今天我看到有人说 DeepSeek 出了识图模式,我的第一反应是,识图?识图不是早就有吗?我之前经常拿着照片让 DeepSeek 提取文字啊。
幸亏我这句话没说出口,要不然该贻笑大方了。
然后我就在 x 上看到了陈小康发的推文。
陈小康是 DeepSeek 的多模态团队的领头人,曾本科和博士都就读于北大。
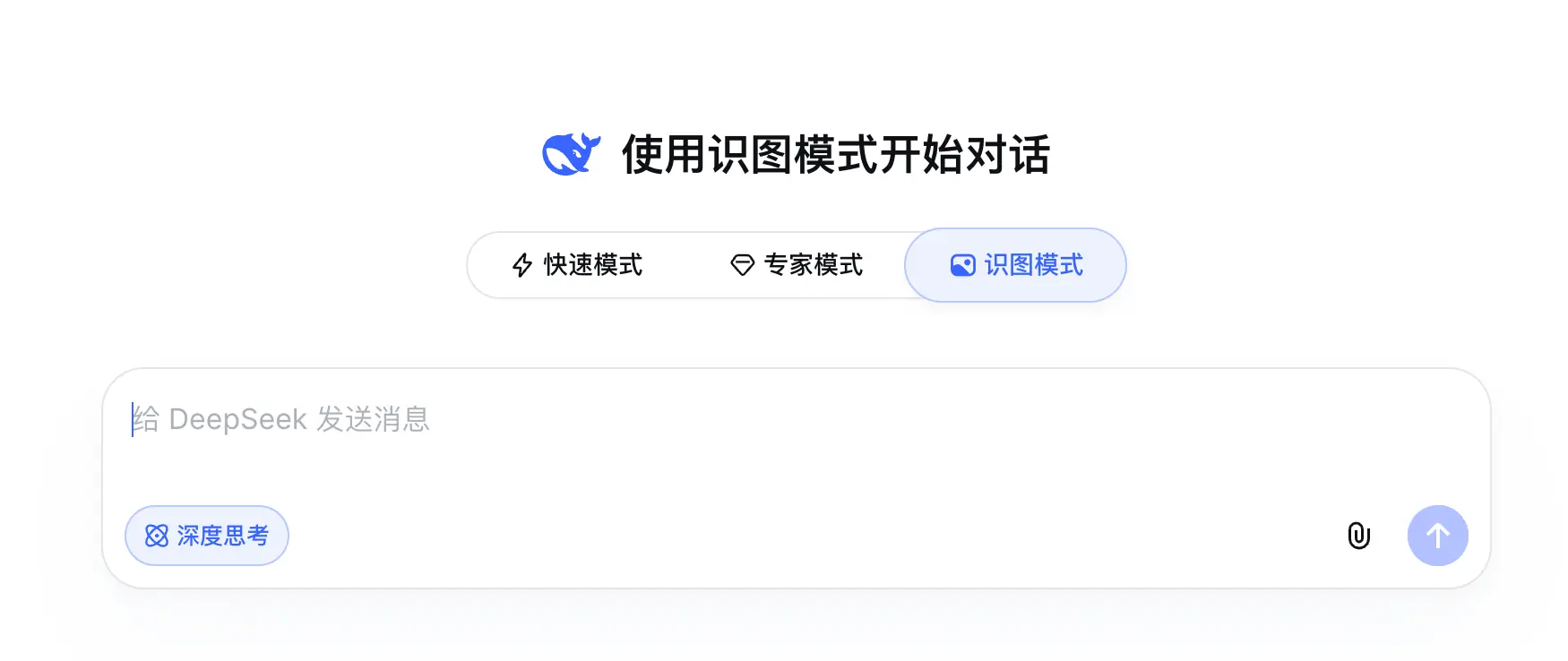
老实说,DeepSeek 的识图模式在 V4 发布几天后就上线了,但当时是灰度测试,并没有大范围开放。
而今天,识图模式终于迎来了大范围开放。
Web 端和 App 端都可以使用。
DeepSeek 的识图模式并不是从 OCR 中提取文字,而是终于认识图片了。
也就是说,DeepSeek,终于开天眼了。
于是,我赶紧让它分析了一张图片。

整个识图过程速度非常快。
它先判断这是夜间足球比赛现场,位置像 VIP/包厢区域;然后继续看人物,能说出这是一位穿米色套装、拿着墨镜、靠在护栏上的女士;再往后,它甚至注意到了右下角护栏上的葡萄牙队徽。
这个细节是他同时注意到了右侧的葡萄牙队徽,这就挺关键。
因为这张图如果只看大概,谁都能说出一个女士在球场上。
它说"很可能是里斯本的光明球场或巨龙球场"。
它没有直接下结论,这就是某个球场,它说可能是,因为现在不怕 AI 犯错,就怕犯错之后还一本正经的胡说八道。
这个识别错误并且纠正的成本太高了。
更让我意外的是后面那段。

