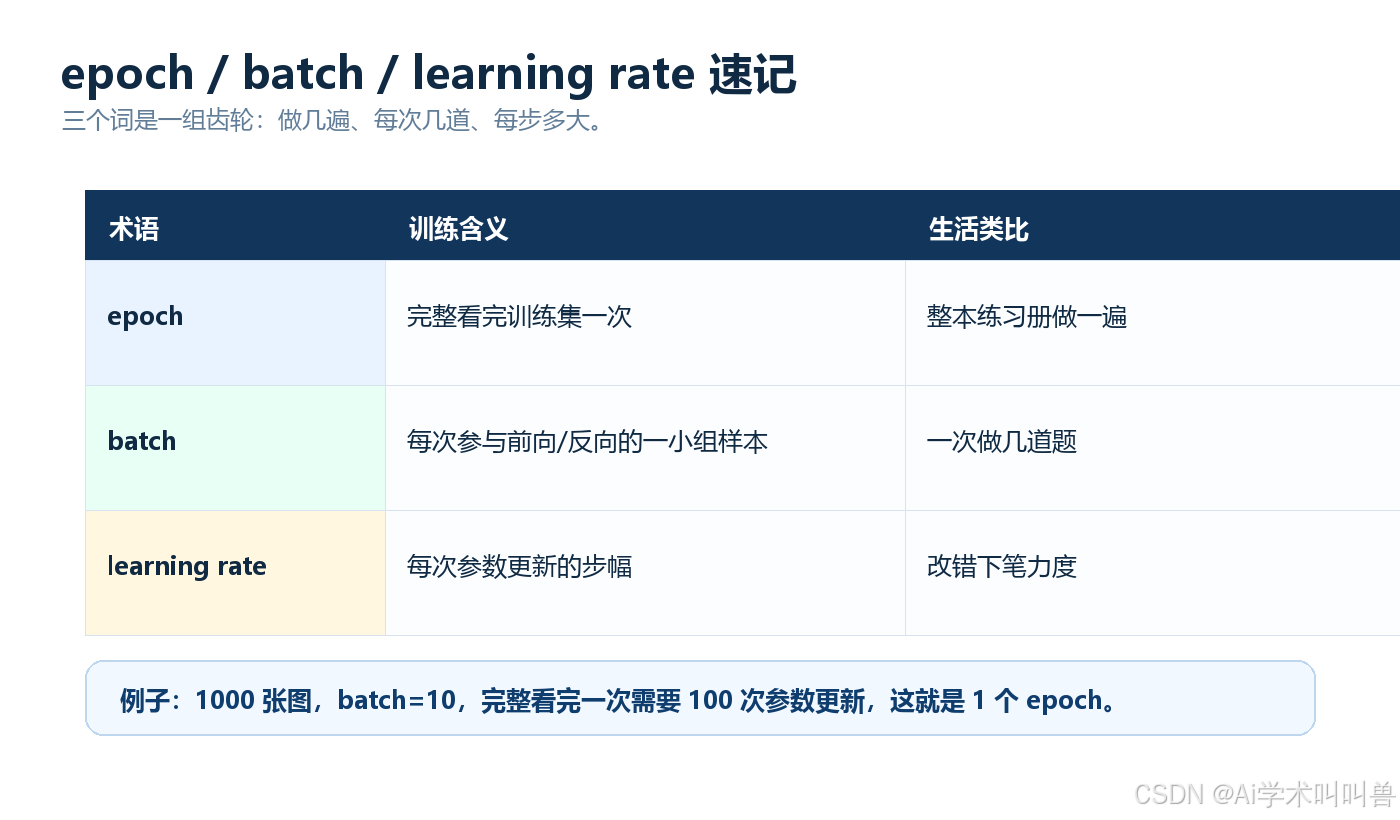
| 术语 | 含义 | 类比 |
|---|---|---|
| epoch | 模型完整看完训练集一次 | 整本练习册做一遍 |
| batch | 每次前向和反向计算的一小组样本 | 一次做几道题 |
| learning rate | 每次参数更新走多大一步 | 改错时改多大幅度 |
举个例子:
假设训练集有 1000 张图,batch=10。
那么模型每次拿 10 张图算一次 Loss、更新一次参数;完整看完 1000 张图,需要 100 次更新,这叫 1 个 epoch。
如果训练 50 个 epoch,就是整本练习册做 50 遍。
但注意:
epoch 不是越多越好,batch 不是越大越好,learning rate 也不是随便填。
epoch 太少可能没学会,太多可能过拟合;batch 太大可能显存不够,太小训练会抖;learning rate 太大可能震荡,太小可能学得很慢。
05 θ ← θ - α∇L 到底是什么意思?
