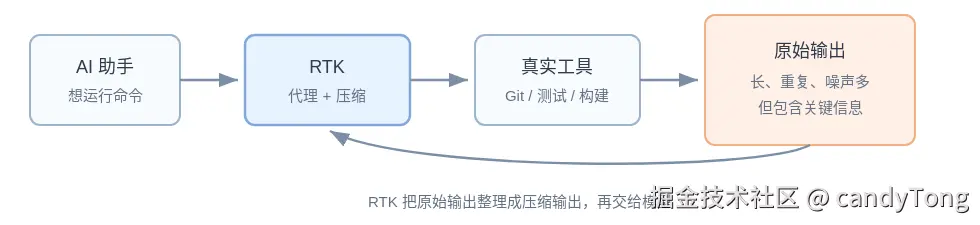
AI 编程助手修前端代码时,不会只靠聊天完成任务。它会反复运行命令:看 git status,用 rg 搜索组件,跑 pnpm test、vitest、tsc、eslint、next build,再根据结果继续修改。
这些命令原本是给人看终端用的。人会跳过进度条、重复日志、通过用例和样板提示,直接找错误位置。LLM 不会自动获得这层筛选。AI 助手里的 Bash / shell 执行工具把完整 stdout / stderr 作为 tool result 塞回上下文后,模型会同时看到有用信息和大量噪声。
RTK(Rust Token Killer)处理这段工具调用成本。它是一个 CLI / 代理层工具,放在 AI 助手和真实开发命令之间工作。它通过 hook 或 plugin 把 AI 助手准备执行的 Bash 命令改写成 RTK 代理命令。真实工具照常运行,文件系统副作用和退出码不应该被改变,但返回给模型的是压缩后的输出。
README 里有一个 30 分钟 Claude Code 会话估算:原始命令输出约 118,000 token,经过 RTK 后约 23,900 token,节省约 80%。这组数字不是固定承诺,它说明的是高频命令输出在典型 AI 编程会话里的成本。
命令输出为什么会吃掉上下文
AI 助手修一个问题时,会连续运行好几类命令:先看工作区状态,再搜索相关代码,然后跑测试或构建。每条命令的输出都会回到模型上下文里,和任务描述、已读代码、错误线索放在一起。
终端输出按人的阅读方式设计。git status 会带上 Git 的说明文本;vitest 或 jest 会打印通过用例、进度和失败栈;tsc、eslint、next build 会混合编译信息、规则提示、构建摘要和错误;搜索命令可能带回几十个无关命中。
这些内容进入上下文后,消耗的是同一块空间。噪声多一行,模型能保留的代码、约束和推理就少一行。上下文接近上限时,模型可能丢掉刚读过的关键文件,也可能忘掉上一轮定位到的失败原因。
模型需要的信息很窄:
| 命令类型 | 模型需要的信息 | 容易吃掉上下文的内容 |
|---|---|---|
| Git | 当前分支、变更文件、diff 摘要 | 模板说明、长 diff 头、重复元信息 |
| 测试 | 失败用例、断言差异、错误栈 | 通过用例、进度条、重复日志 |
| TypeScript / Lint / 构建 | 错误文件、行号、规则、失败原因 | banner、构建进度、长 warning 列表 |
| 搜索 / 文件读取 | 命中文件、关键行、必要上下文 | 无关命中、过长文件内容 |
RTK 处理这部分浪费。它不等模型读完整段终端日志后再总结,而是在命令输出进入上下文之前,先把适合机器消费的部分提出来。
RTK 只处理输出边界
RTK 不修 bug,也不替模型判断代码对不对。它只处理命令输出进入模型之前的那一段。
AI 助手运行 vitest 时,RTK 仍然调用测试框架;助手运行 next build 时,RTK 仍然调用 Next.js;助手运行 git diff 时,RTK 仍然调用 Git。RTK 只压缩真实工具的输出。
它有三类职责:

传话:接住 AI 助手要运行的命令,把它交给真实工具。
整理:过滤真实工具返回的 stdout / stderr,保留模型下一步需要的信息。
记账:记录原始输出和压缩输出的差异,让用户看到节省了多少 token。
RTK 的目标是减少 LLM 上下文里的无效 token。
Hook 接入:用户写原命令,RTK 自动接管
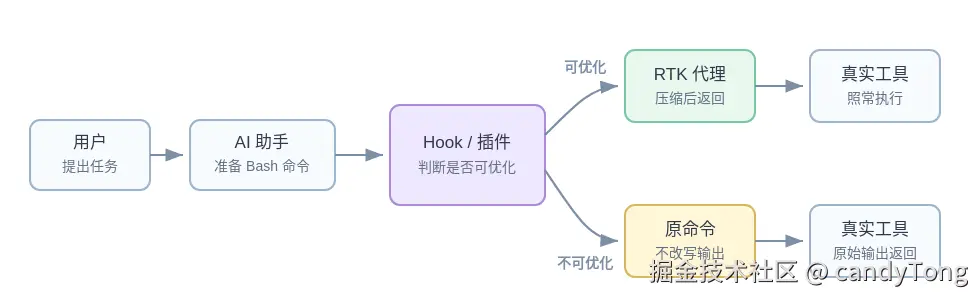