它看出了这张图很可能是 AI 生成图像。
理由也给得比较具体:画面太干净,光影太电影感,皮肤和人物边缘融合得有点过于平滑。
现在网上到处都是 AI 图,很多图第一眼看上去已经不差了。你让人肉眼看,很多时候也只能说"感觉有点怪",但无法给出清晰的理由。
而且之前 ChatGPT 纠正图的时候,也只是从两点来判断的。
一个是检测到 SynthID,一个是检测到内容凭证。
这个更像是从图片源头的角度来判断。
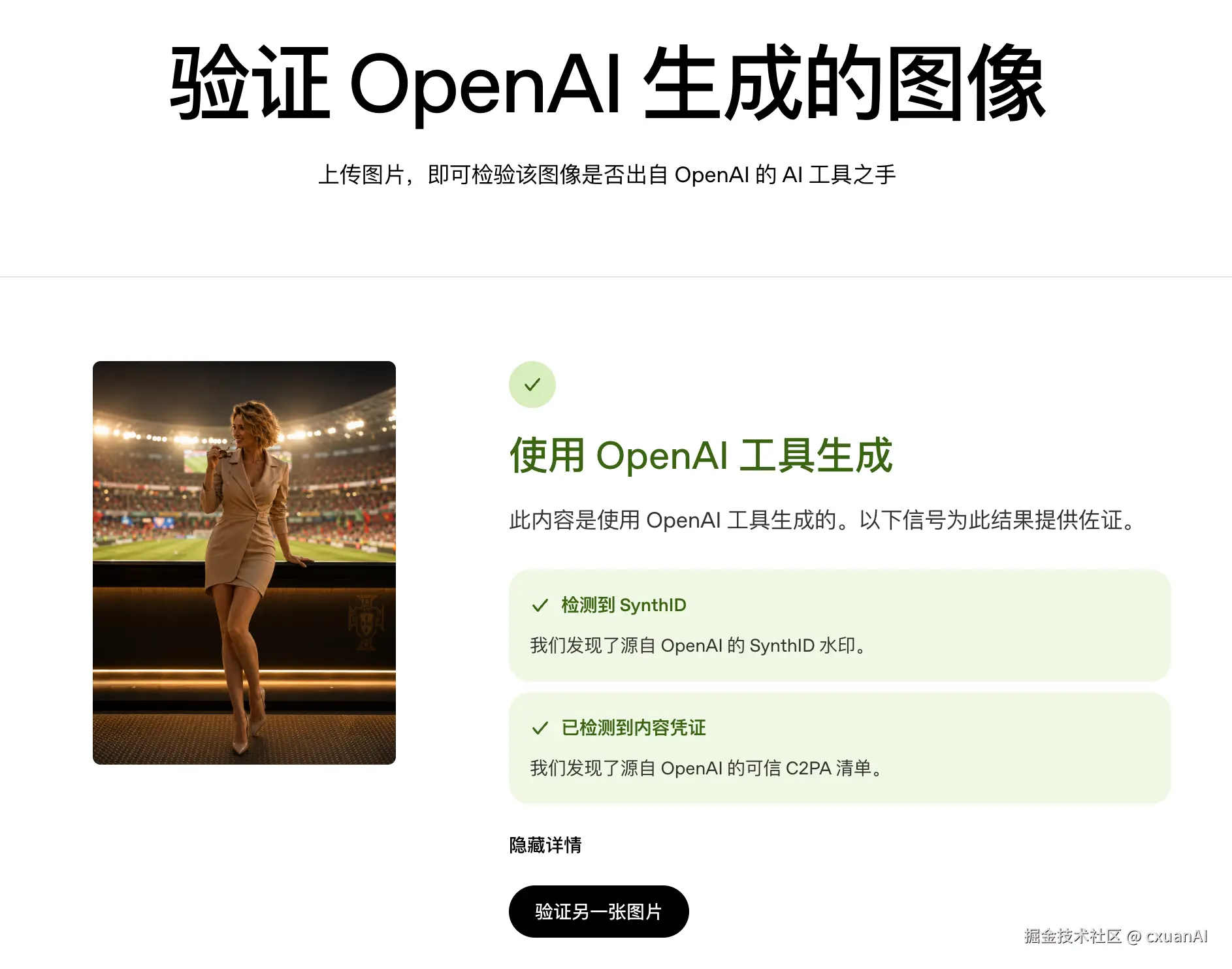
而 DeepSeek 是从图像本身出发来判断的。
而且 DeepSeek 对于图像识别的推理能力也很出色。
我用了这张充满戏谑的图来问让他解释一下。

由于推理过程太多,放图文效果很差,所以我这里给大家录一个视频,来感受下。
它的推理过程非常出色,但是整个推理过它犯了两个错误。
一个是错误的把 Claude 3.5 认成了 Fable 5,第二个是被禁的原因说的是无法向中国大陆者提供服务。
不过这两个错误我觉得问题不大,无非是知识库训练时间的问题。
它目前的训练时间还是在

我需要联网搜索才能让它查询到最新日期的消息。
但是识图功能目前不支持联网搜索。
所以这就死锁了。
也就是说,目前识图功能只能大概率确定图片是不是 AI 图,而无法实时的分析和解释图片内容。
但是这个限制,反而让我更确定它现在适合干嘛。
它不是一个"看图搜索引擎"。
它更像一个"看图推理器"。
你给它一张图,它能把图里的元素拆开,把人物、文字、动作、空间关系和画面质感给你说出来。
但如果这张图背后依赖的是昨天刚发生的新闻,或者今天刚火起来的梗,它就会出现刚才这种情况
不过,这次更新至少说明一件事:
DeepSeek 补上了多模态入口。
以后它要拼的,是看见以后,能不能继续把事想明白、做下去。