这一讲唯一需要抓住的公式是:
text
θ ← θ - α∇L别被符号吓到,它翻译成人话就是:
参数等于旧参数,减去一小步能让 Loss 下降的方向。
| 符号 | 含义 | 小白理解 |
|---|---|---|
θ |
模型参数 | 模型当前的做题方法 |
L |
Loss | 错了多少 |
∇L |
梯度 | 往哪改能少错 |
α |
学习率 | 每次改多大步 |
如果用爬山类比:
Loss 是海拔,训练目标是往低处走;梯度告诉你哪里下坡;学习率决定你一步迈多远。
步子太大,可能越过低谷来回震荡;步子太小,走半天还在原地附近。
06 Loss 下降,模型就一定变好吗?
不一定。
这是很多新手最容易误会的地方。
训练 Loss 下降,只说明模型在训练集上的错误变小了。它可能真的学到了规律,也可能只是把训练样本记住了。

| 曲线现象 | 可能含义 | 先检查什么 |
|---|---|---|
| 训练 Loss 和验证 Loss 都下降 | 正常学习 | 继续观察指标和错例 |
| 训练 Loss 下降,验证 Loss 上升 | 可能过拟合 | 数据量、正则化、增强、epoch |
| Loss 一直很高 | 可能欠拟合或数据有问题 | 模型容量、学习率、标签 |
| Loss 剧烈震荡 | 训练不稳定 | 学习率、batch、异常样本 |
| 训练 Loss 很低但效果差 | 可能标签/指标/验证集问题 | 标签质量、指标、数据分布 |
所以文章看到这里,一定记住:
训练 Loss 只是体温计,不是最终诊断书。
你还要看验证集、测试集、指标、预测图和错例。
07 标签质量为什么这么重要?
监督学习里的标签,就是老师给模型的标准答案。
如果标准答案错了,模型会很认真地学错。
比如商品缺陷检测中,图片里明明有一个小划痕,但标注人员漏标了。对模型来说,这张图的监督信号就是:这里没有缺陷。
模型不会知道"老师可能漏标了"。它只会把漏标缺陷当作背景学进去。
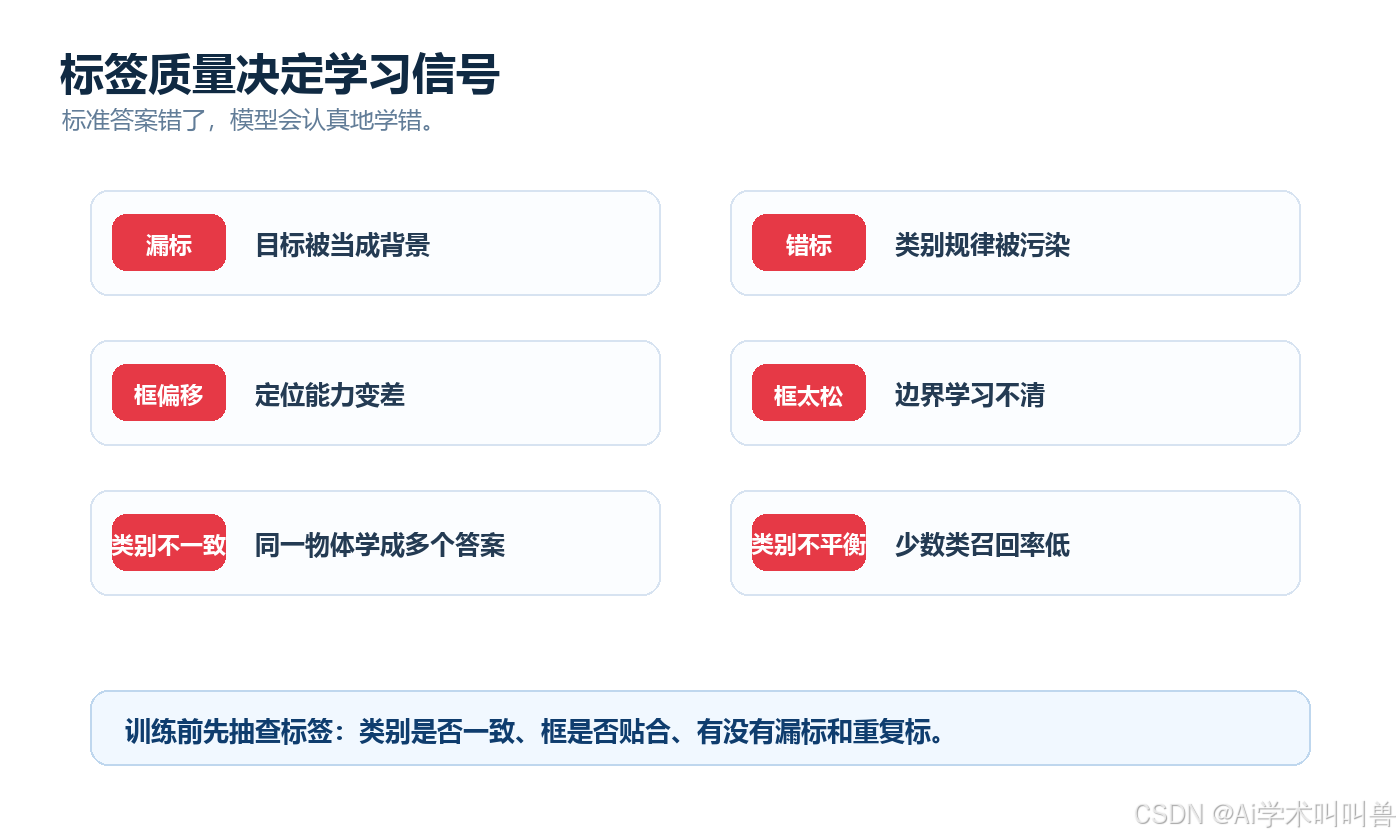
检测任务尤其要注意:
| 标签问题 | 结果风险 |
|---|---|
| 漏标 | 模型把目标当背景 |
| 错标 | 模型学错类别 |
| 框偏移 | 定位能力变差 |
| 框太松 | 模型不知道目标边界 |
| 类别不一致 | 同一物体学成多个答案 |
| 类别极不平衡 | 少数类召回率很差 |
很多时候模型效果差,不是模型不够先进,而是老师给的答案不干净。
所以做 YOLO26 数据集时,第一轮不要急着训练大模型。先随机抽 50 张图,看标签是否贴合目标、类别是否一致、有没有漏标。
08 实操教程:用最小例子看参数如何被 Loss 推着更新