用户不需要每次手写代理命令。安装 hook 或 plugin 后,AI 助手仍然发起普通 Bash 命令,改写发生在命令执行前。
hook 接在 AI 助手调用 Bash 工具之前。助手提交原始命令,hook 可以把这段命令文本替换成另一条命令,再交给执行器运行。
在 Claude Code 里,RTK 会把自己注册成 PreToolUse hook。settings.json 大致长这样:
json
{
"hooks": {
"PreToolUse": [
{
"matcher": "Bash",
"hooks": [
{
"type": "command",
"command": "rtk hook claude"
}
]
}
]
}
}模型不需要记住"我应该主动用 RTK"。用户也不用改变和 AI 助手协作的方式。可优化命令在执行前被路由到 RTK,模型收到的是过滤后的结果。
Bash / terminal tool call 才会触发这类透明改写。Claude Code 的内置读文件、搜索、Glob 能力不一定经过 Bash hook;这类场景要么显式使用 shell 命令,要么直接调用 rtk read、rtk grep、rtk find。
RTK 也保留直接调用方式。用户可以显式运行 rtk grep、rtk read、rtk find,也可以用 rtk proxy 跑暂不支持的命令并记录用量。
代理执行:真实工具照常运行
命令被改写后,RTK 进入代理执行阶段。这个"代理"不要求模型换写法,也不依赖用户的 shell alias。
命令改写:PreToolUse 返回新的 Bash 输入
先看 PreToolUse 这类 hook 的通用原理。AI 助手准备调用 Bash 工具时,宿主先启动配置好的 hook 命令,并把这次工具调用的信息通过 stdin 传给 hook。输入里会有工具名和工具参数,例如工具名是 Bash,参数里有 command: "git status"。
hook 如果不想介入,可以什么都不返回,让宿主按原样执行。如果要改写 Bash 命令,就往 stdout 返回一段结构化结果,告诉宿主替换这次工具输入。在 Claude Code 这类格式里,关键字段是 hookSpecificOutput.updatedInput.command,它会覆盖原来的 command 字段:
json
{
"hookSpecificOutput": {
"hookEventName": "PreToolUse",
"permissionDecision": "ask",
"permissionDecisionReason": "rewrite command before Bash runs",
"updatedInput": {
"command": "rtk git status"
}
}
}宿主收到这段返回后,把 updatedInput.command 里的新命令交给 Bash。代理发生在工具调用参数提交给 Bash 之前。
RTK 用这层机制改写命令文本。改写后的 rtk ... 命令启动后,RTK 进程调用真实的 Git、测试框架、构建工具,捕获 stdout / stderr,过滤后把结果打印回 Bash tool result。
RTK 先保证真实命令照常运行,再处理输出。
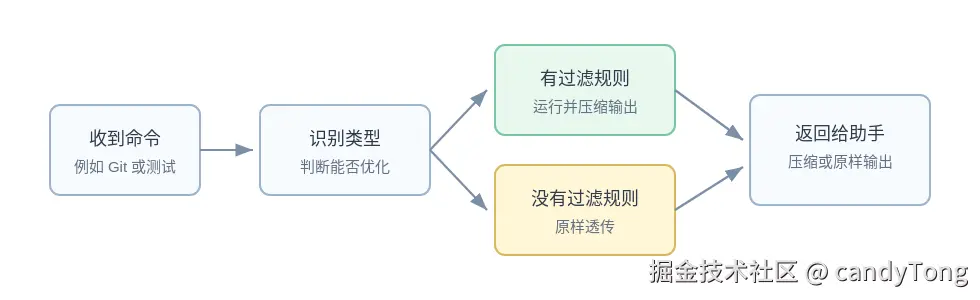
图里的关键点:RTK 先判断有没有可靠规则,有就压缩,没有就透传。省 token 不能破坏真实命令行为。
这条链路里有几个底线:
- 真实工具仍然执行:Git 还是 Git,测试框架还是测试框架。