下面这段代码不用数据集,也不用图片。它只做一件事:
让模型从一堆点里学出一条直线。
真实规律是:
text
y = 2x + 1模型一开始不知道 w=2、b=1,它会通过 Loss 一点点把参数学出来。
新建 01_numpy_tiny_training_loop.py:
python
import numpy as np
rng = np.random.default_rng(0)
x = np.linspace(-1, 1, 50)
y = 2 * x + 1 + rng.normal(0, 0.05, size=x.shape)
w = 0.0
b = 0.0
lr = 0.1
for epoch in range(101):
y_pred = w * x + b
loss = np.mean((y_pred - y) ** 2)
grad_w = np.mean(2 * (y_pred - y) * x)
grad_b = np.mean(2 * (y_pred - y))
w -= lr * grad_w
b -= lr * grad_b
if epoch % 20 == 0:
print(f"epoch={epoch:03d} loss={loss:.4f} w={w:.3f} b={b:.3f}")你会看到 w 慢慢靠近 2,b 慢慢靠近 1,Loss 逐渐下降。
这就是训练循环最小版本:
- 做预测:
y_pred = w * x + b - 算 Loss:均方误差
- 算梯度:
grad_w、grad_b - 更新参数:
w -= lr * grad_w - 重复很多轮
别小看这个例子。CNN、YOLO26 当然更复杂,但训练思想还是这条线。
09 实操教程:PyTorch 训练循环模板
下面给一个 PyTorch 版最小模板,适合小白以后改成自己的分类任务。
新建 02_pytorch_train_loop_template.py:
python
import torch
from torch import nn
from torch.utils.data import DataLoader, TensorDataset, random_split
torch.manual_seed(0)
x = torch.randn(600, 2)
y = (x[:, 0] + x[:, 1] > 0).long()
dataset = TensorDataset(x, y)
train_set, val_set = random_split(dataset, [500, 100])
train_loader = DataLoader(train_set, batch_size=32, shuffle=True)
val_loader = DataLoader(val_set, batch_size=64)
model = nn.Sequential(
nn.Linear(2, 16),
nn.ReLU(),
nn.Linear(16, 2),
)
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
for epoch in range(20):
model.train()
train_loss = 0.0
for xb, yb in train_loader:
pred = model(xb)
loss = loss_fn(pred, yb)
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_loss += loss.item() * xb.size(0)
train_loss /= len(train_loader.dataset)
model.eval()
correct = 0
with torch.no_grad():
for xb, yb in val_loader:
pred = model(xb)
correct += (pred.argmax(dim=1) == yb).sum().item()
val_acc = correct / len(val_loader.dataset)
print(f"epoch={epoch:02d} train_loss={train_loss:.4f} val_acc={val_acc:.3f}")你要重点看这 5 行:
python
optimizer.zero_grad()
loss.backward()
optimizer.step()
model.eval()
torch.no_grad()| 代码 | 作用 |
|---|---|
zero_grad() |
清空上一轮梯度 |
backward() |
反向传播,计算梯度 |
step() |
根据梯度更新参数 |
eval() |
切换到验证/推理模式 |
no_grad() |
验证时不计算梯度,节省显存 |
这就是 PyTorch 训练循环的基本骨架。
10 训练异常时,按这张表排查
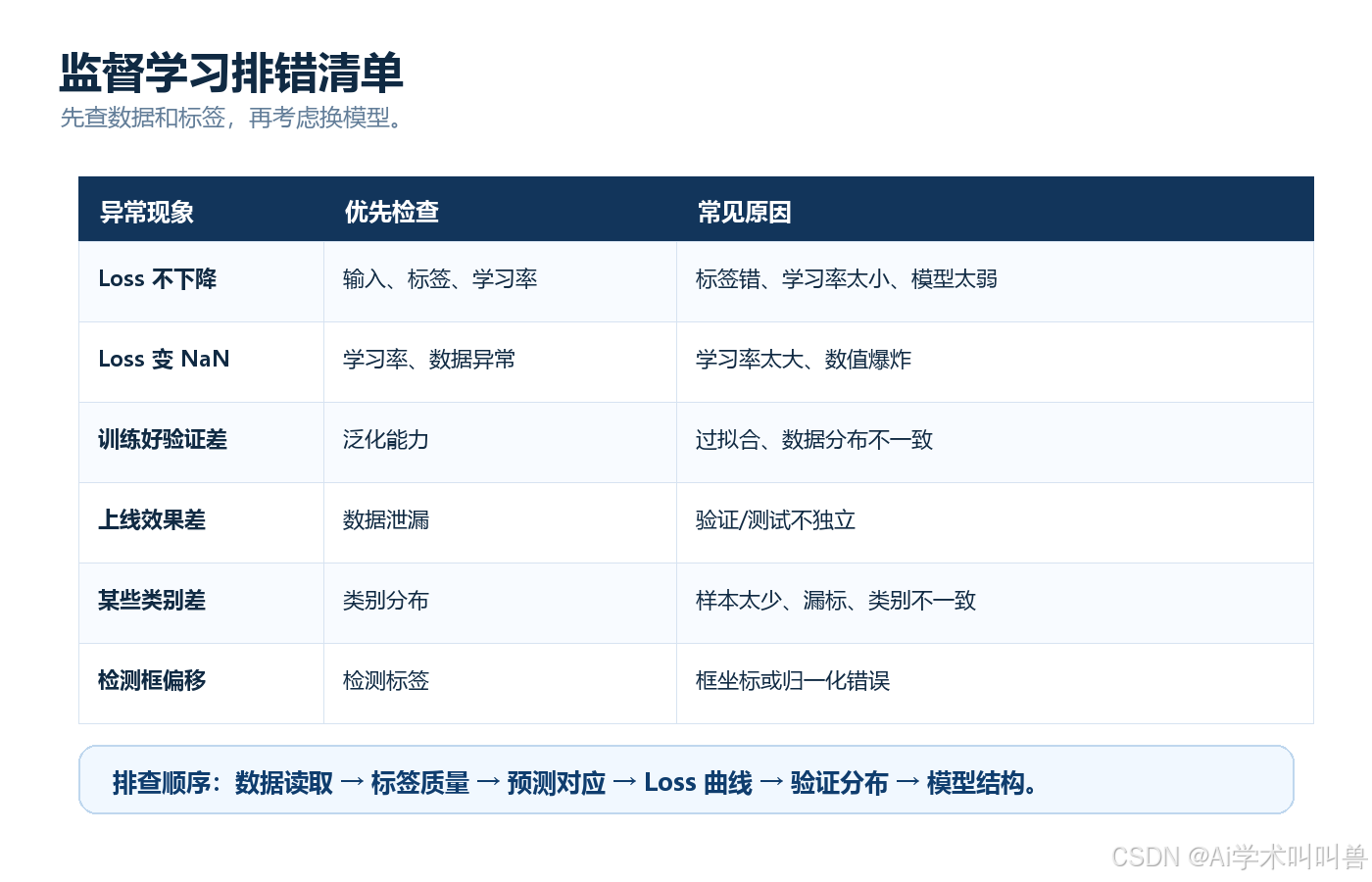
| 异常现象 | 优先检查 | 常见原因 |
|---|---|---|
| Loss 不下降 | 输入、标签、学习率 | 标签错、学习率太小、模型太弱 |
| Loss 变成 NaN | 学习率、数据异常 | 学习率太大、数值爆炸 |