- 退出码要保留:测试失败、构建失败、Git 命令失败,都不能被压缩过程吞掉。
- 不认识的命令要透传:RTK 没有可靠规则时,不强行改写输出。
- 过滤失败要可回退:压缩工具不能破坏原始排障路径。
这些底线把 RTK 限定在开发工具链代理的位置,而不是日志总结脚本。
RTK 如何识别命令类型
RTK 分两层识别命令。
第一层发生在 hook 或 plugin 里。Claude Code 准备执行 Bash 命令时,RTK hook 会拿到原始命令文本。它先判断这条命令有没有已知改写规则:git status 可以改写到 rtk git status,rg Button src 可以改写到 RTK 的搜索过滤链路,vitest、tsc、eslint、next build 这类前端命令也会进入对应代理路径。
比如 AI 助手想运行 rg Button src。hook 先判断它是搜索命令,再把它交给 RTK 的搜索链路;RTK 运行真实搜索工具后,按文件分组命中行,并截断过长上下文,最后把更短的搜索结果返回给模型。
第二层发生在 RTK 进程内部。命令已经带上 rtk 前缀后,RTK 会根据子命令和工具名路由到具体模块:
| 原始命令形态 | RTK 识别到的类型 | 后续过滤重点 |
|---|---|---|
git status / git diff |
Git | 分支、变更文件、diff 摘要 |
rg ... / grep ... |
搜索 | 命中文件、关键行、截断上下文 |
vitest / jest |
前端测试 | 失败用例、断言差异、错误栈 |
tsc |
TypeScript | 文件、行号、类型错误 |
eslint / biome |
Lint | 文件、规则、错误数量 |
next build / vite build |
构建 | 构建错误、关键 warning、摘要 |
hook 找不到可靠规则时,不改写命令。RTK 内部没有对应过滤器时,走原样透传或通用处理。识别类型只服务于一件事:在有把握压缩时介入。
过滤阶段:按命令类型提取信号
统一截断解决不了命令输出问题。
测试失败的关键内容可能在末尾。Git diff 的关键内容在变更行。eslint 输出要按规则和文件聚合。tsc 输出要按文件和错误位置整理。搜索输出要按文件分组并截断长行。
RTK 因此按命令类型选择过滤器。
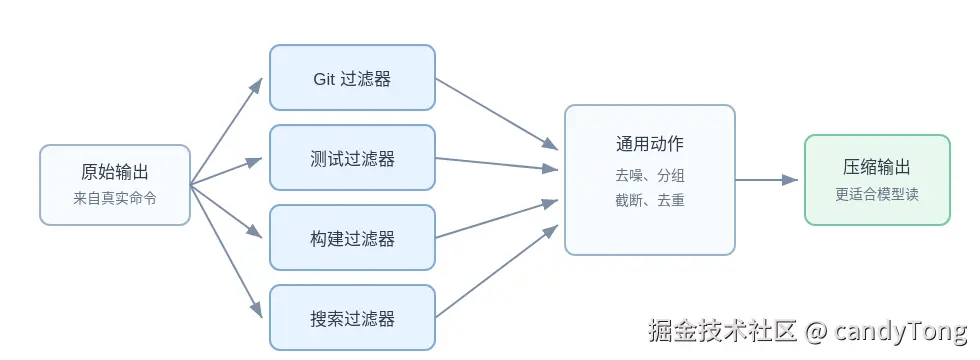
不同命令的噪声长得不一样,过滤器不能只做统一截断。
以 git status 为例。普通输出适合人看,会带上分支说明、未跟踪文件提示和 git add 建议。模型需要更短的状态信号:当前分支、文件状态,以及仓库是否处在 rebase、merge、cherry-pick、detached HEAD 这类危险状态里。
RTK 默认用更适合机器解析的状态输出生成短结果,同时从普通 git status 头部补回危险状态。这样既删掉了 Git 的提示语,也不会因为压缩把关键仓库状态藏起来。
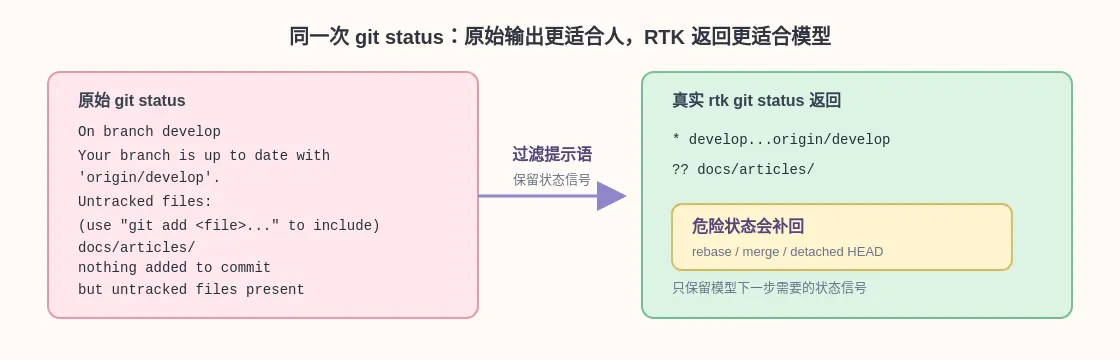
RTK 过滤器先判断哪些信息会影响模型下一步行动,再删掉解释性、重复性和过长的内容。
常见过滤策略包括:
- Git 输出压缩:保留分支、变更文件、提交摘要、diff 统计,删掉长说明和冗余头部。
- 前端测试失败聚焦 :隐藏通过用例,保留
vitest、jest、playwright test的失败用例、断言差异和相关栈信息。 - TypeScript / Lint 分组 :按文件、规则或错误类型聚合
tsc、eslint、biome输出,让模型先看到错误分布。 - 构建输出整理 :从