| 训练好验证差 | 泛化能力 | 过拟合、数据分布不一致 |
| 验证集特别好但上线差 | 数据泄漏 | 验证/测试不独立 |
| 某些类别很差 | 类别分布 | 样本太少、漏标、类别不一致 |
| 检测框偏移 | 检测标签 | 框坐标或归一化错误 |
排查顺序建议:
- 先看数据能不能正确读取。
- 再看标签是否可信。
- 再看预测和标签能不能对应。
- 再看 Loss 是否正常下降。
- 再看验证集和训练集是否分布一致。
- 最后再考虑换模型、调结构。
科研小白最容易反过来:一出问题就换模型。更稳的做法是先查数据和标签。
11 学完本讲,你要能回答 6 个问题
- 训练集、验证集、测试集分别做什么?
- 一次训练循环包含哪 6 个步骤?
- Loss 是什么,为什么它能推动模型学习?
- 为什么训练 Loss 下降不等于实际效果一定提升?
- epoch、batch、learning rate 分别是什么意思?
- 为什么标签质量差时,模型会认真学错?
如果你能把这 6 个问题讲给别人听,第 03 讲就不是"看过了",而是真的学进去了。
12 最后总结
本讲最重要的一句话:
监督学习就是让模型反复"做题---对答案---算错分---改参数"。
完整训练闭环是:
输入样本 → 前向预测 → 计算 Loss → 反向传播 → 优化更新 → 验证观察
后面学 YOLO26 时,只要遇到训练问题,就回到这条链路检查:
数据进来了吗?标签对吗?Loss 算得合理吗?梯度能回传吗?学习率合适吗?验证集真的独立吗?
如果这篇文章帮你把监督学习想清楚了,建议先关注、收藏,也可以转给正在被 Loss 曲线折磨的同学。
评论区留言:Loss。下一篇继续整理第 04 讲:单神经元与逻辑回归,看看最小的可学习单元如何从输入产生预测。
参考资料
- B 站视频:《第03讲〈监督学习:数据、标签、Loss与训练循环〉》
https://www.bilibili.com/video/BV1Ttjg6XEaP/ - PyTorch Optimizing Model Parameters
https://docs.pytorch.org/tutorials/beginner/basics/optimization_tutorial.html - PyTorch Automatic Differentiation with torch.autograd
https://docs.pytorch.org/tutorials/beginner/basics/autogradqs_tutorial.html - Ultralytics YOLO Train 文档
https://docs.ultralytics.com/modes/train/