next build、vite build里保留路由摘要、构建错误和关键 warning。 - 搜索结果整理:按文件分组命中,截断过长行,避免把整个代码库塞进上下文。
不同命令的"有用信息"不同。RTK 的过滤器要理解这些差异,而不是用一把尺子裁所有输出。
共享 runner:把执行链收在一起
RTK 支持很多开发常用命令:Git、GitHub CLI、pnpm、npm、vitest、jest、tsc、eslint、next build、playwright test、文件读取和搜索等。命令种类多,代理执行的骨架相似。
过滤器负责"某类输出怎样压缩"。runner 负责把真实命令运行、输出捕获、过滤调用、结果打印、统计记录这些通用步骤串起来。

runner 大致支持四类处理方式:
| 处理方式 | 适合场景 | 结果 |
|---|---|---|
| 一次性过滤 | 输出不长,结构清楚 | 收完整输出后再压缩 |
| 看退出码过滤 | 成功和失败需要不同摘要 | 成功极短,失败保留证据 |
| 流式过滤 | 输出较长 | 边读边处理 |
| 原样通过 | 没有可靠规则 | 保持原始输出 |
共享 runner 让命令模块复用执行逻辑。过滤器只关注"怎样把这个命令的输出压缩好"。
失败路径:不能只返回一句"失败了"
成功输出可以很短。vitest 通过、tsc 无类型错误、next build 完成、Git add 成功,模型往往只需要一个状态信号。
失败输出不能压成一句"失败了"。模型下一步要修问题,至少需要知道:
- 哪个文件出错。
- 哪个测试或构建步骤失败。
- 错误位置和错误类型。
- 断言差异或相关栈信息。
- 必要时怎样回看原始输出。
RTK 需要在压缩率和证据保留之间做取舍。它默认给模型更短的结果,也保留回看能力:需要时可以查看原始输出,用 verbose 模式拿到更多细节,或者用 tee 保存原始日志。压缩不能关掉后续排障入口。
TOML 规则:给简单命令做轻量扩展
专门模块适合复杂命令,小脚本不一定需要。
很多团队内部脚本只需要简单规则:删除进度行、保留错误行、去掉 ANSI 颜色码、限制最大行数、输出为空时返回默认摘要。
RTK 用 TOML 规则承载这类轻量扩展。它是一层声明式文本过滤,适合处理输出格式稳定、规则简单、团队经常运行的命令。
比如团队里有一个 api pull 命令,用来从接口平台拉取请求类型和发起请求的代码。原始输出可能长这样:
text
[auth] refreshing token
[download] GET https://api.example.com/openapi.json
[cache] schema unchanged: shared/common.json
[type] UserProfile -> src/api/types/user.ts
[type] OrderDetail -> src/api/types/order.ts
[client] GET /api/users/:id -> src/api/user.ts fetchUser
[client] POST /api/orders -> src/api/order.ts createOrder
[progress] generated 2 type files, 2 client files
[done] api pull completed in 4.8s模型需要知道哪些类型文件变了、哪些请求函数变了、有没有失败或 warning。用 TOML 规则做轻量过滤后,返回可以压成:
text
[type] UserProfile -> src/api/types/user.ts
[type] OrderDetail -> src/api/types/order.ts
[client] GET /api/users/:id -> src/api/user.ts fetchUser
[client] POST /api/orders -> src/api/order.ts createOrder
[done] api pull completed in 4.8sapi pull 适合 TOML,因为输出按行稳定,保留 [type]、[client]、[warn]、[error]、[done] 这几类行就够了。如果团队以后要解析 OpenAPI JSON、按模块重新分组、合并重复类型、判断 breaking change,就应该写专用过滤器。
对应的项目级 TOML 规则可以放在 .rtk/filters.toml:
toml
[filters.api-pull]
description = "Keep generated API types, client functions, and failures"
match_command = "^api\\s+pull\\b"
strip_ansi = true
keep_lines_matching = [
"^\\[type\\]",
"^\\[client\\]",
"^\\[warn\\]",
"^\\[error\\]",
"^\\[done\\]",
]
truncate_lines_at = 160
max_lines = 80
on_empty = "api pull: no changed API output"这段配置不理解接口结构,只在稳定日志里保留关键行。仓库里的 .rtk/filters.toml 需要用户信任后才会生效,因为它会影响 AI 助手看到哪些命令输出。
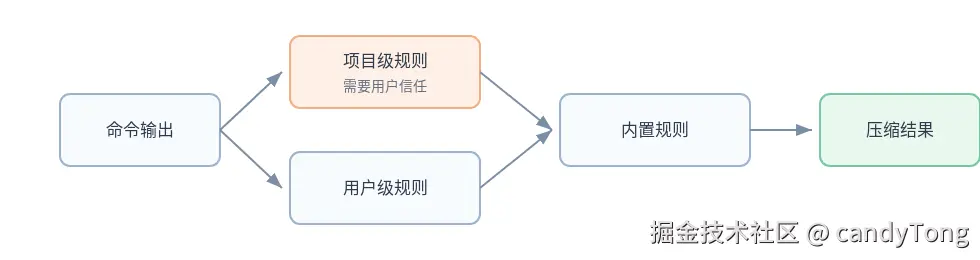
TOML 规则降低扩展成本。团队可以把常见噪声沉淀成配置,不必为了每个小脚本都改 Rust 代码。RTK 仍然保留专用过滤器处理 Git、前端测试、TypeScript、构建、Lint 这类复杂输出。
TOML 适合扩展简单命令。没有被专用模块接管的命令,可以先尝试 TOML 规则;需要理解结构、分组错误、解析 JSON、处理失败路径或流式输出的命令,应该写专用过滤器。Git、tsc、vitest、next build、eslint 这类内置命令先走对应的专用过滤器,而不是让项目 TOML 规则直接覆盖。
项目级规则还需要信任机制。仓库里的规则可能来自别人提交,它虽然不是 shell 脚本,但会影响 AI 助手看到什么。RTK 要求用户显式信任项目级规则后再启用。
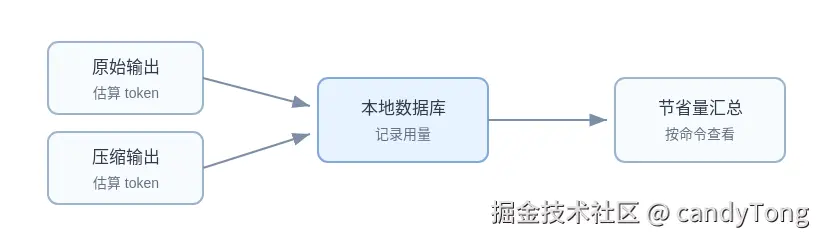
统计系统:节省量怎样被看见
RTK 会记录原始输出和过滤输出的 token 估算。用户可以通过 rtk gain 看累计节省,也可以用 rtk discover 找还没有接入 RTK 的高浪费命令。
总结
AI 助手写代码时,命令输出很容易变成另一种上下文债务。一次 git status 不算多,几轮搜索、测试、构建叠在一起,模型要读的噪声就会超过真正的线索。
RTK 的做法很克制:命令还是原来的命令,Git、测试框架、构建工具照常运行;进入模型之前,输出先被整理成更适合下一步行动的信息。成功时给状态,失败时保留证据,不认识的命令就透传。
你可以把 RTK 当成 AI 编程会话里的输出闸门。它不替模型写代码,也不替工具做判断;它只让模型少读一些没用的终端文本,多保留一些代码、错误和上下文。
如果你觉得这篇文章有帮助,欢迎点赞、收藏,也可以关注我。